
Q-learning(DQN):强化学习之摆车
强化学习经典算法Q-learning(DQN)从0开始搭建,并使用目标网络缓解高估问题。在(Cartpole-v0)摆车环境中应用,获得了不错的效果。欢迎fork及交流学习,谢谢~
1.项目介绍
Q-learning :Q-learning 最早在1989年提出,最开始是基于表格形式。
DQN:DQN(deep Q network)则是 2013 年才提出,它是基于深度神经网络的Q-learning,也是目前我们最常使用的Q-learning算法。
本项目的目标:
使用DQN算法训练一个智能体,使其在摆车环境中获得较高的奖励值。关于摆车的详细描述,可以参考博客:OpenAI Gym 经典控制环境介绍——CartPole
本项目的参考内容有:
- 强化学习7日打卡营中的课节四:基于神经网络方法求解RL
- Paddle的高性能、灵活的强化学习框架:PARL
- 王树森老师的深度强化学习书籍
2.导入依赖
import os
import gym
import numpy as np
import paddle
from collections import deque
from visualdl import LogWriter
import copy
import time
3. 构建模型
3.1 DQN网络结构
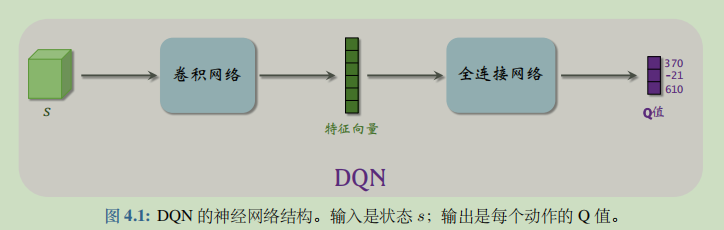
因为我们的状态s是一维向量,所以在实际中用的是全连接层
class MyDQNnetwork(paddle.nn.Layer):
# state_size : 状态空间的大小
# action_size: 动作空间的大小
def __init__(self, state_size, action_size):
super(MyDQNnetwork, self).__init__()
self.fc1 = paddle.nn.Linear(state_size, 128)
self.fc2 = paddle.nn.Linear(128, 128)
self.fc3 = paddle.nn.Linear(128, action_size)
self.relu=paddle.nn.ReLU()
def forward(self, state):
out = self.relu(self.fc1(state))
out = self.relu(self.fc2(out))
q = self.fc3(out)
return q
3.2 经验回放数组
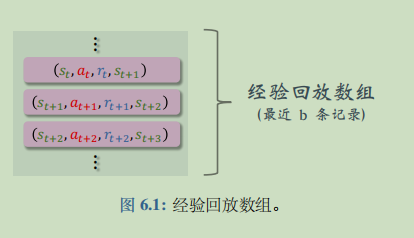
经验回放(experience replay)是强化学习中一个重要的技巧,可以大幅提升强化学习的表现。经验回放的意思是把智能体与环境交互的记录(即经验)储存到一个数组里,事后反复利用这些经验训练智能体。这个数组被称为经验回放数组(replay buffer)。
经验回放的优点:
-
打破序列的相关性:训练 DQN 的时候,每次我们用一个四元组对 DQN 的参数做一次更新。我们希望相邻两次使用的四元组是独立的。然而当智能体收集经验的时候,相邻两个四元组 (st, at, rt, st+1) 和 (st+1, at+1, rt+1, st+2) 有很强的相关性。依次使用这些强关联的四元组训练 DQN,效果往往会很差。经验回放每从数组里随机抽取一个四元组,用来对 DQN 参数做一次更新。这样随机抽到的四元都是独立的,消除了相关性。
-
重复利用收集到的经验,而不是用一次就丢弃,这样可以用更少的样本数量达到同样的表现
实际操作的修改:
-
使用deque存储经验,deque是Python的双端队列,当指定容量后,如继续向队尾加入元素,队首元素自动出队。
-
实际使用的时候,经验数组存储的不一定是四元组,可能是n元组(该项目就是用的五元组),根据实际情况而定。
class MyMemoryBuffer(object):
def __init__(self,memory_size):
self.memory_size=memory_size
self.buffer=deque(maxlen=self.memory_size)
# 增加经验,因为经验数组是存放在deque中的,deque是双端队列,
# 我们的deque指定了大小,当deque满了之后再add元素,则会自动把队首的元素出队
def add(self,experience):
self.buffer.append(experience)
def size(self):
return len(self.buffer)
# continuous=True则表示连续取batch_size个经验
def sample(self , batch_szie , continuous = True):
# 选取的经验数目是否超过缓冲区内经验的数目
if batch_szie>len(self.buffer):
batch_szie=len(self.buffer)
# 是否连续取经验
if continuous:
# random.randint(a,b) 返回[a,b]之间的任意整数
rand=np.random.randint(0,len(self.buffer)-batch_szie)
return [self.buffer[i] for i in range(rand,rand+batch_szie)]
else:
# numpy.random.choice(a, size=None, replace=True, p=None)
# a 如果是数组则在数组中采样;a如果是整数,则从[0,a-1]这个序列中随机采样
# size 如果是整数则表示采样的数量
# replace为True可以重复采样;为false不会重复
# p 是一个数组,表示a中每个元素采样的概率;为None则表示等概率采样
indexes=np.random.choice(np.arange(len(self.buffer)),size=batch_szie,replace=False)
return [self.buffer[i] for i in indexes]
def clear(self):
self.buffer.clear()
4. 定义智能体
异策略、行为策略、目标策略:
- 行为策略: 在强化学习中,我们让智能体与环境交互,记录下观测到的状态、动作、奖励,用这些经验来学习一个策略函数。在这一过程中,控制智能体与环境交互的策略被称作行为策略。行为策略的作用是收集经验 (experience),即观测的环境、动作、奖励。
- 目标策略:训练的目的是得到一个策略函数,在结束训练之后,用这个策略函数来控制智能体;这个策略函数就叫做目标策略。
- 行为策略和目标策略可以相同,也可以不同。同策略是指用相同的行为策略和目标策略;异策略是指用不同的行为策略和目标策略。
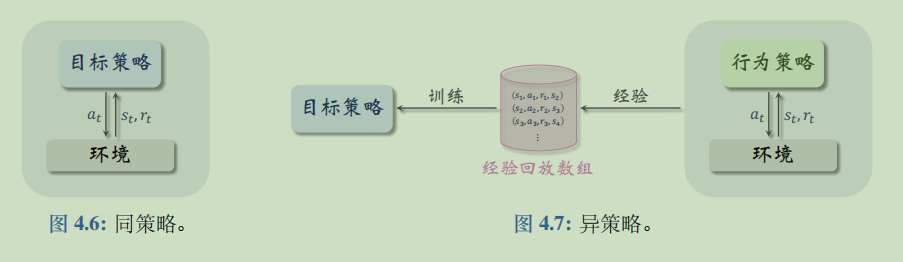
DQN是异策略。在该项目中,行为策略使用的是ϵ-greedy策略,这是比较常用的,也是比较简单的。在我们的代码中对应sample函数

目标策略是一个确定性的策略,即用 DQN网络进行预测,在代码中对应predict函数。
目标网络:
Q 学习算法有一个缺陷:用 Q 学习训练出的 DQN 会高估真实的价值,而且高估通
常是非均匀的。这个缺陷导致 DQN 的表现很差。高估问题并不是 DQN 模型的缺陷而
是 Q 学习算法的缺陷。Q 学习产生高估的一个原因是自举导致偏差的传播(其实不止一个原因,可以参考王树森老师的书)。
自举问题在这里的体现就是DQN让自己去拟合自己做出的估计。如果估计高了,那么拟合值会高,进而再估计,再拟合…就这么一直高下去。缓解自举问题的一个方法是使用目标网络。

智能体的训练流程如下:
主要体现在learn函数中
- DQN正向传播,输入是s_t,a_t,输出得到q_t
- 目标网络正向传播,输入是s_t+1,a_t,输出得到q’_t
- 计算TD目标 y=r_t+gamma*q’_t
- 计算TD误差 error=q_t-y
- DQN反向传播,计算梯度,进行更新
- 更新目标网络的参数(可以多个时间步执行一次)
# 更新目标网络的操作函数,在MyDQNAgent.learn()函数中调用
def soft_update(target,source,tau=0):
# zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
for target_param,param in zip(target.parameters(),source.parameters()):
target_param.set_value(target_param*tau+param*(1.0-tau))
class MyDQNAgent():
def __init__(self, model, action_size,gamma=None, lr=None, e_greed=0.1, e_greed_decrement=0):
self.action_size = action_size
self.global_step = 0
self.update_target_steps = 200 # 每200个时间步更新一次目标网络的参数
self.e_greed = e_greed # ϵ-greedy中的ϵ
self.e_greed_decrement = e_greed_decrement # ϵ的动态更新因子
self.model = model
self.target_model = copy.deepcopy(model)
self.gamma = gamma # 回报折扣因子
self.lr = lr
self.mse_loss = paddle.nn.MSELoss(reduction='mean')
self.optimizer = paddle.optimizer.Adam(learning_rate=lr, parameters=self.model.parameters())
# 使用行为策略生成动作
def sample(self, state):
sample = np.random.random() # [0.0, 1.0)
if sample < self.e_greed:
act = np.random.randint(self.action_size) # 返回[0, action_size)的整数,这里就是0或1
else:
if np.random.random() < 0.01:
act = np.random.randint(self.action_size)
else:
act = self.predict(state)
# 动态更改e_greed,但不小于0.01
self.e_greed = max(0.01, self.e_greed - self.e_greed_decrement)
return act
# DQN网络做预测
def predict(self, state):
state = paddle.to_tensor(state, dtype='float32')
# DQN网络做预测
pred_q = self.model(state)
# 选取概率值最大的动作
act = pred_q.argmax().numpy()[0]
return act
# 更新DQN网络
def learn(self, state, action, reward, next_state, terminal):
"""Update model with an episode data
Args:
state(np.float32): shape of (batch_size, state_size)
act(np.int32): shape of (batch_size)
reward(np.float32): shape of (batch_size)
next_state(np.float32): shape of (batch_size, state_size)
terminal(np.float32): shape of (batch_size)
Returns:
loss(float)
"""
if self.global_step % self.update_target_steps == 0:
# 6. 更新目标网络
soft_update(self.target_model,self.model)
self.global_step += 1
action = np.expand_dims(action, axis=-1)
reward = np.expand_dims(reward, axis=-1)
terminal = np.expand_dims(terminal, axis=-1)
state = paddle.to_tensor(state, dtype='float32')
action = paddle.to_tensor(action, dtype='int32')
reward = paddle.to_tensor(reward, dtype='float32')
next_state = paddle.to_tensor(next_state, dtype='float32')
terminal = paddle.to_tensor(terminal, dtype='float32')
# 1. DQN网络做正向传播
pred_values = self.model(state)
# action的维度:2
action_dim = pred_values.shape[-1]
# 删除输入action的Shape中尺寸为1的维度
action = paddle.squeeze(action, axis=-1)
# action进行onhot编码
action_onehot = paddle.nn.functional.one_hot(action, num_classes=action_dim)
pred_value = paddle.multiply(pred_values, action_onehot)
pred_value = paddle.sum(pred_value, axis=1, keepdim=True)
# target Q
with paddle.no_grad():
# 2. 目标网络做正向传播
max_v = self.target_model(next_state).max(1, keepdim=True)
# 3. TD 目标
target = reward + (1 - terminal) * self.gamma * max_v
# 4. TD 误差
loss = self.mse_loss(pred_value, target)
# 5. 更新DQN的参数
# 梯度清零
self.optimizer.clear_grad()
# 反向计算梯度
loss.backward()
# 梯度更新
self.optimizer.step()
return loss.numpy()[0]
5. 训练
5.1 定义可视化文件路径
writer=LogWriter('./logs')
5.2 训练
LEARN_FREQ = 5 # 训练的频率,
MEMORY_SIZE = 200000 # 经验数组大小
MEMORY_WARMUP_SIZE = 200 # 开始训练的经验数量阈值
BATCH_SIZE = 32
LEARNING_RATE = 0.0005
GAMMA = 0.99
# 启用环境进行训练,done=1则结束该次训练,返回奖励值
def run_train_episode(agent, env, rpmemory):
total_reward = 0
state = env.reset()
step = 0
while True:
step += 1
# 智能体抽样动作
action = agent.sample(state)
next_state, reward, done, _ = env.step(action)
rpmemory.add((state, action, reward, next_state, done))
# 当经验回放数组中的经验数量足够多时(大于给定阈值,手动设定),每5个时间步训练一次
if (rpmemory.size() > MEMORY_WARMUP_SIZE) and (step % LEARN_FREQ == 0):
# s,a,r,s',done
experiences=rpmemory.sample(BATCH_SIZE)
batch_state, batch_action, batch_reward, batch_next_state,batch_done = zip(*experiences)
# 智能体更新价值网络
train_loss = agent.learn(batch_state, batch_action, batch_reward,batch_next_state, batch_done)
total_reward += reward
state = next_state
if done:
break
return total_reward
# 验证环境5次,取平均的奖励值
def run_evaluate_episodes(agent, env, eval_episodes=5, render=False):
eval_reward = []
for i in range(eval_episodes):
state = env.reset()
episode_reward = 0
while True:
# 智能体选取动作执行
action = agent.predict(state)
state, reward, done, _ = env.step(action)
episode_reward += reward
# render 在AI studio平台不支持,可在自己的计算机上开启
if render:
env.render()
if done:
break
eval_reward.append(episode_reward)
return np.mean(eval_reward)
def main():
# 加载环境
env = gym.make('CartPole-v0')
state_size = env.observation_space.shape[0] # 4
action_size = env.action_space.n # 2
# 初始化经验数组
rpm = MyMemoryBuffer(MEMORY_SIZE)
# build an agent
model = MyDQNnetwork(state_size, action_size)
agent = MyDQNAgent(model, action_size,gamma=GAMMA, lr=LEARNING_RATE, e_greed=0.1, e_greed_decrement=1e-6)
max_episode = 1200
# start training
start_time=time.time()
episode = 0
while episode < max_episode:
# train part
for i in range(50):
total_reward = run_train_episode(agent, env, rpm)
episode += 1
# test part
eval_reward= run_evaluate_episodes(agent, env, render=False)
writer.add_scalar('eval reward',eval_reward,episode)
if episode%50==0:
print('episode:{} e_greed:{} Test reward:{}'.format(episode, agent.e_greed, eval_reward))
print('all used time {:.2}s = {:.2}h'.format(time.time()-start_time,(time.time()-start_time)/3600))
if __name__ == '__main__':
main()
W1227 16:36:14.529779 4613 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1
W1227 16:36:14.534389 4613 device_context.cc:465] device: 0, cuDNN Version: 7.6.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:130: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
if data.dtype == np.object:
episode:50 e_greed:0.09952399999999953 Test reward:8.8
episode:100 e_greed:0.09902599999999903 Test reward:8.6
episode:150 e_greed:0.09853399999999854 Test reward:9.6
episode:200 e_greed:0.09804899999999805 Test reward:9.6
episode:250 e_greed:0.09756399999999757 Test reward:9.8
episode:300 e_greed:0.09706799999999707 Test reward:9.6
episode:350 e_greed:0.09656799999999657 Test reward:9.4
episode:400 e_greed:0.09608299999999609 Test reward:9.6
episode:450 e_greed:0.0955879999999956 Test reward:9.6
episode:500 e_greed:0.0950979999999951 Test reward:9.8
episode:550 e_greed:0.09447199999999448 Test reward:15.8
episode:600 e_greed:0.09283599999999284 Test reward:53.0
episode:650 e_greed:0.08931699999998932 Test reward:52.4
episode:700 e_greed:0.08250499999998251 Test reward:145.8
episode:750 e_greed:0.07330899999997331 Test reward:200.0
episode:800 e_greed:0.06380499999996381 Test reward:200.0
episode:850 e_greed:0.054163999999954165 Test reward:193.2
episode:900 e_greed:0.044443999999944445 Test reward:164.8
episode:950 e_greed:0.03524099999993524 Test reward:139.8
episode:1000 e_greed:0.026618999999926618 Test reward:157.4
episode:1050 e_greed:0.01726199999991726 Test reward:194.4
episode:1100 e_greed:0.01 Test reward:200.0
episode:1150 e_greed:0.01 Test reward:154.2
episode:1200 e_greed:0.01 Test reward:195.0
all used time 1.3e+02s = 0.036h
5.3 结果展示
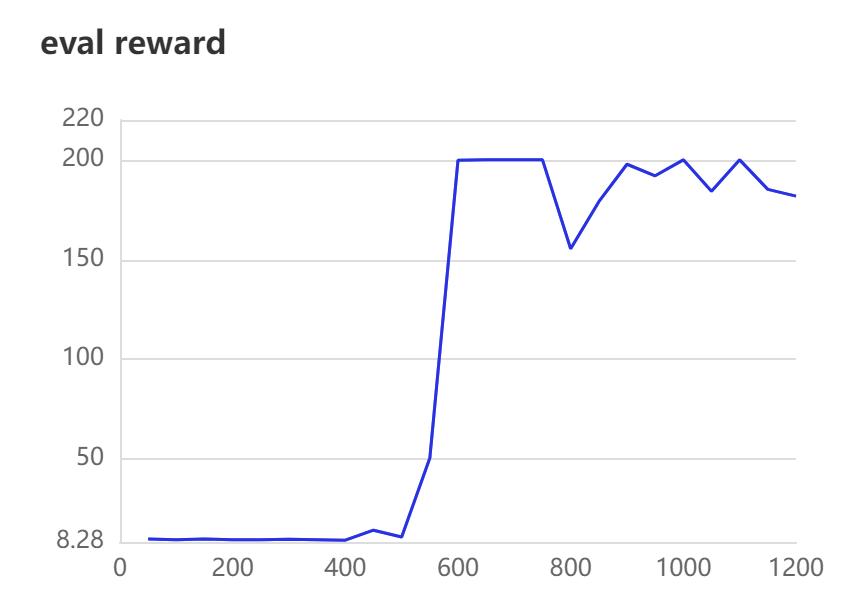
刚开始的奖励值一直不高,是因为经验数组中没有足够的经验。随着迭代次数增加,经验数组中的经验达到一定数量后,奖励值开始跃迁。
6. 项目总结
该项目是对DQN的从0开始的搭建,个人认为比较详细了。因为之前一直看书,只有理论知识,然后现在开始实践,感觉理论到实践还是有些困难的,但是有很多样例可以参考,可以加快学习的步伐。
本人学疏才浅,并且刚刚入门强化学习这块,有很多不足的地方,敬请大佬们批评指正!!

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)