
PaddleNLP+Paddlehub打造你的发泄机器人
使用plato-mini模型和生成式api实现人机交互
聊天机器人
聊天机器人可用于实用的目的,如客户服务或资讯获取。有些聊天机器人会搭载自然语言处理系统,但大多简单的系统只会撷取输入的关键字,再从数据库中找寻最合适的应答句。聊天机器人是虚拟助理(如Google智能助理)的一部分,可以与许多组织的应用程序,网站以及即时消息平台(Facebook Messenger)连接。非助理应用程序包括娱乐目的的聊天室,研究和特定产品促销,社交机器人。
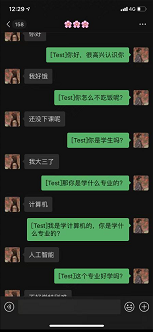
感兴趣的同学可参照此demo在自己微信上实现一个情感识别机器人哦~
demo链接:https://github.com/mawenjie8731/paddlenlp-wechaty-demo
使用PaddleNLP生成式API搭建一个聊天机器人
近年来,人机对话系统受到了学术界和产业界的广泛关注并取得了不错的发展。开放域对话系统旨在建立一个开放域的多轮对话系统,使得机器可以流畅自然地与人进行语言交互,既可以进行日常问候类的闲聊,又可以完成特定功能,以使得开放域对话系统具有实际应用价值。
本实例将重点介绍PaddleNLP内置的生成式API的功能和用法,并使用PaddleNLP内置的plato-mini模型和配套的生成式API实现一个简单的闲聊机器人。
环境要求
-
PaddlePaddle
本项目依赖于 PaddlePaddle 2.0 及以上版本,请参考 安装指南 进行安装
-
PaddleNLP
pip install --upgrade paddlenlp -i https://pypi.org/simple -
sentencepiece
pip install --upgrade sentencepiece -i https://pypi.org/simple -
Python
Python的版本要求 3.6+
AI Studio平台默认安装了Paddle和PaddleNLP,并定期更新版本。 如需手动更新Paddle,可参考飞桨安装说明,安装相应环境下最新版飞桨框架。
使用如下命令确保安装最新版PaddleNLP:
!pip install --upgrade paddlenlp -i https://pypi.org/simple
!pip install --upgrade pip
!pip install --upgrade sentencepiece
生成式API
PaddleNLP针对生成式任务提供了generate()函数,内嵌于PaddleNLP所有的生成式模型。支持Greedy Search、Beam Search和Sampling解码策略,用户只需指定解码策略以及相应的参数即可完成预测解码,得到生成的sequence的token ids以及概率得分。
下面给大家展示一个GPT模型使用生成API的例子:
1. 加载 paddlenlp.transformers.GPTChineseTokenizer用于数据处理
文本数据在输入预训练模型之前,需要经过数据处理转化为Feature。这一过程通常包括分词,token to id,add special token等步骤。
PaddleNLP对于各种预训练模型已经内置了相应的tokenizer,指定想要使用的模型名字即可加载对应的tokenizer。
调用GPTChineseTokenizer的__call__方法即可将我们说的话转为模型可接受的输入。
from paddlenlp.transformers import GPTChineseTokenizer
# 设置想要使用模型的名称
model_name = 'gpt-cpm-small-cn-distill'
tokenizer = GPTChineseTokenizer.from_pretrained(model_name)
import paddle
user_input = "锄禾日当午,汗滴禾下土,谁知盘中餐"
# 将文本转为ids
input_ids = tokenizer(user_input)['input_ids']
print(input_ids)
# 将转换好的id转为tensor
input_ids = paddle.to_tensor(input_ids, dtype='int64').unsqueeze(0)
print(input_ids)
2. 使用PaddleNLP一键加载预训练模型
PaddleNLP提供了GPT,UnifiedTransformer等中文预训练模型,可以通过预训练模型名称完成一键加载。
GPT以Transformer Decoder的编码器为网络基本组件,采用单向注意力机制,适用于长文本生成任务。
PaddleNLP目前提供多种中英文GPT预训练模型,我们这次用的是一个小的中文GPT预训练模型。其他预训练模型请参考模型列表。
from paddlenlp.transformers import GPTLMHeadModel
# 一键加载中文GPT模型
model = GPTLMHeadModel.from_pretrained(model_name)
# 调用生成API升成文本
ids, scores = model.generate(
input_ids=input_ids,
max_length=16,
min_length=1,
decode_strategy='greedy_search')
print(ids)
print(scores)
generated_ids = ids[0].numpy().tolist()
# 使用tokenizer将生成的id转为文本
generated_text = tokenizer.convert_ids_to_string(generated_ids)
print(generated_text)
可以看到生成的效果还不错,生成式API的用法也是非常的简便。
下面我们来展示一下如何使用UnifiedTransformer模型和生成式API完成闲聊对话。
1. 加载 paddlenlp.transformers.UnifiedTransformerTokenizer用于数据处理
UnifiedTransformerTokenizer的调用方式与GPT相同,但数据处理的API略有不同。
调用UnifiedTransformerTokenizer的dialogue_encode方法即可将我们说的话转为模型可接受的输入。
from paddlenlp.transformers import UnifiedTransformerTokenizer
# 设置想要使用模型的名称
model_name = 'plato-mini'
tokenizer = UnifiedTransformerTokenizer.from_pretrained(model_name)
user_input = ['你好啊,你今年多大了']
# 调用dialogue_encode方法生成输入
encoded_input = tokenizer.dialogue_encode(
user_input,
add_start_token_as_response=True,
return_tensors=True,
is_split_into_words=False)
print(encoded_input.keys())
dialogue_encode的详细用法,请参考dialogue_encode。
2. 使用PaddleNLP一键加载预训练模型
与GPT相同,我们可以一键调用UnifiedTransformer预训练模型。
UnifiedTransformer以Transformer的编码器为网络基本组件,采用灵活的注意力机制,十分适合文本生成任务,并在模型输入中加入了标识不同对话技能的special token,使得模型能同时支持闲聊对话、推荐对话和知识对话。
PaddleNLP目前为UnifiedTransformer提供了三个中文预训练模型:
unified_transformer-12L-cn该预训练模型是在大规模中文会话数据集上训练得到的unified_transformer-12L-cn-luge该预训练模型是unified_transformer-12L-cn在千言对话数据集上进行微调得到的。plato-mini该模型使用了十亿级别的中文闲聊对话数据进行预训练。
from paddlenlp.transformers import UnifiedTransformerLMHeadModel
model = UnifiedTransformerLMHeadModel.from_pretrained(model_name)
下一步我们将处理好的输入传入generate函数,并配置解码策略。
这里我们使用的是TopK加sampling的解码策略。即从概率最大的k个结果中按概率进行采样。
ids, scores = model.generate(
input_ids=encoded_input['input_ids'],
token_type_ids=encoded_input['token_type_ids'],
position_ids=encoded_input['position_ids'],
attention_mask=encoded_input['attention_mask'],
max_length=64,
min_length=1,
decode_strategy='sampling',
top_k=5,
num_return_sequences=20)
print(ids)
print(scores)
from utils import select_response
# 简单根据概率选取最佳回复
result = select_response(ids, scores, tokenizer, keep_space=False, num_return_sequences=20)
print(result)
关于生成式API更详细的用法,请参考generate。
下面我们去终端里试试多轮对话吧!
PaddleNLP的example中提供了搭建完整对话系统的代码(人机交互)。我们可以去终端里尝试一下。在终端复制下面代码块即可使用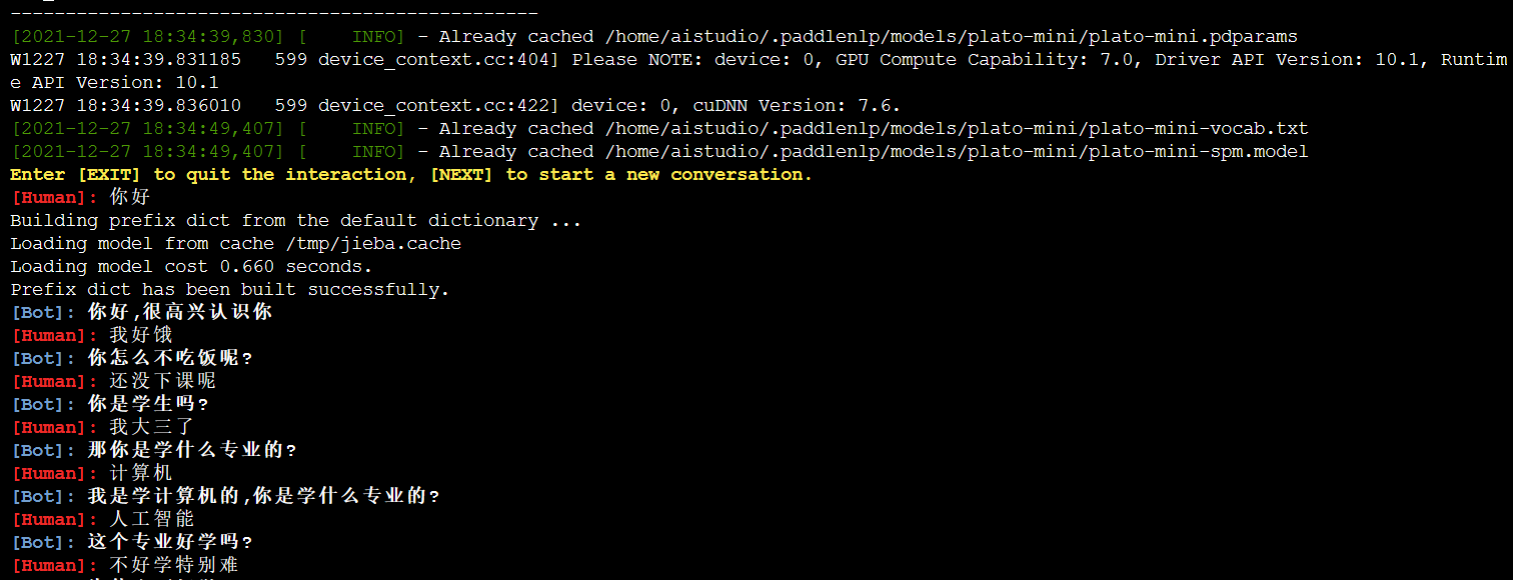
# GPU启动,仅支持单卡
#在后台输入就好
# export CUDA_VISIBLE_DEVICES=0
# python interaction.py \
# --model_name_or_path=plato-mini \
# --min_dec_len=1 \
# --max_dec_len=64 \
# --num_return_sequences=20 \
# --decode_strategy=sampling \
# --top_k=5 \
# --device=gpu
wecheaty bot
下面实现一个可以在自己的微信号上使用的聊天机器人,不过使用者需要承担来自微信官方的风险。首先克隆paddlehub-wechaty-demo
!git clone https://github.com/KPatr1ck/paddlehub-wechaty-demo.git
puppet-wechat
然后去申请一个短期的token,之后配置环境变量即可使用,短期token只有7天,申请链接https://wechaty.js.org/docs/puppet-services/
申请之后复制到下面的export WECHATY_PUPPET_SERVICE_TOKEN即可
%cd paddlehub-wechaty-demo
在终端复制代码块然后登陆微信即可使用
# export WECHATY_PUPPET="wechaty-puppet-wechat"
# export WECHATY_PUPPET_SERVICE_TOKEN="your_token"
# export WECHATY_PUPPET_SERVICE_ENDPOINT="your_SERVICE_ENDPOINT"
# python examples/paddlehub-chatbot.py
七、总结与升华
- 本项目是本人在NLP上的第一次尝试,希望大家多多鼓励
- 后续会尝试申请长期token,敬请期待
个人简介
本人来自江苏科技大学本科三年级,刚刚接触深度学习不久希望大家多多关注
感兴趣的方向:目标检测,强化学习,自然语言处理、
个人链接:
马骏骁
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/824948

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)