
基于PP-YOLO Tiny和DSST算法的多目标跟踪
Tracking-by-Detection:PP-YOLO-tiny + DSST (Single) => Multi-Cell-Tracking
1 项目背景
视频序列中的目标跟踪是计算机视觉领域的研究热点之一,该技术在安防、交通、军事等领域有重要的应用价值。

本项目是基于 PaddlePaddle 计算机视觉开发套件,结合深度学习与传统视觉跟踪算法实现多目标跟踪任务。
本项目作为从目标检测到(多)目标跟踪学习的基础衔接,在Tracking-by-Detection的思路下设计跟踪方法,熟悉相关步骤和难点。
常见的目标跟踪方法大体分为生成模型和判别模型两大类,本项目采用的是判别模型方法:
- 生成模型方法:通过学习后的目标模型去搜索图像区域和最小化重构误差,例如 Kalman Filter;
- 判别模型方法:将跟踪问题看成一个二分类问题,通过判定目标和背景的差别进行区别,例如 DSST。
2 主要工作
本项目以手工标注的 HeLa 细胞数据集(http://celltrackingchallenge.net/2d-datasets)为例,使用 PaddleX 实现 PP-YOLO Tiny 目标检测器的训练,然后利用 DLib 中内置的 DSST 单目标跟踪算法通过检测框和观测框的交并比级联匹配实现多目标跟踪。

- 说明:项目的产出已在版本中保存(
work/),所以已经注释代码无需运行,检测器的训练部分也可以跳过,但需要解压数据集。
3 目标检测
在 Tracking-by-Detection 的算法思路下,跟踪目标的确定是基于检测模型的。所以如何生成跟踪目标呢?考虑在图像中还没有跟踪目标的时候(第 1 帧),使用检测器获得预测框,将它们作为首批拟跟踪目标,通过设置多个跟踪器的分别观测每个预测框即可;当之后图像帧到来时,单目标跟踪器依据其本身的区域匹配算法(例如 DSST 算法的 {尺度+位置} 滤波器)在该帧中搜寻最佳匹配区域,然后它自动的把这个新区域作为观测目标。通过以上的思路,我们就解决了跟踪目标的如何产生的问题,即用检测器的预测框去产生。
3.1 依赖准备
- 至尊版环境下持久化安装DLIB。
# !mkdir /home/aistudio/external-libraries
# !pip install dlib -t /home/aistudio/external-libraries
原计划是将检测器导出为高性能部署接口,但 paddlex.deploy.Predictor 的PIP源发布版还存在些许问题(开发版已修复,但在AI Studio上进行源码安装还是存在问题),所以后面将直接使用训练好的模型直接进行推理,或是利用 Paddle Inference 推理。
# !git clone https://gitee.com/PaddlePaddle/PaddleX.git
# %cd PaddleX
# !git checkout develop
# !python setup.py install
# %cd ../
!pip install paddlex
import sys
sys.path.append('/home/aistudio/external-libraries')
import paddle
import paddlex as pdx
from paddlex import transforms as T
import shutil
import glob
import os
import dlib
import numpy as np
import pandas as pd
import cv2
import imghdr
from PIL import Image
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
3.2 数据划分
- 解压文件至同级目录下。
!unzip -oq data/data107056/DIC-C2DH-HeLa.zip -d data/data107056
- 20%验证(16),80%训练(68)
!paddlex --split_dataset --format VOC\
--dataset_dir data/data107056/DIC-C2DH-HeLa\
--val_value 0.2\
--test_value 0
3.3 数据增强与读取器
定义训练集和验证集的数据预处理方法;
二者都需要 Resize 到 320x320 尺寸,然后使用IMAGENET的归一化系数(后续使用IMAGNET的预训练权重)。
train_transforms = T.Compose([
T.MixupImage(alpha=1.5, beta=1.5, mixup_epoch=int(550 * 25. / 27)),
T.RandomDistort(
brightness_range=0.5, brightness_prob=0.5,
contrast_range=0.5, contrast_prob=0.5,
saturation_range=0.5, saturation_prob=0.5,
hue_range=18.0, hue_prob=0.5),
T.RandomExpand(prob=0.5,
im_padding_value=[float(int(x * 255)) for x in [0.485, 0.456, 0.406]]),
T.RandomCrop(),
T.Resize(target_size=320, interp='RANDOM'),
T.RandomHorizontalFlip(prob=0.5),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
eval_transforms = T.Compose([
T.Resize(target_size=320, interp='AREA'),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
将步骤 [3.2] 生成的 *.txt 配置于数据读取器上。
train_dataset = pdx.datasets.VOCDetection(
data_dir='data/data107056/DIC-C2DH-HeLa',
file_list='data/data107056/DIC-C2DH-HeLa/train_list.txt',
label_list='data/data107056/DIC-C2DH-HeLa/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.VOCDetection(
data_dir='data/data107056/DIC-C2DH-HeLa',
file_list='data/data107056/DIC-C2DH-HeLa/val_list.txt',
label_list='data/data107056/DIC-C2DH-HeLa/labels.txt',
transforms=eval_transforms)
3.4 模型配置与训练
- 在训练集上对 anchors 进行聚类。
anchors = pdx.tools.YOLOAnchorCluster(
num_anchors=9,
dataset=train_dataset,
image_size=320)()
- 装载适应性的聚类数据,构建 PP-TOLO Tiny。
model = pdx.det.PPYOLOTiny(
num_classes=len(train_dataset.labels),
backbone='MobileNetV3',
anchors=anchors)
- 自定义优化器(Momentum,L2(5e-4)),基于经验值的学习率衰减策略(Warmup + Piecewise-decay)。
learning_rate = 0.001
warmup_steps = 66
warmup_start_lr = 0.0
train_batch_size = 8
step_each_epoch = train_dataset.num_samples // train_batch_size
lr_decay_epochs = [130, 540]
boundaries = [b * step_each_epoch for b in lr_decay_epochs]
values = [learning_rate * (0.1**i) for i in range(len(lr_decay_epochs) + 1)]
lr = paddle.optimizer.lr.PiecewiseDecay(
boundaries=boundaries,
values=values)
lr = paddle.optimizer.lr.LinearWarmup(
learning_rate=lr,
warmup_steps=warmup_steps,
start_lr=warmup_start_lr,
end_lr=learning_rate)
optimizer = paddle.optimizer.Momentum(
learning_rate=lr,
momentum=0.9,
weight_decay=paddle.regularizer.L2Decay(0.0005),
parameters=model.net.parameters())
- 开始训练,使用 IMAGENET 预训练权重和自定义 optimizer,每 30 个 EPOCH 评估保存一次模型。
model.train(
train_dataset=train_dataset,
eval_dataset=eval_dataset,
num_epochs=550,
train_batch_size=train_batch_size,
optimizer=optimizer,
save_interval_epochs=30,
log_interval_steps=step_each_epoch * 5,
save_dir=r'output/PPYOLOTiny',
pretrain_weights=r'IMAGENET',
use_vdl=True)
3.5 模型评估
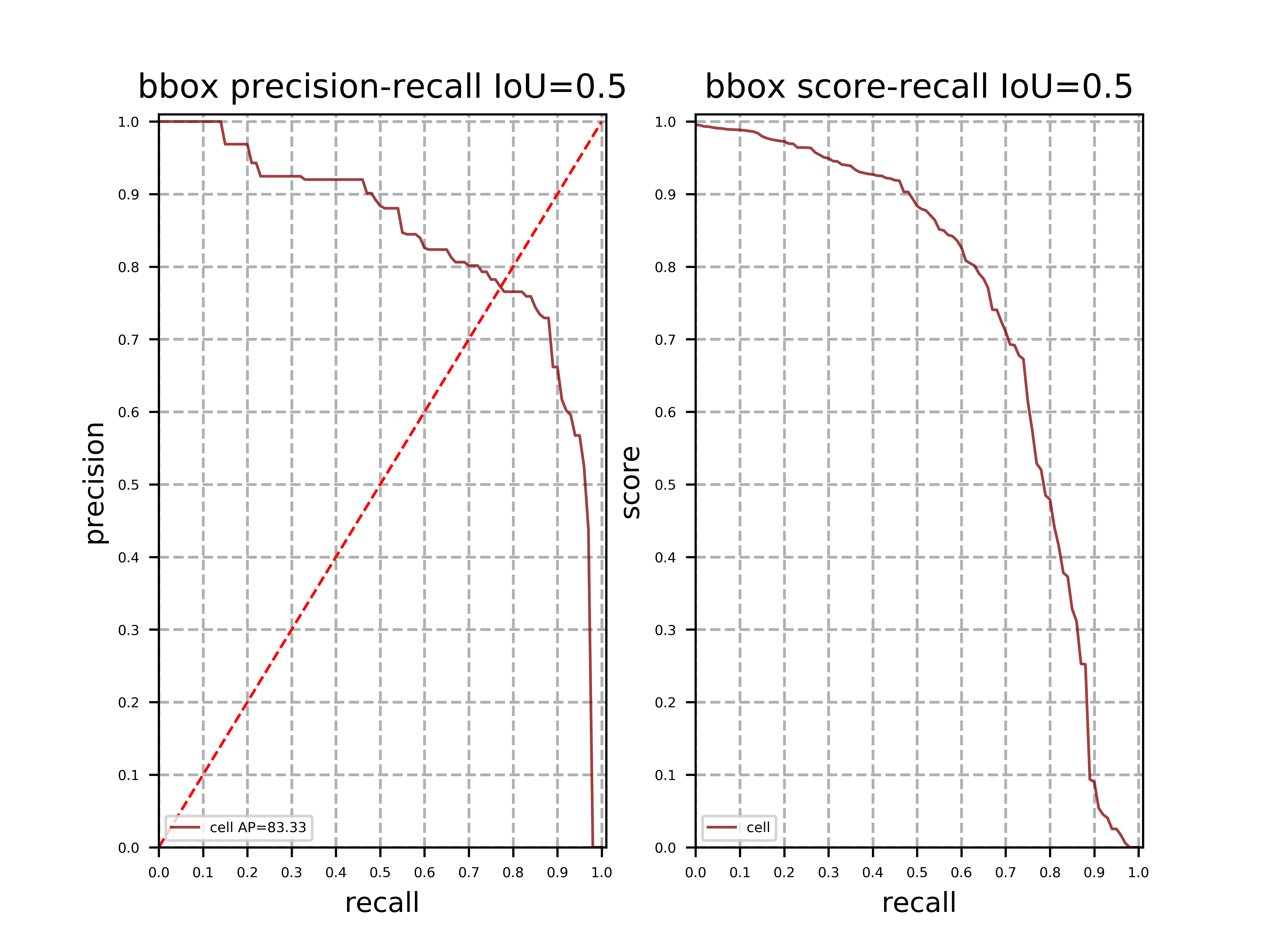
- 绘制 PR 曲线。
pdx.det.draw_pr_curve(
eval_details_file='output/PPYOLOTiny/best_model/eval_details.json',
save_dir='work/visual')
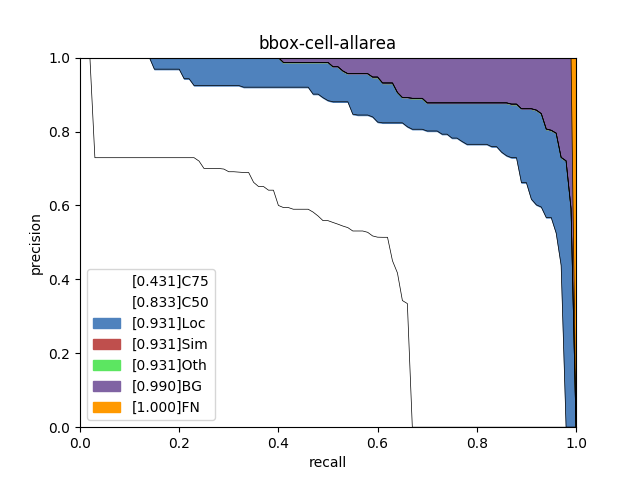
- 绘制误差分析图表。
_, evaluate_details = model.evaluate(eval_dataset, return_details=True)
gt, bbox = evaluate_details['gt'], evaluate_details['bbox']
pdx.det.coco_error_analysis(
gt=gt,
pred_bbox=bbox,
save_dir='work/visual')
-
观察到当前最优模型为 EPOCH-550 (最后一次保存的模型),mAP = 79.77。
-
将该模型保存至
work/best_model,至此,完成了目标检测器的步骤。
!cp -r output/PPYOLOTiny/best_model work/
4 目标跟踪
4.1 图片合成视频
这一步是先定义一个 images2mp4 函数:在我们的原始数据集中,是 FPS 为 10 的视频序列图像,需要将目标文件夹下的 *.jpg 文件合并成一个 FPS 为 10 的 mp4 视频文件,模拟部署视频流的预测。
def images2mp4(images_dir, output_path):
"""
将目标文件夹下的所有.jpg图片合成.mp4格式视频文件。
:param images_dir: 目标文件夹的路径
:param output_path: 合成视频保存的位置
:return:
"""
# 创建一个512x512分辨率,FPS为10的mp4视频流文件
video = cv2.VideoWriter(
filename=output_path,
fourcc=cv2.VideoWriter_fourcc(*'mp4v'),
fps=10,
frameSize=(512, 512))
# 读取每张目标图片文件,将其写入视频流中
for img_path in sorted(glob.glob(os.path.join(images_dir, '*.jpg'))):
video.write(cv2.imread(img_path))
video.release()
!mkdir work/viedio
# DIC-C2DH-HeLa/Test/*.jpg => work/viedio/test.mp4
images2mp4(
images_dir='data/data107056/DIC-C2DH-HeLa/Test',
output_path='work/viedio/test.mp4')
# 使用 ffmpeg 将 .mp4 转换为 .gif 文件
!ffmpeg -i work/viedio/test.mp4 -s 320*320 work/viedio/test.gif -y
下方为测试图像合成之后的视频序列(FPS=10):
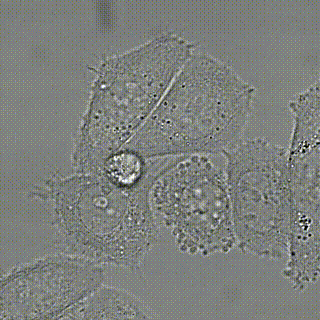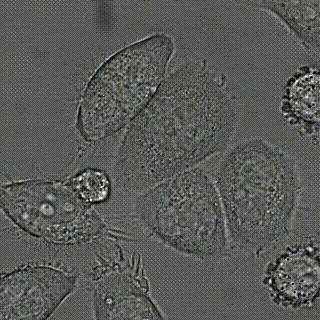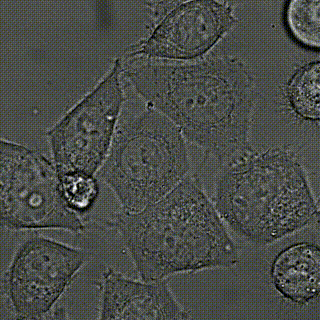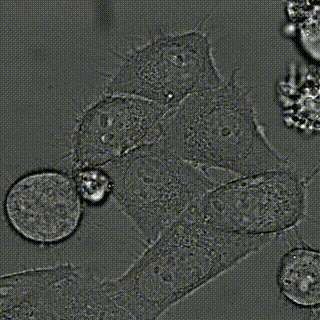
之后定义好跟踪器,就可以将该文件作为输入进行测试。
4.2 单目标跟踪器
目标跟踪是使用单个跟踪器去跟踪固定目标,我们通过设计方案把这些单目标跟踪器进行统一的管理,以实现多目标跟踪。所以,先构建一个单目标跟踪器,封装好它所必须的步骤,之后在多目标跟踪器里只需要设计好算法,调用它们接口即可。
下面是设计好的 DSST 单目标跟踪器 SingleTracker,我们可以使用它来跟踪单个目标。
DSST(Accurate Scale Estimation for Robust Visual Tracking)将跟踪分为两个部分,定义了两个相关滤波器,一个滤波器(Translation Filter)用于估计位置,另一个滤波器(Scale Filter)用于估计尺度。在 DLib 中已经内置该方法。
下面是单目标跟踪的简要流程,边框我们统一使用(x_min, y_min, x_max, y_max):
(1)创建跟踪器,传入首帧以确定目标位置:创建一个 SingleTracker 类,将观测区域传入 begin() 方法,开始自动跟踪;
(2)读取后续帧:将 image 传入 update_bbox() 返回得到分数,若分数小于某阈值,我们认为目标在图像中丢失,删除该跟踪器即可。
简而言之,确定跟踪目标的框后(手动),每次输入图像它都会自动更新观测位置,更新后可调用 SingleTracker.bbox 绘制边框。
class SingleTracker(dlib.correlation_tracker):
def __init__(self,
tracker_id,
category):
"""
初始化单目标跟踪器。
:param tracker_id: 跟踪器被分配的ID
:param category: 跟踪目标的类别
"""
super().__init__()
self.id = int(tracker_id)
self.category = str(category)
self.bbox = None
self.bbox_color = (
100 + np.random.randint(0, 155),
100 + np.random.randint(0, 155),
100 + np.random.randint(0, 155))
def begin(self, image, bbox: list or tuple):
"""
对输入图像image中位置bbox进行观测。
:param image: 输入图像
:param bbox: x_min, y_min, x_max, y_max
:return: None
"""
self.bbox = bbox
self.start_track(image, dlib.rectangle(*bbox))
def update_bbox(self, image):
"""
根据输入图像对当前跟踪器更新观测区域。
:param image: 输入图像
:return: 跟踪器对当前图像的跟踪质量分数
"""
score = self.update(image)
curr_pos = self.get_position()
self.bbox = (int(curr_pos.left()), int(curr_pos.top()),
int(curr_pos.right()), int(curr_pos.bottom()))
return score
4.3 多目标跟踪器
如何将单目标跟踪器应用于多目标跟踪任务呢?一个简单的思路就是使用多个跟踪器去跟踪不同的目标,但这要处理好 跟踪目标的生成、新旧匹配和已有目标消失 三个主要问题。
- 检测器步骤(3)中提到,目标生成是通过 PP-YOLO Tiny 的预测框;
- 目标跟踪步骤(4.2)中描述了,目标消失可以通过跟踪器返回的跟踪质量分数低于某个阈值而判断;
- 最后,新旧目标的匹配,我们采用交并比级联匹配的方法(虽然物体重叠的时候效果会差,但细胞的跟踪可能这种情况较少):假定已有的跟踪目标 N ( 0 < = N ) N(0<=N) N(0<=N) 个,检测器得到的目标 M ( 0 < = M ) M(0<=M) M(0<=M) 个,将它们两两级联得到一个交并比矩阵 c o s t _ m a t r i x ( N × M ) cost\_matrix(N×M) cost_matrix(N×M),使用分配算法将 N N N 和 M M M 两两配对,最后剩下未能配对的预测框的作为新目标跟踪区域。
关于下面的 MultiTracker 类的设计,代码逻辑还是比较清晰的,入口在最下方的 update_trackers(image):
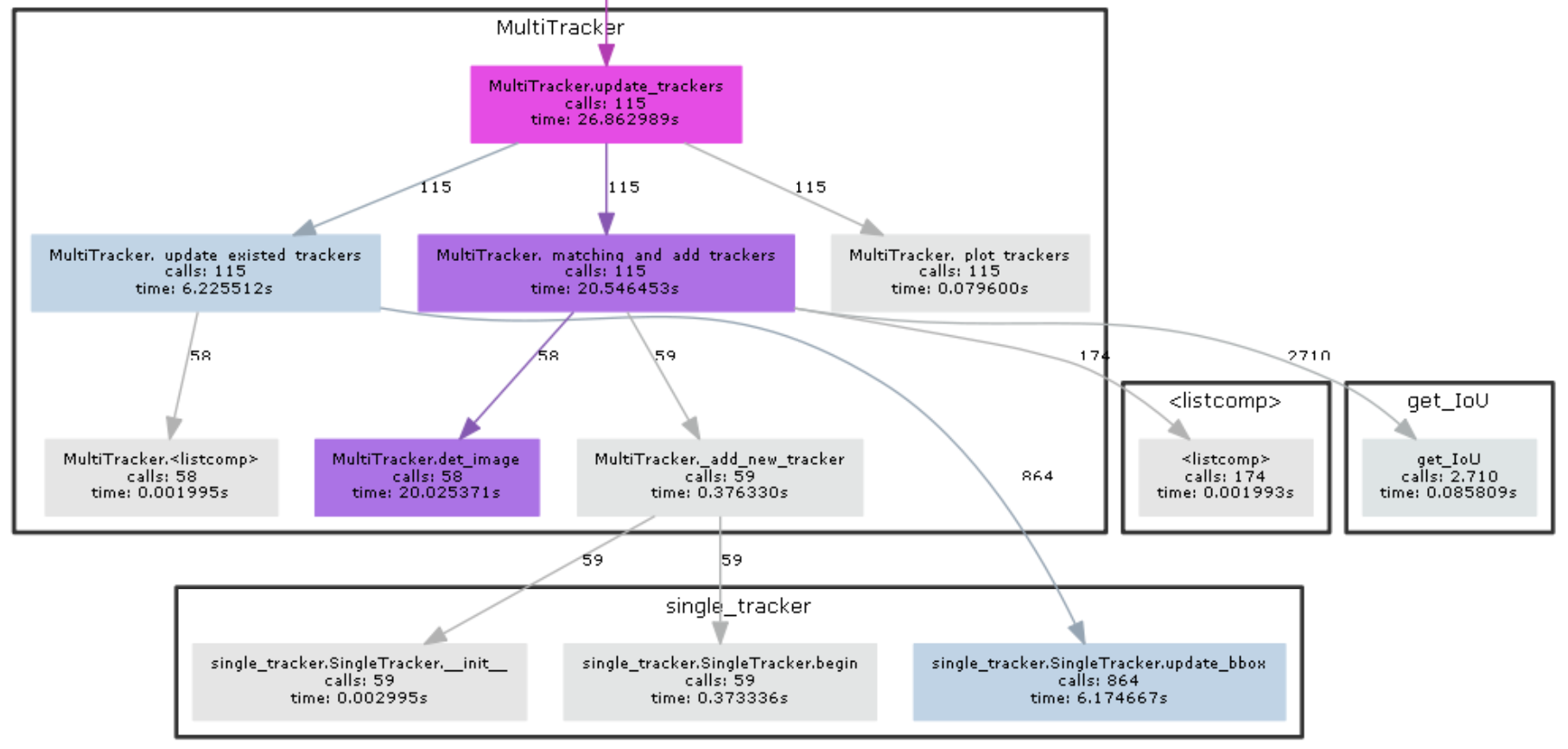
# 导入线性分配函数,我们级联匹配里面需要用到:linear_sum_assignment(cost_matrix, maximize=False)
from scipy.optimize import linear_sum_assignment
class MultiTracker:
def __init__(self,
model_path,
det_threshold=0.35,
stride=2):
"""
:param model_path: 模型的路径
:param det_threshold: 预测过滤的阈值
:param stride: 生成新目标的间隔
"""
self.det_threshold = det_threshold
self.stride = stride
try:
from paddlex import load_model
self.model = load_model(model_path)
except Exception as e:
raise e
self.frame_num = 0 # 帧数统计
self.tracker_num = 0 # 跟踪器ID统计
self.trackers = [] # 跟踪器实例列表
self.tracking_threshold = 6.5 # 跟踪器实例的跟踪分数阈值
def _update_existed_trackers(self, image, is_update_frame=False):
"""
对于每一个已经存在的DSST算法跟踪器,都将其跟踪区域转移至当前图像image的位置上,
若跟踪分数低于self.tracking_threshold,则默认该目标已丢失,删除该目标。
"""
del_idx = []
for i in range(len(self.trackers)):
if self.trackers[i].update_bbox(image) < self.tracking_threshold:
del_idx.append(i)
if is_update_frame:
self.trackers = [self.trackers[i] for i in range(len(self.trackers)) if i not in del_idx]
def det_image(self, img):
"""
模型预测函数,返回img上预测得到的结果 ([xmin, ymin, xmax, ymax], category)
"""
result = self.model.predict(img.astype('float32'))
selected_result = []
for item in result:
if item['score'] < self.det_threshold:
continue
x_min, y_min, w, h = np.int64(item['bbox'])
selected_result.append((
[x_min, y_min, x_min + w, y_min + h],
item['category']))
return selected_result
@staticmethod
def get_IoU(_bbox1, _bbox2):
"""
输入边框的对角线端点(x_min, y_min, x_max, y_max),计算两个矩形的交并比IoU。
"""
x1min, y1min, x1max, y1max = _bbox1
x2min, y2min, x2max, y2max = _bbox2
s1 = (y1max - y1min + 1.) * (x1max - x1min + 1.)
s2 = (y2max - y2min + 1.) * (x2max - x2min + 1.)
x_min, y_min = max(x1min, x2min), max(y1min, y2min)
x_max, y_max = min(x1max, x2max), min(y1max, y2max)
inter_w, inter_h = max(y_max - y_min + 1., 0.), max(x_max - x_min + 1., 0.)
intersection = inter_h * inter_w
union = s1 + s2 - intersection
return intersection / union
def _add_new_tracker(self, image, bbox: list or list, category: str):
"""
生成一个单目标跟踪器,观测图片image上的bbox边框区域。
"""
tracker = SingleTracker(tracker_id=self.tracker_num, category=category)
tracker.begin(image=image, bbox=bbox)
self.trackers.append(tracker)
self.tracker_num += 1
def _matching_and_add_trackers(self, image, is_update_frame):
"""
将预测框和跟踪框根据交并比距离级联匹配,未匹配上的视为新目标,对其创建跟踪器。
"""
if not is_update_frame:
return
# 获取模型的预测结果,生成预测框和观测框列表
predict_result = self.det_image(image)
predict_bboxes = [bbox for bbox, _ in predict_result]
tracker_bboxes = [tracker.bbox for tracker in self.trackers]
# 生成交并比距离矩阵
cost_matrix = np.zeros(shape=(len(tracker_bboxes), len(predict_bboxes)), dtype='float32')
for i in range(len(tracker_bboxes)):
for j in range(len(predict_bboxes)):
cost_matrix[i, j] = 1. - self.get_IoU(tracker_bboxes[i], predict_bboxes[j])
# 获取实现级联后距离和最小化的下标对 (row_i, col_i)
row, col = linear_sum_assignment(cost_matrix)
# 将没有被匹配的预测框当作新目标,生成跟踪器观测该框
unused_idx = [i for i in range(len(predict_result)) if i not in col]
for idx in unused_idx:
bbox, category = predict_result[idx]
self._add_new_tracker(image, bbox, category)
def _plot_trackers(self, image):
"""
将regions_info中的边框等信息在图像image上绘制出来并返回。
"""
thickness = round(0.002 * (image.shape[0] + image.shape[1]) / 2) + 1 # 线条粗细程度
for tracker in self.trackers:
# 获取边框的两个对角顶点
pt1, pt2 = (tracker.bbox[0], tracker.bbox[1]), (tracker.bbox[2], tracker.bbox[3])
# 绘制目标边框
cv2.rectangle(image,
pt1=pt1, pt2=pt2,
color=tracker.bbox_color,
thickness=thickness,
lineType=cv2.LINE_AA)
# 获取文字边框的两个对角顶点
w, h = cv2.getTextSize(text=tracker.category,
fontFace=0,
fontScale=thickness / 3,
thickness=max(thickness - 1, 1))[0]
font_pt1, font_pt2 = pt1, (pt1[0] + w, pt1[1] + h)
# 填充文字框区域的背景色
cv2.rectangle(image,
pt1=font_pt1, pt2=font_pt2,
color=tracker.bbox_color,
thickness=-1,
lineType=cv2.LINE_AA)
# 将字符输出在文字框所在的区域
cv2.putText(image, '{}({})'.format(tracker.category, tracker.id),
org=(font_pt1[0], font_pt2[1]),
fontFace=0,
fontScale=thickness / 3,
color=(225, 255, 255),
thickness=max(thickness - 1, 1),
lineType=cv2.LINE_AA)
return image
def update_trackers(self, image):
self.frame_num = (self.frame_num + 1) % 864000 # 防止溢出
is_update_frame = self.frame_num % self.stride == 1 # 间隔式增减跟踪器的标识
self._update_existed_trackers(image, is_update_frame) # 更新跟踪器的跟踪区域,删除某些目标
self._matching_and_add_trackers(image, is_update_frame) # 检测器预测框和跟踪器观测框的级联匹配,增加新目标
plotted_image = self._plot_trackers(image) # 获取已有跟踪器的信息,在原图上绘制。
return plotted_image
4.4 预测体验
这里定义一个函数 predict_stream() 用于读取视频流和模型位置,将对应帧的预测结果(.jpg)保存到 save_dir 中,后续我们使用步骤(4.1)的图片合成函数 images2mp4() 还原成视频。
def predict_stream(stream_path, model_path, save_dir):
"""
在一个视频流中对每帧图片进行预测,将每帧图片绘制边框后的结果保存在文件夹下。
:param stream_path: 视频流文件路径
:param model_path: 模型路径
:param save_dir: 图片保存的文件夹地址
:return:
"""
if not os.path.exists(save_dir):
os.mkdir(save_dir)
# 打开目标视频流
video = cv2.VideoCapture(stream_path)
# 定义多目标跟踪器
multi_tracker = MultiTracker(
model_path=model_path,
det_threshold=0.35,
stride=2)
while True: # 读取视频流的每帧图像进行预测
_, frame = video.read()
if frame is None:
video.release()
break
# 更新多目标跟踪器中各个跟踪器的跟踪区域,返回绘制后的图像
plotted_frame = multi_tracker.update_trackers(frame)
# 将绘制好边框的图像保存在目标文件夹下,以帧号命名
save_path = os.path.join(save_dir, '%03d.jpg' % (multi_tracker.frame_num - 1))
cv2.imwrite(save_path, plotted_frame)
# 视频进行推理,生成添加了跟踪标注的图片
predict_stream(
stream_path='work/viedio/test.mp4',
model_path='work/best_model',
save_dir='work/tracking_result')
# 将推理结果图片合成为视频
images2mp4(
images_dir='work/tracking_result',
output_path='work/viedio/test_track_result.mp4')
# 将刚刚合成的 `work/viedio/test_track_result.mp4` 转换成 gif
hon
# 视频进行推理,生成添加了跟踪标注的图片
predict_stream(
stream_path='work/viedio/test.mp4',
model_path='work/best_model',
save_dir='work/tracking_result')
# 将推理结果图片合成为视频
images2mp4(
images_dir='work/tracking_result',
output_path='work/viedio/test_track_result.mp4')
# 将刚刚合成的 `work/viedio/test_track_result.mp4` 转换成 gif
!ffmpeg -i work/viedio/test_track_result.mp4 -s 320*320 work/viedio/test_track_result.gif -y
-
可以看到,部分跟踪效果较差,这是因为细胞存在分裂增殖行为,相对于行人等目标,它们的形状也会改变,增加了预测难度。
5 总结分析
本项目在 Tracking-By-Detection 的思路指导下,使用计算机视觉开发套件 PaddleX 训练 PP-YOLO Tiny 目标检测模型对细胞进行检测,然后利用 DLib 内置 DSST 单目标跟踪算法,构建了一种基于预测框和观测框之间交并比距离的级联匹配方法,实现了一个多目标跟踪类。
本项目可优化方向:
(1)检测器的检测性能(检测器检测的速度会影响系统速度,精度影响跟踪器对初始目标的跟踪质量);
(2)单目标跟踪器的跟踪性能(DSST相关滤波器可替换为 Kalman Filter,这样项目就变成了经典的 SORT 算法,指出了项目最开始描述的“本项目是为之后学习做铺垫”);
(3)预测框和跟踪框的之间的匹配算法(本文使用交并比距离作为代价,DEEPSORT 使用余弦距离和马氏距离);
(4)预测框的生成、预测框和跟踪框之间的匹配阈值等参数的调整(特定场景下特定的参数可以涨点,但若部署意义不大)。
- 有相关问题或侵权行为可以联系笔者处理。
- 我的 AI Studio 主页

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)