
LiTv2:用于高效建模高低频信息的Vision Transformer
Vision Transformer(ViTs)引发了计算机视觉领域最近的重大突破。他们的高效设计主要是由计算复杂性的间接度量来指导的,例如,FLOPs,但是它与吞吐量等直接度量有明显的差距。因此,我们建议将目标平台上的直接速度评估作为高效vit的设计原则。特别地,我们引入了LITv2,一个简单而有效的ViT,它在不同模型规模的光谱中以更快的速度优于现有的最先进的方法。LITv2的核心是一种新颖的
摘要
Vision Transformer(ViTs)引发了计算机视觉领域最近的重大突破。他们的高效设计主要是由计算复杂性的间接度量来指导的,例如,FLOPs,但是它与吞吐量等直接度量有明显的差距。因此,我们建议将目标平台上的直接速度评估作为高效vit的设计原则。特别地,我们引入了LITv2,一个简单而有效的ViT,它在不同模型规模的光谱中以更快的速度优于现有的最先进的方法。LITv2的核心是一种新颖的自我注意机制,我们称之为HiLo。HiLo的灵感来自于图像中的高频捕获局部精细细节,低频关注全局结构,而多头自我注意层忽略了不同频率的特征。因此,我们建议通过将头部分成两组来分解注意层中的高频/低频模式,其中一组通过在每个局部窗口内的自我注意来编码高频,另一组通过注意来建模每个窗口中平均汇聚的低频键与输入特征图中每个查询位置之间的全局关系。受益于这两组的高效设计,我们通过对gpu上的FLOPs、速度和内存消耗进行全面的基准测试,表明HiLo优于现有的注意力机制。在HiLo的支持下,LITv2作为主流视觉任务的主干,包括图像分类、密集检测和分割。
1. LiTv2
1.1 LiTv1回顾
LITv1是一个简单的ViT baseline,它在早期阶段删除所有多头自注意力层(MSA),而在后期阶段应用标准MSA。得益于这种设计,LITv1比ImageNet分类的许多现有工作都要快,因为早期的MSA不需要计算成本,而后期的MSA只需要处理下采样的低分辨率特征图。然而仍存在如下问题:
- 对于高分辨率图像,尤其是密集预测任务,标准MSA仍然存在巨大的计算开销
- 所使用的固定相对位置编码对于不同分辨率的图像输入,会使用插值,这会动态降低速度
1.2 LiTv2总览
本文针对问题1提出了一种新的注意力机制,可以同时对高频信息和低频信息进行建模;而针对问题2基于位置信息可以从CNN的零填充中隐式学习的研究提出了使用3×3深度卷积层来隐式学习的位置信息,LiTv2的整体架构如下图所示:
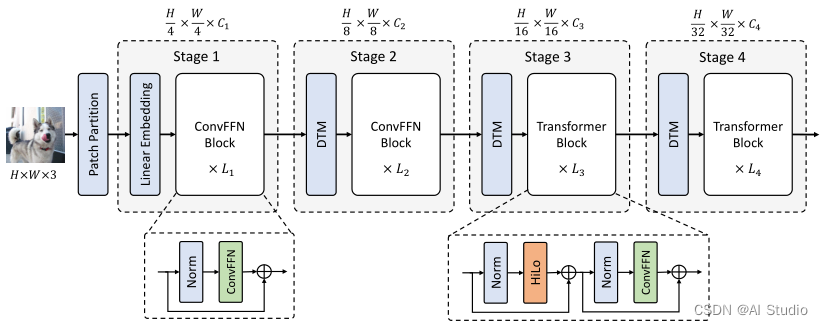
1.3 HiLo
自然图像包含丰富的频率,其中高频捕捉对象的局部细节(如线条和形状),低频编码全局结构(如纹理和颜色)。然而,在一个典型的MSA层中,全局自注意并没有考虑不同底层频率的特征。为此,作者提出在注意力层分别处理特征图中的高频/低频。作者将新的注意力机制命名为HiLo。如图1所示,HiLo包含高频注意力(Hi-Fi)和低频注意力(Lo-Fi),用于在特征图中模拟不同频率上的关系。
- High-frequency attention (Hi-Fi)
直观地说,由于高频对对象的局部细节进行编码,因此在特征图上应用全局注意力可能是多余的,并且计算代价高昂。因此,作者设计Hi-Fi,以捕获具有局部窗口自注意的细粒度高频(例如,2×2窗口),从而节省大量计算复杂性。此外,作者在Hi-Fi中使用了简单的非重叠窗口分区,与耗时的操作(如窗口移位或多尺度窗口分区)相比,它对硬件更加友好。 - Low-frequency attention (Lo-Fi)
最近的研究表明,MSA中的全局注意力有助于捕捉低频信息。然而,将MSA直接应用于高分辨率特征图需要巨大的计算成本。由于平均池化是一种低通滤波器,Lo-Fi首先对每个窗口应用平均池化,以获得输入X中的低频信号。接下来,将平均池化后的特征映射投影到键和值,其中s是窗口大小。Lo-Fi中的查询Q仍然来自原始特征图X。然后,作者应用标准注意力来捕获特征图中丰富的低频信息。由于K和V的空间减少,Lo-Fi同时降低了复杂性。 - Head splitting
头分配的一个简单解决方案是将Hi-Fi和Lo-Fi的头分配为与标准MSA层相同的数目。然而,加倍的头会导致更多的计算成本。为了获得更好的效率,HiLo将与MSA中相同数量的头部分为两组,分割比率为 α\alphaα ,其中 (1−α)Nh(1-\alpha)N_h(1−α)Nh 头用于Hi-Fi,其他的 αNh\alpha N_hαNh 个头用于Lo-Fi。这样,由于每个注意力的复杂性都低于标准MSA,整个HiLo框架保证了低复杂性,并确保了GPU上的高吞吐量。此外,头分配的另一个好处是,可学习参数 W0W_0W0 可以分解为两个较小的矩阵,这有助于减少模型参数。最后,HiLo的输出是每个注意力输出的concat结果:
HiLo(X)=[Hi-Fi(X),Lo-Fi(X)]\text{HiLo}(X) = [\text{Hi-Fi}(X), \text{Lo-Fi}(X)]HiLo(X)=[Hi-Fi(X),Lo-Fi(X)]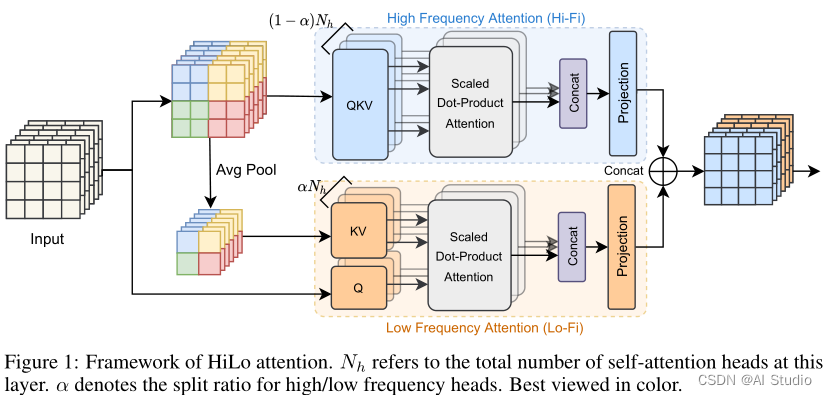
2. 代码复现
2.1 下载并导入所需的库
!pip install paddlex
%matplotlib inline
import paddle
import paddle.fluid as fluid
import numpy as np
import matplotlib.pyplot as plt
from paddle.vision.datasets import Cifar10
from paddle.vision.transforms import Transpose
from paddle.io import Dataset, DataLoader
from paddle import nn
import paddle.nn.functional as F
import paddle.vision.transforms as transforms
import os
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import paddlex
from paddle.vision.ops import DeformConv2D
import math
2.2 创建数据集
train_tfm = transforms.Compose([
transforms.Resize((230, 230)),
transforms.ColorJitter(brightness=0.4,contrast=0.4, saturation=0.4),
transforms.RandomResizedCrop(224, scale=(0.4, 1.0)),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomRotation(20),
paddlex.transforms.MixupImage(),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
test_tfm = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
paddle.vision.set_image_backend('cv2')
# 使用Cifar10数据集
train_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='train', transform = train_tfm, )
val_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='test',transform = test_tfm)
print("train_dataset: %d" % len(train_dataset))
print("val_dataset: %d" % len(val_dataset))
train_dataset: 50000
val_dataset: 10000
batch_size=128
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=4)
2.3 模型的创建
2.3.1 标签平滑
class LabelSmoothingCrossEntropy(nn.Layer):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing
def forward(self, pred, target):
confidence = 1. - self.smoothing
log_probs = F.log_softmax(pred, axis=-1)
idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1)
nll_loss = paddle.gather_nd(-log_probs, index=idx)
smooth_loss = paddle.mean(-log_probs, axis=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss
return loss.mean()
2.3.2 DropPath
def drop_path(x, drop_prob=0.0, training=False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ...
"""
if drop_prob == 0.0 or not training:
return x
keep_prob = paddle.to_tensor(1 - drop_prob)
shape = (paddle.shape(x)[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)
random_tensor = paddle.floor(random_tensor) # binarize
output = x.divide(keep_prob) * random_tensor
return output
class DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
2.3.3 Patch Embedding
def to_2tuple(x):
return (x, x)
class PatchEmbed(nn.Layer):
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2D(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose([0, 2, 1]) # B Ph*Pw C
# _, _, H, W = x.shape
if self.norm is not None:
x = self.norm(x)
return x
model = PatchEmbed(norm_layer=nn.LayerNorm)
paddle.summary(model, (1, 3, 224, 224))
W0724 10:52:55.032507 347 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0724 10:52:55.039357 347 gpu_resources.cc:91] device: 0, cuDNN Version: 7.6.
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-1 [[1, 3, 224, 224]] [1, 96, 56, 56] 4,704
LayerNorm-1 [[1, 3136, 96]] [1, 3136, 96] 192
===========================================================================
Total params: 4,896
Trainable params: 4,896
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 4.59
Params size (MB): 0.02
Estimated Total Size (MB): 5.19
---------------------------------------------------------------------------
{'total_params': 4896, 'trainable_params': 4896}
2.3.4 DTM
# DCNv2
class DeformablePatchMerging(nn.Layer):
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.kernel_size = 2
self.stride = 2
self.padding = 0
self.c_in = dim
self.c_out = dim*2
self.offset = paddle.nn.Conv2D(dim, 2 * 2 * 2, kernel_size=2, stride=2, padding=0)
self.mask = paddle.nn.Conv2D(dim, 2 * 2, kernel_size=2, stride=2, padding=0)
self.dconv = DeformConv2D(dim, dim * 2, kernel_size=2, stride=2, padding=0)
self.norm_layer = nn.BatchNorm2D(dim*2)
self.act_layer = nn.GELU()
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.reshape([B, H, W, C]).transpose([0, 3, 1, 2]) #B C H W
offset = self.offset(x)
mask = self.mask(x)
x= self.dconv(x, offset, mask)
# x= self.dconv(x, offset)
x = self.act_layer(self.norm_layer(x)).flatten(2).transpose([0, 2, 1]) # B H*W C
return x
model = DeformablePatchMerging((16, 16), 96)
paddle.summary(model, (1, 16 * 16, 96))
----------------------------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
====================================================================================================
Conv2D-2 [[1, 96, 16, 16]] [1, 8, 8, 8] 3,080
Conv2D-3 [[1, 96, 16, 16]] [1, 4, 8, 8] 1,540
DeformConv2D-1 [[1, 96, 16, 16], [1, 8, 8, 8], [1, 4, 8, 8]] [1, 192, 8, 8] 73,920
BatchNorm2D-1 [[1, 192, 8, 8]] [1, 192, 8, 8] 768
GELU-1 [[1, 192, 8, 8]] [1, 192, 8, 8] 0
====================================================================================================
Total params: 79,308
Trainable params: 78,540
Non-trainable params: 768
----------------------------------------------------------------------------------------------------
Input size (MB): 0.09
Forward/backward pass size (MB): 0.29
Params size (MB): 0.30
Estimated Total Size (MB): 0.68
----------------------------------------------------------------------------------------------------
{'total_params': 79308, 'trainable_params': 78540}
2.3.5 HiLo
class HiLo(nn.Layer):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., window_size=2, alpha=0.5):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
head_dim = int(dim // num_heads)
self.dim = dim
# self-attention heads in Lo-Fi
self.l_heads = int(num_heads * alpha)
# token dimension in Lo-Fi
self.l_dim = self.l_heads * head_dim
# self-attention heads in Hi-Fi
self.h_heads = num_heads - self.l_heads
# token dimension in Hi-Fi
self.h_dim = self.h_heads * head_dim
# local window size. The `s` in our paper.
self.ws = window_size
if self.ws == 1:
# ws == 1 is equal to a standard multi-head self-attention
self.h_heads = 0
self.h_dim = 0
self.l_heads = num_heads
self.l_dim = dim
self.scale = qk_scale or head_dim ** -0.5
# Low frequence attention (Lo-Fi)
if self.l_heads > 0:
if self.ws != 1:
self.sr = nn.AvgPool2D(kernel_size=window_size, stride=window_size)
self.l_q = nn.Linear(self.dim, self.l_dim, bias_attr=qkv_bias)
self.l_kv = nn.Linear(self.dim, self.l_dim * 2, bias_attr=qkv_bias)
self.l_proj = nn.Linear(self.l_dim, self.l_dim)
# High frequence attention (Hi-Fi)
if self.h_heads > 0:
self.h_qkv = nn.Linear(self.dim, self.h_dim * 3, bias_attr=qkv_bias)
self.h_proj = nn.Linear(self.h_dim, self.h_dim)
self.softmax = nn.Softmax(axis=-1)
def hifi(self, x):
B, H, W, C = x.shape
h_group, w_group = H // self.ws, W // self.ws
total_groups = h_group * w_group
x = x.reshape((B, h_group, self.ws, w_group, self.ws, C)).transpose([0, 1, 3, 2, 4, 5]) # B, hg, ws, wg, ws, C
qkv = self.h_qkv(x).reshape((B, total_groups, -1, 3, self.h_heads, self.h_dim // self.h_heads)).transpose([3, 0, 1, 4, 2, 5])
q, k, v = qkv[0], qkv[1], qkv[2] # B, hw, n_head, ws*ws, head_dim
attn = (q @ k.transpose([0, 1, 2, 4, 3])) * self.scale # B, hw, n_head, ws*ws, ws*ws
attn = self.softmax(attn) # B, hw, n_head, ws*ws, ws*ws
attn = (attn @ v).transpose([0, 1, 3, 2, 4]).reshape(
(B, h_group, w_group, self.ws, self.ws, self.h_dim)) # B, hw, n_head, ws*ws, head_dim
x = attn.transpose([0, 1, 3, 2, 4, 5]).reshape(
(B, h_group * self.ws, w_group * self.ws, self.h_dim)) # B, H, W, C
x = self.h_proj(x)
return x
def lofi(self, x):
B, H, W, C = x.shape
q = self.l_q(x).reshape(
(B, H * W, self.l_heads, self.l_dim // self.l_heads)).transpose([0, 2, 1, 3]) # B, n_head, hw, head_dim
if self.ws > 1:
x_ = x.transpose([0, 3, 1, 2]) # B, C, H, W
x_ = self.sr(x_).reshape((B, C, -1)).transpose([0, 2, 1]) # B, h'w', C
kv = self.l_kv(x_).reshape(
(B, -1, 2, self.l_heads, self.l_dim // self.l_heads)).transpose([2, 0, 3, 1, 4]) # 2, B, n_head, h'w', head_dim
else:
kv = self.l_kv(x).reshape(
(B, -1, 2, self.l_heads, self.l_dim // self.l_heads)).transpose([2, 0, 3, 1, 4]) # 2, B, n_head, hw, head_dim
k, v = kv[0], kv[1]
# B, n_head, hw, h'w' if ws > 1 else B, n_head, hw, hw
attn = (q @ k.transpose([0, 1, 3, 2])) * self.scale
attn = self.softmax(attn)
# B, n_head, hw, hw
x = (attn @ v).transpose([0, 2, 1, 3]).reshape(((B, H, W, self.l_dim)))
x = self.l_proj(x)
return x
def forward(self, x):
B, N, C = x.shape
H = W = int(N ** 0.5)
x = x.reshape((B, H, W, C))
if self.h_heads == 0:
x = self.lofi(x)
return x.reshape((B, N, C))
if self.l_heads == 0:
x = self.hifi(x)
return x.reshape((B, N, C))
hifi_out = self.hifi(x)
lofi_out = self.lofi(x)
x = paddle.concat((hifi_out, lofi_out), axis=-1)
x = x.reshape((B, N, C))
return x
model = HiLo(96, num_heads=16)
paddle.summary(model, (1, 16 * 16, 96))
----------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
============================================================================
Linear-4 [[1, 8, 8, 2, 2, 96]] [1, 8, 8, 2, 2, 144] 13,824
Softmax-1 [[1, 8, 256, 64]] [1, 8, 256, 64] 0
Linear-5 [[1, 16, 16, 48]] [1, 16, 16, 48] 2,352
Linear-1 [[1, 16, 16, 96]] [1, 16, 16, 48] 4,608
AvgPool2D-1 [[1, 96, 16, 16]] [1, 96, 8, 8] 0
Linear-2 [[1, 64, 96]] [1, 64, 96] 9,216
Linear-3 [[1, 16, 16, 48]] [1, 16, 16, 48] 2,352
============================================================================
Total params: 32,352
Trainable params: 32,352
Non-trainable params: 0
----------------------------------------------------------------------------
Input size (MB): 0.09
Forward/backward pass size (MB): 1.66
Params size (MB): 0.12
Estimated Total Size (MB): 1.87
----------------------------------------------------------------------------
{'total_params': 32352, 'trainable_params': 32352}
2.3.6 ConvFFN
class DWConv(nn.Layer):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2D(dim, dim, 3, 1, 1, bias_attr=True, groups=dim)
def forward(self, x):
B, N, C = x.shape
H = W = int(math.sqrt(N))
x = x.transpose([0, 2, 1]).reshape((B, C, H, W))
x = self.dwconv(x)
x = x.flatten(2).transpose([0, 2, 1])
return x
class DWMlp(nn.Layer):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0., linear=False):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.dwconv = DWConv(hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
self.linear = linear
def forward(self, x):
x = self.fc1(x)
x = self.dwconv(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class ConvFFNBlock(nn.Layer):
def __init__(self, dim, input_resolution, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, local_ws=1, alpha=0.5):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.mlp_ratio = mlp_ratio
self.local_ws=local_ws
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = DWMlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
model = ConvFFNBlock(96, (16, 16), num_heads=64)
paddle.summary(model, (1, 16 * 16, 96))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
LayerNorm-2 [[1, 256, 96]] [1, 256, 96] 192
Linear-6 [[1, 256, 96]] [1, 256, 384] 37,248
Conv2D-4 [[1, 384, 16, 16]] [1, 384, 16, 16] 3,840
DWConv-1 [[1, 256, 384]] [1, 256, 384] 0
GELU-2 [[1, 256, 384]] [1, 256, 384] 0
Dropout-1 [[1, 256, 96]] [1, 256, 96] 0
Linear-7 [[1, 256, 384]] [1, 256, 96] 36,960
DWMlp-1 [[1, 256, 96]] [1, 256, 96] 0
Identity-1 [[1, 256, 96]] [1, 256, 96] 0
===========================================================================
Total params: 78,240
Trainable params: 78,240
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.09
Forward/backward pass size (MB): 3.94
Params size (MB): 0.30
Estimated Total Size (MB): 4.33
---------------------------------------------------------------------------
{'total_params': 78240, 'trainable_params': 78240}
2.3.7 LiTv2
class TransformerBlock(nn.Layer):
def __init__(self, dim, input_resolution, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, local_ws=1, alpha=0.5):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.mlp_ratio = mlp_ratio
self.norm1 = norm_layer(dim)
self.attn = HiLo(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, window_size=local_ws, alpha=alpha)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = DWMlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
model = TransformerBlock(96, (16, 16), num_heads=16)
paddle.summary(model, (1, 16 * 16, 96))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
LayerNorm-3 [[1, 256, 96]] [1, 256, 96] 192
Linear-8 [[1, 16, 16, 96]] [1, 16, 16, 96] 9,216
Linear-9 [[1, 16, 16, 96]] [1, 16, 16, 192] 18,432
Softmax-2 [[1, 16, 256, 256]] [1, 16, 256, 256] 0
Linear-10 [[1, 16, 16, 96]] [1, 16, 16, 96] 9,312
HiLo-2 [[1, 256, 96]] [1, 256, 96] 0
Identity-2 [[1, 256, 96]] [1, 256, 96] 0
LayerNorm-4 [[1, 256, 96]] [1, 256, 96] 192
Linear-11 [[1, 256, 96]] [1, 256, 384] 37,248
Conv2D-5 [[1, 384, 16, 16]] [1, 384, 16, 16] 3,840
DWConv-2 [[1, 256, 384]] [1, 256, 384] 0
GELU-3 [[1, 256, 384]] [1, 256, 384] 0
Dropout-2 [[1, 256, 96]] [1, 256, 96] 0
Linear-12 [[1, 256, 384]] [1, 256, 96] 36,960
DWMlp-2 [[1, 256, 96]] [1, 256, 96] 0
===========================================================================
Total params: 115,392
Trainable params: 115,392
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.09
Forward/backward pass size (MB): 13.06
Params size (MB): 0.44
Estimated Total Size (MB): 13.60
---------------------------------------------------------------------------
{'total_params': 115392, 'trainable_params': 115392}
class LITv2Layer(nn.Layer):
def __init__(self, dim, input_resolution, depth, num_heads,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, has_msa=True,
local_ws=1, alpha=0.5):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
# build blocks
block = TransformerBlock if has_msa else ConvFFNBlock
self.blocks = nn.LayerList([
block(dim=dim, input_resolution=input_resolution,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer, local_ws=local_ws, alpha=alpha)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x
model = LITv2Layer(96, (16, 16), 1, num_heads=16)
paddle.summary(model, (1, 16 * 16, 96))
------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
==============================================================================
LayerNorm-5 [[1, 256, 96]] [1, 256, 96] 192
Linear-13 [[1, 16, 16, 96]] [1, 16, 16, 96] 9,312
Linear-14 [[1, 16, 16, 96]] [1, 16, 16, 192] 18,624
Softmax-3 [[1, 16, 256, 256]] [1, 16, 256, 256] 0
Linear-15 [[1, 16, 16, 96]] [1, 16, 16, 96] 9,312
HiLo-3 [[1, 256, 96]] [1, 256, 96] 0
Identity-3 [[1, 256, 96]] [1, 256, 96] 0
LayerNorm-6 [[1, 256, 96]] [1, 256, 96] 192
Linear-16 [[1, 256, 96]] [1, 256, 384] 37,248
Conv2D-6 [[1, 384, 16, 16]] [1, 384, 16, 16] 3,840
DWConv-3 [[1, 256, 384]] [1, 256, 384] 0
GELU-4 [[1, 256, 384]] [1, 256, 384] 0
Dropout-3 [[1, 256, 96]] [1, 256, 96] 0
Linear-17 [[1, 256, 384]] [1, 256, 96] 36,960
DWMlp-3 [[1, 256, 96]] [1, 256, 96] 0
TransformerBlock-2 [[1, 256, 96]] [1, 256, 96] 0
==============================================================================
Total params: 115,680
Trainable params: 115,680
Non-trainable params: 0
------------------------------------------------------------------------------
Input size (MB): 0.09
Forward/backward pass size (MB): 13.25
Params size (MB): 0.44
Estimated Total Size (MB): 13.79
------------------------------------------------------------------------------
{'total_params': 115680, 'trainable_params': 115680}
class LITv2(nn.Layer):
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, patch_norm=True, has_msa=[0, 0, 1, 1],
alpha=[0.1, 0.1, 0.9, 1.0], local_ws=[1, 1, 2, 1], **kwargs):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
self.has_msa = has_msa
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x.item() for x in paddle.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.LayerList()
for i_layer in range(self.num_layers):
layer = LITv2Layer(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=DeformablePatchMerging if (i_layer < self.num_layers - 1) else None,
has_msa=self.has_msa[i_layer], local_ws=local_ws[i_layer], alpha=alpha[i_layer])
self.layers.append(layer)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1D(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
trunc_normal_ = paddle.nn.initializer.TruncatedNormal(mean=0.0, std=.02)
zeros_ = nn.initializer.Constant(value=0.)
ones_ = nn.initializer.Constant(value=1.)
if isinstance(m, nn.Linear):
trunc_normal_(m.weight)
if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias)
elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight)
elif isinstance(m, nn.Conv2D):
nn.initializer.XavierNormal(m.weight)
def forward_features(self, x):
x = self.patch_embed(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
x = self.avgpool(x.transpose([0, 2, 1])) # B C 1
x = paddle.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
2.3.8 模型的参数
# LIT-S
model = LITv2(num_classes=10, embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24])
paddle.summary(model, (1, 3, 224, 224))

# LIT-M
model = LITv2(num_classes=10, embed_dim=96, depths=[2, 2, 18, 2], num_heads=[3, 6, 12, 24])
paddle.summary(model, (1, 3, 224, 224))
# LIT-B
model = LITv2(num_classes=10, embed_dim=128, depths=[2, 2, 18, 2], num_heads=[3, 6, 16, 32])
paddle.summary(model, (1, 3, 224, 224))

model = LITv2(num_classes=10, embed_dim=64, depths=[2, 2, 6, 2], num_heads=[3, 6, 16, 32])
paddle.summary(model, (1, 3, 224, 224))

### 2.4 训练
```python
learning_rate = 5e-5
n_epochs = 100
paddle.seed(42)
np.random.seed(42)
work_path = 'work/model'
# LIT-ours
model = LITv2(num_classes=10, embed_dim=64, depths=[2, 2, 6, 2], num_heads=[3, 6, 16, 32])
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0
threshold = 0.0
best_acc = 0.0
val_acc = 0.0
loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording loss
acc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracy
loss_iter = 0
acc_iter = 0
for epoch in range(n_epochs):
# ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy()
print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr()))
for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
accuracy_manager.update(acc)
if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100))
# ---------- Validation ----------
model.eval()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter)
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100))
# ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))
print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
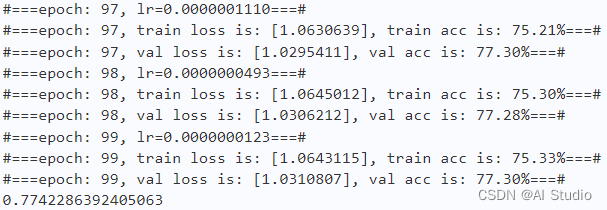
2.5 结果分析
def plot_learning_curve(record, title='loss', ylabel='CE Loss'):
''' Plot learning curve of your CNN '''
maxtrain = max(map(float, record['train'][title]))
maxval = max(map(float, record['val'][title]))
ymax = max(maxtrain, maxval) * 1.1
mintrain = min(map(float, record['train'][title]))
minval = min(map(float, record['val'][title]))
ymin = min(mintrain, minval) * 0.9
total_steps = len(record['train'][title])
x_1 = list(map(int, record['train']['iter']))
x_2 = list(map(int, record['val']['iter']))
figure(figsize=(10, 6))
plt.plot(x_1, record['train'][title], c='tab:red', label='train')
plt.plot(x_2, record['val'][title], c='tab:cyan', label='val')
plt.ylim(ymin, ymax)
plt.xlabel('Training steps')
plt.ylabel(ylabel)
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
2.5.1 loss和acc曲线
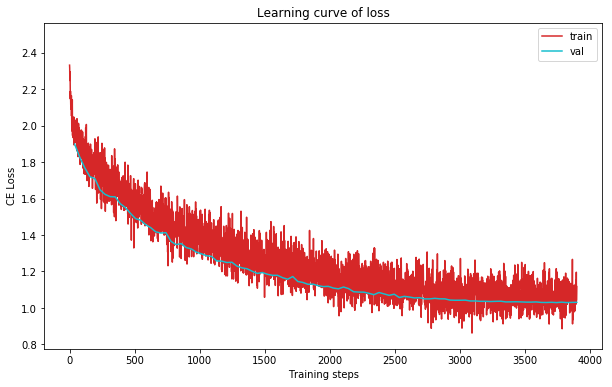
plot_learning_curve(loss_record, title='loss', ylabel='CE Loss')
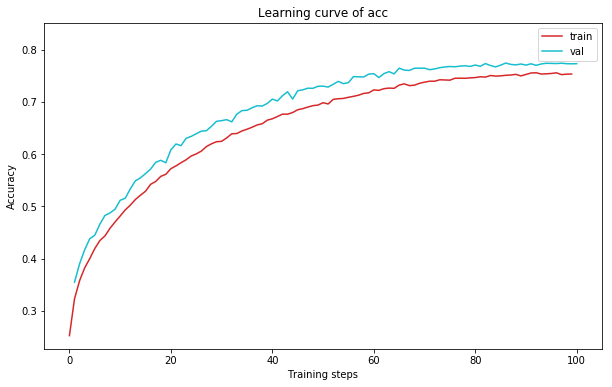
plot_learning_curve(acc_record, title='acc', ylabel='Accuracy')
import time
work_path = 'work/model'
model = LITv2(num_classes=10, embed_dim=64, depths=[2, 2, 6, 2], num_heads=[3, 6, 16, 32])
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
bb = time.time()
print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:958
2.5.2 预测与真实标签比较
def get_cifar10_labels(labels):
"""返回CIFAR10数据集的文本标签。"""
text_labels = [
'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog',
'horse', 'ship', 'truck']
return [text_labels[int(i)] for i in labels]
def show_images(imgs, num_rows, num_cols, pred=None, gt=None, scale=1.5):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if paddle.is_tensor(img):
ax.imshow(img.numpy())
else:
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if pred or gt:
ax.set_title("pt: " + pred[i] + "\ngt: " + gt[i])
return axes
work_path = 'work/model'
X, y = next(iter(DataLoader(val_dataset, batch_size=18)))
model = LITv2(num_classes=10, embed_dim=64, depths=[2, 2, 6, 2], num_heads=[3, 6, 16, 32])
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
logits = model(X)
y_pred = paddle.argmax(logits, -1)
X = paddle.transpose(X, [0, 2, 3, 1])
axes = show_images(X.reshape((18, 224, 224, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y))
plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

2.5.3 可视化结果
!pip install interpretdl
import interpretdl as it
work_path = 'work/model'
model = LITv2(num_classes=10, embed_dim=64, depths=[2, 2, 6, 2], num_heads=[3, 6, 16, 32])
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
X, y = next(iter(DataLoader(val_dataset, batch_size=18)))
lime = it.LIMECVInterpreter(model, use_cuda=True)
lime_weights = lime.interpret(X.numpy()[3], interpret_class=y.numpy()[3], batch_size=100, num_samples=10000, visual=True)
100%|██████████| 10000/10000 [00:53<00:00, 161.55it/s]

lime_weights = lime.interpret(X.numpy()[13], interpret_class=y.numpy()[13], batch_size=100, num_samples=10000, visual=True)
100%|██████████| 10000/10000 [00:53<00:00, 160.13it/s]

总结
LiTv2基于LiTv1对其进行了两个主要改进:1. 提出HiLo注意力机制;2. 使用深度卷积来代替相对位置编码
未来工作:仔细调整参数在更大的数据集上验证LiTv2的有效性
转载自:https://aistudio.baidu.com/aistudio/projectdetail/4367898

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)