
【原理】经典的预训练模型(上)-预训练模型发展历史
介绍预训练语言模型的发展历史,word2vec,elmo,bert,gpt,bert一些拓展:比如长序列建模,高效结构,CV领域的Transformer等的演进过程。
预训练模型发展史
1.传统的词向量
传统的词向量是每个词用一个向量表示。传统的方法是用One-Hot向量表示,就是给每个词都给一个编号,One-Hot词向量是一个正交向量,每个词给一个编号,编号所对应的位置的值为1,其余为0,但这样表示会导致严重的数据稀疏、离散、正交等问题。词袋模型是每一个词对应一个位置,按照数量不断加一,好处是容易获取和计算,但是忽略了词序信息。
上面方法表示的向量不能很好的对词进行建模,另一种很好的方式是分布式表示。即一个词的含义可以由它周围的词决定。就是常说的word embedding。分布式表示就是直接用一个低维的、稠密的、连续的向量表示一个词。如何获得这样的表示是研究重点。
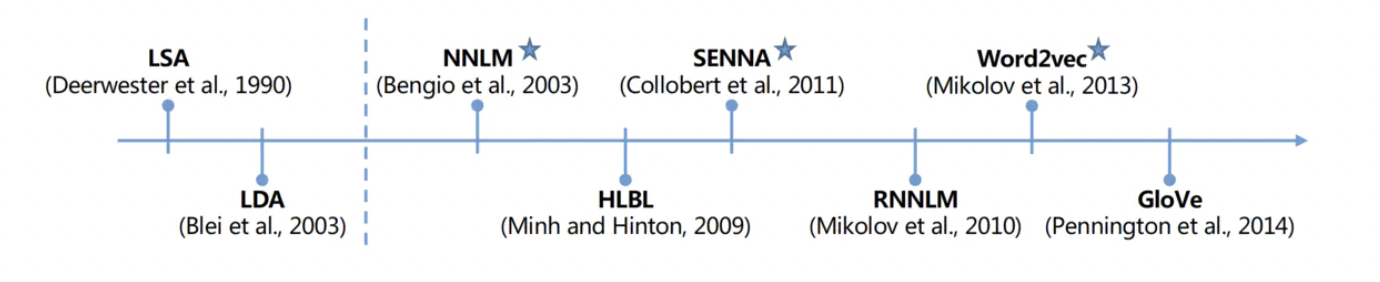
-
基于神经网络的方法的工作最早是在2003年有Bengio等提出的,叫Nerual Network Language Models.
-
基于神经网络最著名的工作是Google在2013年的工作Word2Vec,之后这个词向量作为了很多NLP任务的初始化输入,得到很大的应用。比如词义相似度计算、类比关系计算、知识图谱补全、推荐系统等。CBOW(Continuous Bag-of-Words Model)和Skip-gram (Continuous Skip-gram Model),是Word2vec 的两种训练模式。
CBOW通过上下文来预测当前值。相当于一句话中扣掉一个词,让你猜这个词是什么。

Skip-gram用当前词来预测上下文。相当于给你一个词,让你猜前面和后面可能出现什么词。

Word2Vec的缺点也很明显,由于词和向量是一对一的关系,所以多义词的问题无法解决。Word2vec 是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化,例子如图

2. 上下文相关词向量
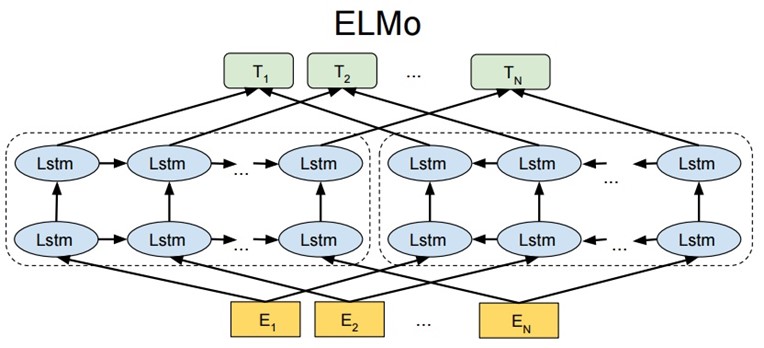
上下文相关的词向量最典型的工作是ELMo,ELMo是“Embedding from Language Models”的简称。它的模型架构就是一个双向LSTM的LM模型。ELMo是为了解决一一词多义性,对于不同的上下文可以给出不同的词向量。ELMo论文被评为NAACL 2018的outstanding paper award,其方法有很大的启发意义。
3. 预训练语言模型
前面的方法不能算是我们现在所说的预训练模型。因为上面的模型训练出来的词向量/词的表示,在做其他任务时作为一个额外的输入,是不变的;而预训练模型是整个模型的结构就是为了用来做目标任务的,我在进行目标任务的同时,还回过头来进行fine-tune,更好的把我当前的任务/模型进行精调。
预训练语言模型最典型的两个模型是GPT和BERT:
- GPT是“Generative Pretrained Transformer”的简称,首次用到了Transformer的Decoder部分。ELMo更多用的是LSTM,而LSTM对长序列的建模效果不是特别好。在目标任务上进行精调。当然就可以设计或者规定几种目标任务,比如分类问题(一个句子属于哪一类)、Entailment(两个句子之间什么关系)、Similarity(两个文本相似度)、多选题等等。获得了比ELMo更好的结果。
- BERT和GPT的一个很大的区别是,BERT是双向的,使用的是Transformer的Encoder部分。就是挖掉几个词,在猜这几个词的时候不光用到前面的词,还会用到后面的信息。
4. 预训练语言模型的改进和拓展
预训练语言模型的改进和拓展的方面有很多,本文章选取了自然语言理解,长序列建模,高效的计算结构,模型压缩,计算机视觉领域的Transformer等方面进行介绍。
4.1 自然语言理解
ERNIE, RoBERTa, KBERT,清华ERNIE等。
- ERNIE(百度):首先预测word piece的任务难度不是很大,比如“哈”和“滨”,预测中间的尔还是比较容易的,预训练难度不是很大。什么比较难呢?就是把整个词挖掉,预测整个词,。比如***是黑龙江的省会,来预测这个空填哈尔滨,提出了这种基于词或者说实体的预训练任务。效果显示很有效。
- RoBERTa(Facebook):对BERT更精细的调参,包括:batch的大小是否可以更大、训练时间是否可以更长;发现去除NSP任务,完全靠完形填空的任务,对整个性能有所帮助;训练数据序列更长;动态改变mask的内容。但是,训练时间很长!
- K-BERT:前面的ERNIE模型做知识融入想法是在预训练的时候把知识融入进去,K-BERT是在推理的时候融入知识。这个知识怎么融入呢?一个办法是把句子中出现的实体、它在知识图谱中与它有关联的实体、它们之间的关系全部加到文本中,构成了一个更复杂的文本。对这个文本上直接用BERT模型,当然文章中提出了一些复杂的mask方法。
- ERNIE(清华):传统的方法是我将词的预训练表示作为输入,这个模型的想法是:假设这个词是一个实体的话,实体在知识库的表示可以直接的拼接过来,作为输入,然后再进行预测。相当于在预训练中用到了实体的信息。在知识库中实体是怎么表示的呢?就涉及到了图谱的embedding表示。整个模型相当于融入了一种额外的知识。
4.2 长序列建模
Transformer-xl, xlnet, longformer等。
-
Transformer本身能够维持的依赖长度很有可能会超出这个固定的划分长度,从而导致Transformer能够捕获的最大依赖长度不超过这个划分长度,Transformer本身达不到更好的性能。Transformer-XL被提出来解决这些问题。它主要提出了两个技术:Segment-Level 循环机制和相对位置编码。Transformer-XL能够建模更长的序列依赖,比RNN长80%,比Vanilla Transformer长450%。同时具有更快的评估速度,比Vanilla Transformer快1800+倍。
-
XLNet是基于自回归模型的建模思路设计的,同时避免了只能单向建模的缺点,因此它是一种能看得见双向信息的广义AR模型。作为一个AR模型,XLNet并没有采用预测mask单词的方式进行建模,因此它不存在BERT中出现的预训练-微调的GAP,更不存在预测mask的独立性假设。
-
Longformer被提出来拓展模型在长序列建模的能力,它提出了一种时空复杂度同文本序列长度呈线性关系的Self-Attention,用以保证模型使用更低的时空复杂度建模长文档。
4.3 高效的模型结构
ALBERT,ELECTRA,Performer等。
- ALBERT 通过两个参数削减技术克服了扩展预训练模型面临的主要障碍: 对嵌入参数化进行因式分解,跨层参数共享。两种技术都显著降低了 BERT 的参数量,同时不对其准确度造成明显影响,从而提升了参数效率。ALBERT 的配置类似于 BERT-large,但参数量仅为后者的 1/18,训练速度却是后者的 1.7 倍。
- ELECTRA作者提出了一种更有效的预训练任务,称为Replaced Token Detection(RTD),字符替换探测。RTD方法不是掩盖输入,而是通过使用生成网络来生成一些合理替换字符来达到破坏输入的目的。然后,我们训练一个判别器模型,该模型可以预测当前字符是否被语言模型替换过。实验结果表明,这种新的预训练任务比MLM更有效,因为该任务是定义在所有文本输入上,而不是仅仅被掩盖的一小部分,在模型大小,数据和计算力相同的情况下,RTD方法所学习的上下文表示远远优于BERT所学习的上下文表示。
- Performer提出了一个具有线性复杂度的注意力,其注意力机制可线性扩展,从而实现更快的训练,同时允许模型处理较长的长度,这对于某些图像数据集(如ImageNet64)和文本数据集(如PG-19)是必需的。Performer 使用一个高效的(线性)广义注意力框架(generalized attention framework),允许基于不同相似性度量(核)的一类广泛的注意力机制。该框架通过谷歌的新算法 FAVOR+( Fast Attention Via Positive Orthogonal Random Features)来实现,后者能够提供注意力机制的可扩展低方差、无偏估计,这可以通过随机特征图分解(常规 softmax-attention)来表达。该方法在保持线性空间和时间复杂度的同时准确率也很有保证,也可以应用到独立的 softmax 运算。此外,该方法还可以和可逆层等其他技术进行互操作。
4.4 模型压缩
DistillBERT、MobileBERT、Patient-KD、ALP-KD、MINILM、BERT-EMD、DistilBERT等。
- Patient-KD: 论文中提出了Patient Knowledge Distillation(Patient KD)方法,将原始大模型压缩为同等有效的轻量级浅层网络。同时,作者对以往的知识蒸馏方法进行了调研,如图1所示,vanilla KD在QNLI和MNLI的训练集上可以很快的达到和teacher model相媲美的性能,但在测试集上则很快达到饱和。对此,作者提出一种假设,在知识蒸馏的过程中过拟合会导致泛化能力不良。为缓解这个问题,论文中提出一种“耐心”师生机制,即让Patient-KD中的学生模型从教师网络的多个中间层进行知识提取,而不是只从教师网络的最后一层输出中学习。
- DistillBERT: 近年来,大规模预训练语言模型成为NLP任务的基本工具,虽然这些模型带来了显著的改进,但它们通常拥有数亿个参数(如图1所示),而这会引起两个问题。首先,大型预训练模型需要的计算成本很高。其次,预训练模型不断增长的计算和内存需求可能会阻碍语言处理应用的广泛落地。因此,作者提出DistilBERT,它表明小模型可以通过知识蒸馏从大模型中学习,并可以在许多下游任务中达到与大模型相似的性能,从而使其在推理时更轻、更快。
- DynaBERT: 近年的模型压缩方式基本上都是将大型的BERT网络压缩到一个固定的小尺寸网络。而实际工作中,不同的任务对推理速度和精度的要求不同,有的任务可能需要四层的压缩网络而有的任务会需要六层的压缩网络。DynaBERT(dynamic BERT)提出一种不同的思路,它可以通过选择自适应宽度和深度来灵活地调整网络大小,从而得到一个尺寸可变的网络。
- TinyBERT: TinyBERT主要做了两点创新,第一点是提供一种新的针对 transformer-based 模型进行蒸馏的方法,使得BERT中具有的语言知识可以迁移到TinyBERT中去。第二点是提出一个两阶段学习框架,在预训练阶段和fine-tuning阶段都进行蒸馏,确保TinyBERT可以充分的从BERT中学习到一般领域和特定任务两部分的知识。
4.5 视觉领域的Transformer
ViT,DeiT ,DETR,Timesformer等。
- ViT: 受到NLP领域中Transformer成功应用的启发,ViT算法中尝试将标准的Transformer结构直接应用于图像,并对整个图像分类流程进行最少的修改。具体来讲,ViT算法中,会将整幅图像拆分成小图像块,然后把这些小图像块的线性嵌入序列作为Transformer的输入送入网络,然后使用监督学习的方式进行图像分类的训练。
- DETR: 该方法提出了一个检测的新的pipeline,无需预定义锚框以及人为添加的后处理操作(NMS)。称为DEtection Transformer(DETR),一个基于集合预测 的全局损失,通过二分匹配和一个transformer编码解码器生成预测。给予一组固定的可学习的目标query集合,DETR推理目标坐标和图片上下文直接输出最终的预测结果。
- Timesformer: TimeSformer是Facebook AI于2021年提出的无卷积视频分类方法,该方法使用ViT网络结构作为backbone,提出时空自注意力机制,以此代替了传统的卷积网络。与图像只具有空间信息不同,视频还包含时间信息,因此TimeSformer对一系列的帧级图像块进行时空特征提取,从而适配视频任务。
5. 总结
本文章梳理了预训练语言模型的发展史以及未来的一个改进和发展方向,包括对于Transformer自身的改进,还有对于BERT的改进,以及在视觉领域的拓展,后续会围绕预训练模型展开一系列的讲解,
6. 参考文献
如果同学们对本课程感兴趣,想了解更多课程相关信息,或者查阅更多课程资料,请移步我们的官方github: awesome-DeepLearning,也欢迎各位同学点击Star,有大家的支持我们才会走得更远,提供更多优质资源以供学习。同时更多深度学习资料请参阅飞桨深度学习平台。

最后,也欢迎同学们加入我们的官方交流群。


学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)