
基于ResNet50模型的行车环境下天气时间分类
AI达人特训营2022/6/14 雾切凉宫一、项目简介 现在自动驾驶场景中,天气和时间(黎明、早上、下午、黄昏、夜晚)会对传感器的精度造成影响,比如雨天和夜晚会对视觉传感器的精度造成很大的影响。此项目旨在对拍摄的照片天气和时间进行分类,从而在不同的天气和时间使用不同的自动驾驶策略。*以上为在未标注数据集中的检测结果二、数据集来源及分析使用公共数据集天气以及时间分类 - 飞桨AI Studio (
AI达人特训营
2022/6/14 雾切凉宫
一、项目简介
现在自动驾驶场景中,天气和时间(黎明、早上、下午、黄昏、夜晚)会对传感器的精度造成影响,比如雨天和夜晚会对视觉传感器的精度造成很大的影响。此项目旨在对拍摄的照片天气和时间进行分类,从而在不同的天气和时间使用不同的自动驾驶策略。
*以上为在未标注数据集中的检测结果
二、数据集来源及分析
使用公共数据集天气以及时间分类 - 飞桨AI Studio (baidu.com)
数据集中包含3000张真实场景下行车记录仪采集的图片,其中训练集包含2600张带有天气和时间类别标签的图片,测试集包含400张不带有标签的图片。 天气类别包含多云、晴天、雨天、雪天和雾天5个类别;时间包含黎明、早上、下午、黄昏、夜晚5个类别。
**虽然描述里说有5种天气但实际上只有多云、晴天、雨天
train_images 训练图片集文件夹
train.json 分类标注文件
2.1 数据集预处理
数据集解压
解压数据集
!unzip /home/aistudio/data/data132154/train_dataset.zip -d /home/aistudio/work/train
三、制作ImageNet数据集
3.1 ImageNet数据集格式说明
在PaddleX中,图像分类任务支持的ImageNet数据集格式要求如下:
数据文件夹结构
数据集目录data_dir下包含多个文件夹,每个文件夹中的图像均属于同一个类别,文件夹的命名即为类别名(注意路径中不要包括中文,空格)。
文件夹结构示例如下:
MyDataset/ # 图像分类数据集根目录
|–dog/ # 当前文件夹所有图片属于dog类别
| |–d1.jpg
| |–d2.jpg
| |–…
| |–…
|
|–…
|
|–snake/ # 当前文件夹所有图片属于snake类别
| |–s1.jpg
| |–s2.jpg
| |–…
| |–…
训练集、验证集列表和类别标签列表
为了完成模型的训练和精度验证。我们需要在MyDataset目录下准备train_list.txt, val_list.txt和labels.txt三个文件,分别用于表示训练集列表,验证集列表和类别标签列表。点击下载图像分类示例数据集查看具体的数据格式。
labels.txt
labels.txt用于列出所有类别,类别对应行号表示模型训练过程中类别的id(行号从0开始计数),例如labels.txt为以下内容
dog
cat
snake
即表示该分类数据集中共有3个类别,分别为dog,cat和snake,在模型训练中dog对应的类别id为0, cat对应1,以此类推
train_list.txt
train_list.txt列出用于训练时的图片集合,与其对应的类别id,示例如下
dog/d1.jpg 0
dog/d2.jpg 0
cat/c1.jpg 1
… …
snake/s1.jpg 2
其中第一列为相对对MyDataset的相对路径,第二列为图片对应类别的类别id
val_list.txt
val_list列出用于验证时的图片集成,与其对应的类别id,格式与train_list.txt一致
3.2 根据ImageNet要求清洗数据
读取json文件,将同类别的图像整理进对应的类别文件夹
import json
import os.path
import shutil
base_dir = r"/home/aistudio/work/train"
info = json.load(open(os.path.join(base_dir, “train.json”), “r+”))
print(info)
infos = info[“annotations”]
for info in infos:
filename = info[“filename”]
filename = filename[filename.find(“\”)+1:]
category = info[“period”]+“_”+info[“weather”]
print(filename,base_dir,filename_path)
filename_path = os.path.join(base_dir,“train_images”, filename)
category_path = os.path.join(base_dir, “ImageNet_dataset”,category, filename)
try:
shutil.copy(filename_path, category_path)
except:
os.makedirs(os.path.join(base_dir, “ImageNet_dataset”,category))
shutil.copy(filename_path, category_path)
3.3 分割数据集
数据被清洗成了ImageNet数据集的形状后,需要对数据集进行划分
!paddlex --split_dataset --format IMAGENET --dataset_dir /home/aistudio/work/train/ImageNet_dataset --val_value 0.1 --test_value 0.1
3.3 定义数据增强策略
准备好数据集并完成了数据集划分之后。需要对数据集进行预处理和数据增强策略(数据增强可根据实际需求添加),然后定义dataset加载划分好的数据集并建立索引。
*更多的数据增强需求可以参阅Paddlex数据增强API
from paddlex import transforms as T
import os
data_dir = r"/home/aistudio/work/train/ImageNet_dataset"
定义训练和验证时的transforms
API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/transforms/transforms.md
train_transforms = T.Compose(
[T.RandomCrop(crop_size=224), T.RandomHorizontalFlip(), T.Normalize()])
eval_transforms = T.Compose([
T.ResizeByShort(short_size=256), T.CenterCrop(crop_size=224), T.Normalize()
])
3.3 数据集读取与预处理
读取ImageNet格式的检测数据集,并对样本进行相应的处理。ImageNet数据集格式的介绍可查看文档:数据集介绍
paddlex.datasets.ImageNet
用于图像分类模型
paddlex.datasets.ImageNet(data_dir, file_list, label_list, transforms=None, num_workers=‘auto’, shuffle=False)
读取ImageNet格式的分类数据集,并对样本进行相应的处理。ImageNet数据集格式的介绍可查看文档:数据集格式说明
示例:代码文件
参数
data_dir (str): 数据集所在的目录路径。
file_list (str): 描述数据集图片文件和类别id的文件路径(文本内每行路径为相对data_dir的相对路径)。
label_list (str): 描述数据集包含的类别信息文件路径。
transforms (paddlex.transforms): 数据集中每个样本的预处理/增强算子,详见paddlex.transforms。
num_workers (int|str):数据集中样本在预处理过程中的进程数。默认为’auto’。当设为’auto’时,根据系统的实际CPU核数设置num_workers: 如果CPU核数的一半大于8,则num_workers为8,否则为CPU核数的一半。
shuffle (bool): 是否需要对数据集中样本打乱顺序。默认为False。
定义训练和验证所用的数据集
API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/datasets.md
train_dataset = pdx.datasets.ImageNet(
data_dir=data_dir,
file_list=os.path.join(data_dir, “train_list.txt”),
label_list=os.path.join(data_dir, “labels.txt”),
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir=data_dir,
file_list=os.path.join(data_dir, “val_list.txt”),
label_list=os.path.join(data_dir, “labels.txt”),
transforms=eval_transforms)
四、模型选取与训练
4.1 目标检测模型选取
paddlex有许多图像分类模型:
[图像分类模型api文档](PaddleX/classification.md at develop · PaddlePaddle/PaddleX (github.com))
这里选取了ResNet50模型完成任务。
**
num_epochs (int): 训练迭代轮数。
train_dataset (paddlex.dataset): 训练数据集。
train_batch_size (int): 训练数据batch大小,默认为64。目前检测仅支持单卡batch大小为1进行评估,train_batch_size参数不影响评估时的batch大小。
eval_dataset (paddlex.dataset or None): 评估数据集。当该参数为None时,训练过程中不会进行模型评估。默认为None。
optimizer (paddle.optimizer.Optimizer): 优化器。当该参数为None时,使用默认优化器:paddle.optimizer.lr.PiecewiseDecay衰减策略,paddle.optimizer.Momentum优化方法。
save_interval_epochs (int): 模型保存间隔(单位:迭代轮数)。默认为1。
log_interval_steps (int): 训练日志输出间隔(单位:迭代次数)。默认为10。
save_dir (str): 模型保存路径。默认为’output’。
pretrain_weights (str ort None): 若指定为’.pdparams’文件时,则从文件加载模型权重;若为字符串’IMAGENET’,则自动下载在ImageNet图片数据上预训练的模型权重(仅包含backbone网络);若为字符串’COCO’,则自动下载在COCO数据集上预训练的模型权重;若为None,则不使用预训练模型。默认为’IMAGENET’。
learning_rate (float): 默认优化器的学习率。默认为0.001。
warmup_steps (int): 默认优化器进行warmup过程的步数。默认为0。
warmup_start_lr (int): 默认优化器warmup的起始学习率。默认为0.0。
lr_decay_epochs (list): 默认优化器的学习率衰减轮数。默认为[216, 243]。
lr_decay_gamma (float): 默认优化器的学习率衰减率。默认为0.1。
metric ({‘COCO’, ‘VOC’, None}): 训练过程中评估的方式。默认为None,根据用户传入的Dataset自动选择,如为VOCDetection,则metric为’VOC’;如为COCODetection,则metric为’COCO’。
use_ema (bool): 是否使用指数衰减计算参数的滑动平均值。默认为False。
early_stop (bool): 是否使用提前终止训练策略。默认为False。
early_stop_patience (int): 当使用提前终止训练策略时,如果验证集精度在early_stop_patience个epoch内连续下降或持平,则终止训练。默认为5。
use_vdl (bool): 是否使用VisualDL进行可视化。默认为True。
resume_checkpoint (str): 恢复训练时指定上次训练保存的模型路径,例如output/ppyolov2/best_model。若为None,则不会恢复训练。默认值为None。恢复训练需要将pretrain_weights设置为None。
初始化模型,并进行训练
可使用VisualDL查看训练指标,参考https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/visualdl.md
num_classes = len(train_dataset.labels)
model = pdx.cls.ResNet50_vd_ssld(num_classes=num_classes)
API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/models/classification.md
各参数介绍与调整说明:https://github.com/PaddlePaddle/PaddleX/tree/develop/docs/parameters.md
model.train(
num_epochs=2,
train_dataset=train_dataset,
train_batch_size=32,
eval_dataset=eval_dataset,
#pretrain_weights=None,
lr_decay_epochs=[4, 6, 8],
learning_rate=0.01,
save_dir=‘/home/aistudio/work/train/output/ResNet50_vd_ssld’,
#resume_checkpoint=‘/home/aistudio/work/train/output/ResNet50_vd_ssld/best_model’,
)
*继续训练则将model.train()中两句注释语句恢复。
4.3 训练可视化
可以利用VisualDL实时可视化训练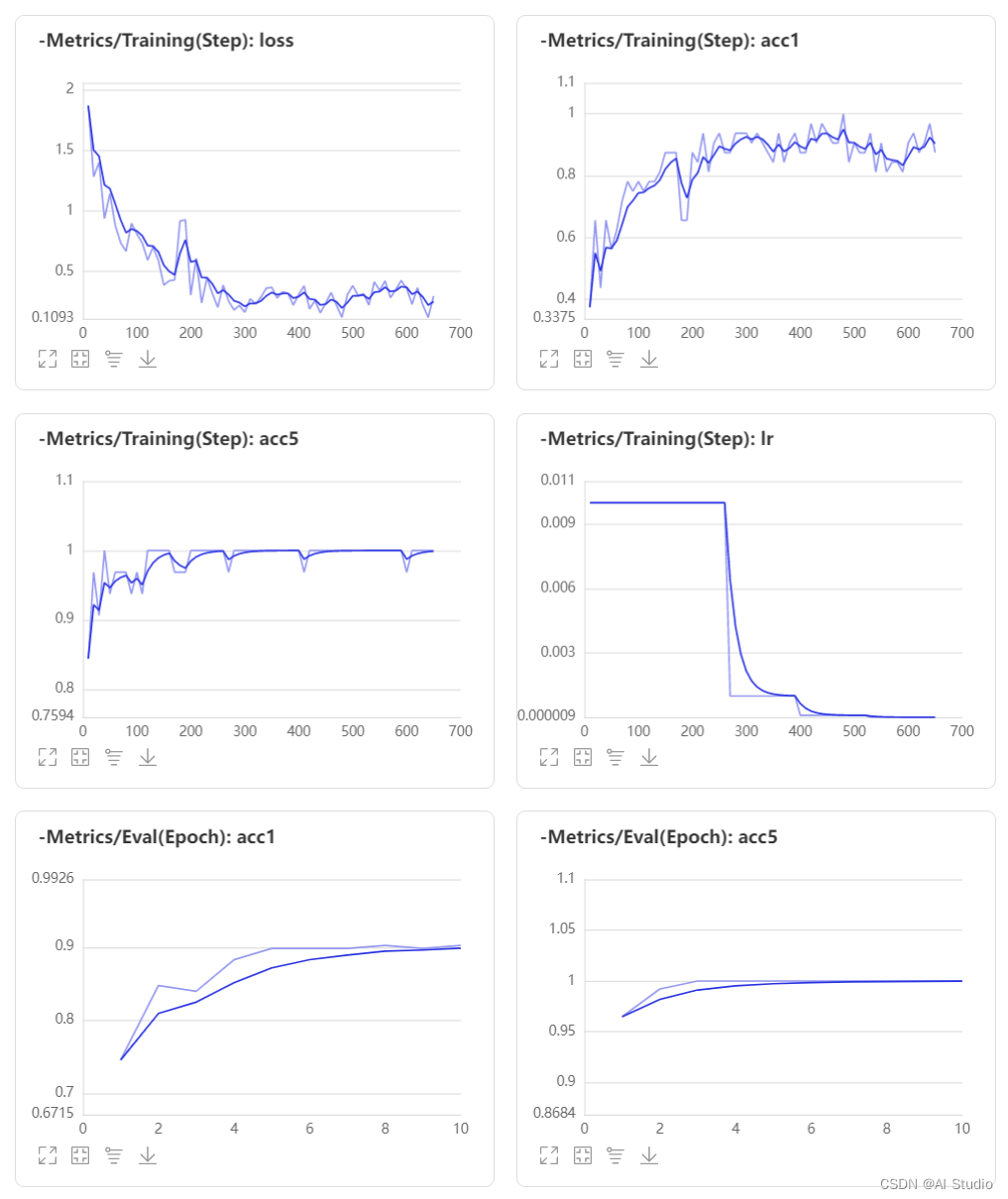
五、模型评估与预测
5.1 模型评估
*以下acc在训练集中划分评估
模型 训练轮数 acc
ResNet50_vd_ssld 10 epoch 0.871093
import paddlex as pdx
from paddlex import transforms as T
import os
from PIL import Image, ImageDraw, ImageFont
import matplotlib.pyplot as plt
model = pdx.load_model(“/home/aistudio/work/train/output/ResNet50_vd_ssld/best_model”) # 加载训练好的模型
data_dir = “/home/aistudio/work/train/ImageNet_dataset”
定义训练和验证时的transforms
API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/transforms/transforms.md
test_transforms = T.Compose([
T.ResizeByShort(short_size=256), T.CenterCrop(crop_size=224), T.Normalize()
])
定义训练和验证所用的数据集
API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/datasets.md
test_dataset = pdx.datasets.ImageNet(
data_dir=data_dir,
file_list=os.path.join(data_dir, “test_list.txt”),
label_list=os.path.join(data_dir, “labels.txt”),
transforms=test_transforms,
shuffle=True)
print(model.evaluate(test_dataset))
5.2 模型预测与评估
5.2.1 模型评估
import paddlex as pdx
from paddlex import transforms as T
import os
from PIL import Image, ImageDraw, ImageFont
import matplotlib.pyplot as plt
model = pdx.load_model(“/home/aistudio/work/train/output/ResNet50_vd_ssld/best_model”) # 加载训练好的模型
pathDir = os.listdir(r"/home/aistudio/work/test/test_images")
count = 0
for path in pathDir:
count = count+1
image_name = os.path.join(r"/home/aistudio/work/test/test_images", path)
print(image_name)
result = model.predict(image_name)
img = Image.open(image_name)
draw = ImageDraw.Draw(img)
font_size = img.size[0] // 10
draw.text((10, 10), result[0][“category”], “red”)
img.save(os.path.join(r"/home/aistudio/work/predict",path))
print(image_name, result)
5.2.2 模型预测
import paddlex as pdx
from paddlex import transforms as T
import os
from PIL import Image, ImageDraw, ImageFont
import matplotlib.pyplot as plt
model = pdx.load_model(“/home/aistudio/work/train/output/ResNet50_vd_ssld/best_model”) # 加载训练好的模型
pathDir = os.listdir(r"/home/aistudio/work/test/test_images")
count = 0
for path in pathDir:
count = count+1
image_name = os.path.join(r"/home/aistudio/work/test/test_images", path)
print(image_name)
result = model.predict(image_name)
img = Image.open(image_name)
draw = ImageDraw.Draw(img)
font_size = img.size[0] // 10
draw.text((10, 10), result[0][“category”], “red”)
img.save(os.path.join(r"/home/aistudio/work/predict",path))
print(image_name, result)
*会在/home/aistudio/work/predict输出带文字标识的图像
六、总结
我作为新手,目标想要跑通paddlex的api实现模型训练。
首先需要熟悉各种标准数据集的格式,并能够把自己的数据集整理成符合要求的形式
熟悉数据增强策略,能够自己调整参数
所提供的数据集分类较少,希望有更多不同时间,不同天气的数据加以补充
参考文章:
https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/data/format/detection.md
https://aistudio.baidu.com/paddle/forum/topic/show/989720
https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/
In [ ]
!pip install paddlex
In [ ]
!unzip /home/aistudio/data/data132154/train_dataset.zip -d /home/aistudio/work/train
In [ ]
import json
import os.path
import shutil
base_dir = r"/home/aistudio/work/train"
info = json.load(open(os.path.join(base_dir, “train.json”), “r+”))
print(info)
infos = info[“annotations”]
for info in infos:
filename = info[“filename”]
filename = filename[filename.find(“\”)+1:]
category = info[“period”]+“_”+info[“weather”]
print(filename,base_dir,filename_path)
filename_path = os.path.join(base_dir,“train_images”, filename)
category_path = os.path.join(base_dir, “ImageNet_dataset”,category, filename)
try:
shutil.copy(filename_path, category_path)
except:
os.makedirs(os.path.join(base_dir, “ImageNet_dataset”,category))
shutil.copy(filename_path, category_path)
In [ ]
!paddlex --split_dataset --format IMAGENET --dataset_dir /home/aistudio/work/train/ImageNet_dataset --val_value 0.2 --test_value 0.1
In [ ]
import paddlex as pdx
from paddlex import transforms as T
import os
data_dir = r"/home/aistudio/work/train/ImageNet_dataset"
定义训练和验证时的transforms
API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/transforms/transforms.md
train_transforms = T.Compose(
[T.RandomCrop(crop_size=224), T.RandomHorizontalFlip(), T.Normalize()])
eval_transforms = T.Compose([
T.ResizeByShort(short_size=256), T.CenterCrop(crop_size=224), T.Normalize()
])
定义训练和验证所用的数据集
API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/datasets.md
train_dataset = pdx.datasets.ImageNet(
data_dir=data_dir,
file_list=os.path.join(data_dir, “train_list.txt”),
label_list=os.path.join(data_dir, “labels.txt”),
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir=data_dir,
file_list=os.path.join(data_dir, “val_list.txt”),
label_list=os.path.join(data_dir, “labels.txt”),
transforms=eval_transforms)
初始化模型,并进行训练
可使用VisualDL查看训练指标,参考https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/visualdl.md
num_classes = len(train_dataset.labels)
model = pdx.cls.ResNet50_vd_ssld(num_classes=num_classes)
API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/models/classification.md
各参数介绍与调整说明:https://github.com/PaddlePaddle/PaddleX/tree/develop/docs/parameters.md
model.train(
num_epochs=10,
train_dataset=train_dataset,
train_batch_size=16,
eval_dataset=eval_dataset,
#pretrain_weights=None,
lr_decay_epochs=[2, 4, 6, 8],
lr_decay_gamma=0.05,
learning_rate=0.01,
save_dir=‘/home/aistudio/work/train/output/ResNet50_vd_ssld’,
#resume_checkpoint=‘/home/aistudio/work/train/output/ResNet50_vd_ssld/best_model’,
)
In [15]
import paddlex as pdx
from paddlex import transforms as T
import os
from PIL import Image, ImageDraw, ImageFont
import matplotlib.pyplot as plt
model = pdx.load_model(“/home/aistudio/work/train/output/ResNet50_vd_ssld/best_model”) # 加载训练好的模型
data_dir = “/home/aistudio/work/train/ImageNet_dataset”
定义训练和验证时的transforms
API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/transforms/transforms.md
test_transforms = T.Compose([
T.ResizeByShort(short_size=256), T.CenterCrop(crop_size=224), T.Normalize()
])
定义训练和验证所用的数据集
API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/datasets.md
test_dataset = pdx.datasets.ImageNet(
data_dir=data_dir,
file_list=os.path.join(data_dir, “test_list.txt”),
label_list=os.path.join(data_dir, “labels.txt”),
transforms=test_transforms,
shuffle=True)
print(model.evaluate(test_dataset))
2022-06-14 14:46:35 [INFO] Model[ResNet50_vd_ssld] loaded.
2022-06-14 14:46:35 [INFO] Starting to read file list from dataset…
2022-06-14 14:46:35 [INFO] 256 samples in file /home/aistudio/work/train/ImageNet_dataset/test_list.txt
2022-06-14 14:46:36 [INFO] Start to evaluate(total_samples=256, total_steps=256)…
OrderedDict([(‘acc1’, 0.828125), (‘acc5’, 0.99609375)])
In [ ]
!unzip /home/aistudio/data/data132154/test_dataset.zip -d /home/aistudio/work/test
In [ ]
import paddlex as pdx
from paddlex import transforms as T
import os
from PIL import Image, ImageDraw, ImageFont
import matplotlib.pyplot as plt
model = pdx.load_model(“/home/aistudio/work/train/output/ResNet50_vd_ssld/best_model”) # 加载训练好的模型
pathDir = os.listdir(r"/home/aistudio/work/test/test_images")
count = 0
for path in pathDir:
count = count+1
image_name = os.path.join(r"/home/aistudio/work/test/test_images", path)
print(image_name)
result = model.predict(image_name)
img = Image.open(image_name)
draw = ImageDraw.Draw(img)
font_size = img.size[0] // 10
draw.text((10, 10), result[0][“category”], “red”)
img.save(os.path.join(r"/home/aistudio/work/predict",path))
print(image_name, result)
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)