
【AI达人特训营】基于全卷积神经网络的图像分类复现
ResNet50-FCN论文地址:https://arxiv.org/abs/1411.4038FCN:Fully Convolutional Networks全卷积模型:本项目将CNN模式后面的全连接层换成卷积层,所以整个网络都是卷积层。其最后输出的是一张已经标记好的热图,而不是一个概率值。 通常的CNN网络中,在最后都会有几层全连接网络来融合特征信息,然后再对融合后的特征信息进行softmax
ResNet50-FCN
论文地址:https://arxiv.org/abs/1411.4038
FCN:Fully Convolutional Networks
全卷积模型:本项目将CNN模式后面的全连接层换成卷积层,所以整个网络都是卷积层。其最后输出的是一张已经标记好的热图,而不是一个概率值。 通常的CNN网络中,在最后都会有几层全连接网络来融合特征信息,然后再对融合后的特征信息进行softmax分类,如下图所示: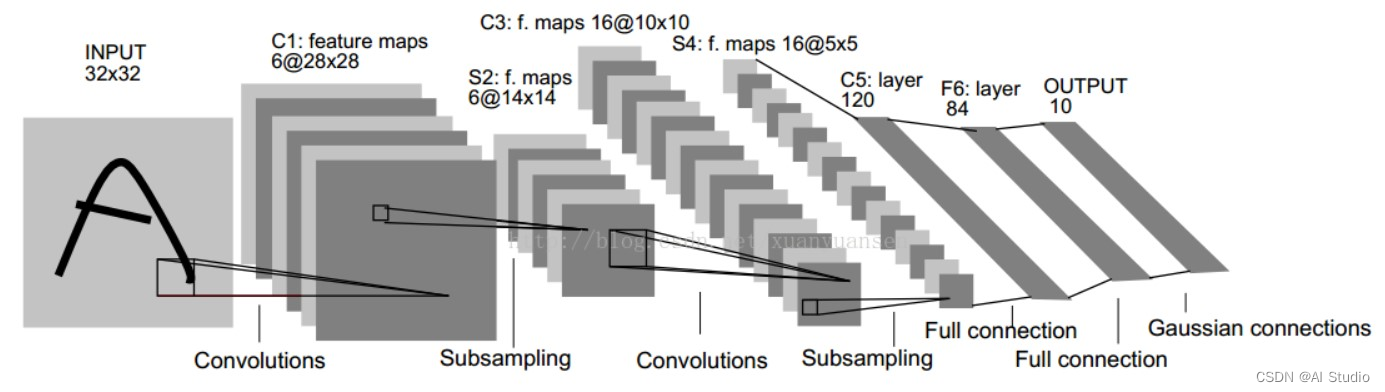
假设最后一层的feature_map的大小是7x7x512,那么全连接层做的事就是用4096个7x7x512的滤波器去卷积这个最后的feature_map。所以可想而知这个参数量是很大的!!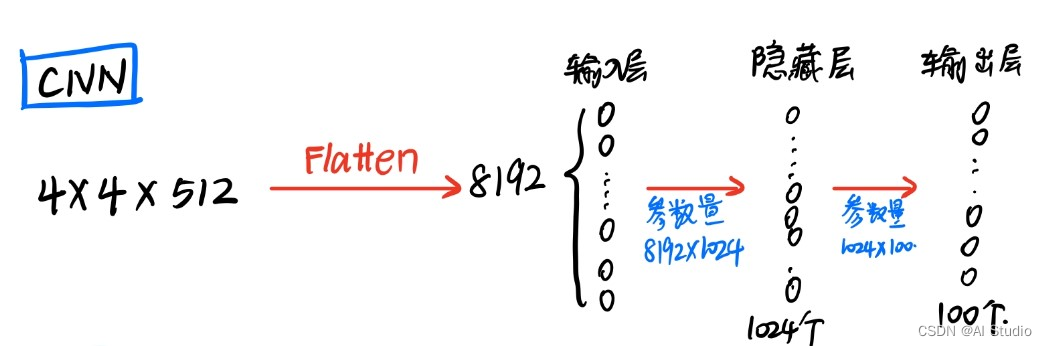
但是全卷积网络就简单多了。FCN的做法是将最后的全连接层替换为4096个1x1x512的卷积核,所以最后得出来的就是一个二维的图像,然后再对这个二维图像进行上采样(反卷积),然后再对最后反卷积的图像的每个像素点进行softmax分类。
我们都知道卷积层后的全连接目的是将 卷积输出的二维特征图(feature map)转化成(N×1N\times 1N×1)一维的一个向量因为传统的卷积神经网络的输出都是分类(一般都是一个概率值),也就是几个类别的概率甚至就是一个类别号,那么全连接层就是高度提纯的特征了,方便交给最后的分类器或者回归。
根据全连接的目的,我们完全可以利用卷积层代替全连接层,在输入端使用 M×MM\times MM×M 大小的卷积核将数据“扁平化处理”,在使用 1×11\times 11×1 卷积核对数据进行降维操作,最终卷积核的通道数即是我们预测数据的维度。这样在输入端不将数据进行扁平化处理,还可以使得图片保留其空间信息:

使用全卷积层的优点:
全卷积层能够兼容不同大小的尺寸输入。
与global avg pooling类似,可以大大减少网络参数量
数据集介绍:Cifar10
链接:http://www.cs.toronto.edu/~kriz/cifar.html
CIFAR-10是一个更接近普适物体的彩色图像数据集。CIFAR-10 是由Hinton 的学生Alex Krizhevsky 和Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含10 个类别的RGB彩色图片:飞机(airplane)、汽车(automobile)、鸟类(bird)、猫(cat)、鹿(deer)、狗(dog)、蛙类(frog)、马(horse)、船(ship)和卡车(truck).
每个图片的尺寸为32×3232\times 3232×32,每个类别有6000个图像,数据集中一共有50000张训练图片和10000张测试图片。
代码复现
1.引入依赖包
In [1]
from future import division
from future import print_function
import paddle
import paddle.nn as nn
from paddle.nn import functional as F
from paddle.utils.download import get_weights_path_from_url
import pickle
import numpy as np
from paddle import callbacks
from paddle.vision.transforms import (
ToTensor, RandomHorizontalFlip, RandomResizedCrop, SaturationTransform, Compose,
HueTransform, BrightnessTransform, ContrastTransform, RandomCrop, Normalize, RandomRotation, Resize
)
from paddle.vision.datasets import Cifar10
from paddle.io import DataLoader
from paddle.optimizer.lr import CosineAnnealingDecay, MultiStepDecay, LinearWarmup
import random
2.定义ResNet50-FCN网络
本代码参考Paddleclas实现,代码中将分类类别设定为100类
In [2]
all = []
model_urls = {
‘resnet18’: (‘https://paddle-hapi.bj.bcebos.com/models/resnet18.pdparams’,
‘cf548f46534aa3560945be4b95cd11c4’),
‘resnet34’: (‘https://paddle-hapi.bj.bcebos.com/models/resnet34.pdparams’,
‘8d2275cf8706028345f78ac0e1d31969’),
‘resnet50’: (‘https://paddle-hapi.bj.bcebos.com/models/resnet50.pdparams’,
‘ca6f485ee1ab0492d38f323885b0ad80’),
‘resnet101’: (‘https://paddle-hapi.bj.bcebos.com/models/resnet101.pdparams’,
‘02f35f034ca3858e1e54d4036443c92d’),
‘resnet152’: (‘https://paddle-hapi.bj.bcebos.com/models/resnet152.pdparams’,
‘7ad16a2f1e7333859ff986138630fd7a’),
}
class BottleneckBlock(nn.Layer):
expansion = 4
def __init__(self,
inplanes,
planes,
stride=1,
downsample=None,
groups=1,
base_width=64,
dilation=1,
norm_layer=None):
super(BottleneckBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2D
width = int(planes * (base_width / 64.)) * groups
self.width = width
self.conv1 = nn.Conv2D(inplanes, width, 1, bias_attr=False)
self.bn1 = norm_layer(width)
self.conv2 = nn.Conv2D(
width,
width,
3,
padding=dilation,
stride=stride,
groups=groups,
dilation=dilation,
bias_attr=False)
self.bn2 = norm_layer(width)
self.conv3 = nn.Conv2D(
width, planes * self.expansion, 1, bias_attr=False)
self.width_2 = planes * self.expansion
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU()
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Layer):
“”"ResNet model from"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>_
Args:
Block (BasicBlock|BottleneckBlock): block module of model.
depth (int): layers of resnet, default: 50.
num_classes (int): output dim of last fc layer. If num_classes <=0, last fc layer
will not be defined. Default: 1000.
with_pool (bool): use pool before the last fc layer or not. Default: True.
Examples:
.. code-block:: python
from paddle.vision.models import ResNet
from paddle.vision.models.resnet import BottleneckBlock, BasicBlock
resnet50 = ResNet(BottleneckBlock, 50)
resnet18 = ResNet(BasicBlock, 18)
"""
def __init__(self, block, depth, num_classes=10, with_pool=False):
super(ResNet, self).__init__()
layer_cfg = {
18: [2, 2, 2, 2],
34: [3, 4, 6, 3],
50: [3, 4, 6, 3],
101: [3, 4, 23, 3],
152: [3, 8, 36, 3]
}
layers = layer_cfg[depth]
self.num_classes = num_classes
self.with_pool = with_pool
self._norm_layer = nn.BatchNorm2D
self.inplanes = 64
self.dilation = 1
self.conv1 = nn.Conv2D(
3,
self.inplanes,
kernel_size=7,
stride=2,
padding=3,
bias_attr=False)
self.bn1 = self._norm_layer(self.inplanes)
self.relu = nn.ReLU()
# self.maxpool = nn.MaxPool2D(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
if with_pool:
self.avgpool = nn.AdaptiveAvgPool2D((1, 1))
if num_classes > 0:
self.fc = nn.Linear(512 * block.expansion, num_classes)
self.final_conv = nn.Conv2D(512 * block.expansion, 1024, 2)
self.final_conv2 = nn.Conv2D(1024, 10, 1)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2D(
self.inplanes,
planes * block.expansion,
1,
stride=stride,
bias_attr=False),
norm_layer(planes * block.expansion), )
layers = []
layers.append(
block(self.inplanes, planes, stride, downsample, 1, 64,
previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, norm_layer=norm_layer))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
# x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
###
# 更改为全卷积层
###
# if self.with_pool:
# x = self.avgpool(x)
# if self.num_classes > 0:
# x = paddle.flatten(x, 1)
# x = self.fc(x)
###
# 全卷积层
###
x = self.final_conv(x)
x = self.final_conv2(x)
x = x.reshape([-1, 10], -1)
return x
def _resnet(arch, Block, depth, pretrained, **kwargs):
model = ResNet(Block, depth, **kwargs)
if pretrained:
assert arch in model_urls, “{} model do not have a pretrained model now, you should set pretrained=False”.format(
arch)
weight_path = get_weights_path_from_url(model_urls[arch][0],
model_urls[arch][1])
param = paddle.load(weight_path)
model.set_dict(param)
return model
def resnet50(pretrained=False, **kwargs):
“”"ResNet 50-layer model
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
Examples:
.. code-block:: python
from paddle.vision.models import resnet50
# build model
model = resnet50()
# build model and load imagenet pretrained weight
# model = resnet50(pretrained=True)
"""
return _resnet('resnet50', BottleneckBlock, 50, pretrained, **kwargs)
In [3]
net = resnet50()
paddle.summary(net, (1,3,32,32))
W0616 14:52:04.385969 2132 gpu_context.cc:278] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0616 14:52:04.390283 2132 gpu_context.cc:306] device: 0, cuDNN Version: 7.6.
Layer (type) Input Shape Output Shape Param #
Conv2D-1 [[1, 3, 32, 32]] [1, 64, 16, 16] 9,408
BatchNorm2D-1 [[1, 64, 16, 16]] [1, 64, 16, 16] 256
ReLU-1 [[1, 64, 16, 16]] [1, 64, 16, 16] 0
Conv2D-3 [[1, 64, 16, 16]] [1, 64, 16, 16] 4,096
BatchNorm2D-3 [[1, 64, 16, 16]] [1, 64, 16, 16] 256
ReLU-2 [[1, 256, 16, 16]] [1, 256, 16, 16] 0
Conv2D-4 [[1, 64, 16, 16]] [1, 64, 16, 16] 36,864
BatchNorm2D-4 [[1, 64, 16, 16]] [1, 64, 16, 16] 256
Conv2D-5 [[1, 64, 16, 16]] [1, 256, 16, 16] 16,384
BatchNorm2D-5 [[1, 256, 16, 16]] [1, 256, 16, 16] 1,024
Conv2D-2 [[1, 64, 16, 16]] [1, 256, 16, 16] 16,384
BatchNorm2D-2 [[1, 256, 16, 16]] [1, 256, 16, 16] 1,024
BottleneckBlock-1 [[1, 64, 16, 16]] [1, 256, 16, 16] 0
Conv2D-6 [[1, 256, 16, 16]] [1, 64, 16, 16] 16,384
BatchNorm2D-6 [[1, 64, 16, 16]] [1, 64, 16, 16] 256
ReLU-3 [[1, 256, 16, 16]] [1, 256, 16, 16] 0
Conv2D-7 [[1, 64, 16, 16]] [1, 64, 16, 16] 36,864
BatchNorm2D-7 [[1, 64, 16, 16]] [1, 64, 16, 16] 256
Conv2D-8 [[1, 64, 16, 16]] [1, 256, 16, 16] 16,384
BatchNorm2D-8 [[1, 256, 16, 16]] [1, 256, 16, 16] 1,024
BottleneckBlock-2 [[1, 256, 16, 16]] [1, 256, 16, 16] 0
Conv2D-9 [[1, 256, 16, 16]] [1, 64, 16, 16] 16,384
BatchNorm2D-9 [[1, 64, 16, 16]] [1, 64, 16, 16] 256
ReLU-4 [[1, 256, 16, 16]] [1, 256, 16, 16] 0
Conv2D-10 [[1, 64, 16, 16]] [1, 64, 16, 16] 36,864
BatchNorm2D-10 [[1, 64, 16, 16]] [1, 64, 16, 16] 256
Conv2D-11 [[1, 64, 16, 16]] [1, 256, 16, 16] 16,384
BatchNorm2D-11 [[1, 256, 16, 16]] [1, 256, 16, 16] 1,024
BottleneckBlock-3 [[1, 256, 16, 16]] [1, 256, 16, 16] 0
Conv2D-13 [[1, 256, 16, 16]] [1, 128, 16, 16] 32,768
BatchNorm2D-13 [[1, 128, 16, 16]] [1, 128, 16, 16] 512
ReLU-5 [[1, 512, 8, 8]] [1, 512, 8, 8] 0
Conv2D-14 [[1, 128, 16, 16]] [1, 128, 8, 8] 147,456
BatchNorm2D-14 [[1, 128, 8, 8]] [1, 128, 8, 8] 512
Conv2D-15 [[1, 128, 8, 8]] [1, 512, 8, 8] 65,536
BatchNorm2D-15 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,048
Conv2D-12 [[1, 256, 16, 16]] [1, 512, 8, 8] 131,072
BatchNorm2D-12 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,048
BottleneckBlock-4 [[1, 256, 16, 16]] [1, 512, 8, 8] 0
Conv2D-16 [[1, 512, 8, 8]] [1, 128, 8, 8] 65,536
BatchNorm2D-16 [[1, 128, 8, 8]] [1, 128, 8, 8] 512
ReLU-6 [[1, 512, 8, 8]] [1, 512, 8, 8] 0
Conv2D-17 [[1, 128, 8, 8]] [1, 128, 8, 8] 147,456
BatchNorm2D-17 [[1, 128, 8, 8]] [1, 128, 8, 8] 512
Conv2D-18 [[1, 128, 8, 8]] [1, 512, 8, 8] 65,536
BatchNorm2D-18 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,048
BottleneckBlock-5 [[1, 512, 8, 8]] [1, 512, 8, 8] 0
Conv2D-19 [[1, 512, 8, 8]] [1, 128, 8, 8] 65,536
BatchNorm2D-19 [[1, 128, 8, 8]] [1, 128, 8, 8] 512
ReLU-7 [[1, 512, 8, 8]] [1, 512, 8, 8] 0
Conv2D-20 [[1, 128, 8, 8]] [1, 128, 8, 8] 147,456
BatchNorm2D-20 [[1, 128, 8, 8]] [1, 128, 8, 8] 512
Conv2D-21 [[1, 128, 8, 8]] [1, 512, 8, 8] 65,536
BatchNorm2D-21 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,048
BottleneckBlock-6 [[1, 512, 8, 8]] [1, 512, 8, 8] 0
Conv2D-22 [[1, 512, 8, 8]] [1, 128, 8, 8] 65,536
BatchNorm2D-22 [[1, 128, 8, 8]] [1, 128, 8, 8] 512
ReLU-8 [[1, 512, 8, 8]] [1, 512, 8, 8] 0
Conv2D-23 [[1, 128, 8, 8]] [1, 128, 8, 8] 147,456
BatchNorm2D-23 [[1, 128, 8, 8]] [1, 128, 8, 8] 512
Conv2D-24 [[1, 128, 8, 8]] [1, 512, 8, 8] 65,536
BatchNorm2D-24 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,048
BottleneckBlock-7 [[1, 512, 8, 8]] [1, 512, 8, 8] 0
Conv2D-26 [[1, 512, 8, 8]] [1, 256, 8, 8] 131,072
BatchNorm2D-26 [[1, 256, 8, 8]] [1, 256, 8, 8] 1,024
ReLU-9 [[1, 1024, 4, 4]] [1, 1024, 4, 4] 0
Conv2D-27 [[1, 256, 8, 8]] [1, 256, 4, 4] 589,824
BatchNorm2D-27 [[1, 256, 4, 4]] [1, 256, 4, 4] 1,024
Conv2D-28 [[1, 256, 4, 4]] [1, 1024, 4, 4] 262,144
BatchNorm2D-28 [[1, 1024, 4, 4]] [1, 1024, 4, 4] 4,096
Conv2D-25 [[1, 512, 8, 8]] [1, 1024, 4, 4] 524,288
BatchNorm2D-25 [[1, 1024, 4, 4]] [1, 1024, 4, 4] 4,096
BottleneckBlock-8 [[1, 512, 8, 8]] [1, 1024, 4, 4] 0
Conv2D-29 [[1, 1024, 4, 4]] [1, 256, 4, 4] 262,144
BatchNorm2D-29 [[1, 256, 4, 4]] [1, 256, 4, 4] 1,024
ReLU-10 [[1, 1024, 4, 4]] [1, 1024, 4, 4] 0
Conv2D-30 [[1, 256, 4, 4]] [1, 256, 4, 4] 589,824
BatchNorm2D-30 [[1, 256, 4, 4]] [1, 256, 4, 4] 1,024
Conv2D-31 [[1, 256, 4, 4]] [1, 1024, 4, 4] 262,144
BatchNorm2D-31 [[1, 1024, 4, 4]] [1, 1024, 4, 4] 4,096
BottleneckBlock-9 [[1, 1024, 4, 4]] [1, 1024, 4, 4] 0
Conv2D-32 [[1, 1024, 4, 4]] [1, 256, 4, 4] 262,144
BatchNorm2D-32 [[1, 256, 4, 4]] [1, 256, 4, 4] 1,024
ReLU-11 [[1, 1024, 4, 4]] [1, 1024, 4, 4] 0
Conv2D-33 [[1, 256, 4, 4]] [1, 256, 4, 4] 589,824
BatchNorm2D-33 [[1, 256, 4, 4]] [1, 256, 4, 4] 1,024
Conv2D-34 [[1, 256, 4, 4]] [1, 1024, 4, 4] 262,144
BatchNorm2D-34 [[1, 1024, 4, 4]] [1, 1024, 4, 4] 4,096
BottleneckBlock-10 [[1, 1024, 4, 4]] [1, 1024, 4, 4] 0
Conv2D-35 [[1, 1024, 4, 4]] [1, 256, 4, 4] 262,144
BatchNorm2D-35 [[1, 256, 4, 4]] [1, 256, 4, 4] 1,024
ReLU-12 [[1, 1024, 4, 4]] [1, 1024, 4, 4] 0
Conv2D-36 [[1, 256, 4, 4]] [1, 256, 4, 4] 589,824
BatchNorm2D-36 [[1, 256, 4, 4]] [1, 256, 4, 4] 1,024
Conv2D-37 [[1, 256, 4, 4]] [1, 1024, 4, 4] 262,144
BatchNorm2D-37 [[1, 1024, 4, 4]] [1, 1024, 4, 4] 4,096
BottleneckBlock-11 [[1, 1024, 4, 4]] [1, 1024, 4, 4] 0
Conv2D-38 [[1, 1024, 4, 4]] [1, 256, 4, 4] 262,144
BatchNorm2D-38 [[1, 256, 4, 4]] [1, 256, 4, 4] 1,024
ReLU-13 [[1, 1024, 4, 4]] [1, 1024, 4, 4] 0
Conv2D-39 [[1, 256, 4, 4]] [1, 256, 4, 4] 589,824
BatchNorm2D-39 [[1, 256, 4, 4]] [1, 256, 4, 4] 1,024
Conv2D-40 [[1, 256, 4, 4]] [1, 1024, 4, 4] 262,144
BatchNorm2D-40 [[1, 1024, 4, 4]] [1, 1024, 4, 4] 4,096
BottleneckBlock-12 [[1, 1024, 4, 4]] [1, 1024, 4, 4] 0
Conv2D-41 [[1, 1024, 4, 4]] [1, 256, 4, 4] 262,144
BatchNorm2D-41 [[1, 256, 4, 4]] [1, 256, 4, 4] 1,024
ReLU-14 [[1, 1024, 4, 4]] [1, 1024, 4, 4] 0
Conv2D-42 [[1, 256, 4, 4]] [1, 256, 4, 4] 589,824
BatchNorm2D-42 [[1, 256, 4, 4]] [1, 256, 4, 4] 1,024
Conv2D-43 [[1, 256, 4, 4]] [1, 1024, 4, 4] 262,144
BatchNorm2D-43 [[1, 1024, 4, 4]] [1, 1024, 4, 4] 4,096
BottleneckBlock-13 [[1, 1024, 4, 4]] [1, 1024, 4, 4] 0
Conv2D-45 [[1, 1024, 4, 4]] [1, 512, 4, 4] 524,288
BatchNorm2D-45 [[1, 512, 4, 4]] [1, 512, 4, 4] 2,048
ReLU-15 [[1, 2048, 2, 2]] [1, 2048, 2, 2] 0
Conv2D-46 [[1, 512, 4, 4]] [1, 512, 2, 2] 2,359,296
BatchNorm2D-46 [[1, 512, 2, 2]] [1, 512, 2, 2] 2,048
Conv2D-47 [[1, 512, 2, 2]] [1, 2048, 2, 2] 1,048,576
BatchNorm2D-47 [[1, 2048, 2, 2]] [1, 2048, 2, 2] 8,192
Conv2D-44 [[1, 1024, 4, 4]] [1, 2048, 2, 2] 2,097,152
BatchNorm2D-44 [[1, 2048, 2, 2]] [1, 2048, 2, 2] 8,192
BottleneckBlock-14 [[1, 1024, 4, 4]] [1, 2048, 2, 2] 0
Conv2D-48 [[1, 2048, 2, 2]] [1, 512, 2, 2] 1,048,576
BatchNorm2D-48 [[1, 512, 2, 2]] [1, 512, 2, 2] 2,048
ReLU-16 [[1, 2048, 2, 2]] [1, 2048, 2, 2] 0
Conv2D-49 [[1, 512, 2, 2]] [1, 512, 2, 2] 2,359,296
BatchNorm2D-49 [[1, 512, 2, 2]] [1, 512, 2, 2] 2,048
Conv2D-50 [[1, 512, 2, 2]] [1, 2048, 2, 2] 1,048,576
BatchNorm2D-50 [[1, 2048, 2, 2]] [1, 2048, 2, 2] 8,192
BottleneckBlock-15 [[1, 2048, 2, 2]] [1, 2048, 2, 2] 0
Conv2D-51 [[1, 2048, 2, 2]] [1, 512, 2, 2] 1,048,576
BatchNorm2D-51 [[1, 512, 2, 2]] [1, 512, 2, 2] 2,048
ReLU-17 [[1, 2048, 2, 2]] [1, 2048, 2, 2] 0
Conv2D-52 [[1, 512, 2, 2]] [1, 512, 2, 2] 2,359,296
BatchNorm2D-52 [[1, 512, 2, 2]] [1, 512, 2, 2] 2,048
Conv2D-53 [[1, 512, 2, 2]] [1, 2048, 2, 2] 1,048,576
BatchNorm2D-53 [[1, 2048, 2, 2]] [1, 2048, 2, 2] 8,192
BottleneckBlock-16 [[1, 2048, 2, 2]] [1, 2048, 2, 2] 0
Conv2D-54 [[1, 2048, 2, 2]] [1, 1024, 1, 1] 8,389,632
Conv2D-55 [[1, 1024, 1, 1]] [1, 10, 1, 1] 10,250
Total params: 31,961,034
Trainable params: 31,854,794
Non-trainable params: 106,240
Input size (MB): 0.01
Forward/backward pass size (MB): 20.10
Params size (MB): 121.92
Estimated Total Size (MB): 142.04
{‘total_params’: 31961034, ‘trainable_params’: 31854794}
3.自定义数据集处理方式
In [4]
class ToArray(object):
def call(self, img):
img = np.array(img)
img = np.transpose(img, [2, 0, 1])
img = img / 255.
return img.astype(‘float32’)
class RandomApply(object):
def init(self, transform, p=0.5):
super().init()
self.p = p
self.transform = transform
def __call__(self, img):
if self.p < random.random():
return img
img = self.transform(img)
return img
class LRSchedulerM(callbacks.LRScheduler):
def init(self, by_step=False, by_epoch=True, warm_up=True):
super().init(by_step, by_epoch)
assert by_step ^ warm_up
self.warm_up = warm_up
def on_epoch_end(self, epoch, logs=None):
if self.by_epoch and not self.warm_up:
if self.model._optimizer and hasattr(
self.model._optimizer, '_learning_rate') and isinstance(
self.model._optimizer._learning_rate, paddle.optimizer.lr.LRScheduler):
self.model._optimizer._learning_rate.step()
def on_train_batch_end(self, step, logs=None):
if self.by_step or self.warm_up:
if self.model._optimizer and hasattr(
self.model._optimizer, '_learning_rate') and isinstance(
self.model._optimizer._learning_rate, paddle.optimizer.lr.LRScheduler):
self.model._optimizer._learning_rate.step()
if self.model._optimizer._learning_rate.last_epoch >= self.model._optimizer._learning_rate.warmup_steps:
self.warm_up = False
def _on_train_batch_end(self, step, logs=None):
logs = logs or {}
logs[‘lr’] = self.model._optimizer.get_lr()
self.train_step += 1
if self._is_write():
self._updates(logs, ‘train’)
def _on_train_begin(self, logs=None):
self.epochs = self.params[‘epochs’]
assert self.epochs
self.train_metrics = self.params[‘metrics’] + [‘lr’]
assert self.train_metrics
self._is_fit = True
self.train_step = 0
callbacks.VisualDL.on_train_batch_end = _on_train_batch_end
callbacks.VisualDL.on_train_begin = _on_train_begin
4.在Cifar10数据集上训练模型
使用Paddle自带的Cifar10数据集API加载
In [ ]
model = paddle.Model(resnet50())
加载checkpoint
model.load(‘output/ResNet50-FCN/299.pdparams’)
MAX_EPOCH = 300
LR = 0.01
WEIGHT_DECAY = 5e-4
MOMENTUM = 0.9
BATCH_SIZE = 256
CIFAR_MEAN = [0.5071, 0.4865, 0.4409]
CIFAR_STD = [0.1942, 0.1918, 0.1958]
DATA_FILE = None
model.prepare(
paddle.optimizer.Momentum(
learning_rate=LinearWarmup(CosineAnnealingDecay(LR, MAX_EPOCH), 2000, 0., LR),
momentum=MOMENTUM,
parameters=model.parameters(),
weight_decay=WEIGHT_DECAY),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy(topk=(1,5)))
定义数据集增强方式
transforms = Compose([
RandomCrop(32, padding=4),
RandomApply(BrightnessTransform(0.1)),
RandomApply(ContrastTransform(0.1)),
RandomHorizontalFlip(),
RandomRotation(15),
ToArray(),
Normalize(CIFAR_MEAN, CIFAR_STD),
# Resize(size=224)
])
val_transforms = Compose([ToArray(), Normalize(CIFAR_MEAN, CIFAR_STD)])
加载训练和测试数据集
train_set = Cifar10(DATA_FILE, mode=‘train’, transform=transforms)
test_set = Cifar10(DATA_FILE, mode=‘test’, transform=val_transforms)
定义保存方式和训练可视化
checkpoint_callback = paddle.callbacks.ModelCheckpoint(save_freq=1, save_dir=‘output/ResNet50-FCN’)
callbacks = [LRSchedulerM(),checkpoint_callback, callbacks.VisualDL(‘vis_logs/resnet50_FCN.log’)]
训练模型
model.fit(
train_set,
test_set,
epochs=MAX_EPOCH,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4,
verbose=1,
callbacks=callbacks,
)
对照实验:原始ResNet50
In [ ]
model = paddle.Model(paddle.vision.models.resnet50(pretrained=False))
加载checkpoint
model.load(‘output/ResNet50/299.pdparams’)
MAX_EPOCH = 300
LR = 0.01
WEIGHT_DECAY = 5e-4
MOMENTUM = 0.9
BATCH_SIZE = 256
CIFAR_MEAN = [0.5071, 0.4865, 0.4409]
CIFAR_STD = [0.1942, 0.1918, 0.1958]
DATA_FILE = None
model.prepare(
paddle.optimizer.Momentum(
learning_rate=LinearWarmup(CosineAnnealingDecay(LR, MAX_EPOCH), 2000, 0., LR),
momentum=MOMENTUM,
parameters=model.parameters(),
weight_decay=WEIGHT_DECAY),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy(topk=(1,5)))
定义数据集增强方式
transforms = Compose([
RandomCrop(32, padding=4),
RandomApply(BrightnessTransform(0.1)),
RandomApply(ContrastTransform(0.1)),
RandomHorizontalFlip(),
RandomRotation(15),
ToArray(),
Normalize(CIFAR_MEAN, CIFAR_STD),
])
val_transforms = Compose([ToArray(), Normalize(CIFAR_MEAN, CIFAR_STD)])
加载训练和测试数据集
train_set = Cifar100(DATA_FILE, mode=‘train’, transform=transforms)
test_set = Cifar100(DATA_FILE, mode=‘test’, transform=val_transforms)
定义保存方式和训练可视化
checkpoint_callback = paddle.callbacks.ModelCheckpoint(save_freq=1, save_dir=‘output/ResNet50’)
callbacks = [LRSchedulerM(),checkpoint_callback, callbacks.VisualDL(‘vis_logs/resnet50.log’)]
训练模型
model.fit(
train_set,
test_set,
epochs=MAX_EPOCH,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4,
verbose=1,
callbacks=callbacks,
)
实验结果
两次实验均使用相同的参数:
epoch = 100
lr = 0.01
weight_decay = 5e-4
momentum = 0.9
pretrained = False
ResNet50-FCN模型的Top-1 acc和Top-5 acc如下图所示: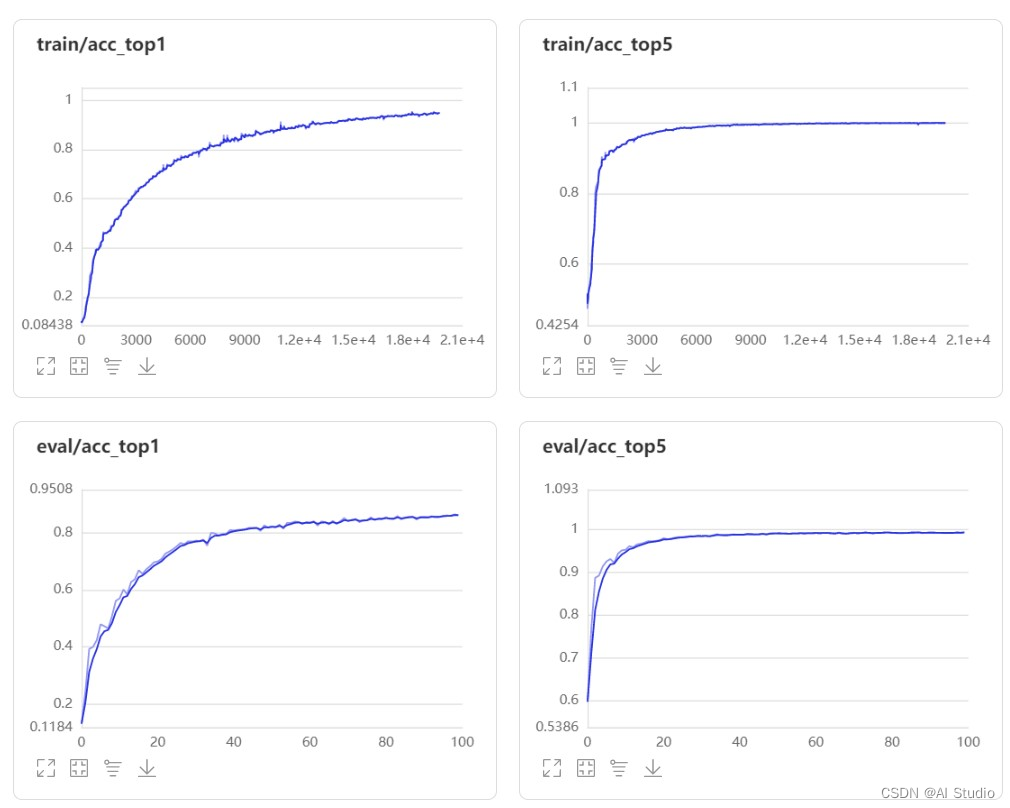
ResNet50模型的Top-1 acc和Top-5 acc如下图所示: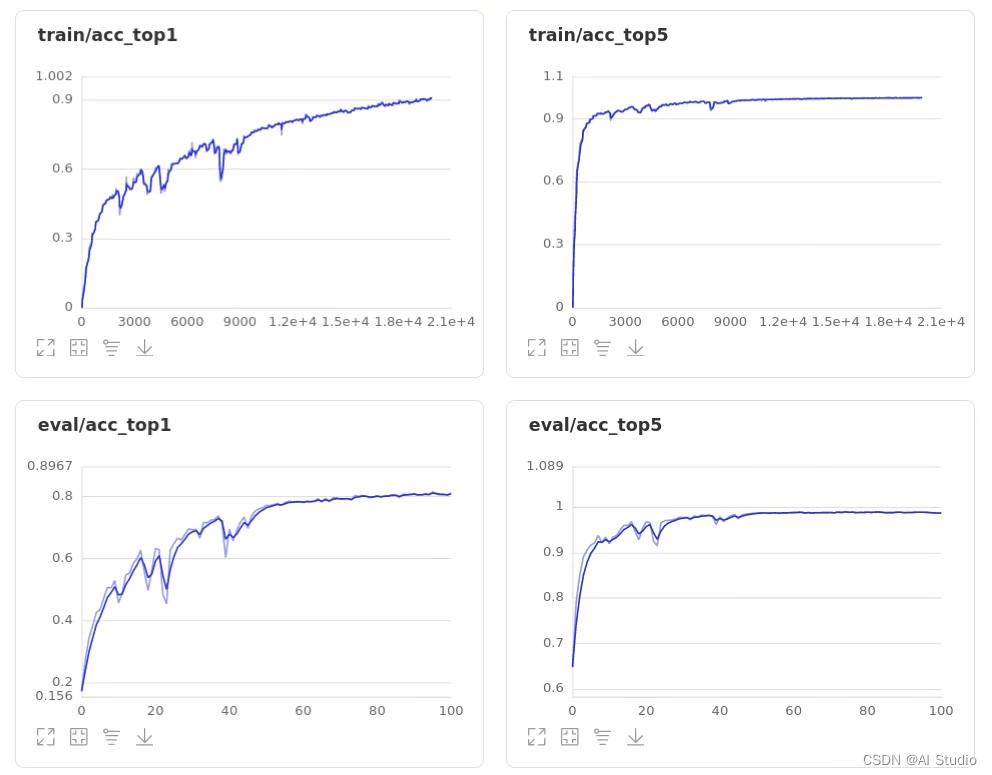
通过比较,经过修改后的模型效果得到了提升,且准确率上升过程更加平滑,抖动较小。
总结
本次复现任务将ResNet50的全连接部分替换为了卷积层,实现了整个网络的全卷积。本项目为百度AI达人项目的一个课题,通过对原论文的理解,设计全卷积层,并使用PaddlePaddle框架实现,特别感谢百度李老师的指导!
由于Cifar10数据集中图片为32×3232\times 3232×32大小,ResNet50网络对于小图片而言网络结构可能偏大,后期可以采用ResNet18等更小的网络进行训练。通过与原始ResNet50模型训练结果的对比,也可以看出全卷积网络在分类领域能够在参数量减少的优势下增加分类准确率。

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)