
新《小兔子乖乖》—基于Inception系列模型对狼和兔子进行图像分类
用通俗易懂的故事,使深度学习不枯燥引起学习兴趣。
新《小兔子乖乖》
基于Inception系列模型对狼和兔子进行图像分类,用通俗易懂的故事,使深度学习不枯燥引起学习兴趣。
一、项目背景:
“首先《小兔乖乖》是传统的民间故事,讲述了一只大灰狼企图模仿兔妈妈进入兔子们的家,兔子们机智地与之斗智斗勇的故事。”本项目通过对家喻户晓的儿歌《小兔子乖乖》为媒介,介绍图像识别与分类技术,用通俗易懂的故事,使深度学习不枯燥引起低年龄阶段的小朋友的学习兴趣。
下面附上项目内容简化视频:
视频作者:青岛农业大学-王慧敏、刘慧玲、闫桐辉;指导教师:宋彩霞
二、数据集简介
2.1数据集收集
本实验采用的数据集由青岛农业大学X-AI实验室网上爬虫收集
2.2数据清洗、标注数据集
本项目爬取的数据中存在许多干扰图片,如图像主体不是兔子
或者**“狗假狼威(混入了好多二哈)”的图片
还有一些不清晰**的图片、重复度高的图片,将上述影响训练模型准确度结果的图片删除。
2.3 解压并查看数据集
!ls /home/aistudio/data
import os
import zipfile
os.chdir('/home/aistudio/data/data119307')
extracting = zipfile.ZipFile('Wolf-and-Rabbit-V2.0.zip')
extracting.extractall()
data119307
2.4对数据集生成固定格式的列表
格式为:图片的路径 图片类别的标签;划分训练集和测试集,各个类别中每隔十张选取一张作为测试集,并将数据集生成固定格式列表。
import json
import os
def create_data_list(data_root_path):
with open(data_root_path + "test.list", 'w') as f:
pass
with open(data_root_path + "train.list", 'w') as f:
pass
# 所有类别的信息
class_detail = []
# 获取所有类别
class_dirs = os.listdir(data_root_path)
# 类别标签
class_label = 0
# 获取总类别的名称
father_paths = data_root_path.split('/')
while True:
if father_paths[len(father_paths) - 1] == '':
del father_paths[len(father_paths) - 1]
else:
break
father_path = father_paths[len(father_paths) - 1]
all_class_images = 0
other_file = 0
# 读取每个类别
for class_dir in class_dirs:
if class_dir == 'test.list' or class_dir == "train.list" or class_dir == 'readme.json':
other_file += 1
continue
print('正在读取类别:%s' % class_dir)
# 每个类别的信息
class_detail_list = {}
test_sum = 0
trainer_sum = 0
# 统计每个类别有多少张图片
class_sum = 0
# 获取类别路径
path = data_root_path + "/" + class_dir
# 获取所有图片
img_paths = os.listdir(path)
for img_path in img_paths:
# 每张图片的路径
name_path = class_dir + '/' + img_path
# 如果不存在这个文件夹,就创建
if not os.path.exists(data_root_path):
os.makedirs(data_root_path)
# 划分训练集和测试集,各个类别中每隔十张选取一张作为测试集,并将数据集生成固定格式列表。
if class_sum % 10 == 0:
test_sum += 1
with open(data_root_path + "test.list", 'a') as f:
f.write(name_path + "\t%d" % class_label + "\n")
else:
trainer_sum += 1
with open(data_root_path + "train.list", 'a') as f:
f.write(name_path + "\t%d" % class_label + "\n")
class_sum += 1
all_class_images += 1
# 说明的json文件的class_detail数据
class_detail_list['class_name'] = class_dir
class_detail_list['class_label'] = class_label
class_detail_list['class_test_images'] = test_sum
class_detail_list['class_trainer_images'] = trainer_sum
class_detail.append(class_detail_list)
class_label += 1
# 获取类别数量
all_class_sum = len(class_dirs) - other_file
# 说明的json文件信息
readjson = {}
readjson['all_class_name'] = father_path
readjson['all_class_sum'] = all_class_sum
readjson['all_class_images'] = all_class_images
readjson['class_detail'] = class_detail
jsons = json.dumps(readjson, sort_keys=True, indent=4, separators=(',', ': '))
with open(data_root_path + "readme.json", 'w') as f:
f.write(jsons)
print('图像列表已生成')
2.5生成图像的列表
if __name__ == '__main__':
# 把生产的数据列表都放在自己的总类别文件夹中
data_root_path = "Wolf-and-Rabbit/"
create_data_list(data_root_path)
正在读取类别:Rabbit
正在读取类别:Wolf
图像列表已生成
2.6训练图片的预处理
采集完数据后我们进行数据的预处理操作, 训练图片的预处理可以提高模型的泛化能力和识别能力,有些照片可能因为拍摄角度不同,或者这个光照的影响,如果不进行一个预处理的操作的话可能模型就不认识了。
在不改变图像类别的情况下,增加数据量,能提高模型的泛化能力。
数据增广的方式有很多,从几何角度来看,常用的有:水平翻转, 位移,裁剪,旋转等!从像素变换来看,常用的有:颜色抖动,增加噪声,例如高斯噪声等。
对图像进行归一化,范围为[0, 1],归一化就是将原始数据归一到相同尺度,通常有两种方法来实现归一化:
1、原始数据除以数据绝对值的最大值,以保证所有的数据归一化后都在0到1之间;
2、原始数据零均值后,再将每一维的数据除以每一维数据的标准差。
我们来看归一化后的数据效果:


分布直方图如下
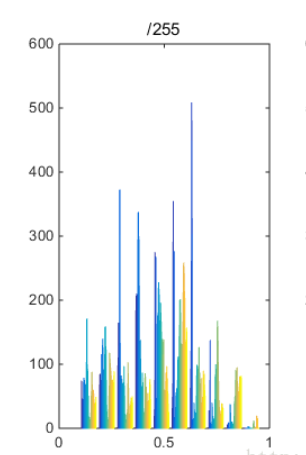
我们输出它的数组看一下吧,此时的数据分布较为均匀,想要具体了解可用ln[18]进行测试!

import random
from PIL import Image
def train_mapper(sample):
img_path, label, crop_size, resize_size = sample
img = Image.open(img_path)
# 统一图片大小
img = img.resize((resize_size, resize_size), Image.ANTIALIAS)
# 随机水平翻转
r1 = random.random()
if r1 > 0.5:
img = img.transpose(Image.FLIP_LEFT_RIGHT)
# 随机垂直翻转
r2 = random.random()
if r2 > 0.5:
img = img.transpose(Image.FLIP_TOP_BOTTOM)
# 随机角度翻转
r3 = random.randint(-3, 3)
img = img.rotate(r3, expand=False)
# 随机裁剪
r4 = random.randint(0, int(resize_size - crop_size))
r5 = random.randint(0, int(resize_size - crop_size))
box = (r4, r5, r4 + crop_size, r5 + crop_size)
img = img.crop(box)
# 把图片转换成numpy值
img = np.array(img).astype(np.float32)
# 转换成CHW
img = img.transpose((2, 0, 1))
# 转换成BGR
img = img[(2, 1, 0), :, :] / 255.0
return img, int(label)
# 获取训练的reader
def train_r(train_list_path, crop_size, resize_size):
father_path = os.path.dirname(train_list_path)
def reader():
with open(train_list_path, 'r') as f:
lines = f.readlines()
# 打乱图像列表
np.random.shuffle(lines)
# 开始获取每张图像和标签
for line in lines:
img, label = line.split('\t')
img = os.path.join(father_path, img)
yield img, label, crop_size, resize_size
return paddle.reader.xmap_readers(train_mapper, reader, cpu_count(), 102400)
# 测试图片的预处理
def test_mapper(sample):
img, label, crop_size = sample
img = Image.open(img)
# 统一图像大小
img = img.resize((crop_size, crop_size), Image.ANTIALIAS)
# 转换成numpy值
img = np.array(img).astype(np.float32)
# 转换成CHW
img = img.transpose((2, 0, 1))
# 转换成BGR
img = img[(2, 1, 0), :, :] / 255.0
return img, int(label)
# 测试的图片reader
def test_r(test_list_path, crop_size):
father_path = os.path.dirname(test_list_path)
def reader():
with open(test_list_path, 'r') as f:
lines = f.readlines()
for line in lines:
img, label = line.split('\t')
img = os.path.join(father_path, img)
yield img, label, crop_size
return paddle.reader.xmap_readers(test_mapper, reader, cpu_count(), 1024)
import cv2
from PIL import Image
import random
# data = cv2.imread("/home/aistudio/data/data119307/Wolf-and-Rabbit/Wolf/Wolf (1001).jpg")
img = Image.open("/home/aistudio/data/data119307/Wolf-and-Rabbit/Wolf/Wolf (1001).jpg")
print(img)
# 统一图片大小
img = img.resize((resize_size, resize_size), Image.ANTIALIAS)
# 随机水平翻转
r1 = random.random()
if r1 > 0.5:
img = img.transpose(Image.FLIP_LEFT_RIGHT)
# 随机垂直翻转
r2 = random.random()
if r2 > 0.5:
img = img.transpose(Image.FLIP_TOP_BOTTOM)
# 随机角度翻转
r3 = random.randint(-3, 3)
img = img.rotate(r3, expand=False)
# 随机裁剪
r4 = random.randint(0, int(resize_size - crop_size))
r5 = random.randint(0, int(resize_size - crop_size))
box = (r4, r5, r4 + crop_size, r5 + crop_size)
img = img.crop(box)
# 把图片转换成numpy值
img = np.array(img).astype(np.float32)
# 转换成CHW
img = img.transpose((2, 0, 1))
# 转换成BGR
img = img[(2, 1, 0), :, :] / 255.0
print(img)
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=612x408 at 0x7F8F17697510>
[[[0.9098039 0.9098039 0.9098039 ... 0.88235295 0.8862745 0.8980392 ]
[0.9098039 0.9098039 0.9098039 ... 0.8784314 0.8745098 0.8901961 ]
[0.90588236 0.90588236 0.9098039 ... 0.87058824 0.8666667 0.88235295]
...
[0.9137255 0.91764706 0.91764706 ... 0.9098039 0.9098039 0.9098039 ]
[0.9137255 0.92156863 0.92156863 ... 0.9098039 0.9098039 0.91764706]
[0.9137255 0.91764706 0.91764706 ... 0.9098039 0.9137255 0.92156863]]
[[0.8627451 0.8627451 0.8627451 ... 0.8235294 0.827451 0.8392157 ]
[0.8627451 0.8627451 0.8627451 ... 0.81960785 0.8235294 0.8352941 ]
[0.85882354 0.85882354 0.8627451 ... 0.8156863 0.8156863 0.83137256]
...
[0.8509804 0.8509804 0.8509804 ... 0.85490197 0.85490197 0.8509804 ]
[0.8509804 0.8509804 0.8509804 ... 0.85882354 0.85882354 0.85882354]
[0.85490197 0.85490197 0.85490197 ... 0.85882354 0.8627451 0.8627451 ]]
[[0.84705883 0.84705883 0.84705883 ... 0.8117647 0.8235294 0.83137256]
[0.84705883 0.84705883 0.84705883 ... 0.80784315 0.8156863 0.827451 ]
[0.84313726 0.84313726 0.84705883 ... 0.8039216 0.80784315 0.8235294 ]
...
[0.8392157 0.827451 0.827451 ... 0.84313726 0.84705883 0.84313726]
[0.8352941 0.827451 0.827451 ... 0.8509804 0.8509804 0.8509804 ]
[0.8392157 0.83137256 0.83137256 ... 0.8509804 0.85490197 0.85490197]]]
三、确立采用的模型
神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,因此我们需要对数据都要做一个归一化预处理。
卷积网络为了提取高维特征,一般方式进行更深层卷积,但是随之带来网络变大的问题。Inception V1模块(借鉴network in network论文中mlpconv思想)提出可以使网络变宽,在保证模型质量的前提下,减少参数个数,提取高维特征。
下面先抽象说明一下Inception V1的基本思想:
Inception结构,首先通过1x1卷积来降低通道数把信息聚集一下,再进行不同尺度的特征提取以及池化,得到多个尺度的信息,最后将特征进行叠加输出(官方说法:可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能)。
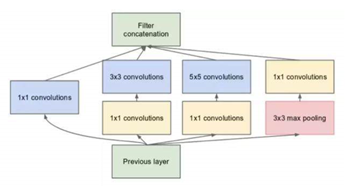
主要过程:
1.相应的在3x3卷积和5x5卷积前面、3x3池化后面添加1x1卷积,将信息聚集且可以有效减少参数量(称为瓶颈层);
2.下一层block就包含1x1卷积,3x3卷积,5x5卷积,3x3池化(使用这样的尺寸不是必需的,可以根据需要进行调整)。这样,网络中每一层都能学习到“稀疏”(3x3、5x5)或“不稀疏”(1x1)的特征,既增加了网络的宽度,也增加了网络对尺度的适应性;
3.通过按深度叠加(deep concat)在每个block后合成特征,获得非线性属性。
利用Inception V1模块叠加形成GoogLeNet网络,结构图如下:
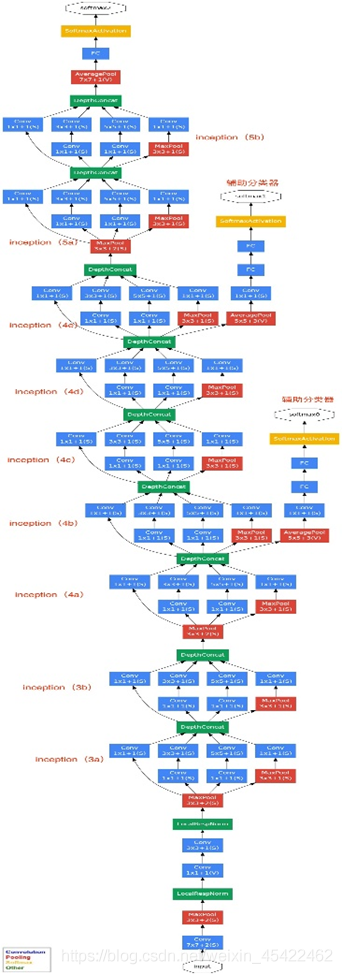
详细了解请点击:Inception系列理解
具体操作如下:
#架构模型时需要用到的组件。
#包括BN层、常规卷积层、xavier初始化方法
#以及改进后的inception结构(animals-inception)和深度可分离卷积结构
import paddle.fluid as fluid
import numpy as np
import time
import math
import paddle
import paddle.fluid as fluid
import codecs
import logging
from paddle.fluid.initializer import MSRA
from paddle.fluid.initializer import Uniform
from paddle.fluid.param_attr import ParamAttr
from PIL import Image
from PIL import ImageEnhance
import os
import random
from multiprocessing import cpu_count
import numpy as np
import paddle
from PIL import Image
#BN层
def conv_bn_layer(input, filter_size, num_filters, stride,
padding, channels=None, num_groups=1, act='relu', use_cudnn=True):
conv = fluid.layers.conv2d(input=input,
num_filters=num_filters,
filter_size=filter_size,
stride=stride,
padding=padding,
groups=num_groups,
act=None,
use_cudnn=use_cudnn,
bias_attr=False)
return fluid.layers.batch_norm(input=conv, act=act)
#常规卷积层
def conv_layer(
input,
num_filters,
filter_size,
stride=1,
groups=1,
act=None,
name=None):
channels = input.shape[1]
stdv = (3.0 / (filter_size**2 * channels))**0.5
param_attr = ParamAttr(
initializer=fluid.initializer.Uniform(-stdv, stdv),
name=name + "_weights")
conv = fluid.layers.conv2d(
input=input,
num_filters=num_filters,
filter_size=filter_size,
stride=stride,
padding=(filter_size - 1) // 2,
groups=groups,
act=act,
param_attr=param_attr,
bias_attr=False,
name=name)
return conv
def xavier(self, channels, filter_size, name):
stdv = (3.0 / (filter_size**2 * channels))**0.5
param_attr = ParamAttr(
initializer=fluid.initializer.Uniform(-stdv, stdv),
name=name + "_weights")
return param_attr
#改进后的inception结构(animals-inception)
def inception(
input,
channels,
filter1,
filter3R,
filter3,
filter5R,
filter5,
filter7R,
filter7,
proj,
name=None):
conv1 = conv_layer(
input=input,
num_filters=filter1,
filter_size=1,
stride=1,
act=None,
name="inception_" + name + "_1x1")
#由一个1*1卷积层和一个3*3卷积层组成salt-inception的支路
conv3r = conv_layer(
input=input,
num_filters=filter3R,
filter_size=1,
stride=1,
act=None,
name="inception_" + name + "_3x3_reduce")
conv3 = conv_layer(
input=conv3r,
num_filters=filter3,
filter_size=3,
stride=1,
act=None,
name="inception_" + name + "_3x3")
#由一个1*1卷积层和2个3*3卷积层组成salt-inception的支路,由2个3*3卷积层代替5*5卷积层
conv5r = conv_layer(
input=input,
num_filters=filter5R,
filter_size=1,
stride=1,
act=None,
name="inception_" + name + "_5x5_reduce")
conv5 = conv_layer(
input=conv5r,
num_filters=filter5R,
filter_size=3,
stride=1,
act=None,
name="inception_" + name + "_5x5")
conv5 = conv_layer(
input=conv5,
num_filters=filter5,
filter_size=3,
stride=1,
act=None,
name="inception_" + name + "_5x5_2")
#由一个1*1卷积层和3个3*3卷积层组成salt-inception的支路,由3个3*3卷积层代替7*7卷积层
conv7r = conv_layer(
input=input,
num_filters=filter7R,
filter_size=1,
stride=1,
act=None,
name="inception_" + name + "_7x7_reduce")
conv7 = conv_layer(
input=conv7r,
num_filters=filter7R,
filter_size=3,
stride=1,
act=None,
name="inception_" + name + "_7x7")
conv7 = conv_layer(
input=conv7,
num_filters=filter7R,
filter_size=3,
stride=1,
act=None,
name="inception_" + name + "_7x7_2")
conv7 = conv_layer(
input=conv7,
num_filters=filter7,
filter_size=3,
stride=1,
act=None,
name="inception_" + name + "_7x7_3")
pool = fluid.layers.pool2d(
input=input,
pool_size=3,
pool_stride=1,
pool_padding=1,
pool_type='max')
convprj = fluid.layers.conv2d(
input=pool,
filter_size=1,
num_filters=proj,
stride=1,
padding=0,
name="inception_" + name + "_3x3_proj",
param_attr=ParamAttr(
name="inception_" + name + "_3x3_proj_weights"),
bias_attr=False)
cat = fluid.layers.concat(input=[conv1, conv3, conv5, conv7, convprj], axis=1)
cat = fluid.layers.relu(cat)
return cat
#深度可分离卷积
def depthwise_separable(input, num_filters1, num_filters2, num_groups, stride, scale):
depthwise_conv = conv_bn_layer(input=input,
filter_size=3,
num_filters=int(num_filters1 * scale),
stride=stride,
padding=1,
num_groups=int(num_groups * scale),
use_cudnn=False)
pointwise_conv = conv_bn_layer(input=depthwise_conv,
filter_size=1,
num_filters=int(num_filters2 * scale),
stride=1,
padding=0)
return pointwise_conv
CNN图像分类网络
说一点废话:CNN网络主要特点是使用卷积层,这其实是模拟了人的视觉神经,单个神经元只能对某种特定的图像特征产生响应,比如横向或者纵向的边缘,本身是非常简单的,但是这些简单的神经元构成一层,在层数足够多后,就可以获取足够丰富的特征。从机制上讲,卷积神经网络与人的视觉神经还真是像。下面进入正题。
卷积神经网络与传统的神经网络非常类似:他们是由一系列可以被训练的神经元组成(可训练的部分为权重(weight)与偏置(bias))。每一个神经元接收一些输入,然后通过点乘和一些非线性变换(如:reLu,sigmoid函数,tanh等等)。整个网络可以模拟出一个可微分的打分函数:以原始的图像像素为输入,以各个类别的分数为输出。CNN在最后一层通常也有损失函数(loss function)(比如SVM/softmax),这点跟传统的神经网络非常像。
传统的神经网络。传统的神经网络输入一个向量,通过隐藏层对这个向量做若干次变换,最后输出结果。每一个隐藏层是由一系列的神经元构成,每一个神经元与上一层的神经元 全部链接,同一层的神经元之间不相互连接。最后一层为输出层,对于分类问题来说,输出层输出各个类别的分数。
传统神经网络对于大型图像来说并不适用。举个例子来说,在CIFAR-10的数据集中,图像的大小为32323,所以对于第一层隐藏层的一个神经元来说,它有32323=3072个参数。这个数字看起来不大,这是因为图像非常的小。如果图像的大小为2002003,那么一个神经元需要训练的参数为2002003+1=120001个。这仅仅是一个神经元,如果算上其他的神经元,需要训练的参数数量将是一个天文数字!很明显,这种全连接的形式非常费时,而且如此大量的参数会导致过拟合的问题。
神经元的3D结构:CNN利用了输入为图像的这个因素,它没有把图像拉成一个向量,而是直接拿来用。具体的说,CNN的输入有三个维度:图像的长宽高,高实际就是图像的颜色通道个数,对于灰度图像,高为1,彩色图像高为3,多光谱图像高为谱段数。比如,输入图像大小为32323,那么CNN的输入也为32323.另外CNN的输出也是一个3维的向量,比如一个10类的输出,CNN的输出就为1110.下边为一个示意图:
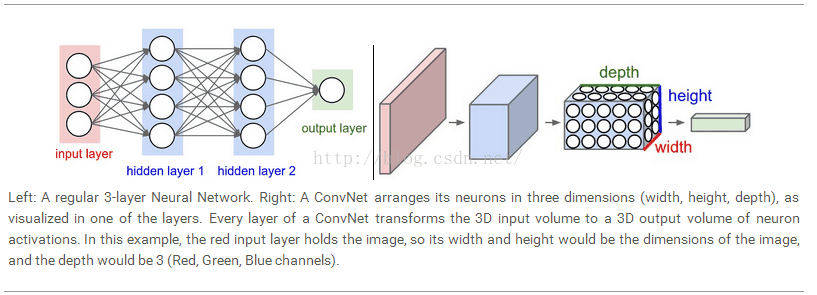
参考文献:
#定义salt-ConvNet卷积神经网络的结构
def net(input, class_dim, scale=1.0):
# 224x224
input = conv_bn_layer(input=input,
filter_size=3,
channels=3,
num_filters=int(32 * scale),
stride=2,
padding=1)
# 112x112
input = depthwise_separable(input=input,
num_filters1=32,
num_filters2=64,
num_groups=32,
stride=1,
scale=scale)
input = depthwise_separable(input=input,
num_filters1=64,
num_filters2=128,
num_groups=64,
stride=2,
scale=scale)
# 56x56
input = depthwise_separable(input=input,
num_filters1=128,
num_filters2=128,
num_groups=128,
stride=1,
scale=scale)
input = depthwise_separable(input=input,
num_filters1=128,
num_filters2=256,
num_groups=128,
stride=2,
scale=scale)
# 28x28
input = depthwise_separable(input=input,
num_filters1=256,
num_filters2=256,
num_groups=256,
stride=1,
scale=scale)
input = depthwise_separable(input=input,
num_filters1=256,
num_filters2=512,
num_groups=256,
stride=2,
scale=scale)
# 14x14
input = inception(input, 480, 192, 96, 208, 16, 24, 16, 24,64, "input")
input1 = inception(input, 512, 160, 112, 224, 24, 32, 24, 32, 64, "input1")
input1 = paddle.fluid.layers.concat(input=[input,input1], axis=1)
input2 = inception(input1, 512, 128, 128, 256, 24, 32, 24, 32, 64, "input2")
input2 = paddle.fluid.layers.concat(input=[input,input1,input2], axis=1)
input3 = inception(input2, 512, 128, 128, 256, 24, 32, 24, 32, 64, "input3")
input3 = paddle.fluid.layers.concat(input=[input,input1,input2,input3], axis=1)
input = depthwise_separable(input=input3,
num_filters1=512,
num_filters2=1024,
num_groups=512,
stride=2,
scale=scale)
# 7x7
input = depthwise_separable(input=input,
num_filters1=1024,
num_filters2=1024,
num_groups=1024,
stride=1,
scale=scale)
feature = fluid.layers.pool2d(input=input,
pool_size=0,
pool_stride=1,
pool_type='avg',
global_pooling=True)
net = fluid.layers.fc(input=feature,
size=class_dim,
act='softmax')
return net
四、进行模型的训练
#进行模型的训练
import os
import shutil
import paddle as paddle
import paddle.fluid as fluid
from multiprocessing import cpu_count
import numpy as np
import os
crop_size = 224
resize_size = 250
# 获取划分好的训练集和数据集,注意传入的.list文件的路径是否正确
try:
os.chdir('/home/aistudio/data/data119307')
except:
pass
train_reader = paddle.batch(reader=train_r('Wolf-and-Rabbit/train.list', crop_size, resize_size), batch_size=32)
test_reader = paddle.batch(reader=test_r('Wolf-and-Rabbit/test.list', crop_size), batch_size=32)
# 定义网络
def vgg_test_net(image, type_size):
def conv_block(ipt, num_filter, groups, dropouts):
return fluid.nets.img_conv_group(
input=ipt, # 具有[N,C,H,W]格式的输入图像
pool_size=2,
pool_stride=2,
conv_num_filter=[num_filter] * groups, # 过滤器个数
conv_filter_size=3, # 过滤器大小
conv_act='relu',
conv_with_batchnorm=True, # 表示在 Conv2d Layer 之后是否使用 BatchNorm
conv_batchnorm_drop_rate=dropouts,# 表示 BatchNorm 之后的 Dropout Layer 的丢弃概率
pool_type='max') # 最大池化
conv1 = conv_block(image, 64, 2, [0.0, 0])
conv2 = conv_block(conv1, 128, 2, [0.0, 0])
conv3 = conv_block(conv2, 256, 3, [0.0, 0.0, 0])
conv4 = conv_block(conv3, 512, 3, [0.0, 0.0, 0])
conv5 = conv_block(conv4, 512, 3, [0.0, 0.0, 0])
drop = fluid.layers.dropout(x=conv2, dropout_prob=0.5)
fc1 = fluid.layers.fc(input=drop, size=512, act=None)
bn = fluid.layers.batch_norm(input=fc1, act='relu')
drop2 = fluid.layers.dropout(x=bn, dropout_prob=0.0)
fc2 = fluid.layers.fc(input=drop2, size=512, act=None)
# predict = fluid.layers.fc(input=fc1, size=type_size, act='softmax')
predict = fluid.layers.fc(input=fc1, size=type_size)
return predict
# 定义输入层
paddle.enable_static()
image = fluid.layers.data(name='image', shape=[3, crop_size, crop_size], dtype='float32')
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
# 调用构建好的网络模型ZOO-ConvNet,并对两种动物进行分类。
predict = net(image, 2)
# 获取损失函数(交叉熵函数)和准确率函数
cost = fluid.layers.cross_entropy(input=predict, label=label)
avg_cost = fluid.layers.mean(cost)
acc = fluid.layers.accuracy(input=predict, label=label)
# 获取训练和测试程序
test_program = fluid.default_main_program().clone(for_test=True)
# 定义优化方法为Adam
optimizer = fluid.optimizer.AdamOptimizer(learning_rate=1e-3,
regularization=fluid.regularizer.L2DecayRegularizer(1e-4))
opts = optimizer.minimize(avg_cost)
# 定义一个使用GPU的执行器
place = fluid.CUDAPlace(0)
# place = fluid.CPUPlace()
exe = fluid.Executor(place)
# 进行参数初始化
exe.run(fluid.default_startup_program())
# 定义输入数据维度
feeder = fluid.DataFeeder(place=place, feed_list=[image, label])
因为时间关系,先训练10轮,结果还不错,Accuracy达到0.83346
# 因为时间关系,先训练10轮
for pass_id in range(10):
# 进行训练
for batch_id, data in enumerate(train_reader()):
train_cost, train_acc = exe.run(program=fluid.default_main_program(),
feed=feeder.feed(data),
fetch_list=[avg_cost, acc])
# 每100个batch打印一次信息
if batch_id % 100 == 0:
print('Pass:%d, Batch:%d, Cost:%0.5f, Accuracy:%0.5f' %
(pass_id, batch_id, train_cost[0], train_acc[0]))
# 进行测试
test_accs = []
test_costs = []
for batch_id, data in enumerate(test_reader()):
test_cost, test_acc = exe.run(program=test_program,
feed=feeder.feed(data),
fetch_list=[avg_cost, acc])
test_accs.append(test_acc[0])
test_costs.append(test_cost[0])
# 求测试结果的平均值
test_cost = (sum(test_costs) / len(test_costs))
test_acc = (sum(test_accs) / len(test_accs))
print('Test:%d, Cost:%0.5f, Accuracy:%0.5f' % (pass_id, test_cost, test_acc))
# 保存预测模型
save_path = 'infer_model/'
# 删除旧的模型文件
shutil.rmtree(save_path, ignore_errors=True)
# 创建保持模型文件目录
os.makedirs(save_path)
# 保存预测模型
fluid.io.save_inference_model(save_path, feeded_var_names=[image.name], target_vars=[predict], executor=exe)
Pass:0, Batch:0, Cost:0.29675, Accuracy:0.81250
Pass:0, Batch:100, Cost:0.21380, Accuracy:0.90625
Pass:0, Batch:200, Cost:0.27218, Accuracy:0.90625
Test:0, Cost:0.37007, Accuracy:0.83417
Pass:1, Batch:0, Cost:0.29944, Accuracy:0.87500
Pass:1, Batch:100, Cost:0.27599, Accuracy:0.90625
Pass:1, Batch:200, Cost:0.31102, Accuracy:0.84375
Test:1, Cost:0.38993, Accuracy:0.82596
Pass:2, Batch:0, Cost:0.33021, Accuracy:0.84375
Pass:2, Batch:100, Cost:0.25625, Accuracy:0.84375
Pass:2, Batch:200, Cost:0.26984, Accuracy:0.87500
Test:2, Cost:0.34155, Accuracy:0.86141
Pass:3, Batch:0, Cost:0.43508, Accuracy:0.78125
Pass:3, Batch:100, Cost:0.26304, Accuracy:0.84375
Pass:3, Batch:200, Cost:0.53662, Accuracy:0.71875
Test:3, Cost:0.36660, Accuracy:0.84233
Pass:4, Batch:0, Cost:0.32089, Accuracy:0.90625
Pass:4, Batch:100, Cost:0.30790, Accuracy:0.87500
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
/tmp/ipykernel_280/1337243622.py in <module>
5 train_cost, train_acc = exe.run(program=fluid.default_main_program(),
6 feed=feeder.feed(data),
----> 7 fetch_list=[avg_cost, acc])
8
9 # 每100个batch打印一次信息
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/executor.py in run(self, program, feed, fetch_list, feed_var_name, fetch_var_name, scope, return_numpy, use_program_cache, return_merged, use_prune)
1106 use_program_cache=use_program_cache,
1107 use_prune=use_prune,
-> 1108 return_merged=return_merged)
1109 except Exception as e:
1110 six.reraise(*sys.exc_info())
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/executor.py in _run_impl(self, program, feed, fetch_list, feed_var_name, fetch_var_name, scope, return_numpy, use_program_cache, return_merged, use_prune)
1237 scope=scope,
1238 return_numpy=return_numpy,
-> 1239 use_program_cache=use_program_cache)
1240
1241 program._compile(scope, self.place)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/executor.py in _run_program(self, program, feed, fetch_list, feed_var_name, fetch_var_name, scope, return_numpy, use_program_cache)
1312 fetch_list=fetch_list,
1313 feed_var_name=feed_var_name,
-> 1314 fetch_var_name=fetch_var_name)
1315
1316 self._feed_data(program, feed, feed_var_name, scope)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/executor.py in _add_feed_fetch_ops(self, program, feed, fetch_list, feed_var_name, fetch_var_name)
601 def _add_feed_fetch_ops(self, program, feed, fetch_list, feed_var_name,
602 fetch_var_name):
--> 603 tmp_program = program.clone()
604
605 global_block = tmp_program.global_block()
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/framework.py in clone(self, for_test)
4545 # NOTE(zhiqiu): we sync the original program first, since its program may diff with
4546 # its desc due to modifying desc in c++ space. E.g. save op will add kLookupTablePath in desc.
-> 4547 self._sync_with_cpp()
4548
4549 pruned_origin_block_id_map = None
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/framework.py in _sync_with_cpp(self)
5009 self.blocks.append(Block(self, block_idx))
5010 for block in self.blocks:
-> 5011 block._sync_with_cpp()
5012
5013 def _copy_param_info_from(self, other):
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/framework.py in _sync_with_cpp(self)
3046 ops_in_cpp = []
3047 for op_idx in range(0, self.desc.op_size()):
-> 3048 ops_in_cpp.append(self.desc.op(op_idx))
3049
3050 if len(self.ops) != 0:
KeyboardInterrupt:
五、模型预测
加载好训练的模型,对某一特定输入的动物图片进行测试,我们直接来看结果吧!
import paddle.fluid as fluid
from PIL import Image
import numpy as np
# 创建执行器
place = fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
# 保存预测模型路径
save_path = 'infer_model/'
# 从模型中获取预测程序、输入数据名称列表、分类器
[infer_program, feeded_var_names, target_var] = fluid.io.load_inference_model(dirname=save_path, executor=exe)
# 预处理图片
def load_image(file):
img = Image.open(file)
# 统一图像大小
img = img.resize((224, 224), Image.ANTIALIAS)
# 转换成numpy值
img = np.array(img).astype(np.float32)
# 转换成CHW
img = img.transpose((2, 0, 1))
# 转换成BGR
img = img[(2, 1, 0), :, :] / 255.0
img = np.expand_dims(img, axis=0)
return img
# 获取图片数据,可以更改imgpath的值,实现对不同的图片进行预测。
imgpath = "/home/aistudio/data/data119307/Wolf-and-Rabbit/Wolf/Wolf (1).jpg"
img = load_image(imgpath)
# 执行预测
result = exe.run(program=infer_program,
feed={feeded_var_names[0]: img},
fetch_list=target_var)
# 显示图片并输出结果最大的label
lab = np.argsort(result)[0][0][-1]
names = ['Wolf','Rabbit']
print('图片路径为:%s, 预测结果标签为:%d, 预测结果为:%s, 概率为:%f' % (imgpath, lab, names[lab], result[0][0][lab]))
图片路径为:/home/aistudio/data/data119307/Wolf-and-Rabbit/Wolf/Wolf (1).jpg, 预测结果标签为:0, 预测结果为:Wolf, 概率为:0.849590
个人简介
青岛农业大学 理学与信息科学学院 通信工程专业 2019级 本科生 冯慧宇
指导老师:青岛农业大学 宋彩霞 副教授
主要方向:人工智能在农业上的应用,省级科研项目参与者,致力于推动AI在农业领域的应用。
Github地址:https://github.com/Fhy001
昵称:小小小疯叔叔 关注我,下次带来更多精彩项目分享!
结束,谢谢您的观看!

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)