
【论文复现赛】ResNet18_3D
第五期论文复现赛ResNet18_3D,复现目标ucf101数据集acc 42.4%,本次复现的acc为43.98%,该算法可用于视频动作识别。
【论文复现赛】Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet?
本文的目标是检验当前的视频数据集是否有充足的数据来训练非常深的3D卷积神经网络(原文:The purpose of this study is to determine whether current video datasets have sufficient data for training very deep convolutional neural networks with spatio-temporal three-dimensional kernels),作者在当前的数据集上使用不同深度的网络进行了实验,得到以下几个结论:
1、ResNet-18在UCF-101,HMDB-51,ActivityNet数据集上过拟合,Kinetics数据集未过拟合;
2、Kinetics数据集有充分的数据训练深的3D卷积网络;
3、网络加载在Kinetics数据集预训练的权重,在其他数据集(UCF-101/HMDB-51)上也可以得到不错的效果。
本次复现的目标是不使用预训练权重,在UCF-101数据集准确率达到42.4%,本次复现的准确率为43.98%,本次复现基于PaddleVideo。
代码参考:
1、https://github.com/kenshohara/3D-ResNets-PyTorch/tree/CVPR2018
2、【从零开始学视觉Transformer】
本项目地址:https://github.com/justld/3D-ResNets_paddle
一、 网络结构
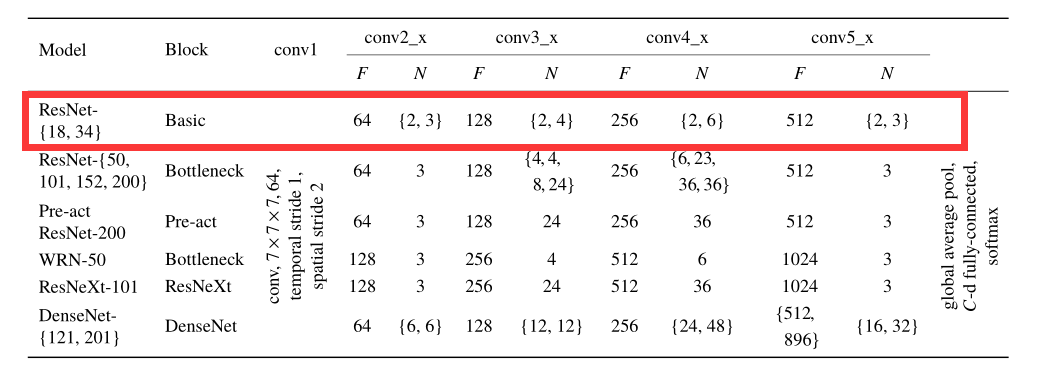
上图未本文实验使用的不同网络结构,红框部分为本次复现的网络结构(ResNet18_3D),ResNet18结构非常简单,而且巧合的是在本次论文复现赛期间官方推出了【从零开始学视觉Transformer】课程,第一节课朱老师就带着大家写了一个ResNet18(2D CNN),只需要对该模型稍加修改即可得到ResNet18_3D,非常感谢朱老师的激情讲解。
二、实验结果
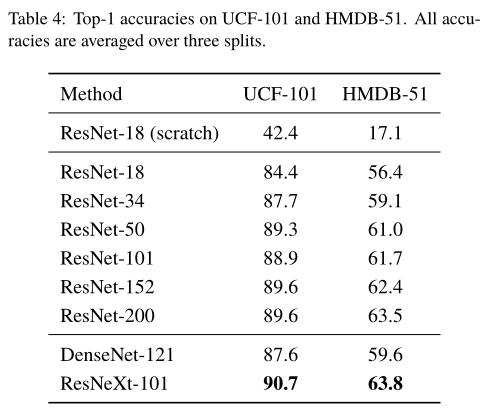
上表为各个模型在UCF-101和HMDB-51数据集上的准确率,Scratch表示未加载Kinetics权重从头训练,未标明Scratch表示使用Kinetics数据集预训练权重。可以看出,使用Kinetics数据集预训练权重可以显著提高准确率,缓解UCF-101和HMDB-51数据集数据不充分的问题。
三、核心代码
class ConvBNRelu(nn.Layer):
def __init__(self, in_channels, out_channels, kernel_size, **kwargs):
super().__init__()
self.conv = nn.Conv3D(in_channels, out_channels, kernel_size=kernel_size, **kwargs)
self.bn = nn.BatchNorm3D(out_channels)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
class Block(nn.Layer):
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.block = nn.Sequential(
ConvBNRelu(in_channels, out_channels, 3, stride=stride, padding='same'),
nn.Conv3D(out_channels, out_channels, 3, stride=1, padding='same'),
nn.BatchNorm3D(out_channels),
)
if in_channels != out_channels or stride != 2:
self.downsample = nn.Sequential(
nn.Conv3D(in_channels, out_channels, kernel_size=1, stride=stride),
nn.BatchNorm3D(out_channels),
)
else:
self.downsample = Identity()
self.relu = nn.ReLU()
def forward(self, x):
res = self.downsample(x)
x = self.block(x)
x = self.relu(x + res)
return x
class Identity(nn.Layer):
def __init__(self):
super().__init__()
def forward(self, x):
return x
@BACKBONES.register()
class ResNet18(nn.Layer):
def __init__(self, in_channels=3, num_seg=8):
super(ResNet18, self).__init__()
self.num_seg = num_seg
self.stem = nn.Sequential(
ConvBNRelu(in_channels, 64, kernel_size=7, stride=(1, 2, 2), padding=(3, 3, 3), bias_attr=False),
nn.MaxPool3D(kernel_size=(3, 3, 3), stride=2, padding=1),
)
self.layer1 = self._make_layer(64, 64, 2, 1)
self.layer2 = self._make_layer(64, 128, 2, 2)
self.layer3 = self._make_layer(128, 256, 2, 2)
self.layer4 = self._make_layer(256, 512, 2, 2)
self.pool = nn.AdaptiveAvgPool3D(1)
def _make_layer(self, in_channels, out_channels, n_blocks, stride=1):
layer_list = []
layer_list.append(Block(in_channels, out_channels, stride))
for i in range(1, n_blocks):
layer_list.append(Block(out_channels, out_channels))
return nn.Sequential(*layer_list)
def forward(self, x):
nt, c, h, w = x.shape
x = x.reshape([-1, self.num_seg, c, h, w]).transpose([0, 2, 1, 3, 4]) # N, C, T, H, W
x = self.stem(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x) # N, C, T, H, W
x = self.pool(x).reshape([paddle.shape(x)[0], -1]) # N, C
return x
上述代码根据【从零开始学视觉Transformer】实战作业ResNet18修改而成,没上课的同学快去看看吧。
四、在线体验
实现ResNet18_3D在UCF-101训练、验证、预测,只需要以下几步:
1、解压数据集
2、处理数据,从视频数据集提取帧,可参考PaddleVideo处理UCF-101数据集的方法
3、安装依赖包
4、训练
5、验证精度
6、模型导出
7、模型预测
# step 1: 解压数据集
%cd ~/data/data105621/
!unzip -oq UCF101.zip
%cd ~/
# step 2: 下载标注文件,生成list, 这里需要的时间比较长(约半小时),请耐心等待
%cd ~/PaddleVideo/data/ucf101/
%cp -r /home/aistudio/data/data105621/UCF-101 ~/PaddleVideo/data/ucf101/videos
# !bash download_annotations.sh # 此版本已经提供了标注信息,下载有时候网络不给力
!python extract_rawframes.py ./videos/ ./rawframes/ --level 2 --ext avi
!python build_ucf101_file_list.py rawframes/ --level 2 --format rawframes --out_list_path ./
# step 3: pip install requirements
%cd ~/PaddleVideo/
!pip install -r requirements.txt
# step 4: training
%cd /home/aistudio/PaddleVideo/
!python3 main.py -c configs/recognition/resnet18_3d/resnet18_3d_ucf101_frames.yaml --validate --seed=10001
# step 5: test
%cd /home/aistudio/PaddleVideo/
!python3 main.py -c configs/recognition/resnet18_3d/resnet18_3d_ucf101_frames.yaml --test -w output/Res18/Res18_best.pdparams
# step 6: export model
!python3.7 tools/export_model.py -c configs/recognition/resnet18_3d/resnet18_3d_ucf101_frames.yaml -p output/Res18/Res18_best.pdparams -o inference/Res18_3D
# step 7: predict,用数据集中的一个数据预测一下,该视频类别为:0
%cd /home/aistudio/PaddleVideo/
!python3.7 tools/predict.py --config configs/recognition/resnet18_3d/resnet18_3d_ucf101_frames.yaml --input_file /home/aistudio/data/data105621/UCF-101/ApplyEyeMakeup/v_ApplyEyeMakeup_g08_c01.avi --model_file inference/Res18_3D/Res18.pdmodel --params_file inference/Res18_3D/Res18.pdiparams --use_gpu=True --use_tensorrt=False
五、复现结果
本次复现的目标是UCF-101验证集acc 42.4%,复现的为acc 43.98%。
环境:
Tesla V100 * 1
PaddlePaddle==2.2.0
| model | dataset | acc |
|---|---|---|
| ResNet18_3D | UCF-101 | 43.98% |
六、复现经验
1、提取视频帧的时候使用了多线程,可能会导致数据标签的顺序不同,从而结果有些许差异,如果一次训练未达标,可以多试几次;
2、在论文复现赛中,使用PaddleClas/PaddleSeg/PaddleVideo等框架可以加快效率。
七、致谢
1、非常感谢AiStudio平台提供的算力和奖金支持;
2、非常感谢朱老师的课程【从零开始学视觉Transformer】。
个人介绍
姓名:郎督
学校:东北大学
年级:研二
GitHub: https://github.com/justld

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 3
3 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)