
基于PaddleLite实现yolov5的移动端部署
本项目是参加飞桨黑客松二期第63号任务,也是本人是上一个项目的续集,将yolov5部署到安卓手机
项目背景
本项目是参加PaddlePaddle Hackathon第二期活动的任务, 在此分享将yolov5模型部署在手机端上的一些实践记录和踩坑经历。
任务目标:
参考ssd_mobilnetv1目标检测的 Android demo,使用 yolo_v5 模型在安卓手机上完成 demo 开发,输入为摄像头实时视频流,输出为包含检测框的视频流;在界面上添加一个 backend 选择开关,用户可以选择将模型运行在 CPU 或 GPU 上,保证分别运行 CPU 和 GPU 结果均正确。
项目任务链接: https://github.com/PaddlePaddle/Paddle/issues/40234
GitHub 任务提交链接: https://github.com/PaddlePaddle/Paddle-Lite-Demo/pull/237
基于之前项目的后续开发
链接: https://aistudio.baidu.com/aistudio/projectdetail/3452279
导出nb文件
基于之前的项目稍微做了调整,代码已上传至GitHub: https://github.com/thunder95/yolov5_paddle_prune
%cd /home/aistudio/
!rm -rf yolov5_paddle_prune/
!git clone https://github.com/thunder95/yolov5_paddle_prune.git
%cd yolov5_paddle_prune
!git checkout android
# 安装依赖库
!pip install gputil==1.4.0 pycocotools terminaltables
!mkdir -p /home/aistudio/.config/thunder95/
!cp /home/aistudio/Arial.ttf /home/aistudio/.config/thunder95/
数据集
本项目不需要训练, 但需要解压并修改数据集加载的配置文件
%cd /home/aistudio/data/data127016/
!unzip /home/aistudio/data/data127016/yolov5_mot20.zip
!python create_txt.py
!sed -i 's|\/f\/dataset\/person\/out|\/home\/aistudio\/data\/data127016|g' /home/aistudio/yolov5_paddle_prune/data/coco.yaml
在models/common.py中修改, 基于PaddleAPI实现PaddleLite不支持的算子silu:
Error: This model is not supported, because 1 ops are not supported on ‘arm’. These unsupported ops are: ‘silu’

修改原后处理逻辑
遇到的问题一:
[F 4/10 8:51:53.568 …-Lite/lite/kernels/opencl/image_helper.h:72 DefaultGlobalWorkSize] Unsupport DefaultGlobalWorkSize with tensor_dim.size():5, image_shape.size():2
所提Issue(https://github.com/PaddlePaddle/Paddle-Lite/issues/8803)反馈, 在PaddleLite中使用opencl不支持>4维的算子
遇到的问题二:
使用paddle.max和paddle.argmax组合会跟原网络输出无法对齐
所提Issue(https://github.com/PaddlePaddle/Paddle-Lite/issues/8647)反馈, 官方待修复这个问题。
修改models/yolo.py中检测头的foward部分
class Detect(nn.Layer):
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__()
self.onnx_dynamic = False # ONNX export parameter
self.stride = None # strides computed during build
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [paddle.zeros([1])] * self.nl # init grid
self.anchor_grid = [paddle.zeros([1])] * self.nl # init anchor grid
self.register_buffer('anchors', paddle.to_tensor(anchors).astype('float32').reshape([self.nl, -1, 2])) # shape(nl,na,2)
self.m = nn.LayerList(nn.Conv2D(x, self.no * self.na, 1) for x in ch) # output conv
self.inplace = inplace # use in-place ops (e.g. slice assignment)
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].reshape([bs, self.na, self.no, ny * nx]).transpose([0, 1, 3, 2])
if not self.training: # inference
y = F.sigmoid(x[i])
z.append(y)
return x if self.training else z
修改detect.py中提取boxes代码, 将在andriod端用c实现
boxes = [] # xywh, score, cls
for l in range(len(pred)):
pred[l] = pred[l].numpy()
bs, ch, nd, cn = pred[l].shape
rows = dim_num[l]
print(l, rows)
for b in range(bs):
for c in range(ch):
for r in range(rows):
offset = r * row_num
max_cls_val = 0
max_cls_id = 0
score = pred[l][b, c, r, 4]
if score < conf_thres:
continue
for i in range(80):
if pred[l][b, c, r, i + 5] > max_cls_val:
max_cls_val = pred[l][b, c, r, i + 5]
max_cls_id = i
score *= max_cls_val
if score < conf_thres:
continue
y = int(r / xdim[l])
x = int(r % xdim[l])
tmp_box = [
(pred[l][b, c, r, 0] * 2 - 0.5 + x) * strides[l],
(pred[l][b, c, r, 1] * 2 - 0.5 + y) * strides[l], # i, y, x, 2
(pred[l][b, c, r, 2] * 2) ** 2 * anchors[l][c * 2],
(pred[l][b, c, r, 3] * 2) ** 2 * anchors[l][c * 2 + 1],
max_cls_id,
score, # scores
]
tmp_box[0] = tmp_box[0] - tmp_box[2] / 2 # x1
tmp_box[1] = tmp_box[1] - tmp_box[3] / 2 # y1
tmp_box[2] = tmp_box[0] + tmp_box[2] # x2
tmp_box[3] = tmp_box[1] + tmp_box[3] # y2
boxes.append(tmp_box)
# 导出静态图模型
%cd /home/aistudio/yolov5_paddle_prune
!python convert_static.py --weights ./weights/yolov5n.pdparams --cfg models/yolov5n.yaml --data ./data/coco.yaml --source crop.jpg
生成NB文件
安装PaddleLite优化工具paddle_lite_opt,并通过命令生成nb权重文件。
本项目推荐编译安装release/v2.11的PaddleLite, 参考issue:https://github.com/PaddlePaddle/Paddle-Lite/issues/9168
git clone https://github.com/PaddlePaddle/Paddle-Lite.git
cd Paddle-Lite
git checkout release/v2.11
export NDK_ROOT=~/Android/Sdk/ndk/24.0.8215888/
./lite/tools/build_android.sh --with_opencl=ON --arch=armv8 --with_extra=ON --with_log=ON
%cd /home/aistudio/yolov5_paddle_prune/
!pip install paddlelite==2.11
# cpu
!paddle_lite_opt --model_file=./simple_net.pdmodel --param_file=simple_net.pdiparams --optimize_out_type=naive_buffer --optimize_out=./yolov5n_cpu --valid_targets=arm
#gpu
!paddle_lite_opt --model_file=./simple_net.pdmodel --param_file=simple_net.pdiparams --optimize_out_type=naive_buffer --optimize_out=./yolov5n_gpu --valid_targets=opencl,arm
/home/aistudio/yolov5_paddle_prune
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting paddlelite==2.11
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/8b/d7/8babc059bff1d02dc85e32fb8bff3c56680db5f5b20246467f9fcbcfe62c/paddlelite-2.11-cp37-cp37m-manylinux1_x86_64.whl (47.1 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m47.1/47.1 MB[0m [31m16.5 MB/s[0m eta [36m0:00:00[0m00:01[0m00:01[0m
[?25hInstalling collected packages: paddlelite
Successfully installed paddlelite-2.11
[33mWARNING: You are using pip version 22.0.4; however, version 22.1.2 is available.
You should consider upgrading via the '/opt/conda/envs/python35-paddle120-env/bin/python -m pip install --upgrade pip' command.[0m[33m
[0mLoading topology data from ./simple_net.pdmodel
Loading params data from simple_net.pdiparams
1. Model is successfully loaded!
2. Model is optimized and saved into ./yolov5n_cpu.nb successfully
Loading topology data from ./simple_net.pdmodel
Loading params data from simple_net.pdiparams
1. Model is successfully loaded!
2. Model is optimized and saved into ./yolov5n_gpu.nb successfully
Adb shell运行
安裝Adb软件(以ubuntu为例)
准备一部测试用的安卓手机armv8版本,处理器Qualcomm Snapdrgon 450。
- 系统 -> 版本号 -> 连续点击7次, 开启开发模式
- 设置 -> 搜索开发人员选项 -> 打开usb调试
- 连接安卓手机, 测试连接状态
sudo apt update
sudo apt install -y wget adb
adb devices
下方出现设备,表示设备连接成功
List of devices attached
XKKBB19A10231894 device
修改本地NDK配置:export NDK_ROOT=~/Android/Sdk/ndk/24.0.8215888
关键代码
下载代码:git clone https://github.com/PaddlePaddle/Paddle-Lite-Demo.git
注意: 之前的版本opencl会存在精度对齐的问题,需要切换到develop或者release/v2.11, 参考本人issue: https://github.com/PaddlePaddle/Paddle-Lite/issues/8807
下载, 解压并拷贝预编译库到Paddle-Lite-Demo项目: https://paddle-lite.readthedocs.io/zh/develop/quick_start/release_lib.html
/cxx/include$ cp ./* /home/hulei/projects/tmp/Paddle-Lite-Demo/libs/android/cxx/include/
/cxx/lib$ cp libpaddle_light_api_shared.so /home/hulei/projects/tmp/Paddle-Lite-Demo/libs/android/cxx/libs/arm64-v8a/
模型加载:
// 1. Set MobileConfig
MobileConfig config;
config.set_model_from_file(model_file);
std::cout << "model_file: " << model_file << std::endl;
config.set_power_mode(static_cast<paddle::lite_api::PowerMode>(power_mode));
config.set_threads(thread_num);
// 2. Create PaddlePredictor by MobileConfig
std::shared_ptr<PaddlePredictor> predictor =
CreatePaddlePredictor<MobileConfig>(config);
// 3. Prepare input data from image
// read img and pre-process
std::unique_ptr<Tensor> input_tensor0(std::move(predictor->GetInput(0)));
input_tensor0->Resize({1, 3, height, width});
auto *data0 = input_tensor0->mutable_data<float>();
cv::Mat img = imread(img_path, cv::IMREAD_COLOR);
pre_process(img, width, height, data0);
// 4. Run predictor
double first_duration{-1};
for (size_t widx = 0; widx < warmup; ++widx) {
if (widx == 0) {
auto start = GetCurrentUS();
predictor->Run();
first_duration = (GetCurrentUS() - start) / 1000.0;
} else {
predictor->Run();
}
}
数据输入预处理
void pre_process(const cv::Mat &img_ori, int width, int height, float *data) {
cv::Mat img = img_ori.clone();
int w, h, x, y;
int channelLength = width * height;
float r_w = width / (img.cols * 1.0);
float r_h = height / (img.rows * 1.0);
if (r_h > r_w) {
w = width;
h = r_w * img.rows;
x = 0;
y = (height - h) / 2;
} else {
w = r_h * img.cols;
h = height;
x = (width - w) / 2;
y = 0;
}
cv::Mat re(h, w, CV_8UC3);
cv::resize(img, re, re.size(), 0, 0, cv::INTER_CUBIC);
cv::Mat out(height, width, CV_8UC3, cv::Scalar(128, 128, 128));
re.copyTo(out(cv::Rect(x, y, re.cols, re.rows)));
// split channels
out.convertTo(out, CV_32FC3, 1. / 255.);
cv::Mat input_channels[3];
cv::split(out, input_channels);
for (int j = 0; j < 3; j++) {
memcpy(data + width * height * j, input_channels[2 - j].data,
channelLength * sizeof(float));
}
}
后处理代码
void post_process(std::shared_ptr<PaddlePredictor> predictor, float thresh,
std::vector<std::string> class_names, const cv::Mat &image,
int in_width, int in_height) { // NOLINT
const int strides[3] = {8, 16, 32};
const int anchors[3][6] = {{10, 13, 16, 30, 33, 23},
{30, 61, 62, 45, 59, 119},
{116, 90, 156, 198, 373, 326}};
std::map<int, std::vector<Object>> raw_outputs;
float r_w = in_width / static_cast<float>(image.cols);
float r_h = in_height / static_cast<float>(image.rows);
float r, off_x, off_y;
if (r_h > r_w) {
r = r_w;
off_x = 0;
off_y = static_cast<int>((in_height - r_w * image.rows) / 2);
} else {
r = r_h;
off_y = 0;
off_x = static_cast<int>((in_width - r_h * image.cols) / 2);
}
for (int k = 0; k < 3; k++) {
std::unique_ptr<const Tensor> output_tensor(
std::move(predictor->GetOutput(k)));
auto *outptr = output_tensor->data<float>();
auto shape_out = output_tensor->shape();
std::vector<int> shape_new(shape_out.begin(), shape_out.end());
int xdim = static_cast<int>(in_width / strides[k]);
extract_boxes(outptr, &raw_outputs, strides[k], anchors[k], shape_new, r,
thresh, off_x, off_y, xdim);
}
std::vector<Object> outs;
nms(&raw_outputs, &outs, 0.45);
}
打开日志调试
模型可能算子不支持,也可能有其他问题,需要更多详细的日志信息, 这是需要打开日志模式。下载PaddleLite源码重新编译:
./lite/tools/build_android_armv8.sh --with_opencl=ON --arch=armv8 --with_extra=ON --with_log=ON
运行Yolov5n推理
cd Paddle-Lite-Demo/libs
# 下载所需要的 Paddle Lite 预测库
sh download.sh
cd ../object_detection/assets
# 下载OPT 优化后模型、测试图片、标签文件
sh download.sh
cd ../android/app/shell/cxx/yolov5n_detection
# 更新 NDK_ROOT 路径,然后完成可执行文件的编译和运行
sh build.sh
# CMakeList.txt 里的 System 默认设置是linux;如果在Mac 运行,则需将 CMAKE_SYSTEM_NAME 变量设置为 drawn
cpu推理性能:

推理结果:

gpu推理性能: shell下相比cpu测试没有明显的性能提升, 输出精度与cpu对齐

部署到Anroid手机
参考教程: https://aistudio.baidu.com/aistudio/projectdetail/3431580
注意:如果您的 Android Studio 尚未配置 NDK ,请根据 Android Studio 用户指南中的安装及配置 NDK 和 CMake 内容,预先配置好 NDK 。您可以选择最新的 NDK 版本,或者使用 Paddle Lite 预测库版本一样的 NDK
使用AndroidStudio打开工程目录: https://github.com/PaddlePaddle/Paddle-Lite-Demo/tree/develop/object_detection/android/shell/cxx/yolov5n_detection
更新预测库到demo工程中:
/java/jar$ cp PaddlePredictor.jar yolov5n_detection_demo/app/PaddleLite/java/
/java/so$ cp libpaddle_lite_jni.so yolov5n_detection_demo/app/PaddleLite/java/libs/arm64-v8a/
cxx/include$ cp ./* yolov5n_detection_demo/app/PaddleLite/cxx/include/
cxx/lib$ cp libpaddle_light_api_shared.so yolov5n_detection_demo/app/PaddleLite/cxx/libs/arm64-v8a/
启动Android部署到到手机上
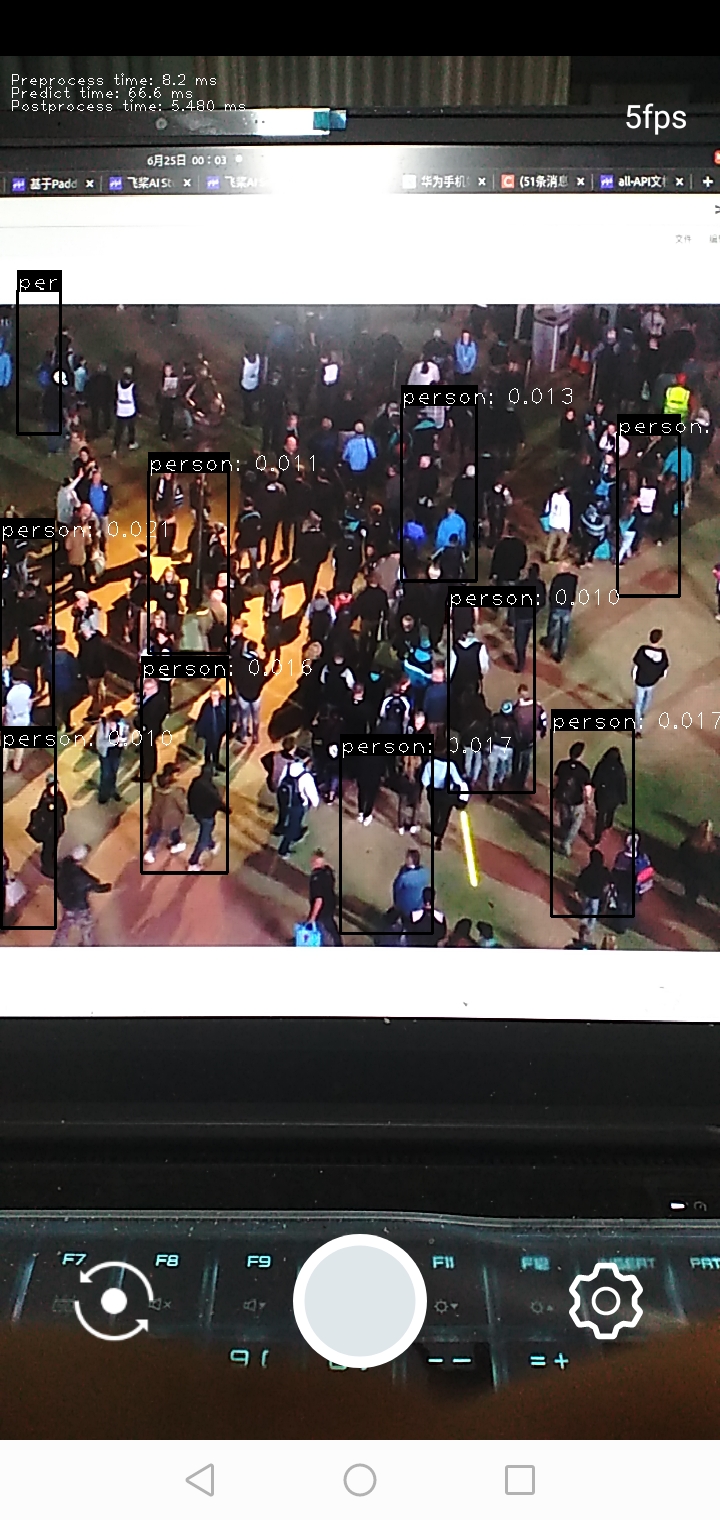
在性能不错的小米手机上可达到50fps

基于裁剪的模型进行部署
使用上一个项目裁剪训练的权重: yolov5_paddle_prune/weights/finetune.pdparams
转换静态图时需要适配cfg配置文件,将裁剪后的模型通过cfg配置文件加载
相比之前的nb文件大小, 裁剪后从 7.5MB 降低到 2.8MB.
%cd /home/aistudio/yolov5_paddle_prune
!python convert_static_prune.py --weights ./weights/finetune.pdparams --cfg cfg/prune_0.5_keep_0.01_8x_yolov5n_v6_person.cfg --data ./data/coco_person.yaml --source crop.jpg
/home/aistudio/yolov5_paddle_prune
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import MutableMapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Iterable, Mapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Sized
[34m[1mconvert_static_prune: [0mweights=['./weights/finetune.pdparams'], cfg=cfg/prune_0.5_keep_0.01_8x_yolov5n_v6_person.cfg, source=crop.jpg, imgsz=[320, 320], conf_thres=0.01, iou_thres=0.6, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, dnn=False, single_cls=False, data=./data/coco_person.yaml, hyp=data/hyps/hyp.scratch.yaml
[31m[1mrequirements:[0m tqdm>=4.36.1 not found and is required by YOLOv5, attempting auto-update...
# 按照同样的方式生成nb文件, 并部署到同样的安卓手机, paddle-lite-demo代码不需要额外的改动
%cd /home/aistudio/yolov5_paddle_prune/
!pip install paddlelite==2.11
# cpu
!paddle_lite_opt --model_file=./prune_net.pdmodel --param_file=prune_net.pdiparams --optimize_out_type=naive_buffer --optimize_out=./yolov5n_cpu_prune --valid_targets=arm
#gpu
!paddle_lite_opt --model_file=./prune_net.pdmodel --param_file=prune_net.pdiparams --optimize_out_type=naive_buffer --optimize_out=./yolov5n_gpu_prune --valid_targets=opencl,arm
/home/aistudio/yolov5_paddle_prune
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting paddlelite==2.11
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/8b/d7/8babc059bff1d02dc85e32fb8bff3c56680db5f5b20246467f9fcbcfe62c/paddlelite-2.11-cp37-cp37m-manylinux1_x86_64.whl (47.1 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m47.1/47.1 MB[0m [31m12.8 MB/s[0m eta [36m0:00:00[0m00:01[0m00:01[0m
[?25hInstalling collected packages: paddlelite
Successfully installed paddlelite-2.11
[33mWARNING: You are using pip version 22.0.4; however, version 22.1.2 is available.
You should consider upgrading via the '/opt/conda/envs/python35-paddle120-env/bin/python -m pip install --upgrade pip' command.[0m[33m
[0mLoading topology data from ./prune_net.pdmodel
Loading params data from prune_net.pdiparams
1. Model is successfully loaded!
2. Model is optimized and saved into ./yolov5n_cpu_prune.nb successfully
Loading topology data from ./prune_net.pdmodel
Loading params data from prune_net.pdiparams
1. Model is successfully loaded!
2. Model is optimized and saved into ./yolov5n_gpu_prune.nb successfully
adb shell运行
替换之前的模型, 推理速度大幅度降低
CPU下运行:

GPU下运行:

注意: 测试时该模型的conf阈值设置0.01, 输出结果 05000319_yolov5n_detection_result.jpg

部署到安卓手机, 原来的代码有点bug, 设置阈值0.01无法生效,需要修改一点源码, 将confThresh_替换成scoreThreshold_

写在最后
本项目详细记录了如何将yolov5模型部署到安卓手机的操作步骤和踩坑经历,不经将原始权重成功部署,还能将自己训练的裁剪后的模型也能无需修改源码进行部署。
关于作者
- 成都飞桨领航团团长
- PPDE
- AICA三期学员
- PFCC成员
我在AI Studio上获得钻石等级,点亮10个徽章,来互关呀~
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/89442
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
此文为搬运,原作链接:https://aistudio.baidu.com/aistudio/projectdetail/4245931

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)