
『行远见大』 BQ Corpus 信贷文本匹配相似度计算
BQ Corpus 信贷文本匹配相似度计算,根据两段银行信贷业务的文本在语义上是否相似进行二分类。本项目为各位同学提供一个 Baseline:acc = 0.84728。
『行远见大』 BQ Corpus 信贷文本匹配相似度计算
项目简介
BQ Corpus 信贷文本匹配相似度计算,根据两段银行信贷业务的文本在语义上是否相似进行二分类,相似判断为1,不相似判断为0。本项目为各位同学提供一个 Baseline:acc = 0.84728,各位同学可参考本项目并在此基础上进一步调优。
数据集介绍
BQ Corpus(Bank Question Corpus), 银行金融领域的问题匹配数据,包括了从一年的线上银行系统日志里抽取的问题 pair 对,是目前最大的银行领域问题匹配数据。
| 数据集名称 | 训练集大小 | 验证集大小 | 测试集大小 |
|---|---|---|---|
| BQ Corpus | 100,000 | 10,000 | 10,000 |
数据集链接:https://aistudio.baidu.com/aistudio/datasetdetail/78992
比赛报名

报名链接:https://aistudio.baidu.com/aistudio/competition/detail/45
致敬开源
大家好,我是行远见大。欢迎你与我一同建设飞桨开源社区,知识分享是一种美德,让我们向开源致敬!
前置基础知识
文本语义匹配
文本语义匹配是自然语言处理中一个重要的基础问题,NLP 领域的很多任务都可以抽象为文本匹配任务。例如,信息检索可以归结为查询项和文档的匹配,问答系统可以归结为问题和候选答案的匹配,对话系统可以归结为对话和回复的匹配。语义匹配在搜索优化、推荐系统、快速检索排序、智能客服上都有广泛的应用。如何提升文本匹配的准确度,是自然语言处理领域的一个重要挑战。
- 信息检索:在信息检索领域的很多应用中,都需要根据原文本来检索与其相似的其他文本,使用场景非常普遍。
- 新闻推荐:通过用户刚刚浏览过的新闻标题,自动检索出其他的相似新闻,个性化地为用户做推荐,从而增强用户粘性,提升产品体验。
- 智能客服:用户输入一个问题后,自动为用户检索出相似的问题和答案,节约人工客服的成本,提高效率。
让我们来看一个简单的例子,比较各候选句子哪句和原句语义更相近:
原句:“车头如何放置车牌”
- 比较句1:“前牌照怎么装”
- 比较句2:“如何办理北京车牌”
- 比较句3:“后牌照怎么装”
(1)比较句1与原句,虽然句式和语序等存在较大差异,但是所表述的含义几乎相同
(2)比较句2与原句,虽然存在“如何” 、“车牌”等共现词,但是所表述的含义完全不同
(3)比较句3与原句,二者讨论的都是如何放置车牌的问题,只不过一个是前牌照,另一个是后牌照。二者间存在一定的语义相关性
所以语义相关性,句1大于句3,句3大于句2,这就是语义匹配。
短文本语义匹配网络
短文本语义匹配(SimilarityNet, SimNet)是一个计算短文本相似度的框架,可以根据用户输入的两个文本,计算出相似度得分。主要包括 BOW、CNN、RNN、MMDNN 等核心网络结构形式,提供语义相似度计算训练和预测框架,适用于信息检索、新闻推荐、智能客服等多个应用场景,帮助企业解决语义匹配问题。
SimNet 模型结构如图所示,包括输入层、表示层以及匹配层。
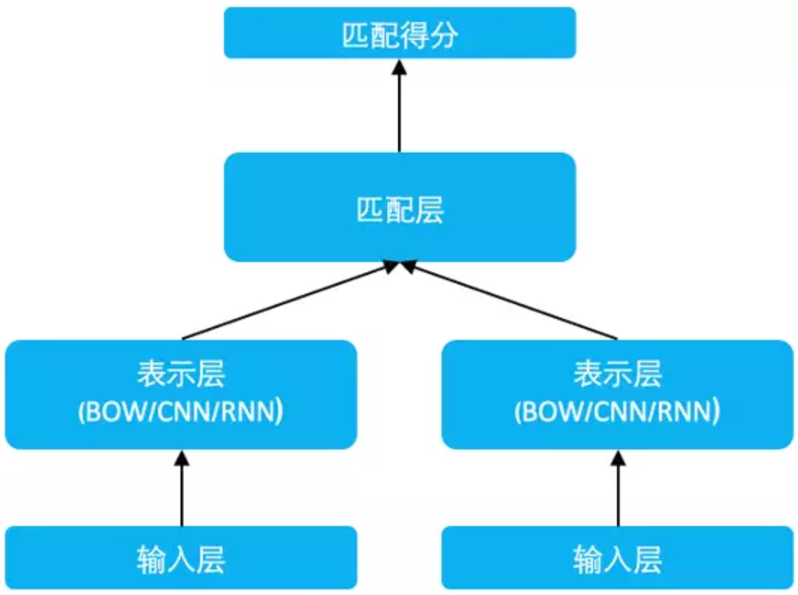
SimilarityNet 模型框架结构图
模型框架结构图如下图所示,其中 query 和 title 是数据集经过处理后的待匹配的文本,然后经过分词处理,编码成id,经过 SimilarityNet 处理,得到输出,训练的损失函数使用的是交叉熵损失。
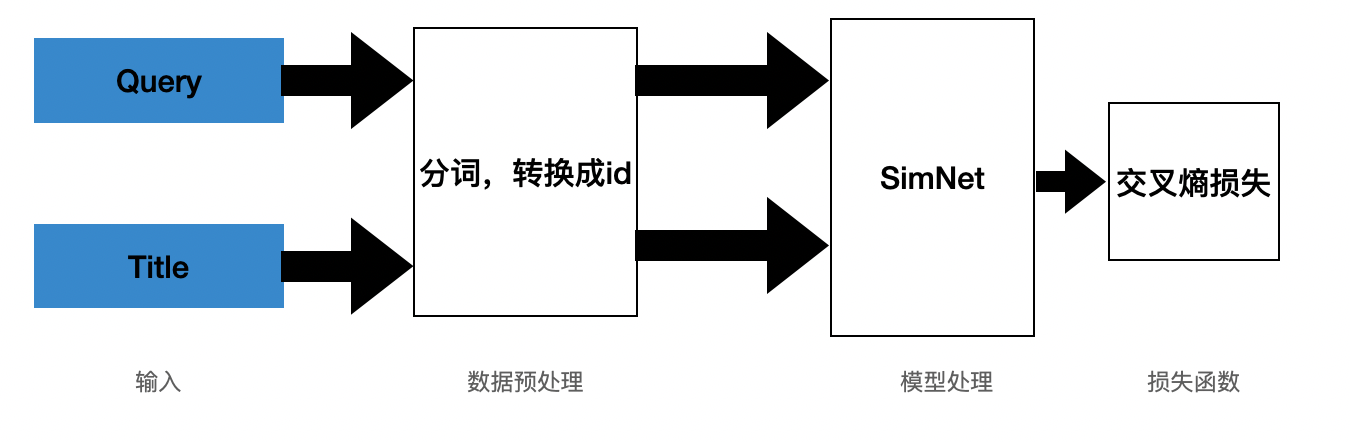
BQ Corpus 信贷文本匹配相似度计算
环境配置
# 导入必要的库
import math
import numpy as np
import os
import collections
from functools import partial
import random
import time
import inspect
import importlib
from tqdm import tqdm
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddle.io import IterableDataset
from paddle.utils.download import get_path_from_url
print("本项目基于Paddle的版本号为:"+ paddle.__version__)
本项目基于Paddle的版本号为:2.1.0
# AI Studio上的PaddleNLP版本过低,所以需要首先升级PaddleNLP
!pip install paddlenlp --upgrade
# 导入PaddleNLP相关的包
import paddlenlp as ppnlp
from paddlenlp.data import JiebaTokenizer, Pad, Stack, Tuple, Vocab
# from utils import convert_example
from paddlenlp.datasets import MapDataset
from paddle.dataset.common import md5file
from paddlenlp.datasets import DatasetBuilder
print("本项目基于PaddleNLP的版本号为:"+ ppnlp.__version__)
本项目基于PaddleNLP的版本号为:2.0.2
加载预训练模型 ERNIE
# 若运行失败,请重启项目
MODEL_NAME = "ernie-1.0"
ernie_model = ppnlp.transformers.ErnieModel.from_pretrained(MODEL_NAME)
model = ppnlp.transformers.ErnieForSequenceClassification.from_pretrained(MODEL_NAME, num_classes=2)
# 定义 ERNIE 模型对应的 tokenizer,并查看效果
tokenizer = ppnlp.transformers.ErnieTokenizer.from_pretrained(MODEL_NAME)
[2021-06-08 22:02:33,437] [ INFO] - Downloading vocab.txt from https://paddlenlp.bj.bcebos.com/models/transformers/ernie/vocab.txt
100%|██████████| 90/90 [00:00<00:00, 3546.51it/s]
tokens = tokenizer._tokenize("行远见大荣誉出品")
print("Tokens: {}".format(tokens))
# token映射为对应token id
tokens_ids = tokenizer.convert_tokens_to_ids(tokens)
print("Tokens id: {}".format(tokens_ids))
# 拼接上预训练模型对应的特殊token ,如[CLS]、[SEP]
tokens_ids = tokenizer.build_inputs_with_special_tokens(tokens_ids)
print("Tokens id: {}".format(tokens_ids))
# 转化成Paddle框架数据格式
tokens_pd = paddle.to_tensor([tokens_ids])
print("Tokens : {}".format(tokens_pd))
# 此时即可输入ERNIE模型中得到相应输出
sequence_output, pooled_output = ernie_model(tokens_pd)
print("Token wise output: {}, Pooled output: {}".format(sequence_output.shape, pooled_output.shape))
Tokens: ['行', '远', '见', '大', '荣', '誉', '出', '品']
Tokens id: [40, 629, 373, 19, 838, 1054, 39, 100]
Tokens id: [1, 40, 629, 373, 19, 838, 1054, 39, 100, 2]
Tokens : Tensor(shape=[1, 10], dtype=int64, place=CUDAPlace(0), stop_gradient=True,
[[1 , 40 , 629, 373, 19 , 838, 1054, 39 , 100, 2 ]])
Token wise output: [1, 10, 768], Pooled output: [1, 768]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:125: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
if data.dtype == np.object:
encoded_text = tokenizer(text="行远见大荣誉出品", max_seq_len=20)
for key, value in encoded_text.items():
print("{}:\n\t{}".format(key, value))
# 转化成Paddle框架数据格式
input_ids = paddle.to_tensor([encoded_text['input_ids']])
print("input_ids : {}".format(input_ids))
segment_ids = paddle.to_tensor([encoded_text['token_type_ids']])
print("token_type_ids : {}".format(segment_ids))
# 此时即可输入ERNIE模型中得到相应输出
sequence_output, pooled_output = ernie_model(input_ids, segment_ids)
print("Token wise output: {}, Pooled output: {}".format(sequence_output.shape, pooled_output.shape))
input_ids:
[1, 40, 629, 373, 19, 838, 1054, 39, 100, 2]
token_type_ids:
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
input_ids : Tensor(shape=[1, 10], dtype=int64, place=CUDAPlace(0), stop_gradient=True,
[[1 , 40 , 629, 373, 19 , 838, 1054, 39 , 100, 2 ]])
token_type_ids : Tensor(shape=[1, 10], dtype=int64, place=CUDAPlace(0), stop_gradient=True,
[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
Token wise output: [1, 10, 768], Pooled output: [1, 768]
加载数据集
# 首次运行需要把注释(#)去掉
# !unzip -oq /home/aistudio/data/data78992/bq_corpus.zip
# 删除解压后的无用文件
!rm -r __MACOSX
查看数据
import pandas as pd
train_data = "./bq_corpus/train.tsv"
train_data = pd.read_csv(train_data, header=None, sep='\t', error_bad_lines=False)
=False)
train_data.head(10)
b'Skipping line 20746: expected 3 fields, saw 4\nSkipping line 54107: expected 3 fields, saw 4\nSkipping line 65083: expected 3 fields, saw 4\nSkipping line 69869: expected 3 fields, saw 4\n'
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 用微信都6年,微信没有微粒贷功能 | 4。号码来微粒贷 | 0.0 |
| 1 | 微信消费算吗 | 还有多少钱没还 | 0.0 |
| 2 | 交易密码忘记了找回密码绑定的手机卡也掉了 | 怎么最近安全老是要改密码呢好麻烦 | 0.0 |
| 3 | 你好我昨天晚上申请的没有打电话给我今天之内一定会打吗? | 什么时候可以到账 | 0.0 |
| 4 | “微粒贷开通" | 你好,我的微粒贷怎么没有开通呢 | 0.0 |
| 5 | 为什么借款后一直没有给我回拨电话 | 怎么申请借款后没有打电话过来呢! | 1.0 |
| 6 | 为什么我每次都提前还款了最后却不给我贷款了 | 30号我一次性还清可以不 | 0.0 |
| 7 | 请问一天是否都是限定只能转入或转出都是五万。 | 微众多少可以赎回短期理财 | 0.0 |
| 8 | 微粒咨询电话号码多少 | 你们的人工客服电话是多少 | 1.0 |
| 9 | 已经在银行换了新预留号码。 | 我现在换了电话号码,这个需要更换吗 | 1.0 |
读取数据
class bq_corpusfile(DatasetBuilder):
SPLITS = {
'train': 'bq_corpus/train.tsv',
'dev': 'bq_corpus/dev.tsv',
}
def _get_data(self, mode, **kwargs):
filename = self.SPLITS[mode]
return filename
def _read(self, filename):
with open(filename, 'r', encoding='utf-8') as f:
head = None
for line in f:
data = line.strip().split("\t")
if not head:
head = data
else:
query, title, label = data
yield {"query": query, "title": title, "label": label}
def get_labels(self):
return ["0", "1"]
def load_dataset(name=None,
data_files=None,
splits=None,
lazy=None,
**kwargs):
reader_cls = bq_corpusfile
print(reader_cls)
if not name:
reader_instance = reader_cls(lazy=lazy, **kwargs)
else:
reader_instance = reader_cls(lazy=lazy, name=name, **kwargs)
datasets = reader_instance.read_datasets(data_files=data_files, splits=splits)
return datasets
train_ds, dev_ds = load_dataset(splits=["train", "dev"])
<class '__main__.lcqmcfile'>
模型构建
from functools import partial
from paddlenlp.data import Stack, Tuple, Pad
from utils import convert_example, create_dataloader
batch_size = 64
max_seq_length = 128
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment
Stack(dtype="int64") # label
): [data for data in fn(samples)]
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
dev_data_loader = create_dataloader(
dev_ds,
mode='dev',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
训练配置
from paddlenlp.transformers import LinearDecayWithWarmup
# 训练过程中的最大学习率
learning_rate = 5e-5
# 训练轮次
epochs = 3
# 学习率预热比例
warmup_proportion = 0.1
# 权重衰减系数,类似模型正则项策略,避免模型过拟合
weight_decay = 0.01
num_training_steps = len(train_data_loader) * epochs
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
])
criterion = paddle.nn.loss.CrossEntropyLoss()
metric = paddle.metric.Accuracy()
模型训练
import paddle.nn.functional as F
from utils import evaluate
global_step = 0
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, segment_ids, labels = batch
logits = model(input_ids, segment_ids)
loss = criterion(logits, labels)
probs = F.softmax(logits, axis=1)
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 10 == 0 :
print("global step %d, epoch: %d, batch: %d, loss: %.5f, acc: %.5f" % (global_step, epoch, step, loss, acc))
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
evaluate(model, criterion, metric, dev_data_loader)
global step 4510, epoch: 3, batch: 1384, loss: 0.07455, acc: 0.95648
global step 4520, epoch: 3, batch: 1394, loss: 0.11048, acc: 0.95652
global step 4530, epoch: 3, batch: 1404, loss: 0.26649, acc: 0.95652
global step 4540, epoch: 3, batch: 1414, loss: 0.09485, acc: 0.95657
global step 4550, epoch: 3, batch: 1424, loss: 0.05482, acc: 0.95667
global step 4560, epoch: 3, batch: 1434, loss: 0.02699, acc: 0.95674
global step 4570, epoch: 3, batch: 1444, loss: 0.10255, acc: 0.95674
global step 4580, epoch: 3, batch: 1454, loss: 0.12598, acc: 0.95688
global step 4590, epoch: 3, batch: 1464, loss: 0.02808, acc: 0.95690
global step 4600, epoch: 3, batch: 1474, loss: 0.04774, acc: 0.95693
global step 4610, epoch: 3, batch: 1484, loss: 0.05953, acc: 0.95699
global step 4620, epoch: 3, batch: 1494, loss: 0.04695, acc: 0.95705
global step 4630, epoch: 3, batch: 1504, loss: 0.14425, acc: 0.95699
global step 4640, epoch: 3, batch: 1514, loss: 0.16755, acc: 0.95693
global step 4650, epoch: 3, batch: 1524, loss: 0.16033, acc: 0.95701
global step 4660, epoch: 3, batch: 1534, loss: 0.06800, acc: 0.95695
global step 4670, epoch: 3, batch: 1544, loss: 0.14630, acc: 0.95697
global step 4680, epoch: 3, batch: 1554, loss: 0.17122, acc: 0.95700
eval loss: 0.50144, accu: 0.84728
Baseline 运行3个epoch,用时约22分钟。
- epoch1:eval loss: 0.38870, accu: 0.84378
- epoch2:eval loss: 0.42888, accu: 0.84608
- epoch3:eval loss: 0.50144, accu: 0.84728
模型保存
model.save_pretrained('xyjd')
tokenizer.save_pretrained('xyjd')
模型预测
测试结果
from utils import predict
import pandas as pd
label_map = {0:'0', 1:'1'}
def preprocess_prediction_data(data):
examples = []
for query, title in data:
examples.append({"query": query, "title": title})
# print(len(examples),': ',query,"---", title)
return examples
test_file = 'bq_corpus/test.tsv'
data = pd.read_csv(test_file, header=None, sep='\t')
# print(data.shape)
data1 = list(data.values)
examples = preprocess_prediction_data(data1)
输出 tsv 文件
results = predict(
model, examples, tokenizer, label_map, batch_size=batch_size)
for idx, text in enumerate(examples):
print('Data: {} \t Label: {}'.format(text, results[idx]))
data2 = []
for i in range(len(data1)):
data2.extend(results[i])
data['label'] = data2
print(data.shape)
data.to_csv('bq_corpus.tsv', header=None, sep='\t')
在测试集上的部分预测结果展示:

作者简介

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 1
1 0
0- 0



 已为社区贡献1438条内容
已为社区贡献1438条内容

所有评论(0)