
基于PaddlePaddle的ConvS2S论文复现
机器翻译,convs2s的PaddlePaddle复现
基于PaddlePaddle的ConvS2S论文复现
Convolutional Sequence to Sequence Learning
机器翻译(Machine Translation)是利用计算机将一种自然语言(源语言)转换为另一种自然语言(目标语言)的过程,输入为源语言句子,输出为相应的目标语言的句子。
本项目是基于卷积的机器翻译模型ConvS2S的PaddlePaddle 实现,该模型不仅能并行计算,还可以通过层叠的方式捕捉长距离依赖关系。
注:本项目并未达到论文指标,在enro数据集上bleu为18.80,fairseq的eoro bleu为30.02。
一、准备工作
# 解压模型
!unzip /home/aistudio/ConvS2S.zip
# 拷贝数据、权重
!cp /home/aistudio/data/data110614/wmt16_enro_bpe.zip /home/aistudio/ConvS2S/
!cp /home/aistudio/data/data111190/ckpt.zip /home/aistudio/ConvS2S/
# 解压数据、权重
%cd /home/aistudio/ConvS2S/
!unzip /home/aistudio/ConvS2S/wmt16_enro_bpe.zip
!unzip /home/aistudio/ConvS2S/ckpt.zip
/home/aistudio/ConvS2S
Archive: /home/aistudio/ConvS2S/wmt16_enro_bpe.zip
creating: wmt16_enro_bpe/
inflating: wmt16_enro_bpe/corpus.bpe.en
inflating: wmt16_enro_bpe/corpus.bpe.ro
inflating: wmt16_enro_bpe/newsdev2016.bpe.en
inflating: wmt16_enro_bpe/newsdev2016.bpe.ro
inflating: wmt16_enro_bpe/preprocess.py
inflating: wmt16_enro_bpe/vocab.en
inflating: wmt16_enro_bpe/vocab.ro
Archive: /home/aistudio/ConvS2S/ckpt.zip
creating: ckpt/
creating: ckpt/epoch_100/
inflating: ckpt/epoch_100/convs2s.pdopt
inflating: ckpt/epoch_100/convs2s.pdparams
# 按照依赖
!pip install -r requirements.txt
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting attrdict (from -r requirements.txt (line 1))
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/ef/97/28fe7e68bc7adfce67d4339756e85e9fcf3c6fd7f0c0781695352b70472c/attrdict-2.0.1-py2.py3-none-any.whl
Requirement already satisfied: tqdm in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from -r requirements.txt (line 2)) (4.36.1)
Requirement already satisfied: six in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from attrdict->-r requirements.txt (line 1)) (1.15.0)
Installing collected packages: attrdict
Successfully installed attrdict-2.0.1
二、数据处理
公开数据集:WMT 翻译大赛是机器翻译领域最具权威的国际评测大赛,其中英罗马翻译任务提供了一个中等规模的数据集,这个数据集是较多论文中使用的数据集,也是 ConvS2S论文中用到的一个数据集。
本项目使用WMT’16 EN-RO 数据集作为示例提供。英罗马数据集共2.86M训练集,1999条测试集。本项目已采用bpe分词处理好,把共现概率最高的字符相连成子词。
三、数据加载
-
由于组batch时需要把长短不一的句子pad成相同长度,若有特长的句子会导致整个batch填充过多,影响训练稳定性和速度。
-
fairseq将长度相近的句子组成一个batch,并且设置max_tokens=4000控制整个batch的词数(src或tgt的最大tokens数),这样会有动态的batchsize。
-
当batch句子过短时,用max_sentences控制最大的batchsize以防止显存溢出。平均一句为30tokens,4000tokens约有128batchsize。
-
实现上我一开始是用桶的思想,把句子按照长度,映射到1024个桶里,哪个桶先装满max_tokens就yield并清空桶.
-
后面发现有许多bug,于是研究了下源码,fairseq中先把数据索引打乱后,然后在依次对tgt和src按照句长用归并排序(稳定),这样得到的结果是
按长度递增(由于先前shuffle过,并以epoch数为随机种子,相同句长的句子在不同epoch顺序不同),最后对所有batch的索引shuffle,得到每次不同句长的batch。
-
注:恢复训练时需要设置sampler的epoch为last_epoch
import yaml
import argparse
from data import prep_dataset,prep_loader
from utils import same_seeds
from attrdict import AttrDict
from utils import logger
from models import build_model
# 加载数据
conf = AttrDict(yaml.load(open('config/en2ro.yaml', 'r', encoding='utf-8'), Loader=yaml.FullLoader))
same_seeds(seed=conf.train.random_seed)
logger.info('Prep | Preparaing train datasets...')
train_dset = prep_dataset(conf, mode='train')
dev_dset = prep_dataset(conf, mode='dev')
train_loader = prep_loader(conf, train_dset, mode='train')
dev_loader = prep_loader(conf, dev_dset, mode='dev')
2021-10-08 22:43:12,643 | ConvS2S: Prep | Preparaing train datasets...
----- Resume Training: set sampler's epoch to 100 as a random seed
----- Resume Training: set sampler's epoch to 100 as a random seed
# 看下batch的shape,[bsz,tokens] 两者相乘总数不超过7000(conf.train.max_tokens),且句数最大为256(conf.train.max_sentences,防止句子太多显存溢出)
for i,batch_data in enumerate(dev_loader):
if i==5:
break
src_tokens, tgt_tokens, lbl_tokens = batch_data
print(f'src shape: {src_tokens.shape} | tgt input shape: {tgt_tokens.shape} | tgt label shape: {lbl_tokens.shape}')
src shape: [256, 13] | tgt input shape: [256, 20] | tgt label shape: [256, 20, 1]
src shape: [240, 17] | tgt input shape: [240, 24] | tgt label shape: [240, 24, 1]
src shape: [216, 21] | tgt input shape: [216, 33] | tgt label shape: [216, 33, 1]
src shape: [200, 25] | tgt input shape: [200, 36] | tgt label shape: [200, 36, 1]
src shape: [168, 28] | tgt input shape: [168, 41] | tgt label shape: [168, 41, 1]
# 看下对应的数据
from data import prep_vocab
src_vocab, tgt_vocab = prep_vocab(conf)
for i,(src_idxs,tgt_idxs,lbl_idxs) in enumerate(zip(src_tokens,tgt_tokens,lbl_tokens)):
if i==5:
break
src_words=src_vocab.to_tokens(src_idxs.numpy())
tgt_words=tgt_vocab.to_tokens(tgt_idxs.numpy())
lbl_words=tgt_vocab.to_tokens(lbl_idxs.squeeze().numpy())
print(f"[src sentence]: {' '.join(src_words)} \n[tgt sentence]: {' '.join(tgt_words)} \n [lbl sentence]: {' '.join(lbl_words)} \n")
# src句末加eos即</s>,tgt句首加bos即<s>,lbl句末加</s>;src在左边pad,而tgt和lbl在右边pad;(fairseq中tgt句首加的还是eos)
[src sentence]: <pad> <pad> <pad> a source close to SA@@ B said it was too early to say what it would do since no offer has been made . </s>
[tgt sentence]: <s> o sursă apropiată a SA@@ B a menționat că e prea devreme de spus ce va face , întrucât nu au primit nicio ofertă . <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad>
[lbl sentence]: o sursă apropiată a SA@@ B a menționat că e prea devreme de spus ce va face , întrucât nu au primit nicio ofertă . </s> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad>
[src sentence]: <pad> <pad> <pad> according to a press release from producers , spec@@ tre is just the third Bond film chosen as a RF@@ P since 1946 . </s>
[tgt sentence]: <s> conform unui comunicat de presă al producătorilor , " Spec@@ tre " este al treilea film Bond ales ca RF@@ P din 1946 încoace . <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad>
[lbl sentence]: conform unui comunicat de presă al producătorilor , " Spec@@ tre " este al treilea film Bond ales ca RF@@ P din 1946 încoace . </s> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad>
[src sentence]: <pad> <pad> <pad> the new Sky@@ trans has re @-@ employed some of the airline staff who lost their jobs when the original Sky@@ trans collapsed . </s>
[tgt sentence]: <s> noul Sky@@ trans a re@@ angajat o parte a personalului companiei aeriene care își pierd@@ useră slujba când vechiul Sky@@ trans a intrat în faliment . <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad>
[lbl sentence]: noul Sky@@ trans a re@@ angajat o parte a personalului companiei aeriene care își pierd@@ useră slujba când vechiul Sky@@ trans a intrat în faliment . </s> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad>
[src sentence]: <pad> <pad> <pad> in addition , he does not even receive the " negative monitoring " for example . his predecessor requested it as a priority . </s>
[tgt sentence]: <s> în plus , nu primeste nici macar " monitorizarea neg@@ ativa " pe care , de exemplu , predeces@@ orul sau o cerea cu prioritate . <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad>
[lbl sentence]: în plus , nu primeste nici macar " monitorizarea neg@@ ativa " pe care , de exemplu , predeces@@ orul sau o cerea cu prioritate . </s> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad>
[src sentence]: <pad> <pad> <pad> the 15 @-@ year @-@ old was arrested in the Philadelphia area in August , when law enforcement authorities fo@@ iled the plot . </s>
[tgt sentence]: <s> băiatul în vârstă de 15 ani a fost arestat în zona Philadelphia în august , când autoritățile de aplicare a legii au de@@ jucat planul . <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad>
[lbl sentence]: băiatul în vârstă de 15 ani a fost arestat în zona Philadelphia în august , când autoritățile de aplicare a legii au de@@ jucat planul . </s> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad>
四、模型训练
模型介绍
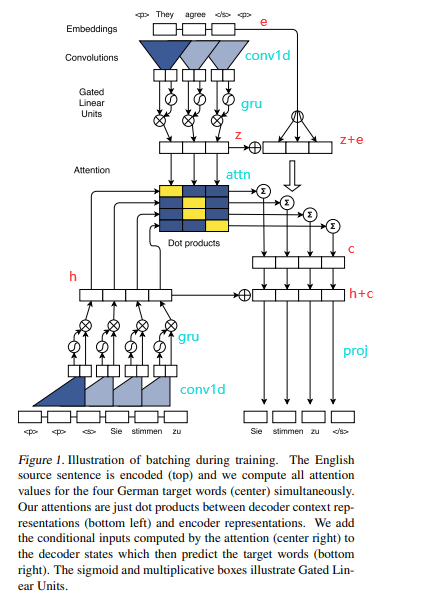
- 整体结构: ConvS2S是经典的encoder、decoder的结构,分别堆叠了多层卷积块。上图中上面的是encoder的结构(嵌入和一个卷积块),最下面是decoder的结构,中间的矩形代表decoder的某层与encoder的输出进行多步注意力,具体为:
- embed:encoder、decoder分别有个嵌入层,包含词嵌入和位置嵌入,分别得到w和p,将两者相加得到嵌入表示e。
- conv block:encoder、decoder的卷积块结构相同,基本上都是核为3的一维卷积,通道为输入通道数d的两倍2d,并使用门控线性函数(GLU)将一半通道的输出作为门控,从另一半中抽取需要的时序信息,最终还是得到d维的通道。除此之外,末尾几层通道数会变大,与上一层输出作残差连接时需要用线性层把输入e扩展到相应通道数。
- multi step attention: 多步注意力即decoder每层输出hi都和encoder输出z做注意力计算,然后用注意力权重抽取encoder的z+e的信息,得到上下文向量c,与当前decoder层的输出hi相加得到hi+c,或者作为decoder下一层输入,或者用proj得到batch*vocab_size的logits,用以表示输出的词
- 模型特点:
- 采用卷积结构,复杂度低:n个词,卷积核宽为k,复杂度为O(n/k),而循环神经网络复杂度为O(n)。速度非常快,能够并行训练。
- 通过堆叠多层卷积,可以扩大感受野,从而捕获长距离的依赖关系,从而用卷积作时序任务。
模型结构
enro的模型,encoder、decoder各有20层,且所有层核宽为3、隐藏层维度为512。

from models import build_model
model = build_model(conf, is_test=False)
# encoder 结构
print(model.encoder)
Train model convs2s_wmt_en_ro created!
Pretrained weight load from:ckpt/epoch_100/convs2s.pdparams!
ConvS2SEncoder(
(dropout_module): PaddleseqDropout()
(embed_tokens): Embedding(24232, 512, padding_idx=1, sparse=False)
(embed_positions): LearnedPositionalEmbedding(1024, 512, padding_idx=1, sparse=False)
(fc1): Linear(in_features=512, out_features=512, dtype=float32)
(projections): LayerList(
(0): None
(1): None
(2): None
(3): None
(4): None
(5): None
(6): None
(7): None
(8): None
(9): None
(10): None
(11): None
(12): None
(13): None
(14): None
(15): None
(16): None
(17): None
(18): None
(19): None
)
(convolutions): LayerList(
(0): ConvNLC(512, 1024, kernel_size=(3,), padding=(1,))
(1): ConvNLC(512, 1024, kernel_size=(3,), padding=(1,))
(2): ConvNLC(512, 1024, kernel_size=(3,), padding=(1,))
(3): ConvNLC(512, 1024, kernel_size=(3,), padding=(1,))
(4): ConvNLC(512, 1024, kernel_size=(3,), padding=(1,))
(5): ConvNLC(512, 1024, kernel_size=(3,), padding=(1,))
(6): ConvNLC(512, 1024, kernel_size=(3,), padding=(1,))
(7): ConvNLC(512, 1024, kernel_size=(3,), padding=(1,))
(8): ConvNLC(512, 1024, kernel_size=(3,), padding=(1,))
(9): ConvNLC(512, 1024, kernel_size=(3,), padding=(1,))
(10): ConvNLC(512, 1024, kernel_size=(3,), padding=(1,))
(11): ConvNLC(512, 1024, kernel_size=(3,), padding=(1,))
(12): ConvNLC(512, 1024, kernel_size=(3,), padding=(1,))
(13): ConvNLC(512, 1024, kernel_size=(3,), padding=(1,))
(14): ConvNLC(512, 1024, kernel_size=(3,), padding=(1,))
(15): ConvNLC(512, 1024, kernel_size=(3,), padding=(1,))
(16): ConvNLC(512, 1024, kernel_size=(3,), padding=(1,))
(17): ConvNLC(512, 1024, kernel_size=(3,), padding=(1,))
(18): ConvNLC(512, 1024, kernel_size=(3,), padding=(1,))
(19): ConvNLC(512, 1024, kernel_size=(3,), padding=(1,))
)
(fc2): Linear(in_features=512, out_features=512, dtype=float32)
)
# decoder 结构
print(model.decoder)
ConvS2SDecoder(
(dropout_module): PaddleseqDropout()
(embed_tokens): Embedding(37296, 512, padding_idx=1, sparse=False)
(embed_positions): LearnedPositionalEmbedding(1024, 512, padding_idx=1, sparse=False)
(fc1): Linear(in_features=512, out_features=512, dtype=float32)
(projections): LayerList(
(0): None
(1): None
(2): None
(3): None
(4): None
(5): None
(6): None
(7): None
(8): None
(9): None
(10): None
(11): None
(12): None
(13): None
(14): None
(15): None
(16): None
(17): None
(18): None
(19): None
)
(convolutions): LayerList(
(0): LinearizedConvolution(512, 1024, kernel_size=(3,), padding=(2,))
(1): LinearizedConvolution(512, 1024, kernel_size=(3,), padding=(2,))
(2): LinearizedConvolution(512, 1024, kernel_size=(3,), padding=(2,))
(3): LinearizedConvolution(512, 1024, kernel_size=(3,), padding=(2,))
(4): LinearizedConvolution(512, 1024, kernel_size=(3,), padding=(2,))
(5): LinearizedConvolution(512, 1024, kernel_size=(3,), padding=(2,))
(6): LinearizedConvolution(512, 1024, kernel_size=(3,), padding=(2,))
(7): LinearizedConvolution(512, 1024, kernel_size=(3,), padding=(2,))
(8): LinearizedConvolution(512, 1024, kernel_size=(3,), padding=(2,))
(9): LinearizedConvolution(512, 1024, kernel_size=(3,), padding=(2,))
(10): LinearizedConvolution(512, 1024, kernel_size=(3,), padding=(2,))
(11): LinearizedConvolution(512, 1024, kernel_size=(3,), padding=(2,))
(12): LinearizedConvolution(512, 1024, kernel_size=(3,), padding=(2,))
(13): LinearizedConvolution(512, 1024, kernel_size=(3,), padding=(2,))
(14): LinearizedConvolution(512, 1024, kernel_size=(3,), padding=(2,))
(15): LinearizedConvolution(512, 1024, kernel_size=(3,), padding=(2,))
(16): LinearizedConvolution(512, 1024, kernel_size=(3,), padding=(2,))
(17): LinearizedConvolution(512, 1024, kernel_size=(3,), padding=(2,))
(18): LinearizedConvolution(512, 1024, kernel_size=(3,), padding=(2,))
(19): LinearizedConvolution(512, 1024, kernel_size=(3,), padding=(2,))
)
(attention): LayerList(
(0): AttentionLayer(
(in_projection): Linear(in_features=512, out_features=512, dtype=float32)
(out_projection): Linear(in_features=512, out_features=512, dtype=float32)
)
(1): AttentionLayer(
(in_projection): Linear(in_features=512, out_features=512, dtype=float32)
(out_projection): Linear(in_features=512, out_features=512, dtype=float32)
)
(2): AttentionLayer(
(in_projection): Linear(in_features=512, out_features=512, dtype=float32)
(out_projection): Linear(in_features=512, out_features=512, dtype=float32)
)
(3): AttentionLayer(
(in_projection): Linear(in_features=512, out_features=512, dtype=float32)
(out_projection): Linear(in_features=512, out_features=512, dtype=float32)
)
(4): AttentionLayer(
(in_projection): Linear(in_features=512, out_features=512, dtype=float32)
(out_projection): Linear(in_features=512, out_features=512, dtype=float32)
)
(5): AttentionLayer(
(in_projection): Linear(in_features=512, out_features=512, dtype=float32)
(out_projection): Linear(in_features=512, out_features=512, dtype=float32)
)
(6): AttentionLayer(
(in_projection): Linear(in_features=512, out_features=512, dtype=float32)
(out_projection): Linear(in_features=512, out_features=512, dtype=float32)
)
(7): AttentionLayer(
(in_projection): Linear(in_features=512, out_features=512, dtype=float32)
(out_projection): Linear(in_features=512, out_features=512, dtype=float32)
)
(8): AttentionLayer(
(in_projection): Linear(in_features=512, out_features=512, dtype=float32)
(out_projection): Linear(in_features=512, out_features=512, dtype=float32)
)
(9): AttentionLayer(
(in_projection): Linear(in_features=512, out_features=512, dtype=float32)
(out_projection): Linear(in_features=512, out_features=512, dtype=float32)
)
(10): AttentionLayer(
(in_projection): Linear(in_features=512, out_features=512, dtype=float32)
(out_projection): Linear(in_features=512, out_features=512, dtype=float32)
)
(11): AttentionLayer(
(in_projection): Linear(in_features=512, out_features=512, dtype=float32)
(out_projection): Linear(in_features=512, out_features=512, dtype=float32)
)
(12): AttentionLayer(
(in_projection): Linear(in_features=512, out_features=512, dtype=float32)
(out_projection): Linear(in_features=512, out_features=512, dtype=float32)
)
(13): AttentionLayer(
(in_projection): Linear(in_features=512, out_features=512, dtype=float32)
(out_projection): Linear(in_features=512, out_features=512, dtype=float32)
)
(14): AttentionLayer(
(in_projection): Linear(in_features=512, out_features=512, dtype=float32)
(out_projection): Linear(in_features=512, out_features=512, dtype=float32)
)
(15): AttentionLayer(
(in_projection): Linear(in_features=512, out_features=512, dtype=float32)
(out_projection): Linear(in_features=512, out_features=512, dtype=float32)
)
(16): AttentionLayer(
(in_projection): Linear(in_features=512, out_features=512, dtype=float32)
(out_projection): Linear(in_features=512, out_features=512, dtype=float32)
)
(17): AttentionLayer(
(in_projection): Linear(in_features=512, out_features=512, dtype=float32)
(out_projection): Linear(in_features=512, out_features=512, dtype=float32)
)
(18): AttentionLayer(
(in_projection): Linear(in_features=512, out_features=512, dtype=float32)
(out_projection): Linear(in_features=512, out_features=512, dtype=float32)
)
(19): AttentionLayer(
(in_projection): Linear(in_features=512, out_features=512, dtype=float32)
(out_projection): Linear(in_features=512, out_features=512, dtype=float32)
)
)
(fc2): Linear(in_features=512, out_features=512, dtype=float32)
(fc3): Linear(in_features=512, out_features=37296, dtype=float32)
)
模型训练
单卡训练
python main.py --config config/en2ro.yaml --mode train
多卡训练(100epoch开始恢复训练)
bash run_multi_gpu.sh --config config/en2ro.yaml
-- last_epoch 100
-- resume ckpt/epoch_100
可以在 config/en2ro.yaml 件中设置相应的参数,如果要恢复训练需指定恢复的轮数last_epoch,和恢复的权重路径resume,其他参数详见yaml文件。
!python main.py --config config/en2ro.yaml --mode train
训练日志:
2021-10-08 13:28:35,043 | ConvS2S: Prep | Preparaing train datasets...
----- Resume Training: set sampler's epoch to 100 as a random seed
----- Resume Training: set sampler's epoch to 100 as a random seed
2021-10-08 13:29:55,104 | ConvS2S: Prep | Train num:2862497 | Val num:1999 | Cost 80.06026077270508 s
2021-10-08 13:29:55,104 | ConvS2S: cfg:AttrDict({'data': {'training_file': 'wmt16_enro_bpe/corpus.bpe.en,wmt16_enro_bpe/corpus.bpe.ro', 'validation_file': 'wmt16_enro_bpe/newsdev2016.bpe.en,wmt16_enro_bpe/newsdev2016.bpe.ro', 'predict_file': 'wmt16_enro_bpe/newsdev2016.bpe.en,wmt16_enro_bpe/newsdev2016.bpe.ro', 'output_file': 'output/predict.txt,output/reference.txt', 'src_vocab_fpath': 'wmt16_enro_bpe/vocab.en', 'tgt_vocab_fpath': 'wmt16_enro_bpe/vocab.ro', 'special_token': ['<s>', '</s>', '<unk>', '<pad>'], 'pad_vocab': True, 'pad_factor': 8}, 'model': {'model_name': 'convs2s_wmt_en_ro', 'dropout': 0.2, 'init_from_params': 'ckpt/epoch_100', 'save_model': 'ckpt', 'src_vocab_size': 24232, 'tgt_vocab_size': 37296, 'bos_idx': 0, 'pad_idx': 1, 'eos_idx': 2, 'unk_idx': 3, 'min_length': 0, 'max_length': 1024, 'resume': 'ckpt/epoch_100'}, 'learning_strategy': {'use_nesterov': True, 'momentum': 0.99, 'weight_decay': 0.0001, 'clip_norm': 0.1, 'learning_rate': 0.5, 'reset_lr': True, 'patience': 1, 'lr_shrink': 0.8, 'force_anneal': 50, 'min_lr': 0.0001, 'label_smooth_eps': 0.1}, 'train': {'random_seed': 2021, 'use_gpu': True, 'num_workers': 1, 'max_epoch': 200, 'avg_steps': 2650, 'auto_cast': True, 'fp16_init_scale': 128, 'amp_scale_window': False, 'growth_interval': 128, 'accumulate_batchs': 1, 'log_step': 400, 'max_tokens': 7000, 'max_sentences': 256, 'batch_size_factor': 8, 'save_epoch': 10, 'stop_patience': -1, 'last_epoch': 100}, 'generate': {'infer_batch_size': 32, 'infer_max_tokens': 4000, 'infer_max_sentences': 'None', 'beam_size': 5, 'n_best': 1, 'max_out_len': 0, 'rel_len': True, 'alpha': 0.6}, 'eval': False, 'SAVE': 'output'})
2021-10-08 13:29:55,104 | ConvS2S: Prep | Loading models...
W1008 13:29:55.106002 440 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W1008 13:29:55.115583 440 device_context.cc:422] device: 0, cuDNN Version: 7.6.
Train model convs2s_wmt_en_ro created!
Pretrained weight load from:ckpt/epoch_100/convs2s.pdparams!
2021-10-08 13:30:02,391 | ConvS2S: Train | Training...
2021-10-08 13:30:05,907 | ConvS2S: ----- Resume Training: Load model and optmizer states from ckpt/epoch_100
2021-10-08 13:30:16,231 | ConvS2S: Train | Epoch: [102/200] | Step: [0/10842.0] | Avg bsz:264.0 Avg loss: 3.467 | nll_loss:1.694 | ppl: 3.237 | Speed:38.75 step/s
2021-10-08 13:32:22,373 | ConvS2S: Train | Epoch: [102/200] | Step: [400/12244.0] | Avg bsz:233.8 Avg loss: 3.420 | nll_loss:1.637 | ppl: 3.111 | Speed:3.17 step/s
五、模型推断
-
整体预测是自回归的,即预测当前词需要前几个词作为输入,再预测下个词。并且采用beam=5的集束搜索,从而提升预测效果。
-
在模型推断时使用encoder部分不变,decoder部分的卷积变为线性卷积,即把3dim的权重拉成2dim,然后与输入作全连接。
-
其中输入用一个命名元组作为buffer,提前将前几步结果缓存下了,用于加快运算速度。(预测时k=3,即预测1个词需要前3个词,再预测下一个词时,把上个词再添加进去。buffer类似队列,每次入队一个新词,出队一个最早的词),如:
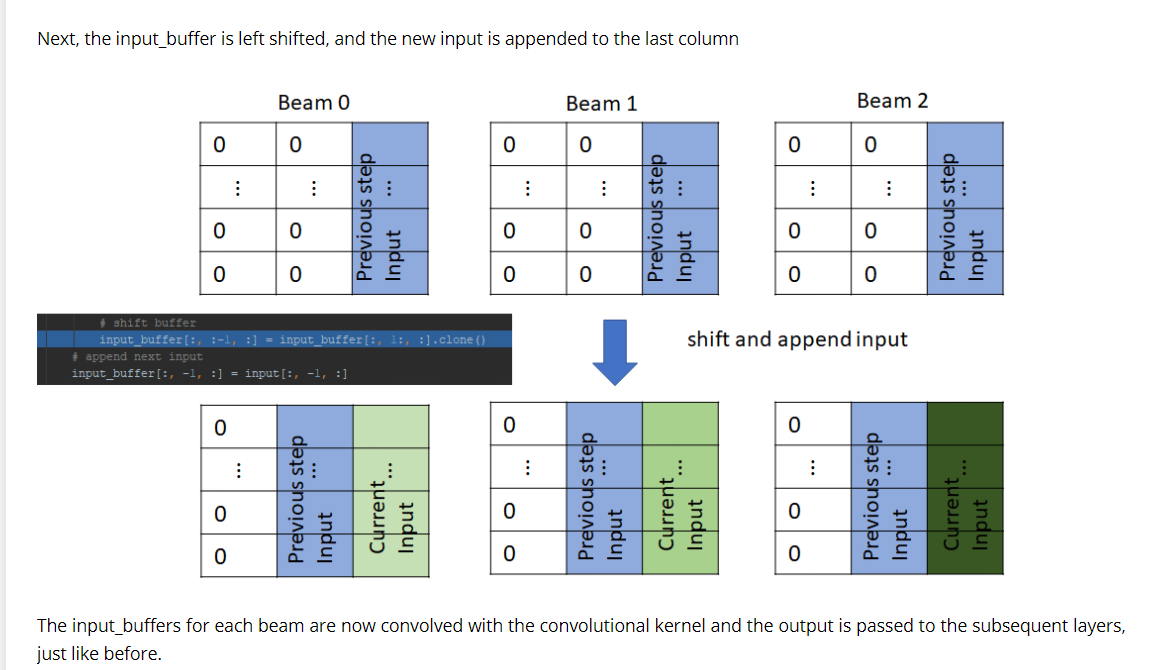
# 模型推断,生成译文
-Decoder_systems)
```python
# 模型推断,生成译文
!python main.py --config config/en2ro.yaml --mode pred
2021-10-08 22:50:09,882 | ConvS2S: Prep | Loading models...
Infer model convs2s_wmt_en_ro created!
W1008 22:50:09.884207 1714 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W1008 22:50:09.887394 1714 device_context.cc:422] device: 0, cuDNN Version: 7.6.
Pretrained weight load from:ckpt/epoch_100/convs2s.pdparams!
2021-10-08 22:50:21,255 | ConvS2S: Pred | Predicting...
2021-10-08 22:50:21,256 | ConvS2S: Prep | Test num:1999
2021-10-08 22:50:22,347 | ConvS2S: Loaded weights from ckpt/epoch_100
17it [09:50, 34.76s/it]
六、结果评估
模型最终训练的效果一般可通过测试集来进行测试,机器翻译领域一般计算BLEU值。
使用镜像hub.fastgit.org下载mosesdecoder会快些。
!bash bleu.sh #bleu=18.80
Cloning into 'mosesdecoder'...
remote: Enumerating objects: 148070, done.
remote: Counting objects: 100% (498/498), done.
remote: Compressing objects: 100% (206/206), done.
remote: Total 148070 (delta 315), reused 433 (delta 289), pack-reused 147572
Receiving objects: 100% (148070/148070), 129.86 MiB | 1.31 MiB/s, done.
Resolving deltas: 100% (114341/114341), done.
Checking connectivity... done.
tar (child): mosesdecoder.tar.gz: Cannot open: No such file or directory
tar (child): Error is not recoverable: exiting now
tar: Child returned status 2
tar: Error is not recoverable: exiting now
BLEU = 18.80, 43.9/23.2/14.2/9.0 (BP=0.988, ratio=0.989, hyp_len=52746, ref_len=53359)
It is not advisable to publish scores from multi-bleu.perl. The scores depend on your tokenizer, which is unlikely to be reproducible from your paper or consistent across research groups. Instead you should detokenize then use mteval-v14.pl, which has a standard tokenization. Scores from multi-bleu.perl can still be used for internal purposes when you have a consistent tokenizer.
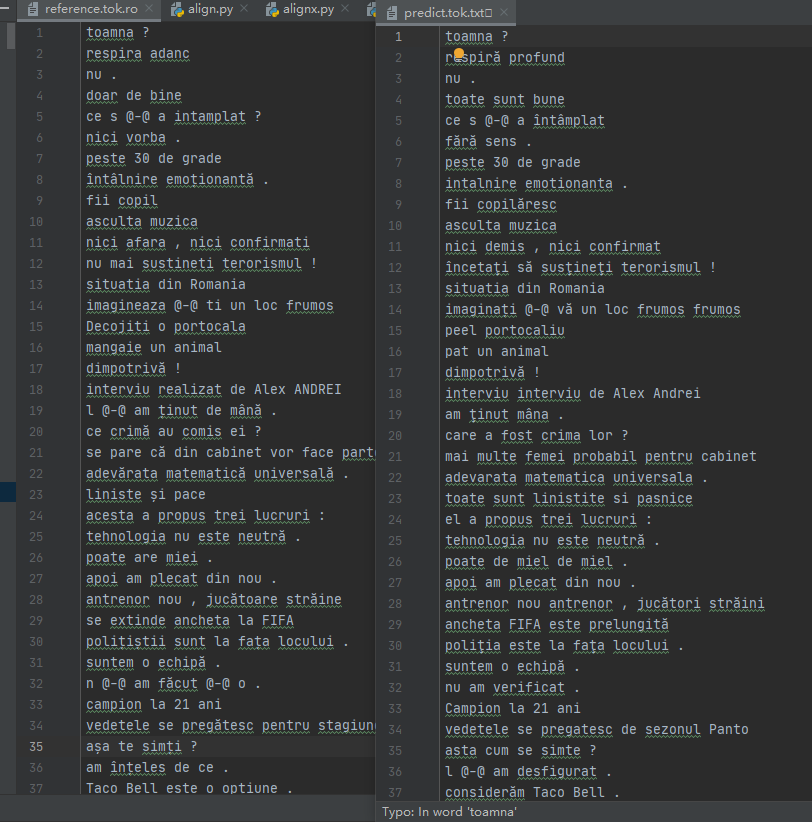
下图左侧是参考文本、右侧是预测文本(见output里的predict.tok.txt):
七、总结展望
(1) 复现这篇ConvS2S差不多花了1个半月,也踩了不少坑,尽管这样还是没有达到指标,可惜!
对于机器翻译我还是个新手,初次接触还是在六月nlp打开营磊子老师的课上,在这之前只是了解transformer模型的结构。因此复现这篇翻译的论文耗时很久,
虽然有遗憾,也学到了不少的东西,我想今后大概率会继续研究机器翻译,这里算是开了个头了。
(2)这里有些坑或者要注意的地方,以供来者避雷:
-
fairseq不易调试: 官方给的demo命令,训练fairseq-train ,生成fairseq-generate,这两个是编译好的,如果在代码里新添加日志不会生效,除非重新编译(我一开始为了搞清楚数据输入,来回编译了几十次QAQ);
后面发现可以替换成直接运行py文件,即:训练python train.py、生成python ./fairseq_cli/generate.py,后面接的参数不变,
这样加日志就可以避免反复编译了。当然,最好的办法应该是用它的task那一套,然后直接debug(惭愧,现在还没用过)。
-
preprocess: 在en-ro的处理脚本中,有两处修改要注意下:
-
第一个是bpe_operations=40000,该脚本里把训练集的en和ro两种语言的句子放一起构建4w的bpe词表(都是印欧语系),然后分别在en、ro的数据集上apply得到bpe后的数据, 而词汇表是分别对bpe好的训练集里的en、ro分词得到的。
-
第二个是bpe前需要用mosesdecoder把超过175长度的句子过滤掉:
- $mosesdecoder/scripts/training/clean-corpus-n.perl data/corpus.tok $SRC $TRG data/corpus.tok.clean 1 175
-
-
-
*使用mmap存储数据: 内存映射,加载数据时直接从磁盘读取,省了大量内存,虽然会慢点,但读取数据比训练快,所以不影响训练,瓶颈不在加载器。(节省内存,不需要加载数据的时间)
这条本项目尚未实现,留待以后完成。
-
组batch: source_tokens在句末加eos,target_tokens在句首也加eos,label_tokens在句末加eos。然后source_tokens是在左边pad,target_tokens和label_tokens是在右边pad。一般来说target_tokens在句首用sos,与eos区分,但是fairseq源码用的都是eos,我ende试了都是eos,而enro是用的正常sos,感觉并不影响效果。
-
sampler动态的batchsize: 第三章提到过,在句长层次不齐的情况下,能够显著减少pad的个数。shuffle的操作再强调下,首先以epoch数为随机种子,对所有的训练样本按照句长shuffle,然后再用归并排序,结果虽然是由短及长的,但是有很多相同长度的句子,他们的相对顺序被第一次shuffle打乱了。后面第二次shuffle是把不同batch进行打乱,从而每次返回不同长度的batch。
除此之外,我试过从短到长训练,想上去模型会训练的更容易些,但是因为越来越难,所以loss也在不断升上去,而不像打乱batch后loss趋势缓慢下降。所以别想那么多,硬train一发。
-
weight_norm: 该函数可以把某层的参数按照某个维度拆成长度变量g和方向变量v,paddle的该函数与torch的对齐,但是应用在linear上时,paddle linear的权重为[in_features,out_features],因此对out_features拆分应该用nn.utils.weight_norm(linear, dim=1),而torch的linear权重维度:[out_channels,in_features],所以对out_infeatures拆要用nn.utils.weight_norm(linear, dim=0)
-
conv_tbc fairseq中使用conv_tbc替代conv1d算子,速度略快,输入数据需要形如[times,batch,dim],第一位是序列长或token数,第二个是batchsize,第三个是嵌入维度。而paddle的conv1d算子在速度上是conv_tbc的两倍左右,但是占显存较大,conv_tbc占60%显存时paddle的conv1d可能占90%了,总的来说是挺nice的。
使用conv_tbc算子需要频繁转置,即在卷积时需要[times,batch,dim],而在decoder的注意力时需要[batch,times,dim]。在使用paddle的conv1d时,我发现可以使用参数format=‘nlc’,
这样可以使输入数据形如[batch,times,dim],从而统一了卷积和注意力的输入形式,不需要频繁转置,测速发现提升了10%左右。
-
学习率 初始为0.5,然后在每个epoch结束计算验针集的perplexity(ppl),若在验证ppl上没有进步(上升了),就降低一个数量级(x0.1),直到小于1e-1(即=1e-5)时停止训练。参数force_annel=50控制学习率在50次没有下降后强制乘0.1。为了尝试更多样的学习率,本项目每次学习率降低时乘0.8,其他未变。
-
损失函数: 模型训练时使用的是ε=0.1的labelsmooth,同时计算nll损失(不带平滑的交叉熵)用于得到ppl(fairseq中ppl=2nll_loss,而非paddle中底为e)。fairseq中的平滑标签损失是用nll_loss计算出来的,而paddle中是直接用onehot生成平滑标签**(即Ptrue=1-ε,Pfalse=ε)然后计算交叉熵,因此需要单独计算nll_loss(交叉熵,该指标仅用于评估而非训练,故可不用计算梯度)。除此之外,训练时fairseq使用的是sum_loss,一开始我用的是avg_loss,后面为对齐改成sum_loss,然后发现没啥改变orz,最后还是换回了avg_loss。还有一点我比较迷惑的是日志里的loss都除了log2。
-
优化器: Fairseq用的是nag(Nesterov accelerated gradient),一开始我用的adamw,发现学习率设置了0.5损失直接nan了,后改为冲量为0.99的momentom优化器,且use_ nesterov=True;除此之外,还按照论文设置了0.1的梯度裁剪。
-
多卡训练: 做本项目时第一次尝试了多卡训练,发现aistudio的脚本任务每次开的时候机子速度不大一致,慢的时候2steps/s,快的时候有3.1steps/s。我之前用2steps/s在enro数据上跑了60epoch,
每个30分钟,而3.1的话只需要20min,痛心疾首!这个故事告诉我们可以多重跑几次,挑个快点的。在多卡最快情况下为3.1,本地单卡速度为3.5,平均每张卡利用率为88.57%,即4卡加速比为3.54。
-
混合精度:使用 paddle.amp.GradScaler开启混合精度,能够显著提升模型的训练速度(两倍左右),且精度损失不大。
-
梯度累积: 由于多卡训练有通信损耗,可以使用梯度累积的方法,即每隔n次前向,使用累积的梯度更新一次参数。这样能提升1.1-1.2倍速度。本项目设accumulate_batchs=4,即4个steps更新一次参数,
其实用梯度累积n次就相当于模拟了n倍的batchsize,学习率可以相应上调。facebook有篇论文提到梯度累积:Scaling Neural Machine Translation
-
cuda版本: 在对齐时发现本地(cuda11.2)的模型和torch的有较大diff,1e-3,花了两天时间无果。后面挪到v100上对齐(cuda10),直接变成了1e-6,说明模型没问题,猜测是cuda版本问题。
-
解码: 第一次评估bleu时仅有2.5,后面发现生成的句子太长了,设置了max_out_len=256,模型几乎生成的平均都是100多个token,而平均参考句长为30,所以多预测多错,导致bleu爆低。
后面设置相对长度rel_len=True,即相对于src,tgt长max_out_len,bleu才上升到十几,本项目发现max_out_len=0时最好。除此之外,本项目beamsearch预测部分的参考的是transformer的解码,后面发现9月初更新了v2版beamsearch,于fairseq对齐。遂也添加了v2,相较于v1 bleu稍微高些。
-
后处理: 论文里提到当词汇表为word时,后处理时,预测的unk利用attention score,对应到src_token,然后查fast-align构建好的词表,找与src_token对应的tgt_token,如果没有词表就使用src_token替代。当然,用sub-word方式不需要用该方法。我利用fast-align写了按照src和tgt共现频率,生成词表的脚本:fast_align.sh,而后处理里尚未添加替换。
(3)未来工作:
1.添加mmap数据处理和加载的脚本
2.将bleu提到原论文水平
3.添加对unk的后处理
八、参考资料
1.Convolutional Sequence to Sequence Learning
2.fairseq
3.Understanding incremental decoding in fairseq
6.Machine Translation using Transformer
7.俺的github
2021/10/8
既是结束,也是开始,角灰大帝冲冲冲!

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)