
【第六届论文复现赛110题】XLM paddle复现
转自AI Studio,原文链接:XLM — Enhancing BERT for Cross-lingual Language Model论文:https://arxiv.org/abs/1901.07291官方pytorch_code:https://github.com/facebookresearch/XLM第三方pytorchcode:https://github.com/hugging
转自AI Studio,原文链接:
XLM — Enhancing BERT for Cross-lingual Language Model
- 论文:https://arxiv.org/abs/1901.07291
- 官方pytorch_code:https://github.com/facebookresearch/XLM
- 第三方pytorchcode:https://github.com/huggingface/transformers/tree/main/src/transformers/models/xlm
- paddle版本code:https://github.com/JunnYu/xlm_paddle
摘要:
最近的研究证明了生成式预训练对英语自然语言理解的有效性。在这项工作中,我们将这种方法扩展到多种语言,并展示了跨语言预训练的有效性。我们提出了两种学习跨语言语言模型 (XLM) 的方法:一种是仅依赖单语数据的无监督方法,另一种是利用具有新的跨语言语言模型目标的并行数据的监督方法。我们在跨语言分类、无监督和有监督机器翻译方面获得了最先进的结果。在 XNLI 上,我们的方法以 4.9% 的绝对精度提升了最新技术水平。在无监督机器翻译上,我们在 WMT'16 German-English 上获得 34.3 BLEU,将之前的最新技术提高了 9 BLEU 以上。在有监督的机器翻译上,我们在 WMT'16 罗马尼亚语-英语上获得了 38.5 BLEU 的最新技术水平,比之前的最佳方法高出 4 BLEU 以上。
一、预训练任务
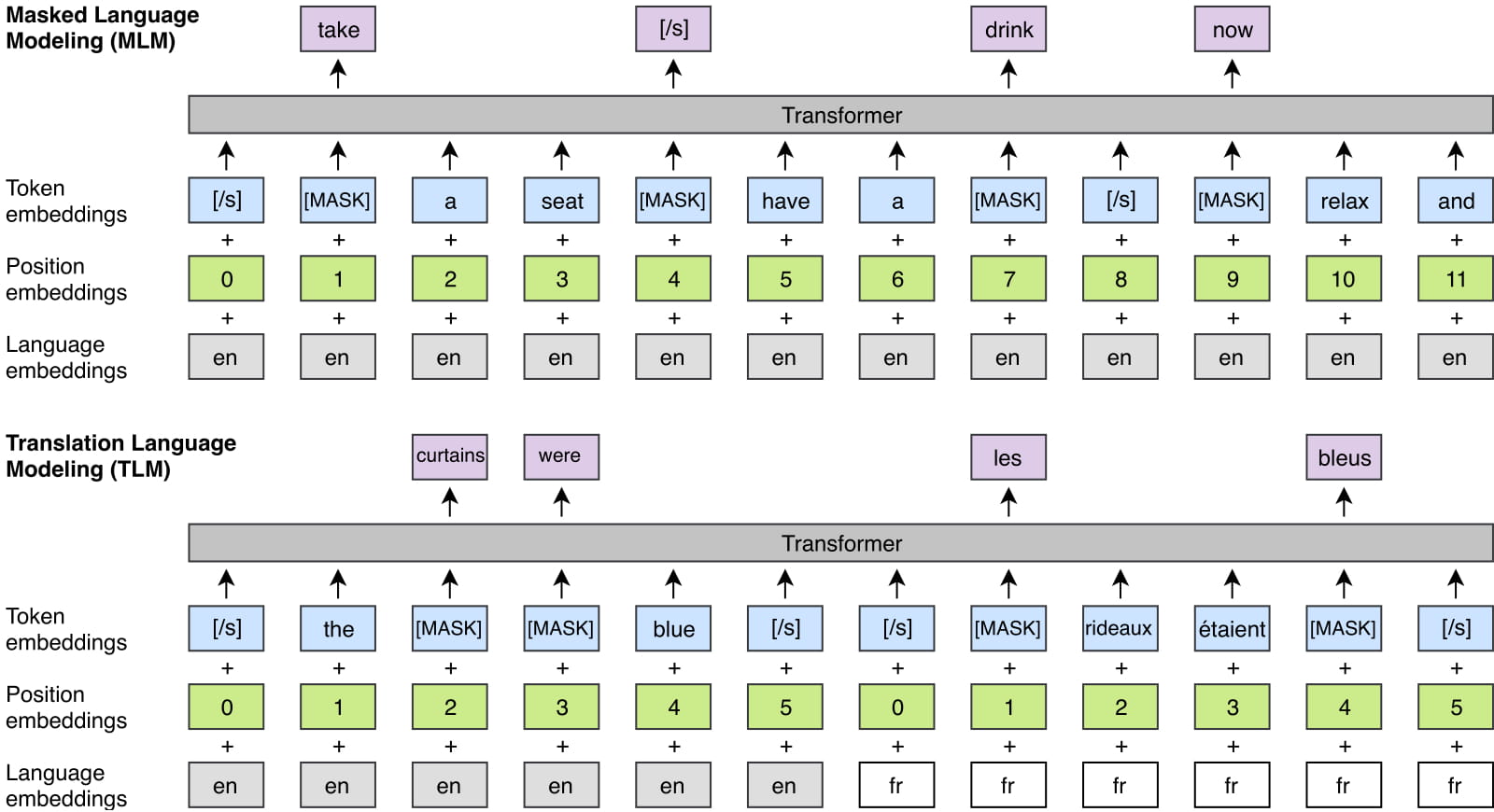
XLM 论文中一共提出了三种预训练任务:CLM、MLM和TLM,下面分别介绍:
- CLM:Causal Language Model,无监督单语单向LM训练任务,就是用Transformer进行LM的单向训练。
- MLM:Masked Language Model,无监督单语双向LM训练任务,与BERT一样。
- TLM:Translation Language Model,有监督翻译LM训练,拼接平行双语语料,然后执行MLM,以期这样能学到翻译的对齐信息。
二、预训练权重
由于论文中提出这三种预训练任务,因此论文分别进行了实验,并且开源了模型权重。
- xlm-mlm-xnli15-1024 : https://huggingface.co/xlm-mlm-xnli15-1024
- xlm-mlm-en-2048: https://huggingface.co/xlm-mlm-en-2048
- xlm-mlm-ende-1024 : https://huggingface.co/xlm-mlm-ende-1024
- xlm-mlm-enfr-1024 : https://huggingface.co/xlm-mlm-enfr-1024
- xlm-mlm-enro-1024: https://huggingface.co/xlm-mlm-enro-1024
- xlm-mlm-tlm-xnli15-1024: https://huggingface.co/xlm-mlm-tlm-xnli15-1024 (本次论文复现主要使用该权重)
- xlm-clm-enfr-1024 : https://huggingface.co/xlm-clm-enfr-1024
- xlm-clm-ende-1024 : https://huggingface.co/xlm-clm-ende-1024
- xlm-mlm-17-1280 : https://huggingface.co/xlm-mlm-17-1280
- xlm-mlm-100-1280 : https://huggingface.co/xlm-mlm-100-1280
在本次论文复现过程种,我们主要使用到了xlm-mlm-tlm-xnli15-1024这个权重。
- 我们可以使用下面的代码手动将该权重转化为paddle版本的权重。
import os
donot_transpose = [
".layer_norm", ".position_embeddings.", ".lang_embeddings.", ".embeddings."
]
def convert_pytorch_checkpoint_to_paddle(pytorch_checkpoint_path="pytorch_model.bin",
paddle_dump_path="model_state.pdparams"):
import torch
import paddle
from collections import OrderedDict
pytorch_state_dict = torch.load(
pytorch_checkpoint_path, map_location="cpu")
paddle_state_dict = OrderedDict()
for k, v in pytorch_state_dict.items():
is_transpose = False
if k[-7:] == ".weight":
if not any(d in k for d in donot_transpose):
if v.ndim == 2:
v = v.transpose(0, 1)
is_transpose = True
oldk = k
k = k.replace("transformer", "xlm")
# remove pred_layer.proj.weight
if "pred_layer.proj.weight" in k:
continue
if "pred_layer.proj.bias" in k:
k = k.replace(".proj.", ".")
print(f"Converting: {oldk} => {k} is_transpose {is_transpose}")
paddle_state_dict[k] = v.data.numpy().astype("float32")
paddle.save(paddle_state_dict, paddle_dump_path)
mapdict = {
"xlm-mlm-tlm-xnli15-1024": "https://huggingface.co/xlm-mlm-tlm-xnli15-1024/resolve/main/merges.txt",
}
for name, url in mapdict.items():
# mkdir
os.makedirs(name, exist_ok=True)
os.chdir(name)
# convert model bin
model_bin_url = url.replace("merges.txt", "pytorch_model.bin")
os.system(f"wget {model_bin_url}")
convert_pytorch_checkpoint_to_paddle()
# convert vocab and merges
merges_url = url
os.system(f"wget {merges_url}")
vocab_url = url.replace("merges.txt", "vocab.json")
os.system(f"wget {vocab_url}")
os.chdir("../")
- 我们也可以加载转化好的paddle权重,链接在这里:https://huggingface.co/junnyu/xlm-mlm-tlm-xnli15-1024-paddle
三、准备工作
为了确保本次论文复现所使用的数据与官方代码相一致,因此在数据准备部分我们使用了官方的代码进行了处理。
3.1 准备环境
- 硬件:Aistudio V100-32G
- 框架:PaddlePaddle >= 2.2.0
- 依赖:paddlenlp>=2.2.6, sacremoses, jieba
3.2 准备数据
数据集介绍:
- 数据集大小:XNLI将NLI数据集扩展到15种语言,包括英语、法语、西班牙语、德语、希腊语、保加利亚语、俄语、土耳其语、阿拉伯语、越南语、泰语、中文、印地语、斯瓦希里语和乌尔都语,并以NLI的三分类格式为每种语言分别提供了7500个经人工标注的开发和测试实例,合计112500个标准句子对。
- 数据格式:原始数据是
tsv格式,这里提供的是处理好的pkl格式,专门为了复现论文而提供的。
数据集准备: (1)自己处理数据: 数据集处理过程参考了facebookresearch/XLM仓库,以下代码可以在Google Colab中运行。
# 将XLM-main.zip上传到Google Colab。
!unzip XLM-main.zip
!chmod -R 777 XLM-main/
%cd XLM-main
# Thai
!pip install pythainlp
# Chinese
%cd tools/
!wget https://nlp.stanford.edu/software/stanford-segmenter-2018-10-16.zip
!unzip stanford-segmenter-2018-10-16.zip
%cd ../
# 下载处理数据
!./get-data-xnli.sh
!./prepare-xnli.sh
# 压缩下载
!mv ./data/processed/XLM15/eval/XNLI ./XNLI
!tar -zcvf xnli.tar.gz ./XNLI
# 我们将处理好的数据./XNLI放进xlm/data/XNLI/这里存放转换后的数据集.txt
(2)下载处理好的数据
已经上传至aistudio,地址:https://aistudio.baidu.com/aistudio/datasetdetail/139402
将处理好的数据xnli.tar.gz下载至本地,然后放进xlm/data/XNLI文件夹。(本教程已经加载好了数据)
#复制数据集
cp /home/aistudio/data/data139402/xnli.tar.gz ./xlm/data
cd ./xlm/data
#解压
tar -zxvf xnli.tar.gz
#返回根目录
cd ../../
四、开始训练
4.1 模型训练
命令已经配置完毕,可以直接运行。详细的参数配置可参考文件train.py中的parse_args函数。
# 其中./xlm-mlm-tlm-xnli15-1024 表示加载的是本地处理好的paddle版本的预训练模型
python train.py --output_dir facebook_xnli --pretrained_model_name_or_path ./xlm-mlm-tlm-xnli15-1024
有如下的训练日志:
04/12/2022 15:25:25 - INFO - __main__ - ********** Configuration Arguments **********
04/12/2022 15:25:25 - INFO - __main__ - adam_epsilon: 1e-08
04/12/2022 15:25:25 - INFO - __main__ - cache_dir: data_caches
04/12/2022 15:25:25 - INFO - __main__ - eval_batch_size: 32
04/12/2022 15:25:25 - INFO - __main__ - fp16: False
04/12/2022 15:25:25 - INFO - __main__ - gradient_accumulation_steps: 1
04/12/2022 15:25:25 - INFO - __main__ - language: en
04/12/2022 15:25:25 - INFO - __main__ - learning_rate: 2e-06
04/12/2022 15:25:25 - INFO - __main__ - log_dir: xnli_right_avg_new/logs
04/12/2022 15:25:25 - INFO - __main__ - logging_steps: 50
04/12/2022 15:25:25 - INFO - __main__ - max_length: 256
04/12/2022 15:25:25 - INFO - __main__ - max_train_steps: 0
04/12/2022 15:25:25 - INFO - __main__ - num_train_epochs: 250
04/12/2022 15:25:25 - INFO - __main__ - num_workers: 0
04/12/2022 15:25:25 - INFO - __main__ - optimizer: adam
04/12/2022 15:25:25 - INFO - __main__ - output_dir: xnli_right_avg_new
04/12/2022 15:25:25 - INFO - __main__ - overwrite_cache: False
04/12/2022 15:25:25 - INFO - __main__ - pretrained_model_name_or_path: xlm-mlm-tlm-xnli15-1024
04/12/2022 15:25:25 - INFO - __main__ - save_steps: 2500
04/12/2022 15:25:25 - INFO - __main__ - scale_loss: 32768
04/12/2022 15:25:25 - INFO - __main__ - seed: 12345
04/12/2022 15:25:25 - INFO - __main__ - sentences_per_epoch: 20000
04/12/2022 15:25:25 - INFO - __main__ - topk: 3
04/12/2022 15:25:25 - INFO - __main__ - train_batch_size: 8
04/12/2022 15:25:25 - INFO - __main__ - train_language: en
04/12/2022 15:25:25 - INFO - __main__ - writer_type: visualdl
04/12/2022 15:25:25 - INFO - __main__ - **************************************************
04/12/2022 15:25:44 - INFO - __main__ - ********** Running training **********
04/12/2022 15:25:44 - INFO - __main__ - Num examples = None
04/12/2022 15:25:44 - INFO - __main__ - Num Epochs = 250
04/12/2022 15:25:44 - INFO - __main__ - Instantaneous train batch size = 8
04/12/2022 15:25:44 - INFO - __main__ - Instantaneous eval batch size = 16
04/12/2022 15:25:44 - INFO - __main__ - Total train batch size (w. accumulation) = 8
04/12/2022 15:25:44 - INFO - __main__ - Gradient Accumulation steps = 1
04/12/2022 15:25:44 - INFO - __main__ - Total optimization steps = 625000
04/12/2022 15:25:49 - INFO - __main__ - global_steps 50 loss: 7.46472330
04/12/2022 15:25:54 - INFO - __main__ - global_steps 100 loss: 5.02984764
04/12/2022 15:25:59 - INFO - __main__ - global_steps 150 loss: 4.60122725
04/12/2022 15:26:04 - INFO - __main__ - global_steps 200 loss: 4.87390495
04/12/2022 15:26:09 - INFO - __main__ - global_steps 250 loss: 4.09307530
04/12/2022 15:26:14 - INFO - __main__ - global_steps 300 loss: 3.93492581
04/12/2022 15:26:19 - INFO - __main__ - global_steps 350 loss: 4.10160220
04/12/2022 15:26:25 - INFO - __main__ - global_steps 400 loss: 3.10217629
04/12/2022 15:26:30 - INFO - __main__ - global_steps 450 loss: 3.54333124
04/12/2022 15:26:34 - INFO - __main__ - global_steps 500 loss: 3.30277427
04/12/2022 15:26:40 - INFO - __main__ - global_steps 550 loss: 3.00207584
04/12/2022 15:26:45 - INFO - __main__ - global_steps 600 loss: 3.02170183
04/12/2022 15:26:50 - INFO - __main__ - global_steps 650 loss: 2.98708332
04/12/2022 15:26:55 - INFO - __main__ - global_steps 700 loss: 2.62695073
04/12/2022 15:27:00 - INFO - __main__ - global_steps 750 loss: 2.70854754
04/12/2022 15:27:05 - INFO - __main__ - global_steps 800 loss: 2.70319111
04/12/2022 15:27:09 - INFO - __main__ - global_steps 850 loss: 2.61839391
04/12/2022 15:27:14 - INFO - __main__ - global_steps 900 loss: 2.72874597
04/12/2022 15:27:19 - INFO - __main__ - global_steps 950 loss: 2.50610820
04/12/2022 15:27:24 - INFO - __main__ - global_steps 1000 loss: 2.53542953
04/12/2022 15:27:29 - INFO - __main__ - global_steps 1050 loss: 2.25212755
04/12/2022 15:27:34 - INFO - __main__ - global_steps 1100 loss: 2.50348177
04/12/2022 15:27:39 - INFO - __main__ - global_steps 1150 loss: 2.14373983
04/12/2022 15:27:43 - INFO - __main__ - global_steps 1200 loss: 2.30000065
04/12/2022 15:27:48 - INFO - __main__ - global_steps 1250 loss: 2.27780871
04/12/2022 15:27:53 - INFO - __main__ - global_steps 1300 loss: 2.27487551
04/12/2022 15:27:58 - INFO - __main__ - global_steps 1350 loss: 2.31865400
04/12/2022 15:28:03 - INFO - __main__ - global_steps 1400 loss: 2.54873763
04/12/2022 15:28:08 - INFO - __main__ - global_steps 1450 loss: 2.16360084
04/12/2022 15:28:12 - INFO - __main__ - global_steps 1500 loss: 2.09571365
04/12/2022 15:28:17 - INFO - __main__ - global_steps 1550 loss: 2.22257620
04/12/2022 15:28:22 - INFO - __main__ - global_steps 1600 loss: 1.93775404
04/12/2022 15:28:27 - INFO - __main__ - global_steps 1650 loss: 2.05469335
04/12/2022 15:28:31 - INFO - __main__ - global_steps 1700 loss: 2.12268977
04/12/2022 15:28:36 - INFO - __main__ - global_steps 1750 loss: 1.98807700
04/12/2022 15:28:41 - INFO - __main__ - global_steps 1800 loss: 1.89246038
04/12/2022 15:28:46 - INFO - __main__ - global_steps 1850 loss: 1.80554641
04/12/2022 15:28:50 - INFO - __main__ - global_steps 1900 loss: 2.01120813
04/12/2022 15:28:55 - INFO - __main__ - global_steps 1950 loss: 1.91710269
04/12/2022 15:29:00 - INFO - __main__ - global_steps 2000 loss: 1.78628310
04/12/2022 15:29:04 - INFO - __main__ - global_steps 2050 loss: 1.95788345
04/12/2022 15:29:09 - INFO - __main__ - global_steps 2100 loss: 1.71753185
04/12/2022 15:29:14 - INFO - __main__ - global_steps 2150 loss: 1.72524106
04/12/2022 15:29:18 - INFO - __main__ - global_steps 2200 loss: 1.98808228
04/12/2022 15:29:23 - INFO - __main__ - global_steps 2250 loss: 1.72786968
04/12/2022 15:29:28 - INFO - __main__ - global_steps 2300 loss: 1.74996327
04/12/2022 15:29:32 - INFO - __main__ - global_steps 2350 loss: 1.69286092
04/12/2022 15:29:37 - INFO - __main__ - global_steps 2400 loss: 1.64929492
04/12/2022 15:29:42 - INFO - __main__ - global_steps 2450 loss: 1.78267193
04/12/2022 15:29:46 - INFO - __main__ - global_steps 2500 loss: 1.74447792
04/12/2022 15:29:46 - INFO - __main__ - ********** Running evaluating **********
04/12/2022 15:29:51 - INFO - __main__ - ########## val_ar_acc 0.3389558232931727 ##########
04/12/2022 15:29:55 - INFO - __main__ - ########## val_bg_acc 0.41244979919678715 ##########
04/12/2022 15:30:00 - INFO - __main__ - ########## val_de_acc 0.3481927710843373 ##########
04/12/2022 15:30:05 - INFO - __main__ - ########## val_el_acc 0.46586345381526106 ##########
04/12/2022 15:30:09 - INFO - __main__ - ########## val_en_acc 0.5333333333333333 ##########
04/12/2022 15:30:13 - INFO - __main__ - ########## val_es_acc 0.4682730923694779 ##########
04/12/2022 15:30:18 - INFO - __main__ - ########## val_fr_acc 0.38072289156626504 ##########
04/12/2022 15:30:23 - INFO - __main__ - ########## val_hi_acc 0.3674698795180723 ##########
04/12/2022 15:30:28 - INFO - __main__ - ########## val_ru_acc 0.385140562248996 ##########
04/12/2022 15:30:32 - INFO - __main__ - ########## val_sw_acc 0.3369477911646586 ##########
04/12/2022 15:30:36 - INFO - __main__ - ########## val_th_acc 0.4827309236947791 ##########
04/12/2022 15:30:40 - INFO - __main__ - ########## val_tr_acc 0.3863453815261044 ##########
04/12/2022 15:30:45 - INFO - __main__ - ########## val_ur_acc 0.3373493975903614 ##########
04/12/2022 15:30:49 - INFO - __main__ - ########## val_vi_acc 0.3333333333333333 ##########
04/12/2022 15:30:54 - INFO - __main__ - ########## val_zh_acc 0.3337349397590361 ##########
04/12/2022 15:31:02 - INFO - __main__ - ########## test_ar_acc 0.3379241516966068 ##########
04/12/2022 15:31:12 - INFO - __main__ - ########## test_bg_acc 0.4119760479041916 ##########
04/12/2022 15:31:21 - INFO - __main__ - ########## test_de_acc 0.35129740518962077 ##########
04/12/2022 15:31:31 - INFO - __main__ - ########## test_el_acc 0.4756487025948104 ##########
04/12/2022 15:31:40 - INFO - __main__ - ########## test_en_acc 0.5467065868263473 ##########
04/12/2022 15:31:49 - INFO - __main__ - ########## test_es_acc 0.4750499001996008 ##########
04/12/2022 15:31:58 - INFO - __main__ - ########## test_fr_acc 0.3870259481037924 ##########
04/12/2022 15:32:09 - INFO - __main__ - ########## test_hi_acc 0.37025948103792417 ##########
04/12/2022 15:32:19 - INFO - __main__ - ########## test_ru_acc 0.37984031936127743 ##########
04/12/2022 15:32:28 - INFO - __main__ - ########## test_sw_acc 0.3401197604790419 ##########
04/12/2022 15:32:37 - INFO - __main__ - ########## test_th_acc 0.4820359281437126 ##########
04/12/2022 15:32:47 - INFO - __main__ - ########## test_tr_acc 0.3908183632734531 ##########
04/12/2022 15:32:57 - INFO - __main__ - ########## test_ur_acc 0.33672654690618764 ##########
04/12/2022 15:33:06 - INFO - __main__ - ########## test_vi_acc 0.3333333333333333 ##########
04/12/2022 15:33:15 - INFO - __main__ - ########## test_zh_acc 0.3333333333333333 ##########
04/12/2022 15:33:15 - INFO - __main__ - val_ar_acc = 0.3389558232931727
04/12/2022 15:33:15 - INFO - __main__ - val_bg_acc = 0.41244979919678715
04/12/2022 15:33:15 - INFO - __main__ - val_de_acc = 0.3481927710843373
04/12/2022 15:33:15 - INFO - __main__ - val_el_acc = 0.46586345381526106
04/12/2022 15:33:15 - INFO - __main__ - val_en_acc = 0.5333333333333333
04/12/2022 15:33:15 - INFO - __main__ - val_es_acc = 0.4682730923694779
04/12/2022 15:33:15 - INFO - __main__ - val_fr_acc = 0.38072289156626504
04/12/2022 15:33:15 - INFO - __main__ - val_hi_acc = 0.3674698795180723
04/12/2022 15:33:15 - INFO - __main__ - val_ru_acc = 0.385140562248996
04/12/2022 15:33:15 - INFO - __main__ - val_sw_acc = 0.3369477911646586
04/12/2022 15:33:15 - INFO - __main__ - val_th_acc = 0.4827309236947791
04/12/2022 15:33:15 - INFO - __main__ - val_tr_acc = 0.3863453815261044
04/12/2022 15:33:15 - INFO - __main__ - val_ur_acc = 0.3373493975903614
04/12/2022 15:33:15 - INFO - __main__ - val_vi_acc = 0.3333333333333333
04/12/2022 15:33:15 - INFO - __main__ - val_zh_acc = 0.3337349397590361
04/12/2022 15:33:15 - INFO - __main__ - val_avg_acc = 0.39405622489959846
04/12/2022 15:33:15 - INFO - __main__ - test_ar_acc = 0.3379241516966068
04/12/2022 15:33:15 - INFO - __main__ - test_bg_acc = 0.4119760479041916
04/12/2022 15:33:15 - INFO - __main__ - test_de_acc = 0.35129740518962077
04/12/2022 15:33:15 - INFO - __main__ - test_el_acc = 0.4756487025948104
04/12/2022 15:33:15 - INFO - __main__ - test_en_acc = 0.5467065868263473
04/12/2022 15:33:15 - INFO - __main__ - test_es_acc = 0.4750499001996008
04/12/2022 15:33:15 - INFO - __main__ - test_fr_acc = 0.3870259481037924
04/12/2022 15:33:15 - INFO - __main__ - test_hi_acc = 0.37025948103792417
04/12/2022 15:33:15 - INFO - __main__ - test_ru_acc = 0.37984031936127743
04/12/2022 15:33:15 - INFO - __main__ - test_sw_acc = 0.3401197604790419
04/12/2022 15:33:15 - INFO - __main__ - test_th_acc = 0.4820359281437126
04/12/2022 15:33:15 - INFO - __main__ - test_tr_acc = 0.3908183632734531
04/12/2022 15:33:15 - INFO - __main__ - test_ur_acc = 0.33672654690618764
04/12/2022 15:33:15 - INFO - __main__ - test_vi_acc = 0.3333333333333333
04/12/2022 15:33:15 - INFO - __main__ - test_zh_acc = 0.3333333333333333
04/12/2022 15:33:15 - INFO - __main__ - test_avg_acc = 0.3968063872255489
04/12/2022 15:33:15 - INFO - __main__ - ########## Step 2500 val_avg_acc 0.39405622489959846 test_avg_acc 0.3968063872255489 ##########
Tips: 训练日志保存在输出路径facebook_xnli/logs文件夹,我们可以在aistudio上使用visualdl在线监控训练过程中指标的变化。
4.2 模型评估
如果我们想评估在xnli上训练好的模型,我们可以使用以下的命令。
# 首先下载权重。
mkdir xlm-mlm-tlm-xnli15-1024-fintuned-on-xnli
cd xlm-mlm-tlm-xnli15-1024-fintuned-on-xnli
# 下载模型config文件
wget https://huggingface.co/junnyu/xlm-mlm-tlm-xnli15-1024-paddle-fintuned-on-xnli/resolve/main/model_config.json
# 下载merges文件
wget https://huggingface.co/junnyu/xlm-mlm-tlm-xnli15-1024-paddle-fintuned-on-xnli/resolve/main/merges.txt
# 下载vocab文件
wget https://huggingface.co/junnyu/xlm-mlm-tlm-xnli15-1024-paddle-fintuned-on-xnli/resolve/main/vocab.json
# 下载tokenizer_config.json
wget https://huggingface.co/junnyu/xlm-mlm-tlm-xnli15-1024-paddle-fintuned-on-xnli/resolve/main/tokenizer_config.json
# 下载模型权重(aistudio下载可能很慢)
wget https://huggingface.co/junnyu/xlm-mlm-tlm-xnli15-1024-paddle-fintuned-on-xnli/resolve/main/model_state.pdparams
cd ..
# 运行评估
# pretrained_model_name_or_path这个可以改成你自己训练好的模型地址。
python eval.py --output_dir eval_output --pretrained_model_name_or_path ./xlm-mlm-tlm-xnli15-1024-fintuned-on-xnli
04/12/2022 22:43:41 - INFO - __main__ - ********** Running evaluating **********
04/12/2022 22:43:46 - INFO - __main__ - ########## val_ar_acc 0.7172690763052209 ##########
04/12/2022 22:43:50 - INFO - __main__ - ########## val_bg_acc 0.7606425702811245 ##########
04/12/2022 22:43:55 - INFO - __main__ - ########## val_de_acc 0.7767068273092369 ##########
04/12/2022 22:43:59 - INFO - __main__ - ########## val_el_acc 0.7522088353413655 ##########
04/12/2022 22:44:04 - INFO - __main__ - ########## val_en_acc 0.8437751004016064 ##########
04/12/2022 22:44:08 - INFO - __main__ - ########## val_es_acc 0.7891566265060241 ##########
04/12/2022 22:44:13 - INFO - __main__ - ########## val_fr_acc 0.7811244979919679 ##########
04/12/2022 22:44:18 - INFO - __main__ - ########## val_hi_acc 0.6899598393574298 ##########
04/12/2022 22:44:22 - INFO - __main__ - ########## val_ru_acc 0.7429718875502008 ##########
04/12/2022 22:44:27 - INFO - __main__ - ########## val_sw_acc 0.6714859437751004 ##########
04/12/2022 22:44:31 - INFO - __main__ - ########## val_th_acc 0.706425702811245 ##########
04/12/2022 22:44:36 - INFO - __main__ - ########## val_tr_acc 0.7208835341365462 ##########
04/12/2022 22:44:40 - INFO - __main__ - ########## val_ur_acc 0.6461847389558233 ##########
04/12/2022 22:44:45 - INFO - __main__ - ########## val_vi_acc 0.7397590361445783 ##########
04/12/2022 22:44:49 - INFO - __main__ - ########## val_zh_acc 0.751004016064257 ##########
04/12/2022 22:44:58 - INFO - __main__ - ########## test_ar_acc 0.7381237524950099 ##########
04/12/2022 22:45:08 - INFO - __main__ - ########## test_bg_acc 0.7758483033932135 ##########
04/12/2022 22:45:17 - INFO - __main__ - ########## test_de_acc 0.7686626746506986 ##########
04/12/2022 22:45:26 - INFO - __main__ - ########## test_el_acc 0.7676646706586826 ##########
04/12/2022 22:45:35 - INFO - __main__ - ########## test_en_acc 0.846307385229541 ##########
04/12/2022 22:45:45 - INFO - __main__ - ########## test_es_acc 0.7978043912175649 ##########
04/12/2022 22:45:54 - INFO - __main__ - ########## test_fr_acc 0.7924151696606786 ##########
04/12/2022 22:46:04 - INFO - __main__ - ########## test_hi_acc 0.6880239520958084 ##########
04/12/2022 22:46:13 - INFO - __main__ - ########## test_ru_acc 0.7618762475049901 ##########
04/12/2022 22:46:22 - INFO - __main__ - ########## test_sw_acc 0.691816367265469 ##########
04/12/2022 22:46:31 - INFO - __main__ - ########## test_th_acc 0.7109780439121757 ##########
04/12/2022 22:46:40 - INFO - __main__ - ########## test_tr_acc 0.7173652694610778 ##########
04/12/2022 22:46:49 - INFO - __main__ - ########## test_ur_acc 0.6584830339321357 ##########
04/12/2022 22:46:59 - INFO - __main__ - ########## test_vi_acc 0.7447105788423154 ##########
04/12/2022 22:47:08 - INFO - __main__ - ########## test_zh_acc 0.7481037924151697 ##########
04/12/2022 22:47:08 - INFO - __main__ - val_ar_acc = 0.7172690763052209
04/12/2022 22:47:08 - INFO - __main__ - val_bg_acc = 0.7606425702811245
04/12/2022 22:47:08 - INFO - __main__ - val_de_acc = 0.7767068273092369
04/12/2022 22:47:08 - INFO - __main__ - val_el_acc = 0.7522088353413655
04/12/2022 22:47:08 - INFO - __main__ - val_en_acc = 0.8437751004016064
04/12/2022 22:47:08 - INFO - __main__ - val_es_acc = 0.7891566265060241
04/12/2022 22:47:08 - INFO - __main__ - val_fr_acc = 0.7811244979919679
04/12/2022 22:47:08 - INFO - __main__ - val_hi_acc = 0.6899598393574298
04/12/2022 22:47:08 - INFO - __main__ - val_ru_acc = 0.7429718875502008
04/12/2022 22:47:08 - INFO - __main__ - val_sw_acc = 0.6714859437751004
04/12/2022 22:47:08 - INFO - __main__ - val_th_acc = 0.706425702811245
04/12/2022 22:47:08 - INFO - __main__ - val_tr_acc = 0.7208835341365462
04/12/2022 22:47:08 - INFO - __main__ - val_ur_acc = 0.6461847389558233
04/12/2022 22:47:08 - INFO - __main__ - val_vi_acc = 0.7397590361445783
04/12/2022 22:47:08 - INFO - __main__ - val_zh_acc = 0.751004016064257
04/12/2022 22:47:08 - INFO - __main__ - val_avg_acc = 0.7393038821954484
04/12/2022 22:47:08 - INFO - __main__ - test_ar_acc = 0.7381237524950099
04/12/2022 22:47:08 - INFO - __main__ - test_bg_acc = 0.7758483033932135
04/12/2022 22:47:08 - INFO - __main__ - test_de_acc = 0.7686626746506986
04/12/2022 22:47:08 - INFO - __main__ - test_el_acc = 0.7676646706586826
04/12/2022 22:47:08 - INFO - __main__ - test_en_acc = 0.846307385229541
04/12/2022 22:47:08 - INFO - __main__ - test_es_acc = 0.7978043912175649
04/12/2022 22:47:08 - INFO - __main__ - test_fr_acc = 0.7924151696606786
04/12/2022 22:47:08 - INFO - __main__ - test_hi_acc = 0.6880239520958084
04/12/2022 22:47:08 - INFO - __main__ - test_ru_acc = 0.7618762475049901
04/12/2022 22:47:08 - INFO - __main__ - test_sw_acc = 0.691816367265469
04/12/2022 22:47:08 - INFO - __main__ - test_th_acc = 0.7109780439121757
04/12/2022 22:47:08 - INFO - __main__ - test_tr_acc = 0.7173652694610778
04/12/2022 22:47:08 - INFO - __main__ - test_ur_acc = 0.6584830339321357
04/12/2022 22:47:08 - INFO - __main__ - test_vi_acc = 0.7447105788423154
04/12/2022 22:47:08 - INFO - __main__ - test_zh_acc = 0.7481037924151697
04/12/2022 22:47:08 - INFO - __main__ - test_avg_acc = 0.7472122421823022
五、模型部署
可以将微调好的模型转化成paddle静态图进行部署调用。
5.1 导出静态图模型
python export_model.py --model_path=./xlm-mlm-tlm-xnli15-1024-fintuned-on-xnli --save_inference_dir=./xlm_infer
5.2 python调用
其中<sep>注释为了分割两个句子,并没有实际意义。
texta, textb = text.split("<sep>") # 主要是为了获得两个分开的句子。
# 英文测试。
python infer.py --model_dir=./xlm_infer/ --text "You don't have to stay there.<sep>You can leave." --language "en"
# 中文测试
# 注意使用中文的时候会使用到jieba,请确保pip install jieba
python infer.py --model_dir=./xlm_infer/ --text "你没有必要一直呆在这。<sep>你可以离开了。" --language "zh"
详细的其他部署方式可以参考 https://github.com/JunnYu/xlm_paddle/tree/main/test_tipc。
参考文献
- https://github.com/facebookresearch/XLM
- https://github.com/huggingface/transformers/tree/main/src/transformers/models/xlm
- https://github.com/PaddlePaddle/PaddleNLP
- https://arxiv.org/pdf/1901.07291.pdf
心得体会
- 本次论文复现我只完成了这一道关于nlp的赛题。其中搭建模型只花了1天,而训练模型却花费了5,6天的时间,主要是进行一些调参工作,毕竟论文所述的效果不一定能够达到。
- 在论文复现过程中,我也遇到了很多的困难,但是也都一一解决了。一方面靠的是自己查找资料的能力,另一方面则是咨询百度官方工作人员,在此我对百度官方工作人员表示感谢。
- 本次论文复现要感谢aistudio的算力支持,让我们可以使用到免费的gpu服务器。
- 最后我要感谢上述参考文献作者们无私的开源贡献。
In [ ]
# 更新一下paddlenlp和jieba
!pip install -U paddlenlp jieba sacremoses
# 复制权重
import os
os.system("cp /home/aistudio/data/data138431/model_state.pdparams ./xlm-mlm-tlm-xnli15-1024")
# 准备数据
import os
os.system("tar -zxvf /home/aistudio/data/data139402/xnli.tar.gz -C ./xlm/data")
In [ ]
# 训练
!python train.py --output_dir facebook_xnli --pretrained_model_name_or_path ./xlm-mlm-tlm-xnli15-1024
In [ ]
# 预测
import os
os.chdir("./xlm-mlm-tlm-xnli15-1024-fintuned-on-xnli")
os.system("wget https://huggingface.co/junnyu/xlm-mlm-tlm-xnli15-1024-paddle-fintuned-on-xnli/resolve/main/model_state.pdparams")
os.chdir("../")
!python eval.py --output_dir eval_output --pretrained_model_name_or_path ./xlm-mlm-tlm-xnli15-1024-fintuned-on-xnli
In [11]
# 静态导出
!python export_model.py --model_path=./xlm-mlm-tlm-xnli15-1024-fintuned-on-xnli --save_inference_dir=./xlm_infer
# python测试
!python infer.py --model_dir=./xlm_infer/ --text "You don't have to stay there.<sep>You can leave." --language "en"
# 中文测试
# 注意使用中文的时候会使用到jieba,请确保pip install jieba
!python infer.py --model_dir=./xlm_infer/ --text "你没有必要一直呆在这。<sep>你可以离开了。" --language "zh"/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/setuptools/depends.py:2: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses import imp /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/scipy/sparse/sputils.py:16: DeprecationWarning: `np.typeDict` is a deprecated alias for `np.sctypeDict`. supported_dtypes = [np.typeDict[x] for x in supported_dtypes] /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/scipy/special/orthogonal.py:81: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations from numpy import (exp, inf, pi, sqrt, floor, sin, cos, around, int, /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/scipy/linalg/__init__.py:217: DeprecationWarning: The module numpy.dual is deprecated. Instead of using dual, use the functions directly from numpy or scipy. from numpy.dual import register_func [2022-05-09 14:45:29,578] [ INFO] - tokenizer config file saved in ./xlm_infer/tokenizer_config.json [2022-05-09 14:45:29,579] [ INFO] - Special tokens file saved in ./xlm_infer/special_tokens_map.json inference model and tokenizer have been saved into ./xlm_infer /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/setuptools/depends.py:2: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses import imp /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/scipy/special/orthogonal.py:81: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations from numpy import (exp, inf, pi, sqrt, floor, sin, cos, around, int, /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/scipy/sparse/sputils.py:16: DeprecationWarning: `np.typeDict` is a deprecated alias for `np.sctypeDict`. supported_dtypes = [np.typeDict[x] for x in supported_dtypes] /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/scipy/linalg/__init__.py:217: DeprecationWarning: The module numpy.dual is deprecated. Instead of using dual, use the functions directly from numpy or scipy. from numpy.dual import register_func [2022-05-09 14:45:35,622] [ WARNING] - Truncation was not explicitly activated but `max_length` is provided a specific value, please use `truncation=True` to explicitly truncate examples to max length. Defaulting to 'longest_first' truncation strategy. If you encode pairs of sequences (GLUE-style) with the tokenizer you can select this strategy more precisely by providing a specific strategy to `truncation`. text: You don't have to stay there.<sep>You can leave., label_id: 1, prob: 0.9443114995956421 1 0.9443115 /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/setuptools/depends.py:2: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses import imp /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/scipy/special/orthogonal.py:81: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations from numpy import (exp, inf, pi, sqrt, floor, sin, cos, around, int, /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/scipy/sparse/sputils.py:16: DeprecationWarning: `np.typeDict` is a deprecated alias for `np.sctypeDict`. supported_dtypes = [np.typeDict[x] for x in supported_dtypes] /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/scipy/linalg/__init__.py:217: DeprecationWarning: The module numpy.dual is deprecated. Instead of using dual, use the functions directly from numpy or scipy. from numpy.dual import register_func [2022-05-09 14:45:52,665] [ WARNING] - Truncation was not explicitly activated but `max_length` is provided a specific value, please use `truncation=True` to explicitly truncate examples to max length. Defaulting to 'longest_first' truncation strategy. If you encode pairs of sequences (GLUE-style) with the tokenizer you can select this strategy more precisely by providing a specific strategy to `truncation`. Building prefix dict from the default dictionary ... Dumping model to file cache /tmp/jieba.cache Loading model cost 0.799 seconds. Prefix dict has been built successfully. text: 你没有必要一直呆在这。<sep>你可以离开了。, label_id: 0, prob: 0.9617933630943298 0 0.96179336
paddlenlp版本数据处理代码。
tokenizer依赖安装
# sacremoses
pip install sacremoses
# Thai tokenizer
pip install pythainlp
# Japanese tokenizer
git clone https://github.com/neubig/kytea.git
cd kytea
autoreconf -i
./configure --prefix=$HOME/local
make && make install
pip install kytea
# Chinese tokenizer
pip install jieba
In [1]
# train
# 确保有预训练权重。
# import os
# os.system("cp /home/aistudio/data/data138431/model_state.pdparams ./xlm-mlm-tlm-xnli15-1024")
!python xlm_train.py --batch_size 8 --model_name_or_path ./xlm-mlm-tlm-xnli15-1024 --output_dir outputs----------- Configuration Arguments -----------
adam_epsilon: 1e-08
batch_size: 8
device: gpu
dropout: 0.1
learning_rate: 2e-06
logging_steps: 200
max_seq_length: 256
max_steps: -1
model_name_or_path: ./xlm-mlm-tlm-xnli15-1024
num_train_epochs: 5
output_dir: outputs
save_steps: 24544
scale_loss: 32768
seed: 42
use_amp: False
------------------------------------------------
W0510 14:13:21.121811 11829 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W0510 14:13:21.125138 11829 device_context.cc:465] device: 0, cuDNN Version: 7.6.
num_training_steps 245440
[2022-05-10 14:13:30,258] [ WARNING] - Truncation was not explicitly activated but `max_length` is provided a specific value, please use `truncation=True` to explicitly truncate examples to max length. Defaulting to 'longest_first' truncation strategy. If you encode pairs of sequences (GLUE-style) with the tokenizer you can select this strategy more precisely by providing a specific strategy to `truncation`.
global step 200/245440, epoch: 0, batch: 199, rank_id: 0, loss: 0.904906, lr: 0.0000020000, speed: 6.5792 step/s
global step 400/245440, epoch: 0, batch: 399, rank_id: 0, loss: 2.385277, lr: 0.0000020000, speed: 12.9650 step/s
[2022-05-10 14:14:21,021] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
[2022-05-10 14:14:31,257] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 600/245440, epoch: 0, batch: 599, rank_id: 0, loss: 2.063957, lr: 0.0000020000, speed: 12.8347 step/s
global step 800/245440, epoch: 0, batch: 799, rank_id: 0, loss: 1.955145, lr: 0.0000020000, speed: 12.8099 step/s
global step 1000/245440, epoch: 0, batch: 999, rank_id: 0, loss: 1.146775, lr: 0.0000020000, speed: 12.8575 step/s
[2022-05-10 14:15:12,445] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 1200/245440, epoch: 0, batch: 1199, rank_id: 0, loss: 1.571175, lr: 0.0000020000, speed: 12.8664 step/s
global step 1400/245440, epoch: 0, batch: 1399, rank_id: 0, loss: 2.023485, lr: 0.0000020000, speed: 13.0635 step/s
global step 1600/245440, epoch: 0, batch: 1599, rank_id: 0, loss: 1.757297, lr: 0.0000020000, speed: 12.8722 step/s
[2022-05-10 14:16:00,817] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 1800/245440, epoch: 0, batch: 1799, rank_id: 0, loss: 1.012990, lr: 0.0000020000, speed: 12.9991 step/s
global step 2000/245440, epoch: 0, batch: 1999, rank_id: 0, loss: 0.581219, lr: 0.0000020000, speed: 12.9902 step/s
global step 2200/245440, epoch: 0, batch: 2199, rank_id: 0, loss: 0.879110, lr: 0.0000020000, speed: 12.7908 step/s
global step 2400/245440, epoch: 0, batch: 2399, rank_id: 0, loss: 1.094651, lr: 0.0000020000, speed: 12.7361 step/s
global step 2600/245440, epoch: 0, batch: 2599, rank_id: 0, loss: 1.058626, lr: 0.0000020000, speed: 12.7710 step/s
global step 2800/245440, epoch: 0, batch: 2799, rank_id: 0, loss: 1.849280, lr: 0.0000020000, speed: 12.9678 step/s
global step 3000/245440, epoch: 0, batch: 2999, rank_id: 0, loss: 1.681761, lr: 0.0000020000, speed: 13.0712 step/s
global step 3200/245440, epoch: 0, batch: 3199, rank_id: 0, loss: 1.324942, lr: 0.0000020000, speed: 13.0383 step/s
[2022-05-10 14:17:57,036] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 3400/245440, epoch: 0, batch: 3399, rank_id: 0, loss: 1.061607, lr: 0.0000020000, speed: 13.1347 step/s
[2022-05-10 14:18:20,920] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 3600/245440, epoch: 0, batch: 3599, rank_id: 0, loss: 1.051999, lr: 0.0000020000, speed: 13.0309 step/s
global step 3800/245440, epoch: 0, batch: 3799, rank_id: 0, loss: 1.278212, lr: 0.0000020000, speed: 12.9343 step/s
global step 4000/245440, epoch: 0, batch: 3999, rank_id: 0, loss: 1.412771, lr: 0.0000020000, speed: 13.0030 step/s
global step 4200/245440, epoch: 0, batch: 4199, rank_id: 0, loss: 0.793066, lr: 0.0000020000, speed: 12.8475 step/s
global step 4400/245440, epoch: 0, batch: 4399, rank_id: 0, loss: 1.265685, lr: 0.0000020000, speed: 13.0956 step/s
global step 4600/245440, epoch: 0, batch: 4599, rank_id: 0, loss: 0.444373, lr: 0.0000020000, speed: 12.9125 step/s
global step 4800/245440, epoch: 0, batch: 4799, rank_id: 0, loss: 0.772130, lr: 0.0000020000, speed: 13.0033 step/s
[2022-05-10 14:20:11,421] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 5000/245440, epoch: 0, batch: 4999, rank_id: 0, loss: 1.069405, lr: 0.0000020000, speed: 12.5757 step/s
[2022-05-10 14:20:17,712] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 5200/245440, epoch: 0, batch: 5199, rank_id: 0, loss: 0.788178, lr: 0.0000020000, speed: 12.8734 step/s
global step 5400/245440, epoch: 0, batch: 5399, rank_id: 0, loss: 0.794968, lr: 0.0000020000, speed: 13.0484 step/s
global step 5600/245440, epoch: 0, batch: 5599, rank_id: 0, loss: 0.456028, lr: 0.0000020000, speed: 12.9436 step/s
global step 5800/245440, epoch: 0, batch: 5799, rank_id: 0, loss: 1.457985, lr: 0.0000020000, speed: 13.0354 step/s
global step 6000/245440, epoch: 0, batch: 5999, rank_id: 0, loss: 0.752273, lr: 0.0000020000, speed: 12.9597 step/s
global step 6200/245440, epoch: 0, batch: 6199, rank_id: 0, loss: 0.595645, lr: 0.0000020000, speed: 12.6078 step/s
global step 6400/245440, epoch: 0, batch: 6399, rank_id: 0, loss: 0.561156, lr: 0.0000020000, speed: 12.8900 step/s
global step 6600/245440, epoch: 0, batch: 6599, rank_id: 0, loss: 0.953108, lr: 0.0000020000, speed: 13.1371 step/s
global step 6800/245440, epoch: 0, batch: 6799, rank_id: 0, loss: 0.527924, lr: 0.0000020000, speed: 12.9120 step/s
[2022-05-10 14:22:33,121] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 7000/245440, epoch: 0, batch: 6999, rank_id: 0, loss: 0.863677, lr: 0.0000020000, speed: 12.9076 step/s
global step 7200/245440, epoch: 0, batch: 7199, rank_id: 0, loss: 1.050440, lr: 0.0000020000, speed: 13.2400 step/s
global step 7400/245440, epoch: 0, batch: 7399, rank_id: 0, loss: 0.601411, lr: 0.0000020000, speed: 13.0624 step/s
global step 7600/245440, epoch: 0, batch: 7599, rank_id: 0, loss: 0.484919, lr: 0.0000020000, speed: 12.8914 step/s
global step 7800/245440, epoch: 0, batch: 7799, rank_id: 0, loss: 1.505674, lr: 0.0000020000, speed: 12.8268 step/s
global step 8000/245440, epoch: 0, batch: 7999, rank_id: 0, loss: 0.481238, lr: 0.0000020000, speed: 12.8894 step/s
global step 8200/245440, epoch: 0, batch: 8199, rank_id: 0, loss: 1.241821, lr: 0.0000020000, speed: 13.2377 step/s
global step 8400/245440, epoch: 0, batch: 8399, rank_id: 0, loss: 0.572331, lr: 0.0000020000, speed: 12.8771 step/s
global step 8600/245440, epoch: 0, batch: 8599, rank_id: 0, loss: 1.099479, lr: 0.0000020000, speed: 12.8703 step/s
[2022-05-10 14:24:56,136] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
[2022-05-10 14:25:03,268] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 8800/245440, epoch: 0, batch: 8799, rank_id: 0, loss: 0.620668, lr: 0.0000020000, speed: 13.0554 step/s
global step 9000/245440, epoch: 0, batch: 8999, rank_id: 0, loss: 0.444480, lr: 0.0000020000, speed: 12.8467 step/s
global step 9200/245440, epoch: 0, batch: 9199, rank_id: 0, loss: 0.351155, lr: 0.0000020000, speed: 12.9830 step/s
[2022-05-10 14:25:38,917] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
[2022-05-10 14:25:39,628] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
[2022-05-10 14:25:50,422] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 9400/245440, epoch: 0, batch: 9399, rank_id: 0, loss: 0.643652, lr: 0.0000020000, speed: 12.6995 step/s
global step 9600/245440, epoch: 0, batch: 9599, rank_id: 0, loss: 0.991604, lr: 0.0000020000, speed: 13.1020 step/s
global step 9800/245440, epoch: 0, batch: 9799, rank_id: 0, loss: 1.230592, lr: 0.0000020000, speed: 13.0739 step/s
[2022-05-10 14:26:28,434] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
[2022-05-10 14:26:36,075] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
[2022-05-10 14:26:37,715] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 10000/245440, epoch: 0, batch: 9999, rank_id: 0, loss: 0.509238, lr: 0.0000020000, speed: 12.5385 step/s
global step 10200/245440, epoch: 0, batch: 10199, rank_id: 0, loss: 0.993236, lr: 0.0000020000, speed: 12.9472 step/s
global step 10400/245440, epoch: 0, batch: 10399, rank_id: 0, loss: 1.400313, lr: 0.0000020000, speed: 13.0152 step/s
global step 10600/245440, epoch: 0, batch: 10599, rank_id: 0, loss: 0.666779, lr: 0.0000020000, speed: 13.0092 step/s
[2022-05-10 14:27:35,296] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 10800/245440, epoch: 0, batch: 10799, rank_id: 0, loss: 0.711479, lr: 0.0000020000, speed: 12.9435 step/s
global step 11000/245440, epoch: 0, batch: 10999, rank_id: 0, loss: 0.606194, lr: 0.0000020000, speed: 13.0159 step/s
global step 11200/245440, epoch: 0, batch: 11199, rank_id: 0, loss: 1.120303, lr: 0.0000020000, speed: 13.2129 step/s
global step 11400/245440, epoch: 0, batch: 11399, rank_id: 0, loss: 0.149079, lr: 0.0000020000, speed: 13.0916 step/s
global step 11600/245440, epoch: 0, batch: 11599, rank_id: 0, loss: 0.448484, lr: 0.0000020000, speed: 12.8955 step/s
global step 11800/245440, epoch: 0, batch: 11799, rank_id: 0, loss: 0.576945, lr: 0.0000020000, speed: 12.8731 step/s
[2022-05-10 14:29:05,359] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 12000/245440, epoch: 0, batch: 11999, rank_id: 0, loss: 0.743585, lr: 0.0000020000, speed: 12.9209 step/s
global step 12200/245440, epoch: 0, batch: 12199, rank_id: 0, loss: 0.578871, lr: 0.0000020000, speed: 13.0720 step/s
[2022-05-10 14:29:42,523] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 12400/245440, epoch: 0, batch: 12399, rank_id: 0, loss: 0.335710, lr: 0.0000020000, speed: 13.0498 step/s
global step 12600/245440, epoch: 0, batch: 12599, rank_id: 0, loss: 0.911561, lr: 0.0000020000, speed: 13.3532 step/s
global step 12800/245440, epoch: 0, batch: 12799, rank_id: 0, loss: 0.897646, lr: 0.0000020000, speed: 13.1413 step/s
global step 13000/245440, epoch: 0, batch: 12999, rank_id: 0, loss: 1.040922, lr: 0.0000020000, speed: 13.0463 step/s
global step 13200/245440, epoch: 0, batch: 13199, rank_id: 0, loss: 0.379575, lr: 0.0000020000, speed: 12.8124 step/s
[2022-05-10 14:31:00,680] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 13400/245440, epoch: 0, batch: 13399, rank_id: 0, loss: 0.735760, lr: 0.0000020000, speed: 13.1080 step/s
[2022-05-10 14:31:13,998] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 13600/245440, epoch: 0, batch: 13599, rank_id: 0, loss: 0.357004, lr: 0.0000020000, speed: 12.8219 step/s
global step 13800/245440, epoch: 0, batch: 13799, rank_id: 0, loss: 1.621418, lr: 0.0000020000, speed: 12.8281 step/s
global step 14000/245440, epoch: 0, batch: 13999, rank_id: 0, loss: 0.623193, lr: 0.0000020000, speed: 13.0207 step/s
[2022-05-10 14:31:59,864] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 14200/245440, epoch: 0, batch: 14199, rank_id: 0, loss: 0.468295, lr: 0.0000020000, speed: 12.8845 step/s
global step 14400/245440, epoch: 0, batch: 14399, rank_id: 0, loss: 0.539498, lr: 0.0000020000, speed: 13.0888 step/s
global step 14600/245440, epoch: 0, batch: 14599, rank_id: 0, loss: 1.127107, lr: 0.0000020000, speed: 12.8566 step/s
global step 14800/245440, epoch: 0, batch: 14799, rank_id: 0, loss: 0.656049, lr: 0.0000020000, speed: 13.0170 step/s
[2022-05-10 14:32:53,928] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 15000/245440, epoch: 0, batch: 14999, rank_id: 0, loss: 0.782793, lr: 0.0000020000, speed: 13.2253 step/s
global step 15200/245440, epoch: 0, batch: 15199, rank_id: 0, loss: 0.539206, lr: 0.0000020000, speed: 12.9239 step/s
global step 15400/245440, epoch: 0, batch: 15399, rank_id: 0, loss: 0.760149, lr: 0.0000020000, speed: 12.7182 step/s
[2022-05-10 14:33:40,981] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 15600/245440, epoch: 0, batch: 15599, rank_id: 0, loss: 0.407618, lr: 0.0000020000, speed: 12.7510 step/s
global step 15800/245440, epoch: 0, batch: 15799, rank_id: 0, loss: 0.537201, lr: 0.0000020000, speed: 12.9010 step/s
[2022-05-10 14:34:14,123] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 16000/245440, epoch: 0, batch: 15999, rank_id: 0, loss: 0.898612, lr: 0.0000020000, speed: 13.0609 step/s
global step 16200/245440, epoch: 0, batch: 16199, rank_id: 0, loss: 0.461565, lr: 0.0000020000, speed: 12.9833 step/s
global step 16400/245440, epoch: 0, batch: 16399, rank_id: 0, loss: 0.265601, lr: 0.0000020000, speed: 12.7207 step/s
global step 16600/245440, epoch: 0, batch: 16599, rank_id: 0, loss: 0.853703, lr: 0.0000020000, speed: 12.9646 step/s
global step 16800/245440, epoch: 0, batch: 16799, rank_id: 0, loss: 0.413988, lr: 0.0000020000, speed: 13.1483 step/s
[2022-05-10 14:35:33,286] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 17000/245440, epoch: 0, batch: 16999, rank_id: 0, loss: 0.731050, lr: 0.0000020000, speed: 12.8153 step/s
global step 17200/245440, epoch: 0, batch: 17199, rank_id: 0, loss: 0.413464, lr: 0.0000020000, speed: 12.9635 step/s
[2022-05-10 14:35:57,043] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 17400/245440, epoch: 0, batch: 17399, rank_id: 0, loss: 0.701752, lr: 0.0000020000, speed: 12.4478 step/s
global step 17600/245440, epoch: 0, batch: 17599, rank_id: 0, loss: 0.152788, lr: 0.0000020000, speed: 12.9928 step/s
global step 17800/245440, epoch: 0, batch: 17799, rank_id: 0, loss: 0.422913, lr: 0.0000020000, speed: 12.9624 step/s
global step 18000/245440, epoch: 0, batch: 17999, rank_id: 0, loss: 0.494070, lr: 0.0000020000, speed: 12.9348 step/s
[2022-05-10 14:37:12,847] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 18200/245440, epoch: 0, batch: 18199, rank_id: 0, loss: 0.112908, lr: 0.0000020000, speed: 12.9248 step/s
global step 18400/245440, epoch: 0, batch: 18399, rank_id: 0, loss: 0.415995, lr: 0.0000020000, speed: 12.8887 step/s
global step 18600/245440, epoch: 0, batch: 18599, rank_id: 0, loss: 1.135111, lr: 0.0000020000, speed: 12.9987 step/s
global step 18800/245440, epoch: 0, batch: 18799, rank_id: 0, loss: 0.983934, lr: 0.0000020000, speed: 13.2320 step/s
global step 19000/245440, epoch: 0, batch: 18999, rank_id: 0, loss: 0.663578, lr: 0.0000020000, speed: 13.1050 step/s
global step 19200/245440, epoch: 0, batch: 19199, rank_id: 0, loss: 0.642299, lr: 0.0000020000, speed: 13.0654 step/s
[2022-05-10 14:38:38,197] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 19400/245440, epoch: 0, batch: 19399, rank_id: 0, loss: 0.362838, lr: 0.0000020000, speed: 12.9993 step/s
global step 19600/245440, epoch: 0, batch: 19599, rank_id: 0, loss: 0.580698, lr: 0.0000020000, speed: 12.8916 step/s
global step 19800/245440, epoch: 0, batch: 19799, rank_id: 0, loss: 0.705512, lr: 0.0000020000, speed: 12.9600 step/s
global step 20000/245440, epoch: 0, batch: 19999, rank_id: 0, loss: 0.575578, lr: 0.0000020000, speed: 13.3108 step/s
global step 20200/245440, epoch: 0, batch: 20199, rank_id: 0, loss: 0.694857, lr: 0.0000020000, speed: 12.7839 step/s
global step 20400/245440, epoch: 0, batch: 20399, rank_id: 0, loss: 0.536539, lr: 0.0000020000, speed: 12.9260 step/s
global step 20600/245440, epoch: 0, batch: 20599, rank_id: 0, loss: 0.636209, lr: 0.0000020000, speed: 13.1394 step/s
global step 20800/245440, epoch: 0, batch: 20799, rank_id: 0, loss: 0.848785, lr: 0.0000020000, speed: 12.9655 step/s
global step 21000/245440, epoch: 0, batch: 20999, rank_id: 0, loss: 0.481010, lr: 0.0000020000, speed: 12.8942 step/s
global step 21200/245440, epoch: 0, batch: 21199, rank_id: 0, loss: 0.326948, lr: 0.0000020000, speed: 13.1130 step/s
[2022-05-10 14:41:10,197] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 21400/245440, epoch: 0, batch: 21399, rank_id: 0, loss: 0.328224, lr: 0.0000020000, speed: 12.6847 step/s
[2022-05-10 14:41:32,730] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
[2022-05-10 14:41:35,312] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 21600/245440, epoch: 0, batch: 21599, rank_id: 0, loss: 0.588411, lr: 0.0000020000, speed: 12.6730 step/s
global step 21800/245440, epoch: 0, batch: 21799, rank_id: 0, loss: 0.463699, lr: 0.0000020000, speed: 12.9696 step/s
global step 22000/245440, epoch: 0, batch: 21999, rank_id: 0, loss: 1.132344, lr: 0.0000020000, speed: 13.1858 step/s
global step 22200/245440, epoch: 0, batch: 22199, rank_id: 0, loss: 0.178347, lr: 0.0000020000, speed: 13.0801 step/s
[2022-05-10 14:42:28,984] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 22400/245440, epoch: 0, batch: 22399, rank_id: 0, loss: 0.664890, lr: 0.0000020000, speed: 12.8744 step/s
[2022-05-10 14:42:43,250] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 22600/245440, epoch: 0, batch: 22599, rank_id: 0, loss: 2.048761, lr: 0.0000020000, speed: 13.0406 step/s
global step 22800/245440, epoch: 0, batch: 22799, rank_id: 0, loss: 1.027367, lr: 0.0000020000, speed: 12.8473 step/s
global step 23000/245440, epoch: 0, batch: 22999, rank_id: 0, loss: 0.323159, lr: 0.0000020000, speed: 13.1574 step/s
global step 23200/245440, epoch: 0, batch: 23199, rank_id: 0, loss: 0.310109, lr: 0.0000020000, speed: 13.1999 step/s
[2022-05-10 14:43:42,702] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 23400/245440, epoch: 0, batch: 23399, rank_id: 0, loss: 0.160734, lr: 0.0000020000, speed: 13.0425 step/s
global step 23600/245440, epoch: 0, batch: 23599, rank_id: 0, loss: 0.550592, lr: 0.0000020000, speed: 12.8480 step/s
global step 23800/245440, epoch: 0, batch: 23799, rank_id: 0, loss: 0.310558, lr: 0.0000020000, speed: 12.9522 step/s
global step 24000/245440, epoch: 0, batch: 23999, rank_id: 0, loss: 0.434293, lr: 0.0000020000, speed: 12.8234 step/s
global step 24200/245440, epoch: 0, batch: 24199, rank_id: 0, loss: 0.864846, lr: 0.0000020000, speed: 12.8260 step/s
global step 24400/245440, epoch: 0, batch: 24399, rank_id: 0, loss: 0.324771, lr: 0.0000020000, speed: 12.8979 step/s
[AR] acc: 0.6499001996007984,
[BG] acc: 0.7005988023952096,
[DE] acc: 0.7219560878243513,
[EL] acc: 0.7119760479041917,
[EN] acc: 0.8145708582834331,
[ES] acc: 0.744311377245509,
[FR] acc: 0.7413173652694611,
[HI] acc: 0.6171656686626746,
[RU] acc: 0.7013972055888223,
[SW] acc: 0.631936127744511,
[TH] acc: 0.6624750499001996,
[TR] acc: 0.6624750499001996,
[UR] acc: 0.6295409181636726,
[VI] acc: 0.7015968063872255,
Building prefix dict from the default dictionary ...
Dumping model to file cache /tmp/jieba.cache
Loading model cost 0.799 seconds.
Prefix dict has been built successfully.
[ZH] acc: 0.6822355289421158,
test mean acc: 0.6916
[2022-05-10 14:49:53,998] [ INFO] - tokenizer config file saved in outputs/best_model/tokenizer_config.json
[2022-05-10 14:49:53,998] [ INFO] - Special tokens file saved in outputs/best_model/special_tokens_map.json
best test mean acc: 0.6916
Save model and tokenizer to outputs/best_model
global step 24600/245440, epoch: 0, batch: 24599, rank_id: 0, loss: 0.890836, lr: 0.0000020000, speed: 0.6988 step/s
global step 24800/245440, epoch: 0, batch: 24799, rank_id: 0, loss: 0.667289, lr: 0.0000020000, speed: 12.8063 step/s
global step 25000/245440, epoch: 0, batch: 24999, rank_id: 0, loss: 0.699567, lr: 0.0000020000, speed: 12.6451 step/s
[2022-05-10 14:50:31,391] [ WARNING] - Be aware, overflowing tokens are not returned for the setting you have chosen, i.e. sequence pairs with the 'longest_first' truncation strategy. So the returned list will always be empty even if some tokens have been removed.
global step 25200/245440, epoch: 0, batch: 25199, rank_id: 0, loss: 0.628719, lr: 0.0000020000, speed: 12.7678 step/s
global step 25400/245440, epoch: 0, batch: 25399, rank_id: 0, loss: 1.258356, lr: 0.0000020000, speed: 12.8640 step/s
global step 25600/245440, epoch: 0, batch: 25599, rank_id: 0, loss: 0.275401, lr: 0.0000020000, speed: 12.7896 step/s
global step 25800/245440, epoch: 0, batch: 25799, rank_id: 0, loss: 0.471893, lr: 0.0000020000, speed: 12.6792 step/s
global step 26000/245440, epoch: 0, batch: 25999, rank_id: 0, loss: 0.258921, lr: 0.0000020000, speed: 12.4272 step/s
global step 26200/245440, epoch: 0, batch: 26199, rank_id: 0, loss: 1.001992, lr: 0.0000020000, speed: 12.1006 step/s
^C
Traceback (most recent call last):
File "run_classifier.py", line 311, in <module>
File "run_classifier.py", line 261, in do_train
File "<decorator-gen-225>", line 2, in step
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/base.py", line 296, in __impl__
return func(*args, **kwargs)
File "<decorator-gen-223>", line 2, in step
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/wrapped_decorator.py", line 25, in __impl__
return wrapped_func(*args, **kwargs)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/framework.py", line 229, in __impl__
return func(*args, **kwargs)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/optimizer/adam.py", line 422, in step
loss=None, startup_program=None, params_grads=params_grads)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/optimizer/optimizer.py", line 891, in _apply_optimize
optimize_ops = self._create_optimization_pass(params_grads)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/optimizer/optimizer.py", line 696, in _create_optimization_pass
self._append_optimize_op(target_block, param_and_grad)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/optimizer/adam.py", line 331, in _append_optimize_op
'beta2', _beta2, 'multi_precision', find_master)
KeyboardInterrupt
In [2]
# evaluate
# 确保训练完毕。
!python xlm_eval.py --batch_size 8 --model_name_or_path ./outputs/best_model----------- Configuration Arguments ----------- batch_size: 8 device: gpu max_seq_length: 256 model_name_or_path: ./outputs/best_model ------------------------------------------------ W0510 15:04:15.468076 15019 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0510 15:04:15.471441 15019 device_context.cc:465] device: 0, cuDNN Version: 7.6. [2022-05-10 15:04:25,729] [ WARNING] - Truncation was not explicitly activated but `max_length` is provided a specific value, please use `truncation=True` to explicitly truncate examples to max length. Defaulting to 'longest_first' truncation strategy. If you encode pairs of sequences (GLUE-style) with the tokenizer you can select this strategy more precisely by providing a specific strategy to `truncation`. [AR] acc: 0.6499001996007984 [BG] acc: 0.7005988023952096 [DE] acc: 0.7219560878243513 [EL] acc: 0.7119760479041917 [EN] acc: 0.8145708582834331 [ES] acc: 0.744311377245509 [FR] acc: 0.7413173652694611 [HI] acc: 0.6171656686626746 [RU] acc: 0.7013972055888223 [SW] acc: 0.631936127744511 [TH] acc: 0.6624750499001996 [TR] acc: 0.6624750499001996 [UR] acc: 0.6295409181636726 [VI] acc: 0.7015968063872255 Building prefix dict from the default dictionary ... Loading model from cache /tmp/jieba.cache Loading model cost 0.704 seconds. Prefix dict has been built successfully. [ZH] acc: 0.6822355289421158 test mean acc: 0.6916
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)