
快速实践大规模轻量级图片分类模型:飞桨识图 PP-ShiTu
飞桨识图 PP-ShiTu是大规模轻量级图片分类模型,重建索引速度快,识别速度快,上手快!展示了官方的饮料数据集和斯坦福在线商品数据集上的效果。
快速实践大规模图片分类模型:飞桨识图 PP-ShiTu
飞桨识图PP-ShiTu是轻量级图像识别系统,集成了目标检测、特征学习、图像检索等模块,广泛适用于各类图像识别任务。CPU上0.2s即可完成在10w+库的图像识别。

本项目第一部分为官方demo示例,超市饮料识别。整个例子简单易懂,重建速度快,识别速度快,整体效果相当惊艳。尤其是重建索引部分,颠覆了我们常规图像分类训练耗时长,重训费时费力的传统观念。
本项目第二部分为动手实践,根据官方示例,稍微动动手,就能将飞桨识图应用在斯坦福商品分类数据集上。斯坦福商品分类数据集有22634个类别,重建索引只需要6分钟,又一次颠覆了我的认知。
官网手册镜像地址
https://hub.fastgit.org/PaddlePaddle/PaddleClas/blob/release/2.3/docs/zh_CN/quick_start/quick_start_recognition.md
斯坦福商品分类数据集:
https://aistudio.baidu.com/aistudio/datasetdetail/5103
学有余力的朋友们可以挑战下这个商超检测数据集:
https://aistudio.baidu.com/aistudio/datasetdetail/52226
PP-ShiTu之手把手教你玩转图像识别
图像识别简介
图像识别,是指利用计算机对图像进行处理、分析和理解,以识别各种不同模式的目标和对象的技术,是应用深度学习算法的一种实践应用。图像的传统识别流程分为四个步骤:图像采集→图像预处理→特征提取→图像识别。但是在于特征提取阶段,利用传统的分类网络,需要提前在训练集中补充所需识别的类别的训练图片,一旦有新增的类别就需要对模型重新训练,无论是训练成本还是数据成本都很高。
类似人脸识别,对于动漫人物识别而已,每个不同的动漫角色都可以看做为一个单独的类别,所以类别数量很难穷举,并且更新需求较大。本次的PaddleClas V2.3提出了PP-ShiTu超轻量识别。
Metric Learning可以借助一系列观测,根据不一样的任务来自主学习出针对某个特定任务的度量距离函数,通过计算两张图片之间的相似度,使得输入图片被归入到相似度大的图片类别中去,从而学习数据间的的距离或差异,有效地描述样本之间的相似度。相比于传统的识别网络是丢弃经典神经网络最后的softmax层,改成直接输出feature vector,去特征库里面按照Metric Learning寻找最近邻的类别作为匹配项。
拥有了强大的特征提取网络,一套完美的识别系统当然也少不了高效的检索模块。在PP-ShiTu中,PaddleClas使用了经过广泛验证并且能够适配于多端多平台的检索系统:faiss。
这样一来就能够避免每次新增类别重新训练的困难,并且对于样本数量很少的类别,在拥有了较好的特征提取网络的前提下,能够直接将小样本数据补充进特征检索库,避免了训练集的大量数据要求,从而实现识别效果。
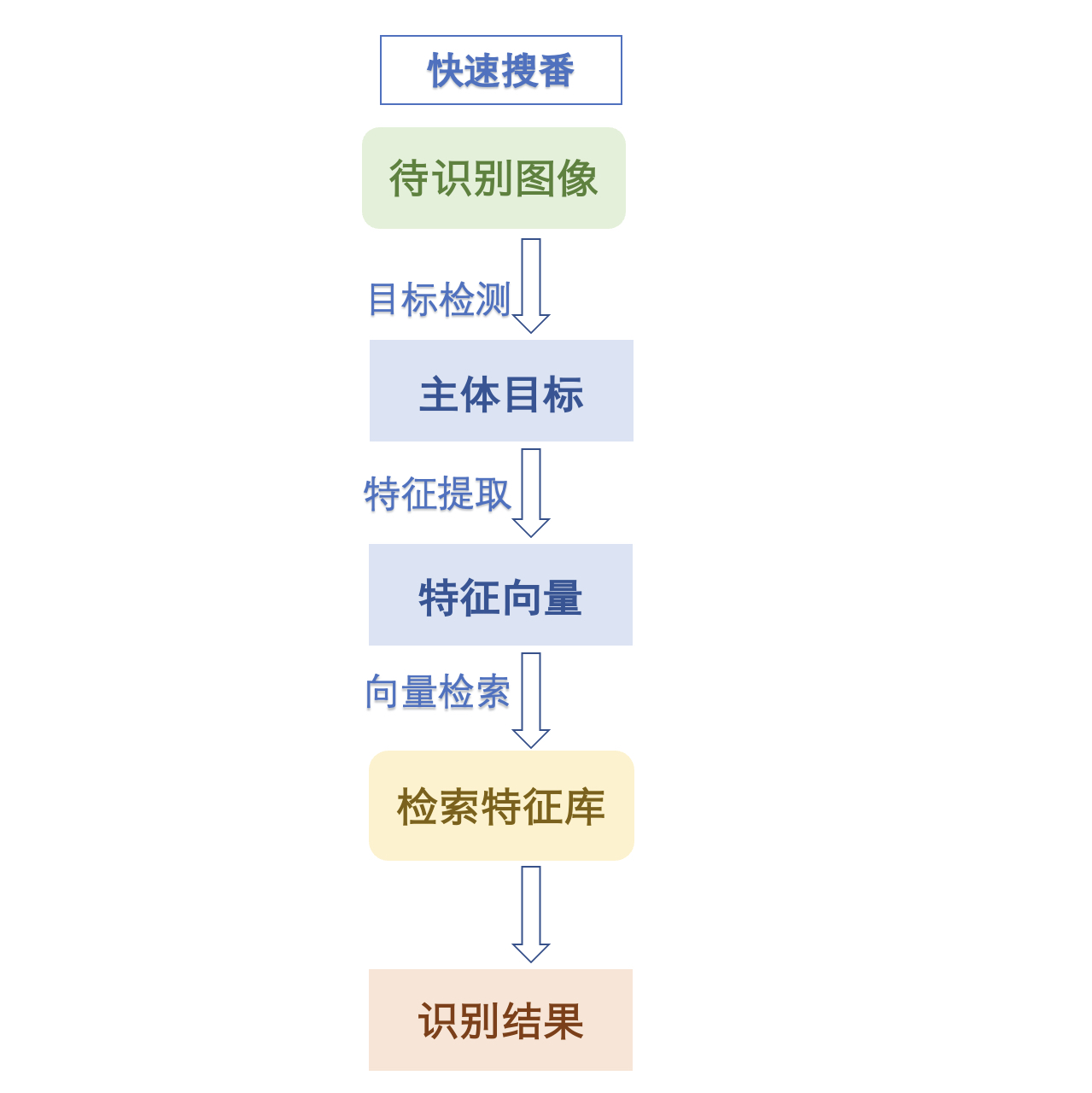
总体来看,图像识别一共包含4个步骤。
- 第一步:准备好需要识别的图片;
- 第二步:通过主体检测模型 定位主体所在位置;
- 第三步:利用metric learning进行特征提取;
- 第四步:经过检索快速匹配最相似结果;
1. 环境配置
- 下载PaddleClas:下载官方repo的PaddleClas代码
!git clone https://hub.fastgit.org/PaddlePaddle/PaddleClas
正克隆到 'PaddleClas'...
remote: Enumerating objects: 22011, done.[K
remote: Counting objects: 100% (882/882), done.[K
remote: Compressing objects: 100% (504/504), done.[K
remote: Total 22011 (delta 540), reused 580 (delta 377), pack-reused 21129[K
接收对象中: 100% (22011/22011), 152.48 MiB | 5.71 MiB/s, 完成.
处理 delta 中: 100% (14792/14792), 完成.
检查连接... 完成。
- 安装requirements。
# 大约耗时40秒
!pip install pip -U
!cd PaddleClas && pip install -r requirements.txt -Uq
2. 图像识别体验
轻量级通用主体检测模型与轻量级通用识别模型和配置文件下载方式如下表所示。
| 模型简介 | 推荐场景 | inference模型 | 预测配置文件 | 构建索引库的配置文件 |
|---|---|---|---|---|
| 轻量级通用主体检测模型 | 通用场景 | 模型下载链接 | - | - |
| 轻量级通用识别模型 | 通用场景 | 模型下载链接 | inference_general.yaml | build_general.yaml |
本章节 demo 数据下载地址如下: 瓶装饮料数据下载链接。
注意
- 可以按照下面的命令下载并解压数据与模型
mkdir models
cd models
# 下载识别inference模型并解压
wget {模型下载链接地址} && tar -xf {压缩包的名称}
cd ..
# 下载demo数据并解压
wget {数据下载链接地址} && tar -xf {压缩包的名称}
- 使用下面的命令将默认工作目录切换到PaddleClas的deploy文件夹下
# import os
# os.chdir("/home/aistudio/PaddleClas/deploy")
# !pwd
%cd ~/PaddleClas/deploy
/home/aistudio/PaddleClas/deploy
2.1 下载、解压 inference 模型与 demo 数据
下载demo数据集以及通用检测、识别模型,命令如下。
!mkdir models
!cd models && wget https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/rec/models/inference/picodet_PPLCNet_x2_5_mainbody_lite_v1.0_infer.tar && tar -xf picodet_PPLCNet_x2_5_mainbody_lite_v1.0_infer.tar
!cd models && wget https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/rec/models/inference/general_PPLCNet_x2_5_lite_v1.0_infer.tar && tar -xf general_PPLCNet_x2_5_lite_v1.0_infer.tar
!wget https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/rec/data/drink_dataset_v1.0.tar && tar -xf drink_dataset_v1.0.tar
解压完毕后,drink_dataset_v1.0/ 文件夹下应有如下文件结构:
├── drink_dataset_v1.0/
│ ├── gallery/
│ ├── index/
│ ├── test_images/
├── ...
其中 gallery 文件夹中存放的是用于构建索引库的原始图像,index 表示基于原始图像构建得到的索引库信息, test_images 文件夹中存放的是用于测试识别效果的图像列表。
models 文件夹下应有如下文件结构:
├── general_PPLCNet_x2_5_lite_v1.0_infer
│ ├── inference.pdiparams
│ ├── inference.pdiparams.info
│ └── inference.pdmodel
├── picodet_PPLCNet_x2_5_mainbody_lite_v1.0_infer
│ ├── inference.pdiparams
│ ├── inference.pdiparams.info
│ └── inference.pdmodel
2.2 瓶装饮料识别与检索
以瓶装饮料识别demo为例,展示识别与检索过程(如果希望尝试其他方向的识别与检索效果,在下载解压好对应的demo数据与模型之后,替换对应的配置文件即可完成预测)。
2.2.1 识别单张图像
运行下面的命令,对图像 ./drink_dataset_v1.0/test_images/nongfu_spring.jpeg 进行识别与检索
!python python/predict_system.py -c configs/inference_general.yaml
待检索图像如下所示。

最终输出结果如下。
[{'bbox': [244, 49, 509, 964], 'rec_docs': '农夫山泉-饮用天然水', 'rec_scores': 0.7585664}]
其中bbox表示检测出的主体所在位置,rec_docs表示索引库中与检测框最为相似的类别,rec_scores表示对应的置信度。
检测的可视化结果也保存在output文件夹下,对于本张图像,识别结果可视化如下所示。

2.2.2 基于文件夹的批量识别
如果希望预测文件夹内的图像,可以直接修改配置文件中的Global.infer_imgs字段,也可以通过下面的-o参数修改对应的配置。
!python python/predict_system.py -c configs/inference_general.yaml -o Global.infer_imgs="./drink_dataset_v1.0/test_images/"
终端中会输出该文件夹内所有图像的识别结果,如下所示。
...
[{'bbox': [345, 95, 524, 586], 'rec_docs': '红牛-强化型', 'rec_scores': 0.80164653}]
Inference: 23.43583106994629 ms per batch image
[{'bbox': [233, 0, 372, 436], 'rec_docs': '康师傅矿物质水', 'rec_scores': 0.72513914}]
Inference: 117.95639991760254 ms per batch image
[{'bbox': [138, 40, 573, 1198], 'rec_docs': '乐虎功能饮料', 'rec_scores': 0.7855944}]
Inference: 22.172927856445312 ms per batch image
[{'bbox': [328, 7, 467, 272], 'rec_docs': '脉动', 'rec_scores': 0.5829516}]
Inference: 118.08514595031738 ms per batch image
[{'bbox': [242, 82, 498, 726], 'rec_docs': '味全_每日C', 'rec_scores': 0.75581443}]
Inference: 150.06470680236816 ms per batch image
[{'bbox': [437, 71, 660, 728], 'rec_docs': '元气森林', 'rec_scores': 0.8478892}, {'bbox': [221, 72, 449, 701], 'rec_docs': '元气森林', 'rec_scores': 0.6790612}, {'bbox': [794, 104, 979, 652], 'rec_docs': '元气森林', 'rec_scores': 0.6292581}]
...
所有图像的识别结果可视化图像也保存在`output`文件夹内。
更多地,可以通过修改`Global.rec_inference_model_dir`字段来更改识别inference模型的路径,通过修改`IndexProcess.index_dir`字段来更改索引库索引的路径。
## 3. 未知类别的图像识别体验
对图像 `./drink_dataset_v1.0/test_images/mosilian.jpeg` 进行识别,命令如下
```python
# 使用下面的命令使用 GPU 进行预测,如果希望使用 CPU 预测,可以在命令后面添加 -o Global.use_gpu=False
!python3.7 python/predict_system.py -c configs/inference_general.yaml -o Global.infer_imgs="./drink_dataset_v1.0/test_images/mosilian.jpeg"
待检索图像如下所示。

输出结果为空。
由于默认的索引库中不包含对应的索引信息,所以这里的识别结果有误,此时我们可以通过构建新的索引库的方式,完成未知类别的图像识别。
当索引库中的图像无法覆盖我们实际识别的场景时,即在预测未知类别的图像时,我们需要将对应类别的相似图像添加到索引库中,从而完成对未知类别的图像识别,这一过程是不需要重新训练的。
3.1 准备新的数据与标签
首先需要将与待检索图像相似的图像列表拷贝到索引库原始图像的文件夹。这里 PaddleClas 已经将所有的图像数据都放在文件夹 drink_dataset_v1.0/gallery/ 中。
然后需要编辑记录了图像路径和标签信息的文本文件,这里 PaddleClas 将更正后的标签信息文件放在了 drink_dataset_v1.0/gallery/drink_label_all.txt 文件中。可以与默认的 drink_dataset_v1.0/gallery/drink_label.txt 标签文件进行对比,添加了光明和三元系列牛奶的索引图像。
每一行的文本中,第一个字段表示图像的相对路径,第二个字段表示图像对应的标签信息,中间用 \t 键分隔开(注意:有些编辑器会将 tab 自动转换为 空格 ,这种情况下会导致文件解析报错)。
# 建立新的索引
!python3.7 python/build_gallery.py -c configs/build_general.yaml -o IndexProcess.data_file="./drink_dataset_v1.0/gallery/drink_label_all.txt" -o IndexProcess.index_dir="./drink_dataset_v1.0/index_all"
最终新的索引信息保存在文件夹 ./drink_dataset_v1.0/index_all 中。
3.3 基于新的索引库的图像识别
使用新的索引库,对上述图像进行识别,运行命令如下。
# 使用下面的命令使用 GPU 进行预测,如果希望使用 CPU 预测,可以在命令后面添加 -o Global.use_gpu=False
!python3.7 python/predict_system.py -c configs/inference_general.yaml -o Global.infer_imgs="./drink_dataset_v1.0/test_images/mosilian.jpeg" -o IndexProcess.index_dir="./drink_dataset_v1.0/index_all"
输出结果如下。
[{'bbox': [396, 553, 508, 621], 'rec_docs': '光明_莫斯利安', 'rec_scores': 0.5921005}]
最终识别结果为安慕希酸奶,识别正确,识别结果可视化如下所示。

- 上面就完成了整个识别的过程,考虑到大家可能会自己修改配置文件,这里以
configs/inference_general.yaml和configs/build_general.yaml为例,给大家介绍下配置文件中的一些参数说明。 - 下面是
configs/inference_general.yaml中的一些参数配置
Global:
# 全局配置
infer_imgs: "./drink_dataset_v1.0/test_images/nongfu_spring.jpeg" # 预测的图片或者预测
det_inference_model_dir: "./models/picodet_PPLCNet_x2_5_mainbody_lite_v1.0_infer" # 检测inference模型路径
rec_inference_model_dir: "./models/general_PPLCNet_x2_5_lite_v1.0_infer" # 识别inference模型路径
rec_nms_thresold: 0.05 # 识别结果的nms阈值
# 主体检测相关配置
batch_size: 1
image_shape: [3, 640, 640] # 输入图像的尺度
threshold: 0.2 # 检测得分阈值
max_det_results: 5 # 返回检测框的最大值
labe_list: # 检测label list
- foreground
# 预测引擎相关配置
use_gpu: True
enable_mkldnn: True
cpu_num_threads: 10
enable_benchmark: True
use_fp16: False
ir_optim: True
use_tensorrt: False
gpu_mem: 8000
enable_profile: False
# 检测预处理
DetPreProcess:
transform_ops:
- DetResize:
interp: 2
keep_ratio: false
target_size: [640, 640]
- DetNormalizeImage:
is_scale: true
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
- DetPermute: {}
DetPostProcess: {}
# 识别预处理
RecPreProcess:
transform_ops:
- ResizeImage:
size: 224
- NormalizeImage:
scale: 0.00392157
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
- ToCHWImage:
RecPostProcess: null
# 索引引擎配置
IndexProcess:
# 索引文件所在目录
index_dir: "./drink_dataset_v1.0/index"
# 返回的检索top-k数量
return_k: 5
# 得分阈值
score_thres: 0.5
- 下面是
configs/build_general.yaml中的一些参数配置
Global:
rec_inference_model_dir: "./models/general_PPLCNet_x2_5_lite_v1.0_infer" # 用于提取特征建库的inference model
batch_size: 32 # 提取特征的batch size
use_gpu: True # 是否使用GPU建库
enable_mkldnn: True
cpu_num_threads: 10
enable_benchmark: True
use_fp16: False
ir_optim: True
use_tensorrt: False
gpu_mem: 8000
enable_profile: False
# 识别预处理
RecPreProcess:
transform_ops:
- ResizeImage:
size: 224
- NormalizeImage:
scale: 0.00392157
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
- ToCHWImage:
RecPostProcess: null
# 索引引擎配置
IndexProcess:
# hnsw32是一种图检索引方式,检索速度快,精度高,但是不支持删已添加的数据。
# ivf是倒排索引的方法。
# flat是暴力检索
index_method: "HNSW32" # supported: HNSW32, IVF, Flat
# 保存的索引文件
index_dir: "./drink_dataset_v1.0/index"
# 图片路径
image_root: "./drink_dataset_v1.0/gallery/"
# 数据标签文件
data_file: "./drink_dataset_v1.0/gallery/drink_label.txt"
# 索引的操作形式
index_operation: "new" # suported: "append", "remove", "new"
# 标签文件的分割符
delimiter: "\t"
# dist_type 是检索的时候使用哪种距离计算方式,支持hamming和IP
# hamming 是汉明距离,一般是配合哈希的向量使用。
# IP是内积的相似度计算方式
dist_type: "IP"
# embedding size
embedding_size: 512
4. 同一幅图片上有多个待检测物体
同一幅图片上有多个待检测物体,也可以一起识别出来。
把两幅图片通过截图的方式,生成一张图片,进行识别操作。
# 使用下面的命令使用 GPU 进行预测,如果希望使用 CPU 预测,可以在命令后面添加 -o Global.use_gpu=False
!python3.7 python/predict_system.py -c configs/inference_general.yaml -o Global.infer_imgs="../../work/twojuice.png" -o IndexProcess.index_dir="./drink_dataset_v1.0/index_all" # -o Global.use_gpu=False
# 看一下测试文件的输出,可以看到红牛和脉动都检测出来了
from IPython.display import display, Image
path = "./output/twojuice.png"
img = Image(path)
display(img)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PefToGJu-1639802078166)(output_32_0.png)]](https://i-blog.csdnimg.cn/blog_migrate/1bc1d37890d5c816d9c7b5de6afb0f7e.png)
飞桨识图斯坦福在线商品分类
飞桨识图实现斯坦福在线商品分类,操作步骤非常简单:
- 准备好数据集
- 建立索引
- 开始识别
1. 准备好数据集:斯坦福数据集介绍和操作
Stanford Online Products Dataset. 包含120053张商品图片,有22634个类别,解压后使用。
其中训练集Ebay_train.txt 59551 张图片,11318 个类别;验证集Ebay_test.txt 60502 张图片,11316 个类别。
每条记录格式为:‘59552 11319 1 bicycle_final/251952414262_0.JPG\n’
使用转换命令,将其转换成如下格式:
‘bicycle_final/111085122871_0.JPG 1\n’
可以参考以前的一个斯坦福商品数据集分类的项目,学习里面的数据集操作方法。项目地址:
https://aistudio.baidu.com/aistudio/projectdetail/169466
第一次转换之后,建立索引的时候报错,后来发现飞桨识图文件中使用/t分隔,命令中进行相应修改即可。
跑准确率的时候,发现原来的训练集和验证集标记不一样,重新从Ebay_info.txt文件中生成和划分训练集和验证集,使用8:2比例。
解压和生成飞桨识图格式数据集索引文件
# 28秒解压 解压到PaddleClas/deploy/Stanford_Online_Products 目录
!unzip -q ~/data/data5103/Stanford_Online_Products.zip
# 在目录/home/aistudio/PaddleClas/deploy/Stanford_Online_Products里面生成训练和验证集
# !cd /home/aistudio/PaddleClas/deploy/Stanford_Online_Products && sed '1d' Ebay_train.txt | awk -F' ' '{print $4"\t"$2}' > train.txt
# !cd /home/aistudio/PaddleClas/deploy/Stanford_Online_Products && sed '1d' Ebay_test.txt | awk -F' ' '{print $4"\t"$2}' > test.txt
!cd /home/aistudio/PaddleClas/deploy/Stanford_Online_Products && sed '1d' Ebay_info.txt | awk -F' ' '{print $4"\t"$2}' > Ebay.txt
# 使用8:2比例生成训练集和验证集
%cd /home/aistudio/PaddleClas/deploy/Stanford_Online_Products
bili = 0.8
ebaytest = []
with open("Ebay.txt", "r") as f:
ebaytest = f.readlines()
lenth = len(ebaytest)
import random
random.shuffle(ebaytest) # shuffle乱序
random.shuffle(ebaytest)
random.shuffle(ebaytest)
# print(lenth)
train = ebaytest[:int(lenth*0.8)] # 按比例切分数据集
val = ebaytest[int(lenth*0.8):]
with open("train.txt", "w") as f: # 写训练集
for i in train:
f.write(f"{i}")
with open("val.txt", "w") as f:
for i in val:
f.writelines(f"{i}")
%cd /home/aistudio/PaddleClas/deploy/ # 再回到工作目录
2. 生成yaml配置文件并建立索引
%%writefile ~/work/build_general.yaml
Global:
rec_inference_model_dir: "./models/general_PPLCNet_x2_5_lite_v1.0_infer"
batch_size: 32
use_gpu: True
enable_mkldnn: True
cpu_num_threads: 10
enable_benchmark: True
use_fp16: False
ir_optim: True
use_tensorrt: False
gpu_mem: 8000
enable_profile: False
RecPreProcess:
transform_ops:
- ResizeImage:
size: 224
- NormalizeImage:
scale: 0.00392157
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
- ToCHWImage:
RecPostProcess: null
# indexing engine config
IndexProcess:
index_method: "HNSW32" # supported: HNSW32, IVF, Flat
image_root: "./Stanford_Online_Products"
index_dir: "./Stanford_Online_Products/index"
data_file: "./Stanford_Online_Products/train.txt"
index_operation: "new" # suported: "append", "remove", "new"
delimiter: "\t"
dist_type: "IP"
embedding_size: 512
Overwriting /home/aistudio/work/build_general.yaml
# 建立新的索引 用时523秒
!python3.7 python/build_gallery.py -c ~/work/build_general.yaml -o IndexProcess.data_file="./Stanford_Online_Products/train.txt" -o IndexProcess.index_dir="./Stanford_Online_Products/index"
# 看下斯坦福数据集格式
# with open("./Stanford_Online_Products/train.txt", 'rb') as dchfile:
# tmp = dchfile.readlines()
# print(len(tmp))
# print(tmp[:10])
# 看下飞桨识图里的数据集格式
# with open("./drink_dataset_v1.0/gallery/drink_label.txt", 'rb') as dchfile:
# tmp = dchfile.readlines()
# print(len(tmp))
# print(tmp[:10])
通过将两个文件打印出来,发现格式不一样,
官方数据集训练索引文件中每条数据里面用的/t分割,而我的数据里面使用的空格,因此将前面生成train.txt文件的命令中’{print $4" “$2}‘修改成’{print $4”\t"$2}'即可。
3. 图像检测和识别
生成识别配置文件
修改官方手册demo里的配置文件,如果希望预测文件夹内的图像,可以直接修改配置文件中的Global.infer_imgs字段,也可以通过在命令中加入-o参数修改对应的配置。
%%writefile ~/work/inference_general.yaml
Global:
# 全局配置
infer_imgs: "./Stanford_Online_Products/bicycle_final/111085122871_0.JPG" # 预测的图片或者预测路径
det_inference_model_dir: "./models/picodet_PPLCNet_x2_5_mainbody_lite_v1.0_infer" # 检测inference模型路径
rec_inference_model_dir: "./models/general_PPLCNet_x2_5_lite_v1.0_infer" # 识别inference模型路径
rec_nms_thresold: 0.05 # 识别结果的nms阈值
# 主体检测相关配置
batch_size: 1
image_shape: [3, 640, 640] # 输入图像的尺度
threshold: 0.2 # 检测得分阈值
max_det_results: 5 # 返回检测框的最大值
labe_list: # 检测label list
- foreground
# 预测引擎相关配置
use_gpu: True
enable_mkldnn: True
cpu_num_threads: 10
enable_benchmark: True
use_fp16: False
ir_optim: True
use_tensorrt: False
gpu_mem: 8000
enable_profile: False
# 检测预处理
DetPreProcess:
transform_ops:
- DetResize:
interp: 2
keep_ratio: false
target_size: [640, 640]
- DetNormalizeImage:
is_scale: true
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
- DetPermute: {}
DetPostProcess: {}
# 识别预处理
RecPreProcess:
transform_ops:
- ResizeImage:
size: 224
- NormalizeImage:
scale: 0.00392157
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
- ToCHWImage:
RecPostProcess: null
# 索引引擎配置
IndexProcess:
# 索引文件所在目录
index_dir: "./Stanford_Online_Products/index"
# 返回的检索top-k数量
return_k: 5
# 得分阈值
score_thres: 0.5
Overwriting /home/aistudio/work/inference_general.yaml
识别并展示效果
!python python/predict_system.py -c ~/work/inference_general.yaml -o Global.infer_imgs="./Stanford_Online_Products/bicycle_final/111687027218_5.JPG"
Traceback (most recent call last):
File "python/predict_system.py", line 23, in <module>
import faiss
ModuleNotFoundError: No module named 'faiss'
# 看一下测试文件的输出,为24类型,对比看下训练集里24类型对应的一张图片,很相似,看来没有预测错。
from IPython.display import display, Image
path = "./output/111687027218_5.JPG"
img = Image(path)
display(img)
print("训练集中24类型的图片:")
path = "./Stanford_Online_Products/bicycle_final/111687027218_0.JPG"
img = Image(path)
display(img)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FR3llW8T-1639802078166)(output_47_0.jpg)]](https://i-blog.csdnimg.cn/blog_migrate/e8e51083c44a8acacdf57b2a435f047e.png)
训练集中24类型的图片:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4PqqEj0X-1639802078167)(output_47_2.jpg)]](https://i-blog.csdnimg.cn/blog_migrate/eb95bbd80dccf1c7fff9372dd122bc57.png)
斯坦福商品分类验证集准确率
原飞桨识图代码库中没有找到计算准确率代码,手工加上,生成predict_system_f1.py文件,放到~/work目录,计算的时候cp到/home/aistudio/PaddleClas/deploy/python/目录。
!cp ~/work/predict_system_f1.py /home/aistudio/PaddleClas/deploy/python/
# 全量评估大约需要5个小时。
# !python python/predict_system_f1.py -c ~/work/inference_general.yaml -o Global.infer_imgs="./Stanford_Online_Products/val.txt"
idx=23600准确率:72.20033049447058%
idx=23700准确率:72.1826083287625%
idx=23800准确率:72.19024410739044%
idx=23900准确率:72.16016066273377%
idx=24000准确率:72.13866088912962%
# 选1200个数据进行评估 用时13分钟
!python python/predict_system_f1.py -c ~/work/inference_general.yaml -o Global.infer_imgs="/home/aistudio/work/valmini.txt"
2021-12-09 17:25:24 INFO:
===========================================================
== PaddleClas is powered by PaddlePaddle ! ==
===========================================================
== ==
== For more info please go to the following website. ==
== ==
== https://github.com/PaddlePaddle/PaddleClas ==
===========================================================
2021-12-09 17:25:24 INFO: DetPostProcess :
2021-12-09 17:25:24 INFO: DetPreProcess :
2021-12-09 17:25:24 INFO: transform_ops :
2021-12-09 17:25:24 INFO: DetResize :
2021-12-09 17:25:24 INFO: interp : 2
2021-12-09 17:25:24 INFO: keep_ratio : False
2021-12-09 17:25:24 INFO: target_size : [640, 640]
2021-12-09 17:25:24 INFO: DetNormalizeImage :
2021-12-09 17:25:24 INFO: is_scale : True
2021-12-09 17:25:24 INFO: mean : [0.485, 0.456, 0.406]
2021-12-09 17:25:24 INFO: std : [0.229, 0.224, 0.225]
2021-12-09 17:25:24 INFO: DetPermute :
2021-12-09 17:25:24 INFO: Global :
2021-12-09 17:25:24 INFO: batch_size : 1
2021-12-09 17:25:24 INFO: cpu_num_threads : 10
2021-12-09 17:25:24 INFO: det_inference_model_dir : ./models/picodet_PPLCNet_x2_5_mainbody_lite_v1.0_infer
2021-12-09 17:25:24 INFO: enable_benchmark : True
2021-12-09 17:25:24 INFO: enable_mkldnn : True
2021-12-09 17:25:24 INFO: enable_profile : False
2021-12-09 17:25:24 INFO: gpu_mem : 8000
2021-12-09 17:25:24 INFO: image_shape : [3, 640, 640]
2021-12-09 17:25:24 INFO: infer_imgs : /home/aistudio/work/valmini.txt
2021-12-09 17:25:24 INFO: ir_optim : True
2021-12-09 17:25:24 INFO: labe_list : ['foreground']
2021-12-09 17:25:24 INFO: max_det_results : 5
2021-12-09 17:25:24 INFO: rec_inference_model_dir : ./models/general_PPLCNet_x2_5_lite_v1.0_infer
2021-12-09 17:25:24 INFO: rec_nms_thresold : 0.05
2021-12-09 17:25:24 INFO: threshold : 0.2
2021-12-09 17:25:24 INFO: use_fp16 : False
2021-12-09 17:25:24 INFO: use_gpu : True
2021-12-09 17:25:24 INFO: use_tensorrt : False
2021-12-09 17:25:24 INFO: IndexProcess :
2021-12-09 17:25:24 INFO: index_dir : ./Stanford_Online_Products/index
2021-12-09 17:25:24 INFO: return_k : 5
2021-12-09 17:25:24 INFO: score_thres : 0.5
2021-12-09 17:25:24 INFO: RecPostProcess : None
2021-12-09 17:25:24 INFO: RecPreProcess :
2021-12-09 17:25:24 INFO: transform_ops :
2021-12-09 17:25:24 INFO: ResizeImage :
2021-12-09 17:25:24 INFO: size : 224
2021-12-09 17:25:24 INFO: NormalizeImage :
2021-12-09 17:25:24 INFO: mean : [0.485, 0.456, 0.406]
2021-12-09 17:25:24 INFO: order :
2021-12-09 17:25:24 INFO: scale : 0.00392157
2021-12-09 17:25:24 INFO: std : [0.229, 0.224, 0.225]
2021-12-09 17:25:24 INFO: ToCHWImage : None
idx=0准确率:0.0%
idx=100准确率:72.27722772277228%
idx=200准确率:71.14427860696517%
idx=300准确率:70.09966777408638%
idx=500准确率:69.46107784431138%
idx=600准确率:71.21464226289518%
idx=700准确率:72.32524964336662%
idx=800准确率:71.66042446941323%
idx=900准确率:71.80910099889012%
idx=1000准确率:71.92807192807193%
idx=1100准确率:71.20799273387829%
准确率:71.25%
最终评测结果
24000个验证数据:准确率72.14%左右。
1200个验证数据:准确率71.25%左右
调试纠错
报错AssertionError
Traceback (most recent call last):
File "python/build_gallery.py", line 214, in <module>
main(config)
File "python/build_gallery.py", line 207, in main
GalleryBuilder(config)
File "python/build_gallery.py", line 60, in __init__
self.build(config['IndexProcess'])
File "python/build_gallery.py", line 69, in build
config['data_file'], config['image_root'], config['delimiter'])
File "python/build_gallery.py", line 45, in split_datafile
assert text_num >= 2, f"line({ori_line}) must be splitted into at least 2 parts, but got {text_num}"
AssertionError: line(bicycle_final/111085122871_0.JPG 1
) must be splitted into at least 2 parts, but got 1
直接查看数据集训练索引文件里面的内容:bicycle_final/111085122871_0.JPG 1
目测没有问题。
通过python输出详细内容进行对比,发现官方数据集训练索引文件中每条数据里面用的/t分割,而我的数据里面使用的空格,就是这点不同导致的报错。因此将生成train.txt文件的命令:
!cd /home/aistudio/PaddleClas/deploy/Stanford_Online_Products && sed '1d' Ebay_train.txt | awk -F' ' '{print $4" "$2}' > train.txt
!cd /home/aistudio/PaddleClas/deploy/Stanford_Online_Products && sed '1d' Ebay_test.txt | awk -F' ' '{print $4" "$2}' > test.txt
修改为:
!cd /home/aistudio/PaddleClas/deploy/Stanford_Online_Products && sed '1d' Ebay_train.txt | awk -F' ' '{print $4"\t"$2}' > train.txt
!cd /home/aistudio/PaddleClas/deploy/Stanford_Online_Products && sed '1d' Ebay_test.txt | awk -F' ' '{print $4"\t"$2}' > test.txt
修改之后报错问题解决。
生成版本的时候报错
notebook生成版本时遇到提示"项目中存在失效的软连接, 影响版本生成,请先删除软连接再尝试生成版本"
解决方法:
写个shell文件,在用户根目录执行即可
for a in `find . -type l`
do
stat -L $a >/dev/null 2>/dev/null
if [ $? -gt 0 ]
then
rm $a
fi
done
此文件已经写入work目录,随项目自带。
计算准确率时发现没有一个预测正确的
输出信息:
Inference: 301.66006088256836 ms per batch image
0 False
Inference: 309.0536594390869 ms per batch image
1 False
Inference: 303.4696578979492 ms per batch image
2 False
Inference: 302.0622730255127 ms per batch image
3 False
通过对训练集和验证集数据进行比较,发现两个数据集的标号竟然是顺下来的,也就是两个集合的label完全不一样。
到官网重新下载数据集看看。
发现新下的数据集也是同样。没有找到更详细的斯坦福数据集的说明,对这样训练集和测试集的label对不上感觉很费解。
不管了,我要做的,就是重新生成训练集和测试集,并按照8:2分割。
重新生成后,再运行,就OK了。
版本更新信息
2021.12.16 2.1版本,根据安全需求升级版本。估计是apache log4j漏洞的锅。
2021.12.9 2.0版本 修正一些小的语法错误。
2021.12.9 1.9版本 增加评估指标
运行中若出现任何问题,请在评论区留言,我会及时生成新版本。
结束语
让我们荡起双桨,在AI的海洋乘风破浪!
飞桨官网:https://www.paddlepaddle.org.cn
因为水平有限,难免有不足之处,还请大家多多帮助。
作者:段春华, 网名skywalk 或 天马行空,济宁市极快软件科技有限公司的AI架构师,百度飞桨PPDE。
我在AI Studio上获得至尊等级,点亮10个徽章,来互关呀~ https://aistudio.baidu.com/aistudio/personalcenter/thirdview/141218

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 3
3 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)