
2021 iFLYTEK A.I 开发者大赛 碎米识别挑战赛-初赛榜三
使用PaddleSeg高层API对碎米进行分割,获得碎米挑战赛初赛第三、决赛第八的成绩。 DSC 0.688997 PaddleSeg佛系上分真好用
讯飞算法赛–碎米识别挑战赛
比赛传送门: 讯飞算法赛–碎米识别挑战赛
本次使用PaddleSeg上分很惬意!
一、赛事背景
美亚光电在光电色选领域深耕多年,秉承着绿色设计、绿色生产、绿色管理的发展理念,并基于人工智能和大数据技术,助力传统农业数字化转型。
我国是世界上最大的稻米生产国,而稻米品质问题已经成为制约我国大米生产、销售和出口的瓶颈。大米的碎米率是影响大米质量和售价的重要指标,同时也是反映稻米种植水平、大米加工水平的重要指标。从整米中识别、分割出碎米,并提高碎米的识别率是提高大米品质的关键性问题。
二、赛事任务
本次大赛提供纯色背景下的整米和碎米数据作为训练样本,参赛选手需基于提供的样本构建模型,对碎米进行分割识别。
三、数据说明
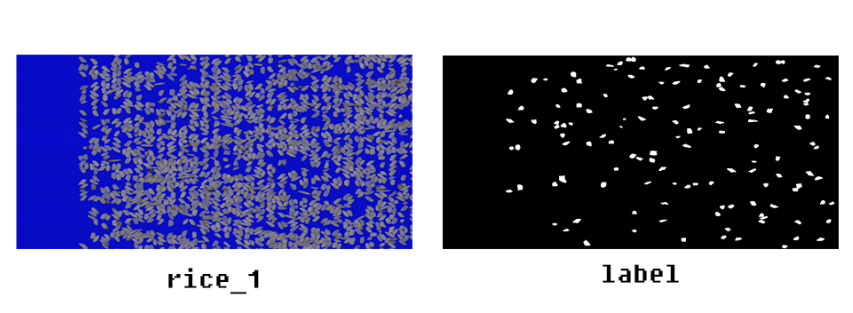
本次比赛为参赛选手提供了两类数据:训练数据、测试数据。训练数据及测试数据皆为分辨率1024×500、位深度24位纯色背景下的整米和碎米png图片其中仅训练数据包含标注信息(分割结果的0/1二值化图,碎米值为1,其余部分为0)。出于数据安全保证的考虑,所有数据均为脱敏处理后的数据。
其中训练数据有120例,测试数据30例
训练数据(rice_1)及其label(已转换为0-255):
四、比赛数据下载链接
现在应该是不能下载了的,直接在公开数据集中搜索添加即可
五、环境配置
深度学习框架:
paddlepaddle 2.2.0
python版本:
python 3.7
硬件信息: CPU:4, RAM:32GB, GPU:v100, 显存:32GB, 磁盘:100GB
本团队的训练皆在Ai Studio深度学习平台上进行
总体方案
1、模型选择
尝试过UNet、BiSeNetV2等网络,虽然BiSeNetV2是轻量级网络,但是精度一直提高不了,所以选择了经典的UNet作为本次比赛的分割网络。
2、数据增强
水平翻转,垂直翻转,随机扭曲,随机缩放,图像标准化。碎米图分辨率为1024×500,所以输入尺寸我设置为1024×1024
可优化点:
- 如果现存允许则增大输出尺寸,榜一榜二的输入尺寸为2048×2048,4096×4096;
- 可以试试增加其他数据增强策略,如仿射变换等,但是裁剪不推荐。
3、主干网络
我只使用了经典的UNet网络进行训练
可优化点:可以尝试使用ResNet、EfficientNet等网络作为主干网络
4、学习率下降策略及优化器
对于分割项目,我都是使用CosineAnnealingDecay + Adam进行训练,这样模型收敛的很快,节省一些时间。
可优化点:可以AdamW作为优化器,该优化器用来解决Adam优化器中L2正则化失效的问题,现在使用的比较多的是AdamW。
5、模型大小问题
我尝试过使用一些轻量级的网络进行训练,但是精度都没有UNet的高,甚至在后面选手们都冲分的时候我都进不了前十,所以最后使用了经典的UNet网络训练出的模型作为最后的成绩。
可优化点:可以减少UNet的filter个数达到减少模型大小的效果,但是相应的,精度可能会降低。
6、分割结果优化
在测试时可以使用TTA。
一 、数据准备
1.解压数据集
如果项目未自带数据集,请自行下载一下数据集
请自行上传下载好的比赛数据集,只需要修改一下cell中的代码即可整个项目自动无误的运行
将data目录下的data105383换成当前上传后数据集的目录即可
!unzip -oq /home/aistudio/data/data105383/碎米识别挑战赛_数据集.zip -d /home/aistudio/work/
#解压数据集
!unzip -oq /home/aistudio/data/data105383/碎米识别挑战赛_数据集.zip -d /home/aistudio/work/
2.导入依赖项
想要深入了解PaddleSeg源码,可参考PaddleSeg代码解读
# 下载PaddleSeg包,使用PaddleSeg高层API进行训练
!pip install paddleseg
3.数据集的划分
因为数据稀少,所以按照9:1的比例划分训练集与验证集,但是通过不断训练得出,8:2比例精度更高。
若是需要更改比例,更改下方代码中的
ratio数值即可
注:选手可以额外增补试题数据集以及其它辅助数据,但所用的数据必须是无违法、敏感等信息的可公开数据。此外,前十名的参赛选手需要在项目文件中将额外的数据一并提供。
0.9最高为0.673,0.8最高为0.68997,在优化模型的时候,最好使用相同的训练集、验证集进行训练。
# import random
# import os
# random.seed(2021)
# mask_dir = '/home/aistudio/work/rice/train/labels'
# img_dir = '/home/aistudio/work/rice/train/images'
# path_list = list()
# for img in os.listdir(img_dir):
# img_path = os.path.join(img_dir,img)
# mask_path = os.path.join(mask_dir,img.replace('jpg', 'png'))
# path_list.append((img_path, mask_path))
# random.shuffle(path_list)
# ratio = 0.8
# train_f = open('/home/aistudio/work/rice/train/train.txt','w')
# val_f = open('/home/aistudio/work/rice/train/val.txt' ,'w')
# for i ,content in enumerate(path_list):
# img, mask = content
# text = img + ' ' + mask + '\n'
# if i < len(path_list) * ratio:
# train_f.write(text)
# else:
# val_f.write(text)
# train_f.close()
# val_f.close()
二 、网络训练
1.数据增强
训练数据及测试数据皆为分辨率1024×500,再加上训练数据数量少的特点,将输入size设为1024×1024,让网络学习到更多特征
size设为1024×1024,加上水平翻转与垂直翻转即可到达0.68+,其他的数据增强可小幅提升成绩
可对照PaddleSeg代码解读项目设计数据增强策略
高层API真好用,可以偷懒哈哈
import paddleseg.transforms as T
from paddleseg.datasets import Dataset
train_transforms = [
T.RandomHorizontalFlip(0.5),# 水平翻转
T.RandomVerticalFlip(0.5),# 垂直翻转
T.RandomDistort(0.6),
T.RandomScaleAspect(min_scale=0.8,aspect_ratio=0.5),# 随机缩放
T.Resize(target_size=(1024,1024)),
T.Normalize() # 图像标准化
]
val_transforms = [
T.Resize(target_size=(1024,1024)),
T.Normalize()
]
2.搭建dataset
dataset_root = '/home/aistudio/work/rice/train'
train_path = '/home/aistudio/work/rice/train/train.txt'
val_path = '/home/aistudio/work/rice/train/val.txt'
# 构建训练集
train_dataset = Dataset(
dataset_root=dataset_root,
train_path=train_path,
transforms=train_transforms,
num_classes=2,
mode='train'
)
#验证集
val_dataset = Dataset(
dataset_root=dataset_root,
val_path=val_path,
transforms=val_transforms,
num_classes=2,
mode='val'
)
3.训练配置
优化器:Adam
class paddle.optimizer. Adam ( learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08, parameters=None, weight_decay=None, grad_clip=None, name=None, lazy_mode=False )
参数:
- learning_rate (float|_LRScheduler) - 学习率,用于参数更新的计算。可以是一个浮点型值或者一个_LRScheduler类,默认值为0.001
- beta1 (float|Tensor, 可选) - 一阶矩估计的指数衰减率,是一个float类型或者一个shape为[1],数据类型为float32的Tensor类型。默认值为0.9
- beta2 (float|Tensor, 可选) - 二阶矩估计的指数衰减率,是一个float类型或者一个shape为[1],数据类型为float32的Tensor类型。默认值为0.999
- epsilon (float, 可选) - 保持数值稳定性的短浮点类型值,默认值为1e-08
- parameters (list, 可选) - 指定优化器需要优化的参数。在动态图模式下必须提供该参数;在静态图模式下默认值为None,这时所有的参数都将被优化。
- weight_decay (float|WeightDecayRegularizer,可选) - 正则化方法。可以是float类型的L2正则化系数或者正则化策略: cn_api_fluid_regularizer_L1Decay 、 cn_api_fluid_regularizer_L2Decay 。如果一个参数已经在 ParamAttr 中设置了正则化,这里的正则化设置将被忽略; 如果没有在 ParamAttr 中设置正则化,这里的设置才会生效。默认值为None,表示没有正则化。
- grad_clip (GradientClipBase, 可选) – 梯度裁剪的策略,支持三种裁剪策略: paddle.nn.ClipGradByGlobalNorm 、 paddle.nn.ClipGradByNorm 、 paddle.nn.ClipGradByValue 。 默认值为None,此时将不进行梯度裁剪。
- name (str, 可选)- 该参数供开发人员打印调试信息时使用,具体用法请参见 Name ,默认值为None
- lazy_mode (bool, 可选) - 设为True时,仅更新当前具有梯度的元素。官方Adam算法有两个移动平均累加器(moving-average accumulators)。累加器在每一步都会更新。在密集模式和稀疏模式下,两条移动平均线的每个元素都会更新。如果参数非常大,那么更新可能很慢。 lazy mode仅更新当前具有梯度的元素,所以它会更快。但是这种模式与原始的算法有不同的描述,可能会导致不同的结果,默认为False
import paddle
from paddleseg.models import UNet
from paddleseg.models.losses import MixedLoss,BCELoss,LovaszSoftmaxLoss
base_lr =0.0025 #初始学习率
iters = 4000
unet_model = UNet(num_classes=2)#使用unet进行训练
#自动调整学习率
lr =paddle.optimizer.lr.CosineAnnealingDecay(base_lr, T_max=(iters // 3), last_epoch=0.5) #使用余弦退火调整学习率
u_optimizer = paddle.optimizer.Adam(lr, parameters=unet_model.parameters())
#构建损失函数
mixtureLosses = [BCELoss(),LovaszSoftmaxLoss() ]
mixtureCoef = [0.7,0.3]
losses = {}
losses['types'] = [MixedLoss(mixtureLosses, mixtureCoef)]
losses['coef'] = [1]
- 余弦退火策略
- 刚开始使用 BCELoss+Diceloss 复合损失函数,发现效果不明显,所以改用BCELoss + LovaszSoftmaxLoss约束训练过程,分割效果小幅度提升
- 加载预训练模型效果不好
4.开始训练
#进行训练
from paddleseg.core import train
train(
model = unet_model,
train_dataset=train_dataset,
val_dataset=val_dataset,
optimizer=u_optimizer,
save_dir='output/RICE_model_1',
iters=iters,
batch_size=2,
save_interval=40,
log_iters=10,
num_workers=0,
losses=losses,
use_vdl=True
)
训练日志:
保存mIou最高的模型为best_model
学习率下降到0.24就开始收敛,到达0.14左右,mIou就到达0.70+
使用BCELoss,LovaszSoftmaxLoss组合损失函数,iters到达400左右,mIou即可到达0.70+,在训练半个周期或者一个半周期之后,mIou将到达最高(接近0.72)
最优的几个模型皆在迭代一个半周期之后达到最高。
最好模型 UNet_0.68997.pdparams:

5.模型评估
RICE_model_17mIou到达0.7202,score就可以拿到0.68571
RICE_model_19mIou到达0.7221,score就可以拿到0.6887(调整了RandomDistort参数)
RICE_model_21mIou到达0.7240,score就可以拿到0.68997(调整了水平翻转和垂直翻转参数, 将默认数值改为0.5)
from paddleseg.core import evaluate
from paddleseg.models import UNet
#设置模型
model = UNet(num_classes=2)
#模型路径
model_path = 'UNet_0.68997.pdparams'
para_state_dict = paddle.load(model_path)
model.set_dict(para_state_dict)
evaluate(model,val_dataset)
三 、结果预测
1.生成测试集路径文件
%cd ~
import random
import os
test_path = r"work/rice/test/images"
test_lst=[]
for test in os.listdir(test_path):
test_lst.append(test)
with open('work/rice/test.txt', 'w') as f:
for line in test_lst:
f.write(line)
f.write('\n')
2.开始预测
import os
from paddleseg.models import UNet
from paddleseg.core import predict
import paddleseg.transforms as T
transforms = T.Compose([
T.Resize(target_size=(1024, 1024)),
T.Normalize()
])
model = UNet(num_classes=2)
#生成图片列表
image_list = []
with open('work/rice/test.txt' ,'r') as f:
for line in f.readlines():
image_list.append(os.path.join('work/rice/test/images/',line.split()[0]))
predict(
model,
#模型路径文件
model_path = 'UNet_0.68997.pdparams',
transforms=transforms,
image_list=image_list,
save_dir='result',
)
3.结果转换
提交预测结果:
- 预测结果压缩包提交,参赛者将测试集的分割结果图放入results文件夹中并压缩为results.zip后提交;
- 以原图片数据格式提交(不能改变图片大小),可以为0/1二值化图,也可以为0/255值图;
- 预测结果中的单个文件名需和预测图片命名方式一致;
- 压缩包内不能包含其他文件夹,否则会导致评分失败
!mkdir results
#采取的方法是将RGB图转换为0/255
import os
import re
import os.path
import numpy as np
from PIL import Image
#将RGB图转为0/255
#Pixels higher than this will be 255. Otherwise 0.
image_path = "result/pseudo_color_prediction"
results_path = "results"
image_arr=[]
for image in os.listdir(image_path):
image_arr.append(image)
for i in range(len(image_arr)):
#Load image and convert to greyscale
img = Image.open(image_path + "/"+image_arr[i])
img = img.convert("L")
imgData = np.asarray(img)
imgData = ((imgData-np.min(imgData))/(np.max(imgData)-np.min(imgData))*255).astype('uint8')
im = Image.fromarray(imgData)
im.save(results_path + "/"+image_arr[i])
4.文件打包
将打包好的results.zip下载即可提交
# 压缩当前路径所有文件,输出zip文件
path='results'
import zipfile,os
zipName = 'results.zip' #压缩后文件的位置及名称
f = zipfile.ZipFile( zipName, 'w', zipfile.ZIP_DEFLATED )
for dirpath, dirnames, filenames in os.walk(path):
for filename in filenames:
print(filename)
f.write(os.path.join(dirpath,filename))
f.close()
总结
模型构建思路及调优过程
【模型】Unet
【数据】用原始数据集,据我所知,也没有见有人增加了数据集。
【图片尺寸】我设置的图片输入尺寸1024×1024,榜一榜二的输入尺寸都比这大,据说精度提升不少。
【数据增强】数据增强一开始会选择水平翻转与垂直翻转,分割效果不错的话会根据数据特点选择添加其他的数据增强方法。
【提高】
在这个项目中尝试
Unet和其他轻量级语义分割网络。因为数据为纯底碎米图,在到达0.68+时并没有进行图像处理,榜一人工清除边界伪碎米(拍照时截断的),score提高了一丢丢。
其他轻量级网络与UNet相比,精度稍差,但是
UNet模型大小为80.6 MB左右,在最终判分中只能拿到0.2,最终只获得了第八名,轻量级网络在模型大小上有优势,但是轻量级网络在精度上会有所下降。榜前选手使用的都是UNet及其衍生网络,通过修改filter个数改变模型大小。
可以尝试寻找其他的碎米数据集
更多前三名trick,请移步:碎米比赛回放
再有,本次比赛是和Niki_173大佬和决赛第三名一起讨论上分的,关注一下他吧~
这是Niki_173大佬简介:
我在AI Studio上获得钻石等级,点亮8个徽章,来互关呀~ https://aistudio.baidu.com/aistudio/personalcenter/thirdview/764763
嘿嘿其实啥也没有~

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)