
自然语言处理:从SimpleRNN到BERT_副本
讲解SimpleRNN,LSTM,Seq2Seq Model,Attention与Self-Attention,Transformer,BERT与ERNIE模型原理,并进行实践!
一、简单循环神经网络(Simple RNN)原理与实战
## 标题转载自AI Studio ## 标题项目链接https://aistudio.baidu.com/aistudio/projectdetail/2379730 # 1. 前言 本文详解Embedding、Simple RNN原理,并使用[飞桨(PaddlePaddle)](https://www.paddlepaddle.org.cn/)基于IMDB电影评论数据集实现电影评论情感分析。本系列文章搬运自我的CSDN博客,更多机器学习及深度学习文章请关注:DeepGeGe
【一文讲完整个自然语言处理核心方法及模型原理,建议Fork收藏】
2. 类别特征数值化方法
机器学习的数据通常有类别特征(categorical feature),训练机器学习模型之前,需要把类别特征转化成机器学习模型能理解的数值特征(numerical feature)。
在自然语言处理任务中,数据都是文本,文本可以分割成许多字符或者词语,每一个字符或者每一个词语就是一个类别特征。将类别特征数值化,主要有两种方式:独热编码(One-hot Encoding)与嵌入(Embedding)。
2.1 独热编码(One-hot Encoding)
独热向量(One-hot Vector)是指只有一个元素为1,其余元素均为0的向量。独热编码是指将类别特征转换为独热向量。
假设训练集文本中包含10000个不同的单词,每一个单词即可视为一个不同的类别特征,即有10000个类别特征。可以使用一个维度为10000的独热向量表示一个单词,不同单词对应的独热向量不同。
在实际处理文本时,会统计文本中单词出现的次数,进行去掉低频词(出现次数较少)、去除停用词(the、a、of等无意义单词)等等数据处理操作,因为低频词往往是命名实体、拼写错误词汇等无意义的单词。这方面的内容不在本文讲解范围。
但是使用独热编码存在如下问题:
- 向量维数等于单词数,单词越多,向量维度越高,表示一个独热单词的向量非常稀疏;
- 任意两个单词对应的向量之间的距离均相等,无法捕捉到单词与单词之间的相关性;
- 单词对应的独热向量只能表示一个类别,无法表示单词的语义。
此外,在RNN等自然语言处理模型中,模型RNN层参数正比于输入的向量的维度。使用独热编码,会使得RNN层参数数量过多。比独热编码更好的选择是Embedding。
2.2 嵌入(Embedding)
在自然语言处理领域,词语/单词级别的Embedding称为词嵌入(Word Embedding),字/字符级别的Embedding被称为字嵌入(Char Embedding)。
词嵌入是将单词映射到低维的连续向量空间中,即单词被表示成实数域上的低维向量。其中向量的长度是超参数,必须人为设定。向量中每一个元素的值,是模型的参数,必须从训练数据中学习获得,即通过大量数据训练,模型自动获得每一个单词该被表示成一个怎样的向量。词嵌入维度的设定并没有精确的理论可以指导,设定的原则是:Embedding表示的对象包含的信息越多(不同语言词汇信息熵不一致),则词嵌入维度应该越高;训练数据集越大,词嵌入维度可以设置得更高。一般词嵌入是8维(对于小型数据集)到1024维(对于超大型数据集)。更高维度的Embedding可以捕获单词之间更细的关系,但是需要更多数据去学习,否则模型非常容易过拟合。
使用词嵌入的优点如下:
- 能捕捉到单词之间的联系,比如通过计算两个词嵌入的距离,可以得到两个单词的相关程度(如图一所示);
- 词嵌入维度较独热向量低的多得多,运算速度较快;
- 实践证明,使用Embedding能够提高情感分析、机器翻译等众多自然语言处理问题的效果。

Deep Learning is all about “Embedding Everything”.
实际上,不仅仅在自然语言处理领域可以将字/词等类别特征通过Embedding方式数值化,任意类别特征均可尝试通过Embedding方式数值化;
处理中文文本时,可以将一个“字”视为一个类别特征,也可以将一个“词语”视为一个类别特征。如果将“字”视为类别特征,则需较多数据才能学习出比较好的Char Embedding。如果将“词语”视为类别特征,则分词效果将会直接影响到最终输出效果。一般建议在相对较小的数据集上使用词嵌入,在大数据集或者网络用语等新词频出的数据集上使用字嵌入。
## 3.3 模型训练
设置超参数`seq_len = 200`、`emb_size = 16`,调用`get_data_loader`函数加载训练和测试数据,调用`emb_softmax_classifier_model`函数获得模型实例。使用`model.summary`获得模型信息如下:
Layer (type) Input Shape Output Shape Param #
Embedding-1 [[1, 200]] [1, 200, 16] 82,384
Flatten-1 [[1, 200, 16]] [1, 3200] 0
Linear-1 [[1, 3200]] [1, 2] 6,402
Total params: 88,786
Trainable params: 88,786
Non-trainable params: 0
Input size (MB): 0.00
Forward/backward pass size (MB): 0.05
Params size (MB): 0.34
Estimated Total Size (MB): 0.39
使用`model.prepare`进行模型配置,使用`paddle.optimizer.Adam`优化器、`paddle.nn.CrossEntropyLoss`损失函数,并添加`paddle.metric.Accuracy`作为衡量指标。使用`model.fit`开启模型训练,设置`eopchs=5`。训练过程信息如下:
The loss value printed in the log is the current step, and the metric is the average value of previous steps.
Epoch 1/5
step 195/195 [] - loss: 0.4092 - acc: 0.6625 - 5ms/step
Epoch 2/5
step 195/195 [] - loss: 0.2929 - acc: 0.8648 - 4ms/step
Epoch 3/5
step 195/195 [] - loss: 0.2057 - acc: 0.9011 - 4ms/step
Epoch 4/5
step 195/195 [] - loss: 0.2373 - acc: 0.9239 - 4ms/step
Epoch 5/5
step 195/195 [==============================] - loss: 0.1361 - acc: 0.9466 - 4ms/step
使用`model.evaluate`在测试集上评估模型,得到测试信息如下:
测试结果: {‘loss’: [0.4164989], ‘acc’: 0.8514423076923077}
测试集中正样本数为12500,负样本数为12500,瞎猜正确率为50%。使用简单浅层网络,经过训练后测试准确率为:`85.14%`。模型训练部分代码如下:
```python
if __name__ == '__main__':
# 设置超参数
seq_len = 200 # 每条文本的长度
emb_size = 16 # 词嵌入(word embedding大小)
# 加载和处理数据
train_data_loader = get_data_loader('train', seq_len=seq_len, data_show=1)
test_data_loader = get_data_loader('test', seq_len=seq_len)
model = emb_softmax_classifier_model(emb_size=emb_size, seq_len=seq_len)
# 打印模型结构信息
model.summary(input_size=(None, seq_len), dtype='int64')
# 配置模型
model.prepare(optimizer=paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(use_softmax=True), metrics=paddle.metric.Accuracy())
model.fit(train_data_loader, epochs=5, verbose=1)
print('测试结果:', model.evaluate(test_data_loader, verbose=0))
训练此模型并没有经过精细的调参,很明显,模型出现了比较严重的过拟合现象;
模型最后没有softmax层,是因为paddle.nn.CrossEntropyLoss()将softmax操作和计算损失操作合并了;
之所以采用两个输出节点+softmax+cross_entropy而不是采用二分类问题中使用更广泛的一个输出节点+sigmoid+binary_cross_entropy,是因为如果在PaddlePaddle中使用后一种方式,貌似在使用高阶API训练模型时,accuracy计算机制存在BUG。这一点我向官方提出来过,也和官方人员讨论过,具体可查看链接。
4. Simple RNN
第3部分直接将文本整体输入模型,对文本进行二分类,所述模型属于一对一(one to one)模型,即一个输入对应一个输出。但是人脑并不使用one to one模型处理时序数据,人类在阅读文章时,并不会把一整段文字全部直接输入大脑。在阅读时,人类通常逐字逐句阅读文章,并逐渐在大脑里积累信息。当整篇文章阅读完毕,大脑里就积累了整篇文章的大意。
One to one模型要求一个输入对应一个输出,比如输入一张图片,输出每一类的概率值。One to one模型非常适合图片处理问题,但不适合文本等时序数据(sequential data)处理问题。对于文本等时序数据处理问题,输入和输出的长度都不固定,更适合时序数据处理问题的模型是多对一(many to one)或者多对多(many to many)模型。
RNN(Recurrent Neural Network)即是这种多对多模型,虽然现在RNN没有以前那么流行,在自然语言处理领域,已经有些过时。如果训练数据足够多,RNN的效果不如Transformer模型。但是在较小规模数据集上,RNN效果仍然比较出色。RNN非常适合处理文本、语音等时序数据,其输入和输出长度均无须固定。RNN处理时序数据的过程与人脑非常类似,人类阅读文本时,每次看一个字,逐渐在大脑里积累信息。RNN每次接受一个输入,用状态向量 h h h积累输入信息。如图二所示,一段文本中的单词,经过Embedding层后从左至右依次输入RNN,状态向量 h 0 h_0 h0包含了第一个词 x 0 x_0 x0的信息, h 1 h_1 h1包含了前两个词 x 0 x_0 x0和 x 1 x_1 x1的信息,以此类推, h t h_t ht包含了 x 0 x_0 x0到 x t x_t xt所有词的信息,如果到 t t t时刻,文本中所有词均被输入RNN,则可以将 h t h_t ht看做RNN从输入的文本中抽取的特征向量。

Simple RNN根据 t t t时刻输入 x t x_t xt和 t − 1 t-1 t−1时刻状态向量 h t − 1 h_{t-1} ht−1计算 t t t时刻状态向量 h t h_{t} ht的方法如图三所示,将 t − 1 t-1 t−1时刻状态向量 h t − 1 h_{t-1} ht−1与 t t t时刻输入 x t x_t xt拼接(concatenation),再左乘参数矩阵 A A A,然后将激活函数tanh作用于得到向量的每一个元素上,最后得到 t t t时刻状态向量 h t h_t ht。其中 A A A是RNN的参数矩阵,需要随机初始化后通过训练数据学习。此外,Simple RNN实际计算过程中往往会加上一个形状与状态向量一致的偏置(bias),然后再通过激活函数并输出新的状态向量,与图三所示有一点点区别,不过本质上没有差别。

Simple RNN的结构展开如图四所示,新的状态 h t h_t ht是上一个时刻状态 h t − 1 h_{t-1} ht−1和 t t t时刻输入 x t x_t xt的函数, A A A是Simple RNN的模型参数矩阵。不论RNN的链展开有多长,RNN中的参数矩阵只有一个,即在始终使用同一个 A A A乘以不同时刻的状态向量 h t − 1 h_{t-1} ht−1和输入向量 x t x_t xt拼接后形成的向量,从而得到新状态向量 h t h_t ht。

Simple RNN的模型参数数量等与参数矩阵 A A A中的元素个数(不考虑偏置),参数矩阵 A A A的行数等于状态向量 h h h的维度: s h a p e ( h ) shape(h) shape(h),列数等于状态向量 h h h的维度加上输入向量 x x x的维度: s h a p e ( h ) + s h a p e ( x ) shape(h)+shape(x) shape(h)+shape(x)。因此Simple RNN模型的总参数个数为: s h a p e ( h ) ∗ [ s h a p e ( h ) + s h a p e ( x ) ] shape(h) * [shape(h)+shape(x)] shape(h)∗[shape(h)+shape(x)]。
4.1 遗忘问题
Simple RNN的记忆时效较短,会遗忘很久之前的输入 x x x。根据图三,Simple RNN状态更新公式可写作如下形式:
h t = t a n h ( W i x t + W h h t − 1 + b ) h_t=tanh(W_ix_t+W_hh_{t-1}+b) ht=tanh(Wixt+Whht−1+b)
W i W_i Wi相当于图三中参数矩阵 A A A右半边蓝色部分, W h W_h Wh相当于左半边紫色部分。此外,公式中加入了偏置项。
令 z t = W i x t + W h h t − 1 + b 则 ∂ h t ∂ x t = ∂ h t ∂ z t W i , ∂ h t ∂ h t − 1 = ∂ h t ∂ z t W h 因 为 h t 是 h t − 1 的 函 数 , h t − 1 是 x t − 1 的 函 数 , 则 : ∂ h t ∂ x t − 1 = ∂ h t ∂ h t − 1 ∂ h t − 1 ∂ x t − 1 同 理 , h t − 1 是 h t − 2 的 函 数 , h t − 2 是 x t − 2 的 函 数 , 则 : ∂ h t ∂ x t − 2 = ∂ h t ∂ h t − 1 ∂ h t − 1 ∂ h t − 2 ∂ h t − 2 ∂ x t − 2 以 此 类 推 , ∂ h t 对 ∂ x t − k 的 偏 导 数 如 下 : ∂ h t ∂ x t − k = ∂ h t ∂ h t − 1 ∂ h t − 1 ∂ h t − 2 ⋯ ∂ h t − k + 1 ∂ h t − k ∂ h t − k ∂ x t − k = [ ∏ j = t − k + 1 t ∂ h j ∂ h j − 1 ] ∂ h t − k ∂ x t − k = { ∏ j = t − k + 1 t [ d i a g ( ∂ h j ∂ z j ) W h ] } ∂ h t − k ∂ x t − k 令~~z_t=W_ix_t+W_hh_{t-1}+b\\ 则~~\frac{\partial h_t}{\partial x_t}=\frac{\partial h_t}{\partial z_t}W_i,~~~~\frac{\partial h_t}{\partial h_{t-1}}=\frac{\partial h_t}{\partial z_t}W_h\\ 因为h_t是h_{t-1}的函数,h_{t-1}是x_{t-1}的函数,则:\\ \frac{\partial h_t}{\partial x_{t-1}}=\frac{\partial h_t}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial x_{t-1}}\\ 同理,h_{t-1}是h_{t-2}的函数,h_{t-2}是x_{t-2}的函数,则:\\ \frac{\partial h_t}{\partial x_{t-2}}=\frac{\partial h_t}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial h_{t-2}}\frac{\partial h_{t-2}}{\partial x_{t-2}}\\ 以此类推,\partial h_t对\partial x_{t-k}的偏导数如下:\\ \frac{\partial h_t}{\partial x_{t-k}}=\frac{\partial h_t}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial h_{t-2}}\cdots\frac{\partial h_{t-k+1}}{\partial h_{t-k}} \frac{\partial h_{t-k}}{\partial x_{t-k}}\\ =[\prod_{j=t-k+1}^t\frac{\partial h_j}{\partial h_{j-1}}]\frac{\partial h_{t-k}}{\partial x_{t-k}}\\ =\{\prod_{j=t-k+1}^t[diag(\frac{\partial h_j}{\partial z_j})W_h]\}\frac{\partial h_{t-k}}{\partial x_{t-k}} 令 zt=Wixt+Whht−1+b则 ∂xt∂ht=∂zt∂htWi, ∂ht−1∂ht=∂zt∂htWh因为ht是ht−1的函数,ht−1是xt−1的函数,则:∂xt−1∂ht=∂ht−1∂ht∂xt−1∂ht−1同理,ht−1是ht−2的函数,ht−2是xt−2的函数,则:∂xt−2∂ht=∂ht−1∂ht∂ht−2∂ht−1∂xt−2∂ht−2以此类推,∂ht对∂xt−k的偏导数如下:∂xt−k∂ht=∂ht−1∂ht∂ht−2∂ht−1⋯∂ht−k∂ht−k+1∂xt−k∂ht−k=[j=t−k+1∏t∂hj−1∂hj]∂xt−k∂ht−k={j=t−k+1∏t[diag(∂zj∂hj)Wh]}∂xt−k∂ht−k
因为激活函数为tanh, h j = t a n h ( z j ) h_j=tanh(z_j) hj=tanh(zj),因此 ∂ h j ∂ z j ≤ 1 \frac{\partial h_j}{\partial z_j}\le1 ∂zj∂hj≤1。若 W h W_h Wh较大,则 k k k较大时 ∂ h t ∂ x t − k \frac{\partial h_t}{\partial x_{t-k}} ∂xt−k∂ht非常大,出现梯度爆炸情况;若 W h W_h Wh较小,则当 k k k较大时, ∂ h t ∂ x t − k \frac{\partial h_t}{\partial x_{t-k}} ∂xt−k∂ht基本等于0,即 x t − k x_{t-k} xt−k发生改变时,状态向量 h t h_t ht基本不变, h t h_t ht与 x t − k x_{t-k} xt−k基本不存在相关关系,Simple RNN遗忘了很久之前的输入信息。
5. 电影评论情感分析(二)
电影评论情感分析(二)使用Simple RNN模型分析电影评论情感,设计如下:
- 模型结构:Embedding层+SimpleRNN层+softmax分类器
- 词嵌入维度:16
- 状态向量维度:32
5.1 模型搭建
数据处理与3.1部分相同,直接介绍搭建神经网络模型。为了展示PaddlePaddle的不同模型搭建方法及高低阶API使用方法,电影评论情感分析(二)将使用不同的方式搭建及训练模型。
定义继承自paddle.nn.Layer的SimpleRNNModel类,在初始化函数__init__中定义网络各层,重写forward方法,实现前向计算流程。代码如下:
class SimpleRNNModel(paddle.nn.Layer):
def __init__(self, emb_size, hidden_size):
super(SimpleRNNModel, self).__init__()
self.emb = paddle.nn.Embedding(num_embeddings=5149, embedding_dim=emb_size)
self.simple_rnn = paddle.nn.SimpleRNN(input_size=emb_size, hidden_size=hidden_size)
self.fc = paddle.nn.Linear(in_features=hidden_size, out_features=2)
self.softmax = paddle.nn.Softmax()
def forward(self, x):
x = self.emb(x)
# SimpleRNN分别返回所有时刻状态和最后时刻状态,这里只使用最后时刻状态
_, x = self.simple_rnn(x)
# 去掉第0维,这么处理与PaddlePaddle的SimpleRNN层返回格式有关
x = paddle.squeeze(x, axis=0)
x = self.fc(x)
x = self.softmax(x)
return x
5.2 模型训练
使用PaddlePaddle低阶API训练模型,定义train函数,遍历epoch次训练样本,在每个epoch的每个batch内,依次执行前向计算、计算损失、后向传播、梯度更新,并且每个epoch遍历结束后评估测试集准确率。代码如下:
def train(model, epochs, train_loader, test_loader):
# 将模型设置为训练模式
model.train()
# 定义优化器
opt = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
for epoch in range(epochs):
for batch_id, data in enumerate(train_loader):
sent = data[0]
label = data[1]
# 前向计算输出
logits = model(sent)
# 计算损失
loss = paddle.nn.functional.cross_entropy(logits, label, use_softmax=False)
if batch_id % 50 == 0:
acc = paddle.metric.accuracy(logits, label)
print("epoch: {}, batch_id: {}, loss: {}, acc:{}".format(epoch, batch_id, loss.numpy(), acc.numpy()))
# 后向传播
loss.backward()
# 参数更新
opt.step()
# 清除梯度
opt.clear_grad()
# 每个epoch数据遍历结束后评估模型
# 将模型设置为评估模式
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(test_loader):
sent = data[0]
label = data[1]
logits = model(sent)
loss = paddle.nn.functional.cross_entropy(logits, label, use_softmax=False)
acc = paddle.metric.accuracy(logits, label)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
avg_acc, avg_loss = np.mean(accuracies), np.mean(losses)
print("[validation] accuracy/loss: {}/{}".format(avg_acc, avg_loss))
# 将模型重新设置为训练模式
model.train()
设置超参数seq_len = 100、emb_size = 16、hidden_size = 32,调用get_data_loader函数加载训练和测试数据,实例化模型对象。使用paddle.summary获得模型信息如下:
---------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
=================================================================================
Embedding-1 [[1, 100]] [1, 100, 16] 82,384
SimpleRNN-1 [[1, 100, 16]] [[1, 100, 32], [1, 1, 32]] 1,600
Linear-1 [[32]] [2] 66
Softmax-1 [[2]] [2] 0
=================================================================================
Total params: 84,050
Trainable params: 84,050
Non-trainable params: 0
---------------------------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.04
Params size (MB): 0.32
Estimated Total Size (MB): 0.36
---------------------------------------------------------------------------------
调用train函数开启模型训练:
if __name__ == '__main__':
# 设置超参数
seq_len = 100 # 每条文本的长度
emb_size = 16 # 词嵌入(word embedding大小)
hidden_size = 32 # Simple RNN中状态向量维度
# 加载和处理数据
train_data_loader = get_data_loader('train', seq_len=seq_len, data_show=1)
test_data_loader = get_data_loader('test', seq_len=seq_len)
# 创建模型对象
model = SimpleRNNModel(emb_size, hidden_size)
# 查看模型结构信息
paddle.summary(model, input_size=(None, seq_len), dtypes='int64')
# 训练模型
train(model, 3, train_data_loader, test_data_loader)
训练过程信息及结果如下:
epoch: 0, batch_id: 0, loss: [0.6936736], acc:[0.5390625]
epoch: 0, batch_id: 50, loss: [0.6944036], acc:[0.484375]
epoch: 0, batch_id: 100, loss: [0.6921302], acc:[0.515625]
epoch: 0, batch_id: 150, loss: [0.69894063], acc:[0.5]
[validation] accuracy/loss: 0.532892644405365/0.6888695359230042
epoch: 1, batch_id: 0, loss: [0.68087435], acc:[0.5703125]
epoch: 1, batch_id: 50, loss: [0.64476], acc:[0.6328125]
epoch: 1, batch_id: 100, loss: [0.57881236], acc:[0.703125]
epoch: 1, batch_id: 150, loss: [0.47674033], acc:[0.8046875]
[validation] accuracy/loss: 0.7377804517745972/0.5892166495323181
epoch: 2, batch_id: 0, loss: [0.5755479], acc:[0.7421875]
epoch: 2, batch_id: 50, loss: [0.5476066], acc:[0.7421875]
epoch: 2, batch_id: 100, loss: [0.53570944], acc:[0.765625]
epoch: 2, batch_id: 150, loss: [0.4936667], acc:[0.765625]
[validation] accuracy/loss: 0.7520833611488342/0.5342828035354614
本文中实战部分,将训练集、测试集中文本数据截断或填充,使得不同长度的原始文本经过处理后长度一致采用的是保留文本数据中前面部分,截断长文本后面部分,在短文本后面部分填充的方法。由于SimpleRNN的遗忘问题,越靠近最后时刻的数据记忆越深刻。本文这种数据处理方法,使得靠近最后时刻的数据要么是一段文本中的中间部分(一般来说,一段评论更倾向于在开头和结尾表达感情。),要么是填充的无意义符号。经过训练发现在测试即上的表现基本比第3部分电影评论情感分析(一)模型差,由此可见数据处理的重要性。如果将
seq_len设置为200,实测在测试集上基本无法做出正确的预测。因为在末尾填充的无意义信息过多,而且SimpleRNN遗忘掉了最开始的输出数据。预期在数据处理时,采用保留文本数据中后面部分,截断长文本前面部分,在短文本前面部分填充的方法,测试效果将会好得多。
6. 参考资料链接
- https://www.icourse163.org/learn/ZUCC-1206146808?tid=1461395446#/learn/content?type=detail&id=1237779505&cid=1257874377
- https://www.icourse163.org/learn/ZUCC-1206146808?tid=1461395446#/learn/content?type=detail&id=1237779506&cid=1257874382
- https://www.icourse163.org/learn/ZUCC-1206146808?tid=1461395446#/learn/content?type=detail&id=1237779507&cid=1257874386
- https://www.icourse163.org/learn/ZJU-1206573810?tid=1206902211#/learn/content?type=detail&id=1235268008&cid=1255629043
- https://www.cnblogs.com/nio-nio/p/11599199.html
- https://www.paddlepaddle.org.cn/documentation/docs/zh/tutorial/nlp_case/imdb_bow_classification/imdb_bow_classification.html
- https://aistudio.baidu.com/aistudio/projectdetail/1981183
- https://www.youtube.com/watch?v=NWcShtqr8kc&list=PLvOO0btloRnuTUGN4XqO85eKPeFSZsEqK&index=1
- https://www.youtube.com/watch?v=6_2_2CPB97s&list=PLvOO0btloRnuTUGN4XqO85eKPeFSZsEqK&index=2
- https://www.youtube.com/watch?v=Cc4ENs6BHQw&list=PLvOO0btloRnuTUGN4XqO85eKPeFSZsEqK&index=3
二、长短期记忆网络(LSTM)原理与实战
1. 前言
本文详解LSTM(Long Short Term Memory)原理,并使用飞桨(PaddlePaddle)基于IMDB电影评论数据集实现电影评论情感分析。
2. LSTM网络结构
LSTM是一种RNN模型,是对Simple RNN的改进,结构如图一所示。其原理与Simple RNN类似,每当读取一个新的输入 x x x,就会更新状态向量 h h h。

LSTM网络结构比Simple RNN复杂很多,其使用传输带(Conveyor Belt,见图二)将过去的信息送到下一个时刻,并使用“门(Gate)”结构遗忘传输带上的信息或向传输带上添加新的信息。这种结构设计,缓解了梯度消失问题,从而获得比Simple RNN更长的记忆能力。

2.1 遗忘门(Forget Gate)
“门”是一种让信息选择式通过的结构,包含一个Sigmoid操作和一个Elementwise Multiplication(两个同样大小矩阵对应元素相乘,得到一个新的同样大小的矩阵)操作。
如图三所示,遗忘门决定过去哪些信息被遗忘,其读取 h t − 1 h_{t-1} ht−1和 x t x_t xt,输出 f t 为 f_t为 ft为一个与传输带状态向量 C t − 1 C_{t-1} Ct−1大小相同且每个元素均在0到1之间的向量。

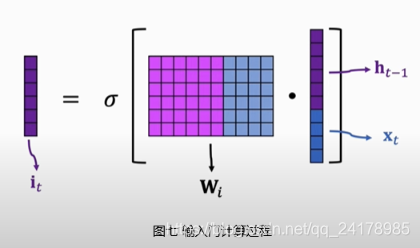
遗忘门 f t f_t ft的具体计算过程如下,将上一时刻状态向量 h t − 1 h_{t-1} ht−1和当前时刻输入向量 x t x_t xt拼接,然后左乘参数矩阵 W f W_f Wf,并使用激活函数Sigmoid作用在得到的新矩阵的每一个元素上(示意图中没考虑添加偏置情况,但公式中加上了偏置项,下同),得到一个与传输带状态向量 C t − 1 C_{t-1} Ct−1大小相同的向量 f t f_t ft, f t = σ ( W f [ h t − 1 , x t ] + b f ) f_t=\sigma(W_f[h_{t-1}, x_t]+b_f) ft=σ(Wf[ht−1,xt]+bf)。

2.2 输入门(Input Gate)
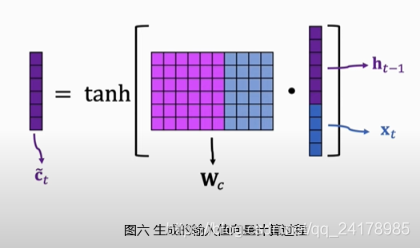
如下图所示, C t ~ \tilde{C_t} Ct~可以看做输入 h t − 1 h_{t-1} ht−1和 x t x_t xt生成的输入信息,输入门的输出 i t i_t it与生成的输入值向量 C t ~ \tilde{C_t} Ct~做Elementwise Multiplication,决定向传输带上添加哪些新的信息。

生成的输入值向量 C t ~ \tilde{C_t} Ct~和输入门 i t i_t it的具体计算过程如下。将上一时刻状态向量 h t − 1 h_{t-1} ht−1和当前时刻输入向量 x t x_t xt拼接,然后分别左乘参数矩阵 W c W_c Wc和 W i W_i Wi,再分别使用激活函数tanh和Sigmoid作用在得到的新矩阵的每一个元素上,得到 C t ~ \tilde{C_t} Ct~和 i t i_t it, C t ~ = t a n h ( W c [ h t − 1 , x t ] + b c ) \tilde{C_t}=tanh(W_c[h_{t-1}, x_t]+b_c) Ct~=tanh(Wc[ht−1,xt]+bc), i t = σ ( W i [ h t − 1 , x t ] + b i ) i_t=\sigma(W_i[h_{t-1}, x_t]+b_i) it=σ(Wi[ht−1,xt]+bi)。
 ~~~~~~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~~~~~~~~~~~ 
2.3 传输带状态向量更新
计算得到遗忘门 f t f_t ft,输入门 i t i_t it和生成的输入值向量 C t ~ \tilde{C_t} Ct~,并且知道传输带旧状态向量 C t − 1 C_{t-1} Ct−1,则可按照如下方法更新传输带上的信息:
- 将传输带旧值 C t − 1 C_{t-1} Ct−1与 f t f_t ft做Elementwise Multiplication,遗忘部分信息;
- 将生成的输入值向量 C t ~ \tilde{C_t} Ct~与 i t i_t it做Elementwise Multiplication,得到输入信息;
- 令 C t = f t ⊗ C t − 1 + i t ⊗ C t ~ C_t=f_t\otimes C_{t-1}+i_t\otimes \tilde{C_t} Ct=ft⊗Ct−1+it⊗Ct~,得到新传输带状态向量。

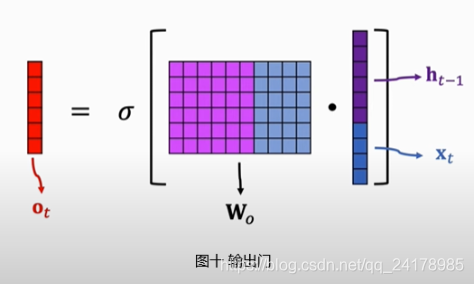
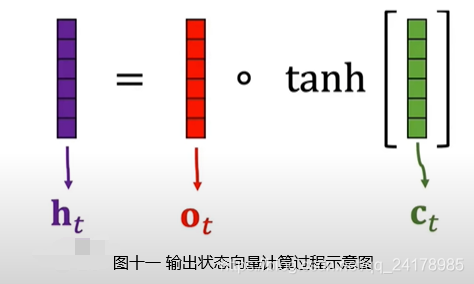
2.4 输出门(Output Gate)
如图九所示,输出门决定传输带上哪些信息被输出, o t = σ ( W o [ h t − 1 , x t ] + b o ) o_t=\sigma(W_o[h_{t-1}, x_t]+b_o) ot=σ(Wo[ht−1,xt]+bo)。将tanh函数作用与新传输带状态向量 C t C_t Ct,然后将结果与 o t o_t ot做Elementwise Multiplication,即得到 t t t时刻输出 h t h_t ht。

具体计算过程如下图所示:
 ~~
~~ 
3. 遗忘问题缓解机制
LSTM使用了传输带结构设计,使得过去的信息很容易传输到下一时刻,从而获得了比Simple RNN更长的记忆能力。根据前文所述内容,LSTM模型计算公式可总结如下:
遗 忘 门 f t : f t = σ ( W f [ h t − 1 , x t ] + b f ) ( 1 ) 输 入 门 i t : i t = σ ( W i [ h t − 1 , x t ] + b i ) ( 2 ) 输 出 门 o t : o t = σ ( W o [ h t − 1 , x t ] + b o ) ( 3 ) 生 成 的 输 入 值 向 量 C t ~ : C t ~ = t a n h ( W c [ h t − 1 , x t ] + b c ) ( 4 ) 新 传 输 带 状 态 向 量 C t : C t = f t ⊗ C t − 1 + i t ⊗ C t ~ ( 5 ) 状 态 向 量 h t : h t = o t ⊗ t a n h ( C t ) ( 6 ) 遗忘门f_t:f_t=\sigma(W_f[h_{t-1}, x_t]+b_f)~~~~~~~~~~~~~~~~~~~(1)\\ 输入门i_t:i_t=\sigma(W_i[h_{t-1}, x_t]+b_i)~~~~~~~~~~~~~~~~~~~~(2)\\ 输出门o_t:o_t=\sigma(W_o[h_{t-1}, x_t]+b_o)~~~~~~~~~~~~~~~~~~~(3)\\ 生成的输入值向量\tilde{C_t}:\tilde{C_t}=tanh(W_c[h_{t-1}, x_t]+b_c)~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~(4)\\ 新传输带状态向量C_t:C_t=f_t\otimes C_{t-1}+i_t\otimes \tilde{C_t}~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~(5)\\ 状态向量h_t:h_t=o_t\otimes tanh(C_t)~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~(6) 遗忘门ft:ft=σ(Wf[ht−1,xt]+bf) (1)输入门it:it=σ(Wi[ht−1,xt]+bi) (2)输出门ot:ot=σ(Wo[ht−1,xt]+bo) (3)生成的输入值向量Ct~:Ct~=tanh(Wc[ht−1,xt]+bc) (4)新传输带状态向量Ct:Ct=ft⊗Ct−1+it⊗Ct~ (5)状态向量ht:ht=ot⊗tanh(Ct) (6)
RNN使用相同的计算单元重复作用于不同时刻的输入向量 x t x_t xt与状态向量 h t − 1 h_{t-1} ht−1,产生下一时刻的新状态向量 h t h_t ht。 h t h_t ht是 x t x_t xt和 h t − 1 h_{t-1} ht−1的函数。因此, ∂ h t ∂ x t − k \frac{\partial h_t}{\partial x_{t-k}} ∂xt−k∂ht的计算公式必定存在 ∂ h t ∂ h t − 1 ∂ h t − 1 ∂ h t − 2 ⋯ ∂ h t − k + 1 ∂ h t − k \frac{\partial h_t}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial h_{t-2}}\cdots\frac{\partial h_{t-k+1}}{\partial h_{t-k}} ∂ht−1∂ht∂ht−2∂ht−1⋯∂ht−k∂ht−k+1沿时间轴传播链式计算部分。在Simple RNN中,由于 ∂ h t ∂ h t − 1 = ∂ h t ∂ z t W h ( 其 中 z t = W i x t + W h h t − 1 + b , h t = t a n h ( z t ) ) \frac{\partial h_t}{\partial h_{t-1}}=\frac{\partial h_t}{\partial z_t}W_h(其中z_t=W_ix_t+W_hh_{t-1}+b, h_t=tanh(z_t)) ∂ht−1∂ht=∂zt∂htWh(其中zt=Wixt+Whht−1+b,ht=tanh(zt))中包含 W h W_h Wh,当 k k k较大时, ∂ h t ∂ h t − 1 ∂ h t − 1 ∂ h t − 2 ⋯ ∂ h t − k + 1 ∂ h t − k \frac{\partial h_t}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial h_{t-2}}\cdots\frac{\partial h_{t-k+1}}{\partial h_{t-k}} ∂ht−1∂ht∂ht−2∂ht−1⋯∂ht−k∂ht−k+1计算式中相当于存在多个 W h W_h Wh连乘。若 W h W_h Wh值较小,则连乘导致整个计算式值接近于0, ∂ h t ∂ x t − k \frac{\partial h_t}{\partial x_{t-k}} ∂xt−k∂ht值接近于0,即输入向量 x t − k x_{t-k} xt−k发生改变,状态向量 h t h_t ht基本不发生改变, h t h_t ht与 x t − k x_{t-k} xt−k基本不存在相关关系,Simple RNN遗忘了比较久之前的信息。
LSTM使用传输带将 t t t时刻之前的信息送到第 t t t个时刻,状态向量 h t h_t ht是 C t C_t Ct的函数,因此可用 ∂ C t ∂ C t − 1 \frac{\partial C_t}{\partial C_{t-1}} ∂Ct−1∂Ct将后一时刻梯度沿时间轴传播至前一时刻。
公式(5)表明 C t C_t Ct是 f t , C t − 1 , i t , C t ~ f_t,C_{t-1},i_t,\tilde{C_t} ft,Ct−1,it,Ct~的函数。公式(1)、(2)、(4)表明 f t , i t , C t ~ f_t,i_t,\tilde{C_t} ft,it,Ct~是 h t − 1 h_{t-1} ht−1的函数,公式(6)表明 h t − 1 h_{t-1} ht−1是 C t − 1 C_{t-1} Ct−1的函数,即 f t , i t , C t ~ f_t,i_t,\tilde{C_t} ft,it,Ct~是 C t − 1 C_{t-1} Ct−1的函数。因此, ∂ C t ∂ C t − 1 \frac{\partial C_t}{\partial C_{t-1}} ∂Ct−1∂Ct计算如下:
∂ C t ∂ C t − 1 = f t + ∂ f t ∂ C t − 1 C t − 1 + i t ∂ C ~ t ∂ C t − 1 + ∂ i t ∂ C t − 1 C t ~ ( 7 ) \frac{\partial C_t}{\partial C_{t-1}}=f_t+\frac{\partial f_t}{\partial C_{t-1}}C_{t-1}+i_t\frac{\partial{\tilde C_t}}{\partial C_{t-1}}+\frac{\partial i_t}{\partial C_{t-1}}\tilde{C_t}~~~~~~~~~~~~~~~~~~~~~~~~(7) ∂Ct−1∂Ct=ft+∂Ct−1∂ftCt−1+it∂Ct−1∂C~t+∂Ct−1∂itCt~ (7)
据式(7)可知, ∂ C t ∂ C t − 1 \frac{\partial C_t}{\partial C_{t-1}} ∂Ct−1∂Ct由四项相加所得,其中第一项为遗忘门 f t f_t ft的输出,其值上界为1,梯度沿时间轴向前传播的链式计算式中不存在Simple RNN中连乘多次参数矩阵的情况,网络结构上保证了LSTM有联系长距离上下文的能力。在模型训练参数初始化时,一般会将遗忘门初始化为接近1的值,保证梯度能够长距离传播,即初始默认认为所有上下文信息均须保留,而实际情况是否真的需要保存所有上下文信息,交由模型在训练数据中学习。
4. 电影评论情感分析(三)
LSTM模型拥有比Simple RNN更长的记忆能力,而且在实践中可以发现LSTM效果总是比Simple RNN好。虽然在RNN模型领域还存在GRU(Gated Recurrent Unit)等模型设计,但是在一般情况下其它RNN模型效果也不比LSTM效果好多少,因此在需要运用RNN模型时候,一般建议首选LSTM模型。
电影评论情感分析(三)使用LSTM模型分析电影评论情感,设计如下:
- 模型结构:Embedding层+LSTM层+Softmax分类器
- 词嵌入维度:16
- 状态向量维度:32
4.1 模型搭建
数据处理与3.1部分相同,直接介绍搭建神经网络模型。定义继承自paddle.nn.Layer的MyLSTM类,在初始化函数__init__中定义网络各层,重写forward方法,实现前向计算流程。代码如下:
# -*- coding: utf-8 -*-
# @Time : 2021/7/4 9:55
# @Author : He Ruizhi
# @File : lstm.py
# @Software: PyCharm
import paddle
from emb_softmax import get_data_loader
import warnings
warnings.filterwarnings('ignore')
class MyLSTM(paddle.nn.Layer):
def __init__(self, embedding_dim, hidden_size):
super(MyLSTM, self).__init__()
self.emb = paddle.nn.Embedding(num_embeddings=5149, embedding_dim=embedding_dim)
self.lstm = paddle.nn.LSTM(input_size=embedding_dim, hidden_size=hidden_size)
self.fc = paddle.nn.Linear(in_features=hidden_size, out_features=2)
self.softmax = paddle.nn.Softmax()
def forward(self, x):
x = self.emb(x)
# LSTM层分别返回所有时刻状态和最后时刻h与c状态,这里只使用最后时刻的h
_, (x, _) = self.lstm(x)
# 去掉第0维,这么处理与PaddlePaddle的LSTM层返回格式有关
x = paddle.squeeze(x, axis=0)
x = self.fc(x)
x = self.softmax(x)
return x
4.2 模型训练
设置超参数seq_len = 200、emb_size = 16,调用get_data_loader函数加载训练和测试数据,实例化模型对象并使用paddle.Model封装。使用model.summary获得模型信息如下:
-----------------------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================================
Embedding-1 [[1, 200]] [1, 200, 16] 82,384
LSTM-1 [[1, 200, 16]] [[1, 200, 32], [[1, 1, 32], [1, 1, 32]]] 6,400
Linear-1 [[1, 32]] [1, 2] 66
Softmax-1 [[1, 2]] [1, 2] 0
===============================================================================================
Total params: 88,850
Trainable params: 88,850
Non-trainable params: 0
-----------------------------------------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.07
Params size (MB): 0.34
Estimated Total Size (MB): 0.41
-----------------------------------------------------------------------------------------------
使用model.prepare进行模型配置,使用paddle.optimizer.Adam优化器、paddle.nn.CrossEntropyLoss损失函数,并添加paddle.metric.Accuracy作为衡量指标。使用model.fit开启模型训练,设置eopchs=5,将test_data_loader作为验证数据。模型训练部分代码如下:
if __name__ == '__main__':
seq_len = 200
emb_size = 16
hidden_size = 32
train_data_loader = get_data_loader('train', seq_len=seq_len, data_show=1)
test_data_loader = get_data_loader('test', seq_len=seq_len)
model = paddle.Model(MyLSTM(16, 32))
model.summary(input_size=(None, seq_len), dtype='int64')
model.prepare(optimizer=paddle.optimizer.Adam(learning_rate=0.01, parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(use_softmax=False),
metrics=paddle.metric.Accuracy())
model.fit(train_data_loader, epochs=5, verbose=1, eval_data=test_data_loader)
训练过程信息如下:
The loss value printed in the log is the current step, and the metric is the average value of previous steps.
Epoch 1/5
step 195/195 [==============================] - loss: 0.6897 - acc: 0.5111 - 13ms/step
Eval begin...
step 195/195 [==============================] - loss: 0.6718 - acc: 0.5367 - 7ms/step
Eval samples: 24960
Epoch 2/5
step 195/195 [==============================] - loss: 0.6352 - acc: 0.5819 - 12ms/step
Eval begin...
step 195/195 [==============================] - loss: 0.6926 - acc: 0.6001 - 7ms/step
Eval samples: 24960
Epoch 3/5
step 195/195 [==============================] - loss: 0.3323 - acc: 0.7799 - 12ms/step
Eval begin...
step 195/195 [==============================] - loss: 0.2929 - acc: 0.8358 - 7ms/step
Eval samples: 24960
Epoch 4/5
step 195/195 [==============================] - loss: 0.2136 - acc: 0.8827 - 12ms/step
Eval begin...
step 195/195 [==============================] - loss: 0.2270 - acc: 0.8569 - 7ms/step
Eval samples: 24960
Epoch 5/5
step 195/195 [==============================] - loss: 0.2640 - acc: 0.9167 - 12ms/step
Eval begin...
step 195/195 [==============================] - loss: 0.2964 - acc: 0.8537 - 7ms/step
Eval samples: 24960
经过对训练样本5轮迭代,模型验证准确率可达
85.69%。显然使用LSTM模型效果远远优于Simple RNN模型。
5. 参考资料链接
- https://www.icourse163.org/learn/ZUCC-1206146808?tid=1461395446#/learn/content?type=detail&id=1237779507&cid=1257874386
- https://www.youtube.com/watch?v=vTouAvxlphc&list=PLvOO0btloRnuTUGN4XqO85eKPeFSZsEqK&index=4
- https://blog.csdn.net/nuohuang3371/article/details/111655642
三、循环神经网络的改进:多层RNN、双向RNN与预训练
1. 前言
本文讲解循环神经网络(RNN)的改进方法,并使用改进的RNN实现电影评论情感分析。
2. 多层RNN(Stacked RNN)
在深度学习领域,可以将许多全连接层堆叠,构成一个多层感知机(Multi-Layer Perception),可以将许多卷积层堆叠,构成一个深度卷积网络。同样的,可以将许多RNN层堆叠,构成一个多层RNN网络。
RNN每读取一个新的输入 x t x_t xt,就会生成状态向量 h t h_t ht作为当前时刻的输出和下一时刻的输入状态。 将 T T T个输入 x 0 ∼ x T x_0\sim x_T x0∼xT依次输入RNN,相应地会产生 T T T个输出。第一层RNN输出的 T T T个状态向量可以作为第二层RNN的输入,第二层RNN拥有独立的参数,依次读取 T T T个来自第一层RNN的状态向量,产生 T T T个新的输出。第二层RNN输出的 T T T个状态向量可以作为第三层RNN的输入,依此类推,构成一个多层RNN网络。

在图一所示3层RNN网络中,输入为词嵌入 x 0 ∼ x t x_0\sim x_t x0∼xt,状态向量 h 1 ∼ h t h_1\sim h_t h1∼ht是最终的输出。可以将最后一个状态向量 h t h_t ht看做是从最底层输入的文本中提取的特征向量。
当训练数据足够多时,多层RNN效果可能会比单层RNN效果好,可以尝试使用多层RNN。
3. 双向RNN(Bidirectional RNN)
RNN对时序数据的处理与人脑一致,人类从左往右依次阅读文本中的每个单词,在大脑里积累信息,RNN从左往右依次读取输入 x t , ( t = 0 ∼ T ) x_t, (t=0\sim T) xt,(t=0∼T),在状态向量 h t , ( t = 0 ∼ T ) h_t, (t=0\sim T) ht,(t=0∼T)中积累信息。
人类习惯于从左往右、从前往后阅读,但是一段文本的内在含义取决于不同单词的排列顺序,当排列顺序固定,文本意义一般是固定的。一般来说,从右往左阅读一段文本并不会影响该文本的内在意义及对其整体含义的理解。对于RNN来说,从左往右或从右往左阅读一段文本并没有本质的区别。在实践中,将训练集中每个训练样本的单词均从右往左依次输入RNN,一般可以取得相同的效果。因此可以训练两个完全独立(不共享参数和状态向量)的RNN,一个从左往右,另一个从右往左依次读取训练样本中输入的单词。

如图二所示,两个RNN分别输出各自状态向量,然后将二者输出的状态向量拼接,形成双向RNN的输出状态向量 y y y。状态向量 h t h_t ht和 h t ′ h_t^\prime ht′拼接后形成的向量 [ h t , h t ′ ] [h_t, h_t^\prime] [ht,ht′]可以看做双向RNN从输入文本中提取的特征向量。
在各类时序数据处理任务中,双向RNN效果总是优于单向RNN。因为不管使用Simple RNN还是LSTM,都会或多或少遗忘掉早先的输入信息。如果RNN从左往右读取输入信息,则最后一个状态 h t h_t ht可能会遗忘掉左侧的输入信息。如果RNN从右往左读取输入信息,则最后一个状态 h t ′ h_t^\prime ht′可能会遗忘掉右侧的输入信息。二者结合可使得模型不会遗忘最先读取的输入信息。
在实际任务中,如果可以,建议使用双向RNN而不使用单向RNN,双向RNN效果至少不会比单向RNN效果差。
4. 预训练(Pretrain)
预训练在深度学习中非常常用,比如在训练深度卷积神经网络时,如果网络模型很大而训练集不够大,则可以先在ImageNet等大数据集上做预训练,从而使神经网络拥有比较合理的初始化,同时可以在一定程度上减少过拟合(Overfitting) 。
训练RNN时,模型Embedding层参数数量等于【词表大小】乘以【词嵌入维度】,该层参数往往比较多,非常容易导致模型过拟合,因此可以预训练Embedding层。预训练具体过程如下:
- 在更大的数据集上训练一个含有Embedding层的模型
- 预训练Embedding层时任务可以与原任务不一致
- 预训练Embedding层时模型结构可以与原任务不一致
两个任务越相似,预训练后Embedding层迁移效果就会越好;预训练时神经网络结构是什么都可以,甚至不用是RNN,但是必须包含Embedding层。
- 预训练完成后,只保留预训练阶段模型Embedding层及其参数
- 搭建解决实际问题的RNN模型,并在训练集上训练该RNN模型
- 搭建解决实际问题的RNN模型时,Embedding层采用预训练好的Embedding层
- 训练该RNN层时,如果训练集较小,建议不训练预训练阶段训练好的Embedding层参数。如果训练集相对较大,建议微调预训练阶段训练好的Embedding层参数
5. 电影评论情感分析(四)
改进电影评论情感分析模型,使用双层双向LSTM取代前文中单层单向LSTM。数据处理及模型训练部分均与电影评论分析(三)一致,只需更改模型搭建部分代码,稍微调整模型结构。
使用PaddlePaddle实现多层双向LSTM非常简单,根据官方API文档,paddle.nn.LSTM类包含direction、num_layers可选参数。direction表示网络迭代方向,可设置为forward或bidirect(或bidirectional),默认为forward。num_layers表示网络层数,默认为1。实现双层双向LSTM只需在实例化paddle.nn.LSTM对象时,传入参数direction='bidirectional'、num_layers=2。此外,在重写forward方法,执行前向计算流程时,需要进行相应的更改,具体代码如下:
# -*- coding: utf-8 -*-
# @Time : 2021/7/6 18:55
# @Author : He Ruizhi
# @File : advanced_rnn.py
# @Software: PyCharm
import paddle
from emb_softmax import get_data_loader
import warnings
warnings.filterwarnings('ignore')
class AdvancedLSTM(paddle.nn.Layer):
def __init__(self, embedding_dim, hidden_size):
super(AdvancedLSTM, self).__init__()
self.emb = paddle.nn.Embedding(num_embeddings=5149, embedding_dim=embedding_dim)
self.lstm = paddle.nn.LSTM(input_size=embedding_dim, hidden_size=hidden_size,
direction='bidirectional', num_layers=2)
self.flatten = paddle.nn.Flatten()
self.fc = paddle.nn.Linear(in_features=hidden_size*2, out_features=2)
self.softmax = paddle.nn.Softmax()
def forward(self, x):
x = self.emb(x)
# LSTM层分别返回所有时刻状态和最后时刻h与c状态,这里只使用最后时刻的h
_, (x, _) = self.lstm(x)
# 获取双层双向LSTM最后一层的输出状态
x = paddle.slice(x, axes=[0], starts=[2], ends=[4])
# 调整x的数据排列,这么处理与PaddlePaddle的LSTM层返回格式有关
x = paddle.transpose(x, [1, 0, 2])
x = self.flatten(x)
x = self.fc(x)
x = self.softmax(x)
return x
使用model.summary可查看模型结构及参数信息:
-----------------------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================================
Embedding-1 [[1, 200]] [1, 200, 16] 82,384
LSTM-1 [[1, 200, 16]] [[1, 200, 64], [[4, 1, 32], [4, 1, 32]]] 37,888
Flatten-1 [[1, 2, 32]] [1, 64] 0
Linear-1 [[1, 64]] [1, 2] 130
Softmax-1 [[1, 2]] [1, 2] 0
===============================================================================================
Total params: 120,402
Trainable params: 120,402
Non-trainable params: 0
-----------------------------------------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.12
Params size (MB): 0.46
Estimated Total Size (MB): 0.58
-----------------------------------------------------------------------------------------------
开启模型训练,打印训练过程信息:
The loss value printed in the log is the current step, and the metric is the average value of previous steps.
Epoch 1/5
step 195/195 [==============================] - loss: 0.5211 - acc: 0.6451 - 47ms/step
Eval begin...
step 195/195 [==============================] - loss: 0.6951 - acc: 0.7158 - 23ms/step
Eval samples: 24960
Epoch 2/5
step 195/195 [==============================] - loss: 0.2767 - acc: 0.8171 - 50ms/step
Eval begin...
step 195/195 [==============================] - loss: 0.1709 - acc: 0.8181 - 24ms/step
Eval samples: 24960
Epoch 3/5
step 195/195 [==============================] - loss: 0.2327 - acc: 0.8855 - 47ms/step
Eval begin...
step 195/195 [==============================] - loss: 0.2820 - acc: 0.8548 - 24ms/step
Eval samples: 24960
Epoch 4/5
step 195/195 [==============================] - loss: 0.2743 - acc: 0.9044 - 47ms/step
Eval begin...
step 195/195 [==============================] - loss: 0.2730 - acc: 0.8567 - 24ms/step
Eval samples: 24960
Epoch 5/5
step 195/195 [==============================] - loss: 0.2919 - acc: 0.9254 - 47ms/step
Eval begin...
step 195/195 [==============================] - loss: 0.2877 - acc: 0.8539 - 22ms/step
Eval samples: 24960
经过实践发现,在IMDB电影评论情感分析数据集上,单层单向LSTM与双层双向LSTM结果基本一致,没有显著效果提升。回顾电影评论情感分析(一)至(四),我认为问题主要是出在Embedding层,Embedding层参数太多,训练数据集较小,出现过拟合。在此情况下,改进RNN层无法提升模型效果。在此情况下,要想提升模型效果,可以预训练Embedding层。
6. 模型大小与训练数据集大小认识(附议)
过拟合是深度学习实践中非常容易出现的现象,其根本原因是:
- 模型的复杂度大于实际问题的复杂度
- 模型的复杂度大于训练数据的复杂度
在各类深度学习资料中,经常可以看到“模型太大,参数过多,训练数据集较小,模型出现过拟合”,但是几乎没有任何资料给出一个对模型和训练数据集相对大小的认识。任何人都知道训练数据越多,则可以将模型训练得越好,训练数据多多益善。但是,对于给定的存在多少参数的模型,究竟需要多少数据才能够从头训练出一套比较合理的模型参数?
对于上述问题,其实并不存在精确的数学指导理论或证明。下面我将用一个例子,和大家一起感性理解模型大小与训练数据集大小的关系。
假设要用数据拟合二维平面内一条直线( y = k x + b y=kx+b y=kx+b,两个参数),当训练数据只有一个,即给定平面上一个点,确定平面内一条直线。显然,在只给定一个点的情况下,拟合出来的直线有极大可能与真实直线存在较大的偏差。如果给定两个点,虽然两点可以确定一条唯一的直线,但是由于给定的两个点,是训练数据集中的随机样本,具有一定的随机性,拟合出来的直线仍有较大可能与真实直线存在一定的偏差。一般来说,当给定十数个甚至数十上百个点,才能拟合出比较精确的直线。

从上述例子可知,比较精确地拟合只有2个参数的模型,需要约20个样本,即在模型复杂度和问题复杂度一致的情况下,训练出一个比较精确合理的模型,训练集数据量预计要十倍于模型参数数量。
在深度学习实践中,模型复杂度很有可能大于实际问题复杂度,而且问题和数据特征空间维度可达成百上千甚至数百万维。模型复杂度比实际问题复杂度越大,则模型越容易拟合训练数据中的噪声、异常值等不能反映实际问题客观规律的随机误差,模型需要更多数据才能学到实际问题中的真实规律。问题和数据特征空间维度越高,则求解空间越大,相当于可选答案更多,干扰项越多,需要更多信息才能找到真实规律。因此,训练深度学习模型,训练集数据量哪怕百倍千倍于模型参数量,都无法肯定的说训练数据集已经足够大。
深度学习模型参数动辄数十万上百万,OpenAI出品的GPT-3模型参数达到了令人恐怖的1750亿,Google出品的Switch Transformer语言模型参数达到了令人发指的1.6万亿,快手出品的精排排序模型参数据说达到了丧心病狂的1.9万亿。
在深度学习领域,训练数据集不论多大,永远都可以说——两个怎么够?我要二十个!

7. 参考资料链接
- 九品芝麻官(普通话版)
- https://www.youtube.com/watch?v=pzWHk_M23a0&list=PLvOO0btloRnuTUGN4XqO85eKPeFSZsEqK&index=5&t=608s
- https://www.icourse163.org/learn/ZJU-1206573810?tid=1206902211#/learn/content?type=detail&id=1234658158&cid=1254264368&replay=true
四、Sequence-to-Sequence模型原理
1. 前言
本文讲解Sequence-to-Sequence(Seq2Seq)模型原理。
2. Seq2Seq模型结构
在机器翻译等多对多(many to many)NLP任务中,输入和输出序列长度往往不固定。RNN每读取一个新的输入 x t x_t xt,就会生成状态向量 h t h_t ht作为当前时刻的输出和下一时刻的输入状态,将 T T T个输入 x 0 ∼ x T x_0\sim x_T x0∼xT依次输入RNN,相应地会产生 T T T个输出,即输入和输出序列长度必定相同,因此RNN不适合解决该类问题。适合解决这种输入和输出序列长度均不固定的NLP任务的模型是Seq2Seq模型。
Seq2Seq模型由编码器(Encoder)和解码器(Decoder)组成。编码器用于编码输入序列信息,其将任意长度的输入序列包含的信息编码成一个信息向量。解码器用于解码信息向量,生成输出序列。
2.1 编码器(Encoder)
Seq2Seq模型的Encoder编码输入序列信息,从输入序列中提取特征。由于Encoder的输入是一个序列,因此Encoder一般是一个RNN。从理论上来说,Encoder可以是任意结构的神经网络。在深度学习实践中,Encoder一般是一个与Decoder类型相同的RNN。

2.2 解码器(Decoder)
Decoder解码Encoder生成的信息向量,生成输出序列。Decoder是一个RNN,其初始状态不是全0向量,而是Encoder的最后一个状态。
在生成序列时,将Encoder的最后一个状态作为Decoder的初始状态,将起始符[start]输入Decoder RNN,Decoder RNN将状态向量更新为 S 1 S_1 S1,将 S 1 S_1 S1输入 S o f t m a x Softmax Softmax分类器,可以生成预测概率 P 1 P_1 P1,根据概率 P 1 P_1 P1可以确定第一个生成序列元素 Z 1 Z_1 Z1。Decoder RNN将 Z 1 Z_1 Z1作为输入,将状态向量从 S 1 S_1 S1更新为 S 2 S_2 S2,将 S 2 S_2 S2输入 S o f t m a x Softmax Softmax分类器,可以生成预测概率 P 2 P_2 P2,根据概率 P 2 P_2 P2可以确定下一个生成序列元素 Z 2 Z_2 Z2。以此类推,将 Z t − 1 Z_{t-1} Zt−1作为输入,将状态向量从 S t − 1 S_{t-1} St−1更新为 S t S_t St,将 S t S_t St输入 S o f t m a x Softmax Softmax分类器,可以生成预测概率 P t P_t Pt,根据概率 P t P_t Pt确定下一个生成序列元素为停止符[stop]。
当生成的元素为停止符,则终止序列生成,返回 Z 1 Z 2 ⋯ Z t − 1 Z_1Z_2\cdots Z_{t-1} Z1Z2⋯Zt−1为生成的输出序列。

3. Seq2Seq模型改进
3.1 Encoder改进方法
3.1.1 结构改进
Encoder对输入序列进行处理,将输入序列信息压缩到信息向量中。Encoder最后一个状态是整个输入序列的概要,即对输入序列的编码。在理想状态下,Encoder最后一个状态包含了整个输入序列的完整信息。
当Encoder采用RNN结构,而且输入序列很长,则RNN会遗忘输入序列部分信息。当Encoder部分信息被遗忘,则Decoder接收到的信息向量中不包含输入序列的完整信息,因此Decoder生成的输出序列肯定存在偏差。缓解RNN的遗忘问题,显然可以使用前文循环神经网络的改进中所述双向RNN方法改进Encoder。
当使用双向RNN结构改进Encoder,Encoder输出的最后一个状态向量长度会变成单向RNN的两倍,但是Encoder和Decoder的状态向量维度并不要求必须相同。在此情况下,Encoder状态向量长度是Decoder状态向量长度的2倍。
此外,还可以使用前文所述多层RNN方法改进Encoder结构,使得Encoder信息编码能力更强。
3.1.2 训练方法改进
改进训练方法,使得Encoder被训练的更好,显然可以使用前文所述预训练方法。当Encoder使用了Embedding层,则可以事先在大数据集上预训练Embedding层。此外,还可以使用多任务学习(Multi-Task Learning)方法使Encoder被训练的更好。
比如在机器翻译中,Encoder输入为一种语言句子,Decoder生成另一种语言对应的句子。训练数据是两种不同语言的“句子对”。将语言A翻译成语言B可以视为一个任务,可以添加多个任务,比如将语言A翻译成语言C、语言D等等,甚至可以将语言A翻译成语言A本身。在这些任务中,均共用一个Encoder,这样处理可使训练Encoder的数据多好几倍,使Encoder被训练的更好。
3.2 Decoder改进方法
3.2.1 Teacher Forcing
在训练Seq2Seq模型时,Decoder在 t t t时刻的输入为 t − 1 t-1 t−1时刻输出状态向量经过 S o f t m a x Softmax Softmax分类器选定的元素。如果 t − 1 t-1 t−1时刻的输出是错误的,则RNN在 t t t时刻接收了一个错误的输入,因此 t t t时刻的输出也很可能是错误的,而且这种错误会一直传递下去。
使用Teacher Forcing,在训练Seq2Seq模型时,Decoder在 t t t时刻的输入并非一定为 t − 1 t-1 t−1时刻输出状态向量经过 S o f t m a x Softmax Softmax分类器选定的元素,而是有一定概率采用正确的序列元素作为输入。
3.2.2 Beam Search
Beam Search(集束搜索)不总是选取 t − 1 t-1 t−1时刻输出概率值最大的元素,而是选取 t − 1 t-1 t−1时刻输出概率值最大的 t o p top top- k k k个元素作为 t t t时刻Decoder的输入。分别将 t − 1 t-1 t−1时刻的 k k k个不同的输出作为 t t t时刻的输入,对于每一个输入,Decoder计算出在 t t t时刻所有 l l l个候选元素的概率,然后在 k l kl kl个结果中选择概率值最大的 t o p top top- k k k个元素作为 t + 1 t+1 t+1时刻Decoder的输入,并重复这个过程。
Beam Search用于模型测试阶段,可减小模型训练阶段性能与测试阶段性能的差异。
改进Seq2Seq模型,除了上述方法之外,还有一种方法:注意力机制(Attention)。Attention可以避免RNN遗忘的问题,而且可以让RNN关注最相关的信息,从而大幅提高机Seq2Seq模型的效果。Attention原理请参见后文:注意力机制(Attention):Seq2Seq模型的改进。

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)