
AdvSemiSeg 利用生成对抗实现半监督语义分割
Reproduction of Paper "Adversarial Learning for Semi-Supervised Semantic Segmentation" with Paddle
项目说明
Reproduction of Paper “Adversarial Learning for Semi-Supervised Semantic Segmentation” with PaddlePaddle.
本项目对半监督语义分割领域的经典论文“Adversarial Learning for Semi-Supervised Semantic Segmentation”基于PaddlePaddle进行了复现,达到了论文指标。
AdvSemiSeg是半监督语义分割领域最早的文章之一。与弱监督领域通常采用的分类级标签数据和分类级损失函数不同,半监督学习更强调少量有标签数据与大量无标签数据的结合,其核心在于如何通过有标签数据更好地挖掘无标签数据的监督信息,从而达到提升模型性能而降低人力支出的目的。
方法流程
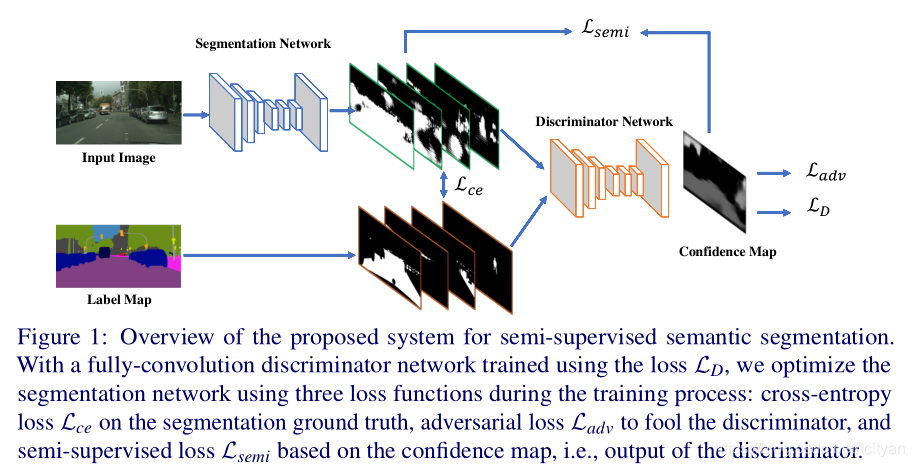
模型包括两个模块
- 分割网络
𝐻×𝑊×3 - > 分割网络 -> 𝐻×𝑊×𝐶 (其中𝐶是分割类别的数量)
- 判别网络
输入是类概率图,类概率图是由分割网络或是从ground truth label 经过one-hot编码得到的
输出是𝐻×𝑊×1的概率图,像素值𝑝=1表示来自ground truth label,像素值𝑝=0表示来自分割网络。
训练过程:
训练时同时使用了带有标注的图像和未标注的图像
1、当使用标注图像时,分割网络同时受到基于ground truth label的标准交叉熵损失𝐿𝑐𝑒和基于判别网络的对抗性损失𝐿𝑎𝑑𝑣,注意,训练判别网络仅仅使用标注的数据。
2、当使用未标注图像时,用分割网络得到初步分割结果,然后将初步分割结果送入判别网络得到置信度图,将置信度图作为监督信号,对初步分割预测结果进行mask后作为标签,用自学习的方法通过𝐿𝑠𝑒𝑚𝑖训练分割网络。
Reference
复现说明
默认的配置是ResNet101+Deeplabv2+VOC2012+1/8Label
其余训练设置与原文项目一致:20000 iter、batch size 10;
- 复现指标
advSemiSeg文件夹版本(原文对应版本)
| 论文指标 | 复现指标 |
|---|---|
| 69.5 miou | 70.4 miou |
1、模型的设置在相应的代码中:
- train.py中204行处;
- evaluate.py中197行处;
2、标签率设置:–labeled-ratio 0.125 表示1/8标签率
3、训练指令和评估指令下方已经设置好
4、评估结果存放在results中的txt文件中
PaddleSeg套件版本:
模型和其余PaddleSeg的模型一致。需要指定label_ratio启用半监督训练算法。具体查看PaddleSeg/semi目录。
| 论文指标 | 复现指标 |
|---|---|
| 69.5 miou | 72.6 miou |
下面的训练评估、代码一键可运行;全监督baseline和自动化测试为可选项,需要注意提示。
数据集准备
数据集采用了PASCAL VOC2012数据集,并采用了原文提供的增强标签。
#解压数据集
!unzip -q data/data4379/pascalvoc.zip -d data/data4379/
!unzip -q data/data117898/SegmentationClassAug.zip -d data/data4379/pascalvoc/VOCdevkit/VOC2012/
!cp aug.txt data/data4379/pascalvoc/VOCdevkit/VOC2012/ImageSets/Segmentation/
# 数据集结构
!tree -L 1 /home/aistudio/data/data4379/pascalvoc/VOCdevkit/VOC2012
训练advSemiSeg
!cd PaddleSegSemi/ && python train.py --config configs/deeplabv2/deeplabv2_resnet101_os8_voc_semi_321x321_20k.yml --label_ratio 0.125 --num_workers 0 --use_vdl --do_eval --save_interval 1000 --save_dir deeplabv2_res101_voc_0.125_20k
## 不使用PaddleSeg套件
# !cd advSemiSeg/ && python train.py --checkpoint_dir ./checkpoints/voc_semi_0_125 --labeled-ratio 0.125 --ignore-label 255 --num-classes 21 --use_vdl
评估advSemiSeg
## 使用PaddleSeg套件
!cd PaddleSegSemi/ && python val.py --config configs/deeplabv2/deeplabv2_resnet101_os8_voc_semi_321x321_20k.yml --model_path deeplabv2_res101_voc_0.125_20k/best_model/model.pdparams
## 不使用PaddleSeg套件
# !cd advSemiSeg/ && python evaluate.py --dataset pascal_voc --num-classes 21 --restore-from ./checkpoints/voc_semi_0_125/20000.pdparams
2021-11-24 10:15:59 [INFO]
------------Environment Information-------------
platform: Linux-4.13.0-36-generic-x86_64-with-debian-stretch-sid
Python: 3.7.4 (default, Aug 13 2019, 20:35:49) [GCC 7.3.0]
Paddle compiled with cuda: True
NVCC: Cuda compilation tools, release 10.1, V10.1.243
cudnn: 7.6
GPUs used: 1
CUDA_VISIBLE_DEVICES: None
GPU: ['GPU 0: Tesla V100-SXM2-16GB']
GCC: gcc (Ubuntu 7.5.0-3ubuntu1~16.04) 7.5.0
PaddlePaddle: 2.2.0
OpenCV: 4.1.1
------------------------------------------------
Namespace(data_dir='/home/aistudio/data/data4379/pascalvoc/VOCdevkit/VOC2012', data_list='./data/voc_list/val.txt', dataset='pascal_voc', gpu=0, ignore_label=255, model='Deeplabv2', num_classes=21, restore_from='./checkpoints/voc_semi_0_125/20000.pdparams', save_dir='results', save_output_images=False)
W1124 10:15:59.974874 2351 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1
W1124 10:15:59.974916 2351 device_context.cc:465] device: 0, cuDNN Version: 7.6.
2021-11-24 10:16:03 [INFO] No pretrained model to load, ResNet_vd will be trained from scratch.
2021-11-24 10:16:03 [INFO] Loading pretrained model from ./checkpoints/voc_semi_0_125/20000.pdparams
2021-11-24 10:16:03 [INFO] There are 538/538 variables loaded into DeepLabV2.
0 processd
evaluate.py:238: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
gt = np.asarray(label[0].numpy()[:size[0],:size[1]], dtype=np.int)
evaluate.py:245: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
output = np.asarray(np.argmax(output, axis=2), dtype=np.int)
100 processd
200 processd
300 processd
400 processd
500 processd
600 processd
700 processd
800 processd
900 processd
1000 processd
1100 processd
1200 processd
1300 processd
1400 processd
class 0 background IU 0.93
class 1 aeroplane IU 0.85
class 2 bicycle IU 0.41
class 3 bird IU 0.85
class 4 boat IU 0.67
class 5 bottle IU 0.78
class 6 bus IU 0.90
class 7 car IU 0.84
class 8 cat IU 0.84
class 9 chair IU 0.32
class 10 cow IU 0.72
class 11 diningtable IU 0.38
class 12 dog IU 0.81
class 13 horse IU 0.73
class 14 motorbike IU 0.81
class 15 person IU 0.83
class 16 pottedplant IU 0.44
class 17 sheep IU 0.78
class 18 sofa IU 0.43
class 19 train IU 0.72
class 20 tvmonitor IU 0.71
meanIOU: 0.7040637094579905
训练 fully-supervised Baseline (可选项)
!cd advSemiSeg/ && python train_full_pd.py --dataset pascal_voc \
--checkpoint-dir ./checkpoints/voc_full \
--ignore-label 255 \
--num-classes 21
TIPC自动化测试(可选项)
详细地可以查看PaddleSegSemi的README.需要安装日志程序相关依赖。
- 安装autolog
git clone https://github.com/LDOUBLEV/AutoLog cd AutoLog pip3 install -r requirements.txt python3 setup.py bdist_wheel pip3 install ./dist/auto_log-1.0.0-py3-none-any.whl cd ../
#进入PaddleSegSemi文件夹,运行命令
%cd PaddleSegSemi/
!pip3 install -r requirements.txt
!bash test_tipc/prepare.sh ./test_tipc/configs/advsemiseg_deeplabv2_res101_humanseg/train_infer_python.txt 'lite_train_lite_infer'
!bash test_tipc/test_train_inference_python.sh ./test_tipc/configs/advsemiseg_deeplabv2_res101_humanseg/train_infer_python.txt 'lite_train_lite_infer'
总结
在仅仅利用原数据集一部分labeled data的情况下,unlabeled data的加入使得性能提高,证明文中所提出的adversarial semi-supervised learning setting是很有效的。
但这篇论文也存在不足。比如判别器没有利用图像信息,这一点在后面的s4GAN(TPAMI,2019)中得到了优化。
后续将继续半监督语义分割方法的Paddle开源~
欢迎大家多多关注~

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)