
Paddle2.2复现经典论文Transformer(代码篇)
基于最新版Paddle2.2复现经典论文Transformer,在上一篇理论篇的基础上,结合torch和paddle官方的复现以及各位大佬的复现结果,模块化的完成本次代码的复现。
Paddle2.2复现经典论文Transformer(代码篇)
项目简介
经典图先放上
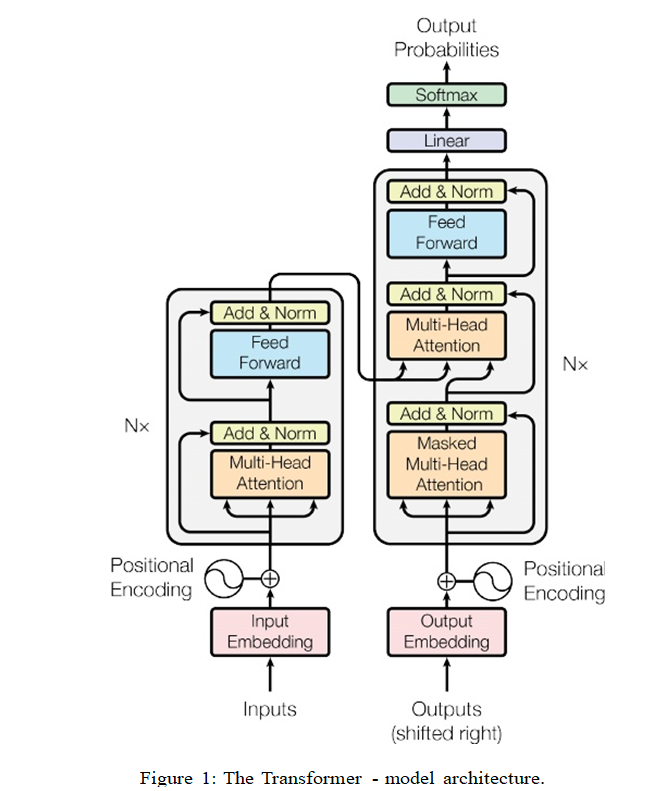
大多数人的复现的代码都是用py文件直接复现,我个人比较喜欢notebook直接写,这里直接用notebook开搞!
首先,从上一章理论篇看,我们要清楚的知道我们要复现什么东西
这里附上理论篇
此外,附上paddle2.0的api开发文档,很重要
(学习语言最重要的一个阶段,自己看文档)
- 简单的attention模块
- 多头注意力机制模块
- 编码层
- 解码层
- transformer实现
# 首先确保自己的paddle版本为2.2.0(2.0.0以上应该都可以)
import paddle
paddle.__version__
'2.2.0'
0 一键调用[官方案例]
复现完结

class paddle.nn.Transformer(d_model=512, nhead=8, num_encoder_layers=6, num_decoder_layers=6, dim_feedforward=2048, dropout=0.1, activation=‘relu’, attn_dropout=None, act_dropout=None, normalize_before=False, weight_attr=None, bias_attr=None, custom_encoder=None, custom_decoder=None)
Transformer模型
Transformer模型由一个 TransformerEncoder 实例和一个 TransformerDecoder 实例组成,不包含embedding层和输出层。
细节可参考论文 Attention is all you need 。
用户可以使用相应的参数配置模型结构。
请注意 normalize_before 的用法与某些类似Transformer的模型例如BERT和GPT2的用法不同,它表示在哪里(多头注意力机制或前馈神经网络的输入还是输出)进行层标准化(Layer Normalization)。
该模型默认的结构是对每个子层的output进行层归一化,并在最后一个编码器/解码器的输出上进行另一个层归一化操作。
import paddle
from paddle.nn import Transformer
# src: [batch_size, tgt_len, d_model]
enc_input = paddle.rand((2, 4, 128))
# tgt: [batch_size, src_len, d_model]
dec_input = paddle.rand((2, 6, 128))
# src_mask: [batch_size, n_head, src_len, src_len]
enc_self_attn_mask = paddle.rand((2, 2, 4, 4))
# tgt_mask: [batch_size, n_head, tgt_len, tgt_len]
dec_self_attn_mask = paddle.rand((2, 2, 6, 6))
# memory_mask: [batch_size, n_head, tgt_len, src_len]
cross_attn_mask = paddle.rand((2, 2, 6, 4))
transformer = Transformer(128, 2, 4, 4, 512)
output = transformer(enc_input,
dec_input,
enc_self_attn_mask,
dec_self_attn_mask,
cross_attn_mask)
# [2, 6, 128]
print(output)
Tensor(shape=[2, 6, 128], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[[[ 0.59077120, 1.43773937, -0.56857866, ..., -0.58212531,
0.58624023, 0.95627415],
[ 0.83392447, 1.34250939, -1.17657292, ..., 0.15285365,
0.13158791, 1.20099020],
[-0.16177787, 1.52969849, 0.21120685, ..., -0.80043119,
-0.04327450, 0.83480334],
[ 1.30470395, 0.43985128, 0.55893886, ..., -0.79290897,
0.29399759, 1.31741369],
[ 0.93303925, 1.05552018, 0.01188910, ..., -1.05249810,
1.38678491, 0.43440744],
[ 1.63166869, 0.48350155, 0.60118508, ..., -1.20537782,
1.29461861, 0.87831932]],
[[ 1.15072727, -0.71999460, -0.34327447, ..., 0.94961172,
-0.25767875, 0.23110202],
[ 0.12578741, 0.01706674, -0.23974656, ..., 0.78010756,
-0.33143252, 0.77478665],
[ 1.08981860, -0.62929344, -0.29936343, ..., -0.23698960,
0.06332687, 0.54342407],
[ 0.57272846, -0.07072425, 0.63095063, ..., -0.02150861,
0.26176050, 0.08369856],
[ 0.30658734, -0.49021766, 0.14039125, ..., -0.15796961,
0.10102152, -0.09494849],
[ 0.91549855, -1.19275117, -0.21476354, ..., 0.53557754,
-0.81377280, 0.62132072]]])
1 代码复现前置
先附上一篇pytorch的版本代码解读
大致理解一下代码
2 代码复现正式开始
先扔一堆包再说
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
import numpy as np
2.1 实现ScaledDotProductAttention
附上图方便对照

# 要实现多头注意力机制,就需要先实现Scaled Dot-Product Attention
# 这个在理论篇有提到
class ScaledDotProductAttention(nn.Layer):
"""
temp = d_k**0.5
attn_dropout 一般都是为0.1,记住即可,也可以自己改改看看变化
"""
def __init__(self, temp, attn_dropout=0.1):
super().__init__()
self.temp = temp
self.dropout = nn.Dropout(p=attn_dropout)
def forward(self, q, k, v, mask=None):
# 相乘前需要转置y
attn = paddle.matmul(q/self.temp, k, transpose_y=True)
if mask is not None:
attn = attn * mask
attn = self.dropout(F.softmax(attn, axis=-1))
output = paddle.matmul(attn, v)
return output, attn
2.2 实现MultiHeadAttention
# 借助于ScaledDotProductAttention,就可以开始实现多头自注意力模块
class MultiHeadAttention(nn.Layer):
"""
n_head 多头注意力机制的Head数量。 默认值:8
d_model 编码器和解码器的输入输出的维度。默认值:512。
d_k 键值对中key的维度
d_v 键值对中value的维度
dropout=0.1 注意力目标的随机失活率 默认一般都是0.1
"""
def __init__(self, n_head=8, d_model=512, d_k=None, d_v=None, dropout=0.1):
super().__init__()
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
# bias_attr 指定偏置参数属性的对象
self.w_qs = nn.Linear(d_model, n_head * d_k, bias_attr=False)
self.w_ks = nn.Linear(d_model, n_head * d_k, bias_attr=False)
self.w_vs = nn.Linear(d_model, n_head * d_v, bias_attr=False)
self.fc = nn.Linear(n_head * d_v, d_model, bias_attr=False)
self.attention = ScaledDotProductAttention(temp= d_k**0.5)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(d_model, epsilon=1e-5) # d_model: 需规范化的shape epsilon:指明在计算过程中是否添加较小的值到方差中以防止除零,paddle中一般都采用1e-5
def forward(self, q, k, v, mask=None):
"""
截选自paddle官方复现的解释
q :query (Tensor): The queries for multi-head attention. It is a
tensor with shape `[batch_size, query_length, embed_dim]`. The
data type should be float32 or float64.
k :key (Tensor): The keys for multi-head attention. It is
a tensor with shape `[batch_size, key_length, kdim]`. The
data type should be float32 or float64. If None, use `query` as
`key`.
v :value (Tensor): The values for multi-head attention. It
is a tensor with shape `[batch_size, value_length, vdim]`.
The data type should be float32 or float64. If None, use `query` as
`value`.
"""
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
"""
batch_size: batch_size
"""
batch_size, len_q, len_k, len_v = q.shape[0], q.shape[1], k.shape[1], v.shape[1]
residual = q
q = self.w_qs(q).reshape((batch_size, len_q, n_head, d_k))
k = self.w_ks(k).reshape((batch_size, len_k, n_head, d_k))
v = self.w_vs(v).reshape((batch_size, len_v, n_head, d_v))
q, k, v = q.transpose([0, 2, 1, 3]), k.transpose([0, 2, 1, 3]), v.transpose([0, 2, 1, 3])
if mask is not None:
mask = mask.unsqueeze(1)
q, attn = self.attention(q, k, v, mask=mask)
q = q.transpose([0, 2, 1, 3]).reshape((batch_size, len_q, -1))
q = self.dropout(self.fc(q))
q += residual
q = self.layer_norm(q)
return q, attn
2.3 PositionwiseForward实现
# 一个双馈前向层的模块
class PositionwiseForward(nn.Layer):
def __init__(self, d_in, d_hid, dropout=0.1):
super().__init__()
self.w_1 = nn.Linear(d_in, d_hid)
self.w_2 = nn.Linear(d_hid, d_in)
self.layer_norm = nn.LayerNorm(d_in, epsilon=1e-5) # d_in: 需规范化的shape epsilon:指明在计算过程中是否添加较小的值到方差中以防止除零,paddle中一般都采用1e-5
self.dropout = nn.Dropout(dropout)
def forward(self, x):
residual = x
x = self.w_2(F.relu(self.w_1(x)))
x = self.dropout(x)
x += residual
x = self.layer_norm(x)
return x
2.4 EncoderLayer编码层
# 拼凑两个层
# 第一层是MultiHeadAttention
# 第二层是PositionwiseForward
class EncoderLayer(nn.Layer):
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
super(EncoderLayer, self).__init__()
self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.pos_ffn = PositionwiseForward(d_model, d_inner, dropout=dropout)
def forward(self, enc_input, self_attn_mask=None):
enc_output, enc_self_attn = self.slf_attn(enc_input, enc_input, enc_input, mask=self_attn_mask)
enc_output = self.pos_ffn(enc_output)
return enc_output, enc_self_attn
2.6 DecoderLayer解码层
# 拼凑三个层
# 多头自注意力机制、编码-解码交叉注意力机制和前馈神经网络
class DecoderLayer(nn.Layer):
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.enc_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.pos_ffn = PositionwiseForward(d_model, d_inner, dropout=dropout)
def forward(self, dec_input, enc_output, self_attn_mask=None, dec_enc_attn_mask=None):
dec_output, dec_self_attn = self.self_attn(dec_input, dec_input, dec_input, mask=self_attn_mask)
dec_output, dec_enc_attn = self.enc_attn(dec_output, enc_output, enc_output, mask=dec_enc_attn_mask)
dec_output = self.pos_ffn(dec_output)
return dec_output, dec_self_attn, dec_enc_attn
2.7 PositionalEncoding实现
class PositionalEncoding(nn.Layer):
def __init__(self, d_hid, n_position=200):
super(PositionalEncoding, self).__init__()
# 动转静
self.register_buffer('pos_table', self._get_sin_encoding_table(n_position, d_hid))
# 采用正弦编码
def _get_sin_encoding_table(self, n_position, d_hid):
def get_position_angle_vec(position):
return [position / np.power(10000, 2 * (hid_j // 2) / d_hid) for hid_j in range(d_hid)]
sin_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)])
sin_table[:, 0::2] = np.sin(sin_table[:, 0::2]) # dim 2i
sin_table[:, 1::2] = np.cos(sin_table[:, 1::2]) # dim 2i+1
# unsqueeze 向输入Tensor的Shape中一个或多个位置(axis)插入尺寸为1的维度。
return paddle.to_tensor(sin_table, dtype='float32').unsqueeze(0)
def forward(self, x):
# paddle.cast 数据类型转换为 dtype 并输出
# detach() 返回一个新的 Variable , 并从当前计算图分离
return x + paddle.cast(self.pos_table[:, :x.shape[1]], dtype='float32').detach()
2.8 Encoder实现
class Encoder(nn.Layer):
"""
n_src_vocab=200 嵌入的词典的大小,
d_word_vec=20, 每个嵌入向量的维度
n_layers=6, encoderlayer的层数
n_head=2, 多头注意力机制的Head数量
d_k=10, 键值对中key的维度
d_v=10, 键值对中value的维度
d_model=20, 输入输出的维度
d_inner=10, 前馈神经网络中隐藏层的大小
pad_idx= 0, 如果配置了padding_idx,那么在训练过程中遇到此id时,其参数及对应的梯度将会以0进行填充
dropout=0.1,
n_position=200,
emb_weight=None
"""
def __init__(self, n_src_vocab=200, d_word_vec=20, n_layers=6, n_head=2,
d_k=10, d_v=10, d_model=20, d_inner=10, pad_idx= 0, dropout=0.1, n_position=200, emb_weight=None):
super().__init__()
self.src_word_emb = nn.Embedding(n_src_vocab, d_word_vec, sparse=True, padding_idx=pad_idx)
if emb_weight is not None:
self.src_word_emb.weight.set_value(emb_weight)
self.src_word_emb.stop_gradient=True
self.position_enc = PositionalEncoding(d_word_vec, n_position=n_position)
self.dropout = nn.Dropout(dropout)
self.layer_stack = nn.LayerList(
[
EncoderLayer(d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
for _ in range(n_layers)
]
)
self.layer_norm = nn.LayerNorm(d_model, epsilon=1e-5)
def forward(self, src_seq, src_mask, return_attns=False):
enc_slf_attn_list = []
print("src_seq:",src_seq.shape)
"""
embeding and positional encoding
"""
enc_output = self.dropout(self.position_enc(self.src_word_emb(src_seq)))
enc_output = self.layer_norm(enc_output)
"""
encoder layer
"""
for enc_layer in self.layer_stack:
enc_output, enc_slf_attn = enc_layer(enc_output, self_attn_mask=src_mask)
enc_slf_attn_list += [enc_slf_attn] if return_attns else []
if return_attns:
return enc_output, enc_slf_attn_list
return enc_output,
2.9 Decoder实现
class Decoder(nn.Layer):
def __init__(self, n_trg_vocab=200, d_word_vec=20, n_layers=6, n_head=2, d_k=10, d_v=10,
d_model=20, d_inner=10, pad_idx=0, dropout=0.1, n_position=200, emb_weight=None):
super().__init__()
self.trg_word_emb = nn.Embedding(n_trg_vocab, d_word_vec, padding_idx=pad_idx)
if emb_weight is not None:
self.trg_word_emb.weight.set_value(emb_weight)
self.trg_word_emb.stop_gradient=True
self.position_enc = PositionalEncoding(d_word_vec, n_position=n_position)
self.dropout = nn.Dropout(dropout)
self.layer_stack = nn.LayerList([
DecoderLayer(d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
for _ in range(n_layers)
])
self.layer_norm = nn.LayerNorm(d_model, epsilon=1e-5)
def forward(self, trg_seq, trg_mask, enc_output, src_mask, return_attns=False):
dec_self_attn_list, dec_enc_attn_list = [], []
dec_output = self.dropout(self.position_enc(self.trg_word_emb(trg_seq)))
dec_output = self.layer_norm(dec_output)
for dec_layer in self.layer_stack:
dec_output, dec_self_attn, dec_enc_attn = dec_layer(
dec_output, enc_output, self_attn_mask=trg_mask, dec_enc_attn_mask=src_mask
)
dec_self_attn_list += [dec_self_attn] if return_attns else []
dec_enc_attn_list += [dec_enc_attn] if return_attns else []
if return_attns:
return dec_output, dec_self_attn_list, dec_enc_attn_list
return dec_output,
2.10 Transformer实现
triu: 返回输入矩阵 input 的上三角部分,其余部分被设为0。 矩形的上三角部分被定义为对角线上和上方的元素。 如果diagonal = 0,表示主对角线; 如果diagonal是正数,表示主对角线之上的对角线;
triu() 介绍
import numpy as np
import paddle
data = np.arange(1, 13, dtype="int64").reshape(3,-1)
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
example 1, default diagonal
x = paddle.to_tensor(data)
triu1 = paddle.tensor.triu(x)
array([[ 1, 2, 3, 4],
[ 0, 6, 7, 8],
[ 0, 0, 11, 12]])
example 2, positive diagonal value
triu2 = paddle.tensor.triu(x, diagonal=2)
array([[0, 0, 3, 4],
[0, 0, 0, 8],
[0, 0, 0, 0]])
example 3, negative diagonal value
triu3 = paddle.tensor.triu(x, diagonal=-1)
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 0, 10, 11, 12]])
def get_pad_mask(seq, pad_idx):
return (seq != pad_idx).unsqueeze(-2)
def get_subsquent_mask(seq):
batch_size, len_s = seq.shape[0], seq.shape[1]
subsequent_mask = (1 - paddle.triu(paddle.ones((1, len_s, len_s)), diagonal=1))
return subsequent_mask
class Transformer(nn.Layer):
def __init__(
self, n_src_vocab, n_trg_vocab, src_pad_idx=0, trg_pad_idx=0,
d_word_vec=512, d_model=512, d_inner=2048,
n_layers=6, n_head=8, d_k=64, d_v=64, dropout=0.1, n_position=200,
src_emb_weight=None, trg_emb_weight=None,
trg_emd_prj_weight_sharing=True, emb_src_trg_weight_sharing=True,
):
super(Transformer, self).__init__()
self.src_pad_idx, self.trg_pad_idx = src_pad_idx, trg_pad_idx
self.encoder = Encoder(
n_src_vocab=n_src_vocab, pad_idx=src_pad_idx, d_word_vec=d_word_vec,
n_layers=n_layers, n_head=n_head, d_model=d_model, d_inner=d_inner,
d_k=d_k, d_v=d_v, dropout=dropout, n_position=n_position,
emb_weight=src_emb_weight)
self.decoder = Decoder(
n_trg_vocab=n_trg_vocab, pad_idx=trg_pad_idx, d_word_vec=d_word_vec,
n_layers=n_layers, n_head=n_head, d_model=d_model, d_inner=d_inner,
d_k=d_k, d_v=d_v, dropout=dropout, n_position=n_position,
emb_weight=trg_emb_weight)
self.trg_word_prj = nn.Linear(d_model, n_trg_vocab, bias_attr=False,
weight_attr=nn.initializer.XavierUniform())
for p in self.parameters():
if p.dim()>1:
print(p.shape)
nn.initializer.XavierUniform(p)
# 判断维度是否相等,残差链接的维度是相等的
assert d_model == d_word_vec, 'To facilitate the residual connections, the dimensions of all module outputs shall be the same'
self.x_logit_scale = 1.
if trg_emd_prj_weight_sharing:
weight = self.decoder.trg_word_emb.weight.numpy()
weight = np.transpose(weight)
self.trg_word_prj.weight.set_value(weight)
self.x_logit_scale= (d_model ** -0.5)
if emb_src_trg_weight_sharing:
weight = self.decoder.trg_word_emb.weight.numpy()
self.encoder.src_word_emb.weight.set_value(weight)
def forward(self, src_seq, trg_seq):
src_mask = get_pad_mask(src_seq, self.src_pad_idx)
trg_mask = get_pad_mask(trg_seq, self.trg_pad_idx).numpy().astype(bool) & get_subsquent_mask(trg_seq).numpy().astype(bool)
trg_mask = paddle.to_tensor(trg_mask)
print("trg_mask:",trg_mask.shape)
enc_output, *_ = self.encoder(src_seq, src_mask)
print("trg_seq,enc_output:",trg_seq.shape, enc_output.shape)
dec_output, *_ = self.decoder(trg_seq, trg_mask, enc_output, src_mask)
seq_logit= self.trg_word_prj(dec_output) * self.x_logit_scale
print("seq_logit:",seq_logit.shape)
return seq_logit.reshape((-1, seq_logit.shape[2]))
2.11 测试
import warnings
warnings.filterwarnings("ignore")
test_data = paddle.to_tensor(100*np.random.random((3, 10)), dtype='int64')
print("*"*30)
print(test_data)
print("*"*30)
enc = Encoder()
dec = Decoder()
transformer = Transformer(n_head=3, n_layers=6, src_pad_idx=0, trg_pad_idx=0, n_src_vocab=200, n_trg_vocab=200)
enc_output, *_ = enc(test_data, src_mask=None)
dec(test_data, trg_mask=None, enc_output=enc_output, src_mask=None)
t = transformer(test_data, test_data)
print("*"*30)
print(t)
print("*"*30)
输出如下:
******************************
Tensor(shape=[3, 10], dtype=int64, place=CUDAPlace(0), stop_gradient=True,
[[85, 26, 36, 67, 92, 20, 70, 88, 11, 53],
[50, 40, 41, 84, 97, 54, 56, 60, 4 , 1 ],
[7 , 88, 78, 86, 78, 52, 47, 97, 78, 59]])
******************************
[200, 512]
······
[192, 512]
[512, 2048]
[2048, 512]
[512, 200]
src_seq: [3, 10]
trg_mask: [3, 10, 10]
src_seq: [3, 10]
trg_seq,enc_output: [3, 10] [3, 10, 512]
seq_logit: [3, 10, 200]
******************************
Tensor(shape=[30, 200], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[[ 0. , -0.03738468, 0.03583783, ..., 0.04741157,
0.01163799, 0.02316635],
[ 0. , -0.02356138, 0.02180030, ..., 0.03975129,
0.00949559, 0.00014461],
[ 0. , -0.05990178, 0.01596778, ..., 0.03817972,
0.03274166, 0.01868936],
...,
[ 0. , -0.01956360, -0.00498928, ..., 0.02958385,
0.04553073, 0.02168844],
[ 0. , -0.01653445, -0.00395881, ..., 0.06549609,
0.03821198, 0.02369210],
[ 0. , -0.04679997, -0.03581379, ..., 0.00555599,
0.02214007, 0.04378328]])
******************************
总结
首先,要对论文的内容进行理解,如果实在不理解的地方,看官方的源码进行理解。
然后去看论文发布者的源码,多看几遍。
其实他们为了优化,很多代码我们是不需要做的,我们可以简化操作,可能精度不够,但跑起来才是关键。
还有多看别人的代码,抄会别人的也是自己的,关键在于自己理解了没有。学习阶段大可化敌为友,化别人的为自己的。
api文档要多看,真的要去多看看文档,不需要掌握每个接口但是需要自己牢记有哪些功能是不需要自己完成的,要在用的时候想的起来它可以做到。
回头再多看看复习复习
个人总结
全网同名: iterhui
我在AI Studio上获得钻石等级,点亮10个徽章,来互关呀~
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/643467

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)