
导盲赛道思路分享
转自AI Studio,原文链接:导盲赛道思路分享 - 飞桨AI Studio零、重要内容(注意事项):本项目不含任何剧透,没有透露任何网络改进所带来的具体收益,只是聊了一些我对这个赛事的看法,其中一些具体的措施能否起到效果,本人概不负责,不会对大赛评选起到内卷效果,请放心!!!!!!!绝不是因为我不惯某关系某民主某大学的某任工啥智能专业的所做所为。望周知一、赛题简介:一只导盲犬能够给
转自AI Studio,原文链接:导盲赛道思路分享 - 飞桨AI Studio
零、重要内容(注意事项):
本项目不含任何剧透,没有透露任何网络改进所带来的具体收益,只是聊了一些我对这个赛事的看法,其中一些具体的措施能否起到效果,本人概不负责,不会对大赛评选起到内卷效果,请放心!!!!!!!
绝不是因为我不惯某关系某民主某大学的某任工啥智能专业的所做所为。望周知
一、赛题简介:
一只导盲犬能够给盲人带来许多生活上的便利,但是导盲犬的培训周期长,费用高昂,因此,不是所有盲人能够拥有导盲犬,如果有机器狗代替导盲犬,将极大的造福盲人,此项比赛为智能导盲机器狗比赛,通过比赛来考评智能导盲机器狗的智能感知能力及综合运动性能,要求智能四足仿生机器人沿布置好的城市人行道场景走完全程并完成指定任务。
其实说起来高大上,当我们一句看到具体的任务的时候就会发现,其实就是一个非常简单的目标检测任务在出塞中,赛事组提供五种不同的目标让你去进行识别,但是为了服务于现实场景, 其在模型大小 以及检测速度等方面均提出了要求模型大小限制在200兆以内检测速度要求不低于20FPS。
二、思路分享:
那么这里,当时我就想到了三个思路,
- 一个的话,自然就是使用像是以mobilenet等为backbone的这种小模型 这种小模型它的好处自然就是不用考虑文件大小, 同时你的Baseline的速度也会很快,像是 有的模型,他可能只有几十兆然后他的IP还是可以飙到200甚至300以上,那么这个时候我就有很大的空间去,提升我的网络大小以及我的分辨率大小,那么这个其实就是一种加法。比如我可以在这之上去增加一些网络结构。例如通常的目标检测网络,他会在NECK当中增加一个结构叫做S P P。但是通常的网络中只会有一个这样的结构,但是由于你的网络十分小,同时FSP还是非常大,那么你就有很大的空间,你可以再增加两个S P P结构 这样你也完全不用担心你会触碰到赛事组设置的一些红线
- 另外一种就是选择一个比较大的模型,他可能是两百多兆 并且速度在20FPS上下, 那么这个时候,你就可以先训练出来一个不错的模型,然后再使用像是裁剪以及蒸馏这些外部措施, 在不改变网络结构的情况下,达到减重,增速的目的。但是,这种情况往往会带来一定的性能损失,通常情况下其可能 在增速一辈,降低50%的参数量的情况下,可能会减少1%的性能。 那么这时 你就要确保在你训练过程中你的原网络的成绩要比其他人的成绩要高出一截 这样啊,当你网络在经过裁剪后你的模型大小,以及检测速度在与他人相同的情况下,才能确保你的网络精度不弱于他人, 怎么这个其实就是一个单纯地减法。
- 最后一种是我比较推崇的,那么就是仍然找一个比较大的网络,然后先给你的网络进行一个减重, 像是PPYOLOv2 Backbone为ResNet-50_DCN的这种,他的检测速度差不多是满足要求,但是他的网络大小超过了200兆,那么这个时候,我们就可以考虑给他的Backbone进行一个减重 比如我们可以将CSP结构应用于PPYOLO的bakcbone当中,这样 就可以满足模型大小,限制在200兆以内, 当网络大小确定后, 接下来我们就可以考虑提速的事情了。首先我们最直接的方法就是将网络的输入分辨率降低,比如320x320,那么这样就两者都可满足了。
三、数据查看:
在我的初中和高中的生物课堂中,生物老师往往告诉我一个事情就是,一个好的实验材料往往能够在实验中起到关键性作用。无数足矣载入史册的实验中,首先是需要一个好的实验材料。 那么在机器学习以及深度学习中,好的数据及往往是一个数据分布均匀,种类繁多,能够反映真实情况的数据。 那么首先就先让我们来看一看,到忙的这个数据是否是一个比较好的数据集。
In [ ]
## 解压文件夹
!tar -zxvf data/data137625/WisdomGuide.tar.gz
## 安装所需环境
!pip install pycocotoolsIn [ ]
from pycocotools.coco import COCO
# 查看train数据分布
annFile='WisdomGuide/annotations/instance_train.json'
coco=COCO(annFile)
training_data= {}
cats = coco.loadCats(coco.getCatIds())
cat_nms=[cat['name'] for cat in cats]
print('-'*10,"training data",'-'*10)
for cat_name in cat_nms:
catId = coco.getCatIds(catNms=[cat_name])
imgId = coco.getImgIds(catIds=catId)
annId = coco.getAnnIds(imgIds=imgId, catIds=catId, iscrowd=None)
training_data[cat_name] = len(imgId), len(annId)
print("{:<15} {:<6d} {:<10d}".format(cat_name, len(imgId), len(annId)))
print(training_data)
# 查看val数据分布
annFile='WisdomGuide/annotations/instance_val.json'
coco=COCO(annFile)
cats = coco.loadCats(coco.getCatIds())
val_data = {}
cat_nms=[cat['name'] for cat in cats]
print('-'*10,"valuation data",'-'*10)
for cat_name in cat_nms:
catId = coco.getCatIds(catNms=[cat_name])
imgId = coco.getImgIds(catIds=catId)
annId = coco.getAnnIds(imgIds=imgId, catIds=catId, iscrowd=None)
val_data[cat_name] = (len(imgId), len(annId))
print("{:<15} {:<6d} {:<10d}".format(cat_name, len(imgId), len(annId)))你是否觉得不够直观那么接下来我们用饼状图的形式来进行演示。
In [ ]
import matplotlib.pyplot as plt
name = [x for x in training_data.keys()]
train_imgid = [training_data[name[x]][0] for x in range(len(name))]
train_annid = [training_data[name[x]][1] for x in range(len(name))]
val_imgid = [val_data[name[x]][0] for x in range(len(name))]
val_annid = [val_data[name[x]][1] for x in range(len(name))]
plt.figure(figsize=(6,6))#将画布设定为正方形,则绘制的饼图是正圆
values = train_imgid
label = name
explode = [0.01,0.01,0.01,0.01,0.01]
patches,l_text,p_text = plt.pie(values,explode=explode,labels=label,autopct='%1.2f%%')
plt.suptitle('train_imgid',fontsize=16,y=0.93)
plt.legend(bbox_to_anchor=(-0.04, 1),borderaxespad=0,frameon=False)
plt.show()
plt.figure(figsize=(6,6))
values = train_annid
label = name
explode = [0.01,0.01,0.01,0.01,0.01]
patches,l_text,p_text = plt.pie(values,explode=explode,labels=label,autopct='%1.2f%%')
plt.suptitle('train_annid',fontsize=16,y=0.93)
plt.legend(bbox_to_anchor=(-0.04, 1),borderaxespad=0,frameon=False)
plt.show()
plt.figure(figsize=(6,6))
values = val_imgid
label = name
explode = [0.01,0.01,0.01,0.01,0.01]
patches,l_text,p_text = plt.pie(values,explode=explode,labels=label,autopct='%1.2f%%')
plt.suptitle('val_imgid',fontsize=16,y=0.93)
plt.legend(bbox_to_anchor=(-0.04, 1),borderaxespad=0,frameon=False)
plt.show()
plt.figure(figsize=(6,6))
values = val_annid
label = name
explode = [0.01,0.01,0.01,0.01,0.01]
patches,l_text,p_text = plt.pie(values,explode=explode,labels=label,autopct='%1.2f%%')
plt.suptitle('val_annid',fontsize=16,y=0.93)
plt.legend(bbox_to_anchor=(-0.04, 1),borderaxespad=0,frameon=False)
plt.show()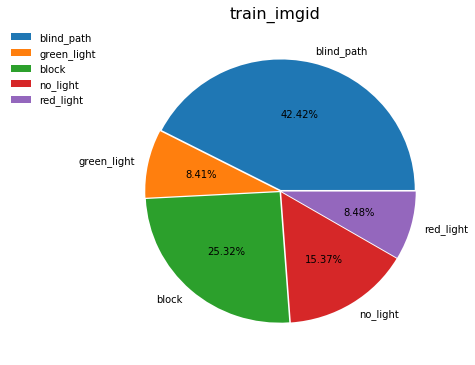
<Figure size 432x432 with 1 Axes>
<Figure size 432x432 with 1 Axes>
<Figure size 432x432 with 1 Axes>
<Figure size 432x432 with 1 Axes>
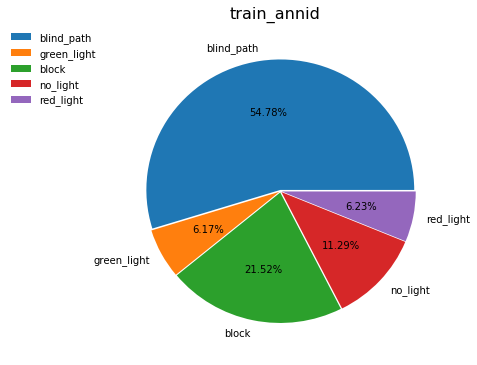
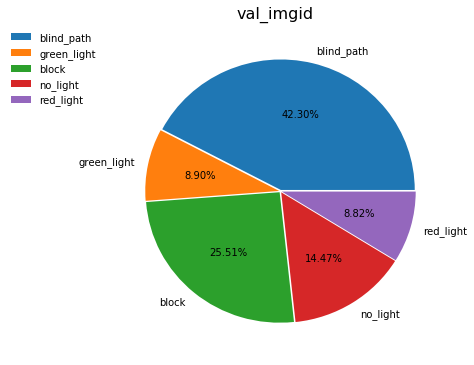
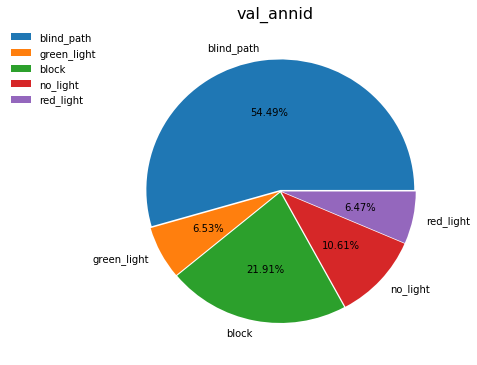
通过饼状图,我们可以发现这是一个不均匀分布的数据集
数据集总共分为五类:盲道、红绿灯(红灯状态)、红绿灯(绿灯状态)、红绿灯(不亮灯状态)、障碍物
其实是有三个大分类——盲道,红绿灯以及障碍物, 其中红绿灯又能被细分为三类分别为红灯,绿灯以及不亮灯。所幸他所需要识别的物体,其实算是比较少的。如果像是这种数据的话,其实还有另外一种说法是密度分类或者叫做多类别分类识别, 比如你首先要识别出来,他是哪种动物像是猫或狗或蛇,然后你又要去细分它的种类,比如比格拉布拉多斗牛,或是暹罗,埃及,、加菲。。当然,那两种识别又是一个更高的领域。在这里,我们并不进行描述。
个人觉得这个数据其实已经是非常不错的,首先他是一个扫盲说自己吗,所以说他大部分的时间肯定是需要去看盲道, 所以他的忙到我的数据只能够占55%左右,剩下的红绿灯和障碍物大概五五分成, 就是有一点我不太明白,为什么没有灯的占了其中的一半,有灯的占了另一半呢,难道现在大街上的红绿灯大多数都是没有灯吗?
四、思路细讲:
- 思路一你可以去找一个不错的网络像是Picodet然后再去找一些trick一点点加只要模型不超过200兆,速度不低于20fps,你就可以无限的去增加trick提升网络精度。但是有一个问题就是像是Picodet 它就是由一群trick叠加而成,那么你去找什么trick在一个原本就很好的网络上去提升精度呢呢?
- 思路二 建议你去找一个速度比较快的单阶段检测模型,因为如果是双阶段检测模型,可能经过裁剪之后你的模型大小达标但是你的速度可能还是无法达标。
- 思路三 第三种是我在做的方向下面我就跟大家来说说我我认为的思路三应该怎么做。
Backbone
在考虑是否对Backbone进行动刀前你应该先考虑清楚你是否有足够的机器或者算力,因为你一旦选择对Backbone动刀就意味着你将失去一个预训练模型,你必须要自己再在Imagenet上去训练一个不错的预训练模型,请注意一定是要不错的预训练模型,因为如果你的预训练模型较差那么你的网络很有可能无法收敛更不要提所谓的达到一个不错的精度了。
如果是像是PPYOLOv2一样没有使用过CSP结构的网络可以直接将CSP结构拿过来使用,CSP结构能够降低网络参数量,在减重的同时还能达到提速的效果,至于精度,论文中说的是能提升精度的哈。要是不能提升我这里也不负责呀,一切情况以实物为准
如果是PPYOLOE就比较尴尬了,因为在PPYOLOE中虽然使用了CSP结构,但是很尴尬的是PPYOLOE也和咱们的思路一样就是先减重然后再增重,结果就是虽然使用了CSP结构但是模型大小反而也没怎么减少但是精度提高了,那么这就比较尴尬了,那么这个时候我们应该怎么找一个比PPYOLOE中 CSPRegResNet精度还高速度更快或者最起码差不多,然后参数还要少的Backbone呢? 所以这里其实就是一个比较尴尬的点了。如果看过我那个给大核卷积提速项目的同学可能知道我是使用CSPConvNeXt平替,但是尴尬的是我的CSPConvNeXt在Iamgenet中也只有78.5,不说和ConvNeXt的82.1相差甚远甚至连CSPRegResNet的79.5也有一个点的差距,然后CSPCOnvNeXt网络还有一个问题就是难以训练,具体来说可以去看一下我的那个给大核卷积提速的项目, 简单一句话来说,就是我并没有找到一个合适的训练策略,去激发CSPResNet的所有潜能,但是一方面我自己没有机器然后ai studio 4卡训练一直报错提了issue也没有解决。因此这方面我也暂时搁置了。
Neck
对neck动刀就不会像是Backbone那么难受了你可以随意去改变那么第一个我想到的就是SPPF去替代SPP
SPPF 与 SPP
简单介绍一下SPPF SPPF就是使用三个5x5的maxpool层代替 原本的SPP结构,SPPF结构与SPP结构结果相同但是所用时间大大减少
下面我们先做一个小实验,来对比SPPF与SPP的所用时间
In [35]
import paddle
import paddle.nn as nn
import time
paddle.device.set_device("cpu")
class SPP(nn.Layer):
def __init__(self):
super().__init__()
self.maxpool1 = nn.MaxPool2D(5,1,padding=2)
self.maxpool2 = nn.MaxPool2D(9,1,padding=4)
self.maxpool3 = nn.MaxPool2D(13,1,padding=6)
def forward(self, x):
p = x
o1 = self.maxpool1(x)
o2 = self.maxpool2(x)
o3 = self.maxpool3(x)
return paddle.concat([x,o1,o2,o3],axis=1)
class SPPF(nn.Layer):
def __init__(self):
super().__init__()
self.maxpool = nn.MaxPool2D(5, 1, padding=2)
def forward(self, x):
o1 = self.maxpool(x)
o2 = self.maxpool(o1)
o3 = self.maxpool(o2)
return paddle.concat([x, o1, o2, o3], axis=1)
def main():
input_tensor = paddle.rand((8, 32, 16, 16))
spp = SPP()
sppf = SPPF()
output1 = spp(input_tensor)
output2 = sppf(input_tensor)
# print(paddle.equal(output1, output2))
t_start = time.time()
for _ in range(100):
spp(input_tensor)
print(f"spp time: {time.time() - t_start}")
t_start = time.time()
for _ in range(100):
sppf(input_tensor)
print(f"sppf time: {time.time() - t_start}")
if __name__ == '__main__':
main()spp time: 1.2195651531219482 sppf time: 0.43102502822875977
可以看到SPPF所用时间几乎是SPP结构的三分之一,那么我们就可以将一个SPP结构平替称为三个SPPF结构,相当于用一个SPP结构的时间,达到了使用三个SPP才能达到的效果。
PAN结构优化
在PPYOLOE论文当中Backbone和Neck的改进被归为一类,这是因为PPYOLOE中的所有block结构都是使用统一的CSPVggResNetStage,所以如果是PPYOLOv2的话可以直接将Block更换为CSPBlock也能一定程度的减少参数量。然后PPYOLOE的话情况特殊,请自行思考。
import matplotlib.pyplot as plt请点击此处查看本环境基本用法.
Please click here for more detailed instructions.

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)