
基于监督学习的 AI 图像恢复模型 CMFNet
“转自AI Studio,原文链接:https://aistudio.baidu.com/aistudio/projectdetail/3732305”引入图像恢复,即将有缺陷的图像通过各种方法进行修复还原常见的图像恢复有:降噪,去模糊,去雾,去雨水等等本次就介绍一个基于监督学习的 AI 图像恢复模型 CMFNetCMFNet 通过同一个模型架构,根据学习的不同类型的成对图像(有缺陷 / 没缺陷)
“转自AI Studio,原文链 接:https://aistudio.baidu.com/aistudio/projectdetail/3732305”
引入
图像恢复,即将有缺陷的图像通过各种方法进行修复还原
常见的图像恢复有:降噪,去模糊,去雾,去雨水等等
本次就介绍一个基于监督学习的 AI 图像恢复模型 CMFNet
CMFNet 通过同一个模型架构,根据学习的不同类型的成对图像(有缺陷 / 没缺陷)实现了去模糊,去雾,去雨水等不同的图像恢复功能
参考资料
论文:COMPOUND MULTI-BRANCH FEATURE FUSION FOR REAL IMAGE RESTORATION
代码:FanChiMao/CMFNet
恢复效果
模糊去除

雾霾去除


雨水去除
 模型架构
模型架构
CMFNet 整体架构:
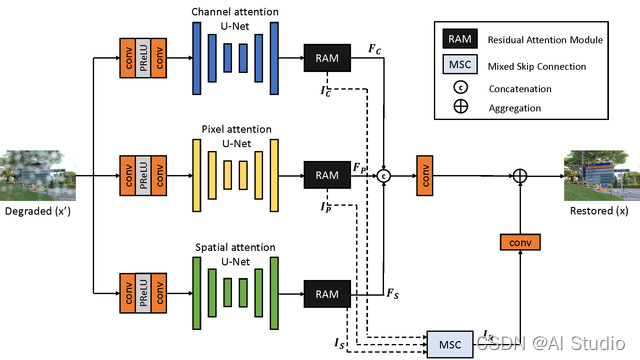 主要思想:
主要思想:
1.用简单的块结构将多个复杂块叠加到多个分支中,分离出不同的注意特征。(即上图中的三个 U-Net 结构,三个 U-Net 使用不同的注意力模块,示意图如下)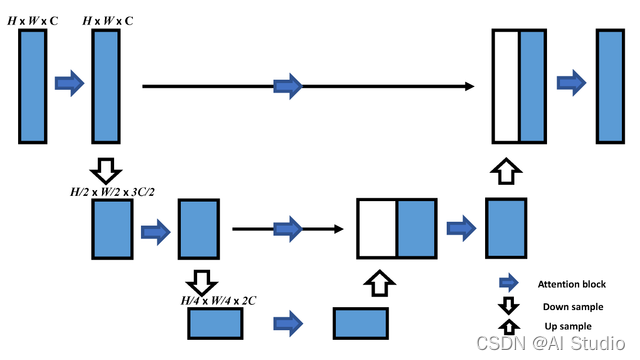
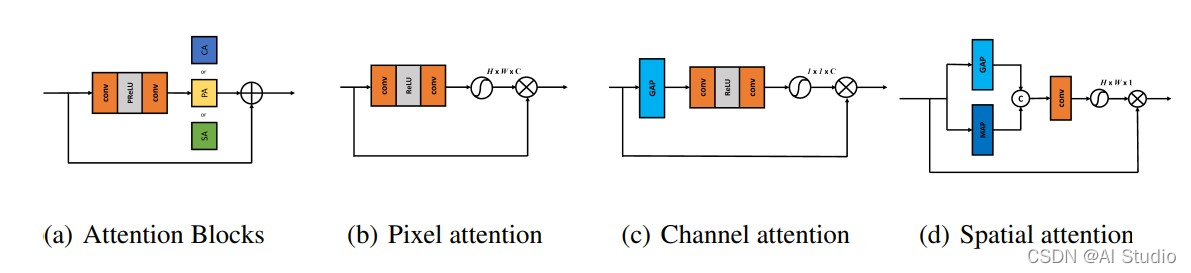
2.使用 Waqas Zamir等人 (2021) 提出的监督注意模块 (SAM) 来提高性能。还消除了 SAM 输出图像与地面真实图像之间的监督损耗,因为作者认为它会限制网络的学习。(即上图中的 RAM 准确讲应该叫做修改版的 Supervised Attention Module 来自文章 【Multi-Stage Progressive Image Restoration】,和另一篇文章 【Residual Attention Network for Image Classification】的中提到的 RAM 不太一样,原版 SAM 示意图如下)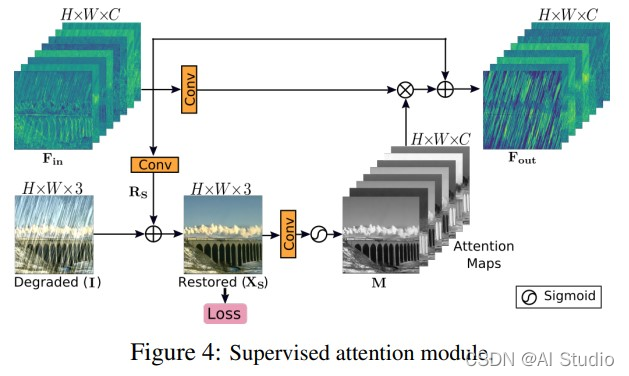
3.提出了一种混合跳跃连接 (MSC),将传统的残差连接替换为一个可学习的常数,使得残差学习在不同的恢复任务下更加灵活。(即上图中的 MSC,示意图如下)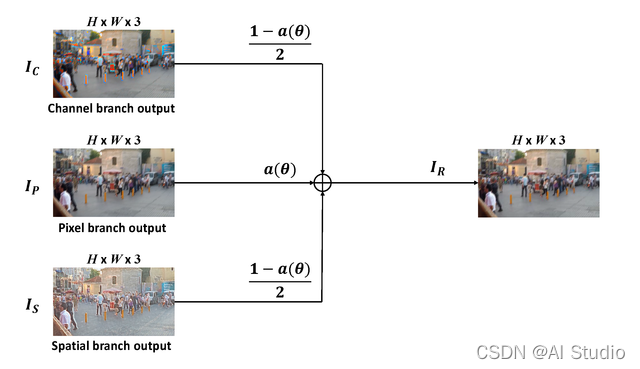
代码实现
基础模块
In [1]
import paddle
import paddle.nn as nn
def conv(in_channels, out_channels, kernel_size, bias_attr=False, stride=1):
layer = nn.Conv2D(in_channels, out_channels, kernel_size, padding=(kernel_size // 2), bias_attr=bias_attr, stride=stride)
return layer
注意力模块
Spatial Attention Block (SAB)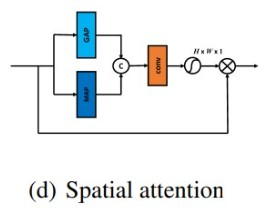
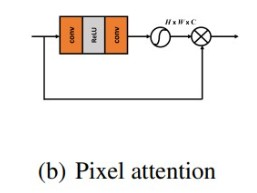
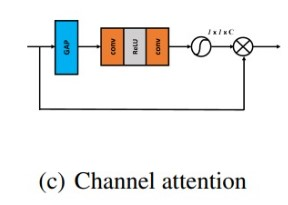
Pixel Attention Block (PAB)# Channel Attention Block (CAB)
In [2]
##########################################################################
Spatial Attention
class SALayer(nn.Layer):
def init(self, kernel_size=7):
super(SALayer, self).init()
self.conv1 = nn.Conv2D(2, 1, kernel_size, padding=kernel_size // 2, bias_attr=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = paddle.mean(x, axis=1, keepdim=True)
max_out = paddle.max(x, axis=1, keepdim=True)
y = paddle.concat([avg_out, max_out], axis=1)
y = self.conv1(y)
y = self.sigmoid(y)
return x * y
Spatial Attention Block (SAB)
class SAB(nn.Layer):
def init(self, n_feat, kernel_size, reduction, bias_attr, act):
super(SAB, self).init()
modules_body = [conv(n_feat, n_feat, kernel_size, bias_attr=bias_attr), act, conv(n_feat, n_feat, kernel_size, bias_attr=bias_attr)]
self.body = nn.Sequential(*modules_body)
self.SA = SALayer(kernel_size=7)
def forward(self, x):
res = self.body(x)
res = self.SA(res)
res += x
return res
##########################################################################
Pixel Attention
class PALayer(nn.Layer):
def init(self, channel, reduction=16, bias_attr=False):
super(PALayer, self).init()
self.pa = nn.Sequential(
nn.Conv2D(channel, channel // reduction, 1, padding=0, bias_attr=bias_attr),
nn.ReLU(),
nn.Conv2D(channel // reduction, channel, 1, padding=0, bias_attr=bias_attr), # channel <-> 1
nn.Sigmoid()
)
def forward(self, x):
y = self.pa(x)
return x * y
Pixel Attention Block (PAB)
class PAB(nn.Layer):
def init(self, n_feat, kernel_size, reduction, bias_attr, act):
super(PAB, self).init()
modules_body = [conv(n_feat, n_feat, kernel_size, bias_attr=bias_attr), act, conv(n_feat, n_feat, kernel_size, bias_attr=bias_attr)]
self.PA = PALayer(n_feat, reduction, bias_attr=bias_attr)
self.body = nn.Sequential(*modules_body)
def forward(self, x):
res = self.body(x)
res = self.PA(res)
res += x
return res
##########################################################################
Channel Attention Layer
class CALayer(nn.Layer):
def init(self, channel, reduction=16, bias_attr=False):
super(CALayer, self).init()
# global average pooling: feature --> point
self.avg_pool = nn.AdaptiveAvgPool2D(1)
# feature channel downscale and upscale --> channel weight
self.conv_du = nn.Sequential(
nn.Conv2D(channel, channel // reduction, 1, padding=0, bias_attr=bias_attr),
nn.ReLU(),
nn.Conv2D(channel // reduction, channel, 1, padding=0, bias_attr=bias_attr),
nn.Sigmoid()
)
def forward(self, x):
y = self.avg_pool(x)
y = self.conv_du(y)
return x * y
Channel Attention Block (CAB)
class CAB(nn.Layer):
def init(self, n_feat, kernel_size, reduction, bias_attr, act):
super(CAB, self).init()
modules_body = [conv(n_feat, n_feat, kernel_size, bias_attr=bias_attr), act, conv(n_feat, n_feat, kernel_size, bias_attr=bias_attr)]
self.CA = CALayer(n_feat, reduction, bias_attr=bias_attr)
self.body = nn.Sequential(*modules_body)
def forward(self, x):
res = self.body(x)
res = self.CA(res)
res += x
return res
图像缩放模块
DownSample:下采样
UpSample:上采样
SkipUpSample:上采样 + 跳跃连接(Skip Connect)
In [3]
##########################################################################
##---------- Resizing Modules ----------
class DownSample(nn.Layer):
def init(self, in_channels, s_factor):
super(DownSample, self).init()
self.down = nn.Sequential(nn.Upsample(scale_factor=0.5, mode=‘bilinear’, align_corners=False),
nn.Conv2D(in_channels, in_channels + s_factor, 1, stride=1, padding=0, bias_attr=False))
def forward(self, x):
x = self.down(x)
return x
class UpSample(nn.Layer):
def init(self, in_channels, s_factor):
super(UpSample, self).init()
self.up = nn.Sequential(nn.Upsample(scale_factor=2, mode=‘bilinear’, align_corners=False),
nn.Conv2D(in_channels + s_factor, in_channels, 1, stride=1, padding=0, bias_attr=False))
def forward(self, x):
x = self.up(x)
return x
class SkipUpSample(nn.Layer):
def init(self, in_channels, s_factor):
super(SkipUpSample, self).init()
self.up = nn.Sequential(nn.Upsample(scale_factor=2, mode=‘bilinear’, align_corners=False),
nn.Conv2D(in_channels + s_factor, in_channels, 1, stride=1, padding=0, bias_attr=False))
def forward(self, x, y):
x = self.up(x)
x = x + y
return x
U-Net
使用对称的 Encoder 和 Decoder,对应层级之间相互连接: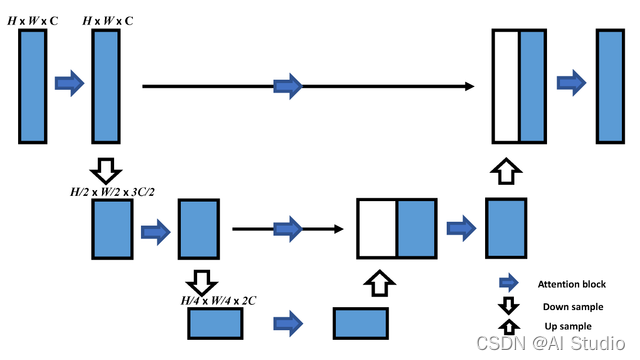 In [4]
In [4]
##########################################################################
U-Net
bn = 2 # block number-1
class Encoder(nn.Layer):
def init(self, n_feat, kernel_size, reduction, act, bias_attr, scale_unetfeats, block):
super(Encoder, self).init()
if block == ‘CAB’:
self.encoder_level1 = [CAB(n_feat, kernel_size, reduction, bias_attr=bias_attr, act=act) for _ in range(bn)]
self.encoder_level2 = [CAB(n_feat + scale_unetfeats, kernel_size, reduction, bias_attr=bias_attr, act=act) for _ in range(bn)]
self.encoder_level3 = [CAB(n_feat + (scale_unetfeats * 2), kernel_size, reduction, bias_attr=bias_attr, act=act) for _ in range(bn)]
elif block == ‘PAB’:
self.encoder_level1 = [PAB(n_feat, kernel_size, reduction, bias_attr=bias_attr, act=act) for _ in range(bn)]
self.encoder_level2 = [PAB(n_feat + scale_unetfeats, kernel_size, reduction, bias_attr=bias_attr, act=act) for _ in range(bn)]
self.encoder_level3 = [PAB(n_feat + (scale_unetfeats * 2), kernel_size, reduction, bias_attr=bias_attr, act=act) for _ in range(bn)]
elif block == ‘SAB’:
self.encoder_level1 = [SAB(n_feat, kernel_size, reduction, bias_attr=bias_attr, act=act) for _ in range(bn)]
self.encoder_level2 = [SAB(n_feat + scale_unetfeats, kernel_size, reduction, bias_attr=bias_attr, act=act) for _ in range(bn)]
self.encoder_level3 = [SAB(n_feat + (scale_unetfeats * 2), kernel_size, reduction, bias_attr=bias_attr, act=act) for _ in range(bn)]
self.encoder_level1 = nn.Sequential(*self.encoder_level1)
self.encoder_level2 = nn.Sequential(*self.encoder_level2)
self.encoder_level3 = nn.Sequential(*self.encoder_level3)
self.down12 = DownSample(n_feat, scale_unetfeats)
self.down23 = DownSample(n_feat + scale_unetfeats, scale_unetfeats)
def forward(self, x):
enc1 = self.encoder_level1(x)
x = self.down12(enc1)
enc2 = self.encoder_level2(x)
x = self.down23(enc2)
enc3 = self.encoder_level3(x)
return [enc1, enc2, enc3]
class Decoder(nn.Layer):
def init(self, n_feat, kernel_size, reduction, act, bias_attr, scale_unetfeats, block):
super(Decoder, self).init()
if block == ‘CAB’:
self.decoder_level1 = [CAB(n_feat, kernel_size, reduction, bias_attr=bias_attr, act=act) for _ in range(bn)]
self.decoder_level2 = [CAB(n_feat + scale_unetfeats, kernel_size, reduction, bias_attr=bias_attr, act=act) for _ in range(bn)]
self.decoder_level3 = [CAB(n_feat + (scale_unetfeats * 2), kernel_size, reduction, bias_attr=bias_attr, act=act) for _ in range(bn)]
elif block == ‘PAB’:
self.decoder_level1 = [PAB(n_feat, kernel_size, reduction, bias_attr=bias_attr, act=act) for _ in range(bn)]
self.decoder_level2 = [PAB(n_feat + scale_unetfeats, kernel_size, reduction, bias_attr=bias_attr, act=act) for _ in range(bn)]
self.decoder_level3 = [PAB(n_feat + (scale_unetfeats * 2), kernel_size, reduction, bias_attr=bias_attr, act=act) for _ in range(bn)]
elif block == ‘SAB’:
self.decoder_level1 = [SAB(n_feat, kernel_size, reduction, bias_attr=bias_attr, act=act) for _ in range(bn)]
self.decoder_level2 = [SAB(n_feat + scale_unetfeats, kernel_size, reduction, bias_attr=bias_attr, act=act) for _ in range(bn)]
self.decoder_level3 = [SAB(n_feat + (scale_unetfeats * 2), kernel_size, reduction, bias_attr=bias_attr, act=act) for _ in range(bn)]
self.decoder_level1 = nn.Sequential(*self.decoder_level1)
self.decoder_level2 = nn.Sequential(*self.decoder_level2)
self.decoder_level3 = nn.Sequential(*self.decoder_level3)
if block == ‘CAB’:
self.skip_attn1 = CAB(n_feat, kernel_size, reduction, bias_attr=bias_attr, act=act)
self.skip_attn2 = CAB(n_feat + scale_unetfeats, kernel_size, reduction, bias_attr=bias_attr, act=act)
if block == ‘PAB’:
self.skip_attn1 = PAB(n_feat, kernel_size, reduction, bias_attr=bias_attr, act=act)
self.skip_attn2 = PAB(n_feat + scale_unetfeats, kernel_size, reduction, bias_attr=bias_attr, act=act)
if block == ‘SAB’:
self.skip_attn1 = SAB(n_feat, kernel_size, reduction, bias_attr=bias_attr, act=act)
self.skip_attn2 = SAB(n_feat + scale_unetfeats, kernel_size, reduction, bias_attr=bias_attr, act=act)
self.up21 = SkipUpSample(n_feat, scale_unetfeats)
self.up32 = SkipUpSample(n_feat + scale_unetfeats, scale_unetfeats)
def forward(self, outs):
enc1, enc2, enc3 = outs
dec3 = self.decoder_level3(enc3)
x = self.up32(dec3, self.skip_attn2(enc2))
dec2 = self.decoder_level2(x)
x = self.up21(dec2, self.skip_attn1(enc1))
dec1 = self.decoder_level1(x)
return [dec1, dec2, dec3]
SAM 模块
Supervised Attention Module(去除了原版图中的 Loss,并且调整了其中卷积的核大小):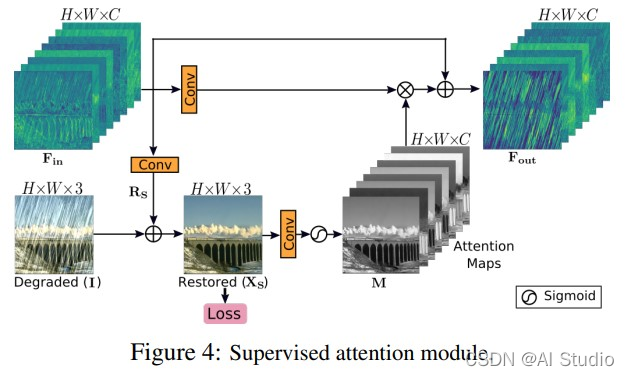
In [5]
##########################################################################
Supervised Attention Module
class SAM(nn.Layer):
def init(self, n_feat, kernel_size, bias_attr):
super(SAM, self).init()
self.conv1 = conv(n_feat, n_feat, kernel_size, bias_attr=bias_attr)
self.conv2 = conv(n_feat, 3, kernel_size, bias_attr=bias_attr)
self.conv3 = conv(3, n_feat, kernel_size, bias_attr=bias_attr)
def forward(self, x, x_img):
x1 = self.conv1(x)
img = self.conv2(x) + x_img
x2 = nn.functional.sigmoid(self.conv3(img))
x1 = x1 * x2
x1 = x1 + x
return x1, img
MSC 模块
Mixed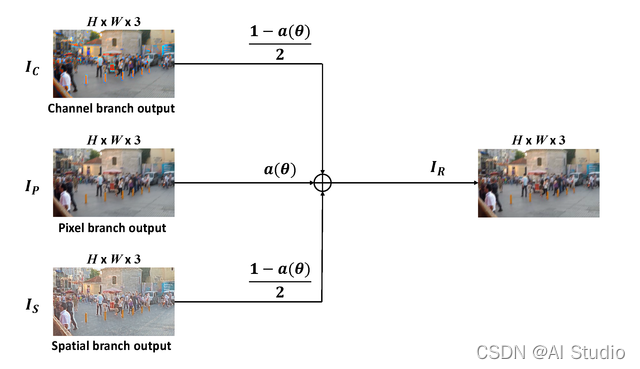
Residual Module
In [6]
##########################################################################
Mixed Residual Module
class Mix(nn.Layer):
def init(self, m=1):
super(Mix, self).init()
self.w = self.create_parameter((1,), default_initializer=nn.initializer.Constant(m))
self.mix_block = nn.Sigmoid()
def forward(self, fea1, fea2, feat3):
factor = self.mix_block(self.w)
other = (1 - factor)/2
output = fea1 * other + fea2 * factor + feat3 * other
return output, factor
CMFNet 模型
上述的多个模块拼接一下即可搭建出完整的 CMFNet: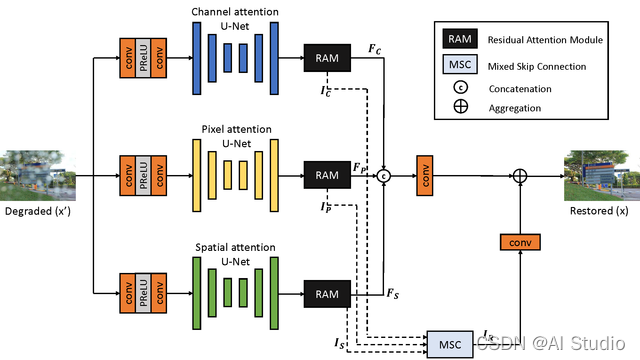
In [7]
##########################################################################
CMFNet
class CMFNet(nn.Layer):
def init(self, in_c=3, out_c=3, n_feat=96, scale_unetfeats=48, kernel_size=3, reduction=4, bias_attr=False):
super(CMFNet, self).init()
p_act = nn.PReLU()
self.shallow_feat1 = nn.Sequential(conv(in_c, n_feat // 2, kernel_size, bias_attr=bias_attr), p_act,
conv(n_feat // 2, n_feat, kernel_size, bias_attr=bias_attr))
self.shallow_feat2 = nn.Sequential(conv(in_c, n_feat // 2, kernel_size, bias_attr=bias_attr), p_act,
conv(n_feat // 2, n_feat, kernel_size, bias_attr=bias_attr))
self.shallow_feat3 = nn.Sequential(conv(in_c, n_feat // 2, kernel_size, bias_attr=bias_attr), p_act,
conv(n_feat // 2, n_feat, kernel_size, bias_attr=bias_attr))
self.stage1_encoder = Encoder(n_feat, kernel_size, reduction, p_act, bias_attr, scale_unetfeats, 'CAB')
self.stage1_decoder = Decoder(n_feat, kernel_size, reduction, p_act, bias_attr, scale_unetfeats, 'CAB')
self.stage2_encoder = Encoder(n_feat, kernel_size, reduction, p_act, bias_attr, scale_unetfeats, 'PAB')
self.stage2_decoder = Decoder(n_feat, kernel_size, reduction, p_act, bias_attr, scale_unetfeats, 'PAB')
self.stage3_encoder = Encoder(n_feat, kernel_size, reduction, p_act, bias_attr, scale_unetfeats, 'SAB')
self.stage3_decoder = Decoder(n_feat, kernel_size, reduction, p_act, bias_attr, scale_unetfeats, 'SAB')
self.sam1o = SAM(n_feat, kernel_size=3, bias_attr=bias_attr)
self.sam2o = SAM(n_feat, kernel_size=3, bias_attr=bias_attr)
self.sam3o = SAM(n_feat, kernel_size=3, bias_attr=bias_attr)
self.mix = Mix(1)
self.add123 = conv(out_c, out_c, kernel_size, bias_attr=bias_attr)
self.concat123 = conv(n_feat*3, n_feat, kernel_size, bias_attr=bias_attr)
self.tail = conv(n_feat, out_c, kernel_size, bias_attr=bias_attr)
def forward(self, x):
## Compute Shallow Features
shallow1 = self.shallow_feat1(x)
shallow2 = self.shallow_feat2(x)
shallow3 = self.shallow_feat3(x)
## Enter the UNet-CAB
x1 = self.stage1_encoder(shallow1)
x1_D = self.stage1_decoder(x1)
## Apply SAM
x1_out, x1_img = self.sam1o(x1_D[0], x)
## Enter the UNet-PAB
x2 = self.stage2_encoder(shallow2)
x2_D = self.stage2_decoder(x2)
## Apply SAM
x2_out, x2_img = self.sam2o(x2_D[0], x)
## Enter the UNet-SAB
x3 = self.stage3_encoder(shallow3)
x3_D = self.stage3_decoder(x3)
## Apply SAM
x3_out, x3_img = self.sam3o(x3_D[0], x)
## Aggregate SAM features of Stage 1, Stage 2 and Stage 3
mix_r = self.mix(x1_img, x2_img, x3_img)
mixed_img = self.add123(mix_r[0])
## Concat SAM features of Stage 1, Stage 2 and Stage 3
concat_feat = self.concat123(paddle.concat([x1_out, x2_out, x3_out], 1))
x_final = self.tail(concat_feat)
return x_final + mixed_img
模型推理
模型推理相对讲算是很简单
功能函数
加载模型
图像预处理
结果后处理
模型推理
In [8]
import cv2
from IPython.display import Image, display
def load_model(model_path):
model = CMFNet()
model.eval()
params = paddle.load(model_path)
model.set_state_dict(params)
return model
def preprocess(img):
clip_h, clip_w = [_ % 4 if _ % 4 else None for _ in img.shape[:2]]
x = img[None, :clip_h, :clip_w, ::-1]
x = x.transpose(0, 3, 1, 2)
x = x.astype(‘float32’)
x /= 255.0
x = paddle.to_tensor(x)
return x
def postprocess(y):
y = y.numpy()
y = y.clip(0.0, 1.0)
y *= 255.0
y = y.transpose(0, 2, 3, 1)
y = y.astype(‘uint8’)
y = y[0, :, :, ::-1]
return y
@paddle.no_grad()
def run(model, img_path, save_path):
img = cv2.imread(img_path)
x = preprocess(img)
y = model(x)
deimg = postprocess(y)
cv2.imwrite(save_path, deimg)
return deimg
def show(img_path, save_path):
display(Image(img_path))
display(Image(save_path))
去模糊
In [9]
deblur_model = load_model(‘models/CMFNet_DeBlur.pdparams’)
run(deblur_model, ‘images/deblur_2.png’, ‘results/deblur_2.jpg’)
show(‘images/deblur_2.png’, ‘results/deblur_2.jpg’)


去雾
In [10]
dehaze_model = load_model(‘models/CMFNet_DeHaze.pdparams’)
run(dehaze_model, ‘images/haze_2.png’, ‘results/haze_2.jpg’)
show(‘images/haze_2.png’, ‘results/haze_2.jpg’)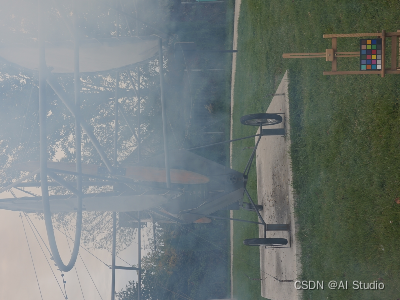
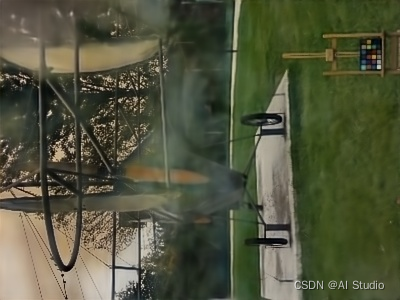
去雨水
In [11]
deraindrop_model = load_model(‘models/CMFNet_DeRainDrop.pdparams’)
run(deraindrop_model, ‘images/raindrop_2.png’, ‘results/raindrop_2.jpg’)
show(‘images/raindrop_2.png’, ‘results/raindrop_2.jpg’)


学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 1
1- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)