
FReLU:简单高效的新型激活函数
我们提出了一个概念简单但有效的漏斗激活图像识别任务,称为漏斗激活(FReLU),它通过添加可忽略的空间条件开销将ReLU和PReLU扩展到2D激活。ReLU和PReLU的形式分别为 y=max(x,0)y = max(x, 0)y=max(x,0) 和 y=max(x,px)y = max(x, px)y=max(x,px) ,而FReLU的形式为 y=max(x,T(x))y = max(x,
摘要
我们提出了一个概念简单但有效的漏斗激活图像识别任务,称为漏斗激活(FReLU),它通过添加可忽略的空间条件开销将ReLU和PReLU扩展到2D激活。ReLU和PReLU的形式分别为 y=max(x,0)y = max(x, 0)y=max(x,0) 和 y=max(x,px)y = max(x, px)y=max(x,px) ,而FReLU的形式为 y=max(x,T(x))y = max(x, T(x))y=max(x,T(x)) ,其中 T(⋅)T(·)T(⋅) 为二维空间条件。此外,空间条件以一种简单的方式实现了像素级建模能力,通过常规卷积捕获复杂的视觉布局。我们在ImageNet、COCO检测和语义分割任务上进行了实验,结果表明FReLU在视觉识别任务上有很大的改进和鲁棒性
1. FReLU
卷积神经网络(CNN)在许多视觉识别任务(例如图像分类,目标检测和语义分割)中均达到了最先进的性能。在CNN中主要的层是卷积层和非线性激活层,在卷积层中,自适应地捕获空间相关性是一个挑战,因此,研究者已经提出了许多更复杂和有效的卷积来在图像中自适应地捕获局部上下文信息,这在密集的预测任务(例如,语义分割和目标检测)上取得了不错的性能提升。但随着卷积的复杂性也带来了一个问题:常规的卷积能否达到类似的精度,以掌握具有挑战性的复杂图像呢?
其次,通常就在卷积层线性捕捉空间依赖性后,再由激活层进行非线性变换。目前最广泛使用的激活仍然是ReLU激活函数,于是有了另一个问题:能否设计一种专门针对视觉任务的激活函数?
为了回答上面提出的两个问题,本文表明简单但有效的视觉激活函数以及常规卷积也可以对密集和稀疏预测任务(例如图像分类,见图1)都能实现显著改善。为了实现这一结果,作者认为激活函数中的空间不敏感是阻碍视觉任务实现显著改善的主要原因,并基于此提出了一种新的视觉激活函数,以消除这一障碍。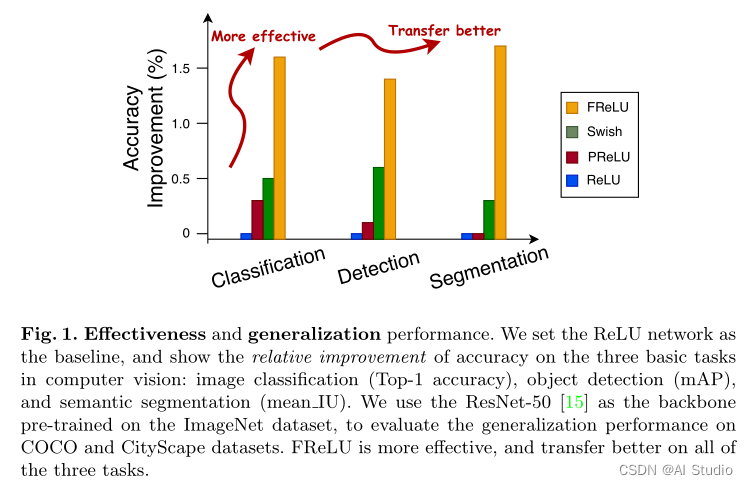
本文的方法被称为Funnel激活函数(FReLU),通过增加一个空间条件(见图2)来扩展ReLU/PReLU函数,它的实现很简单,只增加了一个可以忽略不计的计算开销。该激活函数的形式是 y=max(x,T(x))y=max(x,T(x))y=max(x,T(x)) ,其中 T(x)T(x)T(x) 代表简单高效的空间上下文特征提取器。由于使用了空间条件,FReLU简单地将ReLU和PReLU扩展为具有像素化建模能力的视觉参数化ReLU
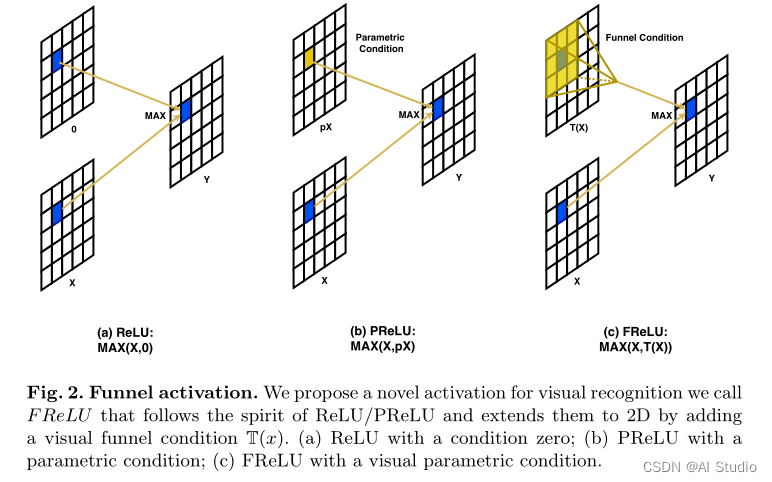
2. 代码复现
2.1 下载并导入所需要的包
!pip install paddlex
%matplotlib inline
import paddle
import paddle.fluid as fluid
import numpy as np
import matplotlib.pyplot as plt
from paddle.vision.datasets import Cifar10
from paddle.vision.transforms import Transpose
from paddle.io import Dataset, DataLoader
from paddle import nn
import paddle.nn.functional as F
import paddle.vision.transforms as transforms
import os
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import paddlex
from paddle import ParamAttr
2.2 创建数据集
train_tfm = transforms.Compose([
transforms.Resize((130, 130)),
transforms.ColorJitter(brightness=0.2,contrast=0.2, saturation=0.2),
paddlex.transforms.MixupImage(),
transforms.RandomResizedCrop(128, scale=(0.6, 1.0)),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomRotation(20),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
test_tfm = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
paddle.vision.set_image_backend('cv2')
# 使用Cifar10数据集
train_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='train', transform = train_tfm, )
val_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='test',transform = test_tfm)
print("train_dataset: %d" % len(train_dataset))
print("val_dataset: %d" % len(val_dataset))
train_dataset: 50000
val_dataset: 10000
batch_size=128
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=2)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=2)
2.3 标签平滑
class LabelSmoothingCrossEntropy(nn.Layer):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing
def forward(self, pred, target):
confidence = 1. - self.smoothing
log_probs = F.log_softmax(pred, axis=-1)
idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1)
nll_loss = paddle.gather_nd(-log_probs, index=idx)
smooth_loss = paddle.mean(-log_probs, axis=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss
return loss.mean()
2.4 AlexNet-FReLU
2.4.1 FReLU
class FReLU(nn.Layer):
def __init__(self, dim, init_weight=False):
super().__init__()
self.conv = nn.Conv2D(dim, dim, 3, 1, 1, groups=dim)
self.bn = nn.BatchNorm2D(dim)
if init_weight:
self.apply(self._init_weight)
def _init_weight(self, m):
init = nn.initializer.Normal(mean=0, std=.02)
zeros = nn.initializer.Constant(0.)
ones = nn.initializer.Constant(1.)
if isinstance(m, nn.Conv2D):
init(m.weight)
zeros(m.bias)
if isinstance(m, nn.BatchNorm2D):
ones(m.weight)
zeros(m.bias)
def forward(self, x):
x1 = self.bn(self.conv(x))
out = paddle.maximum(x, x1)
return out
model = FReLU(64)
paddle.summary(model, (1, 64, 224, 224))
W0727 16:05:19.179476 263 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0727 16:05:19.185858 263 gpu_resources.cc:91] device: 0, cuDNN Version: 7.6.
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-1 [[1, 64, 224, 224]] [1, 64, 224, 224] 640
BatchNorm2D-1 [[1, 64, 224, 224]] [1, 64, 224, 224] 256
===========================================================================
Total params: 896
Trainable params: 640
Non-trainable params: 256
---------------------------------------------------------------------------
Input size (MB): 12.25
Forward/backward pass size (MB): 49.00
Params size (MB): 0.00
Estimated Total Size (MB): 61.25
---------------------------------------------------------------------------
{'total_params': 896, 'trainable_params': 640}
2.4.2 AlexNet-FReLU
class AlexNet_FReLU(nn.Layer):
def __init__(self,num_classes=10):
super().__init__()
self.features=nn.Sequential(
nn.Conv2D(3,48, kernel_size=11, stride=4, padding=11//2),
FReLU(48),
nn.MaxPool2D(kernel_size=3,stride=2),
nn.Conv2D(48,128, kernel_size=5, padding=2),
FReLU(128),
nn.MaxPool2D(kernel_size=3,stride=2),
nn.Conv2D(128, 192,kernel_size=3,stride=1,padding=1),
FReLU(192),
nn.Conv2D(192,192,kernel_size=3,stride=1,padding=1),
FReLU(192),
nn.Conv2D(192,128,kernel_size=3,stride=1,padding=1),
FReLU(128),
nn.MaxPool2D(kernel_size=3,stride=2),
)
self.classifier=nn.Sequential(
nn.Linear(3 * 3 * 128,2048),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(2048,2048),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(2048,num_classes),
)
def forward(self,x):
x = self.features(x)
x = paddle.flatten(x, 1)
x=self.classifier(x)
return x
model = AlexNet_FReLU(num_classes=10)
paddle.summary(model, (1, 3, 128, 128))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-2 [[1, 3, 128, 128]] [1, 48, 32, 32] 17,472
Conv2D-3 [[1, 48, 32, 32]] [1, 48, 32, 32] 480
BatchNorm2D-2 [[1, 48, 32, 32]] [1, 48, 32, 32] 192
FReLU-2 [[1, 48, 32, 32]] [1, 48, 32, 32] 0
MaxPool2D-1 [[1, 48, 32, 32]] [1, 48, 15, 15] 0
Conv2D-4 [[1, 48, 15, 15]] [1, 128, 15, 15] 153,728
Conv2D-5 [[1, 128, 15, 15]] [1, 128, 15, 15] 1,280
BatchNorm2D-3 [[1, 128, 15, 15]] [1, 128, 15, 15] 512
FReLU-3 [[1, 128, 15, 15]] [1, 128, 15, 15] 0
MaxPool2D-2 [[1, 128, 15, 15]] [1, 128, 7, 7] 0
Conv2D-6 [[1, 128, 7, 7]] [1, 192, 7, 7] 221,376
Conv2D-7 [[1, 192, 7, 7]] [1, 192, 7, 7] 1,920
BatchNorm2D-4 [[1, 192, 7, 7]] [1, 192, 7, 7] 768
FReLU-4 [[1, 192, 7, 7]] [1, 192, 7, 7] 0
Conv2D-8 [[1, 192, 7, 7]] [1, 192, 7, 7] 331,968
Conv2D-9 [[1, 192, 7, 7]] [1, 192, 7, 7] 1,920
BatchNorm2D-5 [[1, 192, 7, 7]] [1, 192, 7, 7] 768
FReLU-5 [[1, 192, 7, 7]] [1, 192, 7, 7] 0
Conv2D-10 [[1, 192, 7, 7]] [1, 128, 7, 7] 221,312
Conv2D-11 [[1, 128, 7, 7]] [1, 128, 7, 7] 1,280
BatchNorm2D-6 [[1, 128, 7, 7]] [1, 128, 7, 7] 512
FReLU-6 [[1, 128, 7, 7]] [1, 128, 7, 7] 0
MaxPool2D-3 [[1, 128, 7, 7]] [1, 128, 3, 3] 0
Linear-1 [[1, 1152]] [1, 2048] 2,361,344
ReLU-5 [[1, 2048]] [1, 2048] 0
Dropout-1 [[1, 2048]] [1, 2048] 0
Linear-2 [[1, 2048]] [1, 2048] 4,196,352
ReLU-6 [[1, 2048]] [1, 2048] 0
Dropout-2 [[1, 2048]] [1, 2048] 0
Linear-3 [[1, 2048]] [1, 10] 20,490
===========================================================================
Total params: 7,533,674
Trainable params: 7,530,922
Non-trainable params: 2,752
---------------------------------------------------------------------------
Input size (MB): 0.19
Forward/backward pass size (MB): 3.38
Params size (MB): 28.74
Estimated Total Size (MB): 32.30
---------------------------------------------------------------------------
{'total_params': 7533674, 'trainable_params': 7530922}
2.5 训练
learning_rate = 0.001
n_epochs = 50
paddle.seed(42)
np.random.seed(42)
work_path = 'work/model'
model = AlexNet_FReLU(num_classes=10)
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0
threshold = 0.0
best_acc = 0.0
val_acc = 0.0
loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording loss
acc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracy
loss_iter = 0
acc_iter = 0
for epoch in range(n_epochs):
# ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy()
print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr()))
for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
accuracy_manager.update(acc)
if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100))
# ---------- Validation ----------
model.eval()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter)
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100))
# ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))
print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
2.6 实验结果
def plot_learning_curve(record, title='loss', ylabel='CE Loss'):
''' Plot learning curve of your CNN '''
maxtrain = max(map(float, record['train'][title]))
maxval = max(map(float, record['val'][title]))
ymax = max(maxtrain, maxval) * 1.1
mintrain = min(map(float, record['train'][title]))
minval = min(map(float, record['val'][title]))
ymin = min(mintrain, minval) * 0.9
total_steps = len(record['train'][title])
x_1 = list(map(int, record['train']['iter']))
x_2 = list(map(int, record['val']['iter']))
figure(figsize=(10, 6))
plt.plot(x_1, record['train'][title], c='tab:red', label='train')
plt.plot(x_2, record['val'][title], c='tab:cyan', label='val')
plt.ylim(ymin, ymax)
plt.xlabel('Training steps')
plt.ylabel(ylabel)
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
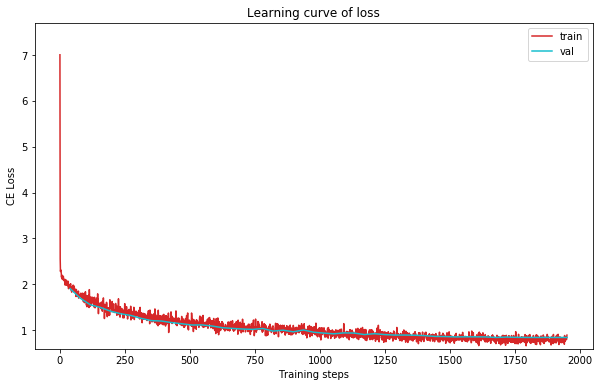
plot_learning_curve(loss_record, title='loss', ylabel='CE Loss')
plot_learning_curve(acc_record, title='acc', ylabel='Accuracy')
import time
work_path = 'work/model'
model = AlexNet_FReLU(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
bb = time.time()
print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:886
def get_cifar10_labels(labels):
"""返回CIFAR10数据集的文本标签。"""
text_labels = [
'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog',
'horse', 'ship', 'truck']
return [text_labels[int(i)] for i in labels]
def show_images(imgs, num_rows, num_cols, pred=None, gt=None, scale=1.5):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if paddle.is_tensor(img):
ax.imshow(img.numpy())
else:
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if pred or gt:
ax.set_title("pt: " + pred[i] + "\ngt: " + gt[i])
return axes
work_path = 'work/model'
X, y = next(iter(DataLoader(val_dataset, batch_size=18)))
model = AlexNet_FReLU(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
logits = model(X)
y_pred = paddle.argmax(logits, -1)
X = paddle.transpose(X, [0, 2, 3, 1])
axes = show_images(X.reshape((18, 128, 128, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y))
plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

3. AlexNet
3.1 AlexNet
class AlexNet(nn.Layer):
def __init__(self,num_classes=10):
super().__init__()
self.features=nn.Sequential(
nn.Conv2D(3,48, kernel_size=11, stride=4, padding=11//2),
nn.ReLU(),
nn.MaxPool2D(kernel_size=3,stride=2),
nn.Conv2D(48,128, kernel_size=5, padding=2),
nn.ReLU(),
nn.MaxPool2D(kernel_size=3,stride=2),
nn.Conv2D(128, 192,kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.Conv2D(192,192,kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.Conv2D(192,128,kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.MaxPool2D(kernel_size=3,stride=2),
)
self.classifier=nn.Sequential(
nn.Linear(3 * 3 * 128,2048),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(2048,2048),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(2048,num_classes),
)
def forward(self,x):
x = self.features(x)
x = paddle.flatten(x, 1)
x=self.classifier(x)
return x
model = AlexNet(num_classes=10)
paddle.summary(model, (1, 3, 128, 128))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-42 [[1, 3, 128, 128]] [1, 48, 32, 32] 17,472
ReLU-13 [[1, 48, 32, 32]] [1, 48, 32, 32] 0
MaxPool2D-13 [[1, 48, 32, 32]] [1, 48, 15, 15] 0
Conv2D-43 [[1, 48, 15, 15]] [1, 128, 15, 15] 153,728
ReLU-14 [[1, 128, 15, 15]] [1, 128, 15, 15] 0
MaxPool2D-14 [[1, 128, 15, 15]] [1, 128, 7, 7] 0
Conv2D-44 [[1, 128, 7, 7]] [1, 192, 7, 7] 221,376
ReLU-15 [[1, 192, 7, 7]] [1, 192, 7, 7] 0
Conv2D-45 [[1, 192, 7, 7]] [1, 192, 7, 7] 331,968
ReLU-16 [[1, 192, 7, 7]] [1, 192, 7, 7] 0
Conv2D-46 [[1, 192, 7, 7]] [1, 128, 7, 7] 221,312
ReLU-17 [[1, 128, 7, 7]] [1, 128, 7, 7] 0
MaxPool2D-15 [[1, 128, 7, 7]] [1, 128, 3, 3] 0
Linear-13 [[1, 1152]] [1, 2048] 2,361,344
ReLU-18 [[1, 2048]] [1, 2048] 0
Dropout-9 [[1, 2048]] [1, 2048] 0
Linear-14 [[1, 2048]] [1, 2048] 4,196,352
ReLU-19 [[1, 2048]] [1, 2048] 0
Dropout-10 [[1, 2048]] [1, 2048] 0
Linear-15 [[1, 2048]] [1, 10] 20,490
===========================================================================
Total params: 7,524,042
Trainable params: 7,524,042
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.19
Forward/backward pass size (MB): 1.81
Params size (MB): 28.70
Estimated Total Size (MB): 30.69
---------------------------------------------------------------------------
{'total_params': 7524042, 'trainable_params': 7524042}
3.2 训练
learning_rate = 0.001
n_epochs = 50
paddle.seed(42)
np.random.seed(42)
work_path = 'work/model1'
model = AlexNet(num_classes=10)
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0
threshold = 0.0
best_acc = 0.0
val_acc = 0.0
loss_record1 = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording loss
acc_record1 = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracy
loss_iter = 0
acc_iter = 0
for epoch in range(n_epochs):
# ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy()
print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr()))
for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
accuracy_manager.update(acc)
if batch_id % 10 == 0:
loss_record1['train']['loss'].append(loss.numpy())
loss_record1['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record1['train']['acc'].append(train_acc)
acc_record1['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100))
# ---------- Validation ----------
model.eval()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record1['val']['loss'].append(total_val_loss.numpy())
loss_record1['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record1['val']['acc'].append(val_acc)
acc_record1['val']['iter'].append(acc_iter)
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100))
# ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))
print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
3.3 实验结果
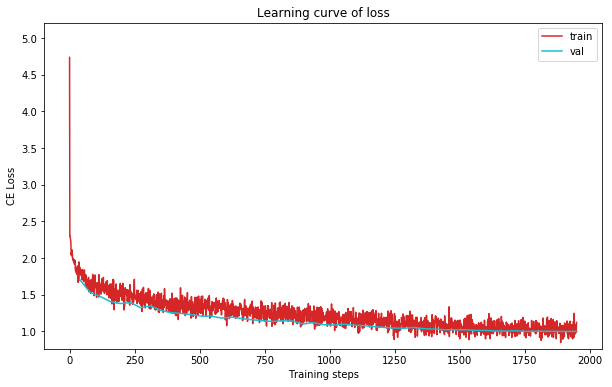
plot_learning_curve(loss_record1, title='loss', ylabel='CE Loss')
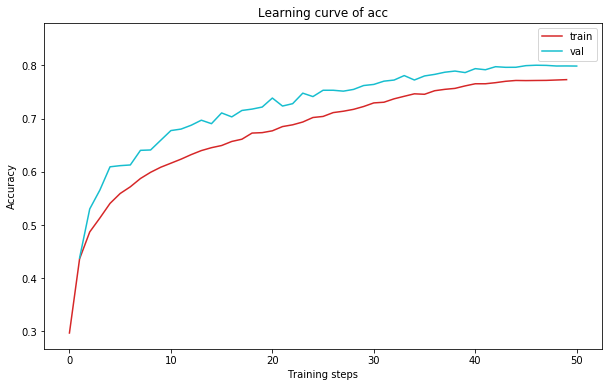
plot_learning_curve(acc_record1, title='acc', ylabel='Accuracy')
import time
work_path = 'work/model1'
model = AlexNet(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
bb = time.time()
print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:1095
work_path = 'work/model1'
X, y = next(iter(DataLoader(val_dataset, batch_size=18)))
model = AlexNet(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
logits = model(X)
y_pred = paddle.argmax(logits, -1)
X = paddle.transpose(X, [0, 2, 3, 1])
axes = show_images(X.reshape((18, 128, 128, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y))
plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

4. 对比实验结果
| model | Train Acc | Val Acc | parameter |
|---|---|---|---|
| AlexNet w/o FReLU | 0.7718 | 0.80044 | 7524042 |
| AlexNet w FReLU | 0.8758 | 0.87243 | 7533674 |
总结
- FReLU在增加少量参数(+9632)的同时大大加快了收敛速度以及精度(+0.07199)。
- FReLU实现极其简单,但是对于ReLU函数形式的观察以及改进非常巧妙
转载自:https://aistudio.baidu.com/aistudio/projectdetail/4381304

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)