
PaddleHub:Transformer模型自定义数据集Finetune
项目背景近年来随着深度学习的发展,模型参数数量飞速增长,为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集成本过高,非常困难,特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 能够习得通用的语言表示,将预训练模型Fin
项目背景
近年来随着深度学习的发展,模型参数数量飞速增长,为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集成本过高,非常困难,特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 能够习得通用的语言表示,将预训练模型Fine-tune到下游任务,能够获得出色的表现。另外,预训练模型能够避免从零开始训练模型。
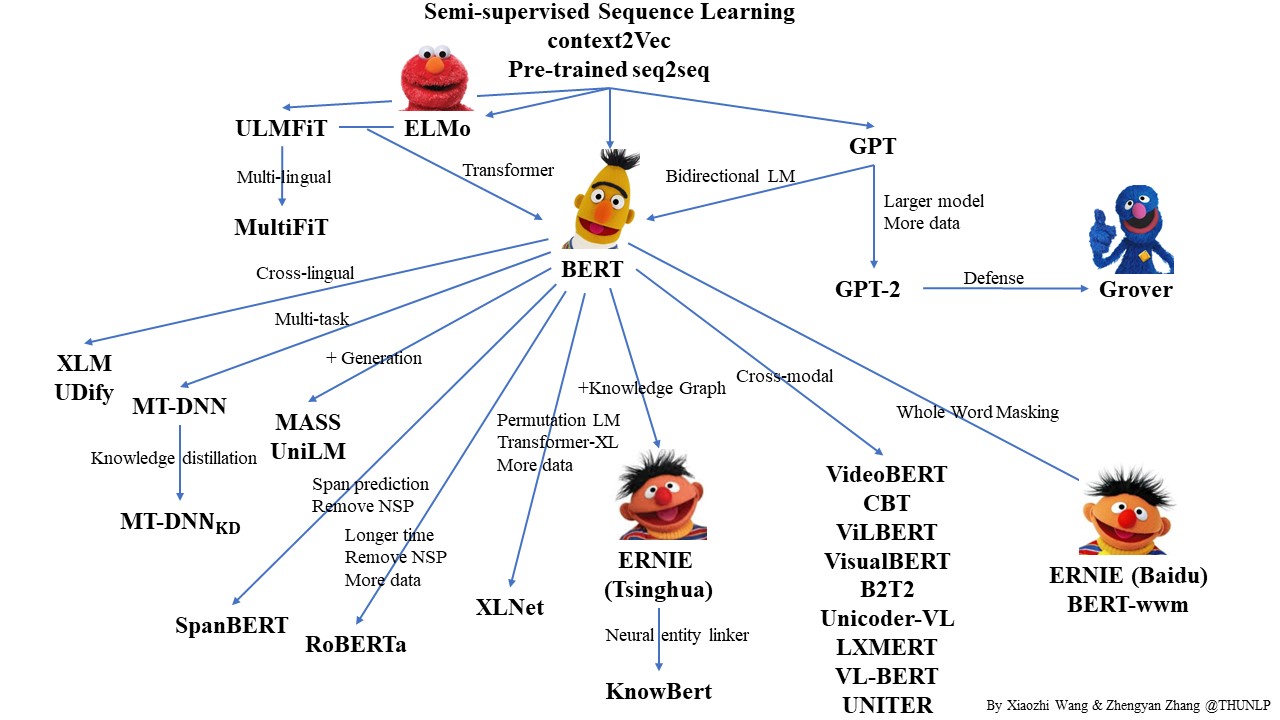
使用PaddleHub进行Finetune的优势
在前面提到的文本分类任务迁移学习项目中,使用的都是PaddleNLP,感兴趣的读者可以了解PaddleNLP2.0:BERT模型在文本分类任务上的应用系列项目:
- 使用PaddleNLP进行恶意网页识别(五):用BERT识别恶意网页内容
- 使用PaddleNLP的BERT预训练模型,根据HTML网页内容处理结果判断网页是否正常,大幅提高验证集上准确率
- 使用PaddleNLP进行恶意网页识别(六):用BERT识别网页标签序列)
- 验证集上模型准确率可以轻松达到96.5%以上,测试集上准确率接近97%,在BERT预训练模型上进行finetune,得到了目前在该HTML标签序列分类任务上的最好表现。
- 使用PaddleNLP识别垃圾邮件(二):用BERT做中文邮件内容分类
- 使用PaddleNLP的BERT预训练模型,根据提取的中文邮件内容判断邮件是否为垃圾邮件,只需3个epoch,验证集准确率即超过99.6%。
PS:如果觉得以上项目写得还行,请轻点下fork哈,感谢!
其实PaddleHub也支持文本分类任务的迁移学习,而且它有一个巨大的优势:代码量低!
比如,我们尝试实现下PaddleHub文档中给的示例:
PaddleHub Transformer模型fine-tune文本分类(动态图)
注:原文档中存在一些问题,本项目已修正,代码请以项目为准。
代码步骤
使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
Step1: 选择模型
%set_env CUDA_VISIBLE_DEVICES=0
import paddlehub as hub
import paddle
model = hub.Module(name='ernie_tiny', version='2.0.1', task='seq-cls', num_classes=2)
Step2: 下载并加载数据集
train_dataset = hub.datasets.ChnSentiCorp(
tokenizer=model.get_tokenizer(), max_seq_len=128, mode='train')
dev_dataset = hub.datasets.ChnSentiCorp(
tokenizer=model.get_tokenizer(), max_seq_len=128, mode='dev')
Step3: 选择优化策略和运行配置
optimizer = paddle.optimizer.Adam(learning_rate=5e-5, parameters=model.parameters())
trainer = hub.Trainer(model, optimizer, checkpoint_dir='test_ernie_text_cls', use_gpu=True)
# 为缩短演示时间,这里只训练一个epoch
trainer.train(train_dataset, epochs=1, batch_size=32, eval_dataset=dev_dataset)
# 在验证集上评估当前训练模型
trainer.evaluate(dev_dataset, batch_size=32)
Step4: 模型预测
import paddlehub as hub
data = [
['这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般'],
['怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片'],
['作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。'],
]
label_map = {0: 'negative', 1: 'positive'}
model = hub.Module(
name='ernie_tiny',
version='2.0.1',
task='seq-cls',
load_checkpoint='./test_ernie_text_cls/best_model/model.pdparams',
label_map=label_map)
results = model.predict(data, max_seq_len=50, batch_size=1, use_gpu=False)
for idx, text in enumerate(data):
print('Data: {} \t Lable: {}'.format(text[0], results[idx]))
输出结果:
Data: 这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般 Lable: negative
Data: 怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片 Lable: negative
Data: 作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。 Lable: negative
30行代码,就完成了Transformer模型的迁移学习!准确率还很高!
说到这,我们一定会想,能不能在自己的数据集上完成如此简单的迁移学习?当然可以,不过得加点代码——真的只需要一点点!
参考PaddleHub文本分类自定义数据集文档,当然,读者也可以看我这个项目,尝试下对源码的分析解读,然后自己运行下。
PaddleHub代码分析
首先,我们聚焦于前面的流程,发现自定义数据集其实只跟一个步骤高度相关,就是它:
Step2: 下载并加载数据集
train_dataset = hub.datasets.ChnSentiCorp( tokenizer=model.get_tokenizer(), max_seq_len=128, mode='train') dev_dataset = hub.datasets.ChnSentiCorp( tokenizer=model.get_tokenizer(), max_seq_len=128, mode='dev')
使用AI Studio上查看源码的功能,我们找到了源代码中对ChnSentiCorp这个类的定义。
# 没错,这里是小写的chnsenticorp!用代码提示的时候会跳出来,读者可以和大写的`hub.datasets.ChnSentiCorp`函数对比下,被封装了
??hub.datasets.chnsenticorp
下面,在注释中对hub.datasets.chnsenticorp源代码进行解读。
from typing import Dict, List, Optional, Union, Tuple
import os
from paddlehub.env import DATA_HOME
from paddlehub.utils.download import download_data
from paddlehub.datasets.base_nlp_dataset import TextClassificationDataset
from paddlehub.text.bert_tokenizer import BertTokenizer
from paddlehub.text.tokenizer import CustomTokenizer
# 下载chnsenticorp数据集,会自动在默认路径解压
@download_data(url="https://bj.bcebos.com/paddlehub-dataset/chnsenticorp.tar.gz")
class ChnSentiCorp(TextClassificationDataset):
"""
ChnSentiCorp is a dataset for chinese sentiment classification,
which was published by Tan Songbo at ICT of Chinese Academy of Sciences.
"""
# TODO(zhangxuefei): simplify datatset load, such as
# train_ds, dev_ds, test_ds = hub.datasets.ChnSentiCorp(tokenizer=xxx, max_seq_len=128, select='train', 'test', 'valid')
# 这里再次说明了相关的输入信息,其中,tokenizer要跟着加载模型来
def __init__(self, tokenizer: Union[BertTokenizer, CustomTokenizer], max_seq_len: int = 128, mode: str = 'train'):
"""
Args:
tokenizer (:obj:`BertTokenizer` or `CustomTokenizer`):
It tokenizes the text and encodes the data as model needed.
max_seq_len (:obj:`int`, `optional`, defaults to :128):
The maximum length (in number of tokens) for the inputs to the selected module,
such as ernie, bert and so on.
mode (:obj:`str`, `optional`, defaults to `train`):
It identifies the dataset mode (train, test or dev).
Examples:
.. code-block:: python
import paddlehub as hub
tokenizer = hub.BertTokenizer(vocab_file='./vocab.txt')
train_dataset = hub.datasets.ChnSentiCorp(tokenizer=tokenizer, max_seq_len=120, mode='train')
dev_dataset = hub.datasets.ChnSentiCorp(tokenizer=tokenizer, max_seq_len=120, mode='dev')
test_dataset = hub.datasets.ChnSentiCorp(tokenizer=tokenizer, max_seq_len=120, mode='test')
"""
# base_path写死了,这是自定义数据集重点要修改的地方
base_path = os.path.join(DATA_HOME, "chnsenticorp")
if mode == 'train':
data_file = 'train.tsv'
elif mode == 'test':
data_file = 'test.tsv'
else:
data_file = 'dev.tsv'
super().__init__(
base_path=base_path,
tokenizer=tokenizer,
max_seq_len=max_seq_len,
mode=mode,
data_file=data_file,
# chnsenticorp数据集的标签就是0和1,所以label_list要根据数据集具体内容来的
label_list=["0", "1"],
# tsv文件有个标题栏
is_file_with_header=True)
不难看出,其实就是到 https://bj.bcebos.com/paddlehub-dataset/chnsenticorp.tar.gz 下载并解压数据集后,继承TextClassificationDataset类,将解压后训练集、验证集、测试集的位置配置进去即可。
也就是说,只要让自己的数据集和chnsenticorp数据集格式一致,我们完全可以仿照ChnSentiCorp这个类的定义,进行数据集自定义,包括配置路径、指定tokenizer类型等。
封装的chnsenticorp数据集格式分析
!wget https://bj.bcebos.com/paddlehub-dataset/chnsenticorp.tar.gz
!tar -zxvf chnsenticorp.tar.gz
chnsenticorp数据集是tsv格式,除首行为标题外,每行都是(标签+分隔符+文本)的形式。
需要注意的是,由于ChnSentiCorp类是直接继承了TextClassificationDataset类,因此准备自定义数据集时,包括标题内容label text_a在内的全部格式都要与chnsenticorp数据集一致。
!head chnsenticorp/train.tsv
label text_a
1 选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般
1 15.4寸笔记本的键盘确实爽,基本跟台式机差不多了,蛮喜欢数字小键盘,输数字特方便,样子也很美观,做工也相当不错
0 房间太小。其他的都一般。。。。。。。。。
0 1.接电源没有几分钟,电源适配器热的不行. 2.摄像头用不起来. 3.机盖的钢琴漆,手不能摸,一摸一个印. 4.硬盘分区不好办.
1 今天才知道这书还有第6卷,真有点郁闷:为什么同一套书有两种版本呢?当当网是不是该跟出版社商量商量,单独出个第6卷,让我们的孩子不会有所遗憾。
0 机器背面似乎被撕了张什么标签,残胶还在。但是又看不出是什么标签不见了,该有的都在,怪
0 呵呵,虽然表皮看上去不错很精致,但是我还是能看得出来是盗的。但是里面的内容真的不错,我妈爱看,我自己也学着找一些穴位。
0 这本书实在是太烂了,以前听浙大的老师说这本书怎么怎么不对,哪些地方都是误导的还不相信,终于买了一本看一下,发现真是~~~无语,这种书都写得出来
1 地理位置佳,在市中心。酒店服务好、早餐品种丰富。我住的商务数码房电脑宽带速度满意,房间还算干净,离湖南路小吃街近。
还要改什么?
确定了数据集形式,其实要改动的内容已经非常少了,总的来说,只有:
- 修改下载数据集为直接使用本地数据集
- base_path的文件路径设置也要相应修改
效果检验:用千言数据集数据进行迁移学习
数据集介绍——千言数据集:情感分析
情感分析旨在自动识别和提取文本中的倾向、立场、评价、观点等主观信息。它包含各式各样的任务,比如句子级情感分类、评价对象级情感分类、观点抽取、情绪分类等。情感分析是人工智能的重要研究方向,具有很高的学术价值。同时,情感分析在消费决策、舆情分析、个性化推荐等领域均有重要的应用,具有很高的商业价值。
近两年,NLP技术发展较快,一个趋势是大家不再过度关注模型在单一数据的效果,开始逐渐关注模型在多个数据集的效果。基于此,百度与多位研究学者一起收集和整理了一个综合、全面的中文情感分析评测数据集,希望能进一步提升情感分析的研究水平,推动自然语言理解和人工智能技术的应用和发展。
本项目评测的情感分析数据集涵盖了是句子级情感分类(Sentence-level Sentiment Classification)任务。定义如下:
句子级情感分类
对于给定的文本d,系统需要根据文本的内容,给出其对应的情感类别s,类别s一般只包含积极、消极两类,部分数据集还包括中性类别。数据集中每个样本是一个二元组 <d, s> ,样例如下:
输入文本(d):15.4寸笔记本的键盘确实爽,基本跟台式机差不多了,蛮喜欢数字小键盘,输数字特方便,样子也很美观,做工也相当不错
情感类别(s):积极
注:数据集中1表示积极,0表示消极
# 为与chnsenticorp数据集进行区分,这里使用千言数据集中的NLPCC14-SC数据集
!unzip data/data53469/NLPCC14-SC.zip
NLPCC14-SC数据集没用提供验证集,因此需要我们自行切分。我们先查看下数据集内容,会发现它的标题与chnsenticorp数据集一致,因此,只需要重点关注数据集的切分即可。注意到NLPCC14-SC数据集的标签,这里还需要进行乱序处理。
!head NLPCC14-SC/train.tsv
label text_a
1 请问这机不是有个遥控器的吗?
1 发短信特别不方便!背后的屏幕很大用起来不舒服,是手触屏的!切换屏幕很麻烦!
1 手感超好,而且黑色相比白色在转得时候不容易眼花,找童年的记忆啦。
1 !!!!!
1 先付款的 有信用
1 价格质量售后都很满意
1 书的质量和印刷都不错,字的大小也刚刚好,很清楚,喜欢
1 超级值得看的一个电影
1 今天突然看到卓越有卖这个的,可是韩国不是卖没有了吗。虽然是引进版的,可是之前也卖没有了。卓越从哪里找出来的啊
准备工具库
import os
import random
import numpy as np
import paddlehub as hub
import paddle
from typing import Dict, List, Optional, Union, Tuple
from paddlehub.datasets.base_nlp_dataset import TextClassificationDataset
from paddlehub.text.bert_tokenizer import BertTokenizer
from paddlehub.text.tokenizer import CustomTokenizer
切分数据集
# 读取tsv
def read_tsv(tsv):
datas = []
with open(tsv, 'r', encoding='UTF-8') as f:
for i, line in enumerate(f):
if i==0:
continue
else:
data = line[:-1].split('\t')
datas.append('\t'.join([data[0], data[1]])+'\n')
return datas
# 写入tsv
def write_tsv(tsv, datas):
with open(tsv, 'w', encoding='UTF-8') as f:
for line in datas:
f.write(line)
# 切分并转换
def split_dataset_change(tsv, split_num):
datas = read_tsv(tsv)
random.shuffle(datas)
write_tsv(tsv, datas[:-split_num])
write_tsv('/'.join(tsv.split('/')[:-1])+'/dev.tsv', datas[-split_num:])
# 我们将train.tsv的后500条切分到了dev.tsv文件中
split_dataset_change('NLPCC14-SC/train.tsv', 500)
选一个Transformer模型
PaddleHub还提供BERT等模型可供选择, 当前支持文本分类任务的模型对应的加载示例如下:
| 模型名 | PaddleHub Module |
|---|---|
| ERNIE, Chinese | hub.Module(name='ernie') |
| ERNIE tiny, Chinese | hub.Module(name='ernie_tiny') |
| ERNIE 2.0 Base, English | hub.Module(name='ernie_v2_eng_base') |
| ERNIE 2.0 Large, English | hub.Module(name='ernie_v2_eng_large') |
| BERT-Base, English Cased | hub.Module(name='bert-base-cased') |
| BERT-Base, English Uncased | hub.Module(name='bert-base-uncased') |
| BERT-Large, English Cased | hub.Module(name='bert-large-cased') |
| BERT-Large, English Uncased | hub.Module(name='bert-large-uncased') |
| BERT-Base, Multilingual Cased | hub.Module(nane='bert-base-multilingual-cased') |
| BERT-Base, Multilingual Uncased | hub.Module(nane='bert-base-multilingual-uncased') |
| BERT-Base, Chinese | hub.Module(name='bert-base-chinese') |
| BERT-wwm, Chinese | hub.Module(name='chinese-bert-wwm') |
| BERT-wwm-ext, Chinese | hub.Module(name='chinese-bert-wwm-ext') |
| RoBERTa-wwm-ext, Chinese | hub.Module(name='roberta-wwm-ext') |
| RoBERTa-wwm-ext-large, Chinese | hub.Module(name='roberta-wwm-ext-large') |
| RBT3, Chinese | hub.Module(name='rbt3') |
| RBTL3, Chinese | hub.Module(name='rbtl3') |
| ELECTRA-Small, English | hub.Module(name='electra-small') |
| ELECTRA-Base, English | hub.Module(name='electra-base') |
| ELECTRA-Large, English | hub.Module(name='electra-large') |
| ELECTRA-Base, Chinese | hub.Module(name='chinese-electra-base') |
| ELECTRA-Small, Chinese | hub.Module(name='chinese-electra-small') |
在本项目中,就先选择BERT-Base, Chinese这个模型,读者可以根据需要,选择想尝试的模型。
model = hub.Module(name='bert-base-chinese', version='2.0.1', task='seq-cls', num_classes=2)
写一个自定义数据集的类
其实就是依葫芦画瓢,不过这里将base_path指定为NLPCC14-SC目录。
class SelfDataset(TextClassificationDataset):
def __init__(self, tokenizer: Union[BertTokenizer, CustomTokenizer], max_seq_len: int = 128, mode: str = 'train'):
base_path = './NLPCC14-SC'
if mode == 'train':
data_file = 'train.tsv'
elif mode == 'test':
data_file = 'test.tsv'
else:
data_file = 'dev.tsv'
super().__init__(
base_path=base_path,
tokenizer=tokenizer,
max_seq_len=max_seq_len,
mode=mode,
data_file=data_file,
label_list=["0", "1"],
is_file_with_header=True)
加载数据集
注意这里tokenizer其实不需要自己指定,用model.get_tokenizer()要更加通用
# 加载训练集和验证集
train_dataset = SelfDataset(tokenizer=model.get_tokenizer(), max_seq_len=128, mode='train')
dev_dataset = SelfDataset(tokenizer=model.get_tokenizer(), max_seq_len=128, mode='dev')
test_dataset = SelfDataset(tokenizer=model.get_tokenizer(), max_seq_len=128, mode='test')
需要注意的是,这里不能直接加载原数据集里的test.tsv作为测试集,会报错。因为实际上chnsenticorp数据集的测试集是带标签的,NLPCC14-SC的首列其实只是序号,读者可以自己对比下。
!head NLPCC14-SC/test.tsv
!head chnsenticorp/test.tsv
选择优化策略和运行配置
接下来的步骤,和前面就没有区别了,当然checkpoint_dir目录可以指定一下,和前面训练的模型分开。
optimizer = paddle.optimizer.Adam(learning_rate=1e-5, parameters=model.parameters())
trainer = hub.Trainer(model, optimizer, checkpoint_dir='test_bert_text_cls',use_gpu=True)
# 这里改为边训练边验证
trainer.train(train_dataset, epochs=3, batch_size=64, eval_dataset=dev_dataset, save_interval=1)
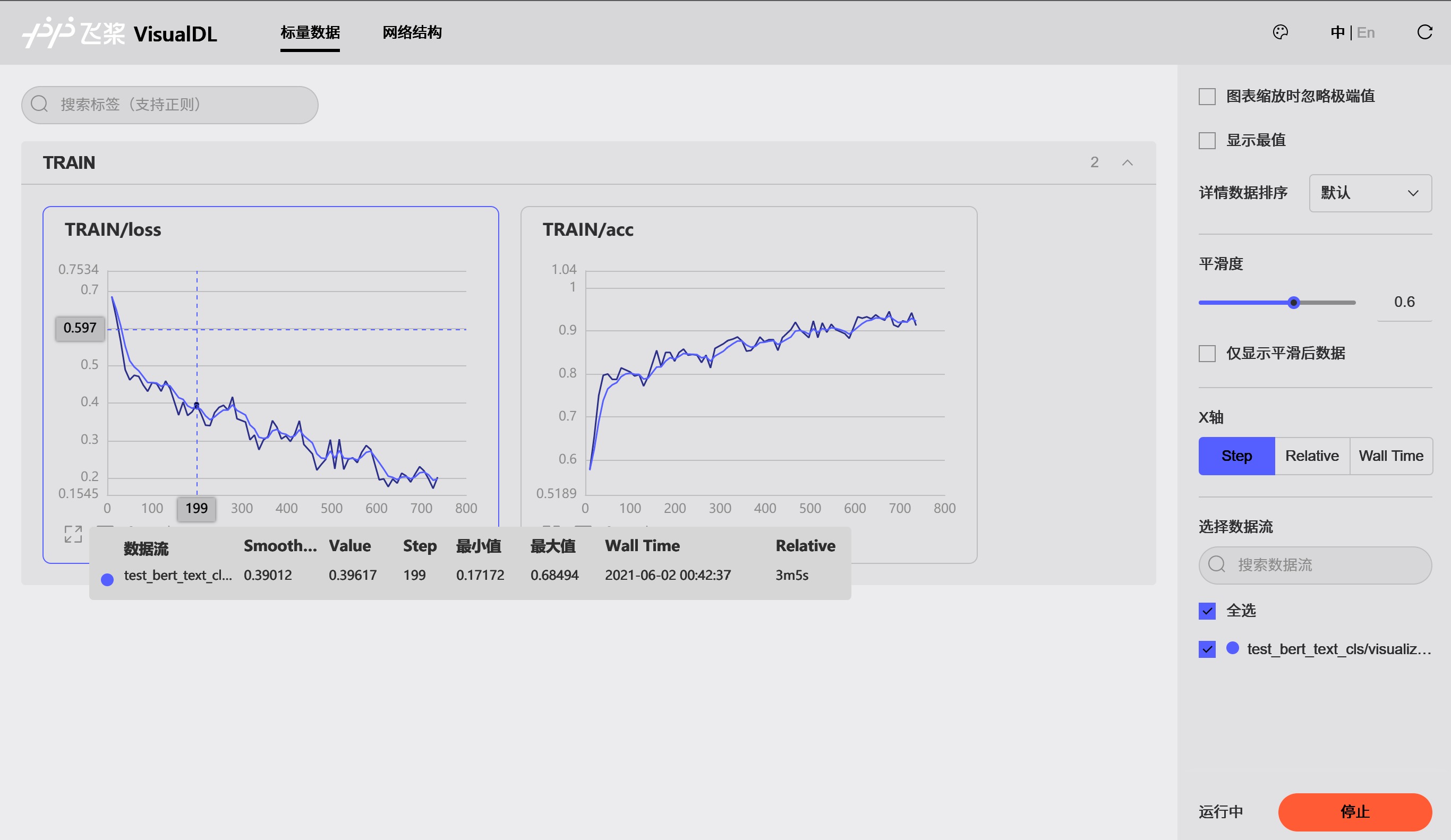
# 在验证集上评估当前训练模型
v_dataset, save_interval=1)
[外链图片转存中…(img-KOC85gCV-1635902146074)]
# 在验证集上评估当前训练模型
trainer.evaluate(dev_dataset, batch_size=64)
模型预测
data = [
['这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般'],
['怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片'],
['作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。'],
]
label_map = {0: 'negative', 1: 'positive'}
model = hub.Module(
name='bert-base-chinese',
version='2.0.1',
task='seq-cls',
load_checkpoint='./test_bert_text_cls/best_model/model.pdparams',
label_map=label_map)
results = model.predict(data, max_seq_len=50, batch_size=1, use_gpu=False)
for idx, text in enumerate(data):
print('Data: {} \t Lable: {}'.format(text[0], results[idx]))
注:更详细的配置项说明请查看文档

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)