
SCNet:自校正卷积网络,无复杂度增加换来性能提升
本文复现了CVPR2020年的一篇论文,本文提出了一种新颖的自校正卷积,该卷积它可以通过特征的内在通信达到扩增卷积感受野的目的。
·
引入
- SCNet:本文提出了一种自校正卷积作为一种有效的方法来帮助卷积网络通过增加每层的基本卷积变换来学习判别表示。
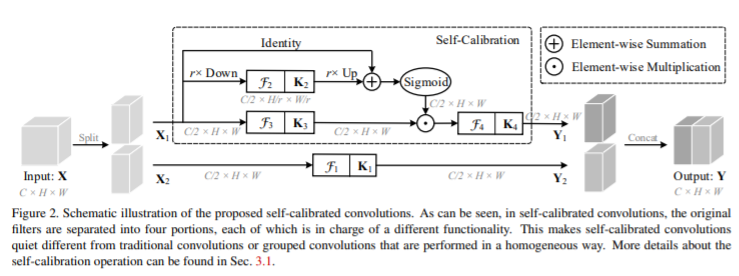
- 类似于分组卷积,它将特定层的卷积核分为多个部分,但不均匀地每个部分中的卷积核以异构方式被利用。具体而言,自校正卷积不是通过均匀地对原始空间中的输入执行所有卷积,而是首先通过下采样将输入转换为低维嵌入。采用由一个卷积核变换的低维嵌入来校准另一部分中卷积核的卷积变换。得益于这种异构卷积和卷积核间通信,可以有效地扩大每个空间位置的感受野。
- 结构上也非常简单,但是同样能够实现一个不错的精度表现,而且为未来的研究提供一种设计新颖的卷积特征变换以改善卷积网络的方法
模型架构
自校正卷积 SCConv(Self-Calibrated Convolutions)
- SCConv 带来了一些新的结果:
- 1.本文所设计的SCConv可以通过自校正操作自适应地在每个空间位置周围建立了远程空间和通道间依存关系.
- 2.自矫正卷积SCConv的设计简单且通用,可以轻松增强标准卷积层的性能,而不会引入额外的参数和复杂性.
- 3.空间上的每一个点都有附近区域的信息和通道上的交互信息,同时避免了整个全局信息中无关区域的干扰.
数据集构建
- 本次实验选用10分类动物数据集进行测试,以下分别对数据集进行了定义及数据增强
!unzip -oq data/data110994/work.zip -d work/
import paddle
paddle.seed(8888)
import numpy as np
from typing import Callable
#参数配置
config_parameters = {
"class_dim": 10, #分类数
"target_path":"/home/aistudio/work/",
'train_image_dir': '/home/aistudio/work/trainImages',
'eval_image_dir': '/home/aistudio/work/evalImages',
'epochs':20,
'batch_size': 64,
'lr': 0.01
}
#数据集的定义
class TowerDataset(paddle.io.Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, transforms: Callable, mode: str ='train'):
"""
步骤二:实现构造函数,定义数据读取方式
"""
super(TowerDataset, self).__init__()
self.mode = mode
self.transforms = transforms
train_image_dir = config_parameters['train_image_dir']
eval_image_dir = config_parameters['eval_image_dir']
train_data_folder = paddle.vision.DatasetFolder(train_image_dir)
eval_data_folder = paddle.vision.DatasetFolder(eval_image_dir)
if self.mode == 'train':
self.data = train_data_folder
elif self.mode == 'eval':
self.data = eval_data_folder
def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
data = np.array(self.data[index][0]).astype('float32')
data = self.transforms(data)
label = np.array([self.data[index][1]]).astype('int64')
return data, label
def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.data)
from paddle.vision import transforms as T
#数据增强
transform_train =T.Compose([T.Resize((256,256)),
#T.RandomVerticalFlip(10),
#T.RandomHorizontalFlip(10),
T.RandomRotation(10),
T.Transpose(),
T.Normalize(mean=[0, 0, 0], # 像素值归一化
std =[255, 255, 255]), # transforms.ToTensor(), # transpose操作 + (img / 255),并且数据结构变为PaddleTensor
T.Normalize(mean=[0.50950350, 0.54632660, 0.57409690],# 减均值 除标准差
std= [0.26059777, 0.26041326, 0.29220656])# 计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]
])
transform_eval =T.Compose([ T.Resize((256,256)),
T.Transpose(),
T.Normalize(mean=[0, 0, 0], # 像素值归一化
std =[255, 255, 255]), # transforms.ToTensor(), # transpose操作 + (img / 255),并且数据结构变为PaddleTensor
T.Normalize(mean=[0.50950350, 0.54632660, 0.57409690],# 减均值 除标准差
std= [0.26059777, 0.26041326, 0.29220656])# 计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]
])
train_dataset = TowerDataset(mode='train',transforms=transform_train)
eval_dataset = TowerDataset(mode='eval', transforms=transform_eval )
#数据异步加载
train_loader = paddle.io.DataLoader(train_dataset,
places=paddle.CUDAPlace(0),
batch_size=16,
shuffle=True,
#num_workers=2,
#use_shared_memory=True
)
eval_loader = paddle.io.DataLoader (eval_dataset,
places=paddle.CUDAPlace(0),
batch_size=16,
#num_workers=2,
#use_shared_memory=True
)
print('训练集样本量: {},验证集样本量: {}'.format(len(train_loader), len(eval_loader)))
训练集样本量: 1309,验证集样本量: 328
代码实现
- 模型的代码实现其实在上面的结构图中已经有出现了,不过由于过于精简可能比较不好理解
- 下面给出官方代码中的另一种常规一些的实现方式,结构比较清晰,并且手动添加了一些注释,相对比较好理解
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
class SCConv(nn.Layer):
def __init__(self, inplanes, planes, stride, padding, dilation, groups, pooling_r, norm_layer):
super(SCConv, self).__init__()
self.k2 = nn.Sequential(
nn.AvgPool2D(kernel_size=pooling_r, stride=pooling_r),
nn.Conv2D(inplanes, planes, kernel_size=3, stride=1,
padding=padding, dilation=dilation,
groups=groups, bias_attr=False),
norm_layer(planes),
)
self.k3 = nn.Sequential(
nn.Conv2D(inplanes, planes, kernel_size=3, stride=1,
padding=padding, dilation=dilation,
groups=groups, bias_attr=False),
norm_layer(planes),
)
self.k4 = nn.Sequential(
nn.Conv2D(inplanes, planes, kernel_size=3, stride=stride,
padding=padding, dilation=dilation,
groups=groups, bias_attr=False),
norm_layer(planes),
)
def forward(self, x):
identity = x
out = F.sigmoid(paddle.add(identity, F.interpolate(self.k2(x), identity.shape[2:]))) # sigmoid(identity + k2)
out = paddle.multiply(self.k3(x), out) # k3 * sigmoid(identity + k2)
out = self.k4(out) # k4
return out
class SCBottleneck(nn.Layer):
"""SCNet SCBottleneck
"""
expansion = 4
pooling_r = 4 # down-sampling rate of the avg pooling layer in the K3 path of SC-Conv.
def __init__(self, inplanes, planes, stride=1, downsample=None,
cardinality=1, bottleneck_width=32,
avd=False, dilation=1, is_first=False,
norm_layer=None):
super(SCBottleneck, self).__init__()
group_width = int(planes * (bottleneck_width / 64.)) * cardinality
self.conv1_a = nn.Conv2D(inplanes, group_width, kernel_size=1, bias_attr=False)
self.bn1_a = norm_layer(group_width)
self.conv1_b = nn.Conv2D(inplanes, group_width, kernel_size=1, bias_attr=False)
self.bn1_b = norm_layer(group_width)
self.avd = avd and (stride > 1 or is_first)
if self.avd:
self.avd_layer = nn.AvgPool2D(3, stride, padding=1)
stride = 1
self.k1 = nn.Sequential(
nn.Conv2D(
group_width, group_width, kernel_size=3, stride=stride,
padding=dilation, dilation=dilation,
groups=cardinality, bias_attr=False),
norm_layer(group_width),
)
self.scconv = SCConv(
group_width, group_width, stride=stride,
padding=dilation, dilation=dilation,
groups=cardinality, pooling_r=self.pooling_r, norm_layer=norm_layer)
self.conv3 = nn.Conv2D(
group_width * 2, planes * 4, kernel_size=1, bias_attr=False)
self.bn3 = norm_layer(planes*4)
self.relu = nn.ReLU()
self.downsample = downsample
self.dilation = dilation
self.stride = stride
def forward(self, x):
residual = x
out_a= self.conv1_a(x)
out_a = self.bn1_a(out_a)
out_b = self.conv1_b(x)
out_b = self.bn1_b(out_b)
out_a = self.relu(out_a)
out_b = self.relu(out_b)
out_a = self.k1(out_a)
out_b = self.scconv(out_b)
out_a = self.relu(out_a)
out_b = self.relu(out_b)
if self.avd:
out_a = self.avd_layer(out_a)
out_b = self.avd_layer(out_b)
out = self.conv3(paddle.concat([out_a, out_b], axis=1))
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class SCNet(nn.Layer):
""" SCNet Variants Definations
Parameters
----------
block : Block
Class for the residual block.
layers : list of int
Numbers of layers in each block.
classes : int, default 1000
Number of classificoncation classes.
dilated : bool, default False
Applying dilation strategy to pretrained SCNet yielding a stride-8 model.
deep_stem : bool, default False
Replace 7x7 conv in input stem with 3 3x3 conv.
avg_down : bool, default False
Use AvgPool instead of stride conv when
downsampling in the bottleneck.
norm_layer : object
Normalization layer used (default: :class:`paddle.nn.BatchNorm2D`).
Reference:
- He, Kaiming, et al. "Deep residual learning for image recognition."
Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
- Yu, Fisher, and Vladlen Koltun. "Multi-scale context aggregation by dilated convolutions."
"""
def __init__(self, block, layers, groups=1, bottleneck_width=32,
num_classes=1000, dilated=False, dilation=1,
deep_stem=False, stem_width=64, avg_down=False,
avd=False, norm_layer=nn.BatchNorm2D):
self.cardinality = groups
self.bottleneck_width = bottleneck_width
# ResNet-D params
self.inplanes = stem_width*2 if deep_stem else 64
self.avg_down = avg_down
self.avd = avd
super(SCNet, self).__init__()
conv_layer = nn.Conv2D
if deep_stem:
self.conv1 = nn.Sequential(
conv_layer(3, stem_width, kernel_size=3, stride=2, padding=1, bias_attr=False),
norm_layer(stem_width),
nn.ReLU(),
conv_layer(stem_width, stem_width, kernel_size=3, stride=1, padding=1, bias_attr=False),
norm_layer(stem_width),
nn.ReLU(),
conv_layer(stem_width, stem_width*2, kernel_size=3, stride=1, padding=1, bias_attr=False),
)
else:
self.conv1 = conv_layer(3, 64, kernel_size=7, stride=2, padding=3,
bias_attr=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2D(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0], norm_layer=norm_layer, is_first=False)
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, norm_layer=norm_layer)
if dilated or dilation == 4:
self.layer3 = self._make_layer(block, 256, layers[2], stride=1,
dilation=2, norm_layer=norm_layer)
self.layer4 = self._make_layer(block, 512, layers[3], stride=1,
dilation=4, norm_layer=norm_layer)
elif dilation==2:
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilation=1, norm_layer=norm_layer)
self.layer4 = self._make_layer(block, 512, layers[3], stride=1,
dilation=2, norm_layer=norm_layer)
else:
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
norm_layer=norm_layer)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
norm_layer=norm_layer)
self.avgpool = nn.AdaptiveAvgPool2D((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
# for m in self.modules():
# if isinstance(m, nn.Conv2D):
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
# elif isinstance(m, norm_layer):
# nn.init.constant_(m.weight, 1)
# nn.init.constant_(m.bias_attr, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilation=1, norm_layer=None,
is_first=True):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
down_layers = []
if self.avg_down:
if dilation == 1:
down_layers.append(nn.AvgPool2D(kernel_size=stride, stride=stride,
ceil_mode=True, count_include_pad=False))
else:
down_layers.append(nn.AvgPool2D(kernel_size=1, stride=1,
ceil_mode=True, count_include_pad=False))
down_layers.append(nn.Conv2D(self.inplanes, planes * block.expansion,
kernel_size=1, stride=1, bias_attr=False))
else:
down_layers.append(nn.Conv2D(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias_attr=False))
down_layers.append(norm_layer(planes * block.expansion))
downsample = nn.Sequential(*down_layers)
layers = []
if dilation == 1 or dilation == 2:
layers.append(block(self.inplanes, planes, stride, downsample=downsample,
cardinality=self.cardinality,
bottleneck_width=self.bottleneck_width,
avd=self.avd, dilation=1, is_first=is_first,
norm_layer=norm_layer))
elif dilation == 4:
layers.append(block(self.inplanes, planes, stride, downsample=downsample,
cardinality=self.cardinality,
bottleneck_width=self.bottleneck_width,
avd=self.avd, dilation=2, is_first=is_first,
norm_layer=norm_layer))
else:
raise RuntimeError("=> unknown dilation size: {}".format(dilation))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes,
cardinality=self.cardinality,
bottleneck_width=self.bottleneck_width,
avd=self.avd, dilation=dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.reshape([x.shape[0], -1])
x = self.fc(x)
return x
def scnet50(pretrained=False, **kwargs):
"""Constructs a SCNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = SCNet(SCBottleneck, [3, 4, 6, 3],
deep_stem=False, stem_width=32, avg_down=False,
avd=False, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['scnet50']))
return model
def scnet50_v1d(pretrained=False, **kwargs):
"""Constructs a SCNet-50_v1d model described in
`Bag of Tricks <https://arxiv.org/pdf/1812.01187.pdf>`_.
`ResNeSt: Split-Attention Networks <https://arxiv.org/pdf/2004.08955.pdf>`_.
Compared with default SCNet(SCNetv1b), SCNetv1d replaces the 7x7 conv
in the input stem with three 3x3 convs. And in the downsampling block,
a 3x3 avg_pool with stride 2 is added before conv, whose stride is
changed to 1.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = SCNet(SCBottleneck, [3, 4, 6, 3],
deep_stem=True, stem_width=32, avg_down=True,
avd=True, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['scnet50_v1d']))
return model
def scnet101(pretrained=False, **kwargs):
"""Constructs a SCNet-101 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = SCNet(SCBottleneck, [3, 4, 23, 3],
deep_stem=False, stem_width=64, avg_down=False,
avd=False, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['scnet101']))
return model
def scnet101_v1d(pretrained=False, **kwargs):
"""Constructs a SCNet-101_v1d model described in
`Bag of Tricks <https://arxiv.org/pdf/1812.01187.pdf>`_.
`ResNeSt: Split-Attention Networks <https://arxiv.org/pdf/2004.08955.pdf>`_.
Compared with default SCNet(SCNetv1b), SCNetv1d replaces the 7x7 conv
in the input stem with three 3x3 convs. And in the downsampling block,
a 3x3 avg_pool with stride 2 is added before conv, whose stride is
changed to 1.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = SCNet(SCBottleneck, [3, 4, 23, 3],
deep_stem=True, stem_width=64, avg_down=True,
avd=True, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['scnet101_v1d']))
return model
模型测试
if __name__ == '__main__':
images = paddle.rand([1, 3, 224, 224])
model = scnet101(pretrained=False)
a = model(images)
print(a.shape)
实例化模型
model = scnet101(num_classes=10,pretrained=False)
model = paddle.Model(model)
#优化器选择
class SaveBestModel(paddle.callbacks.Callback):
def __init__(self, target=0.5, path='work/best_model2', verbose=0):
self.target = target
self.epoch = None
self.path = path
def on_epoch_end(self, epoch, logs=None):
self.epoch = epoch
def on_eval_end(self, logs=None):
if logs.get('acc') > self.target:
self.target = logs.get('acc')
self.model.save(self.path)
print('best acc is {} at epoch {}'.format(self.target, self.epoch))
callback_visualdl = paddle.callbacks.VisualDL(log_dir='work/no_SA')
callback_savebestmodel = SaveBestModel(target=0.5, path='work/best_model1')
callbacks = [callback_visualdl, callback_savebestmodel]
base_lr = config_parameters['lr']
epochs = config_parameters['epochs']
def make_optimizer(parameters=None):
momentum = 0.9
learning_rate= paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=base_lr, T_max=epochs, verbose=False)
weight_decay=paddle.regularizer.L2Decay(0.0001)
optimizer = paddle.optimizer.Momentum(
learning_rate=learning_rate,
momentum=momentum,
weight_decay=weight_decay,
parameters=parameters)
return optimizer
optimizer = make_optimizer(model.parameters())
model.prepare(optimizer,
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
模型训练
model.fit(train_loader,
eval_loader,
epochs=10,
batch_size=1, # 是否打乱样本集
callbacks=callbacks,
verbose=1) # 日志展示格式
对比实验
- 本次对比实验选用层数相同地resnet101进行对比
model_2 = paddle.vision.models.resnet101(num_classes=10,pretrained=False)
model_2 = paddle.Model(model_2)
model_2.summary((1,3,256,256))
#优化器选择
class SaveBestModel(paddle.callbacks.Callback):
def __init__(self, target=0.5, path='work/best_model2', verbose=0):
self.target = target
self.epoch = None
self.path = path
def on_epoch_end(self, epoch, logs=None):
self.epoch = epoch
def on_eval_end(self, logs=None):
if logs.get('acc') > self.target:
self.target = logs.get('acc')
self.model.save(self.path)
print('best acc is {} at epoch {}'.format(self.target, self.epoch))
callback_visualdl = paddle.callbacks.VisualDL(log_dir='work/no_SA')
callback_savebestmodel = SaveBestModel(target=0.5, path='work/best_model2')
callbacks = [callback_visualdl, callback_savebestmodel]
base_lr = 0.01
epochs = config_parameters['epochs']
def make_optimizer(parameters=None):
momentum = 0.9
learning_rate= paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=base_lr, T_max=epochs, verbose=False)
weight_decay=paddle.regularizer.L2Decay(0.0001)
optimizer = paddle.optimizer.Momentum(
learning_rate=learning_rate,
momentum=momentum,
weight_decay=weight_decay,
parameters=parameters)
return optimizer
optimizer = make_optimizer(model_2.parameters())
model_2.prepare(optimizer,
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
model_2.fit(train_loader,
eval_loader,
epochs=10,
batch_size=1, # 是否打乱样本集
callbacks=callbacks,
ze=1, # 是否打乱样本集
callbacks=callbacks,
verbose=1) # 日志展示格式
总结
- 介绍并实现了 SCNet 模型,实现了模型对齐并实现了与resnet50的对比实验。
- 自校正卷积网络通过特征图下采样来增大CNN的感受野,使每个空间位置都可以通过自校准操作融合来自两个不同空间尺度空间的信息,有效地提升了自校正卷积产生特征地辨识性,从而达到更好地分类效果。
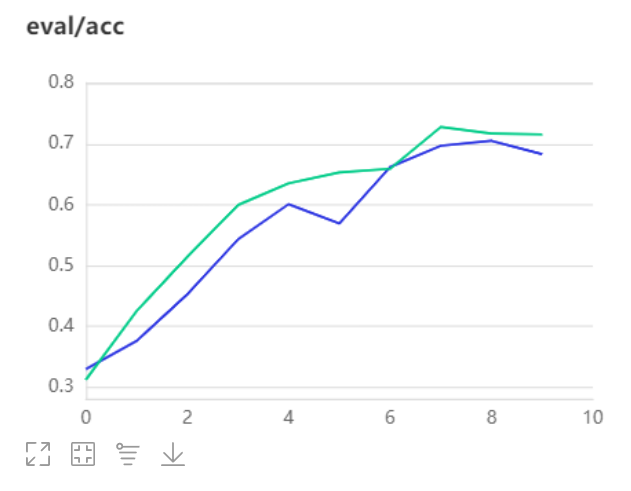
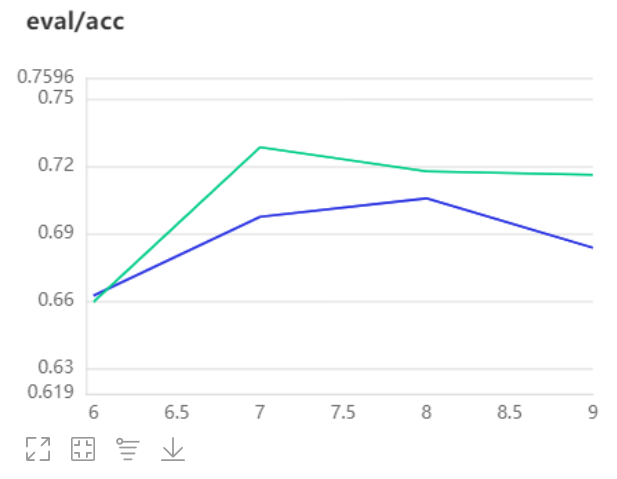
- 以下为本次实验结果,绿色曲线为SCNet101,蓝色曲线为Resnet101,很明显SCNet达到了更好地分类效果
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 3
3 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)