
基于PaddleClas的PP-LCNet模型的动物图像识别与分类
转自AI Studio,原文链接:基于PaddleClas的PP-LCNet模型的动物图像识别与分类 - 飞桨AI Studio一、基于PP-LCNet的动物图像识别与分类比赛地址和鲸社区 - Heywhale.com1.数据集介绍数据集是一个用于多分类任务的动物图像数据集,包含10种不同动物的图像。数据集来源由Google上的真实图像通过爬虫得到,图片尺寸大小以及格式不固定(包含jpg、jpeg
转自AI Studio,原文链接:基于PaddleClas的PP-LCNet模型的动物图像识别与分类 - 飞桨AI Studio
一、基于PP-LCNet的动物图像识别与分类
1.数据集介绍
数据集是一个用于多分类任务的动物图像数据集,包含10种不同动物的图像。数据集来源由Google上的真实图像通过爬虫得到,图片尺寸大小以及格式不固定(包含jpg、jpeg以及png三种图像格式),另外对敏感信息进行了脱敏处理。

1.1训练集
训练集文件夹名为train_data,共有17803张图像,文件夹中包含10个子文件夹,文件名分别是butterfly、cat、chicken、cow、dog、elephant、horse、ragno、sheep、squirrel,文件名为对应文件夹下图像的类别,选手需自行读取标签信息。每个子文件夹下包含若干图像文件,数量约为1000-5000。
1.2测试集
测试集文件夹名为test_data,文件夹中包含8150张图像,选手需根据训练集建立模型,对测试集文件进行预测分类。
2.PP-LCNet介绍
在工业界真实落地的场景中,推理速度才是考量模型好坏的重要指标,然而,推理速度和准确性很难兼得。考虑到工业界有很多基于 Intel CPU 的应用,所以我们本次的工作旨在使骨干网络更好的适应 Intel CPU,从而得到一个速度更快、准确率更高的轻量级骨干网络,与此同时,目标检测、语义分割等下游视觉任务的性能也同样得到提升。针对 Intel CPU 设备以及其加速库 MKLDNN 设计了特定的骨干网络 PP-LCNet,比起其他的轻量级的 SOTA 模型,该骨干网络可以在不增加推理时间的情况下,进一步提升模型的性能,最终大幅度超越现有的 SOTA 模型。


二、数据准备
1.解压缩数据
In [1]
!unzip -qoa data/data140388/traindata.zip -d data/
!unzip -qoa data/data140388/testdata.zip -d data/In [2]
!mv data/input/animal7479/* data/2.生成数据列表
In [3]
# paddlex安装
!pip install paddlex >log.logIn [4]
!paddlex --split_dataset --format ImageNet --dataset_dir data/train_data/train_data --val_value 0.2[04-21 09:55:30 MainThread @logger.py:242] Argv: /opt/conda/envs/python35-paddle120-env/bin/paddlex --split_dataset --format ImageNet --dataset_dir data/train_data/train_data --val_value 0.2 [04-21 09:55:30 MainThread @utils.py:79] WRN paddlepaddle version: 2.2.2. The dynamic graph version of PARL is under development, not fully tested and supported /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/parl/remote/communication.py:38: DeprecationWarning: 'pyarrow.default_serialization_context' is deprecated as of 2.0.0 and will be removed in a future version. Use pickle or the pyarrow IPC functionality instead. context = pyarrow.default_serialization_context() /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import MutableMapping /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Iterable, Mapping /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Sized 2022-04-21 09:55:34 [INFO] Dataset split starts... 2022-04-21 09:55:34 [INFO] Dataset split done. 2022-04-21 09:55:34 [INFO] Train samples: 14246 2022-04-21 09:55:34 [INFO] Eval samples: 3557 2022-04-21 09:55:34 [INFO] Test samples: 0 2022-04-21 09:55:34 [INFO] Split files saved in data/train_data/train_data
In [11]
with open('data/train_data/train_data/labels.txt','r') as f:
lines=f.readlines()
print(lines)
f_list=open('label_list.txt','w')
print(len(lines))
for i in range(len(lines)):
f_list.write(str(i)+' '+ lines[i])
f_list.close()['butterfly\n', 'cat\n', 'chicken\n', 'cow\n', 'dog\n', 'elephant\n', 'horse\n', 'ragno\n', 'sheep\n', 'squirrel\n'] 10
0.8的训练集,0.2的测试集。Train数量为: 14246、Eval 数量为: 3557
2022-04-20 01:02:48 [INFO] Train samples: 14246
2022-04-20 01:02:48 [INFO] Eval samples: 3557
2022-04-20 01:02:48 [INFO] Test samples: 0
二、环境准备
PaddleClas下载,计划使用PaddleClas中的 PP-LCNet 进行训练
In [5]
# !git clone https://gitee.com/paddlepaddle/PaddleClas.git --depth=1三、修改代码
1.修改配置
以 PaddleClas/ppcls/configs/ImageNet/PPLCNet/PPLCNet_x0_25.yaml 为基础进行配置
# global configs
Global:
checkpoints: null
pretrained_model: null
output_dir: ./output/
device: gpu
save_interval: 1
eval_during_train: True
eval_interval: 1
epochs: 300
print_batch_step: 10
use_visualdl: False
# used for static mode and model export
image_shape: [3, 224, 224]
save_inference_dir: ./inference
# model architecture
Arch:
name: PPLCNet_x0_25
class_num: 10
# loss function config for traing/eval process
Loss:
Train:
- CELoss:
weight: 1.0
epsilon: 0.1
Eval:
- CELoss:
weight: 1.0
Optimizer:
name: Momentum
momentum: 0.9
lr:
name: Cosine
learning_rate: 0.1
warmup_epoch: 10
regularizer:
name: 'L2'
coeff: 0.0001
# data loader for train and eval
DataLoader:
Train:
dataset:
name: ImageNetDataset
image_root: /home/aistudio/data/train_data/train_data/
cls_label_path: train_list.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- RandCropImage:
size: 224
- RandFlipImage:
flip_code: 1
- AutoAugment:
- NormalizeImage:
scale: 1.0/255.0
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
batch_transform_ops:
- CutmixOperator:
alpha: 0.2
sampler:
name: DistributedBatchSampler
batch_size: 2048
drop_last: False
shuffle: True
loader:
num_workers: 4
use_shared_memory: False
Eval:
dataset:
name: ImageNetDataset
image_root: /home/aistudio/data/train_data/train_data/
cls_label_path: val_list.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
sampler:
name: DistributedBatchSampler
batch_size: 1024
drop_last: False
shuffle: False
loader:
num_workers: 4
use_shared_memory: False
Infer:
infer_imgs: docs/images/inference_deployment/whl_demo.jpg
batch_size: 10
transforms:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
- ToCHWImage:
PostProcess:
name: Topk
topk: 5
class_id_map_file: ../label_list.txt
Metric:
Train:
- TopkAcc:
topk: [1, 5]
Eval:
- TopkAcc:
topk: [1, 5]
2.修改代码
修改self._cls_path为os.path.join(self._img_root,self._cls_path)
from __future__ import print_function
import numpy as np
import os
from .common_dataset import CommonDataset
class ImageNetDataset(CommonDataset):
def _load_anno(self, seed=None):
# print(self._cls_path)
# print(self._img_root)
# 修改
self._cls_path=os.path.join(self._img_root,self._cls_path)
assert os.path.exists(self._cls_path)
assert os.path.exists(self._img_root)
self.images = []
self.labels = []
with open(self._cls_path) as fd:
lines = fd.readlines()
if seed is not None:
np.random.RandomState(seed).shuffle(lines)
for l in lines:
l = l.strip().split(" ")
self.images.append(os.path.join(self._img_root, l[0]))
self.labels.append(np.int64(l[1]))
assert os.path.exists(self.images[-1])
四、模型训练
1.训练模型
没啥说的,配置文件都写好了,跑就完事了。当然配置文件主要做以下工作:
- 一是数据集地址更改
- 二是训练轮次、batch size更改
- 三是数据增强配置
2.注意事项
- 一是使用预训练模型,傻子才从头开始训练,懂得都懂,掌声响起来
- 二是不要使用aistudio中复制完整路径,因为复制了是错的
例如:/home/aistudio/PPLCNet_x0_25.yaml路径,会变为/home/aistudio/.jupyter/lab/workspaces/PPLCNet_x0_25.yaml,简直让你防不胜防。
!python3 tools/train.py \
-c /home/aistudio/.jupyter/lab/workspaces/PPLCNet_x0_25.yaml \
-o Arch.pretrained=False \
-o Global.device=gpu
/home/aistudio/PaddleClas
Traceback (most recent call last):
File "tools/train.py", line 29, in <module>
args.config, overrides=args.override, show=False)
File "/home/aistudio/PaddleClas/ppcls/utils/config.py", line 179, in get_config
'config file({}) is not exist'.format(fname))
AssertionError: config file(/home/aistudio/.jupyter/lab/workspaces/PPLCNet_x0_25.yaml) is not exist
In [ ]
%cd ~/PaddleClas/
# 复制修改后的imagenet_dataset.py到原位
!cp ../imagenet_dataset.py ./ppcls/data/dataloader/imagenet_dataset.py
# 开始训练
!python3 tools/train.py \
-c ../PPLCNet_x0_25.yaml \
-o Arch.pretrained=True \
-o Global.device=gpu74个epoch可达到91%的准确率,如时间宽裕,可继续提升准确率
[2022/04/21 02:48:33] root INFO: [Train][Epoch 74/300][Iter: 0/7]lr: 0.08875, CELoss: 0.86730, loss: 0.86730, batch_cost: 14.51762s, reader_cost: 12.59892, ips: 141.06996 images/sec, eta: 6:24:28
[2022/04/21 02:48:51] root INFO: [Train][Epoch 74/300][Avg]CELoss: 0.88821, loss: 0.88821
[2022/04/21 02:49:06] root INFO: [Eval][Epoch 74][Iter: 0/4]CELoss: 0.43258, loss: 0.43258, top1: 0.88574, top5: 0.98633, batch_cost: 14.79859s, reader_cost: 13.25228, ips: 69.19578 images/sec
[2022/04/21 02:49:07] root INFO: [Eval][Epoch 74][Avg]CELoss: 0.45654, loss: 0.45654, top1: 0.87855, top5: 0.99044
[2022/04/21 02:49:07] root INFO: [Eval][Epoch 74][best metric: 0.914815859962857]
[2022/04/21 02:49:07] root INFO: Already save model in ./output/PPLCNet_x0_25/epoch_74
[2022/04/21 02:49:07] root INFO: Already save model in ./output/PPLCNet_x0_25/latest
五、模型预测
1.模型导出
在上述模型导出命令中,所使用的配置文件需要与该模型的训练文件相同,在配置文件中有以下字段用于配置模型导出参数:
-
Global.image_shape:用于指定模型的输入数据尺寸,该尺寸不包含 batch 维度;
-
Global.save_inference_dir:用于指定导出的 inference 模型的保存位置;
-
Global.pretrained_model:用于指定训练过程中保存的模型权重文件路径,该路径无需包含模型权重文件后缀名 .pdparams。 上述命令将生成以下三个文件:
-
inference.pdmodel:用于存储网络结构信息;
-
inference.pdiparams:用于存储网络权重信息;
-
inference.pdiparams.info:用于存储模型的参数信息,在分类模型和识别模型中可忽略。
In [4]
%cd ~/PaddleClas/
!python tools/export_model.py \
-c ../PPLCNet_x0_25.yaml \
-o Global.pretrained_model=.//output/PPLCNet_x0_25/best_model \
-o Global.save_inference_dir=./deploy/models/class_PPLCNet_x0_25_ImageNet_infer/home/aistudio/PaddleClas [2022/04/21 12:39:48] root INFO: =========================================================== == PaddleClas is powered by PaddlePaddle ! == =========================================================== == == == For more info please go to the following website. == == == == https://github.com/PaddlePaddle/PaddleClas == =========================================================== [2022/04/21 12:39:48] root INFO: Arch : [2022/04/21 12:39:48] root INFO: class_num : 10 [2022/04/21 12:39:48] root INFO: name : PPLCNet_x0_25 [2022/04/21 12:39:48] root INFO: DataLoader : [2022/04/21 12:39:48] root INFO: Eval : [2022/04/21 12:39:48] root INFO: dataset : [2022/04/21 12:39:48] root INFO: cls_label_path : val_list.txt [2022/04/21 12:39:48] root INFO: image_root : /home/aistudio/data/train_data/train_data/ [2022/04/21 12:39:48] root INFO: name : ImageNetDataset [2022/04/21 12:39:48] root INFO: transform_ops : [2022/04/21 12:39:48] root INFO: DecodeImage : [2022/04/21 12:39:48] root INFO: channel_first : False [2022/04/21 12:39:48] root INFO: to_rgb : True [2022/04/21 12:39:48] root INFO: ResizeImage : [2022/04/21 12:39:48] root INFO: resize_short : 256 [2022/04/21 12:39:48] root INFO: CropImage : [2022/04/21 12:39:48] root INFO: size : 224 [2022/04/21 12:39:48] root INFO: NormalizeImage : [2022/04/21 12:39:48] root INFO: mean : [0.485, 0.456, 0.406] [2022/04/21 12:39:48] root INFO: order : [2022/04/21 12:39:48] root INFO: scale : 1.0/255.0 [2022/04/21 12:39:48] root INFO: std : [0.229, 0.224, 0.225] [2022/04/21 12:39:48] root INFO: loader : [2022/04/21 12:39:48] root INFO: num_workers : 4 [2022/04/21 12:39:48] root INFO: use_shared_memory : False [2022/04/21 12:39:48] root INFO: sampler : [2022/04/21 12:39:48] root INFO: batch_size : 1024 [2022/04/21 12:39:48] root INFO: drop_last : False [2022/04/21 12:39:48] root INFO: name : DistributedBatchSampler [2022/04/21 12:39:48] root INFO: shuffle : False [2022/04/21 12:39:48] root INFO: Train : [2022/04/21 12:39:48] root INFO: batch_transform_ops : [2022/04/21 12:39:48] root INFO: CutmixOperator : [2022/04/21 12:39:48] root INFO: alpha : 0.2 [2022/04/21 12:39:48] root INFO: dataset : [2022/04/21 12:39:48] root INFO: cls_label_path : train_list.txt [2022/04/21 12:39:48] root INFO: image_root : /home/aistudio/data/train_data/train_data/ [2022/04/21 12:39:48] root INFO: name : ImageNetDataset [2022/04/21 12:39:48] root INFO: transform_ops : [2022/04/21 12:39:48] root INFO: DecodeImage : [2022/04/21 12:39:48] root INFO: channel_first : False [2022/04/21 12:39:48] root INFO: to_rgb : True [2022/04/21 12:39:48] root INFO: RandCropImage : [2022/04/21 12:39:48] root INFO: size : 224 [2022/04/21 12:39:48] root INFO: RandFlipImage : [2022/04/21 12:39:48] root INFO: flip_code : 1 [2022/04/21 12:39:48] root INFO: AutoAugment : None [2022/04/21 12:39:48] root INFO: NormalizeImage : [2022/04/21 12:39:48] root INFO: mean : [0.485, 0.456, 0.406] [2022/04/21 12:39:48] root INFO: order : [2022/04/21 12:39:48] root INFO: scale : 1.0/255.0 [2022/04/21 12:39:48] root INFO: std : [0.229, 0.224, 0.225] [2022/04/21 12:39:48] root INFO: loader : [2022/04/21 12:39:48] root INFO: num_workers : 4 [2022/04/21 12:39:48] root INFO: use_shared_memory : False [2022/04/21 12:39:48] root INFO: sampler : [2022/04/21 12:39:48] root INFO: batch_size : 2048 [2022/04/21 12:39:48] root INFO: drop_last : False [2022/04/21 12:39:48] root INFO: name : DistributedBatchSampler [2022/04/21 12:39:48] root INFO: shuffle : True [2022/04/21 12:39:48] root INFO: Global : [2022/04/21 12:39:48] root INFO: checkpoints : None [2022/04/21 12:39:48] root INFO: device : gpu [2022/04/21 12:39:48] root INFO: epochs : 300 [2022/04/21 12:39:48] root INFO: eval_during_train : True [2022/04/21 12:39:48] root INFO: eval_interval : 1 [2022/04/21 12:39:48] root INFO: image_shape : [3, 224, 224] [2022/04/21 12:39:48] root INFO: output_dir : ./output/ [2022/04/21 12:39:48] root INFO: pretrained_model : .//output/PPLCNet_x0_25/best_model [2022/04/21 12:39:48] root INFO: print_batch_step : 10 [2022/04/21 12:39:48] root INFO: save_inference_dir : ./deploy/models/class_PPLCNet_x0_25_ImageNet_infer [2022/04/21 12:39:48] root INFO: save_interval : 1 [2022/04/21 12:39:48] root INFO: use_visualdl : False [2022/04/21 12:39:48] root INFO: Infer : [2022/04/21 12:39:48] root INFO: PostProcess : [2022/04/21 12:39:48] root INFO: class_id_map_file : ../label_list.txt [2022/04/21 12:39:48] root INFO: name : Topk [2022/04/21 12:39:48] root INFO: topk : 5 [2022/04/21 12:39:48] root INFO: batch_size : 10 [2022/04/21 12:39:48] root INFO: infer_imgs : docs/images/inference_deployment/whl_demo.jpg [2022/04/21 12:39:48] root INFO: transforms : [2022/04/21 12:39:48] root INFO: DecodeImage : [2022/04/21 12:39:48] root INFO: channel_first : False [2022/04/21 12:39:48] root INFO: to_rgb : True [2022/04/21 12:39:48] root INFO: ResizeImage : [2022/04/21 12:39:48] root INFO: resize_short : 256 [2022/04/21 12:39:48] root INFO: CropImage : [2022/04/21 12:39:48] root INFO: size : 224 [2022/04/21 12:39:48] root INFO: NormalizeImage : [2022/04/21 12:39:48] root INFO: mean : [0.485, 0.456, 0.406] [2022/04/21 12:39:48] root INFO: order : [2022/04/21 12:39:48] root INFO: scale : 1.0/255.0 [2022/04/21 12:39:48] root INFO: std : [0.229, 0.224, 0.225] [2022/04/21 12:39:48] root INFO: ToCHWImage : None [2022/04/21 12:39:48] root INFO: Loss : [2022/04/21 12:39:48] root INFO: Eval : [2022/04/21 12:39:48] root INFO: CELoss : [2022/04/21 12:39:48] root INFO: weight : 1.0 [2022/04/21 12:39:48] root INFO: Train : [2022/04/21 12:39:48] root INFO: CELoss : [2022/04/21 12:39:48] root INFO: epsilon : 0.1 [2022/04/21 12:39:48] root INFO: weight : 1.0 [2022/04/21 12:39:48] root INFO: Metric : [2022/04/21 12:39:48] root INFO: Eval : [2022/04/21 12:39:48] root INFO: TopkAcc : [2022/04/21 12:39:48] root INFO: topk : [1, 5] [2022/04/21 12:39:48] root INFO: Train : [2022/04/21 12:39:48] root INFO: TopkAcc : [2022/04/21 12:39:48] root INFO: topk : [1, 5] [2022/04/21 12:39:48] root INFO: Optimizer : [2022/04/21 12:39:48] root INFO: lr : [2022/04/21 12:39:48] root INFO: learning_rate : 0.1 [2022/04/21 12:39:48] root INFO: name : Cosine [2022/04/21 12:39:48] root INFO: warmup_epoch : 10 [2022/04/21 12:39:48] root INFO: momentum : 0.9 [2022/04/21 12:39:48] root INFO: name : Momentum [2022/04/21 12:39:48] root INFO: regularizer : [2022/04/21 12:39:48] root INFO: coeff : 0.0001 [2022/04/21 12:39:48] root INFO: name : L2 [2022/04/21 12:39:48] root INFO: train with paddle 2.2.2 and device CUDAPlace(0) W0421 12:39:48.412415 405 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1 W0421 12:39:48.417142 405 device_context.cc:465] device: 0, cuDNN Version: 7.6. /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return (isinstance(seq, collections.Sequence) and
2.模型预测配置
在配置文件 configs/inference_cls.yaml 中有以下字段用于配置预测参数:
- Global.infer_imgs:待预测的图片文件路径;
- Global.inference_model_dir:inference 模型文件所在目录,该目录下需要有文件 inference.pdmodel 和 inference.pdiparams 两个文件;
- Global.use_tensorrt:是否使用 TesorRT 预测引擎,默认为 False;
- Global.use_gpu:是否使用 GPU 预测,默认为 True;
- Global.enable_mkldnn:是否启用 MKL-DNN 加速库,默认为 False。注意 enable_mkldnn 与 use_gpu 同时为 True 时,将忽略 enable_mkldnn,而使用 GPU 预测;
- Global.use_fp16:是否启用 FP16,默认为 False;
- PreProcess:用于数据预处理配置;
- PostProcess:由于后处理配置;
- PostProcess.Topk.class_id_map_file:数据集 label 的映射文件,默认为 ./utils/imagenet1k_label_list.txt,该文件为 PaddleClas 所使用的 ImageNet 数据集 label 映射文件。
注意:
如果使用 VisionTransformer 系列模型,如 DeiT_384, ViT_384 等,请注意模型的输入数据尺寸,部分模型需要修改参数: PreProcess.resize_short=384, PreProcess.resize=384。
预测文件配置如下:
Global:
infer_imgs: "../data/testdata/testdata"
inference_model_dir: "./deploy/models/class_PPLCNet_x0_25_ImageNet_infer"
batch_size: 1
use_gpu: True
enable_mkldnn: True
cpu_num_threads: 10
enable_benchmark: True
use_fp16: False
ir_optim: True
use_tensorrt: False
gpu_mem: 8000
enable_profile: False
PreProcess:
transform_ops:
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 0.00392157
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
channel_num: 3
- ToCHWImage:
PostProcess:
main_indicator: Topk
Topk:
topk: 5
class_id_map_file: "../label_list.txt"
SavePreLabel:
save_dir: ./pre_label/Global:
infer_imgs: "../data/testdata/testdata"
inference_model_dir: "./deploy/models/class_PPLCNet_x0_25_ImageNet_infer"
batch_size: 1
use_gpu: True
enable_mkldnn: True
cpu_num_threads: 10
enable_benchmark: True
use_fp16: False
ir_optim: True
use_tensorrt: False
gpu_mem: 8000
enable_profile: False
PreProcess:
transform_ops:
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 0.00392157
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
channel_num: 3
- ToCHWImage:
PostProcess:
main_indicator: Topk
Topk:
topk: 5
class_id_map_file: "../label_list.txt"
SavePreLabel:
save_dir: ./pre_label/Global:
infer_imgs: "../data/testdata/testdata"
inference_model_dir: "./deploy/models/class_PPLCNet_x0_25_ImageNet_infer"
batch_size: 1
use_gpu: True
enable_mkldnn: True
cpu_num_threads: 10
enable_benchmark: True
use_fp16: False
ir_optim: True
use_tensorrt: False
gpu_mem: 8000
enable_profile: False
PreProcess:
transform_ops:
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 0.00392157
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
channel_num: 3
- ToCHWImage:
PostProcess:
main_indicator: Topk
Topk:
topk: 5
class_id_map_file: "../label_list.txt"
SavePreLabel:
save_dir: ./pre_label/
3.预测保存修改
直接修改预测脚本PaddleClas/deploy/python/predict_cls.py的main函数即可
def main(config):
cls_predictor = ClsPredictor(config)
image_list = get_image_list(config["Global"]["infer_imgs"])
batch_imgs = []
batch_names = []
cnt = 0
# 写入文件
f=open('result.csv','w')
f.write('name,label\n')
for idx, img_path in enumerate(image_list):
img = cv2.imread(img_path)
if img is None:
logger.warning(
"Image file failed to read and has been skipped. The path: {}".
format(img_path))
else:
img = img[:, :, ::-1]
batch_imgs.append(img)
img_name = os.path.basename(img_path)
batch_names.append(img_name)
cnt += 1
if cnt % config["Global"]["batch_size"] == 0 or (idx + 1
) == len(image_list):
if len(batch_imgs) == 0:
continue
batch_results = cls_predictor.predict(batch_imgs)
for number, result_dict in enumerate(batch_results):
filename = batch_names[number]
clas_ids = result_dict["class_ids"]
scores_str = "[{}]".format(", ".join("{:.2f}".format(
r) for r in result_dict["scores"]))
label_names = result_dict["label_names"]
print("{}:\tclass id(s): {}, score(s): {}, label_name(s): {}".
format(filename, clas_ids, scores_str, label_names))
# 保存预测
f.write(filename+','+label_names[0]+'\n')
batch_imgs = []
batch_names = []
if cls_predictor.benchmark:
cls_predictor.auto_logger.report()
return
In [ ]
# 覆盖原预测脚本
!cp ~/predict_cls.py ~/PaddleClas/deploy/python/
%cd ~/PaddleClas/
# 开始预测
!python ./deploy/python/predict_cls.py -c ../inference_cls.yaml预测日志
0.jpeg: class id(s): [1, 2, 9, 0, 3], score(s): [0.71, 0.07, 0.06, 0.04, 0.03], label_name(s): ['cat', 'chicken', 'squirrel', 'butterfly', 'cow']
1.jpeg: class id(s): [1, 4, 9, 2, 6], score(s): [0.78, 0.14, 0.02, 0.02, 0.01], label_name(s): ['cat', 'dog', 'squirrel', 'chicken', 'horse']
10.jpeg: class id(s): [2, 3, 4, 5, 6], score(s): [0.53, 0.15, 0.15, 0.06, 0.05], label_name(s): ['chicken', 'cow', 'dog', 'elephant', 'horse']
100.jpeg: class id(s): [1, 4, 9, 2, 0], score(s): [0.61, 0.16, 0.06, 0.04, 0.03], label_name(s): ['cat', 'dog', 'squirrel', 'chicken', 'butterfly']
1000.jpg: class id(s): [8, 2, 5, 0, 1], score(s): [0.74, 0.11, 0.03, 0.02, 0.02], label_name(s): ['sheep', 'chicken', 'elephant', 'butterfly', 'cat']
六、提交&总结
1.提交
下载PaddlleClas下的result.csv并提交
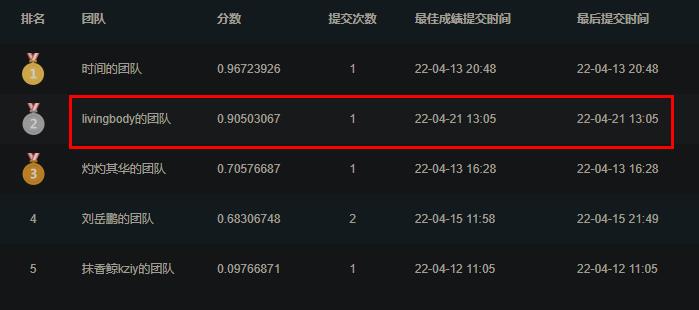
In [1]
%cd ~
!head ~/PaddleClas/result.csv/home/aistudio name,label 0.jpeg,cat 1.jpeg,cat 10.jpeg,chicken 100.jpeg,cat 1000.jpg,sheep 1001.jpg,sheep 1002.jpg,sheep 1003.jpg,sheep 1004.jpg,sheep
2.总结
- 一是选择训练模型,其中原数据脚本需要修改
- 二是预测,需修改预测脚本用于保存结果
- 三是可持续训练,以获取更好的成绩*

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 0
0 0
0- 0



 已为社区贡献1438条内容
已为社区贡献1438条内容

所有评论(0)