
基于PaddleNLP完成 千言情感分析————0.8014分方案
基于paddlenlp完成千言|情感分析比赛
千言|情感分析————0.7839分方案
比赛介绍:
情感分析旨在自动识别和提取文本中的倾向、立场、评价、观点等主观信息。它包含各式各样的任务,比如句子级情感分类、评价对象级情感分类、观点抽取、情绪分类等。情感分析是人工智能的重要研究方向,具有很高的学术价值。同时,情感分析在消费决策、舆情分析、个性化推荐等领域均有重要的应用,具有很高的商业价值。
近两年,NLP技术发展较快,一个趋势是大家不再过度关注模型在单一数据的效果,开始逐渐关注模型在多个数据集的效果。基于此,百度与多位研究学者一起收集和整理了一个综合、全面的中文情感分析评测数据集,希望能进一步提升情感分析的研究水平,推动自然语言理解和人工智能技术的应用和发展。
数据集
- 句子级情感分类——ChnSentiCorp(内置数据集)、NLPCC14-SC
- 评价对象级情感分类——SE-ABSA16_PHNS(内置数据集)、SE-ABSA16_CAME
- 观点抽取——COTE-BD、COTE-MFW、COTE-DP
比赛链接:
# 更新paddlenlp
!pip install --upgrade paddlenlp -i https://pypi.org/simple
ChnSenticorp(句子级)
对于给定的文本d,系统需要根据文本的内容,给出其对应的情感类别s,类别s一般只包含积极、消极两类,部分数据集还包括中性类别。数据集中每个样本是一个二元组 <d, s> ,样例如下:
输入文本(d):15.4寸笔记本的键盘确实爽,基本跟台式机差不多了,蛮喜欢数字小键盘,输数字特方便,样子也很美观,做工也相当不错
情感类别(s):积极
注:数据集中1表示积极,0表示消极。
数据加载
from paddlenlp.datasets import load_dataset
train_ds, dev_ds, test_ds = load_dataset("chnsenticorp", splits=["train", "dev", "test"])
print(train_ds[0])
print(dev_ds[0])
print(test_ds[0])
100%|██████████| 1909/1909 [00:00<00:00, 53122.75it/s]
{'text': '选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般', 'label': 1, 'qid': ''}
{'text': '這間酒店環境和服務態度亦算不錯,但房間空間太小~~不宣容納太大件行李~~且房間格調還可以~~ 中餐廳的廣東點心不太好吃~~要改善之~~~~但算價錢平宜~~可接受~~ 西餐廳格調都很好~~但吃的味道一般且令人等得太耐了~~要改善之~~', 'label': 1, 'qid': '0'}
{'text': '这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般', 'label': '', 'qid': '0'}
SKEP模型加载
数据处理
from paddlenlp.transformers import SkepForSequenceClassification, SkepTokenizer
# 指定模型名称一键加载模型
model = SkepForSequenceClassification.from_pretrained('skep_ernie_1.0_large_ch', num_classes=len(train_ds.label_list))
# 指定模型名称一键加载tokenizer
tokenizer = SkepTokenizer.from_pretrained('skep_ernie_1.0_large_ch')
import os
from functools import partial
import numpy as np
import paddle
import paddle.nn.functional as F
from paddlenlp.data import Stack, Tuple, Pad
from utils import create_dataloader
def convert_example(example,
tokenizer,
max_seq_length=512,
is_test=False):
# 将原数据处理成model可读入的格式,enocded_inputs是一个dict,包含input_ids、token_type_ids等字段
encoded_inputs = tokenizer(
text=example["text"], max_seq_len=max_seq_length)
# input_ids:对文本切分token后,在词汇表中对应的token id
input_ids = encoded_inputs["input_ids"]
# token_type_ids:当前token属于句子1还是句子2,即上述图中表达的segment ids
token_type_ids = encoded_inputs["token_type_ids"]
if not is_test:
# label:情感极性类别
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
else:
# qid:每条数据的编号
qid = np.array([example["qid"]], dtype="int64")
return input_ids, token_type_ids, qid
# 批量数据大小
batch_size = 32
# 文本序列最大长度
max_seq_length = 128
# 将数据处理成模型可读入的数据格式
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
# 将数据组成批量式数据,如
# 将不同长度的文本序列padding到批量式数据中最大长度
# 将每条数据label堆叠在一起
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack() # labels
): [data for data in fn(samples)]
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
dev_data_loader = create_dataloader(
dev_ds,
mode='dev',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
模型训练和评估
可尝试的超参设置:
- max_seq_length=256
- batch_size=48
- learning_rate=2e-5
- epochs=10
import time
from utils import evaluate
# 训练轮次(3+准确率便不再提高.接近1.可尝试修改其他参数)
epochs = 10
# 训练过程中保存模型参数的文件夹
ckpt_dir = "skep_ChnSentiCorp"
# len(train_data_loader)一轮训练所需要的step数
num_training_steps = len(train_data_loader) * epochs
# Adam优化器
optimizer = paddle.optimizer.AdamW(
learning_rate=2e-5,
parameters=model.parameters())
# 交叉熵损失函数
criterion = paddle.nn.loss.CrossEntropyLoss()
# accuracy评价指标
metric = paddle.metric.Accuracy()
# 开启训练
global_step = 0
tic_train = time.time()
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch
# 喂数据给model
logits = model(input_ids, token_type_ids)
# 计算损失函数值
loss = criterion(logits, labels)
# 预测分类概率值
probs = F.softmax(logits, axis=1)
# 计算acc
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 10 == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %.5f, accu: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, acc,
10 / (time.time() - tic_train)))
tic_train = time.time()
# 反向梯度回传,更新参数
loss.backward()
optimizer.step()
optimizer.clear_grad()
if global_step % 100 == 0:
save_dir = os.path.join(ckpt_dir, "model_%d" % global_step)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 评估当前训练的模型
evaluate(model, criterion, metric, dev_data_loader)
# 保存当前模型参数等
model.save_pretrained(save_dir)
# 保存tokenizer的词表等
tokenizer.save_pretrained(save_dir)
预测提交结果
使用训练得到的模型还可以对文本进行情感预测。
import numpy as np
import paddle
# 处理测试集数据
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
is_test=True)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment
Stack() # qid
): [data for data in fn(samples)]
test_data_loader = create_dataloader(
test_ds,
mode='test',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
# 根据实际运行情况,更换加载的参数路径
params_path = 'skep_ckp/model_3000/model_state.pdparams'
if params_path and os.path.isfile(params_path):
# 加载模型参数
state_dict = paddle.load(params_path)
model.set_dict(state_dict)
print("Loaded parameters from %s" % params_path)
label_map = {0: '0', 1: '1'}
results = []
# 切换model模型为评估模式,关闭dropout等随机因素
model.eval()
for batch in test_data_loader:
input_ids, token_type_ids, qids = batch
# 喂数据给模型
logits = model(input_ids, token_type_ids)
# 预测分类
probs = F.softmax(logits, axis=-1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
labels = [label_map[i] for i in idx]
qids = qids.numpy().tolist()
results.extend(zip(qids, labels))
res_dir = "./results"
if not os.path.exists(res_dir):
os.makedirs(res_dir)
# 写入预测结果
with open(os.path.join(res_dir, "ChnSentiCorp.tsv"), 'w', encoding="utf8") as f:
f.write("index\tprediction\n")
for qid, label in results:
f.write(str(qid[0])+"\t"+label+"\n")
NLPCC14-SC(句子级)
由于与ChnSentiCorp数据集同为句子级情感分类任务,所以主要步骤便不做注释
数据准备
不同于ChnSentiCorp数据集的是,NLPCC14-SC还未被纳入Paddle内置数据集,所以需从千言下载
#下载数据集
!wget https://dataset-bj.cdn.bcebos.com/qianyan/NLPCC14-SC.zip
# 解压数据集到 ./data 目录
!unzip ./NLPCC14-SC.zip -d ./data/
# 删除压缩包
!rm NLPCC14-SC.zip
- 训练集格式:

- 测试集格式:
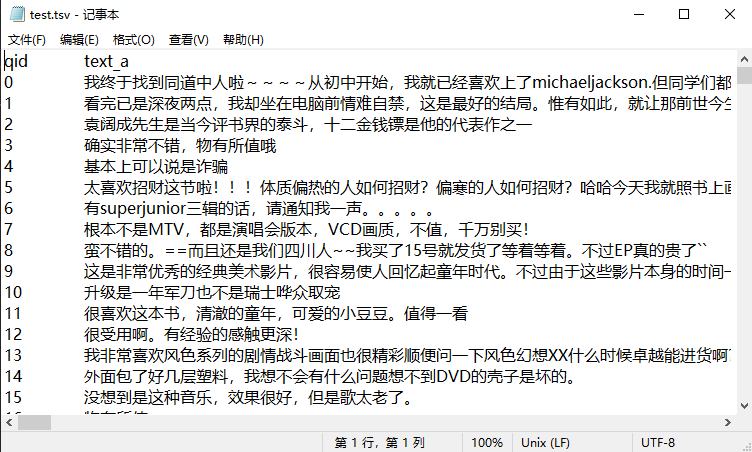
import paddlenlp
import random
# 查看NLPCC14-SC数据
# 创建NLPCC14-SC的训练集、测试集
train_ds, test_ds = [], []
# 观察上图可知训练集为两列:label text
with open("data/NLPCC14-SC/train.tsv", "r") as f:
lines = f.readlines() # 读取每行
for i in range(1, len(lines)): # 第0行为表头,所以从第1行开始~
label, text = lines[i].rstrip('\n').split('\t') # label和text中间是以tab隔开,每行换行隔开
train_ds.append({"text":text, "label":int(label), "qid":''}) # 将每条数据以键值对形式存入trian_ds 额外添加qid为了与测试集统一
f.close()
# 测试集与训练集格式相同
with open("data/NLPCC14-SC/test.tsv", "r") as f:
lines = f.readlines()
for i in range(1, len(lines)):
qid, text = lines[i].rstrip('\n').split('\t')
test_ds.append({"text":text, "qid":int(qid), "label":''}) # 将每条数据以键值对形式存入test_ds 额外添加label为了与训练集统一
f.close()
# 从训练集中分出20%作验证集
# 打乱训练集
random.shuffle(train_ds)
# print(len(train_ds)) 10000
# 取后2000条作为验证集
dev_ds = paddlenlp.datasets.dataset.MapDataset(train_ds[:2000])
# 取前8000条作为训练集
train_ds = paddlenlp.datasets.dataset.MapDataset(train_ds[8000:])
# 测试集不动
test_ds = paddlenlp.datasets.dataset.MapDataset(test_ds)
print("训练集数据(3:")
for idx, example in enumerate(train_ds):
if idx < 3:
print(example)
print("验证集数据(3:")
for idx, example in enumerate(dev_ds):
if idx < 3:
print(example)
print("测试集数据(3:")
for idx, example in enumerate(test_ds):
if idx < 3:
print(example)
训练集数据(3:
{'text': '实战技巧与实战分析有不一致的地方。 每篇章的技术内容含量太少,尽是过去式的实战技巧。实战分析前后也有不一致的观点。 都是过去时,是否短线点金(之二)、短线点金(之三)能结合现在股市实况讲点有实质性邦助的内容?', 'label': 0, 'qid': ''}
{'text': '说是要多中国不高兴说不,又不承认是跟风之作,看了遍书目,严重文不对题,扯得很远。看来这6位自封的知名学者不高兴了。呵呵。另外======================================编辑推荐章诒和 黎鸣 王文元 李建军 周非 贺雄飞五位著名学者对《中国不高兴》联手说不,探寻中国兴衰的深层历史文化原因 ===========================================明明六位,却写成五位,请问其中哪位是非著名学者?编辑也够水的了。', 'label': 0, 'qid': ''}
{'text': '经典的老曲子', 'label': 1, 'qid': ''}
验证集数据(3:
{'text': '看了各位初学者的评论后才买的,不像大家所学的入门容易,如前一位评论者说到,没涉及细节,分解,入门要掌握要领不容易,非常失望', 'label': 0, 'qid': ''}
{'text': '太好了!!!', 'label': 0, 'qid': ''}
{'text': '一到货就在单位试了,敏感调节到最右边了,才能有时准,有时多。座在凳子上转两圈也计数。', 'label': 1, 'qid': ''}
测试集数据(3:
{'text': '我终于找到同道中人啦~~~~从初中开始,我就已经喜欢上了michaeljackson.但同学们都用鄙夷的眼光看我,他们人为jackson的样子古怪甚至说"丑".我当场气晕.但现在有同道中人了,我好开心!!!michaeljacksonisthemostsuccessfulsingerintheworld!!~~~', 'qid': 0, 'label': ''}
{'text': '看完已是深夜两点,我却坐在电脑前情难自禁,这是最好的结局。惟有如此,就让那前世今生的纠结就停留在此刻。再相逢时,愿他的人生不再让人唏嘘,他们的身心也会只居一处。可是还是痛心为这样的人,这样的爱……', 'qid': 1, 'label': ''}
{'text': '袁阔成先生是当今评书界的泰斗,十二金钱镖是他的代表作之一', 'qid': 2, 'label': ''}
以下步骤同ChnSentiCorp
from paddlenlp.transformers import SkepForSequenceClassification, SkepTokenizer
# 指定模型名称,一键加载模型
model = SkepForSequenceClassification.from_pretrained(pretrained_model_name_or_path="skep_ernie_1.0_large_ch", num_classes=8000) # 注意num_classes
# 同样地,通过指定模型名称一键加载对应的Tokenizer,用于处理文本数据,如切分token,转token_id等。
tokenizer = SkepTokenizer.from_pretrained(pretrained_model_name_or_path="skep_ernie_1.0_large_ch")
[2021-06-19 13:02:27,350] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.pdparams
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.weight. classifier.weight is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.bias. classifier.bias is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
[2021-06-19 13:02:32,067] [ INFO] - Found /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.vocab.txt
def convert_example(example,
tokenizer,
max_seq_length=512,
is_test=False):
# 将原数据处理成model可读入的格式,enocded_inputs是一个dict,包含input_ids、token_type_ids等字段
encoded_inputs = tokenizer(
text=example["text"], max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"]
if not is_test:
# label:情感极性类别
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
else:
# qid:每条数据的编号
qid = np.array([example["qid"]], dtype="int64")
return input_ids, token_type_ids, qid
import os
from functools import partial
import numpy as np
import paddle
import paddle.nn.functional as F
from paddlenlp.data import Stack, Tuple, Pad
from utils import create_dataloader
# 批量数据大小
batch_size = 32
# 文本序列最大长度
max_seq_length = 128
# 将数据处理成模型可读入的数据格式
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
# 将数据组成批量式数据,如
# 将不同长度的文本序列padding到批量式数据中最大长度
# 将每条数据label堆叠在一起
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack() # labels
): [data for data in fn(samples)]
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
dev_data_loader = create_dataloader(
dev_ds,
mode='dev',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
import time
from utils import evaluate
# 训练轮次
epochs = 10
# 训练过程中保存模型参数的文件夹
ckpt_dir = "skep_NLPCC14-SC"
# len(train_data_loader)一轮训练所需要的step数
num_training_steps = len(train_data_loader) * epochs
# Adam优化器
optimizer = paddle.optimizer.AdamW(
learning_rate=1e-5,
parameters=model.parameters())
# 交叉熵损失函数
criterion = paddle.nn.loss.CrossEntropyLoss()
# accuracy评价指标
metric = paddle.metric.Accuracy()
# 开启训练
global_step = 0
tic_train = time.time()
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch
# 喂数据给model
logits = model(input_ids, token_type_ids)
# 计算损失函数值
loss = criterion(logits, labels)
# 预测分类概率值
probs = F.softmax(logits, axis=1)
# 计算acc
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 10 == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %.5f, accu: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, acc,
10 / (time.time() - tic_train)))
tic_train = time.time()
# 反向梯度回传,更新参数
loss.backward()
optimizer.step()
optimizer.clear_grad()
if global_step % 100 == 0:
save_dir = os.path.join(ckpt_dir, "model_%d" % global_step)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 评估当前训练的模型
evaluate(model, criterion, metric, dev_data_loader)
# 保存当前模型参数等
model.save_pretrained(save_dir)
# 保存tokenizer的词表等
tokenizer.save_pretrained(save_dir)
import numpy as np
import paddle
# 处理测试集数据
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
is_test=True)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment
Stack() # qid
): [data for data in fn(samples)]
test_data_loader = create_dataloader(
test_ds,
mode='test',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
label_map = {0: '0', 1: '1'}
results = []
# 切换model模型为评估模式,关闭dropout等随机因素
model.eval()
for batch in test_data_loader:
input_ids, token_type_ids, qids = batch
# 喂数据给模型
logits = model(input_ids, token_type_ids)
# 预测分类
probs = F.softmax(logits, axis=-1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
labels = [label_map[i] for i in idx]
qids = qids.numpy().tolist()
results.extend(zip(qids, labels))
# 根据实际运行情况,更换加载的参数路径
params_path = 'skep_NLPCC14-SC/model_600/model_state.pdparams'
if params_path and os.path.isfile(params_path):
# 加载模型参数
state_dict = paddle.load(params_path)
model.set_dict(state_dict)
print("Loaded parameters from %s" % params_path)
res_dir = "./results"
if not os.path.exists(res_dir):
os.makedirs(res_dir)
# 写入预测结果
with open(os.path.join(res_dir, "NLPCC14-SC.tsv"), 'w', encoding="utf8") as f:
f.write("index\tprediction\n")
for qid, label in results:
f.write(str(qid[0])+"\t"+label+"\n")
SE-ABSA16_PHNS(评价对象级)
对于给定的文本d和文本中描述的一个评价对象a,给出针对该评价对象a的情感类别s,类别s一般只包含积极、消极两类,部分数据集涵盖更细粒度的分类体系。数据集中每个样本是一个三元组<d, a, s>,样例如下:
输入文本(d):D4外形设计真的很成功不知道楼主摸没摸过D4真机非常成功的设计本以为D3系列很难超越了但是D4的流线风格显然不比D3差在整体感上还更胜一筹
评价对象(a):相机外形设计
情感类别(s):积极
注:数据集中1表示积极,0表示消极。
数据加载
from paddlenlp.datasets import load_dataset
# SE-ABSA16_PHNS数据集无验证集,可仿照NLPCC14-SC将训练集拆分20%作测试集
train_ds, test_ds = load_dataset("seabsa16", "phns", splits=["train", "test"])
print(train_ds[0])
print(test_ds[0])
100%|██████████| 381/381 [00:00<00:00, 25949.63it/s]
{'text': 'phone#design_features', 'text_pair': '今天有幸拿到了港版白色iPhone 5真机,试玩了一下,说说感受吧:1. 真机尺寸宽度与4/4s保持一致没有变化,长度多了大概一厘米,也就是之前所说的多了一排的图标。2. 真机重量比上一代轻了很多,个人感觉跟i9100的重量差不多。(用惯上一代的朋友可能需要一段时间适应了)3. 由于目前还没有版的SIM卡,无法插卡使用,有购买的朋友要注意了,并非简单的剪卡就可以用,而是需要去运营商更换新一代的SIM卡。4. 屏幕显示效果确实比上一代有进步,不论是从清晰度还是不同角度的视角,iPhone 5绝对要更上一层,我想这也许是相对上一代最有意义的升级了。5. 新的数据接口更小,比上一代更好用更方便,使用的过程会有这样的体会。6. 从简单的几个操作来讲速度比4s要快,这个不用测试软件也能感受出来,比如程序的调用以及照片的拍摄和浏览。不过,目前水货市场上坑爹的价格,最好大家可以再观望一下,不要急着出手。', 'label': 1}
{'text': 'software#usability', 'text_pair': '刚刚入手8600,体会。刚刚从淘宝购买,1635元(包邮)。1、全新,应该是欧版机,配件也是正品全新。2、在三星官网下载了KIES,可用免费软件非常多,绝对够用。3、不到2000元能买到此种手机,知足了。'}
SKEP模型加载
from paddlenlp.transformers import SkepForSequenceClassification, SkepTokenizer
# 指定模型名称一键加载模型
model = SkepForSequenceClassification.from_pretrained('skep_ernie_1.0_large_ch', num_classes=len(train_ds.label_list))
# 指定模型名称一键加载tokenizer
tokenizer = SkepTokenizer.from_pretrained('skep_ernie_1.0_large_ch')
数据处理
def convert_example(example,
tokenizer,
max_seq_length=512,
is_test=False):
# 将原数据处理成model可读入的格式,enocded_inputs是一个dict,包含input_ids、token_type_ids等字段
encoded_inputs = tokenizer(
text=example["text"],
text_pair=example["text_pair"],
max_seq_len=max_seq_length)
# input_ids:对文本切分token后,在词汇表中对应的token id
input_ids = encoded_inputs["input_ids"]
# token_type_ids:当前token属于句子1还是句子2,即上述图中表达的segment ids
token_type_ids = encoded_inputs["token_type_ids"]
if not is_test:
# label:情感极性类别
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
else:
return input_ids, token_type_ids
import os
from functools import partial
import numpy as np
import paddle
import paddle.nn.functional as F
from paddlenlp.data import Stack, Tuple, Pad
from utils import create_dataloader
# 处理的最大文本序列长度
max_seq_length=256
# 批量数据大小(32会爆)
batch_size=16
# 将数据处理成model可读入的数据格式
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
# 将数据组成批量式数据,如
# 将不同长度的文本序列padding到批量式数据中最大长度
# 将每条数据label堆叠在一起
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack(dtype="int64") # labels
): [data for data in fn(samples)]
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
模型训练
import time
# 训练轮次(感觉10层往上还能继续提升acc,可以再加)
epochs = 10
# 总共需要训练的step数
num_training_steps = len(train_data_loader) * epochs
# 优化器
optimizer = paddle.optimizer.AdamW(
learning_rate=5e-5,
parameters=model.parameters())
# 交叉熵损失
criterion = paddle.nn.loss.CrossEntropyLoss()
# Accuracy评价指标
metric = paddle.metric.Accuracy()
# 开启训练
ckpt_dir = "skep_SE-ABSA16_PHNS"
global_step = 0
tic_train = time.time()
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch
# 喂数据给model
logits = model(input_ids, token_type_ids)
# 计算损失函数值
loss = criterion(logits, labels)
# 预测分类概率
probs = F.softmax(logits, axis=1)
# 计算acc
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 10 == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %.5f, acc: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, acc,
10 / (time.time() - tic_train)))
tic_train = time.time()
# 反向梯度回传,更新参数
loss.backward()
optimizer.step()
optimizer.clear_grad()
if global_step % 100 == 0:
save_dir = os.path.join(ckpt_dir, "model_%d" % global_step)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 未分验证集,所以没有评估
# 保存模型参数
model.save_pretrained(save_dir)
# 保存tokenizer的词表等
tokenizer.save_pretrained(save_dir)
预测提交结果
使用训练得到的模型还可以对评价对象进行情感预测。
@paddle.no_grad()
def predict(model, data_loader, label_map):
model.eval()
results = []
for batch in data_loader:
input_ids, token_type_ids = batch
logits = model(input_ids, token_type_ids)
probs = F.softmax(logits, axis=1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
labels = [label_map[i] for i in idx]
results.extend(labels)
return results
# 处理测试集数据
label_map = {0: '0', 1: '1'}
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
is_test=True)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
): [data for data in fn(samples)]
test_data_loader = create_dataloader(
test_ds,
mode='test',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
# 根据实际运行情况,更换加载的参数路径
params_path = 'skep_SE-ABSA16_PHNS/model_800/model_state.pdparams'
if params_path and os.path.isfile(params_path):
# 加载模型参数
state_dict = paddle.load(params_path)
model.set_dict(state_dict)
print("Loaded parameters from %s" % params_path)
results = predict(model, test_data_loader, label_map)
Loaded parameters from skep_SE-ABSA16_PHNS/model_800/model_state.pdparams
with open(os.path.join("results", "SE-ABSA16_PHNS.tsv"), 'w', encoding="utf8") as f:
f.write("index\tprediction\n")
for idx, label in enumerate(results):
f.write(str(idx)+"\t"+label+"\n")
SE-ABSA16_CAME(评价对象级)
由于与SE-ABSA16_PHNS数据集同为评价对象级情感分类任务,所以主要步骤便不做注释
数据准备
不同于SE-ABSA16_PHNS数据集的是,SE-ABSA16_CAME还未被纳入Paddle内置数据集,所以需从千言下载
#下载数据集
!wget https://dataset-bj.cdn.bcebos.com/qianyan/SE-ABSA16_CAME.zip
# 解压数据集到 ./data 目录
!unzip ./SE-ABSA16_CAME.zip -d ./data/
# 删除压缩包
!rm SE-ABSA16_CAME.zip
- 训练集数据格式:
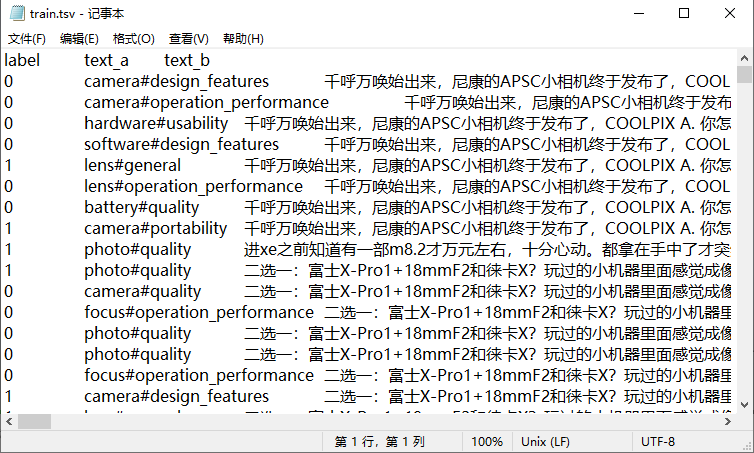
- 测试集数据格式:

import paddlenlp
# 查看# 查看SE-ABSA16_CAME数据 创建SE-ABSA16_CAME的训练集、测试集
# SE-ABSA16_PHNS数据集无验证集,可仿照NLPCC14-SC将训练集拆分20%作测试集
train_ds, test_ds = [], []
with open("data/SE-ABSA16_CAME/train.tsv", "r") as f:
lines = f.readlines()
for i in range(1, len(lines)):
label, text, text_pair = lines[i].rstrip('\n').split('\t')
train_ds.append({"text":text, "label":int(label), "text_pair":text_pair})
f.close()
with open("data/SE-ABSA16_CAME/test.tsv", "r") as f:
lines = f.readlines()
for i in range(1, len(lines)):
qid, text, text_pair = lines[i].rstrip('\n').split('\t')
test_ds.append({"text":text, "qid":int(qid), "text_pair":text_pair})
f.close()
train_ds = paddlenlp.datasets.dataset.MapDataset(train_ds)
test_ds = paddlenlp.datasets.dataset.MapDataset(test_ds)
# 由于单条数据内容较多,所以不做展示
print("训练集数据(3:")
for idx, example in enumerate(train_ds):
if idx < 3:
print(example)
print("测试集数据(3:")
for idx, example in enumerate(test_ds):
if idx < 3:
print(example)
以下步骤同SE-ABSA16_PHNS
# 指定模型名称一键加载模型
model = SkepForSequenceClassification.from_pretrained('skep_ernie_1.0_large_ch', num_classes=len(train_ds)) # 注意num_classes
# 指定模型名称一键加载tokenizer
tokenizer = SkepTokenizer.from_pretrained('skep_ernie_1.0_large_ch')
[2021-06-19 14:35:48,996] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.pdparams
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.weight. classifier.weight is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.bias. classifier.bias is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
[2021-06-19 14:35:53,635] [ INFO] - Found /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.vocab.txt
def convert_example(example,
tokenizer,
max_seq_length=512,
is_test=False):
encoded_inputs = tokenizer(
text=example["text"],
text_pair=example["text_pair"],
max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"]
if not is_test:
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
else:
return input_ids, token_type_ids
# 处理的最大文本序列长度
max_seq_length=256
# 批量数据大小(32会爆)
batch_size=16
# 将数据处理成model可读入的数据格式
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
# 将数据组成批量式数据,如
# 将不同长度的文本序列padding到批量式数据中最大长度
# 将每条数据label堆叠在一起
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack(dtype="int64") # labels
): [data for data in fn(samples)]
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
# 训练轮次(感觉10层往上还能继续提升acc,可以再加)
epochs = 10
# 总共需要训练的step数
num_training_steps = len(train_data_loader) * epochs
# 优化器
optimizer = paddle.optimizer.AdamW(
learning_rate=5e-5,
parameters=model.parameters())
# 交叉熵损失
criterion = paddle.nn.loss.CrossEntropyLoss()
# Accuracy评价指标
metric = paddle.metric.Accuracy()
# 开启训练
ckpt_dir = "skep_SE-ABSA16_CAME"
global_step = 0
tic_train = time.time()
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch
# 喂数据给model
logits = model(input_ids, token_type_ids)
# 计算损失函数值
loss = criterion(logits, labels)
# 预测分类概率
probs = F.softmax(logits, axis=1)
# 计算acc
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 10 == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %.5f, acc: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, acc,
10 / (time.time() - tic_train)))
tic_train = time.time()
# 反向梯度回传,更新参数
loss.backward()
optimizer.step()
optimizer.clear_grad()
if global_step % 100 == 0:
save_dir = os.path.join(ckpt_dir, "model_%d" % global_step)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 未分验证集,所以没有评估
# 保存模型参数
model.save_pretrained(save_dir)
# 保存tokenizer的词表等
tokenizer.save_pretrained(save_dir)
@paddle.no_grad()
def predict(model, data_loader, label_map):
"""
Given a prediction dataset, it gives the prediction results.
Args:
model(obj:`paddle.nn.Layer`): A model to classify texts.
data_loader(obj:`paddle.io.DataLoader`): The dataset loader which generates batches.
label_map(obj:`dict`): The label id (key) to label str (value) map.
"""
model.eval()
results = []
for batch in data_loader:
input_ids, token_type_ids = batch
logits = model(input_ids, token_type_ids)
probs = F.softmax(logits, axis=1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
labels = [label_map[i] for i in idx]
results.extend(labels)
return results
# 处理测试集数据
label_map = {0: '0', 1: '1'}
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
is_test=True)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
): [data for data in fn(samples)]
test_data_loader = create_dataloader(
test_ds,
mode='test',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
# 根据实际运行情况,更换加载的参数路径
params_path = 'skep_SE-ABSA16_CAME/model_800/model_state.pdparams'
if params_path and os.path.isfile(params_path):
# 加载模型参数
state_dict = paddle.load(params_path)
model.set_dict(state_dict)
print("Loaded parameters from %s" % params_path)
results = predict(model, test_data_loader, label_map)
Loaded parameters from skep_SE-ABSA16_CAME/model_800/model_state.pdparams
with open(os.path.join("results", "SE-ABSA16_CAME.tsv"), 'w', encoding="utf8") as f:
f.write("index\tprediction\n")
for idx, label in enumerate(results):
f.write(str(idx)+"\t"+label+"\n")
COTE-BD ~ COTE-MFW ~ COTE-DP(观点抽取)
对于给定的文本d,系统需要根据文本的内容,给出其中描述的评价对象a,其中评价对象一定在文本d中出现。数据集中每个样本是一个二元组<d, a>,样例如下:
输入文本(d):重庆老灶火锅还是很赞的,有机会可以尝试一下!
评价对象(a):重庆老灶火锅
# 载入模型和Tokenizer
import paddlenlp
from paddlenlp.transformers import SkepForTokenClassification, SkepTokenizer
#下载数据集
!wget https://dataset-bj.cdn.bcebos.com/qianyan/COTE-BD.zip
!wget https://dataset-bj.cdn.bcebos.com/qianyan/COTE-MFW.zip
!wget https://dataset-bj.cdn.bcebos.com/qianyan/COTE-DP.zip
# 解压数据集到 ./data 目录
!unzip ./COTE-BD.zip -d ./data/
!unzip ./COTE-MFW.zip -d ./data/
!unzip ./COTE-DP.zip -d ./data/
# 删除压缩包
!rm COTE-BD.zip
!rm COTE-MFW.zip
!rm COTE-DP.zip
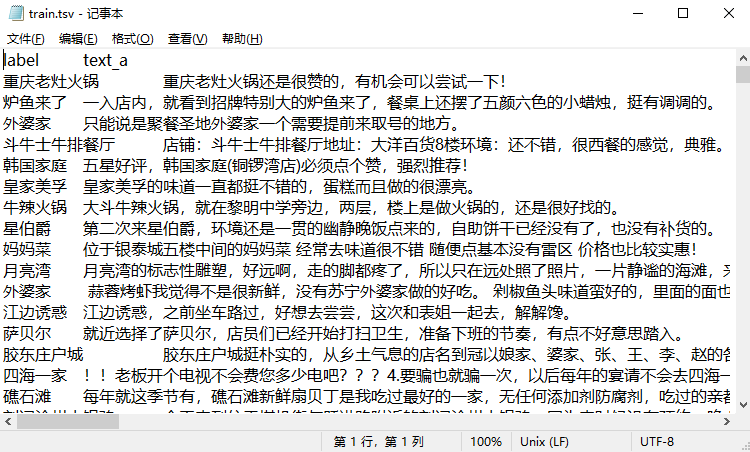
由于三个数据集格式相同,以COTE-DP为例展示数据集格式
-
训练集:
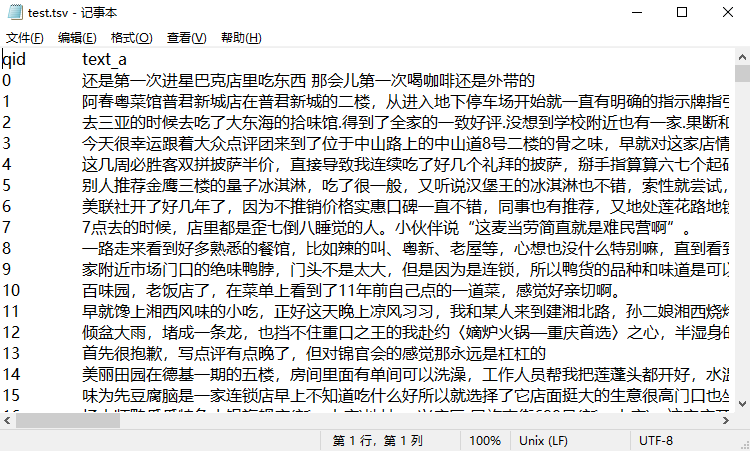
-
测试集:
# 得到数据集字典
def open_func(file_path):
return [line.strip() for line in open(file_path, 'r', encoding='utf8').readlines()[1:] if len(line.strip().split('\t')) >= 2]
data_dict = {'cotebd': {'test': open_func('data/COTE-BD/test.tsv'),
'train': open_func('data/COTE-BD/train.tsv')},
'cotedp': {'test': open_func('data/COTE-DP/test.tsv'),
'train': open_func('data/COTE-DP/train.tsv')},
'cotemfw': {'test': open_func('data/COTE-MFW/test.tsv'),
'train': open_func('data/COTE-MFW/train.tsv')}}
# 定义数据读取器
# 定义数据集
from paddle.io import Dataset, DataLoader
from paddlenlp.data import Pad, Stack, Tuple
import numpy as np
label_list = {'B': 0, 'I': 1, 'O': 2}
index2label = {0: 'B', 1: 'I', 2: 'O'}
# 考虑token_type_id
class MyDataset(Dataset):
def __init__(self, data, tokenizer, max_len=512, for_test=False):
super().__init__()
self._data = data
self._tokenizer = tokenizer
self._max_len = max_len
self._for_test = for_test
def __len__(self):
return len(self._data)
def __getitem__(self, idx):
samples = self._data[idx].split('\t')
label = samples[-2]
text = samples[-1]
if self._for_test:
origin_enc = self._tokenizer.encode(text, max_seq_len=self._max_len)['input_ids']
return np.array(origin_enc, dtype='int64')
else:
# 由于并不是每个字都是一个token,这里采用一种简单的处理方法,先编码label,再编码text中除了label以外的词,最后合到一起
texts = text.split(label)
label_enc = self._tokenizer.encode(label)['input_ids']
cls_enc = label_enc[0]
sep_enc = label_enc[-1]
label_enc = label_enc[1:-1]
# 合并
origin_enc = []
label_ids = []
for index, text in enumerate(texts):
text_enc = self._tokenizer.encode(text)['input_ids']
text_enc = text_enc[1:-1]
origin_enc += text_enc
label_ids += [label_list['O']] * len(text_enc)
if index != len(texts) - 1:
origin_enc += label_enc
label_ids += [label_list['B']] + [label_list['I']] * (len(label_enc) - 1)
origin_enc = [cls_enc] + origin_enc + [sep_enc]
label_ids = [label_list['O']] + label_ids + [label_list['O']]
# 截断
if len(origin_enc) > self._max_len:
origin_enc = origin_enc[:self._max_len-1] + origin_enc[-1:]
label_ids = label_ids[:self._max_len-1] + label_ids[-1:]
return np.array(origin_enc, dtype='int64'), np.array(label_ids, dtype='int64')
def batchify_fn(for_test=False):
if for_test:
return lambda samples, fn=Pad(axis=0, pad_val=tokenizer.pad_token_id): np.row_stack([data for data in fn(samples)])
else:
return lambda samples, fn=Tuple(Pad(axis=0, pad_val=tokenizer.pad_token_id),
Pad(axis=0, pad_val=label_list['O'])): [data for data in fn(samples)]
def get_data_loader(data, tokenizer, batch_size=32, max_len=512, for_test=False):
dataset = MyDataset(data, tokenizer, max_len, for_test)
shuffle = True if not for_test else False
data_loader = DataLoader(dataset=dataset, batch_size=batch_size, collate_fn=batchify_fn(for_test), shuffle=shuffle)
return data_loader
# 模型搭建
import paddle
from paddle.static import InputSpec
from paddlenlp.metrics import Perplexity
# 模型和分词
model = SkepForTokenClassification.from_pretrained('skep_ernie_1.0_large_ch', num_classes=3)
tokenizer = SkepTokenizer.from_pretrained('skep_ernie_1.0_large_ch')
# 参数设置
data_name = 'cotemfw' # 更改此选项改变数据集
## 训练相关
epochs = 1
learning_rate = 2e-5
batch_size = 8
max_len = 512
## 数据相关
train_dataloader = get_data_loader(data_dict[data_name]['train'], tokenizer, batch_size, max_len, for_test=False)
input = InputSpec((-1, -1), dtype='int64', name='input')
label = InputSpec((-1, -1, 3), dtype='int64', name='label')
model = paddle.Model(model, [input], [label])
# 模型准备
optimizer = paddle.optimizer.Adam(learning_rate=learning_rate, parameters=model.parameters())
model.prepare(optimizer, loss=paddle.nn.CrossEntropyLoss(), metrics=[Perplexity()])
[2021-06-18 21:07:34,824] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.pdparams
[2021-06-18 21:07:39,431] [ INFO] - Found /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.vocab.txt
model.fit(train_dataloader, batch_size=batch_size, epochs=epochs, save_freq=5, save_dir='./checkpoints', log_freq=200)
# 导入预训练模型
checkpoint_path = './checkpoints/final' # 填写预训练模型的保存路径
model = SkepForTokenClassification.from_pretrained('skep_ernie_1.0_large_ch', num_classes=3)
input = InputSpec((-1, -1), dtype='int64', name='input')
model = paddle.Model(model, [input])
model.load(checkpoint_path)
# 导入测试集
test_dataloader = get_data_loader(data_dict[data_name]['test'], tokenizer, batch_size, max_len, for_test=True)
# 预测保存
save_file = {'cotebd': './results/COTE_BD.tsv', 'cotedp': './results/COTE_DP.tsv', 'cotemfw': './results/COTE_MFW.tsv'}
predicts = []
input_ids = []
for batch in test_dataloader:
predict = model.predict_batch(batch)
predicts += predict[0].argmax(axis=-1).tolist()
input_ids += batch.numpy().tolist()
# 先找到B所在的位置,即标号为0的位置,然后顺着该位置一直找到所有的I,即标号为1,即为所得。
def find_entity(prediction, input_ids):
entity = []
entity_ids = []
for index, idx in enumerate(prediction):
if idx == label_list['B']:
entity_ids = [input_ids[index]]
elif idx == label_list['I']:
if entity_ids:
entity_ids.append(input_ids[index])
elif idx == label_list['O']:
if entity_ids:
entity.append(''.join(tokenizer.convert_ids_to_tokens(entity_ids)))
entity_ids = []
return entity
with open(save_file[data_name], 'w', encoding='utf8') as f:
f.write("index\tprediction\n")
for idx, sample in enumerate(data_dict[data_name]['test']):
qid = sample.split('\t')[0]
entity = find_entity(predicts[idx], input_ids[idx])
entity = list(set(entity)) # 去重
f.write(qid + '\t' + '\x01'.join(entity) + '\n')
f.close()
[2021-06-18 21:27:05,375] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.pdparams
#将预测文件结果压缩至zip文件,提交
!zip -r results.zip results
adding: results/ (stored 0%)
adding: results/NLPCC14-SC.tsv (deflated 64%)
adding: results/COTE_MFW.tsv (deflated 54%)
adding: results/SE-ABSA16_CAME.tsv (deflated 63%)
adding: results/COTE_BD.tsv (deflated 44%)
adding: results/ChnSentiCorp.tsv (deflated 63%)
adding: results/COTE_DP.tsv (deflated 54%)
adding: results/SE-ABSA16_PHNS.tsv (deflated 64%)
adding: results/.ipynb_checkpoints/ (stored 0%)
qid = sample.split('\t')[0]
entity = find_entity(predicts[idx], input_ids[idx])
entity = list(set(entity)) # 去重
f.write(qid + '\t' + '\x01'.join(entity) + '\n')
f.close()
[2021-06-18 21:27:05,375] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.pdparams
```python
#将预测文件结果压缩至zip文件,提交
!zip -r results.zip results
adding: results/ (stored 0%)
adding: results/NLPCC14-SC.tsv (deflated 64%)
adding: results/COTE_MFW.tsv (deflated 54%)
adding: results/SE-ABSA16_CAME.tsv (deflated 63%)
adding: results/COTE_BD.tsv (deflated 44%)
adding: results/ChnSentiCorp.tsv (deflated 63%)
adding: results/COTE_DP.tsv (deflated 54%)
adding: results/SE-ABSA16_PHNS.tsv (deflated 64%)
adding: results/.ipynb_checkpoints/ (stored 0%)
结语
- 本项目旨在入门paddlenlp,同时参加千言数据集的情感分析比赛
- 如果项目中有什么问题,欢迎在评论区留言提出~
- 一个月内还会不断更新(冲榜~)
关于作者
- 小白一枚~俞立可
- 金陵科技学院 软件工程学院 大二在读
- 感兴趣的方向为:自然语言处理和生成对抗网络等
- AIstudio个人主页:小阿美
- 欢迎大家留言,一起学习,共同成长~

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 2
2 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)