
基于paddlehub和wechaty实现一句话给你emoji过来
一:Emoji起源emoji就是表情符号,来自日语词汇“絵文字”(假名为“えもじ”,读音即emoji)。emoji的创造者是日本人栗田穰崇(Shigetaka Kurita),他将目光投向儿时的各种元素以获取灵感,如日本漫画和日本汉字等。“日本漫画中有许多不同的符号。漫画家会画出一些表情,表现一个人满头大汗或是迸发出一个想法时头上出现一个灯泡。”同时,从日本汉字中他获得了一种能力,用简单的字符来表
一:Emoji起源
emoji就是表情符号,来自日语词汇“絵文字”(假名为“えもじ”,读音即emoji)。
emoji的创造者是日本人栗田穰崇(Shigetaka Kurita),他将目光投向儿时的各种元素以获取灵感,如日本漫画和日本汉字等。“日本漫画中有许多不同的符号。漫画家会画出一些表情,表现一个人满头大汗或是迸发出一个想法时头上出现一个灯泡。”同时,从日本汉字中他获得了一种能力,用简单的字符来表达“秘密”和“爱”等抽象概念。
2014年8月,牛津词典在线版(Oxford Dictionary Online)把“Emoji”添加到新词汇中,这也意味着它已经变成一个正式词汇。
二:Emoji影响
全球约有90%的在线用户频繁使用emoji,每天有60亿个emoji表情符号被传送。不夸张地说,emoji已成为日本最大的出口商品之一。人们甚至也将emoji当作一门艺术。2016年,纽约现代艺术博物馆将emoji列为永久收藏,其中包括176个诞生于1999年的最初版本emoji表情。
三:效果图
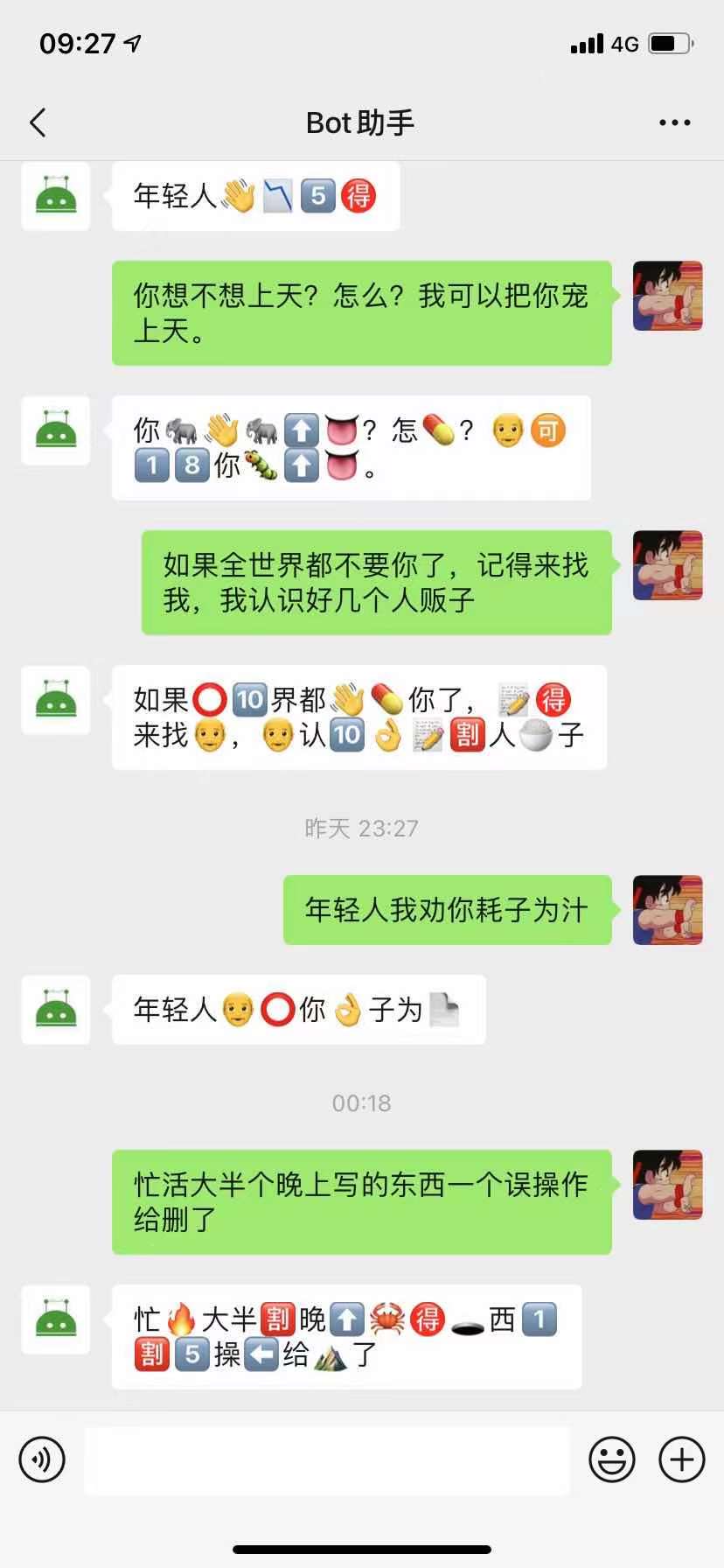
四:实现思路

# 安装paddlehub
# pip install --upgrade paddlehub -i https://mirror.baidu.com/pypi/simple
# 使用lac词法分析模型,对用户输入的原话进行分词
import paddlehub as hub
lac = hub.Module(name="lac")
text = ["忙活大半个晚上写的东西一个误操作给删了"]
results = lac.cut(text=text, use_gpu=False, batch_size=1, return_tag=True)
print(results[0]['word'])
# ['忙活', '大半个', '晚上', '写', '的', '东西', '一个', '误', '操作', '给', '删', '了']
# 准备emoji词典见附录data文件夹下
# 对分词后的结果进行分词拼音检索
import pinyin
text = ['忙活', '大半个', '晚上', '写', '的', '东西', '一个', '误', '操作', '给', '删', '了']
# 分词拼音检索
for t in text:
print(pinyin.get(t, format='strip'), end=' ')
# manghuo dabange wanshang xie de dongxi yige wu caozuo gei shan le
# 单词拼音检索
if len(t) > 0:
for t_children in t:
# print(t_children)
print(pinyin.get(t_children, format='strip'), end=' ')
# mang huo da ban ge wan shang xie de dong xi yi ge wu cao zuo gei shan le
# 对分词后的结果在词典里进行检索
def retrieve_emoji_dict(text):
for word in text:
word = word.strip()
if word in emoji_dict.keys():
text_emoji += emoji_dict[word]
else:
if len(word) > 0:#不止一个字
for character in word:
if character in emoji_dict.keys():
text_emoji += emoji_dict[character]
else:
text_emoji += character
else: # 一个字
text_emoji += word
return text_emoji
text_emoji += word
return text_emoji
五:模型概述
Lexical Analysis of Chinese,简称 LAC,是一个联合的词法分析模型,能整体性地完成中文分词、词性标注、专名识别任务。在百度自建数据集上评测,LAC效果:Precision=88.0%,Recall=88.7%,F1-Score=88.4%。该PaddleHub Module支持预测。
六:总结+改进完善方向
-
emoji词典原始数据较少(600多个),往往返回的emoji表情不是很准确
-
目前emoji差不多有1300多个https://emojipedia.org/
-
后续增加对网络流行词语和英文进行添加
七:飞桨使用体验
- 接触飞桨时间也不长就几天,就拿项目中对于分词这一模型来说还是挺好的,然后就是试了一下关于图像和视频的模型发现在自己的电脑上运行还是有点吃力的
- 建议接触的同学多看看文档(这是个好东西)然后多实践就OK了
八:参考资料
- emojipediahttps://emojipedia.org/
- emoji百度百科https://baike.baidu.com/item/emoji/8154456?fr=aladdin
九:致谢

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)