
基于PaddleGAN框架复现遥感影像超分辨率网络DSSR_副本
基于PaddleGAN框架对CNN-based的遥感超分辨率网络DSSR进行复现
基于PaddleGAN框架复现遥感影像超分辨率网络DSSR
标题转载自AI Studio
标题项目链接https://aistudio.baidu.com/aistudio/projectdetail/2305475
一、遥感影像超分重建的背景
这学期上了一门遥感图像处理与分析的课程,需要做论文汇报。我选了一篇发表在TGRS上的做遥感影像超分重建的论文《Remote Sensing Image Super-Resolution Using Novel Dense-Sampling Networks》展示,途中发现该论文所提网络DSSR目前还没有开源,所以决定使用paddleGAN框架复现该网络。
二、复现DSSR网络的准备工作
- 利用PaddleGAN复现,第一步肯定是将PaddleGAN从github上clone下来,网速慢也可以从码云,问题不大。
# !git clone https://github.com/PaddlePaddle/PaddleGAN #从github上clone
!git clone https://gitee.com/paddlepaddle/PaddleGAN.git #从码云上clone
Cloning into 'PaddleGAN'...
remote: Enumerating objects: 4397, done.[K
remote: Counting objects: 100% (453/453), done.[K
remote: Compressing objects: 100% (274/274), done.[K
remote: Total 4397 (delta 205), reused 401 (delta 169), pack-reused 3944[K
Receiving objects: 100% (4397/4397), 162.51 MiB | 7.52 MiB/s, done.
Resolving deltas: 100% (2822/2822), done.
Checking connectivity... done.
-
下一步就是准备训练数据,在AI studio中有了其他用户上传的DIV2K数据,可以直接为本项目添加他们上传的数据集。我从上面添加了DIV2K的X4尺度的数据集,打算就训练X4尺度的模型。
因为其他尺度的数据没有上传。 -
在这里说一下,其实DSSR是从x2开始训练的,然后将x2的权重给训练x4之前初始化,这样效果更好,但是我没那时间慢慢来了,就直接上x4尺度的训练。
-
添加了数据集后,可以从data文件夹中看到相应的压缩文件,然后我们就对其进行解压,并放入" PaddleGAN/data"文件夹下。
!unzip -o data/data104667/DIV2K_train_HR.zip -d /home/aistudio/PaddleGAN/data/
!unzip -o data/data104667/DIV2K_train_LR_bicubic_X4.zip -d /home/aistudio/PaddleGAN/data/
!unzip -o data/data104667/DIV2K_valid_LR_bicubic_X4.zip -d /home/aistudio/PaddleGAN/data/
!unzip -o data/data104667/DIV2K_valid_HR.zip -d /home/aistudio/PaddleGAN/data/
- 在解压之后我们若是发现DIV2K_train_HR中的文件名和DIV2K_train_LR_bicubic_X4不一致,则需要修改。我们现在使用的这个数据集,高分辨率影像是0802.png,低分辨率影像是0802x4.png,命名不一致,则需要修改文件名,通过以下函数修改:
import shutil
import re
import os
def changeName(inputFolder):
filenames = os.listdir(inputFolder)
saveFolder = os.path.join(list(os.path.split(inputFolder)[:-1])[0], 'new')
if not os.path.isdir(saveFolder):
os.mkdir(saveFolder)
for filename in filenames:
src = os.path.join(inputFolder,filename)
new_filename = re.sub('x[2348]', '', filename)
dst = os.path.join(saveFolder,new_filename)
shutil.move(src, dst)
changeName('PaddleGAN/data/DIV2K_train_LR_bicubic/X4') #转换成功后,将先前的X4文件夹删掉 将new文件夹改为X4
changeName('PaddleGAN/data/DIV2K_valid_LR_bicubic/X4') #同上
- 准备好数据之后,就准备安装依赖项,这些都在PaddleGAN文件夹下的requirements.txt文件中
%cd PaddleGAN
!pip install -r requirements.txt
三、开始复现DSSR网络
- DSSR网络的结构不算复杂,整体的结构图如下所示:
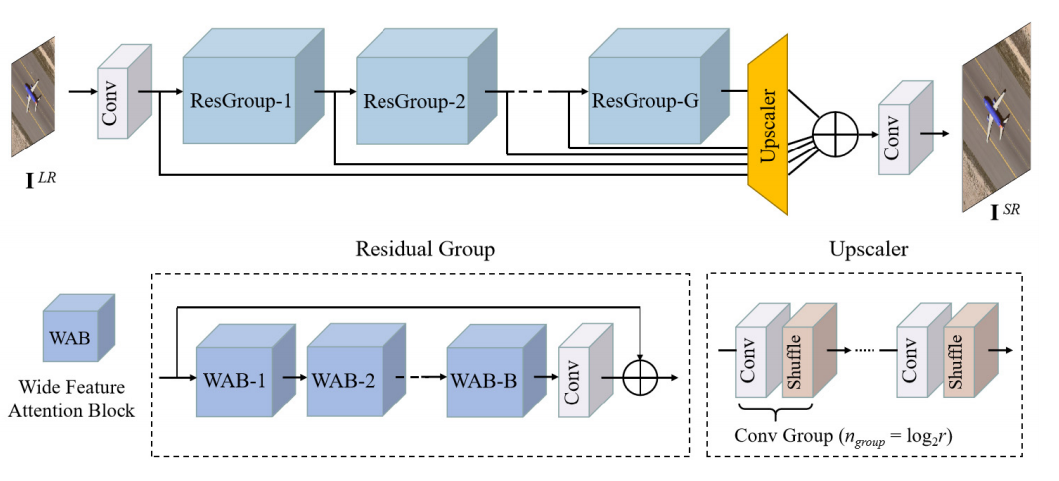
-
具体而言, DSSR的网络结构包括四个模块:
- 浅层特征模块,以一层卷积层来提取浅层特征模块
- 深层特征提取模块,是用多个残差组堆叠组成
- 上采样模块,采用亚像素卷积进行上采样,而该网络特别之处在于将所有残差组的输出都送入上采样模块中,形成该文章所提的密集上采样机制
- 重建模块,用一个卷积层将特征图转为超分的结果图
-
相关的原理我就不展示了,可以去看原文,这里着重讲如何实现。其实从给出的网络结构图就可以分别定义四个模块,然后将主体搭建起来。
# 首先将用到的库先引入
import math
import numpy as np
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
# 因为要保证一个大的感受野,特征图经过卷积运算后要保持不变,所以需要填充,方便起见定义一个能保持运算之后不改变特征图大小的卷积算子
def default_conv(in_channels, out_channels, kernel_size, bias=True):
return nn.Conv2D(in_channels,
out_channels,
kernel_size,
padding=(kernel_size // 2),
bias_attr=bias)
# 针对训练所用的DIV2K数据集,在将其数据送入网络前,进行标准化处理,先定义标准化处理的模块
class MeanShift(nn.Layer):
def __init__(self, mean_rgb, sub):
super(MeanShift, self).__init__()
sign = -1 if sub else 1
r = mean_rgb[0] * sign
g = mean_rgb[1] * sign
b = mean_rgb[2] * sign
self.shifter = nn.Conv2D(3, 3, 1, 1, 0)
self.shifter.weight.set_value(paddle.eye(3).reshape([3, 3, 1, 1]))
self.shifter.bias.set_value(np.array([r, g, b]).astype('float32'))
# 冻结参数,不参与训练
for params in self.shifter.parameters():
params.trainable = False
def forward(self, x):
x = self.shifter(x)
return x
# 定义DSSR的网络结构
class DSSR(nn.Layer):
def __init__(self, scale=4, n_feats=64, reduction=16, n_wabblocks=10, n_resgroups=3, n_colors=3, kernel_size=3, conv=default_conv, ):
super(DSSR, self).__init__()
self.scale = scale
self.sub_mean = MeanShift((0.4488, 0.4371, 0.4040), sub=True)
self.add_mean = MeanShift((0.4488, 0.4371, 0.4040), sub=False)
self.head = conv(n_colors, n_feats, kernel_size)
self.upsample = UpsampleBlock(n_feats, scale, 1)
self.reconstructConv = conv(n_feats, n_colors, kernel_size)
act = nn.ReLU()
self.ResG = ResidualGroups(conv, n_feats, kernel_size, reduction, act, n_wabblocks)
self.n_ResGs = n_resgroups
def forward(self, x):
x = self.sub_mean(x)
x = self.head(x)
InputUpScaler = []
InputUpScaler.append(x)
for i in range(self.n_ResGs):
if i==0:
out = x
out = self.ResG(out)
InputUpScaler.append(out)
outList = []
for i in range(len(InputUpScaler)):
out = self.upsample(InputUpScaler[i])
outList.append(out)
for i, an_out in enumerate(outList):
if i==0:
res = an_out
continue
res += an_out
res = self.reconstructConv(res)
out = self.add_mean(res)
return out
-
搭建好主体之后,我们再来看四个模块的细节。浅层特征提取模块和影像重构模块都是一层卷积层,这里不必赘述。我们先来看深层特征提取模块。
- 深层特征模块是由一个个残差组组成的,而残差组的结构如下图所示:
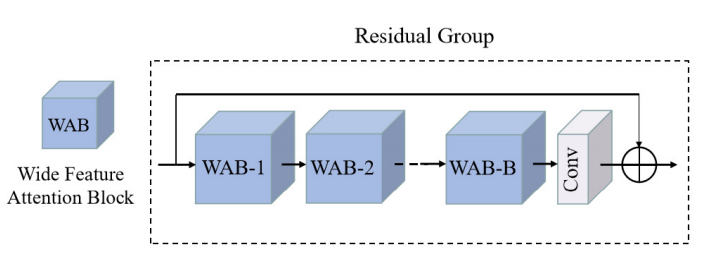
- 深层特征模块是由一个个残差组组成的,而残差组的结构如下图所示:
-
可以看到,残差组是由多个WAB(广域特征激活块)组合,最后加一个卷积层聚集特征信息,然后通过跳接加快信息的流动,代码也很简单:
class ResidualGroups(nn.Layer):
def __init__(self, conv, n_feat, kernel_size, reduction, act, n_wabblocks):
super(ResidualGroups, self).__init__()
modules_body = []
modules_body = [
WAB(
conv, n_feat, kernel_size, reduction, bias=True, bn=False, act=act, res_scale=4) \
for _ in range(n_wabblocks)]
modules_body.append(conv(n_feat, n_feat, kernel_size))
self.body = nn.Sequential(*modules_body)
def forward(self, x):
res = self.body(x)
x += res
return x
- 弄完了残差组,下一个就是你,广域特征激活模块(WAB),他的结构如下图所示:
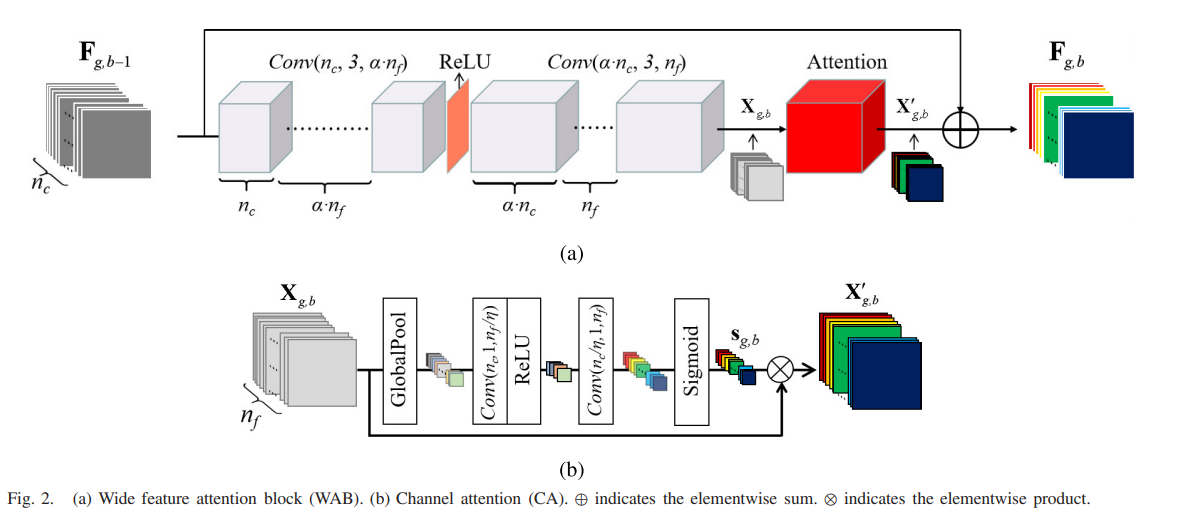
- 可以看到该模块就是正常的Resblock加了通道注意力机制,同时在ReLU激活层前增大通道数,激活之后再将通道数恢复成原来的通道数量,所以我们先定义通道注意力模块:
## 通道注意力模块
class CALayer(nn.Layer):
def __init__(self, channel, reduction=16):
super(CALayer, self).__init__()
# 全局池化将特征变为点
self.avg_pool = nn.AdaptiveAvgPool2D(1)
self.conv_du = nn.Sequential(
nn.Conv2D(channel,
channel // reduction,
1,
padding=0,
bias_attr=True), nn.ReLU(),
nn.Conv2D(channel // reduction,
channel,
1,
padding=0,
bias_attr=True), nn.Sigmoid())
def forward(self, x):
y = self.avg_pool(x)
y = self.conv_du(y)
return x * y
- 再将通道注意力模块加入,一起构建WAB。
class WAB(nn.Layer):
def __init__(self,
conv,
n_feat,
kernel_size,
reduction=16,
bias=True,
bn=False,
act=nn.ReLU(),
res_scale=4):
super(WAB, self).__init__()
modules_body = []
modules_body.append(conv(n_feat, n_feat*res_scale, kernel_size, bias=bias))
modules_body.append(act)
modules_body.append(conv(n_feat*res_scale, n_feat, kernel_size, bias=bias))
modules_body.append(CALayer(n_feat, reduction))
self.body = nn.Sequential(*modules_body)
def forward(self, x):
res = self.body(x)
res += x
return res
- 以上部分就是深层特征提取模块。深层特征提取模块中的每一个残差组的输出都将送入上采样模块,上采样模块由卷积层和亚像素卷积组成一个小组,根据需要重建的尺度来确定个数,放大倍数r=2^n,n就是组的个数。结构图如下:
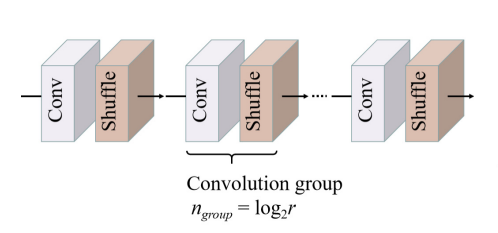
class UpsampleBlock(nn.Layer):
def __init__(self, n_channels, scale, group=1):
super(UpsampleBlock, self).__init__()
modules = []
if scale == 2 or scale == 4 or scale == 8:
for _ in range(int(math.log(scale, 2))):
modules += [
nn.Conv2D(n_channels, 4 * n_channels, 3, 1, 1, groups=group)
]
modules += [nn.PixelShuffle(2)]
elif scale == 3:
modules += [
nn.Conv2D(n_channels, 9 * n_channels, 3, 1, 1, groups=group)
]
modules += [nn.PixelShuffle(3)]
self.body = nn.Sequential(*modules)
def forward(self, x):
out = self.body(x)
return out
- OK,做完之后,咱们现在算是把DSSR的网络搭建起来了,那如何利用PaddleGAN训练呢?
四、利用PaddleGAN进行网络的训练
- 在“PaddleGAN/ppgan/models/generators”文件夹下,新建一个.py文件,命名为dssr.py,将上述代码放入,同时调整两个地方。(注:以下代码只做展示,不能运行)
import math
import numpy as np
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from .builder import GENERATORS #增加引入该函数,然后在DSSR类定义前添加相应的调用语句
def default_conv(in_channels, out_channels, kernel_size, bias=True):
return nn.Conv2D(in_channels,
out_channels,
kernel_size,
padding=(kernel_size // 2),
bias_attr=bias)
class MeanShift(nn.Layer):
def __init__(self, mean_rgb, sub):
super(MeanShift, self).__init__()
sign = -1 if sub else 1
r = mean_rgb[0] * sign
g = mean_rgb[1] * sign
b = mean_rgb[2] * sign
self.shifter = nn.Conv2D(3, 3, 1, 1, 0)
self.shifter.weight.set_value(paddle.eye(3).reshape([3, 3, 1, 1]))
self.shifter.bias.set_value(np.array([r, g, b]).astype('float32'))
# Freeze the mean shift layer
for params in self.shifter.parameters():
params.trainable = False
def forward(self, x):
x = self.shifter(x)
return x
class UpsampleBlock(nn.Layer):
def __init__(self, n_channels, scale, group=1):
super(UpsampleBlock, self).__init__()
modules = []
if scale == 2 or scale == 4 or scale == 8:
for _ in range(int(math.log(scale, 2))):
modules += [
nn.Conv2D(n_channels, 4 * n_channels, 3, 1, 1, groups=group)
]
modules += [nn.PixelShuffle(2)]
elif scale == 3:
modules += [
nn.Conv2D(n_channels, 9 * n_channels, 3, 1, 1, groups=group)
]
modules += [nn.PixelShuffle(3)]
self.body = nn.Sequential(*modules)
def forward(self, x):
out = self.body(x)
return out
## Channel Attention (CA) Layer
class CALayer(nn.Layer):
def __init__(self, channel, reduction=16):
super(CALayer, self).__init__()
# global average pooling: feature --> point
self.avg_pool = nn.AdaptiveAvgPool2D(1)
# feature channel downscale and upscale --> channel weight
self.conv_du = nn.Sequential(
nn.Conv2D(channel,
channel // reduction,
1,
padding=0,
bias_attr=True), nn.ReLU(),
nn.Conv2D(channel // reduction,
channel,
1,
padding=0,
bias_attr=True), nn.Sigmoid())
def forward(self, x):
y = self.avg_pool(x)
y = self.conv_du(y)
return x * y
class WAB(nn.Layer):
def __init__(self,
conv,
n_feat,
kernel_size,
reduction=16,
bias=True,
bn=False,
act=nn.ReLU(),
res_scale=4):
super(WAB, self).__init__()
modules_body = []
modules_body.append(conv(n_feat, n_feat*res_scale, kernel_size, bias=bias))
modules_body.append(act)
modules_body.append(conv(n_feat*res_scale, n_feat, kernel_size, bias=bias))
modules_body.append(CALayer(n_feat, reduction))
self.body = nn.Sequential(*modules_body)
def forward(self, x):
res = self.body(x)
res += x
return res
class ResidualGroups(nn.Layer):
def __init__(self, conv, n_feat, kernel_size, reduction, act, n_wabblocks):
super(ResidualGroups, self).__init__()
modules_body = []
modules_body = [
WAB(
conv, n_feat, kernel_size, reduction, bias=True, bn=False, act=act, res_scale=4) \
for _ in range(n_wabblocks)]
modules_body.append(conv(n_feat, n_feat, kernel_size))
self.body = nn.Sequential(*modules_body)
def forward(self, x):
res = self.body(x)
x += res
return x
@GENERATORS.register()
class DSSR(nn.Layer):
def __init__(self, scale=4, n_feats=64, reduction=16, n_wabblocks=10, n_resgroups=3, n_colors=3, kernel_size=3, conv=default_conv, ):
super(DSSR, self).__init__()
self.scale = scale
self.sub_mean = MeanShift((0.4488, 0.4371, 0.4040), sub=True)
self.add_mean = MeanShift((0.4488, 0.4371, 0.4040), sub=False)
self.head = conv(n_colors, n_feats, kernel_size)
self.upsample = UpsampleBlock(n_feats, scale, 1)
self.reconstructConv = conv(n_feats, n_colors, kernel_size)
act = nn.ReLU()
self.ResG = ResidualGroups(conv, n_feats, kernel_size, reduction, act, n_wabblocks)
self.n_ResGs = n_resgroups
def forward(self, x):
x = self.sub_mean(x)
x = self.head(x)
InputUpScaler = []
InputUpScaler.append(x)
for i in range(self.n_ResGs):
if i==0:
out = x
out = self.ResG(out)
InputUpScaler.append(out)
outList = []
for i in range(len(InputUpScaler)):
out = self.upsample(InputUpScaler[i])
outList.append(out)
for i, an_out in enumerate(outList):
if i==0:
res = an_out
continue
res += an_out
res = self.reconstructConv(res)
out = self.add_mean(res)
return out
-
然后在和dssr.py同一个文件夹下的__init__.py文件中加入这一句话:
from .dssr import DSSR -
接着是对模型训练定义一些参数,我们到PaddleGAN/configs文件夹下,新建一个.yaml文件,我命名为dssr_x4_div2k.yaml,设置是按照论文里的要求来的,具体如下:
total_iters: 400000 #迭代的iter次数
output_dir: output_dir #保存权重的路径
# tensor range for function tensor2img
min_max:
(0., 1.)
model:
name: BaseSRModel
generator:
name: DSSR #使用的模型名称
pixel_criterion:
name: L1Loss #损失函数
dataset:
train:
name: SRDataset
gt_folder: data/DIV2K_train_HR #训练集的高分辨率影像
lq_folder: data/DIV2K_train_LR_bicubic/X4 #训练集的低分辨率影像
num_workers: 1
batch_size: 16
scale: 4
preprocess:
- name: LoadImageFromFile
key: lq
- name: LoadImageFromFile
key: gt
- name: Transforms
input_keys: [lq, gt]
pipeline:
- name: SRPairedRandomCrop
gt_patch_size: 192
scale: 4
keys: [image, image]
- name: PairedRandomHorizontalFlip
keys: [image, image]
- name: PairedRandomVerticalFlip
keys: [image, image]
- name: PairedRandomTransposeHW
keys: [image, image]
- name: Transpose
keys: [image, image]
- name: Normalize
mean: [0., .0, 0.]
std: [255., 255., 255.]
keys: [image, image]
test:
name: SRDataset
gt_folder: data/DIV2K_valid_HR #测试集的高分辨率影像
lq_folder: data/DIV2K_valid_LR_bicubic/X4 #测试集的低分辨率影像
scale: 4 #放大的倍数
preprocess:
- name: LoadImageFromFile
key: lq
- name: LoadImageFromFile
key: gt
- name: Transforms
input_keys: [lq, gt]
pipeline:
- name: Transpose
keys: [image, image]
- name: Normalize
mean: [0., .0, 0.]
std: [255., 255., 255.]
keys: [image, image]
lr_scheduler:
name: CosineAnnealingRestartLR
learning_rate: 0.0001 #学习率的选择
periods: [200000, 200000]
restart_weights: [1, 1]
eta_min: !!float 1e-7
optimizer:
name: Adam
# add parameters of net_name to optim
# name should in self.nets
net_names:
- generator
beta1: 0.9
beta2: 0.99
validate:
interval: 5000 #每间隔5000个就验证一下
save_img: false
metrics:
psnr: # metric name, can be arbitrary
name: PSNR
crop_border: 4
test_y_channel: True
ssim:
name: SSIM
crop_border: 4
test_y_channel: True
log_config:
interval: 100
visiual_interval: 5000
snapshot_config:
interval: 5000 #每间隔5000个iter就保存一次权重和checkpoint
- 接着就是开始训练了,直接运行如下命令:
!python -u tools/main.py --config-file configs/dssr_x4_div2k.yaml
/home/aistudio/PaddleGAN/ppgan/engine/trainer.py:73: DeprecationWarning: invalid escape sequence \/
"""
/home/aistudio/PaddleGAN/ppgan/modules/init.py:58: DeprecationWarning: invalid escape sequence \s
"""
/home/aistudio/PaddleGAN/ppgan/modules/init.py:122: DeprecationWarning: invalid escape sequence \m
"""
/home/aistudio/PaddleGAN/ppgan/modules/init.py:147: DeprecationWarning: invalid escape sequence \m
"""
/home/aistudio/PaddleGAN/ppgan/modules/init.py:178: DeprecationWarning: invalid escape sequence \m
"""
/home/aistudio/PaddleGAN/ppgan/modules/init.py:215: DeprecationWarning: invalid escape sequence \m
"""
/home/aistudio/PaddleGAN/ppgan/modules/dense_motion.py:156: DeprecationWarning: invalid escape sequence \h
"""
[02/10 09:52:00] ppgan INFO: Configs: {'total_iters': 400000, 'output_dir': 'output_dir/dssr_x4_div2k-2022-02-10-09-52', 'min_max': (0.0, 1.0), 'model': {'name': 'BaseSRModel', 'generator': {'name': 'DSSR'}, 'pixel_criterion': {'name': 'L1Loss'}}, 'dataset': {'train': {'name': 'SRDataset', 'gt_folder': 'data/DIV2K_train_HR', 'lq_folder': 'data/DIV2K_train_LR_bicubic/X4', 'num_workers': 1, 'batch_size': 16, 'scale': 4, 'preprocess': [{'name': 'LoadImageFromFile', 'key': 'lq'}, {'name': 'LoadImageFromFile', 'key': 'gt'}, {'name': 'Transforms', 'input_keys': ['lq', 'gt'], 'pipeline': [{'name': 'SRPairedRandomCrop', 'gt_patch_size': 192, 'scale': 4, 'keys': ['image', 'image']}, {'name': 'PairedRandomHorizontalFlip', 'keys': ['image', 'image']}, {'name': 'PairedRandomVerticalFlip', 'keys': ['image', 'image']}, {'name': 'PairedRandomTransposeHW', 'keys': ['image', 'image']}, {'name': 'Transpose', 'keys': ['image', 'image']}, {'name': 'Normalize', 'mean': [0.0, 0.0, 0.0], 'std': [255.0, 255.0, 255.0], 'keys': ['image', 'image']}]}]}, 'test': {'name': 'SRDataset', 'gt_folder': 'data/DIV2K_valid_HR', 'lq_folder': 'data/DIV2K_valid_LR_bicubic/X4', 'scale': 4, 'preprocess': [{'name': 'LoadImageFromFile', 'key': 'lq'}, {'name': 'LoadImageFromFile', 'key': 'gt'}, {'name': 'Transforms', 'input_keys': ['lq', 'gt'], 'pipeline': [{'name': 'Transpose', 'keys': ['image', 'image']}, {'name': 'Normalize', 'mean': [0.0, 0.0, 0.0], 'std': [255.0, 255.0, 255.0], 'keys': ['image', 'image']}]}]}}, 'lr_scheduler': {'name': 'CosineAnnealingRestartLR', 'learning_rate': 0.0001, 'periods': [200000, 200000], 'restart_weights': [1, 1], 'eta_min': 1e-07}, 'optimizer': {'name': 'Adam', 'net_names': ['generator'], 'beta1': 0.9, 'beta2': 0.99}, 'validate': {'interval': 5000, 'save_img': False, 'metrics': {'psnr': {'name': 'PSNR', 'crop_border': 4, 'test_y_channel': True}, 'ssim': {'name': 'SSIM', 'crop_border': 4, 'test_y_channel': True}}}, 'log_config': {'interval': 100, 'visiual_interval': 5000}, 'snapshot_config': {'interval': 5000}, 'is_train': True, 'profiler_options': None, 'timestamp': '-2022-02-10-09-52'}
W0210 09:52:00.863458 2746 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W0210 09:52:00.868741 2746 device_context.cc:422] device: 0, cuDNN Version: 7.6.
五、训练完成后的测试
-
训练的模型将会保存在PaddleGAN/output_dir文件夹下,可以调用模型进行预测,这里我们选用Set5模型来测试。
-
先将Set5测试集的文件夹上传至PaddleGAN/data文件夹下,再修改dssr_x4_div2k.yaml文件,将其测试集路径改为如下所示:
gt_folder: data/Set5/GTmod12
lq_folder: data/Set5/LRbicx4
- 再将文件中的save_img改为True:
validate:
interval: 5000
save_img: True
- 然后将以下命令运行,在output_dir文件夹中得到测试的结果
!python -u tools/main.py --config-file configs/dssr_x4_div2k.yaml --evaluate-only --load output_dir/dssr_div2k_x4.pdparams
[11/04 21:09:46] ppgan INFO: Configs: {'total_iters': 400000, 'output_dir': 'output_dir/dssr_x4_div2k-2021-11-04-21-09', 'min_max': (0.0, 1.0), 'model': {'name': 'BaseSRModel', 'generator': {'name': 'DSSR'}, 'pixel_criterion': {'name': 'L1Loss'}}, 'dataset': {'train': {'name': 'SRDataset', 'gt_folder': 'data/DIV2K_train_HR', 'lq_folder': 'data/DIV2K_train_LR_bicubic/X4', 'num_workers': 1, 'batch_size': 16, 'scale': 4, 'preprocess': [{'name': 'LoadImageFromFile', 'key': 'lq'}, {'name': 'LoadImageFromFile', 'key': 'gt'}, {'name': 'Transforms', 'input_keys': ['lq', 'gt'], 'pipeline': [{'name': 'SRPairedRandomCrop', 'gt_patch_size': 192, 'scale': 4, 'keys': ['image', 'image']}, {'name': 'PairedRandomHorizontalFlip', 'keys': ['image', 'image']}, {'name': 'PairedRandomVerticalFlip', 'keys': ['image', 'image']}, {'name': 'PairedRandomTransposeHW', 'keys': ['image', 'image']}, {'name': 'Transpose', 'keys': ['image', 'image']}, {'name': 'Normalize', 'mean': [0.0, 0.0, 0.0], 'std': [255.0, 255.0, 255.0], 'keys': ['image', 'image']}]}]}, 'test': {'name': 'SRDataset', 'gt_folder': 'data/Set5/GTmod12', 'lq_folder': 'data/Set5/LRbicx4', 'scale': 4, 'preprocess': [{'name': 'LoadImageFromFile', 'key': 'lq'}, {'name': 'LoadImageFromFile', 'key': 'gt'}, {'name': 'Transforms', 'input_keys': ['lq', 'gt'], 'pipeline': [{'name': 'Transpose', 'keys': ['image', 'image']}, {'name': 'Normalize', 'mean': [0.0, 0.0, 0.0], 'std': [255.0, 255.0, 255.0], 'keys': ['image', 'image']}]}]}}, 'lr_scheduler': {'name': 'CosineAnnealingRestartLR', 'learning_rate': 0.0001, 'periods': [200000, 200000], 'restart_weights': [1, 1], 'eta_min': 1e-07}, 'optimizer': {'name': 'Adam', 'net_names': ['generator'], 'beta1': 0.9, 'beta2': 0.99}, 'validate': {'interval': 5000, 'save_img': True, 'metrics': {'psnr': {'name': 'PSNR', 'crop_border': 4, 'test_y_channel': True}, 'ssim': {'name': 'SSIM', 'crop_border': 4, 'test_y_channel': True}}}, 'log_config': {'interval': 100, 'visiual_interval': 5000}, 'snapshot_config': {'interval': 5000}, 'is_train': False, 'profiler_options': None, 'timestamp': '-2021-11-04-21-09'}
W1104 21:09:46.302886 1413 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1
W1104 21:09:46.307420 1413 device_context.cc:422] device: 0, cuDNN Version: 7.6.
[11/04 21:09:49] ppgan.engine.trainer INFO: Loaded pretrained weight for net generator
[11/04 21:09:49] ppgan.engine.trainer INFO: Test iter: [0/5]
[11/04 21:09:49] ppgan.engine.trainer INFO: Test iter: [1/5]
[11/04 21:09:49] ppgan.engine.trainer INFO: Test iter: [2/5]
[11/04 21:09:50] ppgan.engine.trainer INFO: Test iter: [3/5]
[11/04 21:09:50] ppgan.engine.trainer INFO: Test iter: [4/5]
[11/04 21:09:50] ppgan.engine.trainer INFO: Metric psnr: 32.1600
[11/04 21:09:50] ppgan.engine.trainer INFO: Metric ssim: 0.8936
# 将结果转移到work文件夹中以用于可视化
!cp -r output_dir/dssr_x4_div2k-2021-11-04-21-09/visual_test/ ../work/
import cv2
import os
folder = '../work/visual_test'
filenames = [f for f in os.listdir(folder) if 'lq' in f]
for filename in filenames:
img = cv2.imread(os.path.join(folder,filename))
h,w,c = img.shape
new_img = cv2.resize(img, (w*4, h*4), cv2.INTER_CUBIC)
filename, _ = os.path.splitext(filename)
savename = filename+'_bic.png'
!cp -r output_dir/dssr_x4_div2k-2021-11-04-21-09/visual_test/ ../work/
import cv2
import os
folder = '../work/visual_test'
filenames = [f for f in os.listdir(folder) if 'lq' in f]
for filename in filenames:
img = cv2.imread(os.path.join(folder,filename))
h,w,c = img.shape
new_img = cv2.resize(img, (w*4, h*4), cv2.INTER_CUBIC)
filename, _ = os.path.splitext(filename)
savename = filename+'_bic.png'
cv2.imwrite(os.path.join(folder, savename), new_img)
| 低分辨率 | 超分重建后 | 高分辨率 |
|---|---|---|
| [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XlJmKYfF-1645855355896)(work/visual_test/butterfly_lq_bic.png)] | [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WBuMI1Gb-1645855355896)(work/visual_test/butterfly_output.png)] | [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Mdc8oEiW-1645855355897)(work/visual_test/butterfly_gt.png)] |
| [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LgUV9a3I-1645855355897)(work/visual_test/bird_lq_bic.png)] | [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FoAGMDok-1645855355897)(work/visual_test/bird_output.png)] | [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1DXqe3QE-1645855355898)(work/visual_test/bird_gt.png)] |
| [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gwgSvPwc-1645855355898)(work/visual_test/baby_lq_bic.png)] | [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YfmJV7hA-1645855355898)(work/visual_test/baby_output.png)] | [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-phk8a2xs-1645855355898)(work/visual_test/baby_gt.png)] |
六、总结
1.选用PaddleGAN框架的原因
- PaddleGAN 框架里有关于超分辨率的网络模型,但是不算多,目前是有RealSR,PAN, ESRGAN, LESRCNN,DRN这几种模型。但是超分辨率任务,尤其是单幅影像的超分辨率重建,网络使用的数据集几乎都是DIV2K数据集,损失函数也无非是 L 1 l o s s L1 loss L1loss、 L 2 l o s s L2 loss L2loss、 G A N l o s s GAN loss GANloss这三类,训练的方式也大同小异。数据的读取、损失函数以及模型的训练均可以使用PaddleGAN的框架。我们只需要定义好网络的相关细节即可,所以基于PaddleGAN框架进行超分辨率重建网络的复现比较方便。
2.不足之处
- 没有使用遥感影像训练模型,已经在我的下一个项目【AI达人创造营第二期】以RCAN模型对遥感图像超分辨率重建,可以直接体验!进行改进了,并且效果不错,感兴趣的可以去fork一下。
注意
- 本教程目的在于教会大家使用PaddleGAN复现CNN-based的超分网络
- 由于我没有时间按照论文里所说的链式训练去做,所以在PSNR指标上不如原论文。而且模型的构建单纯靠我对模型图的理解,也许会出现问题,这个得等原作者公布源码才能知道了。
- 训练好的模型和Set5测试结果都放在了work文件夹下

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)