
基于DeepLabv3p的遥感影像地块分割
本项目使用DeepLabv3p实现遥感影像地块分割。
遥感影像地块分割
赛题链接:
背景介绍
遥感影像地块分割, 旨在对遥感影像进行像素级内容解析,对遥感影像中感兴趣的类别进行提取和分类,在城乡规划、防汛救灾等领域具有很高的实用价值,在工业界也受到了广泛关注。现有的遥感影像地块分割数据处理方法局限于特定的场景和特定的数据来源,且精度无法满足需求。因此在实际应用中,仍然大量依赖于人工处理,需要消耗大量的人力、物力、财力。本赛题旨在衡量遥感影像地块分割模型在多个类别(如建筑、道路、林地等)上的效果,利用人工智能技术,对多来源、多场景的异构遥感影像数据进行充分挖掘,打造高效、实用的算法,提高遥感影像的分析提取能力。
本项目旨在对遥感影像进行像素级内容解析,并对遥感影像中感兴趣的类别进行提取和分类,以衡量遥感影像地块分割模型在多个类别(如建筑、道路、林地等)上的效果。
赛题任务
本赛题旨在对遥感影像进行像素级内容解析,并对遥感影像中感兴趣的类别进行提取和分类,以衡量遥感影像地块分割模型在多个类别(如建筑、道路、林地等)上的效果。
数据说明
本赛题提供了多个地区已脱敏的遥感影像数据,各参赛选手可以基于这些数据构建自己的地块分割模型。
训练数据集
样例图片及其标注如下图所示:




训练数据集文件名称:train_and_label.zip
包含2个子文件,分别为:训练数据集(原始图片)文件、训练数据集(标注图片)文件,详细介绍如下:
-
训练数据集(原始图片)文件名称:img_train
包含66,653张分辨率为2m/pixel,尺寸为256 * 256的JPG图片,每张图片的名称形如T000123.jpg。
-
训练数据集(标注图片)文件名称:lab_train
包含66,653张分辨率为2m/pixel,尺寸为256 * 256的PNG图片,每张图片的名称形如T000123.png。
-
备注: 全部PNG图片共包括4种分类,像素值分别为0、1、2、3。此外,像素值255为未标注区域,表示对应区域的所属类别并不确定,在评测中也不会考虑这部分区域。
测试数据集
测试数据集文件名称:img_test.zip,详细介绍如下:
包含4,609张分辨率为2m/pixel,尺寸为256 * 256的JPG图片,文件名称形如123.jpg。、
数据增强工具
PaTTA:由第三方开发者组织AgentMaker维护的Test-Time Augmentation库,可在测试时通过数据增强方式产生额外的推理结果,在此基础上进行投票即可获得更稳定的成绩表现。 https://github.com/AgentMaker/PaTTA
RIFLE:由第三方开发者对ICML 2020中的《RIFLE: Backpropagation in Depth for Deep Transfer Learning through Re-Initializing the Fully-connected LayEr》论文所提供的封装版本,其通过对输出层多次重新初始化来使得深层backbone得到更充分的更新。 https://github.com/GT-ZhangAcer/RIFLE_Module
1、环境配置
# 克隆paddleSeg的github仓库
!git clone https://github.com/paddlepaddle/PaddleSeg.git
Cloning into 'PaddleSeg'...
remote: Enumerating objects: 19132, done.
remote: Counting objects: 100% (662/662), done.
remote: Compressing objects: 100% (444/444), done.
remote: Total 19132 (delta 314), reused 466 (delta 214), pack-reused 18470
Receiving objects: 100% (19132/19132), 345.51 MiB | 16.79 MiB/s, done.
Resolving deltas: 100% (12193/12193), done.
Checking connectivity... done.
命令行执行:
pip install -r PaddleSeg/requirements.txt
2、数据准备
# 解压数据集
!unzip -q data/data80164/train_and_label.zip
!unzip -q data/data80164/img_test.zip
3、数据预处理
(1)数据增强模块
项目使用Paddleseg进行数据处理和训练,Paddleseg的API说明文档传送门:https://github.com/PaddlePaddle/PaddleSeg
- RandomHorizontalFlip 以一定的概率对图像进行水平翻转,默认翻转概率为0.5。
- Resize 调整图像大小。
- RandomCrop 对图像和标注图进行随机裁剪,模型训练时的数据增强操作。
- RandomBlur 以一定的概率对图像进行高斯模糊,模型训练时的数据增强操作,默认概率是0.1。
- RandomDistort 以一定的概率对图像进行随机像素内容变换,可包括亮度、对比度、饱和度、色相角度、通道顺序的调整,模型训练时的数据增强操作。
- Normalize 对图像进行标准化。
(2)数据集划分模块
import numpy as np
import os
datas = []
image_base = 'img_train' # 训练集原图路径
annos_base = 'lab_train' # 训练集标签路径
# 读取原图文件名
ids_ = [v.split('.')[0] for v in os.listdir(image_base)]
# 将训练集的图像集和标签路径写入datas中
for id_ in ids_:
img_pt0 = os.path.join(image_base, '{}.jpg'.format(id_))
img_pt1 = os.path.join(annos_base, '{}.png'.format(id_))
datas.append((img_pt0.replace('/home/aistudio', ''), img_pt1.replace('/home/aistudio', '')))
if os.path.exists(img_pt0) and os.path.exists(img_pt1):
pass
else:
raise "path invalid!"
# 打印datas的长度和具体存储例子
print('total:', len(datas))
print(datas[0][0])
print(datas[0][1])
print(datas[10][:])
total: 66652
img_train/T042641.jpg
lab_train/T042641.png
('img_train/T102112.jpg', 'lab_train/T102112.png')
import cv2
# 四类标签,这里用处不大,比赛评测是以0、1、2、3类来对比评测的
labels = ['建筑', '耕地', '林地', '其他']
# 将labels写入标签文件
with open('labels.txt', 'w') as f:
for v in labels:
f.write(v+'\n')
# 随机打乱datas
np.random.seed(123)
np.random.shuffle(datas)
# 验证集与训练集的划分,0.2表示20%为验证集,80%为训练集
split_num = int(0.2*len(datas))
# 划分训练集和验证集
train_data = datas[:-split_num]
valid_data = datas[-split_num:]
# 写入训练集list
with open('train_list.txt', 'w') as f:
for img, lbl in train_data:
f.write(img + ' ' + lbl + '\n')
# 写入验证集list
with open('valid_list.txt', 'w') as f:
for img, lbl in valid_data:
# 进行数据清洗,数据验证过程中,对于全为255的图像直接忽略
clean = cv2.imread(lbl)
# print(lbl)
if (clean == 255).all():
continue
f.write(img + ' ' + lbl + '\n')
# 打印训练集和测试集大小
print('train:', len(train_data))
print('valid:', len(valid_data))
train: 53322
valid: 13330
4、模型选择
1、DeepLabV3p:
DeepLabv3p介绍:
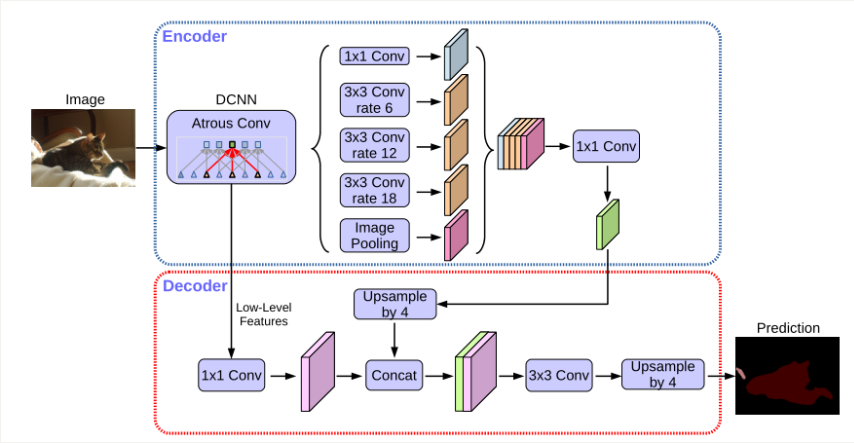
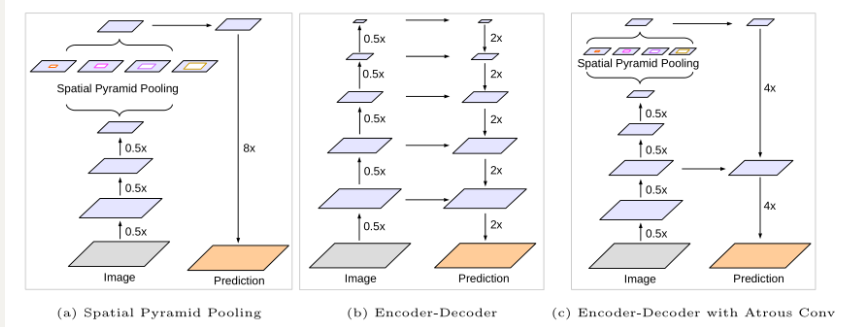
在DeepLabv3的基础上添加了decoder结构,并且细化了ASPP模块,实现更为细致的特征融合,带有ASPP的encoder-decoder架构与其他结构的对比如下图所示:
2、SETR:
SETR介绍:
传统的语义分割架构都是基于FCN的编码器解码器,但是作者认为这种架构虽然具有平移不变性和局部性,满足自然图像的形成特征,但是缺乏长距离上下文建模语义信息。因此,提出了一个pure transformer架构SEgmentation TRansformer.
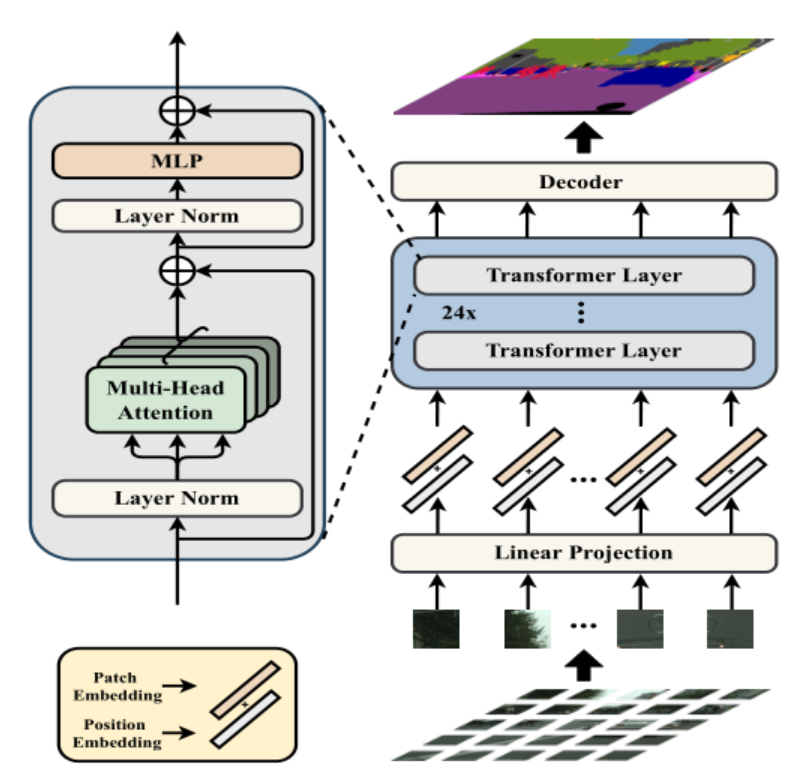
编码器就是普通的一个ViT架构,然后设计了三种解码器结构来产生mask,Naive就是一次上采样,PUP是多次逐步上采样,MLA是特征聚合解码,如下图所示:
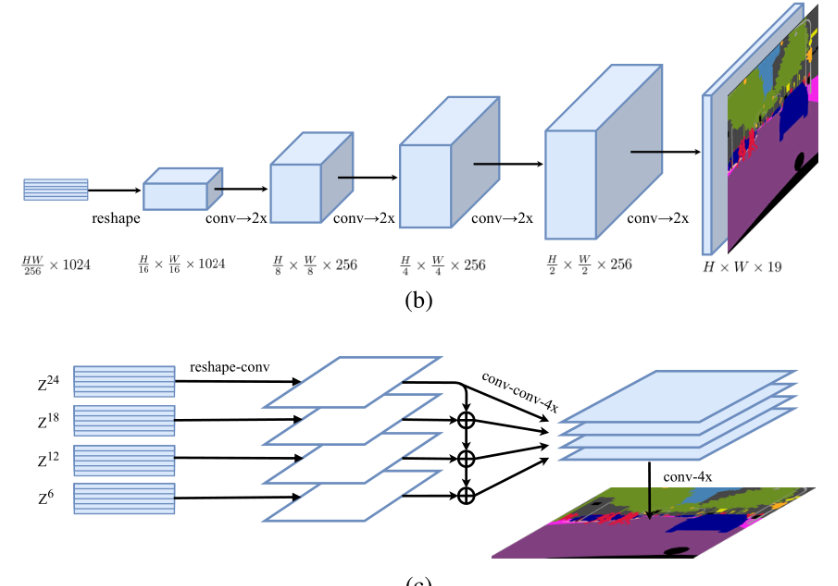
MLA的decoder就是按照固定步长选择不同的transformer encoder block的输出tokens,然后经过1x1,3x3,3x3三层卷积改变通道,然后用一个4倍上采样。接着,不同的特征逐元素相加,然后在4倍上采样得到原图。本项目使用的SETR-PUP。
5、模型训练
1、DeepLabv3使用Paddlex.seg中提供的模型训练的,代码如下:
!pip install paddlex==2.0.0 -i https://mirror.baidu.com/pypi/simple
from paddlex import transforms
# 定义训练和验证时的transforms
train_transforms = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.Resize(target_size=300),
transforms.RandomCrop(crop_size=256),
transforms.RandomBlur(prob=0.1),
transforms.RandomDistort(brightness_range=0.5),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.Resize(256),
transforms.Normalize()
])
%cd ~/PaddleSeg/datasets/
import paddlex as pdx
data_dir = '/home/aistudio/PaddleSeg/datasets'
# 定义训练和验证数据集
train_dataset = pdx.datasets.SegDataset(
data_dir=data_dir, # 数据集路径
file_list='train.txt', # 训练集图片文件list路径
label_list='labels.txt', # 训练集标签文件list路径
transforms=train_transforms, # train_transforms
shuffle=True) # 数据集是否打乱
eval_dataset = pdx.datasets.SegDataset(
data_dir=data_dir, # 数据集路径
file_list='val.txt', # 验证集图片文件list路径
label_list='labels.txt', # 验证集标签文件list路径
transforms=eval_transforms, # eval_transforms
shuffle=False)
/home/aistudio/PaddleSeg/datasets
2022-08-08 10:55:21 [INFO] 53322 samples in file train.txt
2022-08-08 10:55:22 [INFO] 12110 samples in file val.txt
# 分割类别数
num_classes = len(train_dataset.labels)
# 构建DeepLabv3p分割器
model = pdx.seg.DeepLabV3P(num_classes=num_classes, backbone='ResNet50_vd')
# 模型训练
model.train(
num_epochs=24, # 训练迭代轮数
train_dataset=train_dataset, # 训练集读取
train_batch_size=8, # 训练时批处理图片数
eval_dataset=eval_dataset, # 验证集读取
learning_rate=0.0002, # 学习率
save_interval_epochs=1, # 保存模型间隔轮次
save_dir='output/deeplabv3p_r50vd', # 模型保存路径
pretrain_weights='COCO', # 下载backbone的预训练参数
use_vdl=True,
log_interval_steps=200) # 日志打印间隔
2、SETR模型训练
首先需要编写配置文件:
setr_mla_large_custom_256x256_2x.yml关键点:
model:
num_classes: 4
test_config:
is_slide: True
crop_size: [256, 256]
stride: [256, 256]
custom_256x256.yml关键点:
batch_size: 12
iters: 106644
iters需要根据batch_size和训练集样本数来计算,iters = (train_samples / batch_size) * 2x(24) = 106644
训练时的参数save_interval为一个epoch的iters = train_samples / batch_size = 6665
%cd ~/PaddleSeg
# 开启训练
! python train.py \
--config configs/setr/setr_pup_large_custom_256x256_2x.yml \
--use_vdl \
--save_interval 2500 \
--save_dir output/setr_2x
6、模型评估
# deeplabv3p模型评估
# 加载模型
model = pdx.load_model('/home/aistudio/PaddleSeg/output/deeplabv3p_r50vd/best_model')
# 模型评估
model.evaluate(eval_dataset, batch_size=1, return_details=False)
# SETR模型评估
%cd ~/PaddleSeg
! python val.py \
--config configs/setr/setr_pup_large_custom_256x256_2x.yml \
--model_path output/setr_2x/iter_106644/model.pdparams
评估结果:
DeepLabv3p_resnet50_vd:
[(‘miou’, 0.5869),
(‘category_iou’,
array([0.5957 , 0.7578, 0.5898 , 0.4041], dtype=float32)),
(‘oacc’, 0.7591634),
(‘category_acc’,
array([0.7184 , 0.8691 , 0.7450 , 0.6049], dtype=float32)),
(‘kappa’, 0.6657747940699081),
(‘category_F1-score’,
array([0.7466, 0.8622 , 0.7420, 0.5756]))]
SETR:
[(‘miou’, 0.5407),
(‘category_iou’,
array([0.5217 , 0.7322, 0.5063 , 0.4026], dtype=float32)),
(‘oacc’, 0.7188),
(‘category_acc’,
array([0.6846 , 0.8319 , 0.6593 , 0.6071], dtype=float32)),
(‘kappa’, 0.6147),
(‘category_Recall’,
array([0.6867, 0.8594 , 0.6856, 0.5444]))]
7、模型预测
%matplotlib inline
%cd ~/
import paddlex as pdx
import matplotlib.pyplot as plt
from tqdm import tqdm
import cv2
# 单张图片可视化预测
test_jpg = 'img_testA/1582.jpg'
model = pdx.load_model('PaddleSeg/output/deeplabv3p_r50vd/best_model')
result = model.predict(test_jpg)
# 可视化结果存储在./visualized_test.jpg,见下图右(左图为原图)
pdx.seg.visualize(test_jpg, result, weight=0.0, save_dir='./')
# 可视化
original = cv2.imread(test_jpg)
b, g, r = cv2.split(original)
original = cv2.merge([r, g, b])
result = cv2.imread("visualize_1582.jpg")
b, g, r = cv2.split(result)
result = cv2.merge([r, g, b])
plt.imshow(original)
plt.show()
plt.imshow(result)
plt.show()
/home/aistudio
2022-08-10 14:41:45 [INFO] Model[DeepLabV3P] loaded.
2022-08-10 14:41:45 [INFO] The visualized result is saved as ./visualize_1582.jpg


# 多张图片预测
import os
test_base = 'img_testA/' # 测试集路径
out_base = 'deeplabv3p_result/' # 预测结果保存路径
# 是否存在结果保存路径,如不存在,则创建该路径
if not os.path.exists(out_base):
os.makedirs(out_base)
# 模型预测并保存预测图片
for im in tqdm(os.listdir(test_base)):
if not im.endswith('.jpg'):
continue
pt = test_base + im
result = model.predict(pt)
# 可视化结果存储在./visualized_images,见下图右(左图为原图)
pdx.seg.visualize(pt, result, weight=0.0, save_dir='./visualize_images')
# 生成最终结果,存储在./result
cv2.imwrite(out_base+im.replace('jpg', 'png'), result['label_map'])
# 将图像合成视频(如果无法生成,可以本地运行)
import numpy as np
import cv2
size = (1640, 590)
# 分割结果
# 完成写入对象的创建,第一个参数是合成之后的视频的名称,第二个参数是可以使用的编码器,第三个参数是帧率即每秒钟展示多少张图片,第四个参数是图片大小信息
videowrite = cv2.VideoWriter('seg_test.mp4', -1, 15, size)#15是帧数,size是图片尺寸
img_array=[]
for filename in os.listdir('visualize_images'):
img = cv2.imread('visualize_images/' + filename)
if img is None:
print(filename + " is error!")
continue
img_array.append(img)
for i in range(len(img_array)):
videowrite.write(img_array[i])
基于PaddleSeg套件训练的SETR模型的预测、推理和部署:
# PaddleSeg套件进行预测
! python PaddleSeg/predict.py --config PaddleSeg/configs/setr/setr_pup_large_custom_256x256_2x.yml \
--model_path PaddleSeg/output/setr_2x/iter_106644/model.pdparams \
--image_path img_testA/7804.jpg \
nfig PaddleSeg/configs/setr/setr_pup_large_custom_256x256_2x.yml \
--model_path PaddleSeg/output/setr_2x/iter_106644/model.pdparams \
--image_path img_testA/7804.jpg \
--save_dir setr_result
8、总结
本项目基于Paddlex利用DeepLabv3p完成遥感影像地块分割。最终对分割结果进行了可视化,发现精度并不是很高,而且在提交的测试集精度也只有60%左右,原因是对于遥感影像分割,本身像素比较模糊,很多地块肉眼也很难分辨。此外,我采样了部分训练集的标注样本进行可视化,发现存在不少训练样本标注精度不高,因此训练集也是比较粗糙的。综合上述原因,我认为这个任务要想再大幅度提高精度,需要从数据集下手。
个人简介
赵祎安 大连理工大学百度飞桨领航团团长 计算机科学与技术专业 2019级 本科生
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 1
1- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)