
手把手教你自制VOC,COCO数据集(超详细)
labelimage标注软件的使用,目标检测标注的细节,批量更改文件名称,批量更改图像尺寸大小,VOC转COCO格式
一、项目背景
目标检测应用于非标准场景时,大部分数据集在网上难以找到,例如工业现场的表面缺陷检测,应用场景大部分都不相似,数据集差异很大。通常需要我们自己去制作数据集。
飞浆框架中的PaddleDetection套件与PaddleX全流程套件可以很好的帮助我们解决目标检测任务,因此自制适用于飞浆框架的数据集是开始目标检测任务的第一步。本项目较为详细的讲述如何自制VOC数据集如何将VOC数据集转换为COCO格式,以及对数据集的一些处理,使得自己的数据集能够完整的跑通模型.
二、PaddleX与PaddleDetection对比
PaddleX与PaddleDetection都可以非常方便的实现目标检测任务。
PaddleX集成飞桨智能视觉领域图像分类、目标检测、语义分割、实例分割任务能力,将深度学习开发全流程从数据准备、模型训练与优化到多端部署端到端打通,同时PaddleX推出GUI界面软件。PaddleX更适合新入门的小白,或者没有python基础的传统机器视觉从业者。
GUI产品全景图: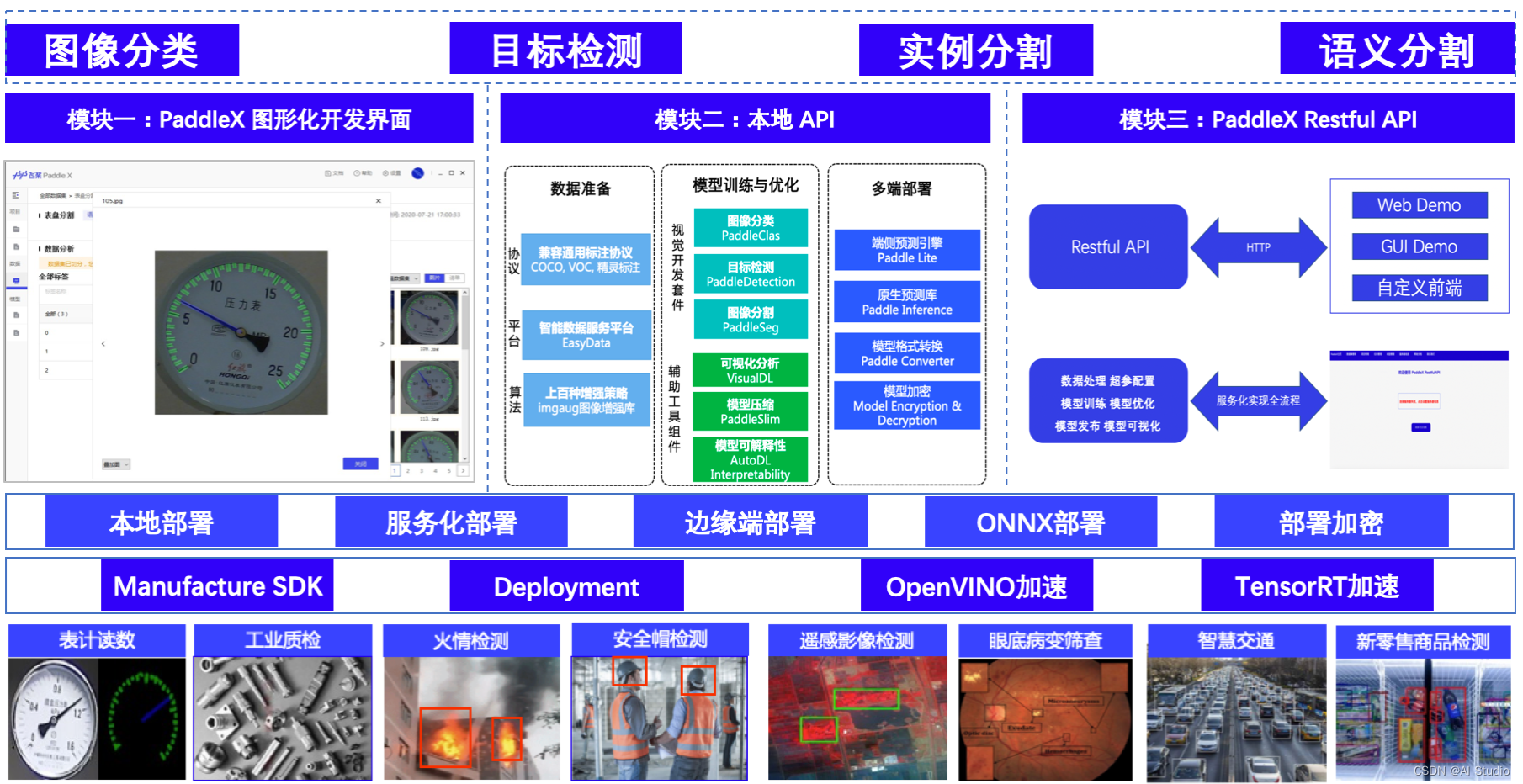
更多介绍:PaddleX
PaddleDetection为基于飞桨PaddlePaddle的端到端目标检测套件,内置30+模型算法及250+预训练模型,提供目标检测、实例分割、多目标跟踪、关键点检测等多种能力。PaddleDetection相对来说更加适合有一定目标检测基础的开发者,它封装没有PaddleX那么高,可以对模型网络进行进行一定的修改更加利于二次开发,同时支持迁移学习。
更多介绍:PaddleDetection
三、数据格式说明
3.1 PaddleX支持的数据集格式
在PaddleX中,目标检测支持PascalVOC数据集格式。
VOC数据是Pascal VOC 比赛使用的数据。Pascal VOC比赛不仅包含图像分类分类任务,还包含图像目标检测、图像分割等任务,其标注文件中包含多个任务的标注内容。VOC数据是每个图像文件对应一个同名的xml文件,xml文件中标记物体框的坐标和类别等信息。
更多介绍:PaddleX目标检测数据格式
3.1 PaddleDetection支持的数据集格式
PaddleDetection默认支持COCO和Pascal VOC 格式
COCO数据是COCO 比赛使用的数据。同样的,COCO比赛数也包含多个比赛任务,其标注文件中包含多个任务的标注内容。 COCO数据集指的是COCO比赛使用的数据。用户自定义的COCO数据,json文件中的一些字段,请根据实际情况选择是否标注或是否使用默认值。
COCO数据标注是将所有训练图像的标注都存放到一个json文件中。数据以字典嵌套的形式存放。
本项目主要讲解VOC数据集制作,以及如何将VOC数据格式转换为COCO格式
四、图像数据处理
不管是voc数据集还是coco数据集通常需要.jpg格式,并且如何批量修改图像尺寸、文件名称也经常用到。
4.1 批量更改文件名后缀,生成.jpg文件
#解压数据集到work文件夹路径下,已经解压过就不必再次运行,不然会报错
!unzip data/data165091/voc_data.zip -d ~/work/
# 批量生成.jpg文件
import os
# file_dir 文件目录 old_suffix 原后缀 new_suffix 新后缀
def change_suffix(file_dir, old_suffix, new_suffix):
for file_name in os.listdir(file_dir):
# os.path.splitext 分割文件主名和后缀名
split_file = os.path.splitext(file_name)
# 获得文件后缀 split_file[0] 文件主名 split_file[1] 后缀名
file_suffix = split_file[1]
if old_suffix == file_suffix:
new_file_name = split_file[0] + new_suffix
# os.rename 重命名
os.rename(os.path.join(file_dir, file_name), os.path.join(file_dir, new_file_name))
if __name__=='__main__':
change_suffix('work/voc_data/JPEGImages', '.JPG', '.jpg')
4.2 批量修改图像尺寸
注意文件路径,不要多或者少“/”,不然会报错
import cv2
import os
os.mkdir(r"data_plus") #创建新文件夹
path = 'work/voc_data/JPEGImages/' #原图像路径
save_path = 'data_plus/' # 修改后的图像路径
files = os.listdir(path)
for file in files:
img = cv2.imread(path + "/" + file)
# img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) 转化为灰度图
try:
img = cv2.resize(img,(640,640))
cv2.imwrite(save_path+"/"+str(file),img)
except:
continue
4.3 批量修改文件名称
import os
# 函数功能:批量修改文件夹路径下所有文件的文件名,在文件名前加数字7
def change_file_name(dir_path):
files = os.listdir(dir_path) # 读取文件名
for i in files:
#设置旧文件名(路径+文件名)
oldname=os.path.join(dir_path,i)
#设置新文件名
newname=os.path.join(dir_path,'7'+i)
#用os模块中的rename方法对文件改名
os.rename(oldname,newname)
print(oldname,'======>',newname)
if __name__=='__main__':
change_file_name('data_plus')
五、VOC数据集制作
5.1 数据文件夹结构

操作步骤:首先在自己电脑上创建一个MyDataset文件夹,文件夹包含JPEGImage文件夹和Annotations文件夹(名称必须是这样命名)然后将转换好的.jpg格式保存在JPEGImage文件夹,将标注好的.xml文件保存在Annotations文件夹中。本项目提供了模板,保存在
data/data165091/voc_data.zip目录,可直接下载。
5.2 用labelimage生成标注.xml文件
飞浆支持labelimage,labelme,标注精灵生成的.xml文件进行目标检测任务。
**操作步骤:**双击labelImg执行文件图标,会出现操作界面,不用理会端口界面:
点击opendir打开创建好的JPEGImage文件夹,点击change save dir,将文件保存在Annotations文件夹里面,点击左中间creatbox就可以进行标注,生成对应图像的标注信息。
**tips:**点击左上角view,勾选第一个自动保存模型就不用每次都手动点击了。
5.3 如何生成负样本标注文件
生成负样本数据可以适当地降低误检率
**操作步骤:**先框选,后删除,生成空的.xml文件,可以看到xml文件里的object节点不存在,这就是我们需要的负样本。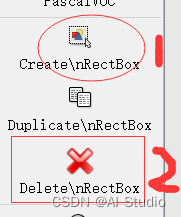

5.4 上传数据集
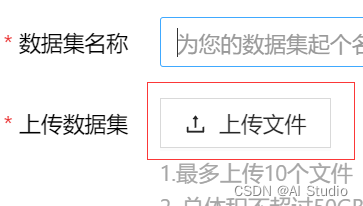
如果需要通过aistudio平台进行训练,一般将自己生成的数据集上传到个人数据集里。
**操作步骤:**进入个人主页=>数据集=>创建数据集=>创建项目=>添加数据集=>个人数据集

六、VOC转COCO格式
PaddleDetection有时候需要用到COCO数据集格式,在这里们进行一个数据格式转换,格式转化需要用到paddledetection的x2coco.py接口
#克隆PaddleDetection仓库
!git clone https://gitee.com/paddlepaddle/PaddleDetection.git -b release/2.4
正克隆到 'PaddleDetection'...
remote: Enumerating objects: 28000, done.[K
remote: Counting objects: 100% (8470/8470), done.[K
remote: Compressing objects: 100% (3450/3450), done.[K
remote: Total 28000 (delta 6365), reused 6821 (delta 4999), pack-reused 19530[K
接收对象中: 100% (28000/28000), 299.63 MiB | 17.40 MiB/s, 完成.
处理 delta 中: 100% (20914/20914), 完成.
检查连接... 完成。
正在检出文件: 100% (1973/1973), 完成.
import random
import os
# 生成train.txt和val.txt
random.seed(2020)
xml_dir = '/home/aistudio/work/voc_data/Annotations'
img_dir = '/home/aistudio/work/voc_data/JPEGImages'
path_list = list()
for img in os.listdir(img_dir):
img_path = os.path.join(img_dir,img)
xml_path = os.path.join(xml_dir,img.replace('jpg', 'xml'))
path_list.append((img_path, xml_path))
random.shuffle(path_list)
ratio = 0.5
train_f = open('/home/aistudio/work/voc_data/train.txt', 'w')
val_f = open('/home/aistudio/work/voc_data/val.txt', 'w')
for i ,content in enumerate(path_list):
img, xml = content
text = img + ' ' + xml + '\n'
if i < len(path_list) * ratio:
train_f.write(text)
else:
val_f.write(text)
train_f.close()
val_f.close()
# 根据自己数据类别生成标签文档
label = ['liewen']
with open('/home/aistudio/work/voc_data/label_list.txt', 'w') as f:
for text in label:
f.write(text + '\n')
# 进入paddledetetion套件路径
%cd ~/PaddleDetection/
/home/aistudio/PaddleDetection
# 生成train.json
!python tools/x2coco.py \
--dataset_type voc \
--voc_anno_dir /home/aistudio/work/voc_data/Annotations \
--voc_anno_list /home/aistudio/work/voc_data/train.txt \
--voc_label_list /home/aistudio/work/voc_data/label_list.txt \
--voc_out_name train.json
Start converting !
100%|█████████████████████████████████████████| 12/12 [00:00<00:00, 4316.24it/s]
**注意:如果运行失败,把train.txt或者val.txt里面的.ipynb_checkpoints数据删除重新保存即可。**转化完成的json文件路径存储在PaddleDetection/文件夹下

# 生成val.json
!python tools/x2coco.py \
--dataset_type voc \
--voc_anno_dir /home/aistudio/work/voc_data/Annotations \
--voc_anno_list /home/aistudio/work/voc_data/val.txt \
--voc_label_list /home/aistudio/work/voc_data/label_list.txt \
--voc_out_name val.json
Start converting !
100%|█████████████████████████████████████████| 10/10 [00:00<00:00, 4322.24it/s]
七、参考资料
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 3
3 1
1- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)