
论文复现:nnformer-3d医学图像分割
这是一篇使用transformer对3d医疗影像进行分割的论文复现。欢迎对transformer或者对3d医疗影像感兴趣的同学点击查看。 dice精度高达0.9188
【第七期论文复现赛-医学图像分割】:nnFormer:Volumetric Medical Image Segmentation via a 3D Transformer
一、简介
nnFormer是基于transformer实现的一篇对3d医学图像进行分割的论文。
如下图,nnformer保留了U-Net结构。同时nnformer模型主要可分为3个blocks构成:encoder,bottleneck,decoder构成。
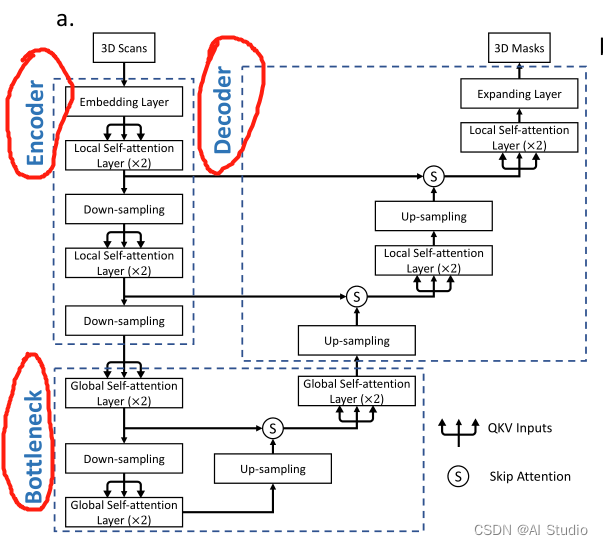
nnformer(not-another transFormer)不同于其他的transformer,nnformer混合使用了convoluton和self-attention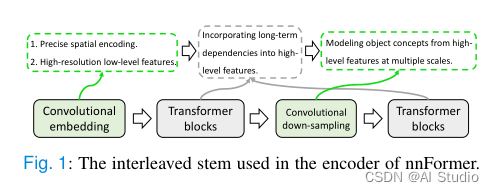
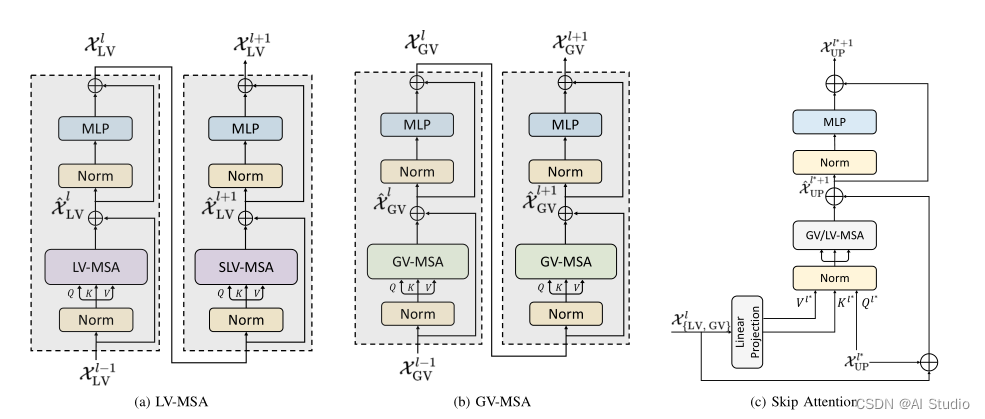
另外nnformer使用了三种方式的attention机制, LV-MSA, GV-MSA, Skip Attention。
其中LV-MSA更多的关注local注意力信息一个LV-MSA使用了swinTransformer串联了无shift和shift。不了解swintransformer的可以自行去了解下。其原理就是一张特征图算全局的qkv计算量太大了。我们就将一张特征图分割为固定大小的windows,然后每个windows里面去计算attention。
其中GV-MSA顾名思义就是算全局qkv关系,因为在做GV-MSA的时候已经做了足够的下采样的操作,此时的特征图已经足够小了。所以可以不在划分window直接全局做attention计算。
最后Skip Attention这里我感觉是一个比较有趣的地方。一般我们在融合浅层特征图和从深层上采样后的特征图的时候要么使用concatenate要么进行直接数值相加。这里是将深层上采样的作为qkv结构里面的q,然后浅层的负责kv,最后算qkv的得到最终融合后的效果。
- Paper地址: nnFormer:Volumetric Medical Image Segmentation via a 3D Transformer
- 参考github:https://github.com/282857341/nnFormer
- 复现地址:https://github.com/YellowLight021/paddle_nnformer
二、模型结构
- 主体模型由Encoder,Decoder组成。论文中还提到一个模块Bottleneck,实际在实现的时候也包含在了encoder和decoder里面了。另外论文中提及的deepsupervision实际是对不同深度的特征图进行监督。所以在构建loss的时候也增加到了输出列表中了
代码如下
class nnFormer(nn.Layer):
def __init__(self, crop_size=[14 ,160 ,160],
embedding_dim=96,
input_channels=1,
num_classes=4,
conv_op=nn.Conv3D,
depths=[2 ,2 ,2 ,2],
num_heads=[3, 6, 12, 24],
patch_size=[2 ,4 ,4],
window_size=[[3,5,5],[3,5,5],[7,10,10],[3,5,5]],
down_stride=[[1 ,2 ,2] ,[1 ,2 ,2] ,[1 ,2 ,2] ,[2 ,2 ,2]],
deep_supervision=True):
super(nnFormer, self).__init__()
self.img_shape=crop_size
self._deep_supervision = deep_supervision
self.do_ds = deep_supervision
self.num_classes = num_classes
self.conv_op = conv_op
self.upscale_logits_ops = []
self.upscale_logits_ops.append(lambda x: x)
embed_dim=embedding_dim
depths=depths
num_heads=num_heads
patch_size=patch_size
window_size=window_size
down_stride=down_stride
self.model_down=Encoder(pretrain_img_size=crop_size,
window_size=window_size,
embed_dim=embed_dim,
patch_size=patch_size,
depths=depths,
num_heads=num_heads,
in_chans=input_channels,
down_stride=down_stride)
self.decoder=Decoder(pretrain_img_size=crop_size,
embed_dim=embed_dim,
window_size=window_size[::-1][1:],
patch_size=patch_size,
num_heads=num_heads[::-1][1:],
depths=depths[::-1][1:],
up_stride=down_stride[::-1][1:])
self.final = []
if self.do_ds:
for i in range(len(depths) - 1):
self.final.append(final_patch_expanding(embed_dim * 2 ** i, num_classes, patch_size=patch_size))
else:
self.final.append(final_patch_expanding(embed_dim, num_classes, patch_size=patch_size))
self.final = nn.LayerList(self.final)
def forward(self, x):
seg_outputs = []
skips = self.model_down(x)
neck = skips[-1]
out = self.decoder(neck, skips)
if self.do_ds:
for i in range(len(out)):
out_put = F.interpolate(
self.final[-(i + 1)](out[i]), size=paddle.shape(x)[2:], data_format='NCDHW', mode='trilinear')
# seg_outputs.append(self.final[-(i + 1)](out[i]))
seg_outputs.append(out_put)
#原来尺寸为先大后小,参考了vnetdeep放大输出特征图
return seg_outputs[::-1]
else:
seg_outputs.append(self.final[0](out[-1]))
return seg_outputs[-1]
- 模型上采样的特征图和浅层特征图的联通,不在使用传统的concatenate或者相加的方式。而是使用了论文中提及的skip Attention的方法。
代码如下
class BasicLayer_up(nn.Layer):
def __init__(self,
dim,
input_resolution,
depth,
num_heads,
window_size=7,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop=0.,
attn_drop=0.,
drop_path=0.,
norm_layer=nn.LayerNorm,
upsample=True,
i_layer=None
):
super().__init__()
self.window_size = window_size
self.shift_size = [window_size[0] // 2,window_size[1] // 2,window_size[2] // 2]
self.depth = depth
self.blocks=nn.LayerList()
self.blocks.append(
SwinTransformerBlock_kv(
dim=dim,
input_resolution=input_resolution,
num_heads=num_heads,
window_size=window_size,
shift_size=[0,0,0] ,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop,
attn_drop=attn_drop,
drop_path=drop_path[0] if isinstance(drop_path, list) else drop_path, norm_layer=norm_layer)
)
for i in range(depth-1):
self.blocks.append(
SwinTransformerBlock(
dim=dim,
input_resolution=input_resolution,
num_heads=num_heads,
window_size=window_size,
shift_size=self.shift_size ,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop,
attn_drop=attn_drop,
drop_path=drop_path[i+1] if isinstance(drop_path, list) else drop_path, norm_layer=norm_layer)
)
self.i_layer=i_layer
if i_layer==1:
self.Upsample = upsample(dim=2*dim, norm_layer=norm_layer,tag=1)
elif i_layer==0:
self.Upsample = upsample(dim=2*dim, norm_layer=norm_layer,tag=2)
else:
self.Upsample = upsample(dim=2*dim, norm_layer=norm_layer,tag=0)
def forward(self, x, skip, S, H, W):
x_up = self.Upsample(x, S, H, W)
x = skip + x_up
if self.i_layer==1:
S, H, W = S * 2 , H * 2, W * 2
elif self.i_layer==0:
S, H, W = (S * 2)+1 , H * 2, W * 2
else:
S, H, W = S , H * 2, W * 2
attn_mask = None
x = self.blocks[0](x, attn_mask, skip=skip, x_up=x_up)
for i in range(self.depth - 1):
x = self.blocks[i + 1](x, attn_mask)
return x, S, H, W
- 至于代码的其他模块个人认为没有太多的创新。主要熟悉swintransformer和vit理解起来应该没有太大问题。无非就是把这两个网络从2d变为3d稍微注意一下。具体可也看解压后PaddleSeg/contrib/MedicalSeg/medicalseg/models/nnFormer.py实现
三、复现精度
基于paddlepaddle深度学习框架,对文献算法进行复现后,本项目达到的测试精度,如下表所示。
| task | 本项目精度 | 参考文献精度 |
|---|---|---|
| 数据集 ACDC | Dice = 91.88% | Dice = 91.78% |
四、数据集
我们要求使用的是ACDC数据集英文全称为Automated cardiac diagnosis,用于自动心脏检测。
ACDC需要分割出RV、Myo、LV,在加上背景我们有4个class。
关于ACDC的数据集具体说明可见如下网址:https://acdc.creatis.insa-lyon.fr/description/databases.html
目前这次复现主要使用了当中的Training dataset里面总共包含了100名病人的数据。
- 数据格式:
training
|
|--patient001
| |--patient001_4d.nii.gz
| |--patient001_frameXX.nii.gz
| |--patient001_frameXX_gt.nii.gz
|..............................
|--patient100
| |--patient100_4d.nii.gz
| |--patient100_frameXX.nii.gz
| |--patient100_frameXX_gt.nii.gz
数据集链接:ACDC
五、环境依赖
- 硬件:
- CPU 4
- GPU v100
- RAM 32GB
- 环境配置:
- PaddlePaddle = 2.3.1
- Python版本 3.7
六、快速开始
1、解压数据集和源代码并且安装必要的python包:
cd /home/aistudio/
unzip /home/aistudio/data/data56020/training.zip
unzip PaddleSeg.zip
pip install -r /home/aistudio/PaddleSeg/contrib/MedicalSeg/requirements.txt
%cd /home/aistudio/
!unzip /home/aistudio/data/data56020/training.zip
%cd /home/aistudio/
!unzip PaddleSeg.zip
#准备阶段:安装必要的依赖包
!pip install -r /home/aistudio/PaddleSeg/contrib/MedicalSeg/requirements.txt
2、新建必要的文件夹并且对数据集进行预处理:
cd /home/aistudio/
mkdir ACDCDataset
mkdir ACDCDataset/clean_data
mkdir ACDCDataset/preprocessed
mkdir testing
cd /home/aistudio/PaddleSeg/contrib/MedicalSeg/tools
执行下面脚本进行数据清洗和预处理,处理完成后
python prepare_acdc.py
#准备阶段:创建必要的文件夹
!mkdir ACDCDataset
!mkdir ACDCDataset/clean_data
!mkdir ACDCDataset/preprocessed
!mkdir testing
%cd /home/aistudio/PaddleSeg/contrib/MedicalSeg/tools
#进行数据清洗和数据正则化操作形成
!python prepare_acdc.py
3、执行以下命令启动训练:
cd /home/aistudio/PaddleSeg/contrib/MedicalSeg/
python train.py --config /home/aistudio/PaddleSeg/contrib/MedicalSeg/configs/nnformer_acdc/nnformer_acdc.yml \
--save_interval 20 --save_dir /home/aistudio/train_model_out --num_workers 4 --do_eval --log_iters 250 --sw_num 1 --is_save_data False --has_dataset_json False >>train.log
模型开始训练,运行完毕后,模型文件保存在save_dir设置的参数下,训练日志写入到了train.log文件中。
%cd /home/aistudio/PaddleSeg/contrib/MedicalSeg/
!python train.py --config /home/aistudio/PaddleSeg/contrib/MedicalSeg/configs/nnformer_acdc/nnformer_acdc.yml \
--save_interval 20 --save_dir /home/aistudio/train_model_out --num_workers 4 --do_eval --log_iters 250 --sw_num 1 --is_save_data False --has_dataset_json False >>train.log
4、执行以下命令进行评估
cd /home/aistudio/PaddleSeg/contrib/MedicalSeg/
python val.py --config /home/aistudio/PaddleSeg/contrib/MedicalSeg/configs/nnformer_acdc/nnformer_acdc.yml \
--model_path /home/aistudio/train_model_out/best_model/model.pdparams --save_dir /home/aistudio/train_model_out/best_model \
--num_workers 1 --sw_num 1 --is_save_data False --has_dataset_json False
用于评估模型在验证集上的精度。验证结果如下:
2022-08-04 13:57:37 [INFO] [EVAL] #Images: 40, Dice: 0.9188, Loss: 0.232877
2022-08-04 13:57:37 [INFO] [EVAL] Class dice:
[0.9972 0.8648 0.8825 0.9307]
%cd /home/aistudio/PaddleSeg/contrib/MedicalSeg/
!python val.py --config /home/aistudio/PaddleSeg/contrib/MedicalSeg/configs/nnformer_acdc/nnformer_acdc.yml \
--model_path /home/aistudio/train_model_out/best_model/model.pdparams --save_dir /home/aistudio/train_model_out/best_model \
--num_workers 1 --sw_num 1 --is_save_data False --has_dataset_json False
3、对测试数据进行动态图推理
cd /home/aistudio/PaddleSeg/contrib/MedicalSeg/
python predict.py --config /home/aistudio/PaddleSeg/contrib/MedicalSeg/configs/nnformer_acdc/nnformer_acdc.yml \
--model_path /home/aistudio/train_model_out/best_model/model.pdparams \
--image_path /home/aistudio/test_images \
--save_dir /home/aistudio/dyinferlabel
推理结果将保存在save_dir保存的目录下。如果想看具体的效果可以download下来放在itksnap上进行查看。如下图: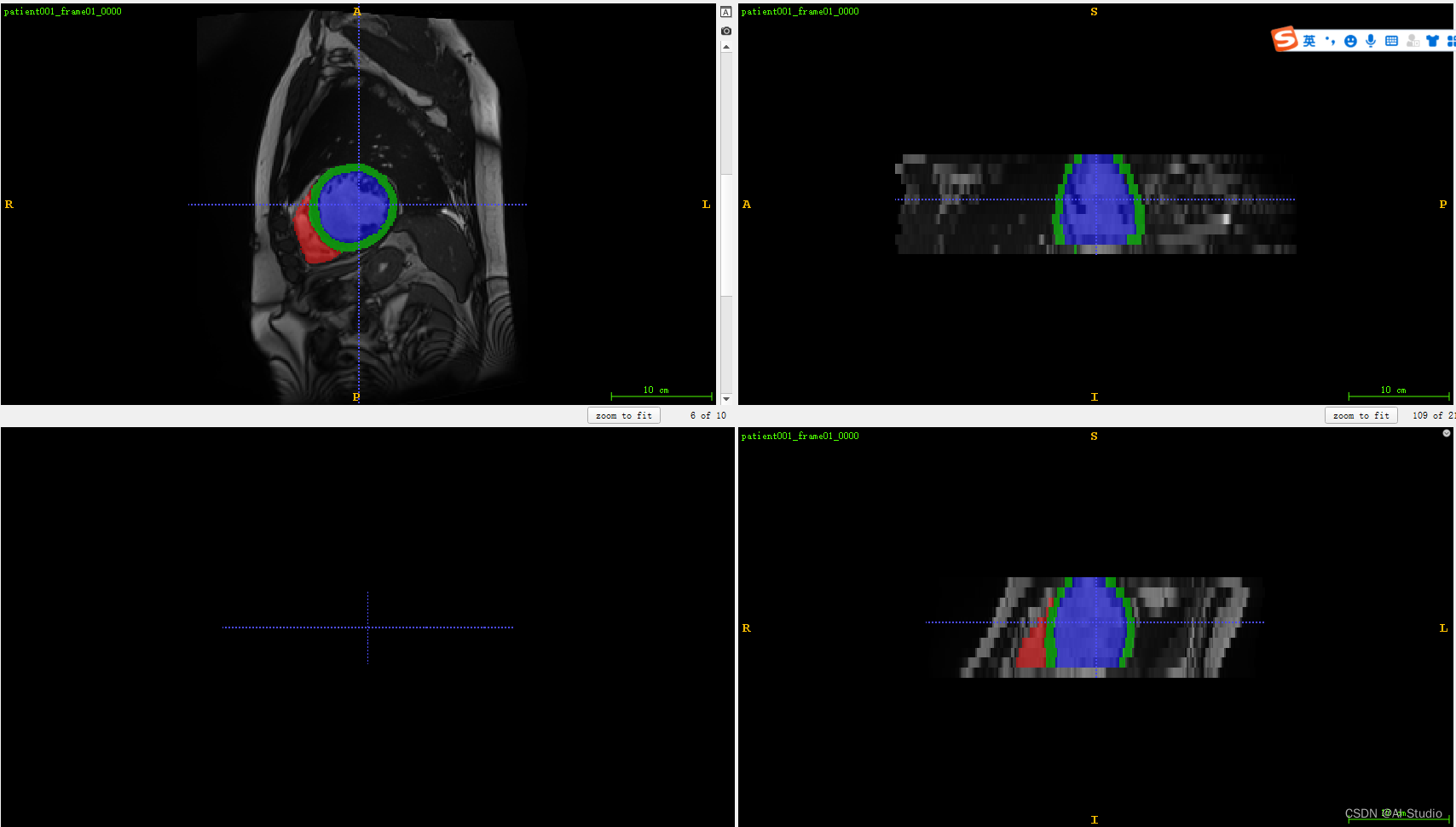
%cd /home/aistudio/PaddleSeg/contrib/MedicalSeg/
!python predict.py --config /home/aistudio/PaddleSeg/contrib/MedicalSeg/configs/nnformer_acdc/nnformer_acdc.yml \
--model_path /home/aistudio/train_model_out/best_model/model.pdparams \
--image_path /home/aistudio/test_images \
dio/test_images \
--save_dir /home/aistudio/dyinferlabel
七、代码结构与详细说明
7.1 代码结构
MedicalSeg
├── configs # All configuration stays here. If you use our model, you only need to change this and run-vnet.sh.
├── data # Data stays here.
├── test_tipc # test_tipc stays here.
├── deploy # deploy related doc and script.
├── medicalseg
│ ├── core # the core training, val and test file.
│ ├── datasets
│ ├── models
│ ├── transforms # the online data transforms
│ └── utils # all kinds of utility files
├── export.py
├── run-vnet.sh # the script to reproduce our project, including training, validate, infer and deploy
├── tools # Data preprocess including fetch data, process it and split into training and validation set
├── train.py
├── val.py
└── visualize.ipynb # You can try to visualize the result use this file.
对于论文nnformer的复现是基于Paddleseg的contrib下的MedicalSeg进行的模型开发。使用方法与原框架保持一致(我这里加了一个predict.py用来动态图推理,当然如果你愿意也可以使用静态图方法进行推理,详细说明去的repo下查看:https://github.com/YellowLight021/paddle_nnformer)
7.2 参数说明
可以在 train.py 中设置训练与评估相关参数,具体如下:
| 参数 | 默认值 | 说明 |
|---|---|---|
| –config | None | yml配置路径 |
| –save_interval | 1000 | 多少个iter进行一次保存 |
| –num_workers | 0 | 根据自己的cpu环境适当设置可调控训练时数据加载速度 |
| –do_eval | 每次保存是否在验证集上进行验证 | |
| –log_iters | 100 | 多少个iter进行一次日志打印 |
| –sw_num | None | 验证的时候进行滑窗验证的设置参数 |
| –is_save_data | True | 这里设置成False |
| –has_dataset_json | True | 这里设置成False |
可以在 eval.py 中设置训练与评估相关参数,具体如下:
| 参数 | 默认值 | 说明 |
|---|---|---|
| –config | None | yml配置路径 |
| –model_path | saved_model/vnet_lung_coronavirus_128_128_128_15k/best_model/model.pdparams | 需要验证的模型保存的路径 |
| –save_dir | saved_model/vnet_lung_coronavirus_128_128_128_15k/best_model | 验证结果的保存路径 |
| –num_workers | 0 | 根据自己的cpu环境适当设置可调控训练时数据加载速度 |
| –sw_num | None | 验证的时候进行滑窗验证的设置参数 |
| –is_save_data | True | 这里设置成False |
| –has_dataset_json | True | 这里设置成False |
可以在 predict.py 中设置训练与评估相关参数,具体如下:
| 参数 | 默认值 | 说明 |
|---|---|---|
| –config | None | yml配置路径 |
| –model_path | saved_model/vnet_lung_coronavirus_128_128_128_15k/best_model/model.pdparams | 加载模的参数路径 |
| –image_path | 需要推理的文件路径 | |
| –save_dir | 0 | 推理结果的保存路径 |
| –sw_num | None | 验证的时候进行滑窗验证的设置参数 |
7.3 训练流程
可参考快速开始章节中的描述
训练输出
执行训练开始后,将得到类似如下的输出。每次会打印当前的loss值以及不同class的dice值。
2022-08-16 09:11:52 [INFO]
------------Environment Information-------------
platform: Linux-4.15.0-140-generic-x86_64-with-debian-stretch-sid
Python: 3.7.4 (default, Aug 13 2019, 20:35:49) [GCC 7.3.0]
Paddle compiled with cuda: True
NVCC: Cuda compilation tools, release 10.1, V10.1.243
cudnn: 7.6
GPUs used: 1
CUDA_VISIBLE_DEVICES: None
GPU: ['GPU 0: Tesla V100-SXM2-32GB']
GCC: gcc (Ubuntu 7.5.0-3ubuntu1~16.04) 7.5.0
PaddlePaddle: 2.3.1
------------------------------------------------
2022-08-16 09:11:52 [INFO]
---------------Config Information---------------
batch_size: 4
data_root: data/
iters: 250000
loss:
coef:
- 0.5714
- 0.2857
- 0.1428
types:
- coef:
- 1
- 1
losses:
- type: CrossEntropyLoss
weight: null
- type: DiceLoss
type: MixedLoss
lr_scheduler:
decay_steps: 250000
end_lr: 0
learning_rate: 0.0004
power: 0.9
type: PolynomialDecay
model:
crop_size:
- 14
- 160
- 160
deep_supervision: true
depths:
- 2
- 2
- 2
- 2
down_stride:
- - 1
- 4
- 4
- - 1
- 8
- 8
- - 2
- 16
- 16
- - 4
- 32
- 32
embedding_dim: 96
input_channels: 1
num_classes: 4
num_heads:
- 3
- 6
- 12
- 24
patch_size:
- 1
- 4
- 4
type: nnFormer
window_size:
- - 3
- 5
- 5
- - 3
- 5
- 5
- - 7
- 10
- 10
- - 3
- 5
- 5
optimizer:
momentum: 0.99
type: sgd
weight_decay: 5.0e-05
train_dataset:
anno_path: train_list_0.txt
dataset_root: /home/aistudio/ACDCDataset/preprocessed
mode: train
num_classes: 4
result_dir: /home/aistudio/ACDCDataset/preprocessed
transforms:
- degrees: 15
type: RandomRotation3D
- interpolation: 3
max_scale_factor: 1.25
min_scale_factor: 0.85
p_per_sample: 0.25
type: ResizeRangeScaling
- p_per_sample: 0.1
type: GaussianNoiseTransform
- blur_sigma:
- 0.5
- 1.0
different_sigma_per_channel: true
p_per_channel: 0.5
p_per_sample: 0.2
type: GaussianBlurTransform
- multiplier_range:
- 0.75
- 1.25
p_per_sample: 0.15
type: BrightnessMultiplicativeTransform
- p_per_sample: 0.15
type: ContrastAugmentationTransform
- order_downsample: 0
order_upsample: 3
p_per_channel: 0.5
p_per_sample: 0.25
per_channel: true
type: SimulateLowResolutionTransform
zoom_range:
- 0.5
- 1
- gamma_range:
- 0.5
- 2
type: GammaTransform
- p_per_sample: 0.2
type: MirrorTransform
- crop_size:
- 14
- 160
- 160
type: RandomPaddingCrop
type: ACDCDataset
val_dataset:
anno_path: val_list_0.txt
dataset_root: /home/aistudio/ACDCDataset/preprocessed
mode: val
num_classes: 4
result_dir: /home/aistudio/ACDCDataset/preprocessed
transforms: []
type: ACDCDataset
------------------------------------------------
2022-08-16 09:12:07 [INFO] Start evaluating (total_samples: 40, total_iters: 40)...
2022-08-16 09:12:20 [INFO] [EVAL] #Images: 40, Dice: 0.2621, Loss: 0.961260
2022-08-16 09:12:20 [INFO] [EVAL] Class dice:
[0.9023 0.0441 0.0527 0.0493]
2022-08-16 09:12:21 [INFO] [EVAL] The model with the best validation mDice (0.2621) was saved at iter 20.
2022-08-16 09:12:30 [INFO] Start evaluating (total_samples: 40, total_iters: 40)...
2022-08-16 09:12:42 [INFO] [EVAL] #Images: 40, Dice: 0.2857, Loss: 0.610074
2022-08-16 09:12:42 [INFO] [EVAL] Class dice:
[0.9719 0.0513 0.063 0.0565]
2022-08-16 09:12:44 [INFO] [EVAL] The model with the best validation mDice (0.2857) was saved at iter 40.
2022-08-16 09:12:53 [INFO] Start evaluating (total_samples: 40, total_iters: 40)...
2022-08-16 09:13:04 [INFO] [EVAL] #Images: 40, Dice: 0.2983, Loss: 0.520968
2022-08-16 09:13:04 [INFO] [EVAL] Class dice:
[0.9807 0.0619 0.0811 0.0696]
2022-08-16 09:13:07 [INFO] [EVAL] The model with the best validation mDice (0.2983) was saved at iter 60.
2022-08-16 09:13:17 [INFO] Start evaluating (total_samples: 40, total_iters: 40)...
2022-08-16 09:13:28 [INFO] [EVAL] #Images: 40, Dice: 0.3092, Loss: 0.540371
2022-08-16 09:13:28 [INFO] [EVAL] Class dice:
[0.9807 0.0738 0.0977 0.0848]
2022-08-16 09:13:30 [INFO] [EVAL] The model with the best validation mDice (0.3092) was saved at iter 80.
2022-08-16 09:13:40 [INFO] Start evaluating (total_samples: 40, total_iters: 40)...
2022-08-16 09:13:51 [INFO] [EVAL] #Images: 40, Dice: 0.3173, Loss: 0.543501
2022-08-16 09:13:51 [INFO] [EVAL] Class dice:
[0.9807 0.0847 0.1076 0.0963]
2022-08-16 09:13:53 [INFO] [EVAL] The model with the best validation mDice (0.3173) was saved at iter 100.
2022-08-16 09:14:02 [INFO] Start evaluating (total_samples: 40, total_iters: 40)...
2022-08-16 09:14:16 [INFO] [EVAL] #Images: 40, Dice: 0.3243, Loss: 0.511888
2022-08-16 09:14:16 [INFO] [EVAL] Class dice:
[0.981 0.0946 0.1162 0.1054]
2022-08-16 09:14:18 [INFO] [EVAL] The model with the best validation mDice (0.3243) was saved at iter 120.
2022-08-16 09:14:27 [INFO] Start evaluating (total_samples: 40, total_iters: 40)...
2022-08-16 09:14:39 [INFO] [EVAL] #Images: 40, Dice: 0.3224, Loss: 0.498481
2022-08-16 09:14:39 [INFO] [EVAL] Class dice:
[0.981 0.0925 0.1143 0.1019]
2022-08-16 09:14:40 [INFO] [EVAL] The model with the best validation mDice (0.3243) was saved at iter 120.
2022-08-16 09:14:49 [INFO] Start evaluating (total_samples: 40, total_iters: 40)...
2022-08-16 09:15:00 [INFO] [EVAL] #Images: 40, Dice: 0.3168, Loss: 0.503380
2022-08-16 09:15:00 [INFO] [EVAL] Class dice:
[0.9807 0.0861 0.1071 0.0932]
7.4 测试流程
可参考快速开始章节中的描述
此时的输出为:
val_dataset:
anno_path: val_list_0.txt
dataset_root: /home/aistudio/ACDCDataset/preprocessed
mode: val
num_classes: 4
result_dir: /home/aistudio/ACDCDataset/preprocessed
transforms: []
type: ACDCDataset
------------------------------------------------
W0804 13:57:11.316898 22617 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0804 13:57:11.316946 22617 gpu_resources.cc:91] device: 0, cuDNN Version: 7.6.
2022-08-04 13:57:13 [INFO] Loading pretrained model from /home/aistudio/PaddleSeg/contrib/MedicalSeg/output/best_model/model.pdparams
2022-08-04 13:57:14 [INFO] There are 250/250 variables loaded into nnFormer.
2022-08-04 13:57:14 [INFO] Loaded trained params of model successfully
2022-08-04 13:57:14 [INFO] Start evaluating (total_samples: 40, total_iters: 40)...
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/math_op_patch.py:278: UserWarning: The dtype of left and right variables are not the same, left dtype is paddle.float32, but right dtype is paddle.bool, the right dtype will convert to paddle.float32
format(lhs_dtype, rhs_dtype, lhs_dtype))
40/40 [==============================] - 23s 566ms/step - batch_cost: 0.5654 - reader cost: 0.00659s - batch_cost: 0.94 - ETA: 13s - batch_cost: 0.692
2022-08-04 13:57:37 [INFO] [EVAL] #Images: 40, Dice: 0.9188, Loss: 0.232877
2022-08-04 13:57:37 [INFO] [EVAL] Class dice:
[0.9972 0.8648 0.8825 0.9307]
八、复现心得
(1)swintransformer的更深度理解:以往使用swintransformer的时候都是基于2d的,在面对3d的时候虽然原理差不多但是需要更多的空间想象能力。这次复现对自己有一定的提升
(2)patch embeding的灵活使用:由于之前对transformer不是很熟也是初步接触,通过复现这次论文也看到了在patch embeding的不同的使用方法,该论文的方式保存了原图更多的细节信息
(3)上采样信息和浅层信息的融合方式:以往的认知中认为融合方式只有concatenate和元素相加两种。该偏论文将上采样的特征图作为Q帮助浅层信息注意到更重要的v。感觉还是比较有意思的
(4)另外这次论文复现使用了batchgenerator中的诸多数据增强方式,我所做的一部分工作也是将其中用到的数据增广方式集成到了我们框架中的transformer.py文件中,也为以后类似的工作做好了铺垫
九.说明
感谢百度提供的算力,以及举办的本场比赛,让我增强对paddle的熟练度,加深对模型的理解!
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 12
12 1
1- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)