
[比赛分享]讯飞-基于论文摘要的文本分类与查询性问答第4名(并列第3)的思考
这里聊聊如何入门NLP比赛,一些方法,一些技巧,一些思考
序
先说说这个比赛,科大讯飞2022年一系列比赛中的一个:《基于论文摘要的文本分类与查询性问答》
这个比赛的具体内容可以看看上面的链接,非常简单的一个多分类任务:
根据论文标题、作者、DOI、Citation、摘要,来判断论文的分类
本来没什么可聊的,但是很不幸,最后是个第4名,并列第3的成绩,由于提交次数多而落败(取前3)。[捂脸]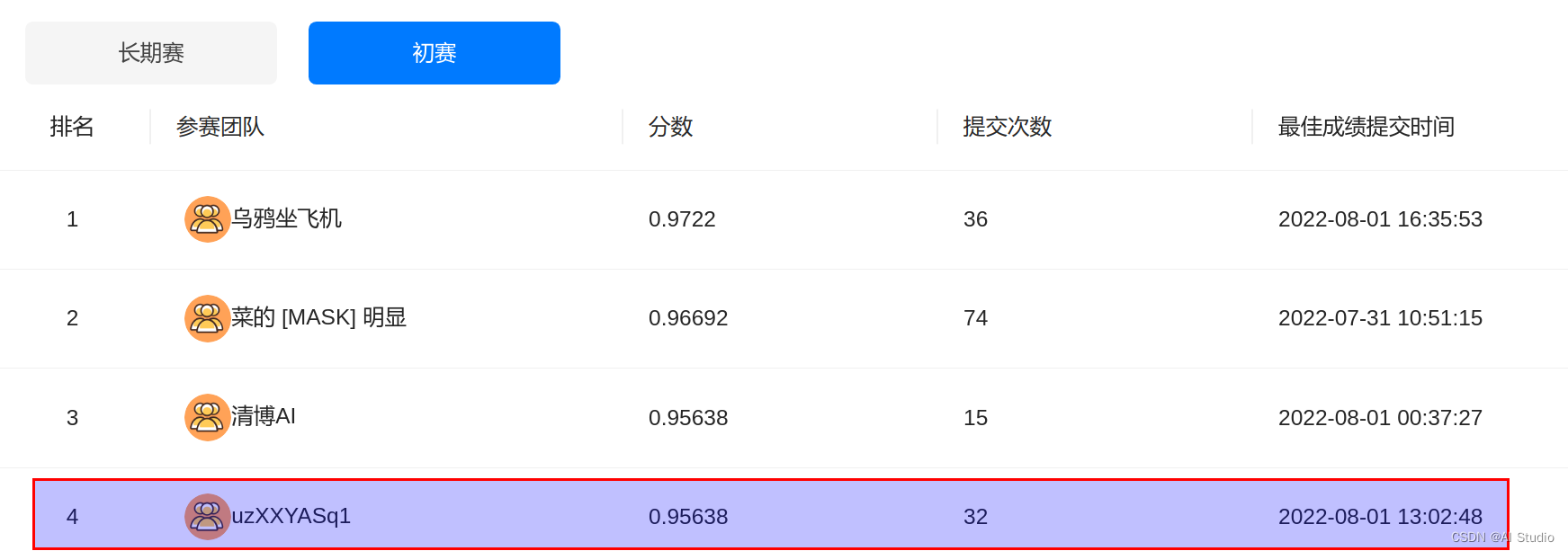
过往已矣,那就写点东西,当作用paddle玩nlp比赛的入门跟大家交流交流。
本文分为这几个部分:
- 比赛与任务
- 一些方法
- 一些技巧
- 一些思考
%%capture
# 安装依赖
!pip install -r work/requirements.txt
比赛与任务
我们先来看看此次比赛的数据
1. 数据概览
import numpy as np
import pandas as pd
df_train = pd.read_csv('work/data/train.csv')
df_test = pd.read_csv('work/data/test.csv')
df_sub = pd.read_csv('work/data/提交示例.csv')
df_train.head(2)
| Title | Authors | Citation | Abstract | DOI | Topic(Label) | |
|---|---|---|---|---|---|---|
| 0 | \n \n \n \n \n \n \n The Va... | ['Seyhmus Tunc', 'Suleyman Cemil Oglak', 'Fatm... | 2022 Jun;32(6):722-727. | \n\n\n Objective:\n \n \n... | \n doi: 10.29271/jcpsp.2022.06.722.\n ... | Abdominal+Fat |
| 1 | \n \n \n \n \n \n \n Metfor... | ['Katrin Schmitz', 'Eva-Maria Turnwald', 'Tobi... | 2022 May 30;14(11):2288. | \n\n \n With the gaining prevalence ... | \n doi: 10.3390/nu14112288.\n | Abdominal+Fat |
df_test.head(2)
| Title | Authors | Citation | Abstract | DOI | |
|---|---|---|---|---|---|
| 0 | \n \n \n \n \n \n \n Gut mi... | ['Xiaomin Su', 'Minying Zhang', 'Houbao Qi', '... | 2022 Jan 24;10(1):13. | \n\n\n Background:\n \n \... | \n doi: 10.1186/s40168-021-01205-8.\n ... |
| 1 | \n \n \n \n \n \n \n [A spa... | ['Naigong Yu', 'Yishen Liao', 'Naigong Yu', 'Y... | 2022 Apr 25;39(2):217-227. | \n\n \n Physiological studies reveal... | \n doi: 10.7507/1001-5515.202109051.\n ... |
训练数据包含:
- Title: 文章标题
- Authors: 文章作者
- Citation: 文章引用
- Abstract: 文章摘要
- DOI: 文章doi
以及标签:Topic(Label)
既然要多分类,那就要确认有哪些类别:
df_train['Topic(Label)'].value_counts()
Neoplasms 1500
Diabetes+Mellitus 1500
Fasting 1500
Gastrointestinal+Microbiome 1500
Artificial+Intelligence 1500
psychology 1500
MicroRNAs 1500
Parkinson+Disease 1500
Abdominal+Fat 1500
Inflammation 1500
Culicidae 1499
Humboldt states 1
Name: Topic(Label), dtype: int64
可以看到数据的分布还是很均衡的,也就是说,这是个连数据均衡问题都不存在的多分类问题。nlp入门绝配!
除了“ Humboldt states”这个标签,我这里直接将其去掉。由此得到下面的标签数据:
LABELS = ['Gastrointestinal+Microbiome',
'MicroRNAs',
'Diabetes+Mellitus',
'Inflammation',
'psychology',
'Neoplasms',
'Abdominal+Fat',
'Artificial+Intelligence',
'Fasting',
'Parkinson+Disease',
'Culicidae',]
# 生成label与idx的对应关系dict
# label:idx
LABELS = {k:i for i, k in enumerate(LABELS)}
# idx:label
LABELS_IDX = {i:k for k, i in LABELS.items()}
由此得到一个11分类任务,接下来就是构建训练数据。
2. 数据预处理
import re
def get_data(df, is_test=False):
# 合并空白字符的regex
pattern = '\\n\s*'
data_x, data_y = [], []
for _, row in df.iterrows():
title = str(row['Title']).strip().lower()
citation = str(row['Citation']).strip().lower()
abstract = str(row['Abstract']).strip().lower()
abstract = re.sub(pattern, ' ', abstract).strip()
data_x.append(title + '[SEP]' + citation + '[SEP]' + abstract)
label = 0
if not is_test:
label = str(row['Topic(Label)']).strip()
if label in LABELS:
label = LABELS[label]
else:
label = 0
data_y.append(label)
return data_x, data_y
train_x, train_y = get_data(df_train, is_test=False)
len(train_x), len(train_y)
(16504, 16504)
train_x[0], train_y[0]
("the value of first-trimester maternal abdominal visceral adipose tissue thickness in predicting the subsequent development of gestational diabetes mellitus[SEP]2022 jun;32(6):722-727.[SEP]objective: to examine the performance of first-trimester visceral (pre-peritoneal), subcutaneous, and total adipose tissue thickness (att) to predict the patients with subsequently developing gestational diabetes mellitus (gdm). study design: observational study. place and duration of study: department of obstetrics and gynecology, diyarbakä±r gazi yaå\x9fargil training and research hospital from january 2021 to july 2021. methodology: a total of 100 pregnant women underwent sonographic measurement of subcutaneous and visceral att at 11-14 weeks' gestation. a 75-g oral glucose tolerance test (ogtt) was conducted between 24-28 weeks of pregnancy for the diagnosis of gdm. results: the mean visceral, subcutaneous, and total att were significantly higher in the gdm group (24.75 â± 10.34 mm, 26.33 â± 5.33 mm, 51.08 â± 14.4 mm) than in the group without a gdm diagnosis (16.68 â± 6.73 mm, 17.68 â± 4.86 mm, 34.25 â± 11.04, respectively, p<0.001). a pre-gestational bmi >30 kg/m2 (odds ratio [or]=10.20, 95% ci=2.519-41.302, p=0.001), visceral att (or=33.2, 95% ci=7.395-149.046, p<0.001), subcutaneous att (or=4.543, 95% ci=1.149-17.960, p=0.031), and total att (or=10.895, 95% ci=2.682-44.262, p=0.001) were the factors that were found to be significantly associated with the subsequent development of gdm after adjusting for potential confounders (maternal age, and parity). the most significant risk factor for the prediction of gdm is visceral att with an or of 33.2. conclusion: us measurement of maternal visceral att during first-trimester fetal aneuploidy screening is a reliable, reproducible, cost-effective, and safe method to identify pregnant women at high risk for gdm. key words: gestational diabetes mellitus, visceral adipose tissue thickness, subcutaneous adipose tissue thickness.",
6)
这里的数据处理也很简单,取每条记录的title、citation、abstract三部分数据,使用正则表达式: pattern = ‘\n\s*’ 将文字中间的多个空白(回车、空格等)合成一个,然后strip掉前后的空白字符,完事儿~
在字符串拼接的时候,这里使用[SEP]作为连接符,tokenizer的时候会作为特殊字符处理,为的是希望模型能够区分各个部分的内容。
为了能够使用paddle处理数据,还需要将其封装为特定的loader模式,但是在这之前我们需要确认具体使用哪个模型进行分类,这里使用bert-base-uncased
作为演示,后面会说说各个模型的实验结果,训练中主要参数如:
- model_name = ‘bert-base-uncased’ (比赛中改为bert-large-uncased)
- MAX_LEN = 128 (比赛中改为512)
- BATCH_SIZE = 64 (比赛中改为8,32g的gpu环境使用bert-large-uncased模型比较合适的大小)
- EPOCHS = 3 (比赛中改为11足够了)
- optimizer = paddle.optimizer.AdamW(learning_rate=1e-5, parameters=model.parameters()) (learning_rate=1e-4可能会不收敛)
另外,这里使用paddlenlp.transformers中的AutoModelForSequenceClassification, AutoTokenizer。使用AutoXXX的最大好处是,尝试多种模型的时候只要改一改预训练模型名称就可以了,谁不想少敲几行代码呢…
3. 模型与训练
import functools
from paddle.io import DataLoader, BatchSampler
from paddlenlp.datasets import MapDataset
from paddlenlp.data import DataCollatorWithPadding
from paddlenlp.data import Dict, Stack, Pad
from paddlenlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
MAX_LEN = 128 # 512
BATCH_SIZE = 64 # 8
model_name = 'bert-base-uncased' # 'bert-large-uncased'
# 生成预训练模型
num_classes = len(LABELS)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_classes=num_classes)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 数据预处理函数,利用分词器将文本转化为整数序列
def preprocess_function(examples, tokenizer, max_seq_length):
result = tokenizer(text=examples["text"], max_seq_len=max_seq_length, truncation=True)
result["labels"] = examples["labels"]
return result
# 生成data loader的几大步骤:
# 1. 生成list或dict的数据
train_data = [{"text": train_x[i], "labels": train_y[i]} for i in range(len(train_x))]
# 2. 封装成MapDataset
train_ds = MapDataset(train_data)
# 3. 转换数据格式为输入形式
trans_func = functools.partial(preprocess_function, tokenizer=tokenizer, max_seq_length=MAX_LEN)
train_ds = train_ds.map(trans_func)
# 4. 将每个batch中的各个字段进行对齐
collate_fn = lambda samples, fn=Dict({
'input_ids': Pad(axis=0, pad_val=tokenizer.pad_token_id),
'token_type_ids': Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
'labels': Stack(dtype="int64")
}): fn(samples)
# 5. 封装成sampler
train_batch_sampler = BatchSampler(train_ds, batch_size=BATCH_SIZE, shuffle=True)
# 6. 封装成data loader
train_data_loader = DataLoader(dataset=train_ds, batch_sampler=train_batch_sampler, collate_fn=collate_fn)
[2022-08-14 18:40:32,359] [ INFO] - We are using <class 'paddlenlp.transformers.bert.modeling.BertForSequenceClassification'> to load 'bert-base-uncased'.
[2022-08-14 18:40:32,362] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/bert-base-uncased/bert-base-uncased.pdparams
W0814 18:40:32.365370 3828 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0814 18:40:32.369132 3828 gpu_resources.cc:91] device: 0, cuDNN Version: 7.6.
[2022-08-14 18:40:38,784] [ INFO] - We are using <class 'paddlenlp.transformers.bert.tokenizer.BertTokenizer'> to load 'bert-base-uncased'.
[2022-08-14 18:40:38,788] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/bert-base-uncased/bert-base-uncased-vocab.txt
[2022-08-14 18:40:38,808] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/bert-base-uncased/tokenizer_config.json
[2022-08-14 18:40:38,810] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/bert-base-uncased/special_tokens_map.json
接下来就是喜闻乐见的炼丹环节
import os
import time
import paddle
import paddle.nn.functional as F
from paddle.metric import Accuracy
EPOCHS = 3 # 11
CKPT_DIR = './work/output'
epoch_base = 0
# 注意:learning_rate=1e-4 可能不收敛
# optimizer = paddle.optimizer.AdamW(learning_rate=1e-4, parameters=model.parameters())
optimizer = paddle.optimizer.AdamW(learning_rate=1e-5, parameters=model.parameters())
criterion = paddle.nn.CrossEntropyLoss()
metric = Accuracy()
epochs = EPOCHS # 训练轮次
ckpt_dir = CKPT_DIR #训练过程中保存模型参数的文件夹
global_step = 0 #迭代次数
tic_train = time.time()
for epoch in range(1+epoch_base, epochs+epoch_base+1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch
# 计算模型输出
logits = model(input_ids, token_type_ids)
loss = criterion(logits, labels)
correct = metric.compute(logits, labels)
metric.update(correct)
res = metric.accumulate()
# 每迭代10次,打印损失函数值、准确率、计算速度
global_step += 1
if global_step % 10 == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %.5f, auc: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, res,
10 / (time.time() - tic_train)))
tic_train = time.time()
# 反向梯度回传,更新参数
loss.backward()
optimizer.step()
optimizer.clear_grad()
# 每迭代400次,评估当前训练的模型、保存当前最佳模型参数和分词器的词表等
if global_step % 400 == 0:
save_dir = ckpt_dir
if not os.path.exists(save_dir):
os.makedirs(save_dir)
model.save_pretrained(save_dir)
tokenizer.save_pretrained(save_dir)
_save_dir = '{}/{}_epoch_{}'.format(ckpt_dir, 'bert', epoch)
model.save_pretrained(_save_dir)
tokenizer.save_pretrained(_save_dir)
global step 10, epoch: 1, batch: 10, loss: 2.38900, auc: 0.09531, speed: 1.07 step/s
global step 20, epoch: 1, batch: 20, loss: 2.20959, auc: 0.14766, speed: 1.49 step/s
global step 30, epoch: 1, batch: 30, loss: 2.15017, auc: 0.19219, speed: 1.49 step/s
global step 40, epoch: 1, batch: 40, loss: 1.93043, auc: 0.23164, speed: 1.48 step/s
global step 50, epoch: 1, batch: 50, loss: 1.77597, auc: 0.26875, speed: 1.47 step/s
global step 60, epoch: 1, batch: 60, loss: 1.77423, auc: 0.30651, speed: 1.46 step/s
global step 70, epoch: 1, batch: 70, loss: 1.68550, auc: 0.35156, speed: 1.47 step/s
global step 80, epoch: 1, batch: 80, loss: 1.55579, auc: 0.39199, speed: 1.49 step/s
global step 90, epoch: 1, batch: 90, loss: 1.36902, auc: 0.42760, speed: 1.45 step/s
global step 100, epoch: 1, batch: 100, loss: 1.35927, auc: 0.46094, speed: 1.47 step/s
global step 110, epoch: 1, batch: 110, loss: 1.32357, auc: 0.49190, speed: 1.49 step/s
global step 120, epoch: 1, batch: 120, loss: 1.10651, auc: 0.51888, speed: 1.49 step/s
global step 130, epoch: 1, batch: 130, loss: 1.09968, auc: 0.54519, speed: 1.47 step/s
global step 140, epoch: 1, batch: 140, loss: 1.01737, auc: 0.56674, speed: 1.46 step/s
global step 150, epoch: 1, batch: 150, loss: 0.93302, auc: 0.58562, speed: 1.48 step/s
global step 160, epoch: 1, batch: 160, loss: 0.76371, auc: 0.60371, speed: 1.45 step/s
global step 170, epoch: 1, batch: 170, loss: 0.78176, auc: 0.61857, speed: 1.48 step/s
global step 180, epoch: 1, batch: 180, loss: 0.62707, auc: 0.63255, speed: 1.47 step/s
global step 190, epoch: 1, batch: 190, loss: 0.59483, auc: 0.64548, speed: 1.45 step/s
global step 200, epoch: 1, batch: 200, loss: 0.56439, auc: 0.65594, speed: 1.47 step/s
global step 210, epoch: 1, batch: 210, loss: 0.60130, auc: 0.66674, speed: 1.47 step/s
global step 220, epoch: 1, batch: 220, loss: 0.62305, auc: 0.67635, speed: 1.49 step/s
global step 230, epoch: 1, batch: 230, loss: 0.63927, auc: 0.68539, speed: 1.47 step/s
global step 240, epoch: 1, batch: 240, loss: 0.50424, auc: 0.69395, speed: 1.48 step/s
global step 250, epoch: 1, batch: 250, loss: 0.44211, auc: 0.70169, speed: 1.48 step/s
[2022-08-14 18:43:36,235] [ INFO] - tokenizer config file saved in ./work/output/bert_epoch_1/tokenizer_config.json
[2022-08-14 18:43:36,238] [ INFO] - Special tokens file saved in ./work/output/bert_epoch_1/special_tokens_map.json
global step 260, epoch: 2, batch: 2, loss: 0.44465, auc: 0.70857, speed: 1.18 step/s
global step 270, epoch: 2, batch: 12, loss: 0.45821, auc: 0.71572, speed: 1.46 step/s
global step 280, epoch: 2, batch: 22, loss: 0.45903, auc: 0.72225, speed: 1.48 step/s
global step 290, epoch: 2, batch: 32, loss: 0.38939, auc: 0.72882, speed: 1.49 step/s
global step 300, epoch: 2, batch: 42, loss: 0.46119, auc: 0.73447, speed: 1.46 step/s
global step 310, epoch: 2, batch: 52, loss: 0.59316, auc: 0.73951, speed: 1.48 step/s
global step 320, epoch: 2, batch: 62, loss: 0.38994, auc: 0.74453, speed: 1.46 step/s
global step 330, epoch: 2, batch: 72, loss: 0.52558, auc: 0.74829, speed: 1.48 step/s
global step 340, epoch: 2, batch: 82, loss: 0.52665, auc: 0.75248, speed: 1.46 step/s
global step 350, epoch: 2, batch: 92, loss: 0.51046, auc: 0.75674, speed: 1.44 step/s
global step 360, epoch: 2, batch: 102, loss: 0.36388, auc: 0.76059, speed: 1.46 step/s
global step 370, epoch: 2, batch: 112, loss: 0.25546, auc: 0.76479, speed: 1.49 step/s
global step 380, epoch: 2, batch: 122, loss: 0.46652, auc: 0.76888, speed: 1.45 step/s
global step 390, epoch: 2, batch: 132, loss: 0.55221, auc: 0.77204, speed: 1.47 step/s
global step 400, epoch: 2, batch: 142, loss: 0.30350, auc: 0.77509, speed: 1.44 step/s
[2022-08-14 18:45:16,268] [ INFO] - tokenizer config file saved in ./work/output/tokenizer_config.json
[2022-08-14 18:45:16,271] [ INFO] - Special tokens file saved in ./work/output/special_tokens_map.json
global step 410, epoch: 2, batch: 152, loss: 0.33138, auc: 0.77775, speed: 1.29 step/s
global step 420, epoch: 2, batch: 162, loss: 0.44352, auc: 0.78074, speed: 1.47 step/s
global step 430, epoch: 2, batch: 172, loss: 0.28219, auc: 0.78348, speed: 1.47 step/s
global step 440, epoch: 2, batch: 182, loss: 0.24660, auc: 0.78684, speed: 1.49 step/s
global step 450, epoch: 2, batch: 192, loss: 0.57840, auc: 0.78932, speed: 1.48 step/s
global step 460, epoch: 2, batch: 202, loss: 0.33877, auc: 0.79179, speed: 1.48 step/s
global step 470, epoch: 2, batch: 212, loss: 0.39400, auc: 0.79423, speed: 1.49 step/s
global step 480, epoch: 2, batch: 222, loss: 0.26174, auc: 0.79702, speed: 1.47 step/s
global step 490, epoch: 2, batch: 232, loss: 0.44455, auc: 0.79890, speed: 1.48 step/s
global step 500, epoch: 2, batch: 242, loss: 0.31625, auc: 0.80101, speed: 1.49 step/s
global step 510, epoch: 2, batch: 252, loss: 0.34040, auc: 0.80295, speed: 1.48 step/s
[2022-08-14 18:46:34,186] [ INFO] - tokenizer config file saved in ./work/output/bert_epoch_2/tokenizer_config.json
[2022-08-14 18:46:34,189] [ INFO] - Special tokens file saved in ./work/output/bert_epoch_2/special_tokens_map.json
global step 520, epoch: 3, batch: 4, loss: 0.26164, auc: 0.80504, speed: 1.19 step/s
global step 530, epoch: 3, batch: 14, loss: 0.33711, auc: 0.80681, speed: 1.47 step/s
global step 540, epoch: 3, batch: 24, loss: 0.19801, auc: 0.80911, speed: 1.45 step/s
global step 550, epoch: 3, batch: 34, loss: 0.17991, auc: 0.81102, speed: 1.47 step/s
global step 560, epoch: 3, batch: 44, loss: 0.38108, auc: 0.81286, speed: 1.48 step/s
global step 570, epoch: 3, batch: 54, loss: 0.38914, auc: 0.81483, speed: 1.46 step/s
global step 580, epoch: 3, batch: 64, loss: 0.27628, auc: 0.81670, speed: 1.49 step/s
global step 590, epoch: 3, batch: 74, loss: 0.15692, auc: 0.81846, speed: 1.46 step/s
global step 600, epoch: 3, batch: 84, loss: 0.26186, auc: 0.82000, speed: 1.49 step/s
global step 610, epoch: 3, batch: 94, loss: 0.26548, auc: 0.82139, speed: 1.45 step/s
global step 620, epoch: 3, batch: 104, loss: 0.54024, auc: 0.82306, speed: 1.48 step/s
global step 630, epoch: 3, batch: 114, loss: 0.24660, auc: 0.82481, speed: 1.47 step/s
global step 640, epoch: 3, batch: 124, loss: 0.21786, auc: 0.82625, speed: 1.45 step/s
global step 650, epoch: 3, batch: 134, loss: 0.24654, auc: 0.82777, speed: 1.43 step/s
global step 660, epoch: 3, batch: 144, loss: 0.15804, auc: 0.82903, speed: 1.48 step/s
global step 670, epoch: 3, batch: 154, loss: 0.31903, auc: 0.83056, speed: 1.48 step/s
global step 680, epoch: 3, batch: 164, loss: 0.18426, auc: 0.83185, speed: 1.47 step/s
global step 690, epoch: 3, batch: 174, loss: 0.17168, auc: 0.83359, speed: 1.49 step/s
global step 700, epoch: 3, batch: 184, loss: 0.29546, auc: 0.83476, speed: 1.48 step/s
global step 710, epoch: 3, batch: 194, loss: 0.32256, auc: 0.83601, speed: 1.47 step/s
global step 720, epoch: 3, batch: 204, loss: 0.20161, auc: 0.83744, speed: 1.48 step/s
global step 730, epoch: 3, batch: 214, loss: 0.22560, auc: 0.83841, speed: 1.46 step/s
global step 740, epoch: 3, batch: 224, loss: 0.22592, auc: 0.83943, speed: 1.45 step/s
global step 750, epoch: 3, batch: 234, loss: 0.38525, auc: 0.84045, speed: 1.48 step/s
global step 760, epoch: 3, batch: 244, loss: 0.28458, auc: 0.84148, speed: 1.48 step/s
global step 770, epoch: 3, batch: 254, loss: 0.20067, auc: 0.84258, speed: 1.57 step/s
[2022-08-14 18:49:31,399] [ INFO] - tokenizer config file saved in ./work/output/bert_epoch_3/tokenizer_config.json
[2022-08-14 18:49:31,401] [ INFO] - Special tokens file saved in ./work/output/bert_epoch_3/special_tokens_map.json
模型训练好之后就可以生成预测结果~
# 首先处理测试数据
test_x, _ = get_data(df_test, is_test=True)
test_data = [{"text": test_x[i], "labels": 0} for i in range(len(test_x))]
test_ds = MapDataset(test_data)
test_ds = test_ds.map(trans_func)
test_batch_sampler = BatchSampler(test_ds, batch_size=BATCH_SIZE, shuffle=False)
test_data_loader = DataLoader(dataset=test_ds, batch_sampler=test_batch_sampler, collate_fn=collate_fn)
for i in range(1, EPOCHS+1):
model.set_dict(paddle.load('{}/{}_epoch_{}/model_state.pdparams'.format(CKPT_DIR, 'bert', i)))
# 构建验证集evaluate函数
@paddle.no_grad()
def do_pred(model, data_loader, label_vocab):
model.eval()
results = []
for batch in data_loader:
input_ids, token_type_ids, labels = batch
logits = model(input_ids, token_type_ids)
# paddle.nn.CrossEntropyLoss是包含了softmax操作的
# 而模型的输出是线性的,所以需要先转成softmax
probs = F.softmax(logits).numpy()
results.extend([label_vocab[i] for i in np.argmax(probs, axis=1)])
return results
pred = do_pred(model, test_data_loader, LABELS_IDX)
df_sub['Topic(Label)'] = pred
df_sub.to_csv('./work/results/{}_epoch_{}.csv'.format('bert', i), index=False)
df_result = pd.read_csv('./work/results/bert_epoch_1.csv')
df_result
| Topic(Label) | |
|---|---|
| 0 | Gastrointestinal+Microbiome |
| 1 | Artificial+Intelligence |
| 2 | Gastrointestinal+Microbiome |
| 3 | Inflammation |
| 4 | Gastrointestinal+Microbiome |
| ... | ... |
| 2081 | MicroRNAs |
| 2082 | Diabetes+Mellitus |
| 2083 | Neoplasms |
| 2084 | Diabetes+Mellitus |
| 2085 | psychology |
2086 rows × 1 columns
确认一下生成的csv文件没啥问题就可以提交了~
至此,一个相对完整的比赛流程就完成了!
比赛本身比较简单,拿来入手paddle真是再合适不过了,比赛网页中的长期赛目前还可以提交结果,有兴趣的可以练练手!
一些方法
先说说比赛本身。
当拿到一个比赛题目之后,首先要做的就是分分类,这里仅就nlp相关的问题来说:
- 是分类问题,还是序列问题,还是生成问题
- 分类:比如情感分析(积极/消极/中性),有的是二分类,有的是多分类(比如这道题),其实可以都当作多分类来处理,这样不用纠结sigmoid或者softmax,代码基本就不需要动了~
- 序列:比如命名实体(NER),输入输出是个一对一的关系
- 生成:其他很多问题如果上面两个模型解决不了,基本都可以用生成模型来做。
- 是否需要自定义模型
- 否:如果是单个任务题目,大部分时候不要自定义模型,这个时候用paddle的AutoModelXXX就很方便,尝试多个model的预训练模型,结果可能会有多个点的差别
- 是:如果一个题目既需要做分类又有序列输出的要求,或者题目比较特别,那么可能就需要定制模型了,比如正在进行的文本智能校对大赛,输入中如果加入拼音的embedding更合理(参考baseline),后面有需要的话再单独开一篇定制模型的文章吧~
上面先把问题定义好了,那接下来就是处理数据:
- 中文vs英文
- 中文跟英文的数据所使用的预训练模型大部分是不一样的,后面具体讲讲怎么找怎么用这些预训练模型
- 预处理,比如英文的大小写统一,空白字符的合并,中文半角全角字符的转换。现在预训练模型的vocab size基本都足够,所以很多时候不怎么需要预处理直接炼,结果也差不了多少…
- 数据集
- 外部数据集: 模型的好坏很大一部分取决于数据集的好坏,有的比赛允许使用外部开源数据集,那么能拿到越多的相关数据集,理论上结果就会越好,这里简单列几个:
- 天池数据集,比如中文医疗信息处理评测基准CBLUE
- CLUE,各类数据集比较全
- 千言,还有各类相关比赛
- 数据增强:nlp的数据增强也有相关工具,不过平时用的不多,这里就不推荐了,不过在具体处理任务的时候可以尝试随机应变,比如实体替换,随机mask掉几个字符等等
- 外部数据集: 模型的好坏很大一部分取决于数据集的好坏,有的比赛允许使用外部开源数据集,那么能拿到越多的相关数据集,理论上结果就会越好,这里简单列几个:
再说回用paddle打比赛,paddlenlp内置了很多预训练模型,要找到这些模型至少有两个途径:
- 官方文档: 这里面列出了paddlenlp中内置的预训练模型,以及中英文的支持情况
- 源码:这是gitee的地址,国内比较快。我个人来这里找模型的情况比较多,因为既可以查看各个模型的参数,又可以看到模型的代码实现情况,对于后续排查问题很有帮助。
最后说说怎么用这些预训练模型,一般来说,用AutoModelForXXX基本就够用,模式类似于这样:
from paddlenlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
MODEL = 'ernie-3.0-base-zh'
num_classes = 2
model = AutoModelForSequenceClassification.from_pretrained(MODEL, num_classes=num_classes)
tokenizer = AutoTokenizer.from_pretrained(MODEL)
这里有几个点注意一下:
AutoModelForSequenceClassification用来解决分类问题,AutoModelForTokenClassification用来一对一的序列问题。model与tokenizer要成对出现,每个模型的vocab不一样,混用就出错了。num_classes设为2的二分类用softmax解决,与num_classes设为1的二分类用sigmoid解决理论上是一样的,但是用softmax适用面更广一些。
如果需要定制模型,也可以用下面的方法引入预训练模型:
from paddlenlp.transformers import ErnieForSequenceClassification, ErnieTokenizer
MODEL = 'ernie-3.0-base-zh'
num_classes = 2
model = ErnieForSequenceClassification.from_pretrained(MODEL, num_classes=num_classes)
tokenizer = ErnieTokenizer.from_pretrained(MODEL)
这种方法用来具体指定模型的原型与定制模型来说比较好。
具体问题具体分析,关于**“一些方法”**就先说这么多吧~
一些技巧
既然是打比赛,提分的技巧还是要有的,这里就这个比赛简单说说:
- 单个模型:如果使用单个模型,那么不同模型的预训练模型可能会导致较大的成绩区别,比如这个比赛:
| gpt epoch 5 | bert epoch 5 | bert large epoch 5 |
|---|---|---|
| 0.92761 | 0.93528 | 0.94966 |
另外,不同的epoch影响也比较大:
| bert epoch 3 | bert epoch 5 | bert epoch 7 |
|---|---|---|
| 0.94295 | 0.93528 | 0.94919 |
成绩与epoch没有必然的线性关系,所以多尝试总没错。
- 多个模型:如果时间或者条件有限,那么多个模型ensemble/voting是比较快提分的途径:
| ensemble 4个 | ensemble 7个 | ensemble 9个 |
|---|---|---|
| 0.95302 | 0.95542 | 0.95638 |
-
特征选取:这个比赛比较特殊的是,给了多个column作为特征,那么进行特征选取会是比较合适的手段。但是这里又不像是机器学习问题有工具帮助特征选取,我这里最后选择title、citation、abstract作为特征,其方法也比较简单:可以先用一个简单的模型比如bert-base,然后每个column单独作为输入去训练模型,这样来看看模型大体能做到什么精度。当时尝试用doi做输入的时候,原本以为doi可以很好的区分文章类别,但是发现模型却迟迟不能提升精度,而最后提交的结果也发现不使用doi成绩反而更好,也就验证了这种反直觉的特征选取方法还是有点效果的。
-
[SEP]的使用:上面也提到了,这里用[SEP]来连接不同column的内容,目的是希望模型能够区分不同的column特征,进一步,还可以尝试用token type ids来区分column,不过此次比赛中没来得及。
另外,模型训练的时候,最好有valid这个对照组,我这里比较懒也就没做了。。。
提分技巧千千万,但总归是术而非道,了解各个模型的区别,选择适合的模型或者定制模型才是提分的终极技巧~
一些思考
最后,简单聊聊一些自己的想法吧~
paddle这个框架还是不错的,虽然有时候问题比较多,定位问题比较烦,文档比较少。。。[捂脸]
但是作为国内做的比较好的deep learning平台,推荐尝试,也希望越做越好,而且架不住人家还免费,吼吼。。。
最近考虑做一个paddle问题定位的notebook,也把自己遇到的一些问题分享一下~
再说回deep learning本身,目前的框架用起来越来越简单,而一些底层的进展却越来越慢,如果不能解决why和how的问题,简单说就是模型的可解释性问题,很快所谓的人工智能专家也就成人工智能民工了~ 未来也许工业应用与模型设计会是完全不同的两拨人?!找准自己的定位从娃娃抓起 :)
行吧,就说这么多,关于自己,一介散修,各类比赛一二三四五等奖若干,算法赛应用赛不限,nlp的较多,欢迎交流~ :)
谢谢!
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)