
对加油站异常行为的检测
基于飞桨的对加油站异常行为的检测
基于飞桨检测加油站人群异常行为
本项目用于人像行为检测,可对加油站异常行为进行检测提醒
一、项目背景
当今社会对公共场合的行为规范不断强化,对公民的规则意识要求逐渐提高。在特定场合会对公民的一些行为做出特定限制,如在加油站禁止吸烟,开车时禁止打电话等,如果对这些行为进行准确的监控、识别,便可以发现、监督和纠正不文明行为,提升城市文明程度。
载入所需库
import paddle
import numpy as np
import cv2
from paddle.vision.models import resnet50
from paddle.vision.datasets import DatasetFolder
import paddle.nn.functional as F
import matplotlib.pylab as plt
import os
import random
import shutil
from shutil import copy2
定义参数
train_file='train'
valid_file='valid'
test_file='test'
imagesize=32
batch_size=32
lr=1e-5
iters=10000
二.数据集介绍
每张图片的清晰度和像素不同,因此要想识别图中人物行为是吸烟、打电话还是正常并不简单。
本数据集一共有三个文件,包含5373张图片。这些图片来自于网络。
smoking_images: 2168 张吸烟图片
calling_images:1227 张打电话图片
normal_images:1978 张非吸烟且非打电话图片
注:原数据集有些问题
下载数据集后删除train目录里的.DS_Store和readme.md文件,
之后再压缩后上传,覆盖原数据集,放到data目录下即可
1.解压数据集
!unzip -oq data/data166448/smoking\ and\ calling\ image_datasets.zip
!unzip -oq data/data166449/test.zip
注:解压后将文件放在data目录下
2.划分数据集
def data_set_split(src_data_folder, target_data_folder, train_scale=0.8, val_scale=0.1, test_scale=0.1):
'''
读取源数据文件夹,生成划分好的文件夹,分为trian、val、test三个文件夹进行
:param src_data_folder: 源文件夹
:param target_data_folder: 目标文件夹
:param train_scale: 训练集比例
:param val_scale: 验证集比例
:param test_scale: 测试集比例
:return:
'''
print("开始数据集划分")
class_names = os.listdir(src_data_folder)
# 在目标目录下创建文件夹
split_names = ['train', 'val', 'test']
for split_name in split_names:
split_path = os.path.join(target_data_folder, split_name)
if os.path.isdir(split_path):
pass
else:
os.mkdir(split_path)
# 然后在split_path的目录下创建类别文件夹
for class_name in class_names:
class_split_path = os.path.join(split_path, class_name)
if os.path.isdir(class_split_path):
pass
else:
os.mkdir(class_split_path)
# 按照比例划分数据集,并进行数据图片的复制
# 首先进行分类遍历
for class_name in class_names:
current_class_data_path = os.path.join(src_data_folder, class_name)
if os.path.isdir(current_class_data_path):
current_all_data = os.listdir(current_class_data_path)
current_data_length = len(current_all_data)
current_data_index_list = list(range(current_data_length))
random.shuffle(current_data_index_list)
train_folder = os.path.join(os.path.join(target_data_folder, 'train'), class_name)
val_folder = os.path.join(os.path.join(target_data_folder, 'val'), class_name)
test_folder = os.path.join(os.path.join(target_data_folder, 'test'), class_name)
train_stop_flag = current_data_length * train_scale
val_stop_flag = current_data_length * (train_scale + val_scale)
current_idx = 0
train_num = 0
val_num = 0
test_num = 0
for i in current_data_index_list:
src_img_path = os.path.join(current_class_data_path, current_all_data[i])
if current_idx <= train_stop_flag:
try:
copy2(src_img_path, train_folder)
# print("{}复制到了{}".format(src_img_path, train_folder))
train_num = train_num + 1
except:
pass
else:
try:
copy2(src_img_path, val_folder)
# print("{}复制到了{}".format(src_img_path, val_folder))
val_num = val_num + 1
except:
pass
current_idx = current_idx + 1
print("*********************************{}*************************************".format(class_name))
print(
"{}类按照{}:{}:{}的比例划分完成,一共{}张图片".format(class_name, train_scale, val_scale, test_scale, current_data_length))
print("训练集{}:{}张".format(train_folder, train_num))
print("验证集{}:{}张".format(val_folder, val_num))
if __name__ == '__main__':
src_data_folder = "smoking and calling image_datasets/train"
target_data_folder = "/home/aistudio/work"
data_set_split(src_data_folder, target_data_folder)
3.数据预处理
# 定义数据预处理
def load_image(img_path):
img = cv2.cvtColor(cv2.imread(img_path), cv2.COLOR_BGR2RGB)
#resize
img = cv2.resize(img,(imagesize,imagesize))
img = np.array(img).astype('float32')
# HWC to CHW
img = img.transpose((2,0,1))
#Normalize
img = img / 255
return img
# 构建Dataset
class Face(DatasetFolder):
def __init__(self, path):
super().__init__(path)
def __getitem__(self, index):
img_path, label = self.samples[index]
label = np.array(label).astype(np.int64)
label = np.expand_dims(label, axis=0)
return load_image(img_path), label
train_file = "/home/aistudio/work/train"
valid_file = "/home/aistudio/work/val"
train_dataset = Face(train_file)
eval_dataset = Face(valid_file)
4.图像查看
未将图片缩小直接显示
# 定义数据预处理
def load_image_1(img_path):
img = cv2.cvtColor(cv2.imread(img_path), cv2.COLOR_BGR2RGB)
img = np.array(img).astype('float32')
# HWC to CHW
img = img.transpose((2,0,1))
#Normalize
img = img / 255
return img
# 构建Dataset
class Face_1(DatasetFolder):
def __init__(self, path):
super().__init__(path)
def __getitem__(self, index):
img_path, label = self.samples[index]
label = np.array(label).astype(np.int64)
label = np.expand_dims(label, axis=0)
return load_image_1(img_path), label
train_file = "/home/aistudio/work/train"
valid_file = "/home/aistudio/work/val"
train_dataset_1 = Face_1(train_file)
eval_dataset_1 = Face_1(valid_file)
plt.figure(figsize=(15, 15))
for i in range(5):
fundus_img, lab = train_dataset.__getitem__(i)
plt.subplot(2, 5, i+1)
plt.imshow(fundus_img.transpose(1, 2, 0))
plt.axis("off")

三.模型选择和开发
1.模型组网
选择了resnet50,又用了两个全连接层,然后输出。
class Network(paddle.nn.Layer):
def __init__(self):
super(Network, self).__init__()
self.resnet = resnet50(pretrained=True, num_classes=0)
self.flatten = paddle.nn.Flatten()
self.linear_1 = paddle.nn.Linear(2048, 512)
self.linear_2 = paddle.nn.Linear(512, 256)
self.linear_3 = paddle.nn.Linear(256, 7)
self.relu = paddle.nn.ReLU()
self.dropout = paddle.nn.Dropout(0.2)
def forward(self, inputs):
# print('input', inputs)
y = self.resnet(inputs)
y = self.flatten(y)
y = self.linear_1(y)
y = self.linear_2(y)
y = self.dropout(y)
y = self.relu(y)
y = self.linear_3(y)
y = paddle.nn.functional.sigmoid(y)
y = F.softmax(y)
return y
model = Network()
W0825 12:57:28.127104 2073 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0825 12:57:28.131276 2073 gpu_resources.cc:91] device: 0, cuDNN Version: 7.6.
2.模型的训练函数的集合
def train(model, iters, optimizer, criterion, train_dataset, eval_dataset, log_interval, eval_interval):
iter = 0
losses = 5
model.train()
avg_loss_list = []
while iter < iters :
iter += 1
for batch_id, train_datas in enumerate(train_loader()):
train_data, train_label = train_datas
train_data = paddle.to_tensor(train_data)
train_label = paddle.to_tensor(train_label)
ligits = model(train_data)
loss = criterion(ligits, train_label)
avg_loss_list.append(loss)
loss.backward()
optimizer.step()
model.clear_gradients()
if iter % log_interval == 0:
avg_loss = np.array(avg_loss_list).mean()
print("[TRAIN] iter={}/{} loss={:.4f}".format(iter, iters, avg_loss))
if iter % eval_interval == 0:
model.eval()
avg_loss_list = []
for eval_datas in eval_dataset:
eval_data, eval_label = eval_datas
eval_data = np.expand_dims(eval_data, axis=0)
eval_data = paddle.to_tensor(eval_data)
eval_label = paddle.to_tensor(eval_label)
ligits = model(eval_data)
loss = criterion(ligits, eval_label)
avg_loss_list.append(loss)
avg_loss = np.array(avg_loss_list).mean()
print("[EVAL] iter={}/{} loss={:.4f}".format(iter, iters, avg_loss))
if loss < losses:
paddle.save(model.state_dict(),os.path.join("best_model_{:.4f}".format(avg_loss), 'model.pdparams'))
model.train()
3.模型的训练
train_loader = paddle.io.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
optimizer = paddle.optimizer.Adam(lr, parameters = model.parameters())
criterion = paddle.nn.CrossEntropyLoss()
train(model, iters, optimizer, criterion, train_dataset, eval_dataset, log_interval = 10, eval_interval=100)
[TRAIN] iter=10/10000 loss=1.8232
[TRAIN] iter=20/10000 loss=1.8122
[TRAIN] iter=30/10000 loss=1.8071
[TRAIN] iter=40/10000 loss=1.8041
四、预测
1.对预测数据处理
def load_test(img_path):
img = cv2.cvtColor(cv2.imread(img_path), cv2.COLOR_BGR2RGB)
#resize
img = cv2.resize(img,(imagesize,imagesize))
img = np.array(img).astype('float32')
# HWC to CHW
img = img.transpose((2,0,1))
#Normalize
img = img / 255
return img
test_dataset=[]
for i in os.listdir(test_file):
test_dataset.append(load_test(test_file+'//'+i))
test_dataset = np.array(test_dataset)
2.对模型预测
# 进行预测操作
best_model_path = "best_model_1.7796/model.pdparams"
para_state_dict = paddle.load(best_model_path)
model.set_state_dict(para_state_dict)
model.eval()
result_list=[]
for test_data in test_dataset:
test_data = np.expand_dims(test_data, axis=0)
test_data = paddle.to_tensor(test_data)
result = model(test_data)
result = paddle.tolist(result)
result_list.append(result)
result_list = np.array(result_list)
# 定义产出数字与行为的对应关系
face={0:'calling',1:'normal',2:'smoking'}
# 定义画图方法
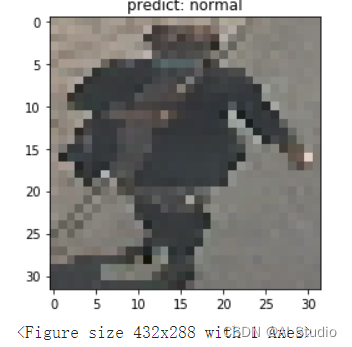
def show_img(img, predict):
plt.figure()
plt.title('predict: {}'.format(face[predict]))
plt.imshow(img.reshape([3, 32, 32]).transpose(1,2,0))
plt.show()
# 抽样展示
indexs = [89, 18, 78]
for idx in indexs:
show_img(test_dataset[idx], np.argmax(result_list[idx]))
结果显示


五、团队成员介绍
太原理工大学 软件学院 软件工程专业 2020级 本科生 王志洲
太原理工大学 软件学院 软件工程专业 2021级 本科生 李杰群
太原理工大学 软件学院 软件工程专业 2021级 本科生 张臻
六、个人介绍
太原理工大学 软件学院 软件工程专业 2020级 本科生 王志洲
AIstudio地址链接:https://aistudio.baidu.com/aistudio/personalcenter/thirdview/559770
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)