
超分辨率模型-LIIF,可放大30多倍
模型亮点:可以以任意分辨率进行超分,超分的分辨率甚至可以高达30x。
复现论文:用局部隐式图像函数(LIIF)学习连续图像表达
《Learning Continuous Image Representation with Local Implicit Image Function》
LIIF主页:
https://yinboc.github.io/liif/
论文地址:
https://arxiv.org/pdf/2012.09161.pdf
torch代码:
https://github.com/yinboc/liif
1. 论文简介
论文中为生成连续的图像表达,作者通过自监督方式在超分任务上训练了一个encoder和LIIF。所学习到的连续表达能够以任意分辨率对图像进行插值,甚至可以进行30x插值,本文的encoder采用的是RDN。先看一下效果: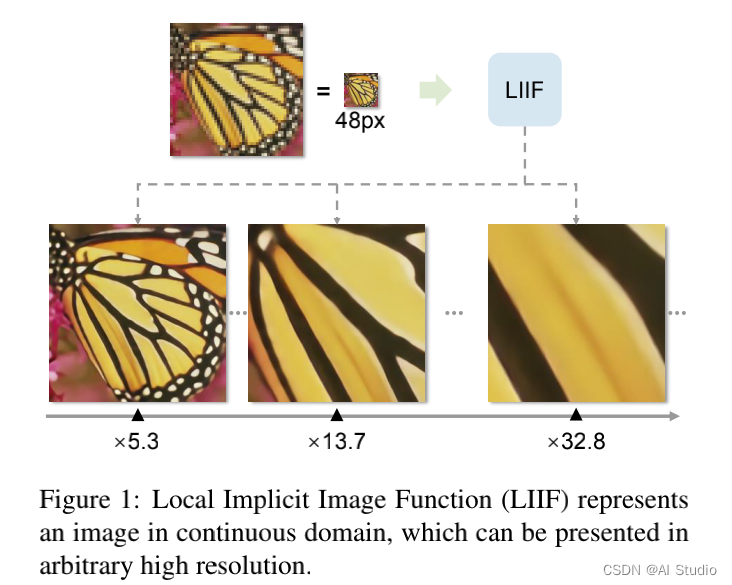
B站UP主展示效果及论文讲解
2. LIIF—— 局部隐式图像函数
Local Implicit Image Function
2.1 LIIF介绍
LIIF在离散2D与连续2D之间构建了桥梁,进而对图像进行分辨率调整,实现所谓的“无限放大”。通过局部的隐式图像函数对连续的图像进行表达。所谓的局部隐式表达(local implicit image Function, LIF),指函数以图像坐标以及坐标周围的二维特征作为输入,以某给定坐标处的RGB数值作为输出。由于坐标是连续的值,因此LIIF可以以任意分辨率进行表示。为了生成影像的连续表达,我们通过一个用于超分的自监督任务训练得到一个编码器。学得的连续表达就可以以任意分辨率进行超分,超分的分辨率甚至可以高达30x。换句话说,LIIF搭建了2D离散值和连续表达之间的桥梁,因此,它天然的支持GT的尺寸不一样的情况。
在LIIF的表达中,将每一个连续的图像 I ( i ) I^{(i)} I(i) 都会被表达成2D的特征图 M ( i ) ∈ R H W D M^{(i)} \in \mathbb{R}^{H W D} M(i)∈RHWD 。解码的函数 f θ f_{\theta} fθ 将被所有的影像共用,其参数 θ {\theta} θ 由 M L P {MLP} MLP 获得,数学表达为:
s = f θ ( z , x ) s=f_{\theta}(z, x) s=fθ(z,x)
其中, z z z 是一个向量,可以理解为隐藏的特征编码, x ∈ X x \in \mathcal{X} x∈X 是在连续影像坐标域上的一个2D的坐标, s ∈ S s \in \mathcal{S} s∈S 是预测的值,比如说RGB图上的颜色值。
学习连续的图像表达的流程示意图为:

3. RDN Encoder
论文中LIIF模型使用的一种骨干网络为RDN,不了解的话可参见上一篇《LIIF超分辨率之RDN(残差密集网络)》
4. DIV2K 数据集
DIV2K是一个流行的单图像超分辨率数据集,它包含 1000 张不同场景的图像,分为 800 张用于训练,100 张用于验证,100 张用于测试。它是为 NTIRE2017 和 NTIRE2018 超分辨率挑战收集的,以鼓励对具有更逼真退化的图像超分辨率的研究。该数据集包含具有不同类型退化的低分辨率图像。
div2k数据集官方地址:https://data.vision.ee.ethz.ch/cvl/DIV2K/
本项目使用的是 AiStudio公开数据集里的已存在的div2k https://aistudio.baidu.com/aistudio/datasetdetail/104667
如果需要测试项目,还需要包含验证集X2、X3 数据集https://aistudio.baidu.com/aistudio/datasetdetail/166552
5. 模型训练
本项目有2种运行方式,互不干涉。
- 一种是直接从github克隆我已转好的PaddlePaddle代码(推荐仅想试用的朋友使用)
- 另一种是在Notebook上直接运行(推荐学习组网的朋友)。
5.1 通git获取直接训练
克隆项目
# 克隆项目
! git clone https://github.com/tianxingxia-cn/LIIF-Paddle
解压数据集
! mkdir /home/aistudio/LIIF-Paddle/load && mkdir /home/aistudio/LIIF-Paddle/load/div2k
# 解压数据集
!unzip -qo /home/aistudio/data/data104667/DIV2K_train_HR.zip -d /home/aistudio/LIIF-Paddle/load/div2k
!unzip -qo /home/aistudio/data/data104667/DIV2K_valid_HR.zip -d /home/aistudio/LIIF-Paddle/load/div2k
# 模型评估数据集(x2,x3,x4)
!unzip -qo /home/aistudio/data/data104667/DIV2K_valid_LR_bicubic_X4.zip -d /home/aistudio/LIIF-Paddle/load/div2k
!unzip -qo /home/aistudio/data/data166552/DIV2K_valid_LR_bicubic_X3.zip -d /home/aistudio/LIIF-Paddle/load/div2k
!unzip -qo /home/aistudio/data/data166552/DIV2K_valid_LR_bicubic_X2.zip -d /home/aistudio/LIIF-Paddle/load/div2k
模型训练
注意,本项目是按Aistudio上32G 设置的,如果出现内存不足,请自行修改config中配置文件
# 模型训练
%cd /home/aistudio/LIIF-Paddle
! python train_liif.py --config configs/train-div2k/train_rdn-liif.yaml
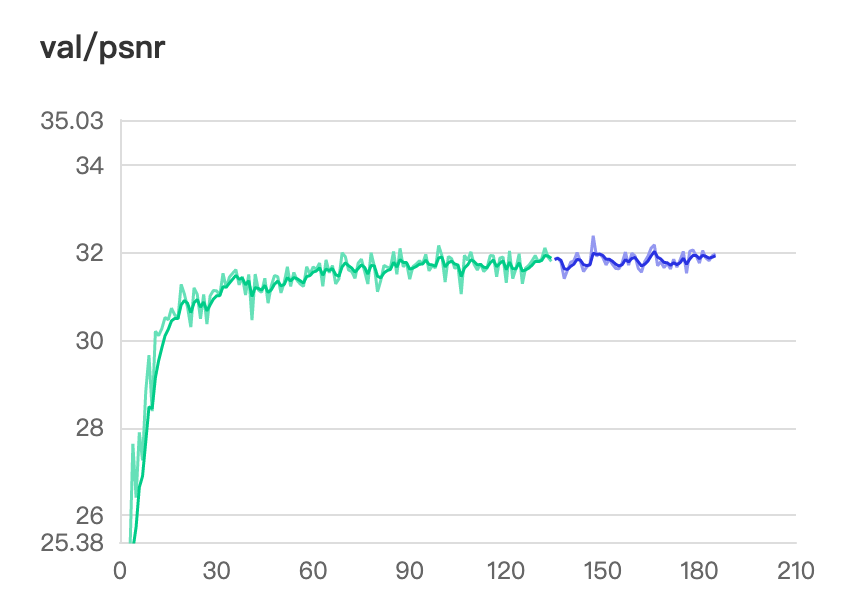
图上有2种颜色是因为中途手动中断过后继续训练的,是2个日志,中断可继续训练,可修改配置文件中 resume: ./save/_train_rdn-liif/epoch-last.pdparams
模型预测
本项目也同时提供训练185轮的paddle模型以及论文中的模型(由torch模型转换)
# --resolution H,W (注意高宽顺序)
! python demo.py --input ../demo.png --model '../pretrained/epoch-185-best.pdparams' --resolution 564,1020 --output ../demo_x4.png
#论文里预训练模型(已转为paddle模型)
! python demo.py --input ../demo.png --model '../pretrained/rdn-liif_torch.pdparams' --resolution 564,1020 --output ../demo_x4.png
%cd /home/aistudio/LIIF-Paddle
# 使用提训练185轮中最佳模型预测
# --resolution H,W (注意高宽顺序)
#! python demo.py --input ../demo.png --model '../pretrained/epoch-185-best.pdparams' --resolution 564,1020 --output ../demo_x4.png
# liif-torch的预训练模型(已转为paddle模型)
! python demo.py --input ../demo.png --model '../pretrained/rdn-liif_torch.pdparams' --resolution 564,1020 --output ../demo_x4.png
# 用训练模型预测
# ! python demo.py --input ../demo.png --model './save/_train_rdn-liif/epoch-best.pdparams' --resolution 564,1020 --output ../demo_x4.png
%cd /home/aistudio/LIIF-Paddle
# ! python demo.py --input ../test.png --model '../pretrained/rdn-liif_torch.pdparams' --resolution 3600,3600 --output ../test_x10.png
! python demo.py --input ../test.png --model '../pretrained/rdn-liif_torch.pdparams' --resolution 10800,10800 --output ../test_x30.png
/home/aistudio/LIIF-Paddle
W0903 09:46:17.388828 4021 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0903 09:46:17.392319 4021 device_context.cc:465] device: 0, cuDNN Version: 7.6.
查看预测效果
可以看到放大4倍,细节还是很清楚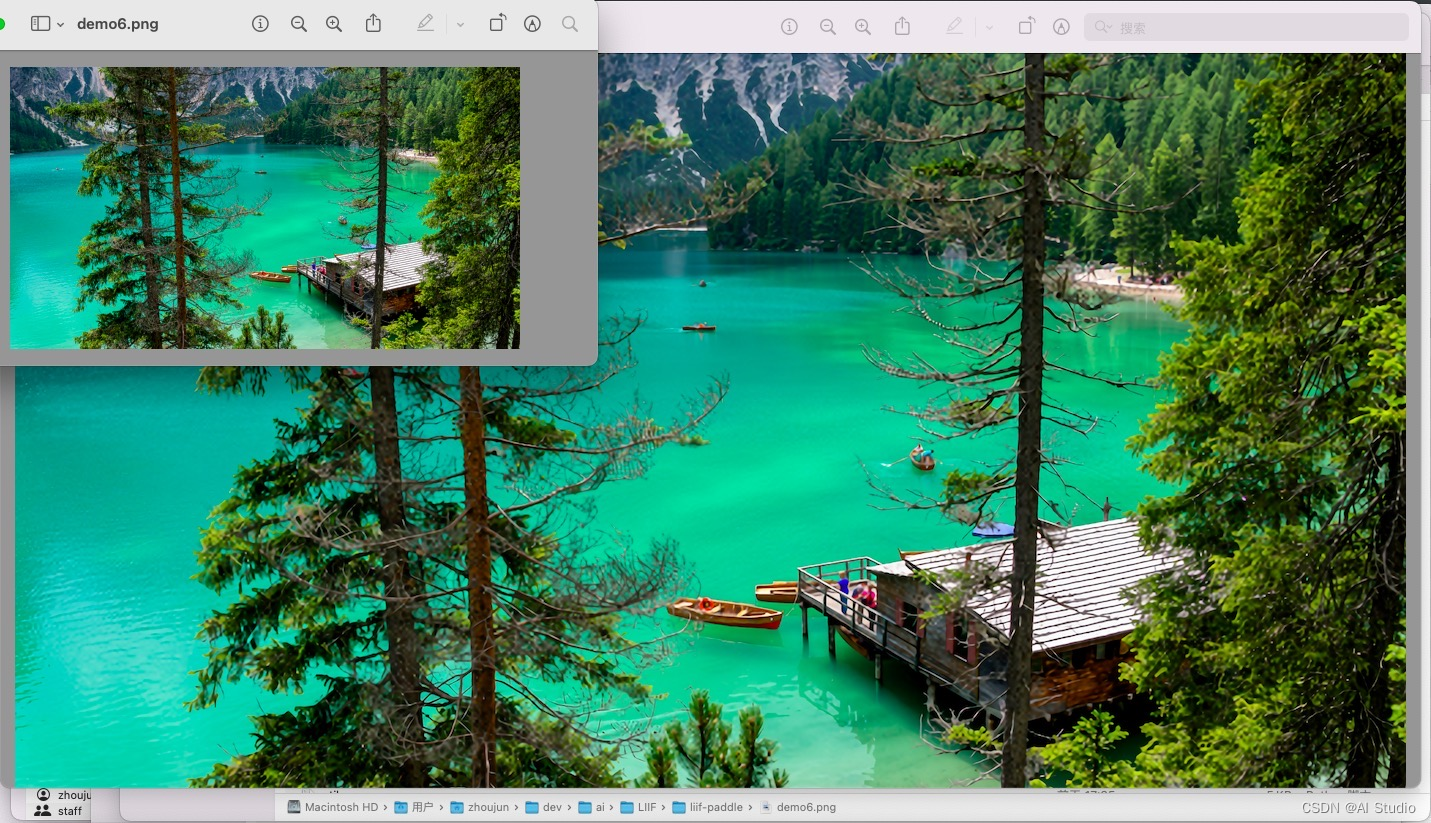
测试模型
# 开始测试
# ! sh ./scripts/test-div2k.sh './save/_train_rdn-liif/epoch-best.pdparams' 0
! sh ./scripts/test-div2k.sh '../pretrained/rdn-liif_torch.pdparams' 0
| Model /PSNR(dB)/ 放大 | div2k-x2 | div2k-x3 | div2k-x4 | div2k-X6 | div2k-x12 | div2k-x18 | div2k-x24 | div2k-x30 |
|---|---|---|---|---|---|---|---|---|
| 论文中模型(torch) | 34.99 | 31.26 | 29.27 | 26.99 | 23.89 | 22.34 | 21.31 | 20.59 |
| 论文中模型(paddle) | 34.9866 | 31.2610 | 29.2719 | 26.6872 | 23.6882 | 22.1407 | 21.1720 | 20.4805 |
| 自训练185轮 | 34.3243 | 30.7030 | 28.7990 | 26.2715 | 23.3602 | 21.8807 | 20.9621 | 20.3099 |
注意,x2,x3,x4的评估数据是从官方下载,但x6到x30是通过resize_fn函数处理,由于paddle无ToPILImage()方法,我采用了从"numpy转PIL图像"的方式,故评估时产生了一些的出入。
这里提供本模型如何从torch模型中提取权重保存为paddle模型,注意:本段代码不能在Aistudio上运行, 感谢 KeyK-小胡之父 和 寂寞你快进去 提供思路。
import paddle
import torch
net = make_model({
'name': 'liif',
'args': {
'encoder_spec': {
'name': 'rdn',
'args': {'no_upsampling': True}
},
'imnet_spec': {
'name': 'mlp',
'args': {
'out_dim': 3,
'hidden_list': [256, 256, 256, 256]
}
}
}
}, load_sd=False)
net.eval()
torch_ckpt = torch.load('./pretrained/rdn-liif.pth', map_location=torch.device('cpu') )
m= torch_ckpt['model']
sd = m['sd']
paddle_sd={}
for k, v in sd.items():
if torch.is_tensor(v):
if 'imnet.layers' in k and 'weight' in k: # 与torch顺序不同,paddle需要转置一下。
paddle_sd[k] = v.t().numpy()
else:
paddle_sd[k] = v.numpy()
else:
paddle_sd[k] = v
paddle_ckpt = {'name': m['name'], 'args': m['args'], 'sd': paddle_sd}
net.set_state_dict(paddle_ckpt)
paddle.save({'model': paddle_ckpt}, './pretrained/rdn-liif.pdparams')
到这里其实已经结束了
以下部分是揉合代码后可以直接在Notebook上运行的,方便从代码层面对论文有个整体的理解。
5.2:在Notebook上直接运行
%cd /home/aistudio/
# 引入包
import os
import time
import shutil
import math
import random
import copy
import json
import pickle
import numpy as np
import functools
import yaml
import imageio
from PIL import Image
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddle.io import Dataset
from paddle.io import DataLoader
from paddle.vision import transforms
from tqdm import tqdm
from visualdl import LogWriter
import argparse
from argparse import Namespace
定义一些工具类和函数
# 计算loss的平均值
class Averager():
def __init__(self):
self.n = 0.0
self.v = 0.0
def add(self, v, n=1.0):
self.v = (self.v * self.n + v * n) / (self.n + n)
self.n += n
def item(self):
return self.v
# 计算训练时长
class Timer():
def __init__(self):
self.v = time.time()
def s(self):
self.v = time.time()
def t(self):
return time.time() - self.v
def time_text(t):
if t >= 3600:
return '{:.1f}h'.format(t / 3600)
elif t >= 60:
return '{:.1f}m'.format(t / 60)
else:
return '{:.1f}s'.format(t)
# 设置训练日志路径
_log_path = None
def set_log_path(path):
global _log_path
_log_path = path
# 写日志
def log(obj, filename='log.txt'):
if _log_path is not None:
with open(os.path.join(_log_path, filename), 'a') as f:
print(obj, file=f)
# 是否覆盖训练目录
def ensure_path(path, remove=True):
basename = os.path.basename(path.rstrip('/'))
if os.path.exists(path):
if remove and (basename.startswith('_')
or input('{} exists, remove? (y/[n]): '.format(path)) == 'y'):
shutil.rmtree(path)
os.makedirs(path)
else:
os.makedirs(path)
# visualdl日志
def set_save_path(save_path, remove=False):
ensure_path(save_path, remove=remove)
set_log_path(save_path)
writer = LogWriter(logdir=os.path.join(save_path, 'visualdl'))
return log, writer
# 计算模型参数
def compute_num_params(model, text=False):
tot = int(sum([np.prod(p.shape) for p in model.parameters()]))
if text:
if tot >= 1e6:
return '{:.1f}M'.format(tot / 1e6)
else:
return '{:.1f}K'.format(tot / 1e3)
else:
return tot
# 获取优化器,load_sd 是优化器的state_dict
def make_optimizer(param_list, optimizer_spec, load_sd=False):
Optimizer = {
'sgd': paddle.optimizer.SGD,
'adam': paddle.optimizer.Adam
}[optimizer_spec['name']]
optimizer = Optimizer(parameters=param_list, learning_rate=optimizer_spec['args']['lr'])
# 上面代码等价于下面这段
# if optimizer_spec['name'] == 'adam':
# optimizer = paddle.optimizer.Adam(learning_rate=optimizer_spec['args']['lr'], beta1=0.9, parameters=param_list)
# elif optimizer_spec['name'] == 'sgd':
# optimizer = paddle.optimizer.SGD(learning_rate=optimizer_spec['args']['lr'], parameters=param_list)
if load_sd:
optimizer.set_state_dict(optimizer_spec['sd'])
return optimizer
def make_coord(shape, ranges=None, flatten=True):
""" Make coordinates at grid centers.
"""
coord_seqs = []
for i, n in enumerate(shape):
if ranges is None:
v0, v1 = -1, 1
else:
v0, v1 = ranges[i]
r = (v1 - v0) / (2 * n)
seq = v0 + r + (2 * r) * paddle.arange(n).astype(np.float32)
coord_seqs.append(seq)
ret = paddle.stack(paddle.meshgrid(*coord_seqs), axis=-1)
if flatten:
ret = paddle.reshape(ret, [-1, ret.shape[-1]])
return ret
def to_pixel_samples(img):
""" Convert the image to coord-RGB pairs.
img: Tensor, (3, H, W)
"""
coord = make_coord(img.shape[-2:])
rgb = paddle.transpose(paddle.reshape(img, [3, -1]), perm=[1, 0])
return coord, rgb
def calc_psnr(sr, hr, dataset=None, scale=1, rgb_range=1):
diff = (sr - hr) / rgb_range
if dataset is not None:
if dataset == 'benchmark':
shave = scale
if diff.size(1) > 1:
gray_coeffs = [65.738, 129.057, 25.064]
diff = paddle.to_tensor(gray_coeffs)
convert = paddle.reshape(diff, shape=[1, 3, 1, 1]) / 256
diff = diff.multiply(convert).sum(axis=1)
elif dataset == 'div2k':
shave = scale + 6
else:
raise NotImplementedError
valid = diff[..., shave:-shave, shave:-shave]
else:
valid = diff
mse = valid.pow(2).mean()
return -10 * paddle.log10(mse)
定义数据集相关
datasets = {}
def register_dataset(name):
def decorator(cls):
datasets[name] = cls
return cls
return decorator
def make(dataset_spec, args=None):
if args is not None:
dataset_args = copy.deepcopy(dataset_spec['args'])
dataset_args.update(args)
else:
dataset_args = dataset_spec['args']
dataset = datasets[dataset_spec['name']](**dataset_args)
return dataset
# 以下3个类是定义了的Wapper,配置文件中采用的是 sr-implicit-downsampled
@register_dataset('sr-implicit-paired')
class SRImplicitPaired(Dataset):
def __init__(self, dataset, inp_size=None, augment=False, sample_q=None):
self.dataset = dataset
self.inp_size = inp_size
self.augment = augment
self.sample_q = sample_q
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
img_lr, img_hr = self.dataset[idx]
s = img_hr.shape[-2] // img_lr.shape[-2] # assume int scale
if self.inp_size is None:
h_lr, w_lr = img_lr.shape[-2:]
img_hr = img_hr[:, :h_lr * s, :w_lr * s]
crop_lr, crop_hr = img_lr, img_hr
else:
w_lr = self.inp_size
x0 = random.randint(0, img_lr.shape[-2] - w_lr)
y0 = random.randint(0, img_lr.shape[-1] - w_lr)
crop_lr = img_lr[:, x0: x0 + w_lr, y0: y0 + w_lr]
w_hr = w_lr * s
x1 = x0 * s
y1 = y0 * s
crop_hr = img_hr[:, x1: x1 + w_hr, y1: y1 + w_hr]
if self.augment:
hflip = random.random() < 0.5
vflip = random.random() < 0.5
dflip = random.random() < 0.5
def augment(x):
if hflip:
x = x.flip(-2)
if vflip:
x = x.flip(-1)
if dflip:
x = x.transpose(-2, -1)
return x
crop_lr = augment(crop_lr)
crop_hr = augment(crop_hr)
# hr_coord, hr_rgb = to_pixel_samples(crop_hr.clone().reshape(crop_hr.shape))
hr_coord, hr_rgb = to_pixel_samples(crop_hr.clone())
if self.sample_q is not None:
sample_lst = np.random.choice(
len(hr_coord), self.sample_q, replace=False)
hr_coord = hr_coord[sample_lst]
hr_rgb = hr_rgb[sample_lst]
cell = paddle.ones_like(hr_coord)
cell[:, 0] *= 2 / crop_hr.shape[-2]
cell[:, 1] *= 2 / crop_hr.shape[-1]
return {
'inp': crop_lr,
'coord': hr_coord,
'cell': cell,
'gt': hr_rgb
}
# 随机下采样
@register_dataset('sr-implicit-downsampled')
class SRImplicitDownsampled(Dataset):
def __init__(self, dataset, inp_size=None, scale_min=1, scale_max=None,
augment=False, sample_q=None):
self.dataset = dataset
self.inp_size = inp_size
self.scale_min = scale_min
if scale_max is None:
scale_max = scale_min
self.scale_max = scale_max
self.augment = augment
self.sample_q = sample_q
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
img = self.dataset[idx]
s = random.uniform(self.scale_min, self.scale_max)
if self.inp_size is None:
h_lr = math.floor(img.shape[-2] / s + 1e-9)
w_lr = math.floor(img.shape[-1] / s + 1e-9)
img = img[:, :round(h_lr * s), :round(w_lr * s)] # assume round int
img_down = resize_fn(img, (h_lr, w_lr))
crop_lr, crop_hr = img_down, img
else:
w_lr = self.inp_size
w_hr = round(w_lr * s)
x0 = random.randint(0, img.shape[-2] - w_hr)
y0 = random.randint(0, img.shape[-1] - w_hr)
crop_hr = img[:, x0: x0 + w_hr, y0: y0 + w_hr]
crop_lr = resize_fn(crop_hr, w_lr)
if self.augment:
hflip = random.random() < 0.5
vflip = random.random() < 0.5
dflip = random.random() < 0.5
def augment(x):
if hflip:
x = x.flip([-2])
if vflip:
x = x.flip([-1])
if dflip:
paddle.transpose(img, perm=[0, 2, 1])
return x
crop_lr = augment(crop_lr)
crop_hr = augment(crop_hr)
hr_coord, hr_rgb = to_pixel_samples(crop_hr.clone())
if self.sample_q is not None:
sample_lst = np.random.choice(len(hr_coord), self.sample_q, replace=False)
hr_coord = hr_coord.gather(paddle.to_tensor(sample_lst))
hr_rgb = hr_rgb.gather(paddle.to_tensor(sample_lst))
cell = paddle.ones_like(hr_coord)
cell[:, 0] *= 2 / crop_hr.shape[-2]
cell[:, 1] *= 2 / crop_hr.shape[-1]
return {
'inp': crop_lr,
'coord': hr_coord,
'cell': cell,
'gt': hr_rgb
}
@register_dataset('sr-implicit-uniform-varied')
class SRImplicitUniformVaried(Dataset):
def __init__(self, dataset, size_min, size_max=None,
augment=False, gt_resize=None, sample_q=None):
self.dataset = dataset
self.size_min = size_min
if size_max is None:
size_max = size_min
self.size_max = size_max
self.augment = augment
self.gt_resize = gt_resize
self.sample_q = sample_q
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
img_lr, img_hr = self.dataset[idx]
p = idx / (len(self.dataset) - 1)
w_hr = round(self.size_min + (self.size_max - self.size_min) * p)
img_hr = resize_fn(img_hr, w_hr)
if self.augment:
if random.random() < 0.5:
img_lr = img_lr.flip(-1)
img_hr = img_hr.flip(-1)
if self.gt_resize is not None:
img_hr = resize_fn(img_hr, self.gt_resize)
hr_coord, hr_rgb = to_pixel_samples(img_hr)
if self.sample_q is not None:
sample_lst = np.random.choice(
len(hr_coord), self.sample_q, replace=False)
hr_coord = hr_coord[sample_lst]
hr_rgb = hr_rgb[sample_lst]
cell = paddle.ones_like(hr_coord)
cell[:, 0] *= 2 / img_hr.shape[-2]
cell[:, 1] *= 2 / img_hr.shape[-1]
return {
'inp': img_lr,
'coord': hr_coord,
'cell': cell,
'gt': hr_rgb
}
# 调整图片大小
def resize_fn(img, size):
#pil_img = Image.fromarray(np.uint8(img.numpy() * 255).transpose(1, 2, 0)).convert('RGB')
pil_img = Image.fromarray(np.float32(img.numpy() * 255).transpose(1, 2, 0),mode='RGB')
if isinstance(size,tuple) or isinstance(size,list):
pil_img_resize = pil_img.resize(size)
else:
pil_img_resize = pil_img.resize((size,size))
return paddle.vision.transforms.ToTensor(data_format='CHW')(pil_img_resize)
@register_dataset('image-folder')
class ImageFolder(Dataset):
def __init__(self, root_path, split_file=None, split_key=None, first_k=None,
repeat=1, cache='none'):
self.repeat = repeat
self.cache = cache
if split_file is None:
filenames = sorted(os.listdir(root_path))
else:
with open(split_file, 'r') as f:
filenames = json.load(f)[split_key]
if first_k is not None:
filenames = filenames[:first_k]
self.files = []
for filename in filenames:
file = os.path.join(root_path, filename)
if cache == 'none':
self.files.append(file)
elif cache == 'bin':
bin_root = os.path.join(os.path.dirname(root_path),
'_bin_' + os.path.basename(root_path))
if not os.path.exists(bin_root):
os.mkdir(bin_root)
print('mkdir', bin_root)
bin_file = os.path.join(
bin_root, filename.split('.')[0] + '.pkl')
if not os.path.exists(bin_file):
with open(bin_file, 'wb') as f:
pickle.dump(imageio.imread(file), f)
print('dump', bin_file)
self.files.append(bin_file)
elif cache == 'in_memory':
self.files.append(transforms.ToTensor()(
Image.open(file).convert('RGB')))
def __len__(self):
return len(self.files) * self.repeat
def __getitem__(self, idx):
x = self.files[idx % len(self.files)]
if self.cache == 'none':
return transforms.ToTensor()(Image.open(x).convert('RGB'))
elif self.cache == 'bin':
with open(x, 'rb') as f:
x = pickle.load(f)
x = np.ascontiguousarray(x.transpose(2, 0, 1))
# x = torch.from_numpy(x).float() / 255
x = paddle.to_tensor(x).astype(np.float32) / 255
return x
elif self.cache == 'in_memory':
return x
@register_dataset('paired-image-folders')
class PairedImageFolders(Dataset):
def __init__(self, root_path_1, root_path_2, **kwargs):
self.dataset_1 = ImageFolder(root_path_1, **kwargs)
self.dataset_2 = ImageFolder(root_path_2, **kwargs)
def __len__(self):
return len(self.dataset_1)
def __getitem__(self, idx):
return self.dataset_1[idx], self.dataset_2[idx]
定义网络模型相关
models = {}
def register_model(name):
def decorator(cls):
models[name] = cls
return cls
return decorator
def make_model(model_spec, args=None, load_sd=False):
if args is not None:
model_args = copy.deepcopy(model_spec['args'])
model_args.update(args)
else:
model_args = model_spec['args']
model = models[model_spec['name']](**model_args)
if load_sd:
model.set_state_dict(model_spec['sd'])
return model
class RDB_Conv(nn.Layer):
def __init__(self, inChannels, growRate, kSize=3):
super(RDB_Conv, self).__init__()
Cin = inChannels
G = growRate
self.conv = nn.Sequential(*[
nn.Conv2D(Cin, G, kSize, padding=(kSize - 1) // 2, stride=1,bias_attr=True,data_format='NCHW'),
nn.ReLU()
])
def forward(self, x):
out = self.conv(x)
return paddle.concat((x, out), axis=1)
class RDB(nn.Layer):
def __init__(self, growRate0, growRate, nConvLayers, kSize=3):
super(RDB, self).__init__()
G0 = growRate0
G = growRate
C = nConvLayers
convs = []
for c in range(C):
convs.append(RDB_Conv(G0 + c*G, G))
self.convs = nn.Sequential(*convs)
# Local Feature Fusion
self.LFF = nn.Conv2D(G0 + C*G, G0, 1, padding=0, stride=1,bias_attr=True,data_format='NCHW')
def forward(self, x):
return self.LFF(self.convs(x)) + x
# RDN组网
class RDN(nn.Layer):
def __init__(self, args):
super(RDN, self).__init__()
self.args = args
r = args.scale[0]
G0 = args.G0
kSize = args.RDNkSize
# number of RDB blocks, conv layers, out channels
self.D, C, G = {
'A': (20, 6, 32),
'B': (16, 8, 64),
}[args.RDNconfig]
# Shallow feature extraction net
self.SFENet1 = nn.Conv2D(args.n_colors, G0, kSize, padding=(kSize-1)//2, stride=1,bias_attr=True,data_format='NCHW')
self.SFENet2 = nn.Conv2D(G0, G0, kSize, padding=(kSize-1)//2, stride=1,bias_attr=True,data_format='NCHW')
# Redidual dense blocks and dense feature fusion
self.RDBs = nn.LayerList()
for i in range(self.D):
self.RDBs.append(
RDB(growRate0 = G0, growRate = G, nConvLayers = C)
)
# Global Feature Fusion
self.GFF = nn.Sequential(*[
nn.Conv2D(self.D * G0, G0, 1, padding=0, stride=1,bias_attr=True,data_format='NCHW'),
nn.Conv2D(G0, G0, kSize, padding=(kSize-1)//2, stride=1,bias_attr=True,data_format='NCHW')
])
if args.no_upsampling:
self.out_dim = G0
else:
self.out_dim = args.n_colors
# Up-sampling net
if r == 2 or r == 3:
self.UPNet = nn.Sequential(*[
nn.Conv2D(G0, G * r * r, kSize, padding=(kSize-1)//2, stride=1,bias_attr=True,data_format='NCHW'),
nn.PixelShuffle(r),
nn.Conv2D(G, args.n_colors, kSize, padding=(kSize-1)//2, stride=1,bias_attr=True,data_format='NCHW')
])
elif r == 4:
self.UPNet = nn.Sequential(*[
nn.Conv2D(G0, G * 4, kSize, padding=(kSize-1)//2, stride=1,bias_attr=True,data_format='NCHW'),
nn.PixelShuffle(2),
nn.Conv2D(G, G * 4, kSize, padding=(kSize-1)//2, stride=1,bias_attr=True,data_format='NCHW'),
nn.PixelShuffle(2),
nn.Conv2D(G, args.n_colors, kSize, padding=(kSize-1)//2, stride=1,bias_attr=True,data_format='NCHW')
])
else:
raise ValueError("scale must be 2 or 3 or 4.")
def forward(self, x):
f__1 = self.SFENet1(x)
x = self.SFENet2(f__1)
RDBs_out = []
for i in range(self.D):
x = self.RDBs[i](x)
RDBs_out.append(x)
x = self.GFF(paddle.concat(RDBs_out, axis=1))
x += f__1
if self.args.no_upsampling:
return x
else:
return self.UPNet(x)
@register_model('rdn')
def make_rdn(G0=64, RDNkSize=3, RDNconfig='B',
scale=2, no_upsampling=False):
args = Namespace()
args.G0 = G0
args.RDNkSize = RDNkSize
args.RDNconfig = RDNconfig
args.scale = [scale]
args.no_upsampling = no_upsampling
args.n_colors = 3
return RDN(args)
# 多层感知机
@register_model('mlp')
class MLP(nn.Layer):
def __init__(self, in_dim, out_dim, hidden_list):
super().__init__()
layers = []
lastv = in_dim
for hidden in hidden_list:
layers.append(nn.Linear(lastv, hidden))
layers.append(nn.ReLU())
lastv = hidden
layers.append(nn.Linear(lastv, out_dim))
self.layers = nn.Sequential(*layers)
def forward(self, x):
shape = x.shape[:-1]
x = self.layers(x.reshape([-1, x.shape[-1]]))
return x.reshape([*shape, -1])
# LIIF组网
@register_model('liif')
class LIIF(nn.Layer):
def __init__(self, encoder_spec, imnet_spec=None,
local_ensemble=True, feat_unfold=True, cell_decode=True):
super().__init__()
self.local_ensemble = local_ensemble
self.feat_unfold = feat_unfold
self.cell_decode = cell_decode
self.encoder = make_model(encoder_spec)
if imnet_spec is not None:
imnet_in_dim = self.encoder.out_dim
if self.feat_unfold:
imnet_in_dim *= 9
imnet_in_dim += 2 # attach coord
if self.cell_decode:
imnet_in_dim += 2
self.imnet = make_model(imnet_spec, args={'in_dim': imnet_in_dim})
else:
self.imnet = None
def gen_feat(self, inp):
self.feat = self.encoder(inp)
return self.feat
def query_rgb(self, coord, cell=None):
feat = self.feat
if self.imnet is None:
ret = F.grid_sample(feat, coord.flip(-1).unsqueeze(1),
mode='nearest', align_corners=False)[:, :, 0, :].transpose(perm=[0, 2, 1])
return ret
if self.feat_unfold:
feat = F.unfold(feat, 3, paddings=1).reshape([feat.shape[0], feat.shape[1] * 9, feat.shape[2], feat.shape[3]])
if self.local_ensemble:
vx_lst = [-1, 1]
vy_lst = [-1, 1]
eps_shift = 1e-6
else:
vx_lst, vy_lst, eps_shift = [0], [0], 0
# field radius (global: [-1, 1])
rx = 2 / feat.shape[-2] / 2
ry = 2 / feat.shape[-1] / 2
feat_coord = make_coord(feat.shape[-2:], flatten=False) \
.transpose(perm=[2, 0, 1]) \
.unsqueeze(0).expand([feat.shape[0], 2, *feat.shape[-2:]])
preds = []
areas = []
for vx in vx_lst:
for vy in vy_lst:
coord_ = coord.clone()
coord_[:, :, 0] += vx * rx + eps_shift
coord_[:, :, 1] += vy * ry + eps_shift
clip_min = -1 + 1e-6
clip_max = 1 - 1e-6
coord_ = paddle.clip(coord_, min=clip_min, max=clip_max)
q_feat = F.grid_sample(
feat, coord_.flip(-1).unsqueeze(1),
mode='nearest', align_corners=False)[:, :, 0, :] \
.transpose(perm=[0, 2, 1])
q_coord = F.grid_sample(
feat_coord, coord_.flip(-1).unsqueeze(1),
mode='nearest', align_corners=False)[:, :, 0, :] \
.transpose(perm=[0, 2, 1])
rel_coord = coord - q_coord
rel_coord[:, :, 0] *= feat.shape[-2]
rel_coord[:, :, 1] *= feat.shape[-1]
inp = paddle.concat([q_feat, rel_coord], axis=-1)
if self.cell_decode:
rel_cell = cell.clone()
rel_cell[:, :, 0] *= feat.shape[-2]
rel_cell[:, :, 1] *= feat.shape[-1]
inp = paddle.concat([inp, rel_cell], axis=-1)
bs, q = coord.shape[:2]
pred = self.imnet(inp.reshape([bs * q, -1])).reshape([bs, q, -1])
preds.append(pred)
area = paddle.abs(rel_coord[:, :, 0] * rel_coord[:, :, 1])
areas.append(area + 1e-9)
tot_area = paddle.stack(areas).sum(axis=0)
if self.local_ensemble:
t = areas[0]; areas[0] = areas[3]; areas[3] = t
t = areas[1]; areas[1] = areas[2]; areas[2] = t
ret = 0
for pred, area in zip(preds, areas):
ret = ret + pred * (area / tot_area).unsqueeze(-1)
return ret
def forward(self, inp, coord, cell):
self.gen_feat(inp)
return self.query_rgb(coord, cell)
定义预测和评估相关
def batched_predict(model, inp, coord, cell, bsize):
with paddle.no_grad():
model.gen_feat(inp)
n = coord.shape[1]
ql = 0
preds = []
while ql < n:
qr = min(ql + bsize, n)
pred = model.query_rgb(coord[:, ql: qr, :], cell[:, ql: qr, :])
preds.append(pred)
ql = qr
pred = paddle.concat(preds, axis=1)
return pred
def eval_psnr(loader, model, data_norm=None, eval_type=None, eval_bsize=None,
verbose=False):
model.eval()
if data_norm is None:
data_norm = {
'inp': {'sub': [0], 'div': [1]},
'gt': {'sub': [0], 'div': [1]}
}
t = data_norm['inp']
inp_sub = paddle.to_tensor(t['sub']).astype('float32').reshape([1, -1, 1, 1])
inp_div = paddle.to_tensor(t['div']).astype('float32').reshape([1, -1, 1, 1])
t = data_norm['gt']
gt_sub = paddle.to_tensor(t['sub']).astype('float32').reshape([1, 1, -1])
gt_div = paddle.to_tensor(t['div']).astype('float32').reshape([1, 1, -1])
if eval_type is None:
metric_fn = calc_psnr
elif eval_type.startswith('div2k'):
scale = int(eval_type.split('-')[1])
metric_fn = partial(calc_psnr, dataset='div2k', scale=scale)
elif eval_type.startswith('benchmark'):
scale = int(eval_type.split('-')[1])
metric_fn = partial(calc_psnr, dataset='benchmark', scale=scale)
else:
raise NotImplementedError
val_res = Averager()
pbar = tqdm(loader, leave=False, desc='val')
for batch in pbar:
for k, v in batch.items():
batch[k] = v
inp = (batch['inp'] - inp_sub) / inp_div
if eval_bsize is None:
with paddle.no_grad():
pred = model(inp, batch['coord'], batch['cell'])
else:
pred = batched_predict(model, inp,
batch['coord'], batch['cell'], eval_bsize)
pred = pred * gt_div + gt_sub
pred = paddle.clip(pred, min=0, max=1)
if eval_type is not None: # reshape for shaving-eval
ih, iw = batch['inp'].shape[-2:]
s = math.sqrt(batch['coord'].shape[1] / (ih * iw))
shape = [batch['inp'].shape[0], round(ih * s), round(iw * s), 3]
pred = pred.reshape(*shape, perm=[0, 3, 1, 2])
batch['gt'] = batch['gt'].reshape(*shape, perm=[0, 3, 1, 2])
res = metric_fn(pred, batch['gt'])
val_res.add(res.item(), inp.shape[0])
if verbose:
pbar.set_description('val {:.4f}'.format(val_res.item()))
return val_res.item()
定义数据读取和训练相关
""" Train for generating LIIF, from image to implicit representation.
Config:
train_dataset:
dataset: $spec; wrapper: $spec; batch_size:
val_dataset:
dataset: $spec; wrapper: $spec; batch_size:
(data_norm):
inp: {sub: []; div: []}
gt: {sub: []; div: []}
(eval_type):
(eval_bsize):
model: $spec
optimizer: $spec
epoch_max:
(multi_step_lr):
milestones: []; gamma: 0.5
(resume): *.pth
(epoch_val): ; (epoch_save):
"""
device = paddle.get_device()
# print(device)
os.environ['CUDA_VISIBLE_DEVICES'] = device.replace('gpu:','')
def make_data_loader(spec, tag=''):
if spec is None:
return None
dataset = make(spec['dataset'])
dataset = make(spec['wrapper'], args={'dataset': dataset})
try:
log('{} dataset: size={}'.format(tag, len(dataset)))
for k, v in dataset[0].items():
log(' {}: shape={}'.format(k, tuple(v.shape)))
finally:
# print('报错了')
pass
loader = DataLoader(dataset, batch_size=spec['batch_size'], shuffle=False, num_workers=0,use_shared_memory=True)
return loader
def make_data_loaders():
train_loader = make_data_loader(config.get('train_dataset'), tag='train')
val_loader = make_data_loader(config.get('val_dataset'), tag='val')
return train_loader, val_loader
def prepare_training():
print('resume config:')
print(config.get('resume'))
if config.get('resume') is not None and os.path.exists(config['resume']):
sv_file = paddle.load(config['resume'])
model = make_model(sv_file['model'], load_sd=True)
optimizer = make_optimizer(
model.parameters(), sv_file['optimizer'], load_sd=True)
print('epoch_resume:')
print(sv_file['epoch'])
epoch_start = sv_file['epoch'] + 1
if config.get('multi_step_lr') is None:
lr_scheduler = None
else:
multi_step_lr = config['multi_step_lr']
lr_scheduler = paddle.optimizer.lr.MultiStepDecay(learning_rate=config['optimizer']['args']['lr'],milestones=multi_step_lr['milestones'],gamma=multi_step_lr['gamma'], verbose=True)
for _ in range(epoch_start - 1):
lr_scheduler.step()
else:
model = make_model(config['model'])
optimizer = make_optimizer(
model.parameters(), config['optimizer'])
epoch_start = 1
if config.get('multi_step_lr') is None:
lr_scheduler = None
else:
multi_step_lr = config['multi_step_lr']
lr_scheduler = paddle.optimizer.lr.MultiStepDecay(learning_rate=config['optimizer']['args']['lr'],
milestones=multi_step_lr['milestones'],
gamma=multi_step_lr['gamma'], verbose=True)
log('model: #params={}'.format(compute_num_params(model, text=True)))
return model, optimizer, epoch_start, lr_scheduler
def train(train_loader, model, optimizer):
model.train()
loss_fn = nn.L1Loss()
train_loss = Averager()
data_norm = config['data_norm']
t = data_norm['inp']
inp_sub = paddle.to_tensor(t['sub']).astype('float32').reshape([1, -1, 1, 1])
inp_div = paddle.to_tensor(t['div']).astype('float32').reshape([1, -1, 1, 1])
t = data_norm['gt']
gt_sub = paddle.to_tensor(t['sub']).astype('float32').reshape([1, 1, -1])
gt_div = paddle.to_tensor(t['div']).astype('float32').reshape([1, 1, -1])
for batch in tqdm(train_loader, leave=False, desc='train'):
for k, v in batch.items():
batch[k] = v
inp = (batch['inp'] - inp_sub) / inp_div
pred = model(inp, batch['coord'], batch['cell'])
gt = (batch['gt'] - gt_sub) / gt_div
loss = loss_fn(pred, gt)
train_loss.add(loss.item())
optimizer.clear_grad()
loss.backward()
optimizer.step()
pred = None
loss = None
return train_loss.item()
def main(config_, save_path):
global config, log, writer
config = config_
log, writer = set_save_path(save_path)
with open(os.path.join(save_path, 'config.yaml'), 'w') as f:
yaml.dump(config, f, sort_keys=False)
train_loader, val_loader = make_data_loaders()
if config.get('data_norm') is None:
config['data_norm'] = {
'inp': {'sub': [0], 'div': [1]},
'gt': {'sub': [0], 'div': [1]}
}
model, optimizer, epoch_start, lr_scheduler = prepare_training()
n_gpus = len(os.environ['CUDA_VISIBLE_DEVICES'].split(','))
if n_gpus > 1:
print("暂不支持多GPUs")
# model = nn.parallel.DataParallel(model)
epoch_max = config['epoch_max']
epoch_val = config.get('epoch_val')
epoch_save = config.get('epoch_save')
max_val_v = -1e18
timer = Timer()
for epoch in range(epoch_start, epoch_max + 1):
# print('epoch = %d' % epoch)
t_epoch_start = timer.t()
log_info = ['epoch {}/{}'.format(epoch, epoch_max)]
writer.add_scalar(tag='train/lr', value=optimizer.get_lr(), step = epoch)
train_loss = train(train_loader, model, optimizer)
if lr_scheduler is not None:
lr_scheduler.step()
log_info.append('train: loss={:.4f}'.format(train_loss))
writer.add_scalar(tag='train/train_loss', value=train_loss, step=epoch)
if n_gpus > 1:
model_ = model.module
else:
model_ = model
model_spec = config['model']
model_spec['sd'] = model_.state_dict()
optimizer_spec = config['optimizer']
optimizer_spec['sd'] = optimizer.state_dict()
sv_file = {
'model': model_spec,
'optimizer': optimizer_spec,
'epoch': epoch
}
paddle.save(sv_file, os.path.join(save_path, 'epoch-last.pdparams'))
if (epoch_save is not None) and (epoch % epoch_save == 0):
paddle.save(sv_file, os.path.join(save_path, 'epoch-{}.pdparams'.format(epoch)))
if (epoch_val is not None) and (epoch % epoch_val == 0):
if n_gpus > 1 and (config.get('eval_bsize') is not None):
model_ = model.module
else:
model_ = model
val_res = eval_psnr(val_loader, model_,
data_norm=config['data_norm'],
eval_type=config.get('eval_type'),
eval_bsize=config.get('eval_bsize'))
log_info.append('val: psnr={:.4f}'.format(val_res))
writer.add_scalar(tag='val/psnr', value=val_res, step=epoch)
if val_res > max_val_v:
max_val_v = val_res
paddle.save(sv_file, os.path.join(save_path, 'epoch-best.pdparams'))
t = timer.t()
prog = (epoch - epoch_start + 1) / (epoch_max - epoch_start + 1)
t_epoch = time_text(t - t_epoch_start)
t_elapsed, t_all = time_text(t), time_text(t / prog)
log_info.append('{} {}/{}'.format(t_epoch, t_elapsed, t_all))
log(', '.join(log_info))
config_path = '/home/aistudio/train_rdn-liif.yaml'
save_name = config_path.split('/')[-1][:-len('.yaml')]
with open(config_path, 'r') as f:
config = yaml.load(f, Loader=yaml.FullLoader)
print('config loaded.')
save_path = os.path.join('home/aistudio/output/', save_name)
main(config, save_path)
6. 总结
本次使用PaddlePaddle复现LIIF对我来说花费的时间还比较长,主要困难有:
- 接触DL时间短,Paddle和Torch都没接触,只用过几次PaddleDetection和PaddleOCR。
- 英语水平差,毕业多年后,读论文都靠翻译工具。
- 工作原因时间上有点不充裕,为此还熬过几个大夜。
克服了这些困难后,现在对Paddle更加熟悉了,对下次复现论文有了更多信心,相信能够快速和高质量的再次复现。
ID:tianxingxia, 一个大龄AI爱好者,有兴趣的朋友希望能多关注,如果本文对你有用请点点赞👍。
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 8
8 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)