
小样本学习分类任务:在文心ERNIE3.0应用(提示学习),提速提效快用起来!
小样本学习在文心模型多分类任务应用(提示学习)
小样本学习在文心ERNIE3.0多分类任务应用(提示学习)
0.小样本学习简介
二分类/多分类任务在商品分类、网页分类、新闻分类、医疗文本分类等现实场景中有着广泛应用。现有的主流解决方案是在大规模预训练语言模型进行微调,因为下游任务和预训练任务训练目标不同,想要取得较好的分类效果往往需要大量标注数据,因此学界和业界开始研究如何在小样本学习(Few-shot Learning)场景下取得更好的学习效果。
提示学习(Prompt Learning) 的主要思想是通过任务转换使得下游任务和预训练任务尽可能相似,充分利用预训练语言模型学习到的特征,从而降低样本需求量。除此之外,我们往往还需要在原有的输入文本上拼接一段“提示”,来引导预训练模型输出期望的结果。
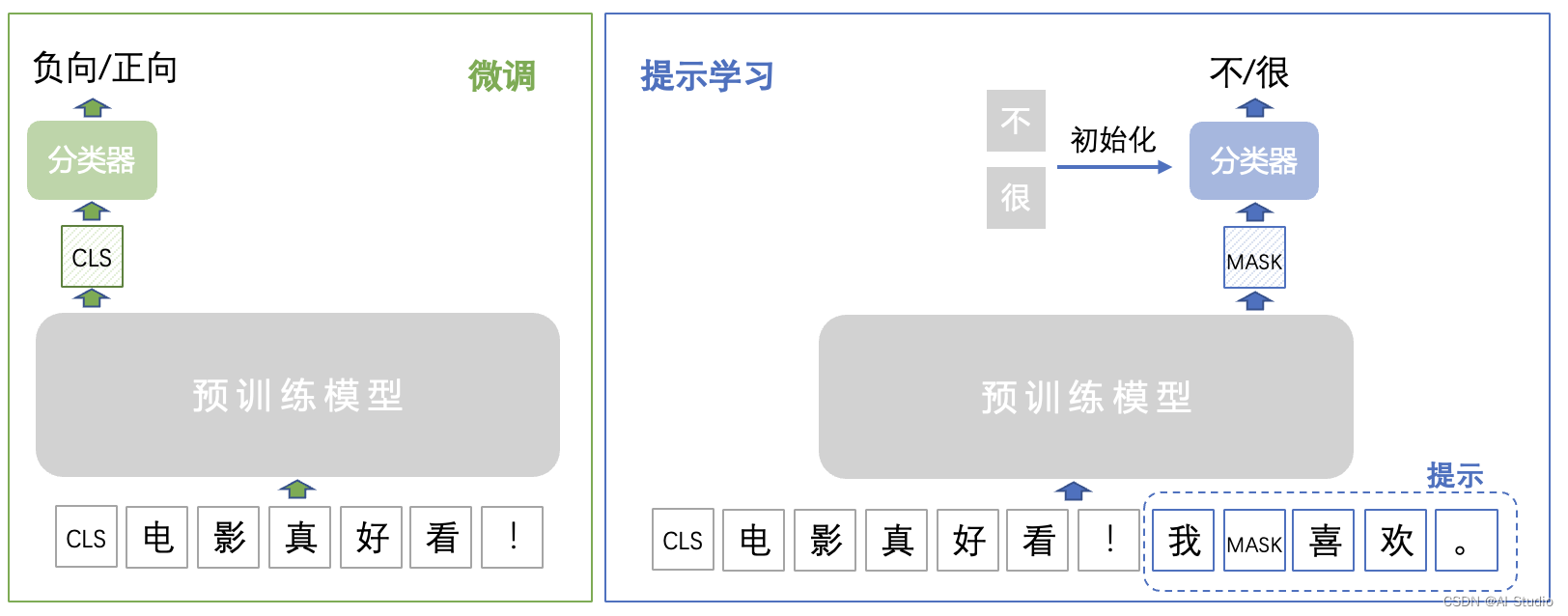
我们以Ernie为例,回顾一下这类预训练语言模型的训练任务。 与考试中的完形填空相似,给定一句文本,遮盖掉其中的部分字词,要求语言模型预测出这些遮盖位置原本的字词。
因此,我们也将多分类任务转换为与完形填空相似的形式。例如影评情感分类任务,标签分为1-正向,0-负向两类。
-
在经典的微调方式中,需要学习的参数是以[CLS]向量为输入,以负向/正向为输出的随机初始化的分类器。
-
在提示学习中,我们通过构造提示,将原有的分类任务转化为完形填空。如下图所示,通过提示我[MASK]喜欢。,原有1-正向,0-负向的标签被转化为了预测空格是很还是不。此时的分类器也不再是随机初始化,而是利用了这两个字的预训练向量来初始化,充分利用了预训练模型学习到的参数。
对于标注样本充足的场景可以直接使用预训练模型微调实现文本多分类,对于尚无标注或者标注样本较少的任务场景我们推荐使用小样本学习,以取得比微调方法更好的效果。
下边通过新闻分类的例子展示如何使用小样本学习来进行文本分类。
0.1 环境要求
python >= 3.6
paddlepaddle >= 2.3
paddlenlp >= 2.4.0 【预计9月份上线】
!pip install --upgrade paddlenlp
#环境安装
paddlenlp目前版本情况:
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
ERROR: Could not find a version that satisfies the requirement paddlenlp==2.4.0 (from versions: 2.0.0a0, 2.0.0a1, 2.0.0a2, 2.0.0a3, 2.0.0a4, 2.0.0a5, 2.0.0a6, 2.0.0a7, 2.0.0a8, 2.0.0a9, 2.0.0b0, 2.0.0b1, 2.0.0b2, 2.0.0b3, 2.0.0b4, 2.0.0rc0, 2.0.0rc1, 2.0.0rc2, 2.0.0rc3, 2.0.0rc4, 2.0.0rc5, 2.0.0rc6, 2.0.0rc7, 2.0.0rc8, 2.0.0rc9, 2.0.0rc10, 2.0.0rc11, 2.0.0rc12, 2.0.0rc13, 2.0.0rc14, 2.0.0rc15, 2.0.0rc16, 2.0.0rc17, 2.0.0rc18, 2.0.0rc19, 2.0.0rc20, 2.0.0rc21, 2.0.0rc22, 2.0.0rc23, 2.0.0rc24, 2.0.0rc25, 2.0.0, 2.0.1, 2.0.2, 2.0.3, 2.0.4, 2.0.5, 2.0.6, 2.0.7, 2.0.8, 2.1.0, 2.1.1, 2.2.0, 2.2.1, 2.2.2, 2.2.3, 2.2.4, 2.2.5, 2.2.6, 2.3.0rc0, 2.3.0rc1, 2.3.0, 2.3.1, 2.3.2, 2.3.3, 2.3.4, 2.3.5)
目前PaddleNLP v2.3.5已经支持新增小样本模型RGL模型了,因此0.1.1不用git方式获取版本;
0.1.1提前尝鲜获取最新版本
!pip install git+
pip 从 git 源码仓库直接 install 。要求是这个github仓库内要有setup.py文件
查看url:
安装git仓库中的包
pip install git+<git仓库地址>
pip install git+<git仓库地址>@<分支名称>
用到它的场景就是比如你有一个代码已经上传到github了,要分发给别人用,你就懒得再下载下来再导出成tar.gz或者whl文件,是可以直接让他从github网址安装
pip install git+http://127.0.0.1/xxx/demo.git --user
pip install git+https://github.com/shadowsocks/shadowsocks.git@master
等价于:
# 两步走的安装(安装完还需要自己删除git文件)
git clone http://127.0.0.1/XXX/demo.git
#change dir
cd demo
# install
python setup.py install --user
# windows环境下加--user 不然容易报错
#直接pip git 无法安装成功,那就采用第二种方案
# !pip install git+https://github.com/PaddlePaddle/PaddleNLP.git@develop
先把paddlenlp develop分支下下载到本地,进行压缩上传到aistudio。
$ git clone https://github.com/PaddlePaddle/PaddleNLP.git
Cloning into 'PaddleNLP'...
remote: Enumerating objects: 27619, done.
remote: Counting objects: 100% (125/125), done.
remote: Compressing objects: 100% (106/106), done.
remote: Total 27619 (delta 46), reused 78 (delta 18), pack-reused 27494
Receiving objects: 100% (27619/27619), 73.69 MiB | 3.03 MiB/s, done.
Resolving deltas: 100% (18182/18182), done.
Updating files: 100% (3115/3115), done.
获得的paddlenl文件夹在C:\Users\admin路径下,然后进行压缩上传到aistudio
win10压缩参考下面链接:(或者直接用压缩软件压缩)
https://blog.csdn.net/sinat_39620217/article/details/126290315
zip -q -r paddlenlp.zip PaddleNLP
# !unzip paddlenlp.zip
#这里采用先装老库再覆盖的方案,确保依赖都安装时,不然直接解压执行setup.py会卡主
!pip install --upgrade paddlenlp
%cd PaddleNLP
!python setup.py install --user
%cd ..
目前PaddleNLP v2.3.5已经支持新增小样本模型RGL模型了,因此0.1.1不用git方式获取版本;
0.2数据集格式要求
对于已有的数据集,需要将数据转换为下述文本分类任务的统一格式。这里我们使用FewCLUE中的tnews数据集后缀为0的子集作为示例数据集,可点击这里下载解压并放入./data/文件夹,或者运行以下脚本
#获取数据
# !wget https://paddlenlp.bj.bcebos.com/datasets/few-shot/tnews.tar.gz
!tar zxvf tnews.tar.gz
!mv tnews data
tnews/
tnews/data.txt
tnews/train.txt
tnews/dev.txt
tnews/label.txt
tnews/test.txt
数据集格式
对于训练/验证/测试数据集文件,每行数据表示一条样本,包括文本和标签两部分,由tab符\t分隔。格式如下
文登区这些公路及危桥将进入封闭施工,请注意绕行! news_car
普洱茶要如何醒茶? news_culture
...
对于待预测数据文件,每行包含一条待预测样本,无标签。格式如下
互联网时代如何保护个人信息
清秋暮雨读柳词:忍把浮名,换了浅斟低唱丨周末读诗
...
对于分类标签集文件,存储了数据集中所有的标签集合,每行为一个标签名。如果需要自定义标签映射用于分类器初始化,则每行需要包括标签名和相应的映射词,由==分隔。格式如下
news_car'=='汽车
news_culture'=='文化
...
Note 这里的标签映射词定义遵循的规则是,不同映射词尽可能长度一致,映射词和提示需要尽可能构成通顺的语句。越接近自然语句,小样本下模型训练效果越好。如果原标签名已经可以构成通顺语句,也可以不构造映射词,每行一个标签即可。
1.模型训练与预测
这里提示一下:
如果运行程序报错:
Traceback (most recent call last):
File "train.py", line 23, in <module>
from paddlenlp.prompt import (
ModuleNotFoundError: No module named 'paddlenlp.prompt'
是因为paddlenlp.prompt在2.4.0版本才会有,请检查上面步骤是否有遗漏,
1.1 训练
1.1.1 微调方式下code
自己跑一下结果即可
!python train.py --dataset_dir "./data/" --save_dir "./checkpoints" --max_seq_length 128 --model_name "ernie-3.0-base-zh" --batch_size 8 --learning_rate 3e-5 --epochs 100 --logging_steps 5 --early_stop
1.1.2 小样本学习下结果
可配置参数说明:
model_name_or_path: 内置模型名,或者模型参数配置目录路径。默认为ernie-3.0-base-zh。
data_dir: 训练数据集路径,数据格式要求详见数据准备。
output_dir: 模型参数、训练日志和静态图导出的保存目录。
prompt: 提示模板。定义了如何将文本和提示拼接结合。
soft_encoder: 提示向量的编码器,lstm表示双向LSTM, mlp表示双层线性层, None表示直接使用提示向量。默认为lstm。
encoder_hidden_size: 提示向量的维度。若为None,则使用预训练模型字向量维度。默认为200。
max_seq_length: 最大句子长度,超过该长度的文本将被截断,不足的以Pad补全。提示文本不会被截断。
learning_rate: 预训练语言模型参数基础学习率大小,将与learning rate scheduler产生的值相乘作为当前学习率。
ppt_learning_rate: 提示相关参数的基础学习率大小,当预训练参数不固定时,与其共用learning rate scheduler。一般设为learning_rate的十倍。
do_train: 是否进行训练。
do_eval: 是否进行评估。
do_predict: 是否进行预测。
do_export: 是否在运行结束时将模型导出为静态图,保存路径为output_dir/export。
max_steps: 训练的最大步数。此设置将会覆盖num_train_epochs。
eval_steps: 评估模型的间隔步数。
logging_steps: 打印日志的间隔步数。
per_device_train_batch_size: 每次训练每张卡上的样本数量。可根据实际GPU显存适当调小/调大此配置。
per_device_eval_batch_size: 每次评估每张卡上的样本数量。可根据实际GPU显存适当调小/调大此配置。
!export CUDA_VISIBLE_DEVICES=0
!python train.py \
--data_dir ./data/tnews \
--output_dir ./checkpoints/ \
--prompt "这条新闻标题的主题是" \
--max_seq_length 128 \
--learning_rate 3e-5 \
--ppt_learning_rate 3e-4 \
--do_train \
--do_eval \
--max_steps 1000 \
--eval_steps 100 \
--logging_steps 10 \
--per_device_eval_batch_size 32 \
--per_device_train_batch_size 32
结果部分展示:
Training Configuration Arguments
[2022-08-18 11:42:58,983] [ INFO] - paddle commit id :3cc6ae69ed93388b2648bcc819d593130dede752
[2022-08-18 11:42:58,983] [ INFO] - _no_sync_in_gradient_accumulation:True
[2022-08-18 11:42:58,983] [ INFO] - adam_beta1 :0.9
[2022-08-18 11:42:58,983] [ INFO] - adam_beta2 :0.999
[2022-08-18 11:42:58,983] [ INFO] - adam_epsilon :1e-08
[2022-08-18 11:42:58,983] [ INFO] - alpha_rdrop :5.0
[2022-08-18 11:42:58,983] [ INFO] - alpha_rgl :0.5
[2022-08-18 11:42:58,983] [ INFO] - current_device :gpu:0
[2022-08-18 11:42:58,984] [ INFO] - dataloader_drop_last :False
[2022-08-18 11:42:58,984] [ INFO] - dataloader_num_workers :0
[2022-08-18 11:42:58,984] [ INFO] - device :gpu
[2022-08-18 11:42:58,984] [ INFO] - disable_tqdm :False
[2022-08-18 11:42:58,984] [ INFO] - do_eval :True
[2022-08-18 11:42:58,984] [ INFO] - do_export :False
[2022-08-18 11:42:58,984] [ INFO] - do_predict :False
[2022-08-18 11:42:58,984] [ INFO] - do_train :True
[2022-08-18 11:42:58,984] [ INFO] - eval_batch_size :32
[2022-08-18 11:42:58,984] [ INFO] - eval_steps :100
[2022-08-18 11:42:58,984] [ INFO] - evaluation_strategy :IntervalStrategy.STEPS
[2022-08-18 11:42:58,984] [ INFO] - first_max_length :None
[2022-08-18 11:42:58,984] [ INFO] - fp16 :False
[2022-08-18 11:42:58,984] [ INFO] - fp16_opt_level :O1
[2022-08-18 11:42:58,984] [ INFO] - freeze_dropout :False
[2022-08-18 11:42:58,984] [ INFO] - freeze_plm :False
[2022-08-18 11:42:58,984] [ INFO] - gradient_accumulation_steps :1
[2022-08-18 11:42:58,984] [ INFO] - greater_is_better :None
[2022-08-18 11:42:58,984] [ INFO] - ignore_data_skip :False
[2022-08-18 11:42:58,984] [ INFO] - label_names :None
[2022-08-18 11:42:58,984] [ INFO] - learning_rate :3e-05
[2022-08-18 11:42:58,984] [ INFO] - load_best_model_at_end :False
[2022-08-18 11:42:58,984] [ INFO] - local_process_index :0
[2022-08-18 11:42:58,984] [ INFO] - local_rank :-1
[2022-08-18 11:42:58,984] [ INFO] - log_level :-1
[2022-08-18 11:42:58,984] [ INFO] - log_level_replica :-1
[2022-08-18 11:42:58,985] [ INFO] - log_on_each_node :True
[2022-08-18 11:42:58,985] [ INFO] - logging_dir :./checkpoints/runs/Aug18_11-42-56_jupyter-691158-4438610
[2022-08-18 11:42:58,985] [ INFO] - logging_first_step :False
[2022-08-18 11:42:58,985] [ INFO] - logging_steps :10
[2022-08-18 11:42:58,985] [ INFO] - logging_strategy :IntervalStrategy.STEPS
[2022-08-18 11:42:58,985] [ INFO] - lr_scheduler_type :SchedulerType.LINEAR
[2022-08-18 11:42:58,985] [ INFO] - max_grad_norm :1.0
[2022-08-18 11:42:58,985] [ INFO] - max_seq_length :128
[2022-08-18 11:42:58,985] [ INFO] - max_steps :5000
[2022-08-18 11:42:58,985] [ INFO] - metric_for_best_model :None
[2022-08-18 11:42:58,985] [ INFO] - minimum_eval_times :None
[2022-08-18 11:42:58,985] [ INFO] - no_cuda :False
[2022-08-18 11:42:58,985] [ INFO] - num_train_epochs :3.0
[2022-08-18 11:42:58,985] [ INFO] - optim :OptimizerNames.ADAMW
[2022-08-18 11:42:58,985] [ INFO] - other_max_length :None
[2022-08-18 11:42:58,985] [ INFO] - output_dir :./checkpoints/
[2022-08-18 11:42:58,985] [ INFO] - overwrite_output_dir :False
[2022-08-18 11:42:58,985] [ INFO] - past_index :-1
[2022-08-18 11:42:58,985] [ INFO] - per_device_eval_batch_size :32
[2022-08-18 11:42:58,985] [ INFO] - per_device_train_batch_size :32
[2022-08-18 11:42:58,985] [ INFO] - ppt_adam_beta1 :0.9
[2022-08-18 11:42:58,985] [ INFO] - ppt_adam_beta2 :0.999
[2022-08-18 11:42:58,985] [ INFO] - ppt_adam_epsilon :1e-08
[2022-08-18 11:42:58,985] [ INFO] - ppt_learning_rate :0.0003
[2022-08-18 11:42:58,985] [ INFO] - ppt_weight_decay :0.0
[2022-08-18 11:42:58,985] [ INFO] - prediction_loss_only :False
[2022-08-18 11:42:58,985] [ INFO] - process_index :0
[2022-08-18 11:42:58,986] [ INFO] - remove_unused_columns :True
[2022-08-18 11:42:58,986] [ INFO] - report_to :['visualdl']
[2022-08-18 11:42:58,986] [ INFO] - resume_from_checkpoint :None
[2022-08-18 11:42:58,986] [ INFO] - run_name :./checkpoints/
[2022-08-18 11:42:58,986] [ INFO] - save_on_each_node :False
[2022-08-18 11:42:58,986] [ INFO] - save_steps :500
[2022-08-18 11:42:58,986] [ INFO] - save_strategy :IntervalStrategy.STEPS
[2022-08-18 11:42:58,986] [ INFO] - save_total_limit :None
[2022-08-18 11:42:58,986] [ INFO] - scale_loss :32768
[2022-08-18 11:42:58,986] [ INFO] - seed :42
[2022-08-18 11:42:58,986] [ INFO] - should_log :True
[2022-08-18 11:42:58,986] [ INFO] - should_save :True
[2022-08-18 11:42:58,986] [ INFO] - task_type :multi-class
[2022-08-18 11:42:58,986] [ INFO] - train_batch_size :32
[2022-08-18 11:42:58,986] [ INFO] - truncate_mode :tail
[2022-08-18 11:42:58,986] [ INFO] - use_rdrop :False
[2022-08-18 11:42:58,986] [ INFO] - use_rgl :False
[2022-08-18 11:42:58,986] [ INFO] - warmup_ratio :0.0
[2022-08-18 11:42:58,986] [ INFO] - warmup_steps :0
[2022-08-18 11:42:58,986] [ INFO] - weight_decay :0.0
[2022-08-18 11:42:58,986] [ INFO] - world_size :1
[2022-08-18 11:42:58,989] [ INFO] - ***** Running training *****
[2022-08-18 11:42:58,989] [ INFO] - Num examples = 240
[2022-08-18 11:42:58,989] [ INFO] - Num Epochs = 625
[2022-08-18 11:42:58,989] [ INFO] - Instantaneous batch size per device = 32
[2022-08-18 11:42:58,989] [ INFO] - Total train batch size (w. parallel, distributed & accumulation) = 32
[2022-08-18 11:42:58,989] [ INFO] - Gradient Accumulation steps = 1
[2022-08-18 11:42:58,989] [ INFO] - Total optimization steps = 5000
[2022-08-18 11:42:58,989] [ INFO] - Total num train samples = 160000
模型保存,以及指标性能
eval_loss: 3.820039987564087, eval_accuracy: 0.5625, eval_runtime: 3.6311, eval_samples_per_second: 66.095, eval_steps_per_second: 2.203, epoch: 125.0
20%|███████▊ | 1000/5000 [08:21<22:29, 2.96it/s]
100%|█████████████████████████████████████████████| 8/8 [00:01<00:00, 7.33it/s]
[2022-08-18 11:51:20,044] [ INFO] - Saving model checkpoint to ./checkpoints/checkpoint-1000
[2022-08-18 11:51:20,045] [ INFO] - Trainer.model is not a `PretrainedModel`, only saving its state dict.
[2022-08-18 11:51:26,610] [ INFO] - tokenizer config file saved in ./checkpoints/checkpoint-1000/tokenizer_config.json
[2022-08-18 11:51:26,610] [ INFO] - Special tokens file saved in ./checkpoints/checkpoint-1000/special_tokens_map.json
#貌似直接点击打不开checkpoints,我们用指令看一下生成的动态模型参数
%cd checkpoints
!ls
%cd ..
/home/aistudio/checkpoints
all_results.json checkpoint-3000 model_state.pdparams trainer_state.json
checkpoint-1000 checkpoint-3500 runs training_args.bin
checkpoint-1500 checkpoint-4000 special_tokens_map.json train_results.json
checkpoint-2000 checkpoint-500 template.json verbalizer.json
checkpoint-2500 export tokenizer_config.json vocab.txt
/home/aistudio
#多卡训练
# !unset CUDA_VISIBLE_DEVICES
# !python -u -m paddle.distributed.launch --gpus 0,1,2,3 train.py \
# --data_dir ./data \
# --output_dir ./checkpoints/ \
# --prompt "这条新闻标题的主题是" \
# --max_seq_length 128 \
# --learning_rate 3e-5 \
# --ppt_learning_rate 3e-4 \
# --do_train \
# --do_eval \
# --max_steps 1000 \
# --eval_steps 100 \
# --logging_steps 10 \
# --per_device_eval_batch_size 32 \
# --per_device_train_batch_size 8 \
# --do_predict \
# --do_export
1.1.3 训练结果对比
精度评价指标:Accuracy
| model_name | 训练方式 | Accuracy |
|---|---|---|
| ernie-3.0-base-zh | 微调学习 | 0.5046 |
| ernie-3.0-base-zh | 小样本学习 | 0.5625 |
1.2 预测
在模型训练时开启–do_predict,训练结束后直接进行预测,也可以在训练结束后,通过运行以下命令加载模型参数进行预测:
可配置参数说明:
data_dir: 测试数据路径。数据格式要求详见数据准备,数据应存放在该目录下test.txt文件中,每行一条待预测文本。
output_dir: 日志的保存目录。
resume_from_checkpoint: 训练时模型参数的保存目录,用于加载模型参数。
do_predict: 是否进行预测。
max_seq_length: 最大句子长度,超过该长度的文本将被截断,不足的以Pad补全。提示文本不会被截断。
!python train.py --do_predict --data_dir ./data/tnews --output_dir ./predict_ckpt --resume_from_checkpoint ./checkpoints --max_seq_length 128
测试结果性能展示:
[2022-08-18 13:04:45,520] [ INFO] - ***** Running Prediction *****
[2022-08-18 13:04:45,520] [ INFO] - Num examples = 2010
[2022-08-18 13:04:45,520] [ INFO] - Pre device batch size = 8
[2022-08-18 13:04:45,520] [ INFO] - Total Batch size = 8
[2022-08-18 13:04:45,520] [ INFO] - Total prediction steps = 252
99%|████████████████████████████████████████▋| 250/252 [00:15<00:00, 16.99it/s]***** test metrics *****
test_accuracy = 0.5468
test_loss = 3.4095
test_runtime = 0:00:16.65
test_samples_per_second = 120.664
test_steps_per_second = 15.128
100%|█████████████████████████████████████████| 252/252 [00:15<00:00, 16.44it/s]
label:
news_tech科技
news_entertainment娱乐
news_car汽车
news_travel旅游
news_finance财经
news_edu教育
news_world国际
news_house房产
news_game电竞
news_military军事
news_story故事
news_culture文化
news_sports体育
news_agriculture农业
news_stock==股票
预测部分结果展示:
电影中的打麻将场景,艺术来源于生活 news_entertainment
在迪士尼说迪士尼 news_entertainment
廖凡重出“江湖”再争影帝 亮相戛纳红毯霸气有型 news_entertainment
2. 模型导出与部署
2.1 导出
在训练结束后,需要将动态图模型导出为静态图参数用于部署推理。可以在模型训练时开启–do_export在训练结束后直接导出,也可以运行以下命令加载并导出训练后的模型参数,默认导出到在output_dir指定的目录下。
python train.py --do_predict --data_dir ./data --output_dir ./predict_ckpt --resume_from_checkpoint ./ckpt/ --max_seq_length 128
可配置参数说明:
data_dir: 标签数据路径。数据格式要求详见数据准备。
output_dir: 静态图模型参数和日志的保存目录。
resume_from_checkpoint: 训练时模型参数的保存目录,用于加载模型参数。
do_export: 是否将模型导出为静态图,保存路径为output_dir/export。
2.2 模型部署
模型转换与ONNXRuntime预测部署依赖Paddle2ONNX和ONNXRuntime,Paddle2ONNX支持将Paddle静态图模型转化为ONNX模型格式,算子目前稳定支持导出ONNX Opset 7~15,更多细节可参考:Paddle2ONNX。
https://github.com/PaddlePaddle/Paddle2ONNX
如果基于GPU部署,请先确保机器已正确安装NVIDIA相关驱动和基础软件,确保CUDA >= 11.2,CuDNN >= 8.2,并使用以下命令安装所需依赖:
pip install paddle2onnx==1.0.0rc3
python -m pip install onnxruntime-gpu onnx onnxconverter-common
如果基于CPU部署,请使用如下命令安装所需依赖:
pip install paddle2onnx==1.0.0rc3
python -m pip install onnxruntime
CPU端推理样例
python infer.py --model_path_prefix ckpt/export/model --data_dir ./data --batch_size 32 --device cpu
GPU端推理样例
python infer.py --model_path_prefix ckpt/export/model --data_dir ./data --batch_size 32 --device gpu --device_id 0
可配置参数说明:
model_path_prefix: 导出的静态图模型路径及文件前缀。
model_name_or_path: 内置预训练模型名,或者模型参数配置目录路径,用于加载tokenizer。默认为ernie-3.0-base-zh。
data_dir: 待推理数据所在路径,数据应存放在该目录下的data.txt文件。
max_seq_length: 最大句子长度,超过该长度的文本将被截断,不足的以Pad补全。提示文本不会被截断。
batch_size: 每次预测的样本数量。
device: 选择推理设备,包括cpu和gpu。默认为gpu。
device_id: 指定GPU设备ID。
num_threads: 设置CPU使用的线程数。默认为机器上的物理内核数。
3.总结
预训练语言模型的参数空间比较大,如果在下游任务上直接对这些模型进行微调,为了达到较好的模型泛化性,需要较多的训练数据。在实际业务场景中,特别是垂直领域、特定行业中,训练样本数量不足的问题广泛存在,极大地影响这些模型在下游任务的准确度,因此,预训练语言模型学习到的大量知识无法充分地发挥出来。本项目实现基于预训练语言模型的小样本数据调优,从而解决大模型与小训练集不相匹配的问题。
小样本学习是机器学习领域未来很有前景的一个发展方向,它要解决的问题很有挑战性、也很有意义。小样本学习中最重要的一点就是先验知识的利用,如果我们妥善解决了先验知识的利用,能够做到很好的迁移性,想必那时我们距离通用AI也不远了。
提速提效:
训练结果对比
精度评价指标:Accuracy
| model_name | 训练方式 | Accuracy |
|---|---|---|
| ernie-3.0-base-zh | 微调学习 | 0.5046 |
| ernie-3.0-base-zh | 小样本学习 | 0.5625 |
可以看到小样本学习训练下,我们标注量更少了,性能准确率更高了,所以提速提效!
最后也可以看出目前在新闻数据做的小样本demo性能结果上还有所欠缺,后续将进行改进。
展望: 后续将完成模型融合环节提升性能,并做可解释性分析。
本人博客:https://blog.csdn.net/sinat_39620217?type=blog
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)