
自监督学习经典之作:DINO
Emerging Properties in Self-Supervised Vision Transformers论文复现
自监督学习经典之作: DINO(self-distillation with no labels)
Emerging Properties in Self-Supervised Vision Transformers
1、引言
一般来说ViT 并不像某些人预期的那样有吸引力:因为它们需要很多的计算资源,并且需要更多的训练数据,最主要的是它们也没有表现出独特的特点。 Caron 等人在 2020 年发表的论文“Emerging Properties in Self-Supervised Vision Transformers”(DINO)中。 旨在研究为什么有监督的 ViT 还没有起飞,以及是否可以通过对它们应用自监督学习方法来改变这种情况。
传统上的计算机视觉模型,例如:卷积神经网络,总是在人工监督下进行训练。 这意味着人类必须为训练数据创建标签,例如告诉模型图像中有一只狗。自监督学习允许它在没有任何标签的情况下训练模型。 因此,在计算机视觉任务的情况下,只有图像被提供给模型,网络本身学会理解周围的视觉世界,这是自监督学习的终极目标。
事实证明,将自监督应用于 Vision Transformers 会得到一下我们期望的特性:该模型学习从语义上分割对象并创建边界。 并且该信息可在自注意力模块中访问。 我们将在后面讨论什么是自注意力。

来自DINO的注意力热图显示了该模型如何令人印象深刻地聚焦于图像最相关的部分。这也作为无监督语义分割。
学习到的特征表示,即模型的输出向量,对于执行聚类非常有用。 此外,应用 k-最近邻分类器会产生一些令人印象深刻的分类结果,如下图所示。DINO以自监督的方式学习的簇。这在训练过程中没有使用任何标签。

2、DINO的工作原理
DINO 采用一种称为自蒸馏的方法。 这也是名字的由来:没有标签的自蒸馏。自蒸馏创造了一个教师和一个学生网络。 这两个网络都具有完全相同的模型架构。 DINO 的一大优势在于在这一点上完全灵活:可以使用 新兴的ViT 或 传统的卷积都是可以的,例如流行的 ResNet-50。

DINO 训练过程的简化概述: 一张图片被裁剪成两种尺寸,然后输入学生和教师网络。 对教师的输出应用居中操作,并且两个输出都通过 softmax 层归一化整理。为了交叉熵作为损失函数为模型反向传播提供更新参数的策略。
两个 softmax 输出都传递到损失函数中,使用随机梯度下降 (SGD) 执行反向传播。在这里的反向传播是通过学生网络执行的,这时教师的权重尚未更新的原因。 为了更新教师模型,DINO 对学生权重使用指数移动平均 (EMA),将学生网络的模型参数传输到教师网络。
3、实验结果
在我看来,最相关的是将 KNN分类器应用于训练特征表示时的分类性能。 如本文的介绍所示,DINO 对不同类别的聚类效果非常好。这种巨大的分离是清晰可见的,代表相似物体的簇彼此更近。这意味着在没有标签监督的情况下,只通过自监督的预训练,就可以实现高准确率的分类。此外,DINO似乎可以很好地进行线性分类。

DINO在ImageNet上自监督学校效果也是非常优异的。
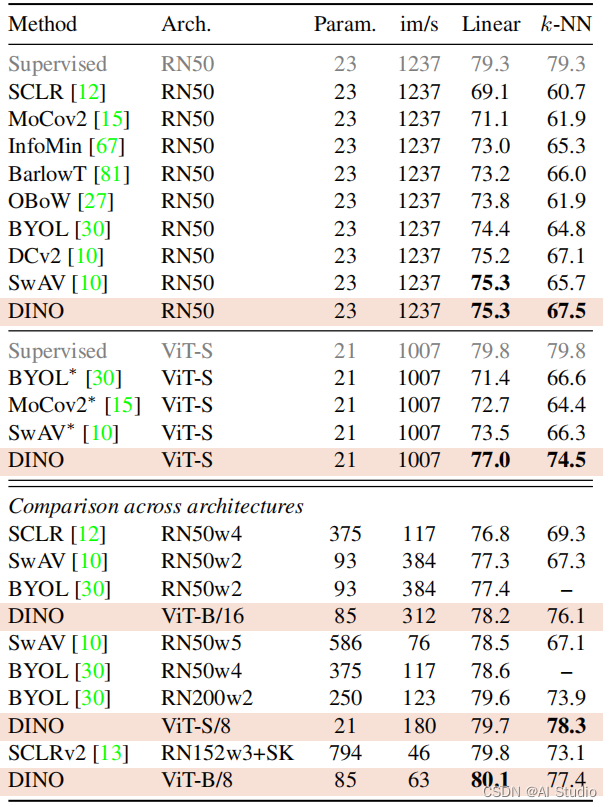
4、高准确率的注意力和完全无监督的语义分割
在视觉上最令人印象深刻的当然是由自注意机制产生的分割结果。就像人类一样,模型关注场景中的相关对象,即使遮挡了部分图像结果还是一样的。虽然在本文中没有进行定量评估,但这种可视化提供了对模型工作过程的更透明解释,并增加了对其能力的可解释性。这一点特性是MAE等掩码建模自监督学习方法不具备的,这一特性可以为无监督语义分割、无监督目标检测等提供一个大致物体位置,这个有很重要意义。

5、代码复现
1、代码位置在Project/dino
2、本次项目复现基于PASSL,感兴趣的同学可以去看看。
3、PASSL使用HOOK进编程(detectron2也是),可以看到项目中没有PASSL中的项目代码,整个项目是基于PASSL进行二次开发,我建议同学们也采用这种方式,对于这种工具型项目,不要修改其源码,而是在其基础上进行二次开发,这样的项目代码整洁、明了。
4、二次开发方式:(1)按照PASSL项目结构创建configs文件夹和dino文件夹。(2)dino文件夹中也按照PASSL中passl文件夹下子文件夹名字进行命名,并依次写入自己新的代码,每一个文件夹下面都要有__init__.py文件,并且每一个新的模块按照PASSL要求进行模块注册。(3)在最外层创建train.py文件夹,直接copy PASSL中train.py代码,但是需要注意,项目中新注册模块需要在train.py中import(示例可以见本项目中train.py)
5、之后我会具体出一期怎么来在这种工具型项目上二次开发的教程(包括Paddledetection、PaddleSeg、Paddleclas)。这个项目大家可以先学习一下,确实很方便,也可以逐渐规范自己代码书写习惯。
核心代码展示
其实核心的就是教师和学生模型结构,其余的都是常见网络(例如VIT)
@MODELS.register()
class DINO(nn.Layer):
"""
Build a DINO model with: a teacher and a student.
"""
def __init__(self,
architecture=None,
neck=None,
head=None,
m=0.996,
epoch=0,
drop_path_rate=0.1,
norm_last_layer=True):
"""
Args:
backbone (dict): config of backbone.
neck (dict): config of neck.
head (dict): config of head.
scale (list|tuple): Range of size of the origin size cropped. Default: (0.08, 1.0)
dim (int): feature dimension. Default: 128.
m (float): moco momentum of updating key encoder. Default: 0.999.
"""
super(DINO, self).__init__()
self.m = m
self.epoch = epoch
# create the teacher and student
self.teacher = nn.Sequential(build_backbone(architecture),
build_neck(neck))
# add specific cfg to student
architecture.update({'drop_path_rate': drop_path_rate})
neck.update({'norm_last_layer': norm_last_layer})
self.student = nn.Sequential(build_backbone(architecture),
build_neck(neck))
self.head = build_head(head)
if has_batchnorms(self.student):
self.teacher = nn.SyncBatchNorm.convert_sync_batchnorm(self.teacher)
self.student = nn.SyncBatchNorm.convert_sync_batchnorm(self.student)
self.teacher.set_state_dict(self.student.state_dict())
for p in self.teacher.parameters():
p.stop_gradient = True
@paddle.no_grad()
def _momentum_update_teacher(self):
"""
Momentum update of the teacher
"""
for param_q, param_k in zip(self.student.parameters(),
self.teacher.parameters()):
paddle.assign((param_k * self.m + param_q * (1. - self.m)), param_k)
param_k.stop_gradient = True
def train_wrapper(self, x, backbone, neck):
# convert to list
if not isinstance(x, (list, tuple)):
x = [x]
idx_crops = paddle.cumsum(paddle.unique_consecutive(
paddle.to_tensor([inp.shape[-1] for inp in x]),
return_counts=True,
)[1], 0)
start_idx, output = 0, paddle.empty((0, ))
for end_idx in idx_crops:
outs = backbone(paddle.concat(x[start_idx: end_idx]))
if isinstance(outs, tuple):
out = outs[0]
patch_token, cls_token = out
# accumulate outputs
output = paddle.concat([output, cls_token])
start_idx = end_idx
return neck(output)
def train_iter(self, *inputs, **kwargs):
teacher_output = self.train_wrapper(x=inputs[:2],
backbone=self.teacher[0],
neck=self.teacher[1])
student_output = self.train_wrapper(x=inputs,
backbone=self.student[0],
neck=self.student[1])
outputs = self.head(student_output, teacher_output, self.epoch)
return outputs
def forward(self, *inputs, mode='train', **kwargs):
if mode == 'train':
return self.train_iter(*inputs, **kwargs)
else:
raise Exception("No such mode: {}".format(mode))
6、训练代码(ImageNet-mini复现)
#不需要git clone源码,我们是二次开发,所以直接pip 安装
!pip install "git+https://gitee.com/qias/PASSL.git"
#解压数据
!unzip -d data/ data/data89857/imagenet.zip
%cd /home/aistudio/Project/
/home/aistudio/dino
#安装必要的库
!pip install -r requirements.txt
#源码中少了个包,这里我已经上传到项目中,直接执行下面命令即可
!cp bpe_simple_vocab_16e6.txt.gz /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/passl/utils/
#开启训练
#我们此次是在ImageNet mini上进行训练
上进行训练
!python train.py -c configs/dino/dino_small_p16_224.yaml
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/passl/datasets/preprocess/auto_augment.py:42: DeprecationWarning: BILINEAR is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.BILINEAR instead.
_RANDOM_INTERPOLATION = (Image.BILINEAR, Image.BICUBIC)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/passl/datasets/preprocess/auto_augment.py:42: DeprecationWarning: BICUBIC is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.BICUBIC instead.
_RANDOM_INTERPOLATION = (Image.BILINEAR, Image.BICUBIC)
[08/24 01:06:40] passl INFO: Configs: {'epochs': 100, 'output_dir': 'outputs', 'seed': 0, 'device': 'gpu', 'model': {'name': 'DINO', 'architecture': {'name': 'DINOVisionTransformer', 'img_size': 224, 'patch_size': 16, 'width': 384, 'depth': 12, 'num_heads': 6, 'mlp_ratio': 4, 'epsilon': 1e-06}, 'neck': {'name': 'DINONeck', 'in_dim': 384, 'out_dim': 65536, 'use_bn': False}, 'head': {'name': 'DINOHead', 'out_dim': 65536, 'n_crops': 10, 'warmup_teacher_temp': 0.04, 'teacher_temp': 0.04, 'warmup_teacher_temp_epochs': 0, 'n_epochs': 100}}, 'dataloader': {'train': {'loader': {'num_workers': 4, 'use_shared_memory': True}, 'sampler': {'batch_size': 64, 'shuffle': True, 'drop_last': True}, 'dataset': {'name': 'ImageNet', 'dataroot': '/home/aistudio/data/imagenet/train/', 'return_label': False, 'return_two_sample': False, 'transforms': [{'name': 'MultiCrop', 'global_transform1': [{'name': 'RandomResizedCrop', 'size': 224, 'scale': [0.4, 1.0], 'interpolation': 'bicubic'}, {'name': 'RandomHorizontalFlip'}, {'name': 'RandomApply', 'transforms': [{'name': 'ColorJitter', 'brightness': 0.4, 'contrast': 0.4, 'saturation': 0.2, 'hue': 0.1}], 'p': 0.8}, {'name': 'RandomGrayscale', 'p': 0.2}, {'name': 'GaussianBlur', '_PIL': True}, {'name': 'Transpose'}, {'name': 'NormalizeImage', 'scale': '1.0/255.0', 'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}], 'global_transform2': [{'name': 'RandomResizedCrop', 'size': 224, 'scale': [0.4, 1.0], 'interpolation': 'bicubic'}, {'name': 'RandomHorizontalFlip'}, {'name': 'RandomApply', 'transforms': [{'name': 'ColorJitter', 'brightness': 0.4, 'contrast': 0.4, 'saturation': 0.2, 'hue': 0.1}], 'p': 0.8}, {'name': 'RandomGrayscale', 'p': 0.2}, {'name': 'RandomApply', 'transforms': [{'name': 'GaussianBlur', '_PIL': True}], 'p': 0.1}, {'name': 'RandomApply', 'transforms': [{'name': 'Solarization'}], 'p': 0.2}, {'name': 'Transpose'}, {'name': 'NormalizeImage', 'scale': '1.0/255.0', 'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}], 'local_transform': [{'name': 'RandomResizedCrop', 'size': 96, 'scale': [0.05, 0.4], 'interpolation': 'bicubic'}, {'name': 'RandomHorizontalFlip'}, {'name': 'RandomApply', 'transforms': [{'name': 'ColorJitter', 'brightness': 0.4, 'contrast': 0.4, 'saturation': 0.2, 'hue': 0.1}], 'p': 0.8}, {'name': 'RandomGrayscale', 'p': 0.2}, {'name': 'RandomApply', 'transforms': [{'name': 'GaussianBlur', '_PIL': True}], 'p': 0.5}, {'name': 'Transpose'}, {'name': 'NormalizeImage', 'scale': '1.0/255.0', 'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}], 'local_crops_number': 8}]}}}, 'lr_scheduler': {'name': 'CosineWarmup', 'learning_rate': 0.001, 'T_max': 250200, 'warmup_steps': 25020, 'start_lr': 0.0, 'end_lr': 0.001, 'eta_min': 1e-06}, 'optimizer': {'name': 'AdamW', 'weight_decay': 0.04, 'grad_clip': {'name': 'clip_norm', 'value': 3.0}, 'exclude_from_weight_decay': ['bias', 'norm']}, 'optimizer_config': {'name': 'DINOOptimizerHook', 'freeze_last_layer': 1}, 'log_config': {'name': 'LogHook', 'interval': 50}, 'custom_config': [{'name': 'DINOHook'}], 'is_train': True, 'timestamp': '-2022-08-24-01-06'}
[08/24 01:06:40] passl.engine.trainer INFO: train with paddle 2.3.1 on Place(gpu:0) device
W0824 01:06:40.755964 10515 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0824 01:06:40.759747 10515 gpu_resources.cc:91] device: 0, cuDNN Version: 7.6.
[08/24 01:06:42] passl.engine.trainer INFO: Number of Parameters is 43.95M.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/vision/transforms/functional_pil.py:297: DeprecationWarning: FLIP_LEFT_RIGHT is deprecated and will be removed in Pillow 10 (2023-07-01). Use Transpose.FLIP_LEFT_RIGHT instead.
return img.transpose(Image.FLIP_LEFT_RIGHT)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/vision/transforms/functional_pil.py:297: DeprecationWarning: FLIP_LEFT_RIGHT is deprecated and will be removed in Pillow 10 (2023-07-01). Use Transpose.FLIP_LEFT_RIGHT instead.
return img.transpose(Image.FLIP_LEFT_RIGHT)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/vision/transforms/functional_pil.py:297: DeprecationWarning: FLIP_LEFT_RIGHT is deprecated and will be removed in Pillow 10 (2023-07-01). Use Transpose.FLIP_LEFT_RIGHT instead.
return img.transpose(Image.FLIP_LEFT_RIGHT)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/vision/transforms/functional_pil.py:297: DeprecationWarning: FLIP_LEFT_RIGHT is deprecated and will be removed in Pillow 10 (2023-07-01). Use Transpose.FLIP_LEFT_RIGHT instead.
return img.transpose(Image.FLIP_LEFT_RIGHT)
[08/24 01:06:48] passl.engine.trainer INFO: Epoch [1/100][0/1562] lr: 0.000e+00, eta: 10 days, 19:01:00, time: 5.970, data_time: 2.784, loss 1.0746e+01 (1.0746e+01)
7、总结
1、在本文中简单介绍了 DINO的工作原理,这是一篇利用 Vision Transformers 中自监督学习的论文。其中,DINO自监督训练的VIT的注意力图中可以大致分割出物体位置,对于无监督语义分割等无监督下游任务可以提供伪标签,很有参考意义。
2、项目目前正在训练中,具体的微调代码,大家可以直接到PASSL中copy过来
3、喜欢的点点star吧
参考文献
1、论文导读:DINO -自监督视觉Transformers
2、DINO代码参考代码地址,感谢这位作者对Paddle社区精彩的贡献
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 10
10 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)