
【强化学习】REINFORCE算法
策略梯度算法:REINFORCE+CartPole-v1的paddle版本
强化学习算法:REINFORCE+CartPole-v1
REINFORCE介绍
强化学习中的策略优化主要有两类:基于价值的方法和基于策略的方法(当然两者的结合产生了 Actor-Critic 等算法)。基于值函数的方法主要是学习值函数,然后根据值函数导出一个策略,学习过程中并不存在一个显式的策略;而基于策略的方法则是直接显式地学习一个目标策略。我们在之前的项目介绍了基于价值的方法DQN;在本项目,我们将介绍一个基于策略的方法REINFORCE,它是策略梯度方法中最早提出的,也是最简单、最基本的方法。
REINFORCE算法
REINFORCE算法仅使用一个网络,我们可以称之为策略网络。我们使用智能体网络与环境进行一个回合的交互,同时收集所有的轨迹信息,最后使用一个回合所有的交互信息更新策略网络。算法如下:
CartPole-v1
CartPole是gym提供的经典控制环境摆车,它要求给小车向左或向右的力,移动小车,让上面的杆子能竖起来。该环境有4个连续的环境状态和2个离散的动作。具体内容如下表所示:
环境状态:
| Num | Observation | Min | Max |
|---|---|---|---|
| 0 | Cart Position | -4.8 | 4.8 |
| 1 | Cart Velocity | -Inf | Inf |
| 2 | Pole Angle | ~ -0.418 rad (-24°) | ~ 0.418 rad (24°) |
| 3 | Pole Angular Velocity | -Inf | Inf |
动作:
| Num | Action |
|---|---|
| 0 | Push cart to the left |
| 1 | Push cart to the right |
1.导入依赖包
- paddle框架
- gym环境库
- matplotlib画图工具
- tqdm进度条显示
import gym
import paddle
import paddle.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
from matplotlib import animation
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import MutableMapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Iterable, Mapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Sized
2.策略网络
我们使用简单的两层全连接网络,两层之间使用relu激活函数连接。由于动作是离散的,因此最后的输出经过sofamax函数处理,将各个输出节点的输出值范围映射到[0, 1],并且约束各个输出节点的输出值的和为1。
class PolicyNet(paddle.nn.Layer):
def __init__(self, obs_dim,act_dim):
super(PolicyNet,self).__init__()
self.fc1 =paddle.nn.Linear(obs_dim,64)
self.fc2 =paddle.nn.Linear(64,act_dim)
def forward(self, obs): # 可直接用model(obs)调用
out1 = F.relu(self.fc1(obs))
out2 = F.softmax(self.fc2(out1))
return out2
3.REINFORCE智能体
- init:初始化函数,包括策略网络,网络优化器,折扣因子
- sample:动作抽样函数,依据概率
- get_ut:计算每个step的折扣回报
- learn:智能体网络更新
- save:保存网络参数
- load:加载网络参数
class REINFORCE:
def __init__(self, state_dim, action_dim, learning_rate, gamma):
self.policy_net = PolicyNet(state_dim,action_dim)
self.optimizer = paddle.optimizer.Adam(learning_rate=learning_rate,parameters=self.policy_net.parameters()) # 使用Adam优化器
self.gamma = gamma # 折扣因子
#选取动作
def sample(self, obs):
obs=paddle.to_tensor(obs,dtype='float32')
act_prob=self.policy_net(obs).numpy() #转换为数组
act = np.random.choice(range(2), p=act_prob) # 根据动作概率选取动作
return act
# 计算每一个step的ut
def get_ut(self,reward_list, gamma=1.0):
for i in range(len(reward_list) - 2, -1, -1):
reward_list[i] += gamma * reward_list[i + 1]
return np.array(reward_list)
def learn(self, transition_dict):
obs=paddle.to_tensor(transition_dict['states'],dtype='float32')
act=paddle.to_tensor(transition_dict['actions'],dtype='int64')
reward=paddle.to_tensor(self.get_ut(transition_dict['rewards'],self.gamma),dtype='float32')
act_prob = self.policy_net(obs) # 获取输出动作概率
# 采用梯度上升,因此要乘以-1
log_prob = paddle.sum(-1.0 * paddle.log(act_prob) * paddle.nn.functional.one_hot(act, act_prob.shape[1]),axis=-1)
loss = log_prob * reward
loss = paddle.mean(loss)
loss.backward()
self.optimizer.step()
self.optimizer.clear_grad()
def save(self):
paddle.save(self.policy_net.state_dict(),'net.pdparams')
def load(self):
layer_state_dict = paddle.load("net.pdparams")
self.policy_net.set_state_dict(layer_state_dict)
4.超参数设置
学习率、回合数episode、折扣因子gamma、环境参数、随机种子…
learning_rate = 1e-3
num_episodes = 1000
gamma = 0.99
env_name = "CartPole-v1"
env = gym.make(env_name)
env.seed(0)
paddle.seed(0)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
5.训练
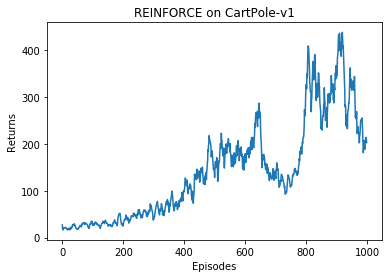
定义智能体并进行训练,使用tqdm输出训练进度条,并绘制训练过程的奖励曲线图。通过奖励图的变化,我们可以看到奖励随着训练不断增加(变好),但是在训练的后期出现了奖励下降的趋势,猜测可能是在学习率设置、动作预测方式、网络更新策略更方面存在不足,后续尽量解决这个问题。目前采用的策略是:保存奖励值最高点的策略网络参数,用于后续的验证。
agent = REINFORCE(state_dim, action_dim, learning_rate, gamma)
return_list = []
maxre=0
for i in range(10):
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)):
episode_return = 0
transition_dict = {
'states': [],
'actions': [],
'rewards': [],
}
state = env.reset()
done = False
while not done:
action = agent.sample(state)
next_state, reward, done, _ = env.step(action)
transition_dict['states'].append(state)
transition_dict['actions'].append(action)
transition_dict['rewards'].append(reward)
state = next_state
episode_return += reward
if maxre<episode_return:
maxre=episode_return
agent.save()
return_list.append(episode_return)
agent.learn(transition_dict)
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({
'episode':
'%d' % (num_episodes / 10 * i + i_episode + 1),
'return':
'%.3f' % np.mean(return_list[-10:])
})
pbar.update(1)
W0906 21:20:43.419157 907 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0906 21:20:43.423945 907 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
Iteration 0: 100%|██████████| 100/100 [00:02<00:00, 39.61it/s, episode=100, return=32.800]
Iteration 1: 100%|██████████| 100/100 [00:01<00:00, 55.35it/s, episode=200, return=30.900]
Iteration 2: 100%|██████████| 100/100 [00:02<00:00, 37.36it/s, episode=300, return=55.500]
Iteration 3: 100%|██████████| 100/100 [00:03<00:00, 26.62it/s, episode=400, return=80.200]
Iteration 4: 100%|██████████| 100/100 [00:07<00:00, 11.68it/s, episode=500, return=163.200]
Iteration 5: 100%|██████████| 100/100 [00:09<00:00, 10.97it/s, episode=600, return=165.800]
Iteration 6: 100%|██████████| 100/100 [00:09<00:00, 14.83it/s, episode=700, return=122.900]
Iteration 7: 100%|██████████| 100/100 [00:07<00:00, 6.24it/s, episode=800, return=264.100]
Iteration 8: 100%|██████████| 100/100 [00:16<00:00, 5.45it/s, episode=900, return=328.000]
Iteration 9: 100%|██████████| 100/100 [00:15<00:00, 9.07it/s, episode=1000, return=203.800]
def moving_average(a, window_size):
cumulative_sum = np.cumsum(np.insert(a, 0, 0))
middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_size
r = np.arange(1, window_size-1, 2)
begin = np.cumsum(a[:window_size-1])[::2] / r
end = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]
return np.concatenate((begin, middle, end))
episodes_list = list(range(len(return_list)))
# plt.plot(episodes_list, return_list)
# plt.xlabel('Episodes')
# plt.ylabel('Returns')
# plt.title('REINFORCE on {}'.format(env_name))
# plt.show()
mv_return = moving_average(return_list, 9)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('REINFORCE on {}'.format(env_name))
plt.show()
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
if isinstance(obj, collections.Iterator):
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return list(data) if isinstance(data, collections.MappingView) else data
6.验证
使用训练好的网络参数初始化策略网络,并在CartPole-v1环境进行250个step的测试。由于ai studio好像不支持gym环境的可视化,运行’‘‘env.render(mode=“rgb_array”)’’'会报错,因此我们将该部分代码使用markdown呈现,可在本地进行运行。我们将本地运行结果附在下方直观的展示REINFORCE的训练结果。
def save_frames_as_gif(frames, filename):
#Mess with this to change frame size
plt.figure(figsize=(frames[0].shape[1]/100, frames[0].shape[0]/100), dpi=300)
patch = plt.imshow(frames[0])
plt.axis('off')
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(plt.gcf(), animate, frames = len(frames), interval=50)
anim.save(filename, writer='pillow', fps=60)
actor_pre=PolicyNet(4,2)
layer_state_dict = paddle.load("net.pdparams")
actor_pre.set_state_dict(layer_state_dict)
env=gym.make('CartPole-v1')
state=env.reset()
frames = []
for i in range(250):
#print(env.render(mode="rgb_array"))
frames.append(env.render(mode="rgb_array"))
state=paddle.to_tensor(state,dtype='float32')
action =actor_pre(state).numpy()
#action=action.numpy()[0]
#print(action)
next_state,reward,done,_=env.step(np.argmax(action))
if i%50==0:
print(i," ",reward,done)
state=next_state
save_frames_as_gif(frames, filename="CartPole.gif")
env.close()

7.总结
本项目对基于策略的强化学习算法REINFORCE进行了复现,但受于本人认知水平等因素影响,在该项目中可能存在不严谨、甚至错误的地方,还请大家批评指正。
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)