
AutoInt 广告点击率预估模型
模型代码实现&在线运行 广告点击率预估模型AutoInt
AutoInt模型
代码请参考:autoint
内容
模型简介
CTR(Click Through Rate),即点击率,是“推荐系统/计算广告”等领域的重要指标,对其进行预估是商品推送/广告投放等决策的基础。简单来说,CTR预估对每次广告的点击情况做出预测,预测用户是点击还是不点击。CTR预估模型综合考虑各种因素、特征,在大量历史数据上训练,最终对商业决策提供帮助。本模型实现了下述论文中的AutoInt模型:
@article{weiping2018autoint,
title={AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks},
author={Weiping, Song and Chence, Shi and Zhiping, Xiao and Zhijian, Duan and Yewen, Xu and Ming, Zhang and Jian, Tang},
journal={arXiv preprint arXiv:1810.11921},
year={2018}
}
数据准备
训练及测试数据集选用Display Advertising Challenge所用的Criteo数据集。该数据集包括两部分:训练集和测试集。训练集包含一段时间内Criteo的部分流量,测试集则对应训练数据后一天的广告点击流量。
每一行数据格式如下所示:
<label> <integer feature 1> ... <integer feature 13> <categorical feature 1> ... <categorical feature 26>
其中<label>表示广告是否被点击,点击用1表示,未点击用0表示。<integer feature>代表数值特征(连续特征),共有13个连续特征。<categorical feature>代表分类特征(离散特征),共有26个离散特征。相邻两个特征用\t分隔,缺失特征用空格表示。测试集中<label>特征已被移除。
基于上述数据集,我们使用了参考repo及原论文给出的数据预处理方法,把原Criteo数据集转换成如下的数据格式:
<label> <feat index 1> ... <feat index 39> <feat value 1> ... <feat value 39>
其中<label>表示广告是否被点击,点击用1表示,未点击用0表示。<feat index>代表特征索引,用于取得连续特征及分类特征对应的embedding。<feat value>代表特征值,对于分类特征,<feat value 14>至<feat value 39>的取值为1,对于连续特征,<feat value 1>至<feat value 13>的取值为连续数值。相邻两个栏位用空格分隔。测试集中<label>特征已被移除。
在模型目录的data目录下为您准备了快速运行的示例数据,若需要使用全量数据可以参考下方效果复现部分。
模型组网
AutoInt模型的组网本质是一个二分类任务,代码参考model.py。模型主要组成是嵌入层(Embedding Layer),交互层(Interacting Layer),输出层(Output Layer)以及相应的分类任务的loss计算和auc计算。
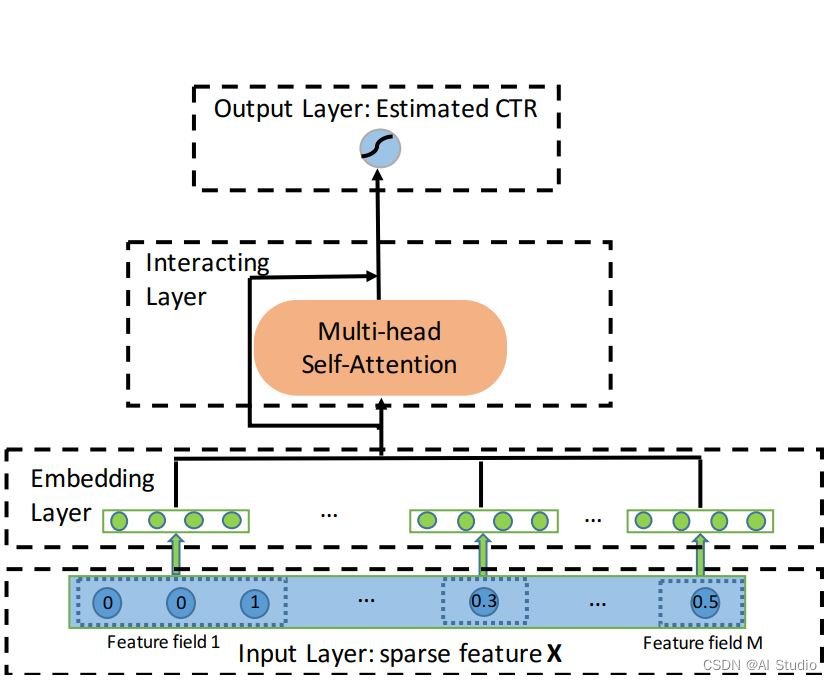
嵌入层(Embedding Layer)
AutoInt首先使用不同的嵌入层将输入的离散数据和连续数据分别映射到同一低维空间。
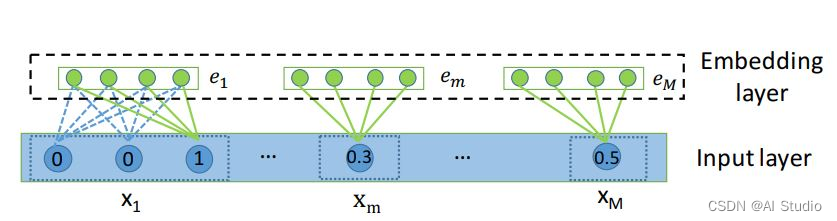
用公式表示如下:
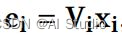
其中 x i \mathbf{x}_{i} xi表示one-hot离散向量, V i \mathbf{V}_{i} Vi是离散量对应的嵌入矩阵, v m \mathbf{v}_{m} vm将连续数据 x m x_{m} xm映射到低维空间。
交互层(Interacting Layer)
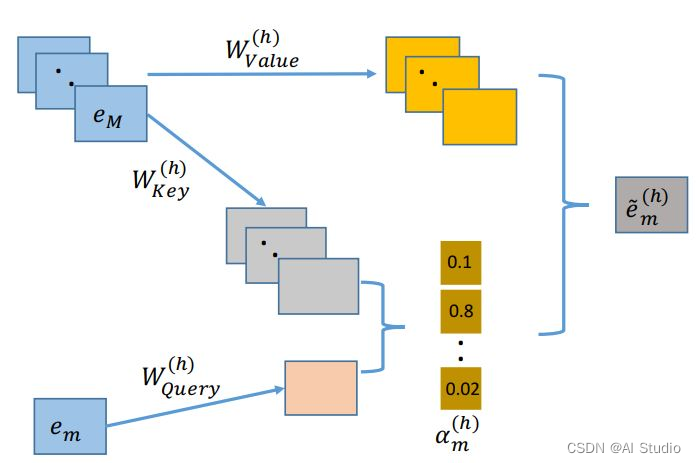
交互层是AutoInt的核心,它使用了Multi-head Self-Attention来构造特征间的高阶组合,具体结构如上图所示。
对于每个从Embedding Layer取得的向量 e m \mathbf{e}_{m} em, 使用不同的注意力函数(Attention Head) Ψ h ( ⋅ , ⋅ ) \Psi^{h}(\cdot,\cdot) Ψh(⋅,⋅)计算向量对 ( e m , e k ) (\mathbf{e}_{m}, \mathbf{e}_{k}) (em,ek)间的相似度 α m , k h \alpha^{h}_{\mathbf{m},\mathbf{k}} αm,kh。
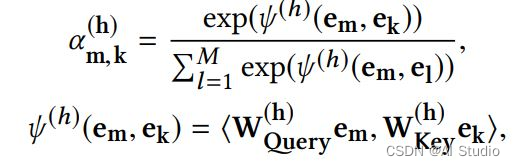
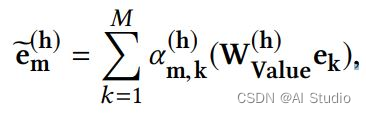
最后把不同注意力函数的输出作拼接,然后使用了残差连接作为Interacting Layer的最终输出。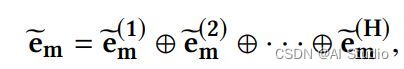
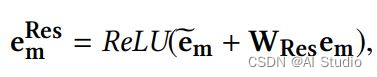
输出层(Output Layer)
输出层把所有在Interacting Layer学到的向量连接其来,然后把它作为fc层的输入,在通过激活函数sigmoid给出预测的点击率。
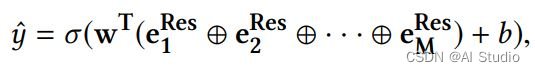
Loss及Auc计算
- 为了得到每条样本分属于正负样本的概率,我们将预测结果和
1-predict合并起来得到predict_2d,以便接下来计算auc。 - 每条样本的损失为负对数损失值,label的数据类型将转化为float输入。
- 该batch的损失
avg_cost是各条样本的损失之和 - 我们同时还会计算预测的auc指标。
运行环境
PaddlePaddle>=2.3
python 3.5/3.6/3.7
os : windows/linux/macos
快速开始
本文提供了样例数据可以供您快速体验,在任意目录下均可执行。在AutoInt模型目录的快速执行命令如下:
cd /home/aistudio/work/PaddleRec/models/rank/autoint
/home/aistudio/work/PaddleRec/models/rank/autoint
# 动态图训练
!python -u ../../../tools/trainer.py -m config.yaml # 全量数据运行config_bigdata.yaml
# 动态图预测
!python -u ../../../tools/infer.py -m config.yaml
# 静态图训练
!python -u ../../../tools/static_trainer.py -m config.yaml # 全量数据运行config_bigdata.yaml
# 静态图预测
!python -u ../../../tools/static_infer.py -m config.yaml
效果复现
为了方便使用者能够快速的跑通每一个模型,我们在每个模型下都提供了样例数据。如果需要复现readme中的效果,请按如下步骤依次操作即可。
在全量数据下模型的指标如下:
| 模型 | auc | batch_size | epoch_num | Time of each epoch |
|---|---|---|---|---|
| AutoInt | 0.80 | 1024 | 3 | 约5小时 |
- 确认您当前所在目录为/home/aistudio/work/PaddleRec/models/rank/autoint
- 进入/home/aistudio/work/PaddleRec/datasets/criteo_autoint目录下,执行该脚本,会从国内源的服务器上下载criteo全量数据集做预处理,并解压到指定文件夹。
cd /home/aistudio/work/PaddleRec/datasets/criteo_autoint
/home/aistudio/work/PaddleRec/datasets/criteo_autoint
!sh run.sh
--2022-08-31 21:39:02-- https://fleet.bj.bcebos.com/ctr_data.tar.gz
Resolving fleet.bj.bcebos.com (fleet.bj.bcebos.com)... 220.181.33.44, 220.181.33.43, 2409:8c04:1001:1002:0:ff:b001:368a
Connecting to fleet.bj.bcebos.com (fleet.bj.bcebos.com)|220.181.33.44|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 4041125592 (3.8G) [application/x-gzip]
Saving to: ‘ctr_data.tar.gz’
ctr_data.tar.gz 23%[===> ] 894.95M 58.6MB/s eta 55s ^C
- 切回模型目录,执行命令运行全量数据
cd /home/aistudio/work/PaddleRec/models/rank/autoint
/home/aistudio/work/PaddleRec/models/rank/autoint
# 动态图训练
!python -u ../../../tools/trainer.py -m config_bigdata.yaml # 全量数据运行config_bigdata.yaml
# 动态图预测
n
# 动态图预测
!python -u ../../../tools/infer.py -m config_bigdata.yaml # 全量数据运行config_bigdata.yaml
复现心得
-
一开始我使用了criteo_dcn_v2数据集,然后参照PaddleRec其他模型的代码以及原论文的pytorch repo实现paddle版本的autoint,训练时我把模型参数设成与原论文5.1.4所述一致,但训练的模型在测试集的AUC一直徘徊在0.80到0.803之间,达不到验收标准。
-
然后我仔细读了一下论文实验设置的部分,发觉有可能是数据的预处理方式不同而导致达不到验收标准。由于pytorch版本的实现没有给出数据的预处理代码,我试着在github上搜一下有没有其他repo,居然找到了原论文作者实现的tensorflow版本有提供数据预处理代码。我按照他提供的代码把原本的ctr数据集转换成数据准备部分所述的格式,然后把模型参数设成与repo提供的例子一致,最终测试集的AUC在0.802~0.804之间。
-
由于还是达不到验收标准,我试着检查paddle模型与tensorflow实现有什么不同,发觉在interacting layer的query, key, value部分没有使用ReLU函数,我试着把它补上。接着我检查了配置文件,发现scaling一直没有开启,而tensorflow版本对相似度 α m , k h \alpha^{h}_{\mathbf{m},\mathbf{k}} αm,kh是默认做scaling处理的。这些修改做完后,测试集的AUC还是没有达到标准。

-
此时我有点怀疑tensorflow版本的例子是否真的有0.80883这么高,我又跑了一下tensorflow的例子,发现AUC也是在0.804到0.805之间游走。由于论文有提到像DeepFM模型那样增加全连接神经网路能进一步提升AUC,因此我在paddle和tensorflow版本都加了3层有400个神经元的全连接网络,最终两者都达到了验收标准。
-
最后,我按照论文5.1.4所述的模型参数在tensorflow和paddle版本下个跑了几次,测试集的AUC只是在0.802~0.804之间,似乎模型的表现与论文所述并不一致,而且模型表现对seed生成的初始化参数比较敏感。
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)