
论文复现赛第6期-SwAV论文复现冠军方案
SwAV是2021NIPS上的一篇关于对比学习的文章。作者提出了一种在线算法 SwAV,它利用对比方法而不需要计算成对比较。此外,作者还提出了一种新颖的数据增强策略Multi-Crop
基于paddle实现的SwAV模型
基于paddle框架的Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
实现
注:本项目根目录在/home/aistudio/work/PASSL下
一、论文解读
本项目使用paddle框架复现SwAV模型。无监督图像表示显着缩小了与有监督预训练的差距,特别是最近对比学习方法的成就。这些对比方法通常在线工作,并且依赖于大量显式的成对特征比较,这在计算上具有挑战性。在本文中,作者提出了一种在线算法 SwAV,它利用对比方法而不需要计算成对比较。具体来说,我们的方法同时对数据进行聚类,同时强制为同一图像的不同增强(或视图)生成的聚类分配之间的一致性,而不是像对比学习中那样直接比较特征。简单地说,我们使用交换预测机制,从另一个视图的表示中预测一个视图的集群分配。该方法可以用大批量和小批量进行训练,并且可以扩展到无限量的数据。与以前的对比方法相比,该方法内存效率更高,因为它不需要大型内存库或特殊的动量网络。此外,作者还提出了一种新的数据增强策略 multi-crop,它使用具有不同分辨率的视图混合来代替两个全分辨率视图,而不会增加内存或计算需求。作者通过使用 ResNet-50 在 ImageNet 上实现 75.3% 的 top-1 准确率来验证他们的发现,并且在所有考虑的下游任务上都超过了监督预训练。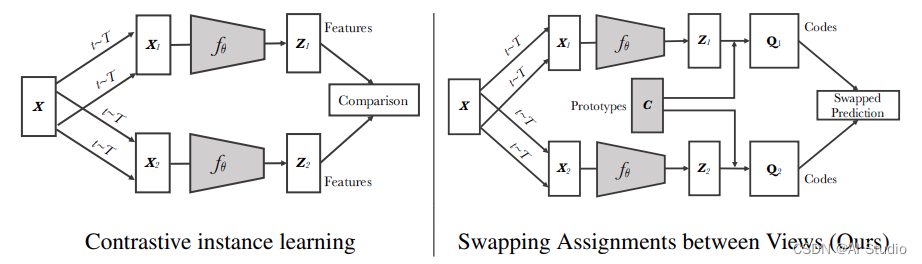
论文:
- [1] Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, Armand Joulin, “Unsupervised Learning of Visual Features by Contrasting Cluster Assignments”, NIPS, 2020.
参考项目:
- SwAV [官方实现]
二、代码复现
2.1 数据集
本项目所使用的数据集为ImageNet2012。该数据集共包含了1000个类别,训练集包含了120W张图像,验证集包含了5W张图像。
# 挂载数据集
tar xf /home/aistudio/.jupyter/lab/workspaces/data/data114241/Light_ILSVRC2012_part_0.tar
tar xf /home/aistudio/.jupyter/lab/workspaces/data/data114746/Light_ILSVRC2012_part_1.tar
2.2 环境依赖
-
硬件:CPU、GPU
-
软件:
- Python 3.7
- PaddlePaddle-GPU == 2.3.0
cd /home/aistudio/work/PASSL/
pip install -r requirements.txt
2.3 模型的创建
import paddle
import paddle.nn as nn
from .builder import MODELS
from ..backbones import build_backbone
from ..necks import build_neck
from ..heads import build_head
@MODELS.register()
class SwAV(nn.Layer):
"""
Build a SwAV model with: a backbone, a neck and a head.
https://arxiv.org/abs/2011.09157
"""
def __init__(self,
backbone,
neck=None,
head=None,
use_synch_bn=True):
super(SwAV, self).__init__()
self.backbone = build_backbone(backbone)
self.neck = build_neck(neck)
self.head = build_head(head)
# Convert BatchNorm*d to SyncBatchNorm*d
if use_synch_bn:
self.backbone = nn.SyncBatchNorm.convert_sync_batchnorm(self.backbone)
self.neck = nn.SyncBatchNorm.convert_sync_batchnorm(self.neck)
def train_iter(self, *inputs, **kwargs):
assert isinstance(inputs, (list, tuple))
# multi-res forward passes
idx_crops = paddle.cumsum(paddle.unique_consecutive(
paddle.to_tensor([inp.shape[-1] for inp in inputs]),
return_counts=True
)[1], 0)
start_idx = 0
output = []
for end_idx in idx_crops:
_out = self.backbone(paddle.concat(inputs[start_idx: end_idx]))
output.append(_out)
start_idx = end_idx
output = self.neck(output)
outputs = self.head(output)
return outputs
def forward(self, *inputs, mode='train', **kwargs):
if mode == 'train':
return self.train_iter(*inputs, **kwargs)
else:
raise Exception("No such mode: {}".format(mode))
2.4 训练
python tools/train.py -c configs/swav/swav_r50_100ep.yaml
class Trainer:
r"""
# trainer calling logic:
#
# build_model || model(BaseModel)
# | ||
# build_dataloader || dataloader
# | ||
# build_lr_scheduler || lr_scheduler
# | ||
# build_optimizer || optimizers
# | ||
# build_train_hooks || train hooks
# | ||
# build_custom_hooks || custom hooks
# | ||
# train loop || train loop
# | ||
# hook(print log, checkpoint, evaluate, ajust lr) || call hook
# | ||
# end \/
"""
def __init__(self, cfg):
# base config
self.logger = logging.getLogger(__name__)
self.cfg = cfg
self.output_dir = cfg.output_dir
dp_rank = dist.get_rank()
self.log_interval = cfg.log_config.interval
# set seed
seed = cfg.get('seed', False)
if seed:
seed += dp_rank
paddle.seed(seed)
np.random.seed(seed)
random.seed(seed)
# set device
assert cfg['device'] in ['cpu', 'gpu', 'xpu', 'npu']
self.device = paddle.set_device(cfg['device'])
self.logger.info('train with paddle {} on {} device'.format(
paddle.__version__, self.device))
self.start_epoch = 0
self.current_epoch = 0
self.current_iter = 0
self.inner_iter = 0
self.batch_id = 0
self.global_steps = 0
use_byol_iters = cfg.get('use_byol_iters', False)
self.use_byol_iters = use_byol_iters
use_simclr_iters = cfg.get('use_simclr_iters', False)
self.use_simclr_iters = use_simclr_iters
self.epochs = cfg.get('epochs', None)
self.timestamp = cfg.timestamp
self.logs = OrderedDict()
# Ensure that the vdl log file can be closed normally
# build model
self.model = build_model(cfg.model)
n_parameters = sum(p.numel() for p in self.model.parameters()
if not p.stop_gradient).item()
i = int(math.log(n_parameters, 10) // 3)
size_unit = ['', 'K', 'M', 'B', 'T', 'Q']
self.logger.info("Number of Parameters is {:.2f}{}.".format(
n_parameters / math.pow(1000, i), size_unit[i]))
# build train dataloader
self.train_dataloader, self.mixup_fn = build_dataloader(
cfg.dataloader.train, self.device)
self.iters_per_epoch = len(self.train_dataloader)
# use byol iters
if self.use_byol_iters:
self.global_batch_size = cfg.global_batch_size
self.byol_total_iters = self.epochs * cfg.total_images // self.global_batch_size
if self.use_byol_iters:
self.lr_scheduler = build_lr_scheduler(cfg.lr_scheduler,
self.byol_total_iters)
elif self.use_simclr_iters:
self.batch_size = cfg.dataloader.train.sampler.batch_size
self.global_batch_size = cfg.global_batch_size
self.epochs = cfg.epochs
self.lr_scheduler = build_lr_scheduler_simclr(
cfg.lr_scheduler, self.iters_per_epoch, self.batch_size * 8,
cfg.epochs, self.current_iter)
else:
self.lr_scheduler = build_lr_scheduler(cfg.lr_scheduler,
self.iters_per_epoch)
self.optimizer = build_optimizer(cfg.optimizer, self.lr_scheduler,
[self.model])
# distributed settings
if dist.get_world_size() > 1:
strategy = fleet.DistributedStrategy()
## Hybrid Parallel Training
strategy.hybrid_configs = cfg.pop(
'hybrid') if 'hybrid' in cfg else {}
fleet.init(is_collective=True, strategy=strategy)
hcg = fleet.get_hybrid_communicate_group()
mp_rank = hcg.get_model_parallel_rank()
pp_rank = hcg.get_stage_id()
dp_rank = hcg.get_data_parallel_rank()
set_hyrbid_parallel_seed(
seed, 0, mp_rank, pp_rank, device=self.device)
# amp training
self.use_amp = cfg.get('use_amp',
False) #if 'use_amp' in cfg else False
if self.use_amp:
amp_cfg = cfg.pop('AMP')
self.auto_cast = amp_cfg.pop('auto_cast')
scale_loss = amp_cfg.pop('scale_loss')
self.scaler = paddle.amp.GradScaler(init_loss_scaling=scale_loss)
amp_cfg['models'] = self.model
self.model = paddle.amp.decorate(**amp_cfg) # decorate for level O2
# ZeRO
self.sharding_strategies = cfg.get('sharding', False)
if self.sharding_strategies:
from paddle.distributed.fleet.meta_parallel.sharding.sharding_utils import ShardingScaler
from paddle.distributed.fleet.meta_parallel.sharding.sharding_stage2 import ShardingStage2
from paddle.distributed.fleet.meta_optimizers.dygraph_optimizer.sharding_optimizer_stage2 import ShardingOptimizerStage2
self.sharding_stage = self.sharding_strategies['sharding_stage']
accumulate_grad = self.sharding_strategies['accumulate_grad']
offload = self.sharding_strategies['offload']
if self.sharding_stage == 2:
self.optimizer = ShardingOptimizerStage2(
params=self.model.parameters(),
optim=self.optimizer,
offload=offload)
self.model = ShardingStage2(
self.model,
self.optimizer,
accumulate_grads=accumulate_grad)
self.scaler = ShardingScaler(self.scaler)
else:
raise NotImplementedError()
# data parallel
elif dist.get_world_size() > 1:
self.model = fleet.distributed_model(self.model)
# build hooks
self.hooks = []
self.add_train_hooks()
self.add_custom_hooks()
self.hooks = sorted(self.hooks, key=lambda x: x.priority)
if self.epochs:
self.total_iters = self.epochs * self.iters_per_epoch
self.by_epoch = True
else:
self.by_epoch = False
self.total_iters = cfg.total_iters
def add_train_hooks(self):
optim_cfg = self.cfg.get('optimizer_config', None)
if optim_cfg is not None:
self.add_hook(build_hook(optim_cfg))
else:
self.add_hook(build_hook({'name': 'OptimizerHook'}))
timer_cfg = self.cfg.get('timer_config', None)
if timer_cfg is not None:
self.add_hook(build_hook(timer_cfg))
else:
self.add_hook(build_hook({'name': 'IterTimerHook'}))
ckpt_cfg = self.cfg.get('checkpoint', None)
if ckpt_cfg is not None:
self.add_hook(build_hook(ckpt_cfg))
else:
self.add_hook(build_hook({'name': 'CheckpointHook'}))
log_cfg = self.cfg.get('log_config', None)
if log_cfg is not None:
self.add_hook(build_hook(log_cfg))
else:
self.add_hook(build_hook({'name': 'LogHook'}))
lr_cfg = self.cfg.get('lr_config', None)
if lr_cfg is not None:
self.add_hook(build_hook(lr_cfg))
else:
self.add_hook(build_hook({'name': 'LRSchedulerHook'}))
def add_custom_hooks(self):
custom_cfgs = self.cfg.get('custom_config', None)
if custom_cfgs is None:
return
for custom_cfg in custom_cfgs:
cfg_ = custom_cfg.copy()
insert_index = cfg_.pop('insert_index', None)
self.add_hook(build_hook(cfg_), insert_index)
def add_hook(self, hook, insert_index=None):
assert isinstance(hook, Hook)
if insert_index is None:
self.hooks.append(hook)
elif isinstance(insert_index, int):
self.hooks.insert(insert_index, hook)
def call_hook(self, fn_name):
for hook in self.hooks:
getattr(hook, fn_name)(self)
def train(self):
self.mode = 'train'
self.model.train()
iter_loader = IterLoader(self.train_dataloader, self.current_epoch)
self.call_hook('run_begin')
while self.current_iter < (self.total_iters):
if self.current_iter % self.iters_per_epoch == 0:
self.call_hook('train_epoch_begin')
self.inner_iter = self.current_iter % self.iters_per_epoch
self.current_iter += 1
self.current_epoch = iter_loader.epoch
data = next(iter_loader)
self.call_hook('train_iter_begin')
if self.use_amp:
with paddle.amp.auto_cast(**self.auto_cast):
if self.use_byol_iters:
self.outputs = self.model(
*data,
total_iters=self.byol_total_iters,
current_iter=self.current_iter,
mixup_fn=self.mixup_fn)
else:
self.outputs = self.model(
*data,
total_iters=self.total_iters,
current_iter=self.current_iter,
mixup_fn=self.mixup_fn)
else:
if self.use_byol_iters:
self.outputs = self.model(
*data,
total_iters=self.byol_total_iters,
current_iter=self.current_iter,
mixup_fn=self.mixup_fn)
else:
self.outputs = self.model(
*data,
total_iters=self.total_iters,
current_iter=self.current_iter,
mixup_fn=self.mixup_fn)
self.call_hook('train_iter_end')
if self.current_iter % self.iters_per_epoch == 0:
self.call_hook('train_epoch_end')
self.current_epoch += 1
self.call_hook('run_end')
2.5 验证
python tools/train.py -c configs/swav/swav_clas_r50.yaml --load ${CLS_WEGHT_FILE} --evaluate-only
def val(self, **kargs):
if not hasattr(self, 'val_dataloader'):
self.val_dataloader, mixup_fn = build_dataloader(
self.cfg.dataloader.val, self.device)
self.logger.info('start evaluate on epoch {} ..'.format(
self.current_epoch + 1))
rank = dist.get_rank()
world_size = dist.get_world_size()
model = self.model
total_samples = len(self.val_dataloader.dataset)
self.logger.info('Evaluate total samples {}'.format(total_samples))
if rank == 0:
dataloader = tqdm(self.val_dataloader)
else:
dataloader = self.val_dataloader
accum_samples = 0
self.model.eval()
outs = OrderedDict()
for data in dataloader:
if isinstance(data, paddle.Tensor):
batch_size = data.shape[0]
elif isinstance(data, (list, tuple)):
batch_size = data[0].shape[0]
else:
raise TypeError('unknown type of data')
labels = data[-1]
if self.use_amp:
with paddle.amp.auto_cast(**self.auto_cast):
pred = model(*data, mode='test')
else:
pred = model(*data, mode='test')
current_samples = batch_size * world_size
accum_samples += current_samples
# for k, v in outputs.items():
if world_size > 1:
pred_list = []
dist.all_gather(pred_list, pred)
pred = paddle.concat(pred_list, 0)
label_list = []
dist.all_gather(label_list, labels)
labels = paddle.concat(label_list, 0)
if accum_samples > total_samples:
self.logger.info('total samples {} {} {}'.format(
total_samples, accum_samples, total_samples +
current_samples - accum_samples))
pred = pred[:total_samples + current_samples -
accum_samples]
labels = labels[:total_samples + current_samples -
accum_samples]
current_samples = total_samples + current_samples - accum_samples
res = self.val_dataloader.dataset.evaluate(pred, labels, **kargs)
for k, v in res.items():
if k not in outs:
outs[k] = AverageMeter(k, ':6.3f')
outs[k].update(float(v), current_samples)
log_str = f'Validate Epoch [{self.current_epoch + 1}] '
log_items = []
for name, val in outs.items():
if isinstance(val, AverageMeter):
string = '{} ({' + outs[k].fmt + '})'
val = string.format(val.name, val.avg)
log_items.append(val)
log_str += ', '.join(log_items)
self.logger.info(log_str)
self.model.train()
2.6 复现结果
本项目验证其在图像分类下游任务中的性能,所使用的数据集为ImageNet2012,复现精度如下:
| Model | Official | Passl |
|---|---|---|
| SwAV | 72.1 | 72.4 |
三、参考资料
- https://github.com/facebookresearch/swav
四、总结
- SwAV的训练有variance,不同的随机种子得到的最终结果可能有0.5左右的误差。
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)