
2022 CCF BDCI 小样本数据分类任务Baseline
2022 CCF BDCI 小样本数据分类任务-Baseline,基线得分0.5005
2022 CCF BDCI 小样本数据分类任务Baseline
赛事地址:https://www.datafountain.cn/competitions/582 👈
赛题合作:智慧芽信息科技(苏州)有限公司(智慧芽)
赛题背景
创新是国家发展、民族复兴的不竭动力。近年来,随着政策扶植、国家工业化水平和国民教育水平提高,我国的专利申请量快速增长,专利检索、查新、管理等需求也不断增加。为了满足以上需求,提升专利服务质量,通常需要建立多个维度的专利分类体系。常见的分类体系有国际专利分类(IPC)、联合专利分类(CPC)、欧洲专利分类(ECLA)等,但是这些分类体系比较复杂,专业性强,对非IP人员而言使用有一定的困难。智慧芽作为国际领先的知识产权SaaS平台,根据用户的搜索习惯等因素,制定了一套新的专利分类体系,从而提升用户的使用体验。
赛题任务
比赛方公开958条专利数据,包括专利权人、专利标题、专利摘要和分类标签,其中分类标签经过脱敏处理,共36类。要求选手设计一套算法,完成测试数据的分类任务。
本次赛题公布的训练数据量较小,属于基于小样本训练数据的分类任务。小样本分类任务作为近年来研究的热点问题,学界提出了远程监督、数据增强、预训练模型、PET范式等方案。希望选手充分发挥创造力,将学界的研究成果落地到本赛题中来。
Baseline流程
本任务是 NLP 最经典的任务类型之—文本分类,本案例首先简单分析了赛题数据的特点,并介绍如何使用paddle准备输入到模型的数据,然后基于 ERNIE3.0模型搭建文本分类网络,使用交叉熵损失函数和R-drop Loss,快速进行小样本文本分类模型的训练、评估和预测。
针对小样本文本分类存在的问题,引入两种方法进一步提高模型的鲁棒性:
- 赛题存在训练数据量过少的难点,借助paddleNLP中的数据增强(EDA)模块,使用了同义词替换文本中的词组生成更多的训练数据,并重新采样数据增强后的文本,使得各类别标签相对平衡。
- 使用R-Drop,本质上来说,R-Drop与MixUp、Manifold-MixUp和Adversarial Training(对抗训练)一样,都是一种数据增强方法,在小样本学习场景中用的非常多,也十分有效。参考资料:https://zhuanlan.zhihu.com/p/419806443
提交分数
| model | 线下 | 线上 |
|---|---|---|
| base | 0.487417 | 待更新 |
| base + R-Drop | 0.492535 | 0.500500457520 |
| base + 数据增强 | 0.481028 | 待更新 |
Baseline+R-Drop上线分数:0.50050045752
注:对于baseline中数据增强效果欠佳,而R-drop有效的猜测如下
首先,数据增强方法主要有样本增强和Embedding增强。NLP领域中,数据增强的目的是在不改变语义的前提下扩充文本数据。主要的方法包括简单文本替换、使用语言模型生成相似句子等,本baseline中使用词级别替换,但是一个词的变化就可能导致整个句子的意思发生翻转,经过替换的文本携带大量噪音,所以很难用简单的规则样本变化产生足够的增强数据。后续需要挖掘更合理的EDA姿势。
而R-drop属于Embedding增强,则不再对输入进行操作,转而在Embedding层面进行操作,可以通过对Embedding增加扰动或者插值等方式提升模型的鲁棒性。此外,后续也可以试试其他Embedding增强方法,例如Mixup、Manifold-Mixup、对抗训练(Adversarial training, AT) 。
Baseline 方案
# 首先通过如下命令将paddlenlp更新至最新版本
!pip install -U paddlenlp
import os
import json
import random
import time
import numpy as np
import pandas as pd
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
import paddle
import paddlenlp
import paddle.nn.functional as F
from functools import partial
from paddlenlp.data import Stack, Dict, Pad
from paddlenlp.datasets import load_dataset
import paddle.nn as nn
import matplotlib.pyplot as plt
import seaborn as sns
from paddlenlp.transformers.auto.tokenizer import AutoTokenizer
seed = 2022
paddle.seed(seed)
random.seed(seed)
np.random.seed(seed)
# 超参数
MODEL_NAME = 'ernie-3.0-base-zh'
# 设置最大阶段长度 和 batch_size
max_seq_length = 365
train_batch_size = 16
valid_batch_size = 16
test_batch_size = 16
# 训练过程中的最大学习率
learning_rate = 8e-5
# 训练轮次
epochs = 50
# 学习率预热比例
warmup_proportion = 0.1
# 权重衰减系数,类似模型正则项策略,避免模型过拟合
weight_decay = 0.01
max_grad_norm = 1.0
# 提交文件名称
sumbit_name = "work/sumbit.csv"
model_logging_dir = 'work/model_logging.csv'
early_stopping = 10
# 是否使用数据增强
enable_dataaug = False
# 是否开启对抗训练
enable_adversarial = False
# Rdrop Loss的超参数,若该值大于0.则加权使用R-drop loss
rdrop_coef = 0.1
# 训练结束后,存储模型参数
save_dir_curr = "checkpoint/{}-{}".format(MODEL_NAME.replace('/','-'),int(time.time()))
1 数据读取和EDA
1.1 读取数据并统一格式
def read_jsonfile(file_name):
data = []
with open(file_name) as f:
for i in f.readlines():
data.append(json.loads(i))
return data
train = pd.DataFrame(read_jsonfile("./data/data167177/train.json"))
test = pd.DataFrame(read_jsonfile("./data/data167177//testA.json"))
print("train size: {} \ntest size {}".format(len(train),len(test)))
train size: 958
test size 20839
train.head(3)
| id | title | assignee | abstract | label_id | |
|---|---|---|---|---|---|
| 0 | 538f267d2e6fba48b1286fb7f1499fe7 | 一种信号的发送方法及基站、用户设备 | 华为技术有限公司 | 一种信号的发送方法及基站、用户设备。在一个子帧中为多个用户设备配置的参考信号的符号和数据的符... | 0 |
| 1 | 635a7d4b6358b6ff24a324bb871505db | 一种5G通讯电缆故障监控系统 | 中铁二十二局集团电气化工程有限公司 | 本发明公开了一种5G通讯电缆故障监控系统,包括信号采样模块、补偿反馈模块,所述信号采样模块对... | 0 |
| 2 | aaf98d6bfe1932cf1a262812ca59d1ba | 一种测试方法及电子设备 | 腾讯科技(北京)有限公司 | 本发明提供了一种测试方法及电子设备,该方法包括:基于选取的测试任务确定目标测试用例,根据所述... | 0 |
train['text'] = [row['title'] + ',' + row['assignee'] + ',' + row['abstract'] for idx,row in train.iterrows()]
test['text'] = [row['title'] + ',' + row['assignee'] + ',' + row['abstract'] for idx,row in test.iterrows()]
train['concat_len'] = [len(row) for row in train['text']]
test['concat_len'] = [len(row) for row in test['text']]
1.2 简易数据分析
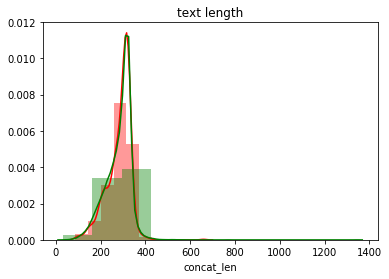
# 拼接后的文本长度分析
for rate in [0.5,0.75,0.9,0.95,0.99]:
print("训练数据中{:.0f}%的文本长度小于等于 {:.2f}".format(rate*100,train['concat_len'].quantile(rate)))
plt.title("text length")
sns.distplot(train['concat_len'],bins=10,color='r')
sns.distplot(test['concat_len'],bins=10,color='g')
plt.show()
训练数据中50%的文本长度小于等于 299.00
训练数据中75%的文本长度小于等于 319.00
训练数据中90%的文本长度小于等于 331.00
训练数据中95%的文本长度小于等于 338.00
训练数据中99%的文本长度小于等于 373.29
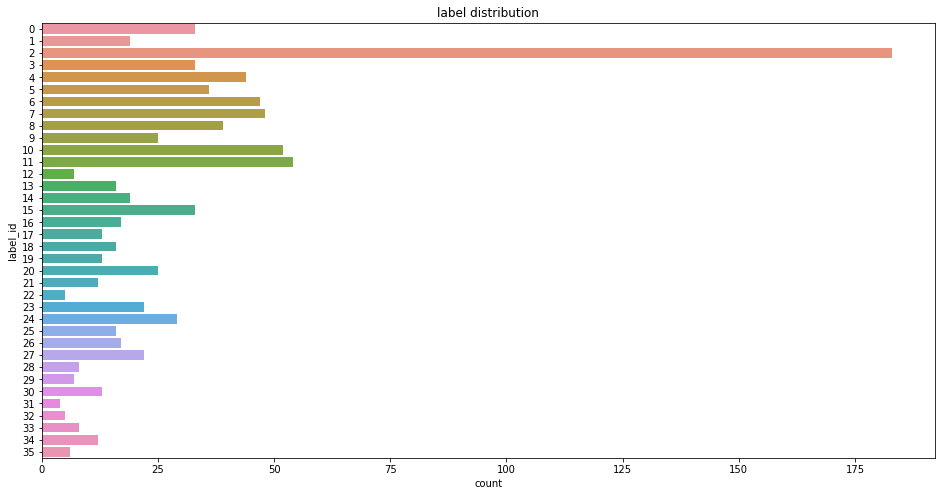
train_label = train["label_id"].unique()
# 查看标签label分布
plt.figure(figsize=(16,8))
plt.title("label distribution")
sns.countplot(y='label_id',data=train)
<matplotlib.axes._subplots.AxesSubplot at 0x7f6f96624350>
1.3 结论
- 训练集共958条,测试集共20839条。
- 拼接所有字段后的文本长度大多数集中在300左右,仅有极少数文本超过400。
- 共有36个标签,标签分布呈现极度不平衡状态,大部分标签类别的标注样本不超过50条。
2 数据处理
2.1 数据划分
# 划分数据集
# 使用留一法划分数据集,训练集:验证集 = 5:1 ,注意这里random_state选择了5,是为了保证36各标签均会出现在训练集和测试集中,某些seed可能会使得验证集的标签不足36个
train_data,valid_data = train_test_split(train,test_size=0.1667,random_state=5)
print("train size: {} \nvalid size {}".format(len(train_data),len(valid_data)))
print("train label: ",sorted(train_data["label_id"].unique()))
print("train label: ",sorted(valid_data["label_id"].unique()))
train size: 798
valid size 160
train label: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35]
train label: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35]
2.2 数据增强
PaddleNLP 数据增强教程文档:https://github.com/PaddlePaddle/PaddleNLP/blob/00a3551f7b9359ea6fe0226b34746e8b91605afb/docs/dataaug.md
目前,PaddleNLP仅支持词级别数据增强策略,本方案使用基于TF-IDF和同义词替换作为数据增强的方法
基于TF-IDF的词替换
TF-IDF算法认为如果一个词在同一个句子中出现的次数多,词对句子的重要性就会增加;如果它在语料库中出现频率越高,它的重要性将被降低。我们将计算每个词的TF-IDF分数,低的TF-IDF得分将有很高的概率被替换。
我们可以在上面所有词替换策略中使用TF-IDF计算词被替换的概率,我们首先需要将tf_idf设为True,并传入语料库文件(包含所有训练的数据) tf_idf_file 用于计算单词的TF-IDF分数。语料库文件为固定 txt 格式,每一行为一条句子。以语料库文件"data.txt"做同义词替换为例,语料库文件格式如下:
人类语言是抽象的信息符号,其中蕴含着丰富的语义信息,人类可以很轻松地理解其中的含义。
而计算机只能处理数值化的信息,无法直接理解人类语言,所以需要将人类语言进行数值化转换。
tf_idf_file = "data.txt"
aug = WordSubstitute('synonym', tf_idf=True, tf_idf_file=tf_idf_file, create_n=1, aug_n=1)
augmented = aug.augment(s1)
print("origin:", s1)
print("augmented:", augmented[0])
'''
origin: 人类语言是抽象的信息符号,其中蕴含着丰富的语义信息,人类可以很轻松地理解其中的含义。
augmented: 人类语言是抽象的信息符号,其中蕴含着丰富的语义信息,人类可以很轻松地理解其中的意思。
'''
可以根据的实际需求,修改数据增强生成句子数 create_n和句子中被替换的词数量 aug_n
from paddlenlp.dataaug import WordSubstitute
if enable_dataaug:
with open("work/data.txt","w") as f:
for i in train['text']:
f.write(i+'\n')
for i in test['text']:
f.write(i+'\n')
random.seed(seed)
np.random.seed(seed)
tf_idf_file = "work/data.txt"
aug = WordSubstitute('synonym',
tf_idf=True, # 使用tf-idf
tf_idf_file=tf_idf_file,
create_n=30, # 生成增强数据的个数
aug_percent=0.15 # 数据增强句子中被替换词数量占全句词比例
)
# 为指定的label生成增强数据
def data_aug_sample(label_id,data,aug):
aug_sample = []
sample = data[data['label_id']==label_id]
for pre_aug_sample in aug.augment(sample['text']):
aug_sample.extend(pre_aug_sample)
return pd.DataFrame({"text":aug_sample,"label_id":[label_id]*len(aug_sample)})
# 设置每个标签的数据条数
upper_limit = 180
# 根据统计信息生成增强数据和采样增强数据
label_id_indexs = train["label_id"].value_counts().index
label_id_nums = train["label_id"].value_counts().values
for label_id,value in zip(label_id_indexs,label_id_nums):
if value < upper_limit:
# 计算采样数量
sample_nums = upper_limit-value
# 获得增强数据
label_aug_data = data_aug_sample(data=train_data,label_id=label_id,aug=aug)
# 如果增强数据的总条数,小于采样数量,将采样数量变为当前增强数据的总条数
if len(label_aug_data) < sample_nums:
sample_nums = len(label_aug_data)
# 采样增强数据
label_aug_data = label_aug_data.sample(n=sample_nums,random_state=0)
# 合并到训练集
train_data = pd.concat((train_data,label_aug_data),axis=0)
# 重置index
train_data = train_data.reset_index(drop=True)
print("train size: {} \nvalid size {}".format(len(train_data),len(valid_data)))
2.3 数据编码
# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
# 创建数据迭代器iter
def read(df,istrain=True):
if istrain:
for idx,data in df.iterrows():
yield {
"words":data['text'],
"labels":data['label_id']
}
else:
for idx,data in df.iterrows():
yield {
"words":data['text'],
}
# 将生成器传入load_dataset
train_ds = load_dataset(read, df=train_data, lazy=False)
valid_ds = load_dataset(read, df=valid_data, lazy=False)
# 查看数据
for idx in range(1,3):
print(train_ds[idx])
print("==="*30)
{'words': '一种混凝土传送料斗,玉田县森源混凝土搅拌有限公司,本实用新型公开了一种混凝土传送料斗,涉及混凝土制备的技术领域,包括料斗本体,所述料斗本体的内侧壁上连接有防撞衬板。解决了搅拌机构内的混凝土落至料斗本体内的过程中,混凝土中的骨料会与料斗本体发生撞击,从而使得料斗本体的使用寿命降低。本实用新型具有料斗本体使用寿命较高的效果。', 'labels': 2}
==========================================================================================
{'words': '一种智慧农业全天候污染物无人机三维测量方法,中南大学,本发明公开了一种智慧农业全天候污染物无人机三维测量方法,属于污染监控技术领域,本发明提出了在目标农作物种植区域内利用均匀分布的无人机自主升降的方法对该区域内的水源、土壤、大气和夜间光照四种自然因素所包含的主要污染物浓度进行随高度变化的实时离散点采样,在一定程度上保证了测量过程的时效性和准确性,避免了不同子区域污染物浓度随高度变化或地域变化的随机性和偶然性,有利于农业种植的智能化管控;本发明方法能够优化农作物种植区域关于污染物浓度管控与决策的有效资源配置,为农作物在多污染源安全浓度环境下健康生长提供保证,助推智慧农业稳健发展。', 'labels': 7}
==========================================================================================
# 编码
def convert_example(example, tokenizer, max_seq_len=512, mode='train'):
# 调用tokenizer的数据处理方法把文本转为id
tokenized_input = tokenizer(example['words'],is_split_into_words=True,max_seq_len=max_seq_len)
if mode == "test":
return tokenized_input
# 把意图标签转为数字id
tokenized_input['labels'] = [example['labels']]
return tokenized_input # 字典形式,包含input_ids、token_type_ids、labels
train_trans_func = partial(
convert_example,
tokenizer=tokenizer,
mode='train',
max_seq_len=max_seq_length)
valid_trans_func = partial(
convert_example,
tokenizer=tokenizer,
mode='dev',
max_seq_len=max_seq_length)
# 映射编码
train_ds.map(train_trans_func, lazy=False)
valid_ds.map(valid_trans_func, lazy=False)
# 初始化BatchSampler
train_batch_sampler = paddle.io.BatchSampler(train_ds, batch_size=train_batch_size, shuffle=True)
valid_batch_sampler = paddle.io.BatchSampler(valid_ds, batch_size=valid_batch_size, shuffle=False)
# print("校准数据是否被seed固定")
# print([*train_batch_sampler][0])
# print([585, 407, 408, 535, 631, 93, 534, 422, 570, 648, 221, 518, 434, 788, 536, 113])
# 定义batchify_fn
batchify_fn = lambda samples, fn = Dict({
"input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id),
"token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
"labels": Stack(dtype="int32"),
}): fn(samples)
# 初始化DataLoader
train_data_loader = paddle.io.DataLoader(
dataset=train_ds,
batch_sampler=train_batch_sampler,
collate_fn=batchify_fn,
return_list=True)
valid_data_loader = paddle.io.DataLoader(
dataset=valid_ds,
batch_sampler=valid_batch_sampler,
collate_fn=batchify_fn,
return_list=True)
# 相同方式构造测试集
test_ds = load_dataset(read,df=test, istrain=False, lazy=False)
test_trans_func = partial(
convert_example,
tokenizer=tokenizer,
mode='test',
max_seq_len=max_seq_length)
test_ds.map(test_trans_func, lazy=False)
test_batch_sampler = paddle.io.BatchSampler(test_ds, batch_size=test_batch_size, shuffle=False)
test_batchify_fn = lambda samples, fn = Dict({
"input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id),
"token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
}): fn(samples)
test_data_loader = paddle.io.DataLoader(
dataset=test_ds,
batch_sampler=test_batch_sampler,
collate_fn=test_batchify_fn,
return_list=True)
3 模型搭建
预训练模型 + 全连接层
from paddlenlp.transformers.ernie.modeling import ErniePretrainedModel,ErnieForSequenceClassification
class CCFFSLModel(ErniePretrainedModel):
def __init__(self, ernie, num_classes=2, dropout=None):
super(CCFFSLModel,self).__init__()
self.ernie = ernie # allow ernie to be config
self.dropout = nn.Dropout(dropout if dropout is not None else self.ernie.config["hidden_dropout_prob"])
self.classifier = nn.Linear(self.ernie.config["hidden_size"],num_classes)
self.apply(self.init_weights)
def forward(self,
input_ids,
token_type_ids=None,
position_ids=None,
attention_mask=None):
_, pooled_output = self.ernie(input_ids,
token_type_ids=token_type_ids,
position_ids=position_ids,
attention_mask=attention_mask)
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
return logits
# 创建model
label_classes = train['label_id'].unique()
model = CCFFSLModel.from_pretrained(MODEL_NAME,num_classes=len(label_classes))
# model = ErnieForSequenceClassification.from_pretrained(MODEL_NAME,num_classes=len(label_classes))
[2022-09-02 23:26:15,344] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie-3.0-base-zh/ernie_3.0_base_zh.pdparams
W0902 23:26:15.347844 25924 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0902 23:26:15.354897 25924 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
4 模型配置
# 训练总步数
num_training_steps = len(train_data_loader) * epochs
# 学习率衰减策略
lr_scheduler = paddlenlp.transformers.LinearDecayWithWarmup(learning_rate, num_training_steps,warmup_proportion)
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
# 定义优化器
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params,
grad_clip=paddle.nn.ClipGradByGlobalNorm(max_grad_norm))
# utils - 对抗训练 FGM
class FGM(object):
"""
Fast Gradient Method(FGM)
针对 embedding 层梯度上升干扰的对抗训练方法
"""
def __init__(self, model, epsilon=1., emb_name='emb'):
# emb_name 这个参数要换成你模型中embedding 的参数名
self.model = model
self.epsilon = epsilon
self.emb_name = emb_name
self.backup = {}
def attack(self):
for name, param in self.model.named_parameters():
if not param.stop_gradient and self.emb_name in name: # 检验参数是否可训练及范围
self.backup[name] = param.numpy() # 备份原有参数值
grad_tensor = paddle.to_tensor(param.grad) # param.grad 是个 numpy 对象
norm = paddle.norm(grad_tensor) # norm 化
if norm != 0:
r_at = self.epsilon * grad_tensor / norm
param.add(r_at) # 在原有 embed 值上添加向上梯度干扰
def restore(self):
for name, param in self.model.named_parameters():
if not param.stop_gradient and self.emb_name in name:
assert name in self.backup
param.set_value(self.backup[name]) # 将原有 embed 参数还原
self.backup = {}
# 对抗训练
if enable_adversarial:
adv = FGM(model=model,epsilon=1e-6,emb_name='word_embeddings')
5 模型训练
# 验证部分
@paddle.no_grad()
def evaluation(model, data_loader):
model.eval()
real_s = []
pred_s = []
for batch in data_loader:
input_ids, token_type_ids, labels = batch
logits = model(input_ids, token_type_ids)
probs = F.softmax(logits,axis=1)
pred_s.extend(probs.argmax(axis=1).numpy())
real_s.extend(labels.reshape([-1]).numpy())
score = f1_score(y_pred=pred_s,y_true=real_s,average="macro")
return score
# 训练阶段
def do_train(model,data_loader):
print("train ...")
total_loss = 0.
model_total_epochs = 0
best_score = 0.
num_early_stopping = 0
if rdrop_coef > 0:
rdrop_loss = paddlenlp.losses.RDropLoss()
# 训练
train_time = time.time()
valid_time = time.time()
model.train()
for epoch in range(0, epochs):
preds,reals = [],[]
for step, batch in enumerate(data_loader, start=1):
input_ids, token_type_ids, labels = batch
logits = model(input_ids, token_type_ids)
# 使用R-drop
if rdrop_coef > 0:
logits_2 = model(input_ids=input_ids, token_type_ids=token_type_ids)
ce_loss = (F.softmax_with_cross_entropy(logits,labels).mean() + F.softmax_with_cross_entropy(logits,labels).mean()) * 0.5
kl_loss = rdrop_loss(logits, logits_2)
loss = ce_loss + kl_loss * rdrop_coef
else:
loss = F.softmax_with_cross_entropy(logits,labels).mean()
loss.backward()
# 对抗训练
if enable_adversarial:
adv.attack() # 在 embedding 上添加对抗扰动
adv_logits = model(input_ids, token_type_ids)
adv_loss = F.softmax_with_cross_entropy(adv_logits,labels).mean()
adv_loss.backward() # 反向传播,并在正常的 grad 基础上,累加对抗训练的梯度
adv.restore() # 恢复 embedding 参数
total_loss += loss.numpy()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
model_total_epochs += 1
# probs = F.softmax(logits,axis=1)
# preds.extend(probs.argmax(axis=1))
# reals.extend(labels.reshape([-1]))
# train_f1 = f1_score(y_pred=preds,y_true=reals,average="macro")
# print("train f1: %.5f training loss: %.5f speed %.1f s" % (train_f1, total_loss/model_total_epochs,(time.time() - train_time)))
# train_time = time.time()
eval_score = evaluation(model, valid_data_loader)
print("【%.2f%%】validation speed %.2f s" % (model_total_epochs/num_training_steps*100,time.time() - valid_time))
valid_time = time.time()
if best_score < eval_score:
num_early_stopping = 0
print("eval f1: %.5f f1 update %.5f ---> %.5f " % (eval_score,best_score,eval_score))
best_score = eval_score
# 只在score高于0.6的时候保存模型
if best_score > 0.45:
# 保存模型
os.makedirs(save_dir_curr,exist_ok=True)
save_param_path = os.path.join(save_dir_curr, 'model_best.pdparams')
paddle.save(model.state_dict(), save_param_path)
# 保存tokenizer
tokenizer.save_pretrained(save_dir_curr)
else:
num_early_stopping = num_early_stopping + 1
print("eval f1: %.5f but best f1 %.5f early_stoping_num %d" % (eval_score,best_score,num_early_stopping))
model.train()
if num_early_stopping >= early_stopping:
break
return best_score
best_score = do_train(model,train_data_loader)
print("best f1 score: %.5f" % best_score)
best f1 score: 0.48742
# logging part
logging_dir = 'work/sumbit'
os.makedirs(logging_dir,exist_ok=True)
logging_name = os.path.join(logging_dir,'run_logging.csv')
os.makedirs(logging_dir,exist_ok=True)
var = [MODEL_NAME, seed, learning_rate, max_seq_length, enable_dataaug, enable_adversarial, rdrop_coef, best_score, save_dir_curr]
names = ['model', 'seed', 'lr', "max_len" , 'enable_dataaug', 'enable_adversarial', 'rdrop_coef','best_score','save_mode_name']
vars_dict = {k: v for k, v in zip(names, var)}
results = dict(**vars_dict)
keys = list(results.keys())
values = list(results.values())
if not os.path.exists(logging_name):
ori = []
ori.append(values)
logging_df = pd.DataFrame(ori, columns=keys)
logging_df.to_csv(logging_name, index=False)
else:
logging_df= pd.read_csv(logging_name)
new = pd.DataFrame(results, index=[1])
logging_df = logging_df.append(new, ignore_index=True)
logging_df.to_csv(logging_name, index=False)
logging_df.tail(10)
| model | seed | lr | max_len | enable_dataaug | enable_adversarial | rdrop_coef | best_score | save_mode_name | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | ernie-3.0-base-zh | 2022 | 0.00008 | 365 | True | False | 0.0 | 0.481028 | checkpoint/ernie-3.0-base-zh-1662124542 |
| 1 | ernie-3.0-base-zh | 2022 | 0.00008 | 365 | False | False | 0.6 | 0.477655 | checkpoint/ernie-3.0-base-zh-1662128851 |
| 2 | ernie-3.0-base-zh | 2022 | 0.00008 | 365 | False | False | 0.1 | 0.492535 | checkpoint/ernie-3.0-base-zh-1662129718 |
| 3 | ernie-3.0-base-zh | 2022 | 0.00008 | 365 | False | False | 0.0 | 0.487417 | checkpoint/ernie-3.0-base-zh-1662132318 |
6 模型预测
# 预测阶段
def do_sample_predict(model,data_loader,is_prob=False):
model.eval()
preds = []
for batch in data_loader:
input_ids, token_type_ids= batch
logits = model(input_ids, token_type_ids)
probs = F.softmax(logits,axis=1)
preds.extend(probs.argmax(axis=1).numpy())
if is_prob:
return probs
return preds
# 读取最佳模型
state_dict = paddle.load(os.path.join(save_dir_curr,'model_best.pdparams'))
model.load_dict(state_dict)
# 预测
print("predict start ...")
pred_score = do_sample_predict(model,test_data_loader)
print("predict end ...")
predict start ...
predict end ...
7 生成提交文件
# 例如sumbit_emtion1.csv 就代表日志index为1的提交结果文件
sumbit = pd.DataFrame({"id":test["id"]})
sumbit["label"] = pred_score
file_name = "work/sumbit/sumbit_fewshot_{}.csv".format(save_dir_curr.split("/")[1])
sumbit.to_csv(file_name,index=False)
print("生成提交文件{}".format(file_name))
生成提交文件work/sumbit/sumbit_fewshot_ernie-3.0-base-zh-1662132318.csv
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)