
【强化学习】SAC算法
强化学习SAC算法+Pendulum的paddle版实现
强化学习算法:SAC+Pendulum
SAC简介
我们之前学习了一些on-policy算法,如A2C,REINFORCE,PPO,但是他们的采样效率比较低;因此我们通常更倾向于使用off-policy算法,如DQN,DDPG,TD3。但是off-policy的训练通过不稳定,收敛性较差,对超参数比较敏感,也难以适应不同的复杂环境。2018 年,一个更加稳定的离线策略算法 Soft Actor-Critic(SAC)被提出。SAC 的前身是 Soft Q-learning,它们都属于最大熵强化学习的范畴。Soft Q-learning 不存在一个显式的策略函数,而是使用一个函数Q的波尔兹曼分布,在连续空间下求解非常麻烦。于是 SAC 提出使用一个 Actor 表示策略函数,从而解决这个问题。目前,在无模型的强化学习算法中,SAC 是一个非常高效的算法,它学习一个随机性策略,在不少标准环境中取得了领先的成绩。
SAC算法
在 SAC 算法中,我们为两个动作价值函数Critic和一个策略函数Actor建模。基于 Double DQN的思想,SAC使用两个Critic网络,但每次用Critic网络时会挑选一个值小的网络,从而缓解值过高估计的问题。具体算法如下(《Soft Actor-Critic:Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor》):
Pendulum环境
Pendulum环境可以参考项目:
【强化学习】Pendulum-v0环境分析
1.导入依赖包
- paddle框架
- gym环境库
- matplotlib画图工具
- tqdm进度条显示
- numpy科学计算库
- copy用于模型的赋值
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddle.distribution import Normal
import gym
import matplotlib.pyplot as plt
from matplotlib import animation
from tqdm import tqdm
import numpy as np
import copy
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import MutableMapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Iterable, Mapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Sized
2.Model-Algorithm-Agent
本项目采用’‘Model-Algorithm-Agent’'的构建方式,即(智能体(算法(网络模型)))的模式。
2.1 搭建网络模型Actor-Critic
- Actor:策略网络,因为我们用正态分布抽样动作,因此输出是均值和方差
- Critic:价值网络,可以看做两个价值网络的合体,输出是两个价值
- ACModel:Actor-Critic模型,把策略网络和价值网络组合起来。模型的一些函数作用如下:
- init:模型的初始化,即初始化价值网络和策略网络
- policy:策略网络根据环境状态做出相应策略
- value:价值网络根据状态对做出的策略进行评价
- get_actor_params:获取策略网络的参数
- get_critic_params:获取价值网络的参数
- sync_weights_to:更新权重,用于目标网络(模型)的权重更新
# clamp bounds for std of action_log
LOG_SIG_MAX = 2.0
LOG_SIG_MIN = -20.0
class Actor(paddle.nn.Layer):
def __init__(self, obs_dim, action_dim):
super(Actor, self).__init__()
self.l1 = nn.Linear(obs_dim, 256)
self.l2 = nn.Linear(256, 256)
self.mean_linear = nn.Linear(256, action_dim)
self.std_linear = nn.Linear(256, action_dim)
def forward(self, obs):
x = F.relu(self.l1(obs))
x = F.relu(self.l2(x))
act_mean = self.mean_linear(x)
act_std = self.std_linear(x)
act_log_std = paddle.clip(act_std, min=LOG_SIG_MIN, max=LOG_SIG_MAX)
return act_mean, act_log_std
class Critic(paddle.nn.Layer):
def __init__(self, obs_dim, action_dim):
super(Critic, self).__init__()
# Q1 network
self.l1 = nn.Linear(obs_dim + action_dim, 256)
self.l2 = nn.Linear(256, 256)
self.l3 = nn.Linear(256, 1)
# Q2 network
self.l4 = nn.Linear(obs_dim + action_dim, 256)
self.l5 = nn.Linear(256, 256)
self.l6 = nn.Linear(256, 1)
def forward(self, obs, action):
x = paddle.concat([obs, action], 1)
# Q1
q1 = F.relu(self.l1(x))
q1 = F.relu(self.l2(q1))
q1 = self.l3(q1)
# Q2
q2 = F.relu(self.l4(x))
q2 = F.relu(self.l5(q2))
q2 = self.l6(q2)
return q1, q2
class ACModel(paddle.nn.Layer):
def __init__(self, obs_dim, action_dim):
super(ACModel, self).__init__()
self.actor_model = Actor(obs_dim, action_dim)
self.critic_model = Critic(obs_dim, action_dim)
def policy(self, obs):
return self.actor_model(obs)
def value(self, obs, action):
return self.critic_model(obs, action)
def get_actor_params(self):
return self.actor_model.parameters()
def get_critic_params(self):
return self.critic_model.parameters()
def sync_weights_to(self, target_model, decay=0.0):
target_vars = dict(target_model.named_parameters())
for name, var in self.named_parameters():
target_data = decay * target_vars[name] + (1 - decay) * var
target_vars[name] = target_data
target_model.set_state_dict(target_vars)
2.2 经验池
定义经验池类,用于存储智能体与环境的经验(交互轨迹),事后反复利用这些经验训练智能体。
经验回放机制有两个好处:
- 打破序列的相关性
- 是重复利用收集到的经验,而不是用一次就丢弃,这样可以用更少的样本数量达到同样的表现
class ReplayMemory(object):
def __init__(self, max_size, obs_dim, act_dim):
self.max_size = int(max_size)
self.obs_dim = obs_dim
self.act_dim = act_dim
self.obs = np.zeros((max_size, obs_dim), dtype='float32')
self.action = np.zeros((max_size, act_dim), dtype='float32')
self.reward = np.zeros((max_size, ), dtype='float32')
self.terminal = np.zeros((max_size, ), dtype='bool')
self.next_obs = np.zeros((max_size, obs_dim), dtype='float32')
self._curr_size = 0
self._curr_pos = 0
# 抽样指定数量(batch_size)的经验
def sample_batch(self, batch_size):
batch_idx = np.random.randint(self._curr_size, size=batch_size)
obs = self.obs[batch_idx]
reward = self.reward[batch_idx]
action = self.action[batch_idx]
next_obs = self.next_obs[batch_idx]
terminal = self.terminal[batch_idx]
return obs, action, reward, next_obs, terminal
def append(self, obs, act, reward, next_obs, terminal):
if self._curr_size < self.max_size:
self._curr_size += 1
self.obs[self._curr_pos] = obs
self.action[self._curr_pos] = act
self.reward[self._curr_pos] = reward
self.next_obs[self._curr_pos] = next_obs
self.terminal[self._curr_pos] = terminal
self._curr_pos = (self._curr_pos + 1) % self.max_size
def size(self):
return self._curr_size
def __len__(self):
return self._curr_size
2.3 定义SAC算法类
- init:初始化模型,包含Actor-Critic模型及目标模型,还有Actor-Critic模型的优化器(分别为Actor和Critic设置不同的优化器);目标网络不设置优化器,使用权重同步函数进行更新参数。
- sample:action的抽样函数,同时返回其对数概率密度
- save:保存模型,仅保存策略网络的参数
- learn:网络模型的更新,包括:
- _critic_learn:价值网络的更新
- _actor_learn:策略网络的更新
- sync_target:目标网络的参数更新
class SAC():
def __init__(self,model,gamma=None,tau=None,alpha=None,actor_lr=None,critic_lr=None):
self.gamma = gamma
self.tau = tau
self.alpha = alpha
self.actor_lr = actor_lr
self.critic_lr = critic_lr
self.model = model
self.target_model = copy.deepcopy(self.model)
self.actor_optimizer = paddle.optimizer.Adam(
learning_rate=actor_lr, parameters=self.model.get_actor_params())
self.critic_optimizer = paddle.optimizer.Adam(
learning_rate=critic_lr, parameters=self.model.get_critic_params())
def sample(self, obs):
act_mean, act_log_std = self.model.policy(obs)
normal = Normal(act_mean, act_log_std.exp())
# 重参数化 (mean + std*N(0,1))
x_t = normal.sample([1])
action = paddle.tanh(x_t)
log_prob = normal.log_prob(x_t)
log_prob -= paddle.log((1 - action.pow(2)) + 1e-6)
log_prob = paddle.sum(log_prob, axis=-1, keepdim=True)
return action[0], log_prob[0]
def save(self):
paddle.save(self.model.actor_model.state_dict(),'net.pdparams')
def learn(self, obs, action, reward, next_obs, terminal):
critic_loss = self._critic_learn(obs, action, reward, next_obs,terminal)
actor_loss = self._actor_learn(obs)
self.sync_target()
return critic_loss, actor_loss
def _critic_learn(self, obs, action, reward, next_obs, terminal):
with paddle.no_grad():
next_action, next_log_pro = self.sample(next_obs)
q1_next, q2_next = self.target_model.value(next_obs, next_action)
target_Q = paddle.minimum(q1_next,
q2_next) - self.alpha * next_log_pro
terminal = paddle.cast(terminal, dtype='float32')
target_Q = reward + self.gamma * (1. - terminal) * target_Q
cur_q1, cur_q2 = self.model.value(obs, action)
critic_loss = F.mse_loss(cur_q1, target_Q) + F.mse_loss(
cur_q2, target_Q)
self.critic_optimizer.clear_grad()
critic_loss.backward()
self.critic_optimizer.step()
return critic_loss
def _actor_learn(self, obs):
act, log_pi = self.sample(obs)
q1_pi, q2_pi = self.model.value(obs, act)
min_q_pi = paddle.minimum(q1_pi, q2_pi)
actor_loss = ((self.alpha * log_pi) - min_q_pi).mean()
self.actor_optimizer.clear_grad()
actor_loss.backward()
self.actor_optimizer.step()
return actor_loss
def sync_target(self, decay=None):
if decay is None:
decay = 1.0 - self.tau
self.model.sync_weights_to(self.target_model, decay=decay)
2.4 SAC智能体
定义智能体,包括以下函数:
- init:初始化需要的算法及目标网络的同步参数
- sample:action的抽样函数
- learn:网络模型的更新
class SACAgent():
def __init__(self, algorithm):
self.alg=algorithm
self.alg.sync_target(decay=0)
def sample(self, obs):
obs = paddle.to_tensor(obs.reshape(1, -1), dtype='float32')
action, _ = self.alg.sample(obs)
action_numpy = action.cpu().numpy()[0]
return action_numpy
def learn(self, obs, action, reward, next_obs, terminal):
terminal = np.expand_dims(terminal, -1)
reward = np.expand_dims(reward, -1)
obs = paddle.to_tensor(obs, dtype='float32')
action = paddle.to_tensor(action, dtype='float32')
reward = paddle.to_tensor(reward, dtype='float32')
next_obs = paddle.to_tensor(next_obs, dtype='float32')
terminal = paddle.to_tensor(terminal, dtype='float32')
critic_loss, actor_loss = self.alg.learn(obs, action, reward, next_obs,
terminal)
return critic_loss, actor_loss
3. SAC的训练及验证
3.1 定义相应的超参数
WARMUP_STEPS = 5e3
MEMORY_SIZE = int(1e6)
BATCH_SIZE = 64 #256
GAMMA = 0.99
TAU = 0.005
ACTOR_LR = 3e-4
CRITIC_LR = 3e-4
env_name='Pendulum-v0'
env_seed=0
alpha=0.2
train_total_steps=200
env = gym.make(env_name)
env.seed(env_seed)
obs_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
# 初始化 模型,算法,智能体以及经验池
model = ACModel(obs_dim, action_dim)
algorithm = SAC(model,gamma=GAMMA,tau=TAU,alpha=alpha,actor_lr=ACTOR_LR,critic_lr=CRITIC_LR)
agent = SACAgent(algorithm)
rpm = ReplayMemory(max_size=MEMORY_SIZE, obs_dim=obs_dim, act_dim=action_dim)
W0907 22:34:49.384989 357 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0907 22:34:49.389746 357 device_context.cc:465] device: 0, cuDNN Version: 7.6.
3.2 定义训练函数
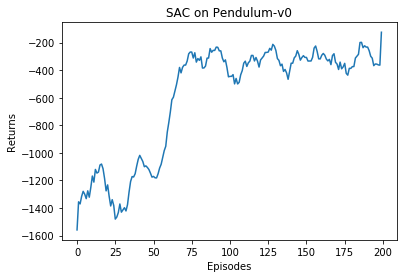
- SAC是off-policy,反复使用经验池中的历史经验进行网络更新。
- 使用tqdm显示训练的进度
- 保存回合奖励最大值时的策略网络参数,用于验证
- 使用matplotlib绘制训练过程的回合奖励变化
def train_off_policy_agent(env, agent, num_episodes, replay_buffer, WARMUP_STEPS,batch_size):
return_list = []
maxre=-10000000
for i in range(10):
with tqdm(total=int(num_episodes/10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes/10)):
action_dim = env.action_space.shape[0]
obs = env.reset()
done = False
episode_reward = 0
episode_steps = 0
while not done:
episode_steps += 1
if replay_buffer.size() < WARMUP_STEPS:
action = np.random.uniform(-1, 1, size=action_dim)
else:
action = agent.sample(obs)
next_obs, reward, done, _ = env.step(action)
terminal = float(done) if episode_steps < 1000 else 0
replay_buffer.append(obs, action, reward, next_obs, terminal)
obs = next_obs
episode_reward += reward
# 收集到足够的经验后进行网络的更新
if replay_buffer.size() >= WARMUP_STEPS:
batch_obs, batch_action, batch_reward, batch_next_obs, batch_terminal = replay_buffer.sample_batch(BATCH_SIZE)
agent.learn(batch_obs, batch_action, batch_reward, batch_next_obs,batch_terminal)
if maxre<episode_reward:
maxre=episode_reward
agent.alg.save()
return_list.append(episode_reward)
if (i_episode+1) % 10 == 0:
pbar.set_postfix({'episode': '%d' % (num_episodes/10 * i + i_episode+1), 'return': '%.3f' % np.mean(return_list[-10:])})
pbar.update(1)
return return_list
return_list=train_off_policy_agent(env, agent, train_total_steps, rpm, WARMUP_STEPS, BATCH_SIZE)
Iteration 0: 100%|██████████| 20/20 [00:00<00:00, 76.89it/s, episode=20, return=-1110.582]
Iteration 1: 100%|██████████| 20/20 [00:45<00:00, 2.30s/it, episode=40, return=-1242.721]
Iteration 2: 100%|██████████| 20/20 [01:00<00:00, 3.04s/it, episode=60, return=-1098.781]
Iteration 3: 100%|██████████| 20/20 [01:00<00:00, 3.01s/it, episode=80, return=-266.299]
Iteration 4: 100%|██████████| 20/20 [01:00<00:00, 3.03s/it, episode=100, return=-305.586]
Iteration 5: 100%|██████████| 20/20 [00:59<00:00, 2.96s/it, episode=120, return=-276.422]
Iteration 6: 100%|██████████| 20/20 [01:00<00:00, 3.04s/it, episode=140, return=-368.387]
Iteration 7: 100%|██████████| 20/20 [00:59<00:00, 3.00s/it, episode=160, return=-288.915]
Iteration 8: 100%|██████████| 20/20 [01:00<00:00, 3.01s/it, episode=180, return=-386.023]
Iteration 9: 100%|██████████| 20/20 [01:01<00:00, 3.07s/it, episode=200, return=-343.094]
def moving_average(a, window_size):
cumulative_sum = np.cumsum(np.insert(a, 0, 0))
middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_size
r = np.arange(1, window_size-1, 2)
begin = np.cumsum(a[:window_size-1])[::2] / r
end = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]
return np.concatenate((begin, middle, end))
episodes_list = list(range(len(return_list)))
# plt.plot(episodes_list, return_list)
# plt.xlabel('Episodes')
# plt.ylabel('Returns')
# plt.title('SAC on {}'.format(env_name))
# plt.show()
mv_return = moving_average(return_list, 9)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('SAC on {}'.format(env_name))
plt.show()
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
if isinstance(obj, collections.Iterator):
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return list(data) if isinstance(data, collections.MappingView) else data
3.3 验证
- 使用保存的策略网络参数初始化一个策略网络
- 使用Pendulum环境进行200个step的验证
- 将验证过程保存成动态图(.gif文件),但是ai studio应该还不支持gym环境的可视化,相应代码可在本地运行,我们在本地运行将保存的动态图展示如下:

actor=Actor(3,1)
layer_state_dict = paddle.load("net.pdparams")
actor.set_state_dict(layer_state_dict)
env=gym.make('Pendulum-v0')
state=env.reset()
for i in range(200):
state=paddle.to_tensor(state,dtype='float32')
action =actor(state)[0].numpy()
next_state,reward,done,_=env.step(action)
if i%20==0:
print(i," ",reward,done)
state=next_state
env.close()
0 -0.2964112865567006 False
20 -1.9899326332069296 False
40 -0.001168723903525063 False
60 -0.00011829137614509929 False
80 -0.0001334316517237268 False
100 -0.00013392322365439715 False
120 -0.00013393802344656305 False
140 -0.00013393840994481763 False
160 -0.00013393841547029297 False
180 -0.0001339385568948745 False
该部分代码在ai studio无法运行,可在本地运行
def save_frames_as_gif(frames, filename):
#Mess with this to change frame size
plt.figure(figsize=(frames[0].shape[1]/100, frames[0].shape[0]/100), dpi=300)
patch = plt.imshow(frames[0])
plt.axis('off')
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(plt.gcf(), animate, frames = len(frames), interval=50)
anim.save(filename, writer='pillow', fps=60)
env=gym.make('Pendulum-v0')
state=env.reset()
frames = []
for i in range(200):
#print(env.render(mode="rgb_array"))
frames.append(env.render(mode="rgb_array"))
state=paddle.to_tensor(state,dtype='float32')
action =actor(state)[0].numpy()
#action=action.numpy()[0]
#print(action)
next_state,reward,done,_=env.step(action)
if i%10==0:
print(i," ",reward,done)
state=next_state
save_frames_as_gif(frames, filename="Pendulum.gif")
env.close()
总结
接触强化学习已经一段时间了,通过对一些开源书籍、开源代码的学习,大体对基本算法有了一些基本了解。一个强化学习算法的创新往往是需要大量的数学公式推导,这是我不擅长的,因此,我的主要目标就是通过借鉴或参考一些书籍、源码,可以对基本算法进行实现即可。目前已有的项目如下:
- DQN+CartPole-v0
- A2C+CartPole-v0
- DDPG+Pendulum-v0
- TD3+Pendulum-v0
- REINFORCE+CartPole-v0
- PPO+CartPole-v0
强化学习是一件很有趣的事情,欢迎大家留下宝贵的学习意见以及一些交流看法,大家一起学习,一起进步!
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 2
2 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)