
2022 CCF BDCI 大赛之Web攻击检测与分类识别
基于paddleNLP和jieba做文本分类任务,分数在0.949左右
零.写在最前
该项目源于2022 CCF BDCI 大赛之《Web攻击检测与分类识别》
• 赛题任务
参赛团队需要对前期提供的训练集进行分析,通过特征工程、机器学习和深度学习等方法构建AI模型,实现对每一条样本正确且快速分类,不断提高模型精确率和召回率。待模型优化稳定后,通过无标签测试集评估各参赛团队模型分类效果,以正确率评估各参赛团队模型质量。
• 解决思路
先通过对训练集关键字提取,再经过PaddleNLP文本分类,快速生成比赛结果文件
快速命令行模式 数据预处理+训练+生成比赛结果:
# 1. 切换到工作目录 + 安装 paddlenlp
%cd work/
!pip install paddlenlp --upgrade --user
# 2. 一键生成符合格式的训练集,验证集,测试集
!python pre.py
# 3. 训练
!python train.py
# 4. 生成比赛结果
!python predict.py
一.数据集生成
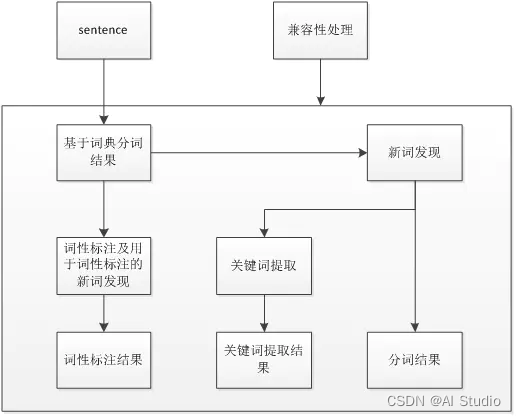
对数据集中user_agent,url,refer,body等字段进行关键字提取。并且生成对应的训练接,验证集,测试集
这里用到jieba分词
# -*- coding: utf-8 -*-
# pre.py
import paddle
import numpy as np
import pandas as pd
from config import Config
from paddlenlp.datasets import load_dataset
import json
import jieba.analyse
import random
class Pre(object):
labels = {}
labels_ = {}
def __init__(self):
self.cf = Config()
self.dataPath = self.cf.dataPath
self.trainRatio = self.cf.trainRatio
def train(self):
lists = []
for i in range(6):
df = pd.read_csv(self.dataPath+'/train/'+str(i)+'.csv').astype(str)
print(len(df))
for j in range(len(df)):
item = []
item.append(df.loc[j, 'method'])
r0 = jieba.analyse.extract_tags(df.loc[j, 'user_agent'], topK=10)
item.extend(r0)
r1 = jieba.analyse.extract_tags(df.loc[j, 'url'], topK=20)
item.extend(r1)
r2 = jieba.analyse.extract_tags(df.loc[j, 'refer'], topK=10)
item.extend(r2)
r3 = jieba.analyse.extract_tags(df.loc[j, 'body'], topK=20)
item.extend(r3)
item_ = {
'text': " ".join(item),
'label': df.loc[j, 'lable']
}
print(j,item_)
lists.append(item_)
random.shuffle(lists)
print(len(lists))
offset = int(len(lists)*float(self.trainRatio))
trains = lists[0:offset]
valids = lists[offset:]
# 生成新的数据集
trainsF = open(self.cf.minePath+'/train.json', 'w')
validsF = open(self.cf.minePath+'/valid.json', 'w')
for item in trains:
trainsF.write(json.dumps(item, ensure_ascii=False))
trainsF.write('\n')
for item in valids:
validsF.write(json.dumps(item, ensure_ascii=False))
validsF.write('\n')
def test(self):
tests = []
df = pd.read_csv(self.dataPath+'/test/test.csv').astype(str)
print(len(df))
for j in range(len(df)):
item = []
item.append(df.loc[j, 'method'])
r0 = jieba.analyse.extract_tags(
df.loc[j, 'user_agent'], topK=10)
item.extend(r0)
r1 = jieba.analyse.extract_tags(df.loc[j, 'url'], topK=20)
item.extend(r1)
r2 = jieba.analyse.extract_tags(df.loc[j, 'refer'], topK=10)
item.extend(r2)
r3 = jieba.analyse.extract_tags(df.loc[j, 'body'], topK=20)
item.extend(r3)
item_ = {
'id': df.loc[j, 'id'],
'text': " ".join(item)
}
print(j, item_)
tests.append(item_)
print(len(tests))
# 生成新的数据集
testsF = open(self.cf.minePath+'/test.json', 'w')
for item in tests:
testsF.write(json.dumps(item, ensure_ascii=False))
testsF.write('\n')
pre = Pre()
pre.train()
pre.test()
二.数据集预处理
将数据集转换成MapDataset格式
# -*- coding: utf-8 -*-
#dataset.py
import paddle
import numpy as np
import pandas as pd
from config import Config
from paddlenlp.datasets import load_dataset
import json
def datas(dataPath, mode='train'):
f = open(dataPath+'/'+ mode+'.json')
while True:
line = f.readline()
if not line:
break
data = line.strip().split('\t')
data = json.loads(data[0])
text = data['text']
if mode == 'test':
yield {"id":data['id'], "text": text, "labels": [0]}
else:
yield {"text": text, "labels": [int(data['label'])]}
f.close()
class Dataset(object):
labels = {}
labels_ = {}
def __init__(self):
self.cf = Config()
self.dataPath = self.cf.minePath
def getLoader(self, mode = 'train'):
ds = load_dataset(datas, dataPath=self.dataPath,mode=mode,lazy=False)
return ds
三.训练模型
模型采用ernie-2.0-base-en
对文本进行分词操作
设置相关配置:
batch_size = 30(32G显卡)
epochs = 100
learning_rate 策略
将每轮的loss,acc存入 rank目录下的record.csv中
将每轮最好的结果存入rank目录下的rank.csv中
不断更新成绩权重为best.pdparams
# -*- coding: utf-8 -*-
import paddle
from paddle.nn import Linear
import paddle.nn.functional as F
import paddle.nn as nn
from visualdl import LogWriter
import numpy as np
from dataset import Dataset
from config import Config
import os
import pandas as pd
import paddlenlp
from paddlenlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
import functools
from paddle.io import DataLoader, BatchSampler
from paddlenlp.data import DataCollatorWithPadding
from metric import MultiLabelReport
from eval import evaluate
import time
def preprocess_function(examples, tokenizer, max_seq_length):
result = tokenizer(text=examples["text"], max_seq_len=max_seq_length)
result["labels"] = examples["labels"]
return result
class Train(object):
batch_size = 30
epochs = 100
data = None
def __init__(self):
cf = Config()
self.cf = cf
self.modelPath = cf.modelPath
self.logPath = cf.logPath
self.pointsPath = cf.pointsPath
self.use_gpu = cf.use_gpu
self.rankPath = cf.rankPath
self.dataset = Dataset()
self.model_name = "ernie-2.0-base-en"
self.num_classes = 6 # 分类
self.max_seq_length = 512
if not os.path.exists(self.rankPath):
os.makedirs(self.rankPath)
def run(self):
#开启GPU
paddle.set_device('gpu:0') if self.use_gpu else paddle.set_device('cpu')
model = AutoModelForSequenceClassification.from_pretrained(self.model_name, num_classes=self.num_classes)
tokenizer = AutoTokenizer.from_pretrained(self.model_name)
train_ds = self.dataset.getLoader(mode='train')
valid_ds = self.dataset.getLoader(mode='valid')
trans_func = functools.partial(preprocess_function, tokenizer=tokenizer, max_seq_length=self.max_seq_length)
train_ds = train_ds.map(trans_func)
valid_ds = valid_ds.map(trans_func)
# collate_fn函数构造,将不同长度序列充到批中数据的最大长度,再将数据堆叠
collate_fn = DataCollatorWithPadding(tokenizer)
# 定义BatchSampler,选择批大小和是否随机乱序,进行DataLoader
train_batch_sampler = BatchSampler(train_ds, batch_size=self.batch_size, shuffle=True)
valid_batch_sampler = BatchSampler(valid_ds, batch_size=self.batch_size, shuffle=False)
train_data_loader = DataLoader(dataset=train_ds, batch_sampler=train_batch_sampler, collate_fn=collate_fn)
valid_data_loader = DataLoader(dataset=valid_ds, batch_sampler=valid_batch_sampler, collate_fn=collate_fn)
self.log_writer = LogWriter(self.cf.logPath)
learning_rate = 3e-5
# 学习率预热比例
warmup_proportion = 0.1
# 权重衰减系数,类似模型正则项策略,避免模型过拟合
weight_decay = 0.01
num_training_steps = len(train_data_loader) * self.epochs
# 学习率衰减策略
lr_scheduler = paddlenlp.transformers.LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
# learning_rate = 1e-4
# optimizer = paddle.optimizer.Adam(learning_rate=learning_rate, weight_decay=paddle.regularizer.L2Decay(coeff=1e-5), parameters=model.parameters())
iter_ = 0 #迭代次数
for epoch in range(1, self.epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch['input_ids'], batch['token_type_ids'], batch['labels']
# 计算模型输出、损失函数值、分类概率值、准确率、f1分数
logits = model(input_ids, token_type_ids)
loss = F.cross_entropy(logits, labels)
avg_loss = paddle.mean(loss)
acc = paddle.metric.accuracy(input=logits, label=labels)
loss_t = avg_loss.numpy()
acc_t = acc.numpy()
loss_t = np.round(loss_t,2)
acc_t = np.round(acc_t,2)
if step % 10 == 0:
print("Train epoch: {}, batch: {}, loss is: {}, acc is {}".format(epoch, step, loss_t, acc_t))
self.log_writer.add_scalar(tag = 'acc', step = iter_, value = acc_t)
self.log_writer.add_scalar(tag = 'loss', step = iter_, value = loss_t)
# 反向梯度回传,更新参数
loss.backward()
lr_scheduler.step()
optimizer.step()
optimizer.clear_grad()
loss_e, acc_e = evaluate(model,valid_data_loader)
loss_e = np.round(loss_e,2)
acc_e = np.round(acc_e,2)
print("Eval epoch: {}, batch: {}, loss is: {}, acc is {}".format(epoch, step, loss_e, acc_e))
paddle.save(model.state_dict(), './{}/epoch{}'.format(self.pointsPath,epoch)+'.pdparams')
self.rank(model,epoch,loss_t,loss_e,acc_t,acc_e)
iter_ += 1
def rank(self, model, epoch, loss_t, loss_e, acc_t, acc_e):
if os.path.exists(self.rankPath+'rank.csv') is False:
df = pd.DataFrame([{
"epoch":epoch,
"loss_t":loss_t,
'loss_e':loss_e,
'acc_t':acc_t,
'acc_e':acc_e,
}])
df.to_csv(self.rankPath+'rank.csv', index=False)
paddle.save(model.state_dict(), self.rankPath+'best.pdparams')
paddle.save(model.state_dict(), self.rankPath+'/records/epoch'+str(epoch)+'.pdparams')
else:
df = pd.read_csv(self.rankPath+'/rank.csv')
maxAccE = df.loc[df.index.max()]['acc_e']
maxAccE = float(maxAccE)
if acc_e > maxAccE:
df.loc[df.index.max() + 1] = [epoch, loss_t, loss_e, acc_t, acc_e]
df.to_csv(self.rankPath+'rank.csv', index=False)
paddle.save(model.state_dict(), self.rankPath+'best.pdparams')
paddle.save(model.state_dict(), self.rankPath+'/records/epoch'+str(epoch)+'.pdparams')
if os.path.exists(self.rankPath+'record.csv') is False:
init = {
"epoch":epoch,
"loss_t":loss_t,
'loss_e':loss_e,
'acc_t':acc_t,
'acc_e':acc_e,
}
dfr = pd.DataFrame([init])
dfr.to_csv(self.rankPath+'record.csv', index=False)
else:
dfr = pd.read_csv(self.rankPath+'record.csv')
dfr.loc[dfr.index.max() + 1] = [
epoch,
loss_t,
loss_e,
acc_t,
acc_e
]
dfr.to_csv(self.rankPath+'record.csv', index=False)
train = Train()
train.run()
四.生成比赛结果文件
通过读取rank目录下权重,进行结果预测
model.set_dict(paddle.load(self.rankPath+'/best.pdparams'))
#model.set_dict(paddle.load(self.pointsPath+'/epoch40.pdparams'))
结果保存在rank目录下
# -*- coding: utf-8 -*-
#predict.py
import paddle
from dataset import Dataset
from config import Config
import os
import pandas as pd
from paddlenlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
import functools
from paddle.io import DataLoader, BatchSampler
from paddlenlp.data import DataCollatorWithPadding
import copy
def preprocess_function(examples, tokenizer, max_seq_length):
result = tokenizer(text=examples["text"], max_seq_len=max_seq_length)
result["labels"] = examples["labels"]
#result["id"] = examples["id"]
return result
class Predict(object):
def __init__(self):
cf = Config()
self.cf = cf
self.logPath = cf.logPath
self.pointsPath = cf.pointsPath
self.use_gpu = cf.use_gpu
self.rankPath = cf.rankPath
self.dataset = Dataset()
self.model_name = "ernie-2.0-base-en"
self.num_classes = 6 # 分类
self.max_seq_length = 512
self.batch_size = 1
if not os.path.exists(self.rankPath):
os.makedirs(self.rankPath)
def run(self):
#开启GPU
paddle.set_device('gpu:0') if self.use_gpu else paddle.set_device('cpu')
model = AutoModelForSequenceClassification.from_pretrained(self.model_name, num_classes=self.num_classes)
tokenizer = AutoTokenizer.from_pretrained(self.model_name)
test_src = self.dataset.getLoader(mode='test')
test_ds = copy.deepcopy(test_src)
trans_func = functools.partial(preprocess_function, tokenizer=tokenizer, max_seq_length=self.max_seq_length)
test_ds = test_ds.map(trans_func)
# collate_fn函数构造,将不同长度序列充到批中数据的最大长度,再将数据堆叠
collate_fn = DataCollatorWithPadding(tokenizer)
# 定义BatchSampler,选择批大小和是否随机乱序,进行DataLoader
test_batch_sampler = BatchSampler(test_ds, batch_size=self.batch_size, shuffle=False)
test_data_loader = DataLoader(dataset=test_ds, batch_sampler=test_batch_sampler, collate_fn=collate_fn)
model.set_dict(paddle.load(self.rankPath+'/best.pdparams'))
#model.set_dict(paddle.load(self.pointsPath+'/epoch40.pdparams'))
model.eval()
results = []
index = 0
for batch in test_data_loader:
input_ids, token_type_ids = batch['input_ids'], batch['token_type_ids']
logits = model(input_ids, token_type_ids)
label = paddle.argmax(logits).numpy()[0]
results.append([test_src[index]['id'], label])
print(test_src[index]['id'], label)
index += 1
submit = pd.DataFrame(results, columns=['id', 'predict'])
submit[['id', 'predict']].to_csv(self.rankPath + '/submit_example.csv', index=False)
predict = Predict()
predict.run()
五.其他配置
日志路径,数据集路径,排名路径可以config.py中进行设置
# -*- coding: utf-8 -*-
class Config(object):
def __init__(self):
self.dataPath = '../data/data168015/data' # 原始数据集路径
self.minePath = './data/' # 生成的数据集路径
self.trainRatio = '0.8' # 训练集和验证集比例
self.modelPath = './model/'
self.rankPath = './rank/'
self.logPath = './logs'
self.pointsPath = './checkpoint' # 每轮保存的权重
self.inferencePath = './inference/'
self.pointsPath = './checkpoint' # 每轮保存的权重
self.inferencePath = './inference/'
self.use_gpu = 1 # 是否使用GPU
六.总结
目前得分在0.949左右,还有很大提升空间
1.数据集方向,通过调整jieba提取关键字的参数,获取不同的关键字
r0 = jieba.analyse.extract_tags(df.loc[j, 'user_agent'], topK=10)
item.extend(r0)
r1 = jieba.analyse.extract_tags(df.loc[j, 'url'], topK=20)
item.extend(r1)
r2 = jieba.analyse.extract_tags(df.loc[j, 'refer'], topK=10)
item.extend(r2)
r3 = jieba.analyse.extract_tags(df.loc[j, 'body'], topK=20)
2.通过修改分配训练集的比例增大训练集范围
self.trainRatio = '0.8'
3.训练方向,微调batch_size,learning_rate,weight_decay等
4.模型方向,尝试替换不同的模型,调整max_seq_length数值等
相关比赛索引:
2022 CCF BDCI 大赛之 高端装备制造知识图谱自动化构建技术评测任务
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 1
1 0
0- 0



 已为社区贡献1438条内容
已为社区贡献1438条内容

所有评论(0)