
【AI达人创造营三期-自动驾驶场景/商品检测Edgeboard部署】
本项目主要完成了自动驾驶场景检测和室内商品检测的Edgeboard部署方案。
一、项目简介
本项目属于AI达人创造营三期项目,主要侧重点在于模型的部署落地。
本次创造营我收到的硬件是Edgeboard FZ3B开发板,虽然是第一次接触,但是按照官方文档操作十分简单易上手,自己也重新安装了一遍1.8.0的软核和各种demo进行尝试。
本项目使用PaddleLitedemo中的YoLov3检测模型(也尝试部署PP-YOLO在FZ3B上,但是1.8.0的软核版本应该是不支持)在两个数据集上进行了训练,一个是BDD100K道路场景数据集,我对这个数据集的格式重新进行了处理,转换成voc格式,总共包括13个类别。另一个数据集是智能零售柜商品识别,包括113中商品,也是voc格式的。 我分别训练了两个模型,部署到开发板上可以成功运行,下面是对整个流程的介绍和记录。
EdgeBoard嵌入式AI解决方案
百度面向嵌入式与边缘计算场景打造的系列软硬件方案。丰富的软硬件选型,可适应多变的场景与边缘部署环境。无缝兼容百度大脑工具平台与算法模型,开发者可轻松上手,集成应用。
基于EdgeBoard计算卡,可便捷搭载自研或百度大脑离线算法,轻松打造嵌入式AI应用设备。
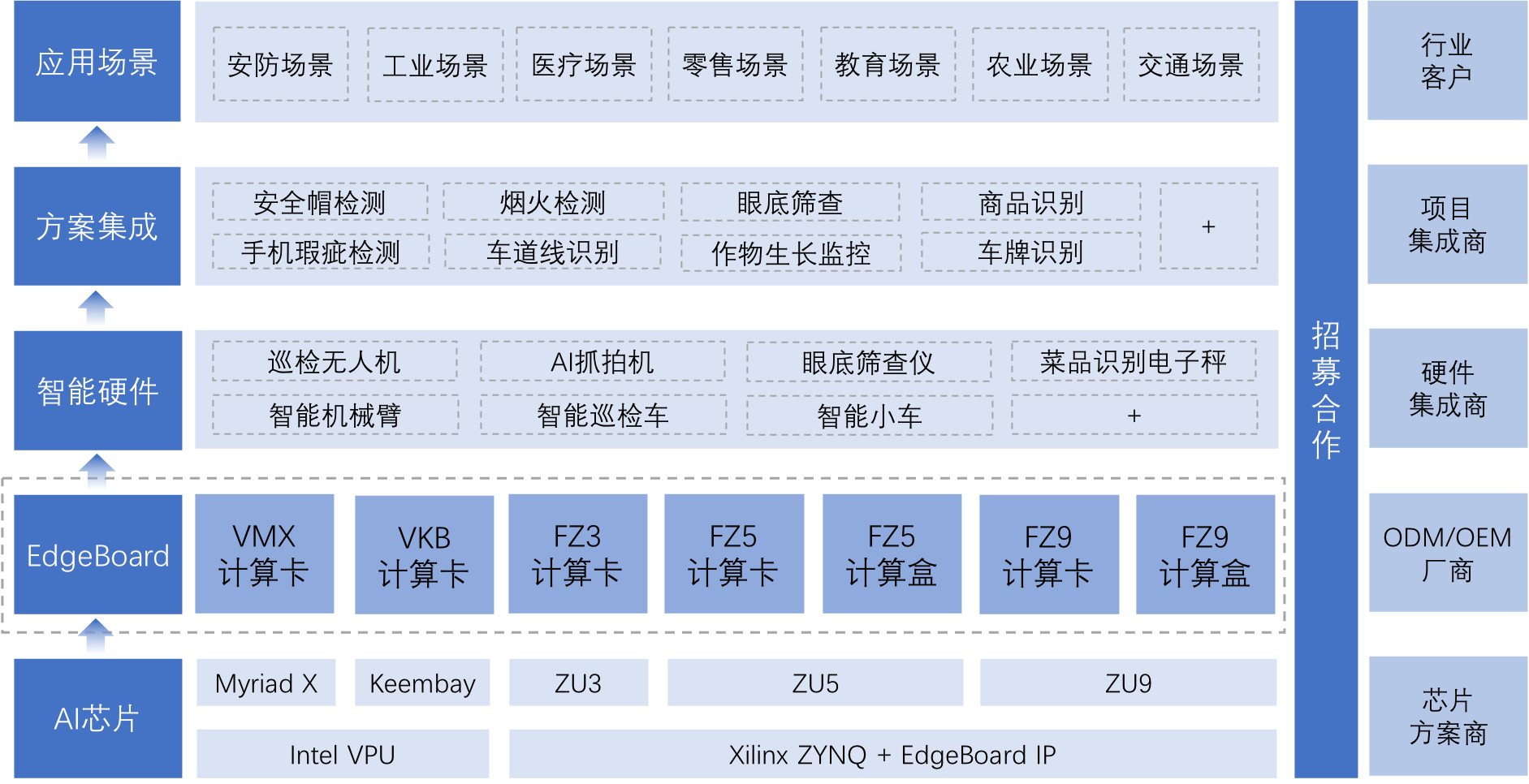
在官方的解决方案中,EdgeBoard更多以一个完整的解决方案形式出现。但是对于单张Edgeboard计算卡如何自定义操作,还有很多需要开发者一起来完善的。
在该系列项目中,我们将从一张FZ3B Edgeboard计算卡开始,探索它是如何实现一系列模型部署的。
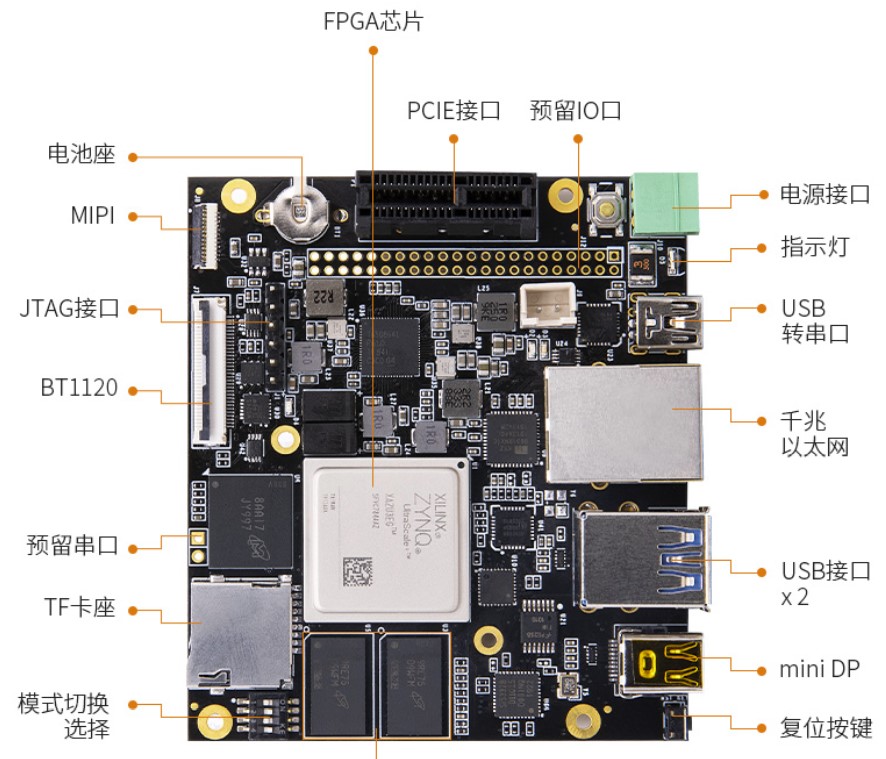
二、EdgeBoard FZ3B计算卡简介
【视频教程】
【更多详细资料】
三、安装Edgeboard管理系统
我拿到的Edgeboard FZ3B计算卡内置的软核版本是1.8.0,官方介绍如下:
- 支持PaddleSlim 量化模型,需保存为float模型。
- 支持多线程和多进程调试
- 优化算子,对于ResNext50、yolov3以及FZ3平台有性能提升
- 提升了模型的精度
- 新增支持HRNet_baseline关键点模型和Deeplabv3p 分割模型
- 支持了GPIO,RS485,RS232,CAN接口通讯,并提供了示例
- 新增Python接口和示例;优化了C++示例。
- 增加了EdgeBoard管理系统(EBM),可视化操作界面
最后一条提到可以使用EdgeBoard管理系统,所以来安装一下方便后续操作:
为使用户能够更便捷的使用Edgeboard进行摄像头增删、模型管理、推理结果处理、系统设置等功能,推出了Edgeboard管理系统,可以通过浏览器页面可视化的进行摄像头管理、模型管理、采集管理以及查看模型推理结果。大大降低了Edgeboard使用难度。管理系统还提供了http回调接口和http服务,回调接口可以实时将摄像头的推理结果上传到服务器,http服务器则支持将图片上传到系统进行推理,以满足不同用户的使用需求。
安装文档:安装文档
将edge-management压缩包拷到设备中,unzip edge-management.zip解压安装包,
解压完毕后进入解压后的edge-management/deployments目录并运行脚本
# 解压
unzip edge-management.zip
# 进入安装目录
cd edge-management/deployments
# FZ5C/D型号执行deploy.sh安装脚本
sh deploy.sh
# FZ3A/B型号执行deploy_fz3.sh安装脚本
sh deploy_fz3.sh
然后等待安装,10分钟左右后安装完毕,会在页面输出提示 :
edge managment install success, please reboot your edgeboard
表示已安装完毕,并会自动重启开发板生效。
四、模型准备
- 有关BDD100K数据集我之前训练过,但是训练的模型是用Paddle2.0以上的高版本训练的,部署到EdgeBoard之后会有问题,因此这里使用Paddle1.8.4重新训练和导出。
4.1 数据准备
# 解压BDD100K数据集并调整数据集位置(请确保运行之前已解压PaddleDetection-release-0.5.zip)
!unzip -oq /home/aistudio/data/data167518/bdd100k.zip
!mv ~/home/aistudio/PaddleDetection/dataset/bdd100k ~/PaddleDetection-release-0.5/dataset
!rm -rf ~/home/
# 解压商品检测数据集
!mkdir /home/aistudio/PaddleDetection-release-0.5/dataset/det
!unzip -oq /home/aistudio/data/data91732/VOC.zip -d /home/aistudio/PaddleDetection-release-0.5/dataset/det
# 安装依赖
!pip install -r ~/PaddleDetection-release-0.5/requirements.txt
4.2 模型训练
# 道路场景检测yolov3
%cd ~/PaddleDetection-release-0.5/
!python -u tools/train.py -c configs/yolov3_darknet_voc.yml --eval \
# 商品检测yolov3
%cd ~/PaddleDetection-release-0.5/
!python -u tools/train.py -c configs/yolov3_darknet_voc_commodity.yml --eval
# 商品检测pp-yolo(尝试了不能运行,可以升级软核版本试试看)
%cd ~/PaddleDetection-release-0.5/
!python -u tools/train.py -c configs/ppyolo/ppyolo_2x.yml -r output3/ppyolo_2x/5000.pdparams --eval
4.3 模型评估
- 提示一下:模型训的时间都比较短,因为YOLO v3训练实在是太慢了,读者有时间的话可以多训练一下,鑫总自己训练的PP-YOLOv2在智能零售柜商品识别数据集上能达到80+
# 评估BDD100K数据集 默认使用训练过程中保存的best_model
# -c 参数表示指定使用哪个配置文件
# -o 参数表示指定配置文件中的全局变量(覆盖配置文件中的设置),需使用单卡评估
%cd ~/PaddleDetection-release-0.5
!python tools/eval.py -c configs/yolov3_darknet_voc.yml \
-o weights=output/yolov3_darknet_voc/best_model \
-o use_gpu=true
# 评估yolov3训练的商品数据集
%cd ~/PaddleDetection-release-0.5
!python tools/eval.py -c configs/yolov3_darknet_voc_commodity.yml \
-o weights=output2/yolov3_darknet_voc_commodity/best_model \
-o use_gpu=true
4.4 模型导出
- 使用0.5版本的PaddleDetection导出前面训练的模型
# 导出BDD100K上训练的yolov3_darknet53推理模型
%cd ~/PaddleDetection-release-0.5/
!python tools/export_model.py -c configs/yolov3_darknet_voc.yml \
-o weights=output/yolov3_darknet_voc/best_model \
--output_dir=inference
# 导出商品检测数据集上训练的yolov3_darknet53推理模型
%cd ~/PaddleDetection-release-0.5/
!python tools/export_model.py -c configs/yolov3_darknet_voc_commodity.yml \
-o weights=output2/yolov3_darknet_voc_commodity/best_model \
net_voc_commodity/best_model \
--output_dir=inference_commodity
五、上传模型
模型导出后得到的文件夹文件结构如下:
inference
|-- infer_cfg.yml
|-- __model__
|-- __params__
需要将__mdoel__和__params__上传到Edgeboard上,这里我使用的工具是Xftp7,使用有线IP连接电脑和开发板,然后在Xftp里面输入开发板的IP地址和账号密码就可以建立连接。
开发板上的模型预测示例里PaddleLiteDemo里提供了一些经典的模型,其中包括yolov3(注:backbone刚好是darknet53,如果backbone是mobilenetv3或其它,当前软核的op很可能还不支持)。
configs目录中已经默认添加每个 模型对应4种不同 输入源的配置
configs ✗ tree
.
├── classification
│ ├── Inceptionv2
│ ├── Inceptionv3
│ ├── mobilenetv1
│ └── resnet50
│ ├── image.json
│ ├── multi_channel_camera.json
│ ├── rtspcamera.json
│ └── usbcamera.json
├── detection
│ ├── mobilenet-ssd
│ ├── mobilenet-ssd-640
│ ├── mobilenet-yolov3
│ ├── vgg-ssd
│ └── yolov3
│ ├── image.json
│ ├── multi_channel_camera.json
│ ├── rtspcamera.json
│ └── usb_camera.json
└── segmentation
└── deeplabv3
├── image.json
├── multi_channel_camera.json
├── rtspcamera.json
└── usbcamera.json
13 directories, 12 files
Xftp7连接之后,看到的文件包括以下四个文件夹:
C++ : C++语言编写的demo 源码
python : python语言编写的demo 源码
configs : 存放了示例运行需要的配置文件
res: 存放了模型相关文件和图片文件
需要做的事情就是进入开发板的model里面的yolov3文件夹中,用__model__和__params__替换原本的model和params就行,但是由于config.json中读取模型的目录写的都是model和params,所以可重命名一下这俩文件(去掉前后双下划线)或者改一下配置文件的目录。然后注意label_list.txt的内容也要换成当前数据集的label。
[PaddleLiteDemo]中config.json的内容
{
"network_type":"YOLOV3",
"model_file_name":"model",
"params_file_name":"params",
"labels_file_name":"label_list.txt",
"format":"RGB",
"input_width":608,
"input_height":608,
"mean":[123.675, 116.28, 103.53],
"scale":[0.0171248, 0.017507, 0.0174292],
"threshold":0.3
}
最后,我们就可以准备运行推理模型了。
运行Python的话需要进入Python/demo文件夹内,有image.json和usb_camera.json,这俩其实一样,就是type不同,会决定是推理图片还是调用摄像头,以usb_camera.json为例,内容如下:
{
"model_config": "../../res/modles/detection/yolov3",
"input": {
"type": "usb_camera",
"path": "/dev/video2"
},
"debug": {
"display_enable": true,
"predict_log_enable": true,
"predict_time_log_enable": true
}
}
model_config : 模型的目录,相对于 PaddleLiteDemo/C++/build 目录,各个示例支持的模型见目录
type: 输入源的类型,可选项目
path: 输入源对应的 设备节点或url 或 图片的名字
display_enable: 显示器显示开关,当没有显示器时可以设置为 false
predict_log_enable : 预测的结果通过命令行打印的开关
predict_time_log_enable: 预测时间的打印开关
使用Python运行步骤如下:
cd PaddleLite/Python/demo
classification.py 分类示例
detection.py 检测示例
以检测为例:
export PYTHONPATH=/home/root/workspace/PaddleLiteDemo/Python/
python3 detection.py ../../configs/detection/yolov3/image.json
项目总结
第一次接触Edgeboard,个人感觉阅读完官方文档之后操作起来没有难度,并且软核升级也很稳定,不会出现奇奇怪怪的异常,对小白十分友好。
模型这里一定要注意使用PaddlePaddle1.8.5以下的版本完成训练和导出,我尝试了高版本的导出模型是不能正常推理的(即便是yolov3_darknet53也不行)。
Edgeboard的推理行为控制代码detection.py写的非常浅显易懂,很容易修改,这点也很好。
还有个小插曲就是我自己准备的显示屏一直没法使用,于是我就自己写了Socket通信代码,使用有线网口来发处理之后的视频帧发送到我的电脑上实时显示,如果直接传输肯定不行,很卡,我用了opencv提供的图像压缩(字节流长度压缩了十几倍,比较震撼),然后使用TCP和UDP都做了尝试。由于是有线网传输,丢包率比较低,所以二者效果上差异不大,但是UDP明显要流畅一些。(socket通信不太好写,读者如果有需要写UDP通信的时候还是要注意一下,不要超过发送方的字节长度限制,TCP的话没这个限制,但是注意在每一帧的开头发送一下总长度,然后接收方接收到当前帧的全部数据之后在显示这一帧,否则可能会解码错误。)
项目作者
赵祎安 大连理工大学飞桨飞桨领航团团长 计算机科学与技术 大四
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)