
手把手快速搭建智能语音客服——保险问答实践
手把手快速搭建简易的智能语音客服,包含语音交互技术,问答查询技术,零基础快速入门语音识别,语音合成,问答检索
零基础快速搭建全流程智能语音客服系统——保险问答实践
1. 背景介绍
智能语音客服是智能客服的重要组成部分,在语音相关的人机交互场景中都有所应用,如智能外呼机器人,智能呼入机器人,虚拟人客服,数字员工以及现在线下的各类语音交互式非接触机器人等,智能语音客服在生活中随处可见。
1.1 场景痛点
以电话场景的智能语音客服为例
-
传统的电话
- 工作重复性高
- 人员培训成本高,流动率大
- 电话有效触达率低,单人只能线性处理工单
- 处理渠道单一,平台间数据难互通
-
智能语音客服
- 擅长处理重复性的工作
- 开发成本低,稳定性高,可以快速适应各类场景
- 快速筛查无效触达,可同时处理多个工单,智能调度,效率大幅提升
- 底层能力通用,多平台多渠道数据可实现统一管理
针对以上场景,应用PaddleSpeech的语音识别技术,语音合成技术,标点恢复技术和PaddleNLP的问答检索系统,可以实现一个完整最小型智能语音客服应用,希望可以为大家开发智能语音客服带来一些帮助。
在本项目中,你将会学习到:
- PaddleSpeech快速开发语音应用
- 语音合成
- 语音识别
- 标点恢复
- PaddleNLP快速搭建检索式FAQ系统
- 无相似 Query-Query Pair 标注数据构建 FAQ System
- hnswlib索引引擎
2. 搭建试验环境
本项目Python环境中只需要安装 paddlenlp 与 paddlespeech 的发行包即可,环境中再带对应的paddlepaddle包。下载相应的模型和数据即可
# 配置开发环境
!pip install paddlenlp
!pip install paddlespeech
# 下载 nltk_data
%cd /home/aistudio
!wget -P data https://paddlespeech.bj.bcebos.com/Parakeet/tools/nltk_data.tar.gz
!tar zxvf data/nltk_data.tar.gz
# 配置 FAQ 问答环境
# 下载模型
!wget https://paddlespeech.bj.bcebos.com/demos/voice_customer_service/SimCSE_PreTrain.zip
!unzip SimCSE_PreTrain.zip
# 下载数据集
!wget https://paddlespeech.bj.bcebos.com/demos/voice_customer_service/baoxian.zip
!unzip baoxian.zip
3. 快速使用PaddleSpeech语音识别与语音合成能力
PaddleSpeech支持一键预测能力,使用Python可以很方便的调用,会自动下载对应的预训练模型。快速使用可以参考【PaddleSpeech 一键预测,快速上手Speech开发任务】
这里我们使用PaddleSpeech的语音识别能力,标点恢复能力,以及语音合成能力。
# 语音合成使用,第一次使用时自动下载模型,耗时比较长
from paddlespeech.cli.tts.infer import TTSExecutor
tts = TTSExecutor()
text = "买了社保,是不是就不用买商业保险了?"
output_wav = "baoxian_example.wav"
tts(text=text, output=output_wav)
# 听一下合成效果
import IPython.display as ipd
ipd.Audio(output_wav)
# 语音识别能力,第一次使用时自动下载模型,耗时比较长
from paddlespeech.cli.asr.infer import ASRExecutor
asr = ASRExecutor()
asr_result = asr(audio_file=output_wav, force_yes=True)
# tts 生成的音频默认为24k, asr 识别默认为16k,重采样一下
print("asr 识别结果:", asr_result)
2022-09-05 15:12:59.449 | INFO | paddlespeech.s2t.modules.embedding:__init__:153 - max len: 5000
[2022-09-05 15:13:00,958] [ WARNING] - The sample rate of the input file is not 16000.
The program will resample the wav file to 16000.
If the result does not meet your expectations,
Please input the 16k 16 bit 1 channel wav file.
asr 识别结果: 买了社保是不是就不用买商业保险了
# 标点恢复,第一次使用时自动下载模型,耗时比较长
from paddlespeech.cli.text.infer import TextExecutor
text_punc = TextExecutor()
text_punc_result = text_punc(text=asr_result)
print("标点恢复结果:", text_punc_result)
[2022-09-05 15:14:24,771] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie-1.0/vocab.txt
[2022-09-05 15:14:24,793] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/ernie-1.0/tokenizer_config.json
[2022-09-05 15:14:24,822] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/ernie-1.0/special_tokens_map.json
标点恢复结果: 买了社保,是不是就不用买商业保险了?
4. 搭建保险领域检索式FAQ问答系统
模型的构造与训练部分可以见【手把手搭建FAQ保险问答系统】,模型通过PaddleNLP训练提供的预训练模型,这里仅展示使用预训练模型进行问答检索部分。
# 加载飞桨的API
import paddlenlp as ppnlp
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddle import inference
# 序列的最大的长度,根据数据集的情况进行设置
max_seq_length=64
batch_size=64
# 使用rocketqa开放领域的问答模型
model_name_or_path='rocketqa-zh-dureader-query-encoder'
tokenizer = ppnlp.transformers.ErnieTokenizer.from_pretrained(model_name_or_path)
[2022-09-05 15:24:03,638] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/rocketqa-zh-dureader-query-encoder/rocketqa-zh-dureader-vocab.txt
[2022-09-05 15:24:03,652] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/rocketqa-zh-dureader-query-encoder/tokenizer_config.json
[2022-09-05 15:24:03,655] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/rocketqa-zh-dureader-query-encoder/special_tokens_map.json
# 加载 SimCSE 模型
from SimCSE import SimCSE
# 关键参数
scale=20 # 推荐值: 10 ~ 30
margin=0.1 # 推荐值: 0.0 ~ 0.2
# 可以根据实际情况进行设置
output_emb_size=256
# 使用预训练模型
pretrained_model = ppnlp.transformers.ErnieModel.from_pretrained(model_name_or_path)
# 无监督+R-Drop,类似于多任务学习
simcse_model = SimCSE(
pretrained_model,
margin=margin,
scale=scale,
output_emb_size=output_emb_size)
# 加载模型
state_dict = paddle.load("model_140/model_state.pdparams")
simcse_model.set_state_dict(state_dict)
simcse_model.eval()
[2022-09-05 15:24:11,903] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/rocketqa-zh-dureader-query-encoder/rocketqa_zh_dureader_query_encoder.pdparams
# 构建向量检索数据库
from ann_util import build_index
from data import convert_example_test
from data import gen_id2corpus
from paddlenlp.data import Stack, Tuple, Pad
from paddlenlp.datasets import load_dataset, MapDataset
from functools import partial
# 明文数据 -> ID 序列训练数据
def create_dataloader(dataset,
mode='train',
batch_size=1,
batchify_fn=None,
trans_fn=None):
if trans_fn:
dataset = dataset.map(trans_fn)
shuffle = True if mode == 'train' else False
if mode == 'train':
batch_sampler = paddle.io.DistributedBatchSampler(
dataset, batch_size=batch_size, shuffle=shuffle)
else:
batch_sampler = paddle.io.BatchSampler(
dataset, batch_size=batch_size, shuffle=shuffle)
return paddle.io.DataLoader(
dataset=dataset,
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
return_list=True)
corpus_file = 'baoxian/corpus.csv'
id2corpus = gen_id2corpus(corpus_file)
# conver_example function's input must be dict
corpus_list = [{idx: text} for idx, text in id2corpus.items()]
print(corpus_list[:4])
trans_func_corpus = partial(
convert_example_test,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
batchify_fn_corpus = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # text_input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # text_segment
): [data for data in fn(samples)]
corpus_ds = MapDataset(corpus_list)
corpus_data_loader = create_dataloader(
corpus_ds,
mode='predict',
batch_size=batch_size,
batchify_fn=batchify_fn_corpus,
trans_fn=trans_func_corpus)
# 索引的大小
hnsw_max_elements=1000000
# 控制时间和精度的平衡参数
hnsw_ef=100
hnsw_m=100
final_index = build_index(corpus_data_loader,
simcse_model,
output_emb_size=output_emb_size,
hnsw_max_elements=hnsw_max_elements,
hnsw_ef=hnsw_ef,
hnsw_m=hnsw_m)
[{0: '如何办理企业养老保险'}, {1: '如何为西班牙购买签证保险?'}, {2: '康慧宝需要买多少?'}, {3: '如果另一方对车辆事故负有全部责任,并且拒绝提前支付维修费,该怎么办'}]
[2022-09-05 14:40:05,420] [ INFO] - start build index..........
[2022-09-05 14:40:19,854] [ INFO] - Total index number:3788
example="买了社保,是不是就不用买商业保险了?"
print('输入文本:{}'.format(example))
encoded_inputs = tokenizer(
text=[example],
max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"]
input_ids = paddle.to_tensor(input_ids)
token_type_ids = paddle.to_tensor(token_type_ids)
cls_embedding=simcse_model.get_pooled_embedding( input_ids=input_ids,token_type_ids=token_type_ids)
# print('提取特征:{}'.format(cls_embedding))
recalled_idx, cosine_sims = final_index.knn_query(
cls_embedding.numpy(), 10)
print('检索召回')
for doc_idx,cosine_sim in zip(,cosine_sims[0]):
print(id2corpus[doc_idx],cosine_sim)
输入文本:买了社保,是不是就不用买商业保险了?
检索召回
如果你买社会保险,你不需要买商业保险吗? 0.27194548
社保跟商业保险的区别在哪?有了社保还需要买商业保险不? 0.3280698
已有社会保险还需要买商业保险吗 0.40743905
个人买商业保险划算吗?还有就是买社保好呀? 0.42893076
有社保和没社保买商业保险的区别 0.4710914
得病之后还可以买商业保险吗 0.48352647
有商业保险,还能交社会社会保吗 0.50378084
我买了社保,含住院保险,又买了商业医疗保险 0.50750923
购买商业保险并获得生存金意味着什么 0.5167047
你通常购买什么商业保险 0.5517243
# 构建问题对
from data import read_text_pair
QA_dict = {}
cnt = 0
for qa in read_text_pair("baoxian/qa_pair.csv"):
q = qa['text_a']
a = qa['text_b']
if q not in QA_dict:
QA_dict[q] = []
QA_dict[q].append(a)
cnt += 1
# 从QA对中检索出答案
def simcse_FAQ(example):
encoded_inputs = tokenizer(
text=[example],
max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"]
input_ids = paddle.to_tensor(input_ids)
token_type_ids = paddle.to_tensor(token_type_ids)
cls_embedding=simcse_model.get_pooled_embedding( input_ids=input_ids,token_type_ids=token_type_ids)
# print('提取特征:{}'.format(cls_embedding))
recalled_idx, cosine_sims = final_index.knn_query(
cls_embedding.numpy(), 10)
# 检索到最接近的问题
q_text = id2corpus[recalled_idx[0][0]]
if q_text in QA_dict:
answer = QA_dict[q_text]
if len(answer) > 0:
# 返回第一个
return QA_dict[q_text][0]
else:
return ""
else:
return ""
simcse_FAQ(example)
如果你买社会保险,你不需要买商业保险吗?
'社保是基础的,就是我们通常说的“五险”包括:基本养老保险、基本医疗保险、失业保险、工伤保险和生育保险。而商业保险则是保障。'
5. 搭建智能语音客服服务
串联PaddleSpeech的语音识别功能,语音合成功能,标点恢复功能与FAQ问答系统,使用FastAPI快速搭建应用。
5.1 核心功能梳理
def audio_faq(input_audio_path, output_audio_path):
# asr 识别
asr_result = asr(audio_file=input_audio_path, force_yes=True)
print("asr 识别结果: ", asr_result)
# 标点恢复
text_punc_result = text_punc(text=asr_result)
# FAQ 检索
faq_result = simcse_FAQ(text_punc_result)
# TTS 合成
if not faq_result:
faq_result = "抱歉,未能查询到相关问题结果"
print("FAQ 检索结果: ", faq_result)
tts(text=faq_result, output=output_audio_path)
return output_audio_path
# 测试一下功能是否完整
input_audio_path = "baoxian_example.wav"
output_audio_path = "baoxian_answer.wav"
audio_faq(input_audio_path, output_audio_path)
[2022-09-05 16:04:24,597] [ WARNING] - The sample rate of the input file is not 16000.
The program will resample the wav file to 16000.
If the result does not meet your expectations,
Please input the 16k 16 bit 1 channel wav file.
asr 识别结果: 买了社保是不是就不用买商业保险了
FAQ 检索结果: 社保是基础的,就是我们通常说的“五险”包括:基本养老保险、基本医疗保险、失业保险、工伤保险和生育保险。而商业保险则是保障。
'baoxian_answer.wav'
# 听一下回答的结果
import IPython.display as ipd
ipd.Audio(output_audio_path)
5.2 基于 FastAPI 封装应用
在aistudio中,无法做前端的演示,我们提供简易版的服务端与客户端进行演示。我们通过fastapi快速搭建网页应用,通过构造post请求,模拟网页调用
Server代码示例,已经写在了server.py文件中,通过命令行执行python server.py快速启动服务。核心代码展示:
from typing import Union
import aiofiles
import os
import json
import uvicorn
from fastapi import FastAPI, UploadFile
from paddlespeech.cli.asr.infer import ASRExecutor
from paddlespeech.cli.text.infer import TextExecutor
from paddlespeech.cli.tts.infer import TTSExecutor
from FAQ import simcse_FAQ
asr = ASRExecutor()
tts = TTSExecutor()
text_punc = TextExecutor()
app = FastAPI()
audio_save_path = "/home/aistudio/work/audio"
os.makedirs(audio_save_path, exist_ok=True)
def audio_faq(input_audio_path, output_audio_path):
# asr 识别
asr_result = asr(audio_file=input_audio_path, force_yes=True)
# 标点恢复
text_punc_result = text_punc(text=asr_result)
# FAQ 检索
faq_result = simcse_FAQ(text_punc_result)
# TTS 合成
if not faq_result:
faq_result = "抱歉,未能查询到相关问题结果"
tts(text=faq_result, output=output_audio_path)
return asr_result, faq_result, output_audio_path
@app.post("/audioFAQ")
async def audioFAQ(file:UploadFile):
# 将传过来的文件保存
out_file_path = os.path.join(audio_save_path, file.filename)
async with aiofiles.open(out_file_path, 'wb') as out_file:
content = await file.read() # async read
await out_file.write(content) # async write
output_audio_path = os.path.join(audio_save_path, 'faq_'+file.filename)
# 语音问答
asr_result, faq_result, output_audio_path = audio_faq(input_audio_path=out_file_path, output_audio_path=output_audio_path)
result = {
'question': asr_result,
'answer': faq_result,
'output_audio': output_audio_path
}
return json.dumps(result, ensure_ascii=False)
if __name__ == '__main__':
uvicorn.run(app=app, host='0.0.0.0', port=8889)
# 安装后端相关依赖库
!pip install fastapi
!pip install uvicorn
!pip install aiofiles
!pip install python-multipart
5.3 启动服务
新建终端(项目左上方➕号),在命令行中执行
python server.py
等服务启动成功后,终端中会出现以下字样
INFO: Waiting for application startup.
[2022-09-05 16:53:26] [INFO] [on.py:47] Waiting for application startup.
INFO: Application startup complete.
[2022-09-05 16:53:26] [INFO] [on.py:61] Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8889 (Press CTRL+C to quit)
[2022-09-05 16:53:26] [INFO] [server.py:212] Uvicorn running on http://0.0.0.0:8889 (Press CTRL+C to quit)
新建终端方法: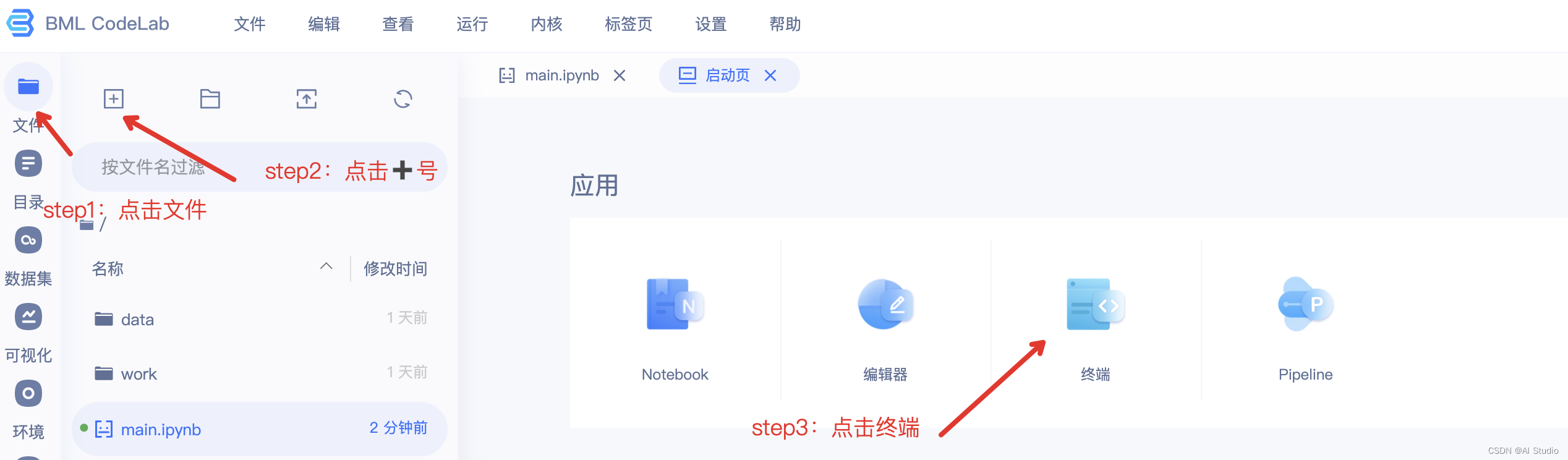
5.4 构造请求
通过requests库,构造Post请求,调用语音FAQ检索的后端服务。(请一定要确保上方的服务,在终端中正常开启)
import requests
import json
files = {"file": open("baoxian_example.wav", "rb")}
r = requests.post("http://0.0.0.0:8889/audioFAQ", files=files)
result = json.loads(r.json())
print(result)
{'question': '买了社保是不是就不用买商业保险了', 'answer': '社保是基础的,就是我们通常说的“五险”包括:基本养老保险、基本医疗保险、失业保险、工伤保险和生育保险。而商业保险则是保障。', 'output_audio': '/home/aistudio/work/audio/faq_baoxian_example.wav'}
6. 结束语
相信通过上述课程的学习,你已经学会了如何搭建一套完整的智能语音客服系统。
如果我们项目对你有所帮助的话,欢迎大家前往Github
⭐️ star ⭐️ 收藏,功能我们会持续更新哦!
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 2
2 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)