
Lang-Seg:文本驱动的图像语义分割
介绍论文 Language-driven Semantic Segmentation 中提出的 LSeg 文本驱动的图像语义分割模型,并加载官方提供的预训练参数实现模型的推理预测。
1. 引入
-
随着 AI 算法的发展,文本可以驱动文本生成、图像生成、图像搜索等任务
-
那么,文本能否驱动图像分割模型去分割指定的物体或者语义类别呢?
-
答案当然也是可以的,今天就来介绍一篇论文 Language-driven Semantic Segmentation
-
了解一下如何使用文本驱动图像的语义分割
2. 效果展示
-
通过控制文本标签,驱动模型对特定物体进行语义分割:
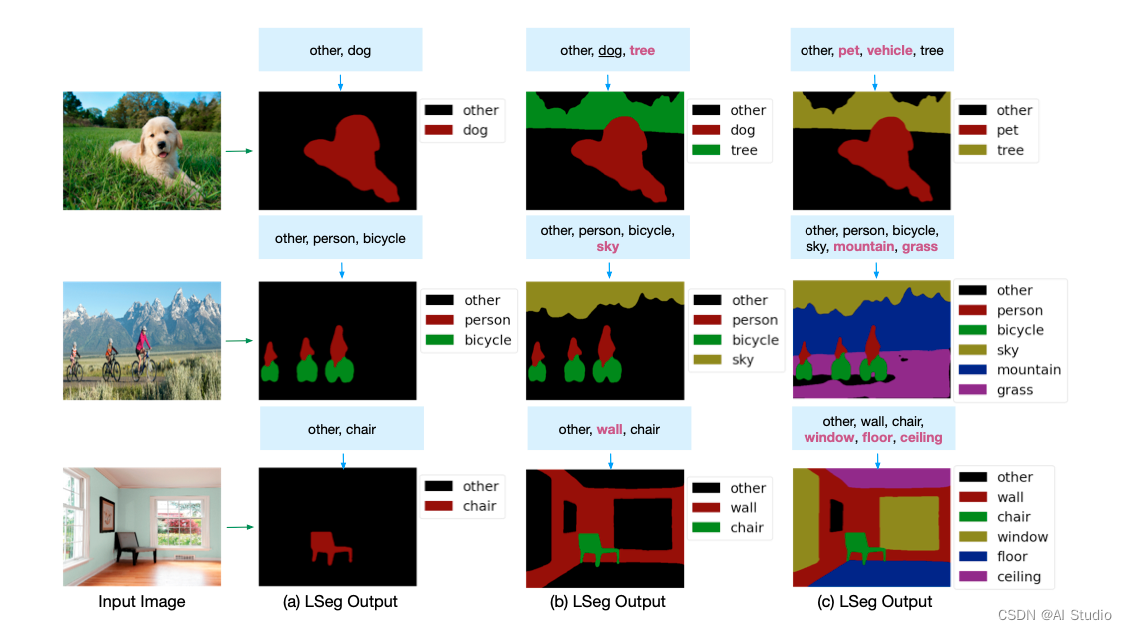
-
太长不看版,使用 PaddleHub 快速调用该模型:PaddleHub:根据文本描述进行快速抠图
3. 参考资料
4. 算法介绍
-
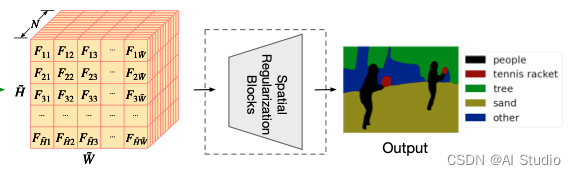
模型架构图:
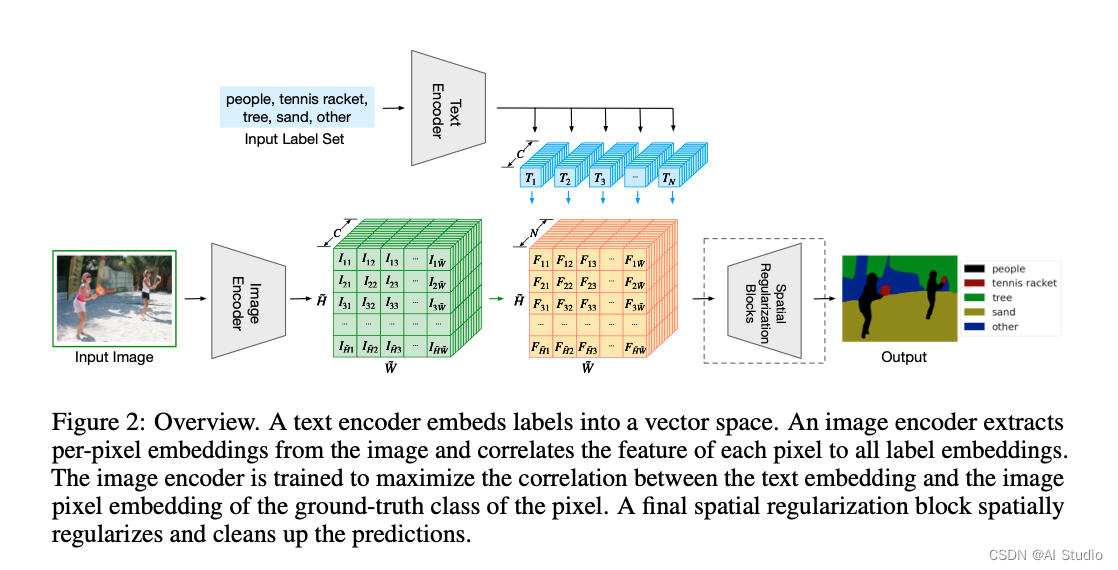
-
通过上面这个模型架构图可以看到,整个 LSeg 模型分为三个主要部分:
-
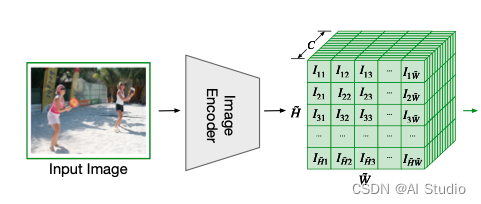
图像编码网络
-
通过一个 CNN 或者 Transformer 模型,文章中测试了 ViT 和 CLIP 模型,用于编码图像特征:
-
-
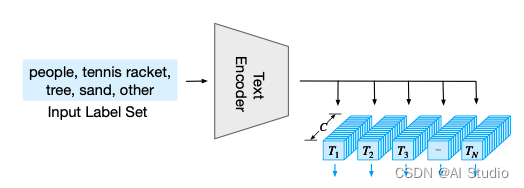
文本编码网络
-
通过一个 Transformer 模型,文章中测试了 CLIP 模型,用于编码文本特征:
-
-
特征融合网络
-
使用一些 CNN 模块融合图像和文本特征,并生成图像分割结果:
-
-
-
算法思路:
-
模型训练时与常规的图像语义分割模型类似,同样使用有标签的语义分割数据,做一个有监督训练
-
不同的是,训练时将图像的语义标签作为额外的输入,转换为特定维度的文本特征,控制分割输出的类别和类别数量
-
这样就可以使用多个不同的语义分割数据集进行融合训练,即使他们的标签不尽相同,也可以正常的训练模型
-
因为相比 CLIP 这样的模型使用的数据规模而言,现在能使用的有标注的语义分割数据规模还是比较小的,所以训练时 CLIP 的模型参数不更新,以免劣化模型的效果。
-
通过 CLIP 这样的文本编码网络引入文本特征,就可以轻松的实现文本驱动的语义分割模型了
-
5. 依赖安装
- 安装一下 PaddleNLP 和 PaddleClas
!pip install paddleclas paddlenlp ftfy regex --upgrade
6. 模型搭建
6.1 图像编码器
-
这里采用了 Vision Transformer 模型作为图像编码器
-
为了更好地提取图像的特征信息,对模型做了一些微小的修改
-
提取多层级的模型输出特征
-
添加一个特征后处理的小网络
-
删除了原来模型输出的 Norm 和 Linear 层
-
import math
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddleclas.ppcls.arch.backbone.model_zoo.vision_transformer import VisionTransformer
class Slice(nn.Layer):
def __init__(self, start_index=1):
super(Slice, self).__init__()
self.start_index = start_index
def forward(self, x):
return x[:, self.start_index:]
class AddReadout(nn.Layer):
def __init__(self, start_index=1):
super(AddReadout, self).__init__()
self.start_index = start_index
def forward(self, x):
if self.start_index == 2:
readout = (x[:, 0] + x[:, 1]) / 2
else:
readout = x[:, 0]
return x[:, self.start_index:] + readout.unsqueeze(1)
class Transpose(nn.Layer):
def __init__(self, dim0, dim1):
super(Transpose, self).__init__()
self.dim0 = dim0
self.dim1 = dim1
def forward(self, x):
prems = list(range(x.dim()))
prems[self.dim0], prems[self.dim1] = prems[self.dim1], prems[self.dim0]
x = x.transpose(prems)
return x
class Unflatten(nn.Layer):
def __init__(self, start_axis, shape):
super(Unflatten, self).__init__()
self.start_axis = start_axis
self.shape = shape
def forward(self, x):
return paddle.reshape(x, x.shape[:self.start_axis] + [self.shape])
class ProjectReadout(nn.Layer):
def __init__(self, in_features, start_index=1):
super(ProjectReadout, self).__init__()
self.start_index = start_index
self.project = nn.Sequential(nn.Linear(2 * in_features, in_features), nn.GELU())
def forward(self, x):
readout = x[:, 0].unsqueeze(1).expand_as(x[:, self.start_index :])
features = paddle.concat((x[:, self.start_index :], readout), -1)
return self.project(features)
class ViT(VisionTransformer):
def __init__(self, img_size=384, patch_size=16, in_chans=3, class_num=1000,
embed_dim=1024, depth=24, num_heads=16, mlp_ratio=4, qkv_bias=True,
qk_scale=None, drop_rate=0, attn_drop_rate=0, drop_path_rate=0,
norm_layer='nn.LayerNorm', epsilon=1e-6, **kwargs):
super().__init__(img_size, patch_size, in_chans, class_num, embed_dim,
depth, num_heads, mlp_ratio, qkv_bias, qk_scale, drop_rate,
attn_drop_rate, drop_path_rate, norm_layer, epsilon, **kwargs)
self.patch_size = patch_size
self.start_index = 1
features = [256, 512, 1024, 1024]
readout_oper = [
ProjectReadout(embed_dim, self.start_index) for out_feat in features
]
self.act_postprocess1 = nn.Sequential(
readout_oper[0],
Transpose(1, 2),
Unflatten(2, [img_size // 16, img_size // 16]),
nn.Conv2D(
in_channels=embed_dim,
out_channels=features[0],
kernel_size=1,
stride=1,
padding=0,
),
nn.Conv2DTranspose(
in_channels=features[0],
out_channels=features[0],
kernel_size=4,
stride=4,
padding=0,
dilation=1,
groups=1,
),
)
self.act_postprocess2 = nn.Sequential(
readout_oper[1],
Transpose(1, 2),
Unflatten(2, [img_size // 16, img_size // 16]),
nn.Conv2D(
in_channels=embed_dim,
out_channels=features[1],
kernel_size=1,
stride=1,
padding=0,
),
nn.Conv2DTranspose(
in_channels=features[1],
out_channels=features[1],
kernel_size=2,
stride=2,
padding=0,
dilation=1,
groups=1,
),
)
self.act_postprocess3 = nn.Sequential(
readout_oper[2],
Transpose(1, 2),
Unflatten(2, [img_size // 16, img_size // 16]),
nn.Conv2D(
in_channels=embed_dim,
out_channels=features[2],
kernel_size=1,
stride=1,
padding=0,
),
)
self.act_postprocess4 = nn.Sequential(
readout_oper[3],
Transpose(1, 2),
Unflatten(2, [img_size // 16, img_size // 16]),
nn.Conv2D(
in_channels=embed_dim,
out_channels=features[3],
kernel_size=1,
stride=1,
padding=0,
),
nn.Conv2D(
in_channels=features[3],
out_channels=features[3],
kernel_size=3,
stride=2,
padding=1,
),
)
self.norm = nn.Identity()
self.head = nn.Identity()
def _resize_pos_embed(self, posemb, gs_h, gs_w):
posemb_tok, posemb_grid = (
posemb[:, : self.start_index],
posemb[0, self.start_index:],
)
gs_old = int(math.sqrt(len(posemb_grid)))
posemb_grid = posemb_grid.reshape(
(1, gs_old, gs_old, -1)).transpose((0, 3, 1, 2))
posemb_grid = F.interpolate(
posemb_grid, size=(gs_h, gs_w), mode="bilinear")
posemb_grid = posemb_grid.transpose(
(0, 2, 3, 1)).reshape((1, gs_h * gs_w, -1))
posemb = paddle.concat([posemb_tok, posemb_grid], axis=1)
return posemb
def forward(self, x):
b, c, h, w = x.shape
pos_embed = self._resize_pos_embed(
self.pos_embed, h // self.patch_size, w // self.patch_size
)
x = self.patch_embed.proj(x).flatten(2).transpose((0, 2, 1))
cls_tokens = self.cls_token.expand(
(b, -1, -1)
)
x = paddle.concat((cls_tokens, x), axis=1)
x = x + pos_embed
x = self.pos_drop(x)
outputs = []
for index, blk in enumerate(self.blocks):
x = blk(x)
if index in [5, 11, 17, 23]:
outputs.append(x)
layer_1 = self.act_postprocess1[0:2](outputs[0])
layer_2 = self.act_postprocess2[0:2](outputs[1])
layer_3 = self.act_postprocess3[0:2](outputs[2])
layer_4 = self.act_postprocess4[0:2](outputs[3])
shape = (-1, 1024, h // self.patch_size, w // self.patch_size)
layer_1 = layer_1.reshape(shape)
layer_2 = layer_2.reshape(shape)
layer_3 = layer_3.reshape(shape)
layer_4 = layer_4.reshape(shape)
layer_1 = self.act_postprocess1[3: len(self.act_postprocess1)](layer_1)
layer_2 = self.act_postprocess2[3: len(self.act_postprocess2)](layer_2)
layer_3 = self.act_postprocess3[3: len(self.act_postprocess3)](layer_3)
layer_4 = self.act_postprocess4[3: len(self.act_postprocess4)](layer_4)
return layer_1, layer_2, layer_3, layer_4
6.2 文本编码器
- 这里采用了 CLIP 模型作为文本编码器
- 因为只需要编码文本信息,所以 CLIP 中包含的图像编码器就无需保留
import paddle
import paddle.nn as nn
from paddlenlp.transformers.clip.modeling import TextTransformer
class CLIPText(nn.Layer):
def __init__(
self,
max_text_length: int = 77,
vocab_size: int = 49408,
text_embed_dim: int = 512,
text_heads: int = 8,
text_layers: int = 12,
text_hidden_act: str = "quick_gelu",
projection_dim: int = 512):
super().__init__()
self.text_model = TextTransformer(context_length=max_text_length,
transformer_width=text_embed_dim,
transformer_heads=text_heads,
transformer_layers=text_layers,
vocab_size=vocab_size,
activation=text_hidden_act,
normalize_before=True)
self.text_projection = paddle.create_parameter(
(text_embed_dim, projection_dim), paddle.get_default_dtype())
def get_text_features(
self,
input_ids,
attention_mask=None,
position_ids=None,
output_attentions=False,
output_hidden_states=False,
return_dict=False,
):
text_outputs = self.text_model(
input_ids=input_ids,
position_ids=position_ids,
attention_mask=attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict)
pooled_output = text_outputs[1]
text_features = paddle.matmul(pooled_output, self.text_projection)
return text_features
6.3 特征融合网络
- 这是论文中提出的一个特征融合模型
import paddle
import paddle.nn as nn
import numpy as np
class Interpolate(nn.Layer):
"""Interpolation module."""
def __init__(self, scale_factor, mode, align_corners=False):
"""Init.
Args:
scale_factor (float): scaling
mode (str): interpolation mode
"""
super(Interpolate, self).__init__()
self.interp = nn.functional.interpolate
self.scale_factor = scale_factor
self.mode = mode
self.align_corners = align_corners
def forward(self, x):
"""Forward pass.
Args:
x (tensor): input
Returns:
tensor: interpolated data
"""
x = self.interp(
x,
scale_factor=self.scale_factor,
mode=self.mode,
align_corners=self.align_corners,
)
return x
class ResidualConvUnit(nn.Layer):
"""Residual convolution module."""
def __init__(self, features):
"""Init.
Args:
features (int): number of features
"""
super().__init__()
self.conv1 = nn.Conv2D(
features, features, kernel_size=3, stride=1, padding=1
)
self.conv2 = nn.Conv2D(
features, features, kernel_size=3, stride=1, padding=1
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
"""Forward pass.
Args:
x (tensor): input
Returns:
tensor: output
"""
out = self.relu(x)
out = self.conv1(out)
out = self.relu(out)
out = self.conv2(out)
return out + x
class FeatureFusionBlock(nn.Layer):
"""Feature fusion block."""
def __init__(self, features):
"""Init.
Args:
features (int): number of features
"""
super(FeatureFusionBlock, self).__init__()
self.resConfUnit1 = ResidualConvUnit(features)
self.resConfUnit2 = ResidualConvUnit(features)
def forward(self, *xs):
"""Forward pass.
Returns:
tensor: output
"""
output = xs[0]
if len(xs) == 2:
output += self.resConfUnit1(xs[1])
output = self.resConfUnit2(output)
output = nn.functional.interpolate(
output, scale_factor=2, mode="bilinear", align_corners=True
)
return output
class ResidualConvUnit_custom(nn.Layer):
"""Residual convolution module."""
def __init__(self, features, activation, bn):
"""Init.
Args:
features (int): number of features
"""
super().__init__()
self.bn = bn
self.groups = 1
self.conv1 = nn.Conv2D(
features,
features,
kernel_size=3,
stride=1,
padding=1,
bias_attr=not self.bn,
groups=self.groups,
)
self.conv2 = nn.Conv2D(
features,
features,
kernel_size=3,
stride=1,
padding=1,
bias_attr=not self.bn,
groups=self.groups,
)
if self.bn == True:
self.bn1 = nn.BatchNorm2D(features)
self.bn2 = nn.BatchNorm2D(features)
self.activation = activation
def forward(self, x):
"""Forward pass.
Args:
x (tensor): input
Returns:
tensor: output
"""
out = self.activation(x)
out = self.conv1(out)
if self.bn == True:
out = self.bn1(out)
out = self.activation(out)
out = self.conv2(out)
if self.bn == True:
out = self.bn2(out)
if self.groups > 1:
out = self.conv_merge(out)
return out + x
class FeatureFusionBlock_custom(nn.Layer):
"""Feature fusion block."""
def __init__(
self,
features,
activation=nn.ReLU(),
deconv=False,
bn=False,
expand=False,
align_corners=True,
):
"""Init.
Args:
features (int): number of features
"""
super(FeatureFusionBlock_custom, self).__init__()
self.deconv = deconv
self.align_corners = align_corners
self.groups = 1
self.expand = expand
out_features = features
if self.expand == True:
out_features = features // 2
self.out_conv = nn.Conv2D(
features,
out_features,
kernel_size=1,
stride=1,
padding=0,
bias_attr=True,
groups=1,
)
self.resConfUnit1 = ResidualConvUnit_custom(features, activation, bn)
self.resConfUnit2 = ResidualConvUnit_custom(features, activation, bn)
def forward(self, *xs):
"""Forward pass.
Returns:
tensor: output
"""
output = xs[0]
if len(xs) == 2:
res = self.resConfUnit1(xs[1])
output += res
output = self.resConfUnit2(output)
output = nn.functional.interpolate(
output, scale_factor=2, mode="bilinear", align_corners=self.align_corners
)
output = self.out_conv(output)
return output
class Scratch(nn.Layer):
def __init__(self, in_channels=[256, 512, 1024, 1024], out_channels=256):
super().__init__()
self.out_c = 512
self.logit_scale = paddle.to_tensor(np.exp(np.log([1 / 0.07])))
self.layer1_rn = nn.Conv2D(
in_channels[0],
out_channels,
kernel_size=3,
stride=1,
padding=1,
bias_attr=False,
groups=1,
)
self.layer2_rn = nn.Conv2D(
in_channels[1],
out_channels,
kernel_size=3,
stride=1,
padding=1,
bias_attr=False,
groups=1,
)
self.layer3_rn = nn.Conv2D(
in_channels[2],
out_channels,
kernel_size=3,
stride=1,
padding=1,
bias_attr=False,
groups=1,
)
self.layer4_rn = nn.Conv2D(
in_channels[3],
out_channels,
kernel_size=3,
stride=1,
padding=1,
bias_attr=False,
groups=1,
)
self.refinenet1 = FeatureFusionBlock_custom(
out_channels, bn=True
)
self.refinenet2 = FeatureFusionBlock_custom(
out_channels, bn=True
)
self.refinenet3 = FeatureFusionBlock_custom(
out_channels, bn=True
)
self.refinenet4 = FeatureFusionBlock_custom(
out_channels, bn=True
)
self.head1 = nn.Conv2D(out_channels, self.out_c, kernel_size=1)
self.output_conv = nn.Sequential(
Interpolate(scale_factor=2, mode="bilinear", align_corners=True)
)
def forward(self, layer_1, layer_2, layer_3, layer_4, text_features):
layer_1_rn = self.layer1_rn(layer_1)
layer_2_rn = self.layer2_rn(layer_2)
layer_3_rn = self.layer3_rn(layer_3)
layer_4_rn = self.layer4_rn(layer_4)
path_4 = self.refinenet4(layer_4_rn)
path_3 = self.refinenet3(path_4, layer_3_rn)
path_2 = self.refinenet2(path_3, layer_2_rn)
path_1 = self.refinenet1(path_2, layer_1_rn)
image_features = self.head1(path_1)
imshape = image_features.shape
image_features = image_features.transpose(
(0, 2, 3, 1)).reshape((-1, self.out_c))
# normalized features
image_features = image_features / \
image_features.norm(axis=-1, keepdim=True)
text_features = text_features / \
text_features.norm(axis=-1, keepdim=True)
logits_per_image = self.logit_scale * image_features @ text_features.t()
out = logits_per_image.reshape(
(imshape[0], imshape[2], imshape[3], -1)).transpose((0, 3, 1, 2))
out = self.output_conv(out)
return out
6.4 语义分割模型
- 将上述的三个模块拼起来,就组成了一个文本驱动的语义分割模型
class LSeg(nn.Layer):
def __init__(self):
super().__init__()
self.clip = CLIPText()
self.vit = ViT()
self.scratch = Scratch()
def forward(self, images, texts):
layer_1, layer_2, layer_3, layer_4 = self.vit.forward(images)
text_features = self.clip.get_text_features(texts)
return self.scratch.forward(layer_1, layer_2, layer_3, layer_4, text_features)
7. 模型推理
7.1 可视化工具
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
def get_new_pallete(num_cls):
n = num_cls
pallete = [0]*(n*3)
for j in range(0,n):
lab = j
pallete[j*3+0] = 0
pallete[j*3+1] = 0
pallete[j*3+2] = 0
i = 0
while (lab > 0):
pallete[j*3+0] |= (((lab >> 0) & 1) << (7-i))
pallete[j*3+1] |= (((lab >> 1) & 1) << (7-i))
pallete[j*3+2] |= (((lab >> 2) & 1) << (7-i))
i = i + 1
lab >>= 3
return pallete
def get_new_mask_pallete(npimg, new_palette, out_label_flag=False, labels=None):
"""Get image color pallete for visualizing masks"""
# put colormap
out_img = Image.fromarray(npimg.squeeze().astype('uint8'))
out_img.putpalette(new_palette)
if out_label_flag:
assert labels is not None
u_index = np.unique(npimg)
patches = []
for i, index in enumerate(u_index):
label = labels[index]
cur_color = [new_palette[index * 3] / 255.0, new_palette[index * 3 + 1] / 255.0, new_palette[index * 3 + 2] / 255.0]
red_patch = mpatches.Patch(color=cur_color, label=label)
patches.append(red_patch)
return out_img, patches
7.2 加载模型
import paddle.vision.transforms as transforms
from paddlenlp.transformers.clip.tokenizer import CLIPTokenizer
model = LSeg()
state_dict = paddle.load('data/data169501/LSeg.pdparams')
model.set_state_dict(state_dict)
model.eval()
transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(
[0.5, 0.5, 0.5],
[0.5, 0.5, 0.5]
),
]
)
tokenizer = CLIPTokenizer.from_pretrained('openai/clip-vit-base-patch32')
7.3 模型预测
import cv2
import numpy as np
from PIL import Image
# 指定图像路径
img_path = 'images/cat.jpeg'
# 指定类别标签
labels = ['plant', 'grass', 'cat', 'stone', 'other']
image = cv2.imread(img_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
h, w = image.shape[:2]
image = image[:-(h%32) if h%32 else None, :-(w%32) if w%32 else None]
images = transform(image).unsqueeze(0)
image = Image.fromarray(image).convert("RGBA")
texts = tokenizer(labels, padding=True, return_tensors="pd")['input_ids']
with paddle.no_grad():
results = model.forward(images, texts)
results = paddle.argmax(results, 1)
results = results.numpy()
new_palette = get_new_pallete(len(labels))
mask, patches = get_new_mask_pallete(results, new_palette, out_label_flag=True, labels=labels)
seg = mask.convert("RGBA")
out = Image.blend(image, seg, alpha=0.5)
plt.axis('off')
plt.imshow(image)
plt.figure()
plt.axis('off')
plt.imshow(out)
plt.figure()
plt.legend(handles=patches, loc='upper right', bbox_to_anchor=(1.5, 1), prop={'size': 20})
plt.axis('off')
plt.imshow(seg)
<matplotlib.image.AxesImage at 0x7ff189365f10>



8. 总结
- 简单介绍 LSeg 模型的思路和模型,并使用作者提供的预训练模型完成了模型的推理预测
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 1
1- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)