
PPSIG:PMBANet深度图超分辨率重建模型复现
使用Paddle框架对PMBNet模型进行复现
·
PMBANet深度图超分辨率重建模型复现
0. 项目背景
- 深度信息是感知三维世界的重要信息之一,其在近年来火热的自动驾驶、自动化物流、AR和VR等场景都起着重要的作用。常用的深度信息设备包括激光雷达、ToF等设备
- 深度信息设备采集的深度信息往往存在信息稀疏、分辨率较低等问题,很难在实际的生产中获取高分辨率、高质量的深度图
- 因此,需要有效的预加工深度超分辨率 (DSR) 技术来从退化的低分辨率 (LR) 对应深度图中产生高分辨率的深度图输出
深度图转点云展示超分效果:

1. 项目简介
-
本项目主要介绍对深度图超分辨率重建模型PMBANet的复现
-
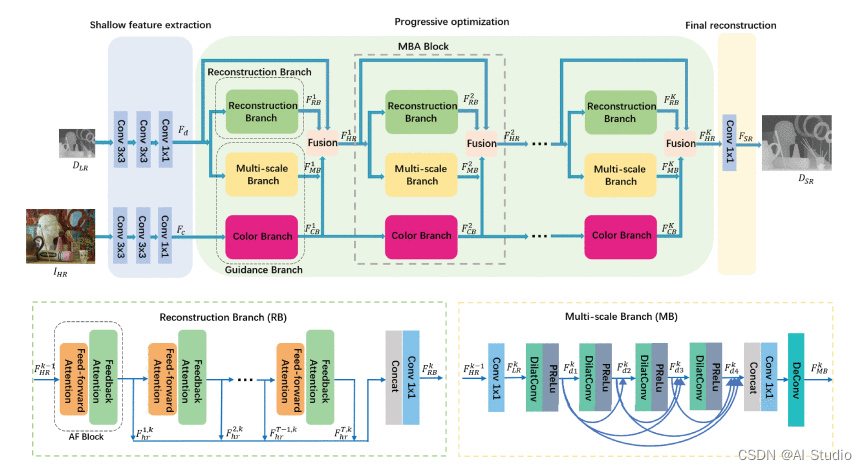
PMBANet是叶昕辰老师团队在2019年发表在IEEE Transactions on Image Processing杂志上的一篇论文<<PMBANet: Progressive Multi-Branch Aggregation Network for Scene Depth Super-Resolution>>。论文针对深度图边界很难重建,尤其是在放大倍数较大的情况下,场景中精细结构和微小物体上的深度区域被下采样退化严重退化破坏的问题,提出一个渐进式多分枝聚合网络PMBANet,网络结构如下图所示:
-
如图所示,网络主要包含了三个部分浅层特征提取、渐进式优化以及最后的重建模块。
2. 模型介绍
- 模型主要分为三部分,浅层特征提取和最后的重建模块比较简单。浅层特征提取模块由三层卷积层堆叠而成,分别从低分辨率的深度图和高分辨率的彩色图中提取浅层特征。最后的重建模块就是一个1×1的卷积层,用于将特征融合得到的最后特征图重建为高分辨率的深度图
- 渐进式优化模块是该模型的特点。该模块由多个MBA block组成,也就是所谓的多分支聚合模块。MBA中包含两个分支,分别是重建分支和指导分支
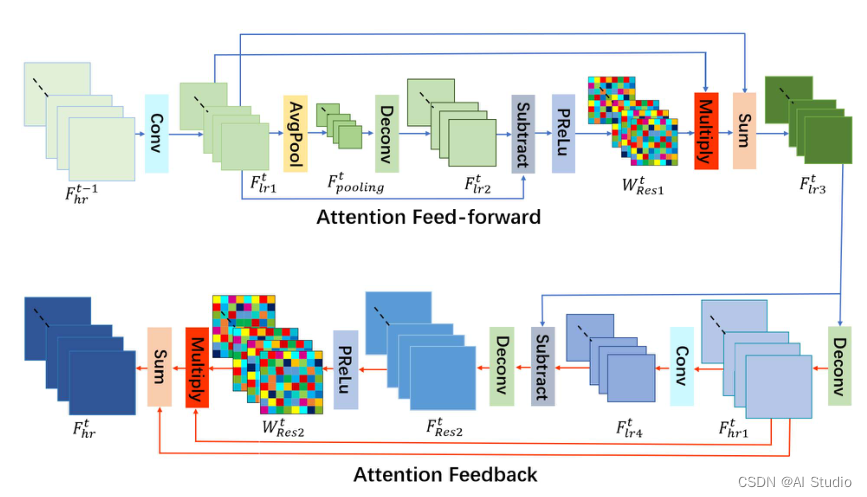
- 重建分支是基于前馈和反馈注意力模块(AF)和最后的卷积层组成,AF的结构如上图所示。由图可以看出,前馈和回馈可以分别视为“高到低”和“低到高”的流。注意力前馈模块通过将HR表示投影到LR空间域来增强深度边界的特征表示,并突出LR空间中的高频特征。相反,注意力反馈模块将LR特征映射回HR空间域,并进一步增强HR空间中的高频特征。通过注意前馈和反馈的交替过程,分支逐渐使重建误差更小,从而更好地恢复深度细节。(注:这里所说的HR,是由LR直接通过反卷积得到的特征图)
- 指导分支中又包含了两个分支,分别是多尺度指导分支和颜色指导分支,可以同时有效地提取多尺度表示和颜色信息,以帮助重建恢复深度细节
- 多尺度指导分支的结构如总体结构图中的右下角图片所示,由四个扩展卷积层(DilatConv)、PReLu、1×1卷积层和反卷积层组成,并且使用了稠密链接来缓解梯度消失的问题,更多细节可以查看原论文
- 颜色指导分支其实就是多个卷积模块堆叠在一起,而且值得注意的是并不是所有的MBA中都含有颜色指导分支,只是在前期加入,因为深度信息和颜色信息在深层网络的时候不一致会带来伪影等影响。另外,颜色指导分支的引入对于比较难重建的尺度(如×8、×16)有较好效果,对于小尺度(×2与×4)重建则会带来不好的影响
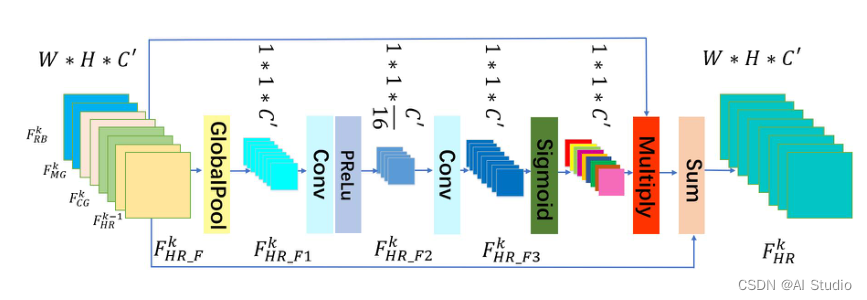
- 除了重建分支和指导分支,MBA中还有融合模块,结构如下图所示,目标是为了选择有用的信息进行融合,所以用到了通道注意力模块,更多细节可看原论文
3. 深度图超分辨率
- 注: 论文训练所用训练集为Middleburry数据集处理得到的RGB-D数据,但是并没有公开,而Middleburry官网上提供的原始数据(RGB与视差图)由于缺少基线长度这一参数而没法计算得到深度图,所以缺少数据,本项目暂不提供训练相关的代码
- 从论文中可知,在×2、×4尺度的超分任务不使用颜色指导模块的模型性能更好,而×8与×16尺度有颜色指导模块超分性能更强,所以本项目分别展示如何使用不同的模型
3.1 不含颜色指导分支的模型
# 创建文件夹,将数据集挂载的权重复制到该文件夹下
!mkdir -p PMBNet_Paddle/no_color-guided/weights
!cp data/data170167/PMBA_x2.pdparams PMBNet_Paddle/no_color-guided/weights/
!cp data/data170167/PMBA_x4.pdparams PMBNet_Paddle/no_color-guided/weights/
%cd /home/aistudio/PMBNet_Paddle/no_color-guided/
/home/aistudio/PMBNet_Paddle/no_color-guided
- ×2尺度的深度图重建
!python test.py --model_type PMBAX2 --upscale_factor 2 --model ./weights/PMBA_x2.pdparams --test_dataset ./testx2/
Namespace(gpu=0, gpu_mode=True, gpus=1, input_dir='./data/', model='./weights/PMBA_x2.pdparams', model_type='PMBAX2', output='Results/', seed=123, testBatchSize=1, test_dataset='./testx2/', threads=0, upscale_factor=2)
===> Loading datasets
===> Building model
W0927 23:51:59.122156 7285 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0927 23:51:59.126549 7285 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
Pre-trained SR model is loaded.<---------------------------->
===> Processing: 5.png || Timer: 2.0581 sec.
===> Processing: 1.png || Timer: 0.0616 sec.
===> Processing: 4.png || Timer: 0.0615 sec.
===> Processing: 2.png || Timer: 0.0636 sec.
===> Processing: 6.png || Timer: 0.0619 sec.
===> Processing: 3.png || Timer: 0.0609 sec.
# 计算指标与论文对照,论文没有给×2尺度的结果
!python Results/mad_rmse.py --dataset_pre ./Results/testx2
mad: [0.07584498643207283, 0.06092984068627451, 0.07811952906162464, 0.06108326631433823, 0.0592058112307423, 0.0668600643382353]
rmse: [0.5750953291455617, 0.3830685436102024, 0.418539536453762, 0.39340280707200387, 0.3644222958672261, 0.4276262391009783]
psnr: [4.8052031935000645, 8.334470189125051, 7.565270220430361, 8.103250911133223, 8.767901202812258, 7.378713087640094]
ssim: [0.9999999971697108, 0.999999999587187, 0.9999999992795167, 0.9999999998995585, 0.9999999990365096, 0.9999999996787082]
import matplotlib.pyplot as plt
%matplotlib inline
from PIL import Image
def show_result(lq_path, dsr_path, start, size, scale):
lq = Image.open(lq_path)
box = (start, start, start+size, start+size)
lq = lq.crop(box)
plt.subplot(121)
plt.imshow(lq)
plt.axis('off')
dsr = Image.open(dsr_path)
box = (start*scale, start*scale, start*scale+scale*size, start*scale+scale*size)
dsr = dsr.crop(box)
plt.subplot(122)
plt.imshow(dsr)
plt.axis('off')
plt.show()
lq_path = r"./data/testx2/6.png"
dsr_path = r"./Results/testx2/6.png"
show_result(lq_path, dsr_path, start=120,size=160, scale=2)

- ×4尺度的深度图重建
!python test.py --model_type PMBAX4 --upscale_factor 4 --model ./weights/PMBA_x4.pdparams --test_dataset ./testx4/
Namespace(gpu=0, gpu_mode=True, gpus=1, input_dir='./data/', model='./weights/PMBA_x4.pdparams', model_type='PMBAX4', output='Results/', seed=123, testBatchSize=1, test_dataset='./testx4/', threads=0, upscale_factor=4)
===> Loading datasets
===> Building model
W0928 00:52:16.082026 15449 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0928 00:52:16.086320 15449 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
Pre-trained SR model is loaded.<---------------------------->
===> Processing: 6.png || Timer: 1.8666 sec.
===> Processing: 3.png || Timer: 0.0622 sec.
===> Processing: 5.png || Timer: 0.0559 sec.
===> Processing: 1.png || Timer: 0.0554 sec.
===> Processing: 4.png || Timer: 0.0553 sec.
===> Processing: 2.png || Timer: 0.0563 sec.
- 计算指标与论文对照,在
mad这一项(越小效果越好),论文中展示的是有颜色指导模块的模型结果,依次为 [0.26, 0.15, 0.19, 0.17, 0.16, 0.17],迁移权重为Paddle的结果如下,可以看到指标均比论文展示的效果好
!python Results/mad_rmse.py --dataset_pre ./Results/testx4
mad: [0.22543001575630253, 0.13487641150210083, 0.17220257243522408, 0.1509988223805147, 0.13572987788865545, 0.16232335707720588]
rmse: [1.9962262793502012, 0.8924387368733661, 0.9412713737617728, 1.1093080059514644, 0.8270734993664964, 1.399244191006765]
psnr: [-6.004195371323813, 0.9884317429941026, 0.5257029802040544, -0.9010429466627823, 1.6491178875241477, -2.917870251987082]
ssim: [0.9999999703374539, 0.9999999880737163, 0.9999999980193652, 0.999999959717816, 0.9999999216556196, 0.9999999950189606]
# 可视化展示
lq_path = r"./data/testx4/6.png"
dsr_path = r"./Results/testx4/6.png"
show_result(lq_path, dsr_path, start=60, size=80, scale=4)

3.2 含颜色指导分支的模型
# 新建文件夹
%cd /home/aistudio/
!mkdir -p PMBNet_Paddle/color-guided/weights/
/home/aistudio
!cp data/data170167/PMBA_color_x4.pdparams PMBNet_Paddle/color-guided/weights/
!cp data/data170167/PMBA_color_x8.pdparams PMBNet_Paddle/color-guided/weights/
!cp data/data170167/PMBA_color_x16.pdparams PMBNet_Paddle/color-guided/weights/
%cd PMBNet_Paddle/color-guided/
/home/aistudio/PMBNet_Paddle/color-guided
- ×8尺度的深度图超分重建
!python test.py --model_type PMBAX8 --upscale_factor 8 --model ./weights/PMBA_color_x8.pdparams --test_dataset ./testx8/
Namespace(gpu_mode=True, gpus=1, input_dir='data', model='./weights/PMBA_color_x8.pdparams', model_type='PMBAX8', output='Results/', seed=123, testBatchSize=1, test_dataset='./testx8/', test_rgb_dataset='test_color/', threads=0, upscale_factor=8)
===> Loading datasets
===> Building model
W0928 01:10:34.982805 17937 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0928 01:10:34.986948 17937 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
Pre-trained SR model is loaded.<---------------------------->
===> Processing: 2.png || Timer: 1.7038 sec.
===> Processing: 6.png || Timer: 0.0593 sec.
===> Processing: 3.png || Timer: 0.0576 sec.
===> Processing: 5.png || Timer: 0.0588 sec.
===> Processing: 1.png || Timer: 0.0584 sec.
===> Processing: 4.png || Timer: 0.0585 sec.
- 和论文指标对照,在×8尺度下为[0.51, 0.26, 0.32, 0.34, 0.26, 0.34],与测试的结果基本一致
!python Results/mad_rmse.py --dataset_pre ./Results/testx8/
mad: [0.5082542782738095, 0.2632923286502101, 0.3177644104516807, 0.3146872127757353, 0.2646983598126751, 0.3349200080422794]
rmse: [3.625601753275494, 1.6836909674182365, 1.472101374900245, 2.1930506651987494, 1.4088587982482885, 2.7405493577746234]
psnr: [-11.187601964006358, -4.525247640409098, -3.3587543663858628, -6.8209733026071735, -2.9773493694329445, -8.75675256396898]
ssim: [0.9999994280349453, 0.9999999348916622, 0.9999999681656758, 0.999999905892383, 0.999999980861976, 0.9999998420293376]
# 可视化展示
lq_path = r"./data/testx8/6.png"
dsr_path = r"./Results/testx8/6.png"
show_result(lq_path, dsr_path, start=30, size=40, scale=8)

- ×16尺度下的超分辨率重建
!python test.py --model_type PMBAX16 --upscale_factor 16 --model ./weights/PMBA_color_x16.pdparams --test_dataset ./testx16/
Namespace(gpu_mode=True, gpus=1, input_dir='data', model='./weights/PMBA_color_x16.pdparams', model_type='PMBAX16', output='Results/', seed=123, testBatchSize=1, test_dataset='./testx16/', test_rgb_dataset='test_color/', threads=0, upscale_factor=16)
===> Loading datasets
===> Building model
W0928 01:19:22.446305 19140 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0928 01:19:22.450486 19140 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
Pre-trained SR model is loaded.<---------------------------->
===> Processing: 5.png || Timer: 1.7113 sec.
===> Processing: 1.png || Timer: 0.0444 sec.
===> Processing: 4.png || Timer: 0.0407 sec.
===> Processing: 2.png || Timer: 0.0398 sec.
===> Processing: 6.png || Timer: 0.0459 sec.
===> Processing: 3.png || Timer: 0.0435 sec.
- 对照论文指标,论文在×16尺度下的
mad为[1.22, 0.59, 0.59, 0.71, 0.67, 0.74],可以明显看到测试结果优于论文
!python Results/mad_rmse.py --dataset_pre ./Results/testx16/
mad: [1.1029021960346639, 0.48977413230917366, 0.5889273678221288, 0.7056317497702206, 0.5249830400910365, 0.6809318991268383]
rmse: [5.937025276337593, 2.5101587247768182, 2.0979781141296368, 3.176103857474606, 2.4584956942954057, 4.739212835322279]
psnr: [-15.471377957974003, -7.99402368153502, -6.4360190674052395, -10.03789390526908, -7.813389040439951, -13.51412426105461]
ssim: [0.9999978768713241, 0.9999990646401361, 0.9999994423060258, 0.9999976843608124, 0.9999990936328861, 0.9999997132045745]
# 可视化展示,效果很好,边界很清晰
lq_path = r"./data/testx16/6.png"
dsr_path = r"./Results/testx16/6.png"
sr_path = r"./Results/testx16/6.png"
show_result(lq_path, dsr_path, start=15, size=20, scale=16)

4. 总结与展望
4.1 总结
- 笔者第一次接触深度超分辨率重建,感觉和普通的图像超分有一些共通的地方,比如在这篇文章大体的结构和前几年超分经典的结构类似,都是浅层特征提取、深层特征提取、重建模块的组合,效果确实比较好,尤其是在大尺度上让人觉得惊艳
- 由于数据集还没有开源,所以缺少训练部分的代码,等拿到数据之后会补上的
4.2 展望
- 之后计划写一个GitHub的repo,将深度超分辨率重建的一些经典模型集成进来,方便用户使用
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)