
PP-YOLOE实现自动驾驶场景检测
利用PaddleDetection中的PP-YOLOE对自动驾驶交通场景下的各种目标类别进行检测,并进行推理部署。
PP-YOLOE实现自动驾驶场景检测
一、项目简介
项目背景:
该项目着眼于基于视觉深度学习的自动驾驶场景,旨在对车载摄像头采集的视频数据进行道路场景解析,为自动驾驶提供一种解决思路。
项目意义:
首先,在行车检测方面,现有检测模型可以实现多种类型的车辆检测,然而,一方面,检测模型在速度和精度上存在矛盾,对于精度较高的模型,如两阶段检测网络Faster R-CNN,其FPS较低,无法满足实时检测,因此其商用价值受到很大限制。另一方面,对于道路场景的目标检测,许多数据集会对场景中很多类型的目标进行标注,然而,经过我们的实践和观察,使用这种数据集训练模型并不能带来很好的效果。由于目标类别本身存在多样性,例如各式各样的货车,电瓶车,亦或是各式各样的路标和交通灯等,这会对模型的学习造成混淆,最终导致模型在现实场景中对很多目标造成误判,极大的影响模型在现实中的应用。为解决这两个问题,我们在本项目中使用飞桨开源的高精度实时检测器PP-YOLOE作为检测模型,在检测速度和检测精度上实现了较好的权衡。
二、数据集介绍
数据集地址:BDD100K 自动驾驶数据集
视频数据: 超过1,100小时的100000个高清视频序列在一天中许多不同的时间,天气条件,和驾驶场景驾驶经验。视频序列还包括GPS位置、IMU数据和时间戳。
道路目标检测:2D边框框注释了100,000张图片,用于公交、交通灯、交通标志、人、自行车、卡车、摩托车、小汽车、火车和骑手。
实例分割:超过10,000张具有像素级和丰富实例级注释的不同图像。
引擎区域:从10万张图片中学习复杂的可驾驶决策。
车道标记:10万张图片上多类型的车道标注,用于引导驾驶。


三、技术路线
1、PaddleDetection简介:
PaddleDetection是飞桨推出的端到端目标检测开发套件,旨在帮助开发者更快更好地完成检测模型的训练、精度速度优化到部署全流程。PaddleDetection以模块化的设计实现了多种主流目标检测算法,并且提供了丰富的数据增强、网络组件、损失函数等模块,集成了模型压缩和跨平台高性能部署能力。目前基于PaddleDetection已经完成落地的项目涉及工业质检、遥感图像检测、无人巡检等多个领域。
PaddleDetection模块式地提供YOLOv3,EfficientDet等10余种目标检测算法、ResNet-vd,MobileNetV3等10余种backbone,以及sync batch norm, IoU Loss、可变性卷积等多个扩展模块,这些模块可以定制化地自由组合,灵活配置;同时预置提供100余种训练好的检测模型。
在YOLOv3系列模型上,通过一键式剪裁+蒸馏的方案,YOLOv3_MobileNetV1剪裁了近70%的计算量,在精度基本无损或略有提升的情况,模型在高通855芯片上加速2.3倍,GPU上也有60%的加速;YOLOv3-ResNet50vd-DCN剪裁模型,精度提升了0.6,GPU上加速20%。同时,对应压缩后的模型、压缩脚本和操作方法均可以在Github上获取。
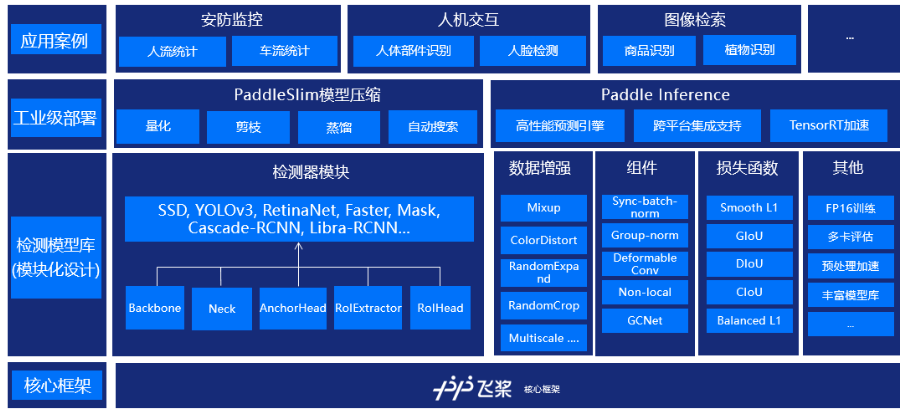
2、模型库链接:
PaddleDetection代码GitHub链接:https://github.com/PaddlePaddle/PaddleDetection
PaddleDetection代码Gitee链接:https://gitee.com/paddlepaddle/PaddleDetection
PaddleDetection文档链接:https://paddledetection.readthedocs.io/
# 克隆paddledetection仓库
# gitee 国内下载比较快
!git clone https://gitee.com/paddlepaddle/PaddleDetection.git
# 导入package
!pip install -r ~/PaddleDetection/requirements.txt
# 继续安装依赖库
!python3 ~/PaddleDetection/setup.py install
四、PP-YOLOE
PP-YOLOE是基于PP-YOLOv2的卓越的单阶段Anchor-free模型,超越了多种流行的YOLO模型。PP-YOLOE有一系列的模型,即s/m/l/x,可以通过width multiplier和depth multiplier配置。PP-YOLOE避免了使用诸如Deformable Convolution或者Matrix NMS之类的特殊算子,以使其能轻松地部署在多种多样的硬件上。更多细节可以参考我们的report。

- PP-YOLOE基于PP-YOLOv2进行改进,PP-YOLOv2是anchor-based的方法,resnet50vd作为backbone,neck是PAN,加入SPP layer和DropBlock,head是lightweight IoU aware head,在此基础上,PP-YOLOE按照FCOS的方法设计为anchor-free,但是正样本的匹配是将距离GT中心最近的Anchor point作为正样本。

- 设计了一个新的基本块叫做RepResBlock,结合了残差连接和密集连接,由该模块构成的backbone成为CSPRepResNet。在这个backbone中首先是三个卷积层的stem,然后是四个串行的CSPRepResStage,在每一个stage还加入了通道注意力模块ESE,在backbone设计中还将concat替换为element-wise add。推理的时候需要重参数化。
- neck使用RepResBlock作为基本块,但是不包括shortcut和ESE。
- 样本匹配策略TAL:包括动态样本匹配和任务对齐损失。
- Efficient Task-aligned Head (ET-head):使用ESE模块替换TOOD模型中的layer attention,将分类分支的对齐简化,将回归分支替换为DFL loss。
- 分类Loss使用VFL ,回归loss使用DFL,并且均采取IOU-aware。

PP-YOLOE由以下方法组成
- 可扩展的backbone和neck
- Task Alignment Learning
- Efficient Task-aligned head with DFL和VFL
- SiLU(Swish)激活函数
五、数据准备
# 解压数据集
# !mkdir /home/aistudio/PaddleDetection/dataset/
!unzip -oq /home/aistudio/data/data124804/bdd100k_det_20_labels_trainval.zip -d /home/aistudio/PaddleDetection/dataset/
!unzip -oq /home/aistudio/data/data124805/bdd100k_images_100k.zip -d /home/aistudio/PaddleDetection/dataset/
# json文件转换为xml格式
import json
import os
from xml.dom.minidom import parse
from xml.dom import minidom
# categorys = ['car', 'bus', 'person', 'bike', 'truck', 'motor', 'train', 'rider', 'traffic sign', 'traffic light']
categorys = set()
def paraseJson(File):
file = open(File)
f = json.load(file)
objects = f
objs = []
print("picture num: ", len(objects))
for i in objects:
if(i.get('labels') == None):
continue
obj_label = []
for j in i['labels']:
obj = []
obj.append(int(j['box2d']['x1']))
obj.append(int(j['box2d']['y1']))
obj.append(int(j['box2d']['x2']))
obj.append(int(j['box2d']['y2']))
obj.append(j['category'])
categorys.add(j['category'])
obj_label.append(obj)
tmp = []
tmp.append(i['name'])
tmp.append(obj_label)
objs.append(tmp)
return objs
def save_xml(objs, dstDir):
for i in objs:
name = ' '
num = 0
dom = minidom.Document()
annotate_node = dom.createElement("annotation")
for j in i:
if num == 0:
name = j
num += 1
name_node = dom.createElement("filename")
name_node.appendChild(dom.createTextNode(str(name)))
annotate_node.appendChild(name_node)
size_node = dom.createElement("size")
width_node = dom.createElement("width")
width_node.appendChild(dom.createTextNode(str(1280)))
size_node.appendChild(width_node)
height_node = dom.createElement("height")
height_node.appendChild(dom.createTextNode(str(720)))
size_node.appendChild(height_node)
depth_node = dom.createElement("depth")
depth_node.appendChild(dom.createTextNode(str(3)))
size_node.appendChild(depth_node)
annotate_node.appendChild(size_node)
continue
for t in j:
object = dom.createElement("object")
name_label_node = dom.createElement("name")
name_label_node.appendChild(dom.createTextNode(str(t[4])))
object.appendChild(name_label_node)
bndbox_node = dom.createElement("bndbox")
xmin_node = dom.createElement("xmin")
xmin_node.appendChild(dom.createTextNode(str(t[0])))
ymin_node = dom.createElement("ymin")
ymin_node.appendChild(dom.createTextNode(str(t[1])))
xmax_node = dom.createElement("xmax")
xmax_node.appendChild(dom.createTextNode(str(t[2])))
ymax_node = dom.createElement("ymax")
ymax_node.appendChild(dom.createTextNode(str(t[3])))
bndbox_node.appendChild(xmin_node)
bndbox_node.appendChild(ymin_node)
bndbox_node.appendChild(xmax_node)
bndbox_node.appendChild(ymax_node)
object.appendChild(bndbox_node)
annotate_node.appendChild(object)
dom.appendChild(annotate_node)
with open(dstDir + '{}.xml'.format(name[:-4]), 'w') as f:
dom.writexml(f, addindent=' ', encoding='utf-8')
def main(srcDir, dstDir):
for dirpath, dirnames, filenames in os.walk(srcDir):
for filepath in filenames:
fileName = os.path.join(dirpath, filepath)
print("processing: {}".format(fileName))
objs = paraseJson(str(fileName))
print('has label: ', len(objs))
if 'train' in fileName:
dst = os.path.join(dstDir, 'train/')
else:
dst = os.path.join(dstDir, 'val/')
if not os.path.exists(dst):
os.makedirs(dst)
save_xml(objs, dst)
os.chdir('/home/aistudio/PaddleDetection/dataset/bdd100k')
srcDir = './labels/det_20'
dstDir = 'labels_xml/'
main(srcDir, dstDir)
with open('labels.txt', 'w') as f:
for label in categorys:
f.write(label + '\n')
processing: ./labels/det_20/det_val.json
picture num: 10000
has label: 10000
processing: ./labels/det_20/det_train.json
picture num: 69863
has label: 69853
# 生成train_list.txt和val_list.txt
import os
os.chdir('/home/aistudio/PaddleDetection/dataset/bdd100k/')
base_dir = 'images/100k/'
label_dir = 'labels_xml/'
# with open('train_list.txt', 'w') as train:
# for filename in os.listdir(label_dir + 'train'):
# train.write(base_dir + 'train/' + filename.split('.')[0] + '.jpg' + " " + label_dir + 'train/' + filename + '\n')
with open('val_list.txt', 'w') as val:
for filename in os.listdir(label_dir + 'val'):
val.write(base_dir + 'val/' + filename.split('.')[0] + '.jpg' + " " + label_dir + 'val/' + filename + '\n')
# 查看数据集数量
import os
os.chdir('/home/aistudio/PaddleDetection/dataset/bdd100k/')
base_dir = 'images/100k/'
imgs = os.listdir(base_dir + 'train')
print('训练集图片总量: {}'.format(len(imgs)))
imgs = os.listdir(base_dir + 'val')
print('验证集图片总量: {}'.format(len(imgs)))
训练集图片总量: 70000
验证集图片总量: 10000
六、数据预处理
TrainReader:
sample_transforms:
- Decode: {}
- RandomDistort: {}
- RandomExpand: {fill_value: [123.675, 116.28, 103.53]}
- RandomCrop: {}
- RandomFlip: {}
batch_transforms:
- BatchRandomResize: {target_size: [320, 352, 384, 416, 448, 480, 512, 544, 576, 608, 640, 672, 704, 736, 768], random_size: True, random_interp: True, keep_ratio: False}
- NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True}
- Permute: {}
- PadGT: {}
batch_size: 20
shuffle: true
drop_last: true
use_shared_memory: true
collate_batch: true
- RandomCrop:随机裁剪图像。
- RandomFlip:实现图像的随机翻转(翻转概率为0.5)。
- RandomDistort:以一定的概率对图像进行随机像素内容变换,可包括亮度、对比度、饱和度、色相角度、通道顺序的调整,模型训练时的数据增强操作。
- BatchRandomResize:对一个批次中的图片随机指定尺寸,范围是[576, 608, 640, 672, 704],插值方式为随机插值,进行多尺度训练。
- Normalize:图像归一化,均值默认为[0.485, 0.456, 0.406]。长度应与图像通道数量相同。标准差默认为[0.229, 0.224, 0.225]。长度应与图像通道数量相同。
七、模型训练
本项目使用的配置文件是~/PaddleDetection/configs/ppyoloe/ppyoloe_crn_m_300e_coco.yml
包含的配置文件如下:
_BASE_: [
'../datasets/voc.yml',
'../runtime.yml',
'./_base_/optimizer_300e.yml',
'./_base_/ppyoloe_crn.yml',
'./_base_/ppyoloe_reader.yml',
]
- 训练阶段采用的学习率衰减策略为余弦衰减,最大迭代轮次为300。
# 开启训练
%cd ~/PaddleDetection
!python3 tools/train.py -c configs/ppyoloe/ppyoloe_crn_m_300e_coco.yml -r output/ppyoloe_crn_m_300e_coco/50.pdparams --eval
八、模型评估
# 评估 默认使用训练过程中保存的best_model
# -c 参数表示指定使用哪个配置文件
# -o 参数表示指定配置文件中的全局变量(覆盖配置文件中的设置),需使用单卡评估
%cd ~/PaddleDetection
!python tools/eval.py -c configs/ppyoloe/ppyoloe_crn_m_300e_coco.yml
/home/aistudio/PaddleDetection
Warning: import ppdet from source directory without installing, run 'python setup.py install' to install ppdet firstly
W0921 13:56:33.244480 707 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0921 13:56:33.248515 707 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[09/21 13:56:39] ppdet.utils.checkpoint INFO: Finish loading model weights: output/ppyoloe_crn_m_300e_coco/best_model.pdparams
[09/21 13:56:43] ppdet.engine INFO: Eval iter: 0
[09/21 13:57:32] ppdet.engine INFO: Eval iter: 100
[09/21 13:58:21] ppdet.engine INFO: Eval iter: 200
[09/21 13:59:10] ppdet.engine INFO: Eval iter: 300
[09/21 14:00:00] ppdet.engine INFO: Eval iter: 400
[09/21 14:00:48] ppdet.engine INFO: Eval iter: 500
[09/21 14:01:38] ppdet.engine INFO: Eval iter: 600
[09/21 14:02:27] ppdet.engine INFO: Eval iter: 700
[09/21 14:03:17] ppdet.engine INFO: Eval iter: 800
[09/21 14:04:06] ppdet.engine INFO: Eval iter: 900
[09/21 14:04:55] ppdet.engine INFO: Eval iter: 1000
[09/21 14:05:45] ppdet.engine INFO: Eval iter: 1100
[09/21 14:06:34] ppdet.engine INFO: Eval iter: 1200
[09/21 14:06:57] ppdet.metrics.metrics INFO: Accumulating evaluatation results...
[09/21 14:07:09] ppdet.metrics.metrics INFO: mAP(0.50, 11point) = 39.83%
[09/21 14:07:09] ppdet.engine INFO: Total sample number: 10000, averge FPS: 16.188732445157605
九、模型测试
# 首先生成测试集
# 随机采样
import shutil
import os
import numpy as np
os.chdir('/home/aistudio/PaddleDetection')
data_dir = "dataset/bdd100k/images/100k/test/"
pathlist= os.listdir(data_dir)
t = np.random.choice(pathlist, size=200, replace=False)
dst_dir = "dataset/static_test/"
if not os.path.exists(dst_dir):
os.mkdir(dst_dir)
for path in t:
src = data_dir + path
dst = dst_dir + path
shutil.copy(src, dst)
动态图测试
%cd ~/PaddleDetection
!python tools/infer.py -c configs/ppyoloe/ppyoloe_crn_m_300e_coco.yml \
--infer_dir=dataset/static_test \
--output_dir=dataset/result \
-o use_gpu=true \
-o weights=output/ppyoloe_crn_m_300e_coco/best_model.pdparams
测试效果可视化


静态图测试
# 将训练好的模型导出为静态图
%cd ~/PaddleDetection
!python tools/export_model.py -c configs/ppyoloe/ppyoloe_crn_m_300e_coco.yml \
-o weights=output/ppyoloe_crn_m_300e_coco/best_model.pdparams \
--output_dir=inference/
/home/aistudio/PaddleDetection
Warning: import ppdet from source directory without installing, run 'python setup.py install' to install ppdet firstly
[09/21 14:17:35] ppdet.utils.checkpoint INFO: Finish loading model weights: output/ppyoloe_crn_m_300e_coco/best_model.pdparams
[09/21 14:17:36] ppdet.engine INFO: Export inference config file to inference/ppyoloe_crn_m_300e_coco/infer_cfg.yml
[09/21 14:17:41] ppdet.engine INFO: Export model and saved in inference/ppyoloe_crn_m_300e_coco
导出文件结构如下
inference/ppyoloe_crn_m_300e_coco
|--infer_cfg.yml
|--model.pdmodel
|--model.pdiparams
|--model.pdiparams.info
PP-YOLOE静态图性能测试
在这里,随机从20000张测试集中选择200张图片进行性能测试,测试环境包括以下三种配置:
- CPU+4 Thread
- CPU+MKL+4 Thread
- GPU
# CPU测试推理模型(不开启mkldnn加速)
!python deploy/python/infer.py --model_dir=inference/ppyoloe_crn_m_300e_coco \
--image_dir dataset/static_test \
--output_dir dataset/static_result \
--device=CPU --batch_size=1 \
--cpu_threads=4
# CPU测试推理模型(开启mkldnn加速)
!python deploy/python/infer.py --model_dir=inference/ppyoloe_crn_m_300e_coco \
--image_dir dataset/static_test \
--output_dir dataset/static_result \
--device=CPU --batch_size=1 \
--cpu_threads=4 \
--enable_mkldnn=True
# GPU测试推理模型
!python deploy/python/infer.py --model_dir=inference/ppyoloe_crn_m_300e_coco \
--image_dir dataset/static_test \
--output_dir dataset/static_result \
--device=GPU --batch_size=1
测试结果
| ppyoloe_crn_m_coco | preprocess_time(ms) | inference_time(ms) | postprocess_time(ms) | average latency time(ms) |
|---|---|---|---|---|
| CPU | 71.80 | 1688.20 | 0.10 | 1760.10 |
| CPU+MKL | 66.50 | 683.60 | 0.10 | 750.11 |
| GPU | 27.70 | 52.20 | 0.00 | 79.96 |
可以看到,ppyoloe_crn_m_coco在开了MKL加速后推理速度快了约57%,而GPU模式下相比于MKL加速的CPU模式推理速度快了约89%。由此,在硬件只提供CPU的情况下,开启MKL加速可以大大提高推理速度,如果提供GPU,那么将会使得推理速度进一步大幅提升。
另外,开启MKL加速对前处理和后处理影响不大,然而,开启GPU加速则对前后处理和模型推理都有较大的提升。
项目总结
利用PP-YOLOE在大规模车辆数据集BDD100k上进行了50个epoch的预训练,并分进行了动态图和静态图的测试。
手动处理数据集,本次总共包含了自动驾驶场景中的13个常见类别,并提供了VOC格式的数据集。
项目作者
个人介绍:赵祎安 大连理工大学 计算机专业大三 大工飞桨领航团团长
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)