
【飞桨论文复现赛-图像超分辨率】TextSR-STT
基于飞桨深度学习框架搭建图像超分辨率模型,复现论文 《Scene Text Telescope: Text-Focused Scene Image Super-Resolution》
一、前言
本项目为百度论文复现赛《Scene Text Telescope: Text-Focused Scene Image Super-Resolution》论文复现代码。
依赖环境:
- paddlepaddle-gpu2.3.1
- python3.7
复现精度:
| Methods | easy | medium | hard | avg |
|---|---|---|---|---|
| 官方repo | 0.5979 | 0.4507 | 0.3418 | 0.4634 |
| 复现repo | 0.5911 | 0.4571 | 0.3418 | 0.4634 |
二、模型背景及其介绍
论文提出了一个聚焦文本的超分辨率框架,称为场景文本Telescope(STT)。在文本级布局方面,提出了一个基于Transformer的超分辨网络(TBSRN),包含一个自注意模块来提取序列信息,对任意方向的文本具有鲁棒性。在字符级的细节方面,提出了一个位置感知模块和一个内容感知模块来突出每个字符的位置和内容。通过观察一些字符在低分辨率条件下看起来难以区分,使用加权交叉熵损失解决。
1、 Scene Text Telescope

STT的总体架构如上图所示。在Pixel-Wise Supervision模块(绿色虚线框)中,首先通过Spatial Transformer Network(STN)对低分辨率的文本图像进行校正,以解决错位问题。校正后的图像进入一系列基于Transformer的超分辨率网络(TBSRN),然后通过像素变换上采样到超分辨率的文本图像。在Position-Aware模块(红色虚线帧)中,以相应的HR图像作为参考,对HR图像和SR图像的注意图进行L1损失监督。Content-Aware模块(蓝色虚线框架)提供了关于内容的线索,并使用了一个加权的交叉熵损失来区分可混淆的字符。
2、Pixel-Wise Supervision
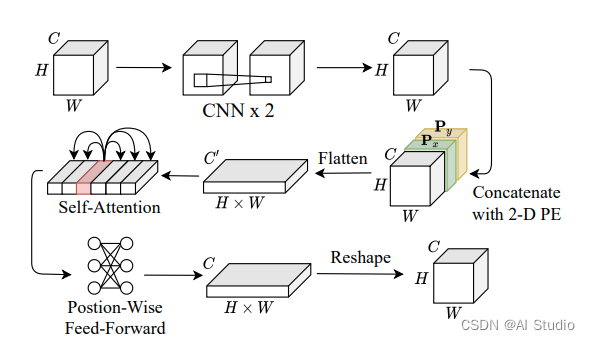
如上图,提出了一个基于Transformer的超分辨率网络(TBSRN),它主要包含一个自注意模块和一个Position-Wise Feed-Forward模块。由于自注意模块可以关联特征映射中的任何像素对,因此它对处理任意方向的文本图像具有鲁棒性。通过STN校正后,将图像输入两个连续的cnn,提取一个特征图,并进一步发送到自注意模块,捕获序列信息。在这种情况下,将一个二维位置编码(PE)与特征映射连接起来。然后将特征图与Px和Py连接,并平展为一个一维序列,依次发送到自注意模块和Position-Wise Feed-Forward模块。然后,生成的特征映射的大小被重塑为与输入图像相同的大小。最后,进行像素变换生成SR图像。
3、Position-Aware
为了避免场景文本图像中复杂背景的干扰,使用了一个位置感知模块来突出显示具有参考高分辨率图像的字符区域。首先使用包括Syn90k和SynthText在内的合成文本数据集预训练一个基于Transformer的识别模型,然后利用其在每个时间步长的参与区域作为位置线索。给定一个 HR 文本图像,Transformer 输出一个注意力映射列表 A H R = ( a 1 , a 2 , … , a l ) \mathbf{A}_{\mathrm{HR}}=\left(\mathbf{a}_{1}, \mathbf{a}_{2}, \ldots, \mathbf{a}_{l}\right) AHR=(a1,a2,…,al),其中 a i \mathbf{a}_{i} ai表示第 i {i} i个时间步的注意力映射, l {l} l是其文本标签的长度。使用字符之间经常有明显间隙的 HR 图像,利用它们的注意力图作为字符区域的标签。 使用一个L1损失来监督以下两张注意力映射列表:
L POS = ∥ A H R − A S R ∥ 1 \mathcal{L}_{\text {POS }}=\left\|\mathbf{A}_{\mathrm{HR}}-\mathbf{A}_{\mathrm{SR}}\right\|_{1} LPOS =∥AHR−ASR∥1
4、Content-Aware
给定超分辨率的图像,使用一个预先训练过的 Transformer(与在Position-Aware模块中使用的 Transformer 相同)来预测一个文本序列。有一些字符对在低分辨率条件下看起来很相似,这对于超分辨率过程来说是很困难的。为了解决这个问题,文章首先使用EMNIST训练一个变分自动编码器(VAE)来获得每个字符的二维潜在表示。
三、数据集
TextZoom中的数据集来自两个超分数据集RealSR和SR-RAW,两个数据集都包含LR-HR对,TextZoom有17367对训数据和4373对测试数据,
全部资源下载地址
- TextZoom dataset
- Pretrained weights of CRNN
- Pretrained weights of Transformer-based recognizer
数据集目录结构:
mydata
├── train1
├── train2
├── confuse.pkl
├── crnn.pdparams
├── pretrain_transformer.pdparams
└── test
├── easy
├── medium
└── hard
四、模型运行
1、加载环境
%cd /home/aistudio/work/Paddle-TextSR-STT/
!pip install -r requirement.txt
2、解压数据集
%cd /home/aistudio/work/Paddle-TextSR-STT/dataset/
!unzip -oq /home/aistudio/data/data171370/stt_data.zip
3、训练
模型训练权重和日志保存到./checkpoint/tbsrn_crnn_train/文件下
可以将训练好的模型权重下载 解压后放在本repo/checkpoint/下,直接运行评估和预测。
%cd /home/aistudio/work/Paddle-TextSR-STT
!python train.py --batch_size 16 --epochs 300 --output_dir './checkpoint/'
4、测试
通过模型训练后,执行测试。
# 加载训练好的模型权重放在本repo/checkpoint/下
%cd /home/aistudio/work/Paddle-TextSR-STT/checkpoint/
!unzip -oq /home/aistudio/data/data171746/tbsrn_crnn_train.zip
/home/aistudio/work/Paddle-TextSR-STT/checkpoint
%cd /home/aistudio/work/Paddle-TextSR-STT
!python eval.py --test_data_dir './dataset/mydata/test'
5、预测
加载./checkpoint/tbsrn_crnn_train/model_best.pdparams文件,模型提升demo1.png图片分辨率生成sr_demo1.png,并使用CRNN模型识别验证效果。
demo1.png图片:

识别结果:vuscaalda
sr_demo1.png图片:

识别结果:musicaalta
%cd /home/aistudio/work/Paddle-TextSR-STT
!python predict.py --image_name demo1.png
五、训练推理开发
飞桨除了基本的模型训练和预测,还提供了支持多端多平台的高性能推理部署工具。
1、模型推理
包含模型动转静脚本(export_model.py)以及模型基于 Paddle Inference 的预测脚本(infer.py)。
%cd /home/aistudio/work/Paddle-TextSR-STT
!python3 deploy/export_model.py
%cd /home/aistudio/work/Paddle-TextSR-STT
!python3 deploy/infer.py --image_name demo1.png
2、训推自动化测试
%cd /home/aistudio/work/Paddle-TextSR-STT
!bash test_tipc/test_train_inference_python.sh test_tipc/configs/TextSR_STT/train_infer_python.txt lite_train_lite_infer
六、代码解析
1、代码结构
|--demo # 测试使用的样例图片
|--deploy # 预测部署相关
|--export_model.py # 导出模型
|--infer.py # 部署预测
|--dataset # 训练和测试数据集
|--interfaces # 模型基础模块
|--loss # 训练损失
|--utils # 模型工具文件
|--model # 论文模块
|--test_tipc # tipc代码
|--predict.py # 预测代码
|--eval.py # 评估代码
|--train.py # 训练代码
|----README.md # 用户手册
2、TBSRN模型
class TBSRN(nn.Layer):
def __init__(self, scale_factor=2, width=128, height=32, STN=True, srb_nums=5, mask=False, hidden_units=32, input_channel=3):
super(TBSRN, self).__init__()
self.conv = nn.Conv2D(input_channel, 3, 3, 1, 1)
self.bn = nn.BatchNorm2D(3)
self.relu = nn.ReLU()
in_planes = 3
if mask:
in_planes = 4
assert math.log(scale_factor, 2) % 1 == 0
upsample_block_num = int(math.log(scale_factor, 2))
self.block1 = nn.Sequential(
nn.Conv2D(in_planes, 2 * hidden_units, kernel_size=9, padding=4),
nn.PReLU()
# nn.ReLU()
)
self.srb_nums = srb_nums
for i in range(srb_nums):
setattr(self, 'block%d' % (i + 2), RecurrentResidualBlock(2 * hidden_units))
setattr(self, 'block%d' % (srb_nums + 2),
nn.Sequential(
nn.Conv2D(2 * hidden_units, 2 * hidden_units, kernel_size=3, padding=1),
nn.BatchNorm2D(2 * hidden_units)
))
# self.non_local = NonLocalBlock2D(64, 64)
block_ = [UpsampleBLock(2 * hidden_units, 2) for _ in range(upsample_block_num)]
block_.append(nn.Conv2D(2 * hidden_units, in_planes, kernel_size=9, padding=4))
setattr(self, 'block%d' % (srb_nums + 3), nn.Sequential(*block_))
self.tps_inputsize = [height // scale_factor, width // scale_factor]
tps_outputsize = [height // scale_factor, width // scale_factor]
num_control_points = 20
tps_margins = [0.05, 0.05]
self.stn = STN
if self.stn:
self.tps = TPSSpatialTransformer(
output_image_size=tuple(tps_outputsize),
num_control_points=num_control_points,
margins=tuple(tps_margins))
self.stn_head = STNHead(
in_planes=in_planes,
num_ctrlpoints=num_control_points,
activation='none')
def forward(self, x):
if self.stn and self.training:
# x = F.interpolate(x, self.tps_inputsize, mode='bilinear', align_corners=True)
_, ctrl_points_x = self.stn_head(x)
x, _ = self.tps(x, ctrl_points_x)
block = {'1': self.block1(x)}
for i in range(self.srb_nums + 1):
block[str(i + 2)] = getattr(self, 'block%d' % (i + 2))(block[str(i + 1)])
block[str(self.srb_nums + 3)] = getattr(self, 'block%d' % (self.srb_nums + 3)) \
((block['1'] + block[str(self.srb_nums + 2)]))
output = paddle.tanh(block[str(self.srb_nums + 3)])
return output
class RecurrentResidualBlock(nn.Layer):
def __init__(self, channels):
super(RecurrentResidualBlock, self).__init__()
self.conv1 = nn.Conv2D(channels, channels, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2D(channels)
self.gru1 = GruBlock(channels, channels)
# self.prelu = nn.ReLU()
self.prelu = mish()
self.conv2 = nn.Conv2D(channels, channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2D(channels)
self.gru2 = GruBlock(channels, channels)
self.feature_enhancer = FeatureEnhancer()
for p in self.parameters():
if p.dim() > 1:
paddle.nn.initializer.XavierUniform(p)
def forward(self, x):
residual = self.conv1(x)
residual = self.bn1(residual)
residual = self.prelu(residual)
residual = self.conv2(residual)
residual = self.bn2(residual)
size = residual.shape
residual = residual.reshape([size[0], size[1], -1])
residual = self.feature_enhancer(residual)
residual = residual.reshape([size[0], size[1], size[2], size[3]])
return x + residual
class UpsampleBLock(nn.Layer):
def __init__(self, in_channels, up_scale):
super(UpsampleBLock, self).__init__()
self.conv = nn.Conv2D(in_channels, in_channels * up_scale ** 2, kernel_size=3, padding=1)
self.pixel_shuffle = nn.PixelShuffle(up_scale)
# self.prelu = nn.ReLU()
self.prelu = mish()
def forward(self, x):
x = self.conv(x)
x = self.pixel_shuffle(x)
x = self.prelu(x)
return x
class mish(nn.Layer):
def __init__(self, ):
super(mish, self).__init__()
self.activated = True
def forward(self, x):
if self.activated:
x = x * (paddle.tanh(F.softplus(x)))
return x
class GruBlock(nn.Layer):
def __init__(self, in_channels, out_channels):
super(GruBlock, self).__init__()
assert out_channels % 2 == 0
self.conv1 = nn.Conv2D(in_channels, out_channels, kernel_size=1, padding=0)
self.gru = nn.GRU(out_channels, out_channels // 2, direction='bidirectional')
def forward(self, x):
# x: b, c, w, h
x = self.conv1(x)
x = x.permute(0, 2, 3, 1).contiguous() # b, w, h, c
b = x.size()
x = x.view(b[0] * b[1], b[2], b[3]) # b*w, h, c
x, _ = self.gru(x)
# x = self.gru(x)[0]
x = x.view(b[0], b[1], b[2], b[3])
x = x.permute(0, 3, 1, 2).contiguous()
return x
3、模型整体损失
class TextFocusLoss(nn.Layer):
def __init__(self, args):
super(TextFocusLoss, self).__init__()
self.args = args
self.mse_loss = nn.MSELoss()
self.ce_loss = nn.CrossEntropyLoss()
self.l1_loss = nn.L1Loss()
self.english_alphabet = '-0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
self.english_dict = {}
for index in range(len(self.english_alphabet)):
self.english_dict[self.english_alphabet[index]] = index
self.build_up_transformer()
def build_up_transformer(self):
transformer = Transformer()
transformer.load_dict(paddle.load('./dataset/mydata/pretrain_transformer.pdparams'))
transformer.eval()
self.transformer = transformer
def label_encoder(self, label):
batch = len(label)
length = [len(i) for i in label]
length_tensor = paddle.to_tensor(length, dtype='int64')
max_length = max(length)
input_tensor = np.zeros((batch, max_length))
for i in range(batch):
for j in range(length[i] - 1):
input_tensor[i][j + 1] = self.english_dict[label[i][j]]
text_gt = []
for i in label:
for j in i:
text_gt.append(self.english_dict[j])
text_gt = paddle.to_tensor(text_gt, dtype='int64')
input_tensor = paddle.to_tensor(input_tensor, dtype='int64')
return length_tensor, input_tensor, text_gt
def forward(self, sr_img, hr_img, label):
mse_loss = self.mse_loss(sr_img, hr_img)
if self.args.text_focus:
label = [str_filt(i, 'lower') + '-' for i in label]
length_tensor, input_tensor, text_gt = self.label_encoder(label)
hr_pred, word_attention_map_gt, hr_correct_list = self.transformer(to_gray_tensor(hr_img), length_tensor,
input_tensor, test=False)
sr_pred, word_attention_map_pred, sr_correct_list = self.transformer(to_gray_tensor(sr_img), length_tensor,
input_tensor, test=False)
attention_loss = self.l1_loss(word_attention_map_gt, word_attention_map_pred)
# recognition_loss = self.l1_loss(hr_pred, sr_pred)
recognition_loss = weight_cross_entropy(sr_pred, text_gt)
loss = mse_loss + attention_loss * 10 + recognition_loss * 0.0005
return loss, mse_loss, attention_loss, recognition_loss
else:
attention_loss = -1
recognition_loss = -1
loss = mse_loss
return loss, mse_loss, attention_loss, recognition_loss
4、训练核心代码
def train(self):
self.config.TRAIN.epochs = args.epochs
cfg = self.config.TRAIN
train_dataset, train_loader = self.get_train_data()
val_dataset_list, val_loader_list = self.get_val_data()
model_dict = self.generator_init()
model, image_crit = model_dict['model'], model_dict['crit']
aster, aster_info = self.CRNN_init()
optimizer_G = self.optimizer_init(model)
best_history_acc = dict(
zip([val_loader_dir.split('/')[-1] for val_loader_dir in self.config.TRAIN.VAL.val_data_dir],
[0] * len(val_loader_list)))
best_model_acc = copy.deepcopy(best_history_acc)
best_model_psnr = copy.deepcopy(best_history_acc)
best_model_ssim = copy.deepcopy(best_history_acc)
best_acc = 0
converge_list = []
for epoch in range(cfg.epochs):
for j, data in (enumerate(train_loader)):
model.train()
for p in model.parameters():
p.stop_gradient = False
iters = len(train_loader) * epoch + j
images_hr, images_lr, label_strs = data
sr_img = model(images_lr)
loss, mse_loss, attention_loss, recognition_loss = image_crit(sr_img, images_hr, label_strs)
self.writer.add_scalar('loss/mse_loss', mse_loss.item())
self.writer.add_scalar('loss/position_loss', attention_loss.item())
self.writer.add_scalar('loss/content_loss', recognition_loss.item())
loss_im = loss * 100
optimizer_G.clear_grad()
loss_im.backward()
optimizer_G.step()
5、评估核心代码
def test(self):
model_dict = self.generator_init()
model, image_crit = model_dict['model'], model_dict['crit']
items = os.listdir(self.test_data_dir)
for test_dir in items:
test_data, test_loader = self.get_test_data(os.path.join(self.test_data_dir, test_dir))
logging.info('evaling %s' % test_dir)
if self.args.rec == 'crnn':
crnn, _ = self.CRNN_init()
crnn.eval()
else:
raise ValueError
if self.args.arch != 'bicubic':
for p in model.parameters():
p.stop_gradient = True
model.eval()
n_correct = 0
sum_images = 0
metric_dict = {'psnr': [], 'ssim': [], 'accuracy': 0.0, 'psnr_avg': 0.0, 'ssim_avg': 0.0}
current_acc_dict = {test_dir: 0}
time_begin = time.time()
sr_time = 0
with tqdm(unit='it', total=len(test_loader)) as pbar:
for i, data in (enumerate(test_loader)):
images_hr, images_lr, label_strs = data
val_batch_size = images_lr.shape[0]
sr_beigin = time.time()
images_sr = model(images_lr)
sr_end = time.time()
sr_time += sr_end - sr_beigin
metric_dict['psnr'].append(self.cal_psnr(images_sr, images_hr))
metric_dict['ssim'].append(self.cal_ssim(images_sr, images_hr))
if self.args.rec == 'crnn':
crnn_input = self.parse_crnn_data(images_sr[:, :3, :, :])
crnn_output = crnn(crnn_input)
_, preds = crnn_output.topk(k=1, axis=2)
preds = preds.transpose([1, 0, 2]).reshape([-1])
preds_size = paddle.to_tensor([crnn_output.shape[0]] * val_batch_size, dtype='int32')
pred_str_sr = self.converter_crnn.decode(preds, preds_size, raw=False)
else:
raise ValueError
for pred, target in zip(pred_str_sr, label_strs):
if str_filt(pred, 'lower') == str_filt(target, 'lower'):
n_correct += 1
sum_images += val_batch_size
paddle.device.cuda.empty_cache()
pbar.update()
七、复现总结
本次复现了聚焦文本的超分辨率模型,这是一篇2021年的CVPR论文,模型提出了很多组件,每一个组件都解决了对应的问题,让人启发。值得注意的是,其中提出的加权交叉熵损失算法,减轻了由可混淆特征引起的差异,让人眼前一亮,读者可自行查阅相关代码学习。项目目前复现了CRNN+TBSRN结构,但基本的框架已经搭建起来,可以看到论文中也验证了其他识别器(ASTER,MORAN)和对比的超分辨率模型(SRCNN,TSRN等),读者根据需要可自行添加,有问题随时交流讨论。
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)