
MobileNeXt论文复现(对Bottleneck的再思考)
MNEXT是一款适合移动设备的轻量模型。它结合了传统ResNet瓶颈构建块和MBV2倒残块的优点。此外,新提出的构建块还考虑了硬件实现,可以在算法级调整内存消耗,而对模型性能的影响最小。
摘要
最近,倒置残差块正在主导移动网络的架构设计。它通过引入两条设计规则改变了经典的残差瓶颈:学习倒残差和使用线性瓶颈。在本文中,我们重新思考了这种设计变化的必要性,发现它可能会带来信息损失和梯度混淆的风险。因此,我们建议翻转结构,提出一种新的瓶颈设计,称为沙漏块(sandglass block)。它在更高的维度上进行身份映射和空间转换从而有效地缓解了信息损失和梯度混淆。广泛的实验证明,与一般人的看法不同,这种瓶颈结构比倒置的结构比倒置的结构对移动网络更有利。在ImageNet分类中,在不增加参数和计算量的情况下,通过简单地将倒置的残差块替换为我们的沙漏块,分类精度就能MobileNetV2提高1.7%以上。在Pascal VOC 2007测试集上,我们观察到mAP也有0.9%的提高。在物体检测方面也有0.9%的改进。我们进一步验证了沙漏块的有效性。将其加入到神经结构搜索方法DARTS的搜索空间中,随着25%的参数减少,分类精度比以前的DARTS模型提高了0.13%。
1. MobileNeXt
1.1 总体架构
基于我们的sandglass块,我们开发了一个模块化的架构,即MobileNeXt。在我们网络的开始,有一个具有32个输出通道的卷积层。之后,我们的sandglass块被堆叠在一起。关于网络结构的详细信息 网络结构的详细信息可以在表2中找到。我们的网络中使用的扩展率,在我们的网络中默认设置为6。最后的输出是全局平均层,将二维特征图转化为一维特征向量,加入一个全连接层来预测每个类别的最终得分。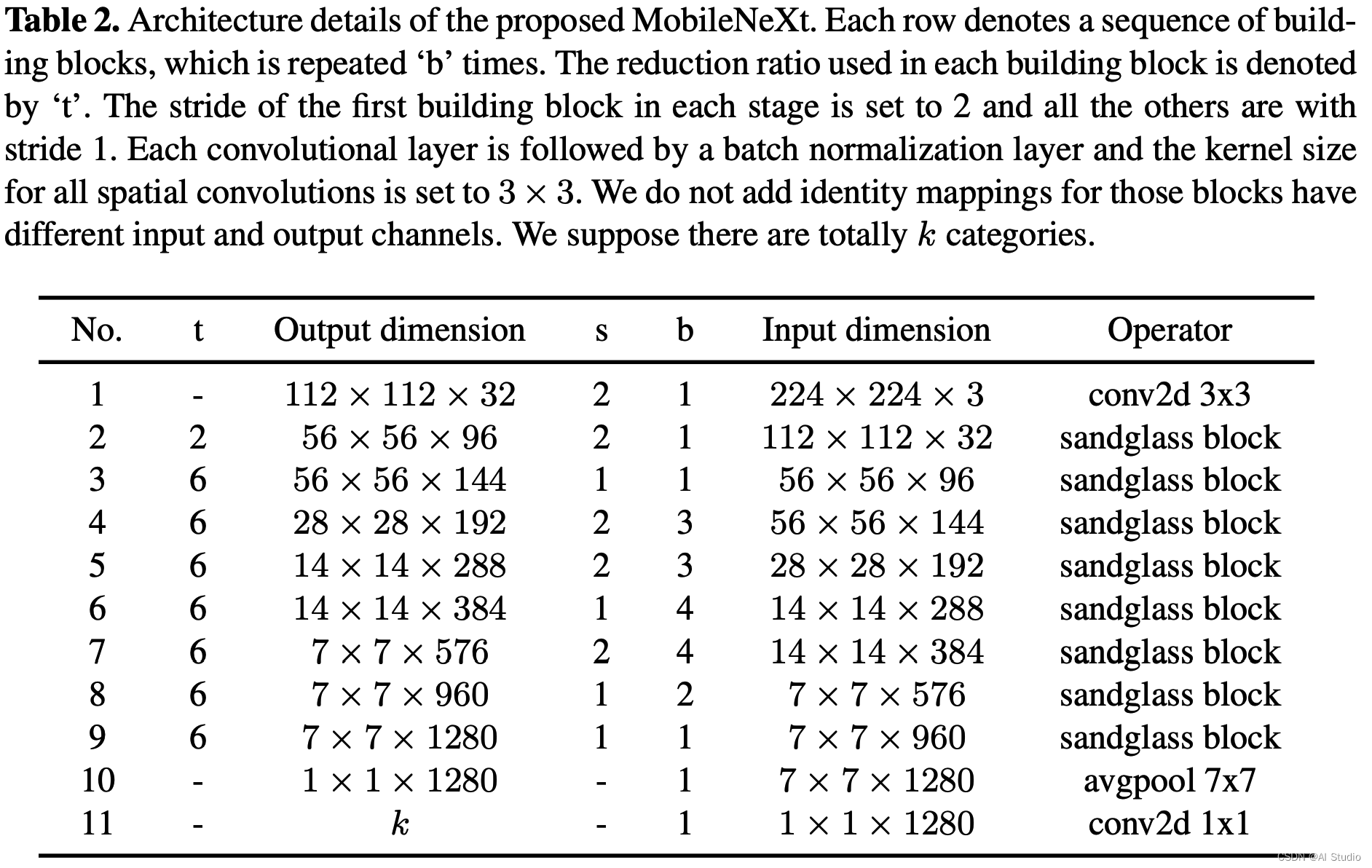
1.2 sandglass block
我们的设计原则主要基于以下观点:(i) 为了保留更多来自底层的信息,并促进底层的梯度在各层的传播。梯度跨层传播,捷径应该被定位为连接高维表征。(ii) 具有小核(例如3×3)的深度卷积是轻量级的,因此我们可以适当地将几个深度卷积应用到高维特征上,这样就可以编码更丰富的空间信息以产生更具表现力的表征。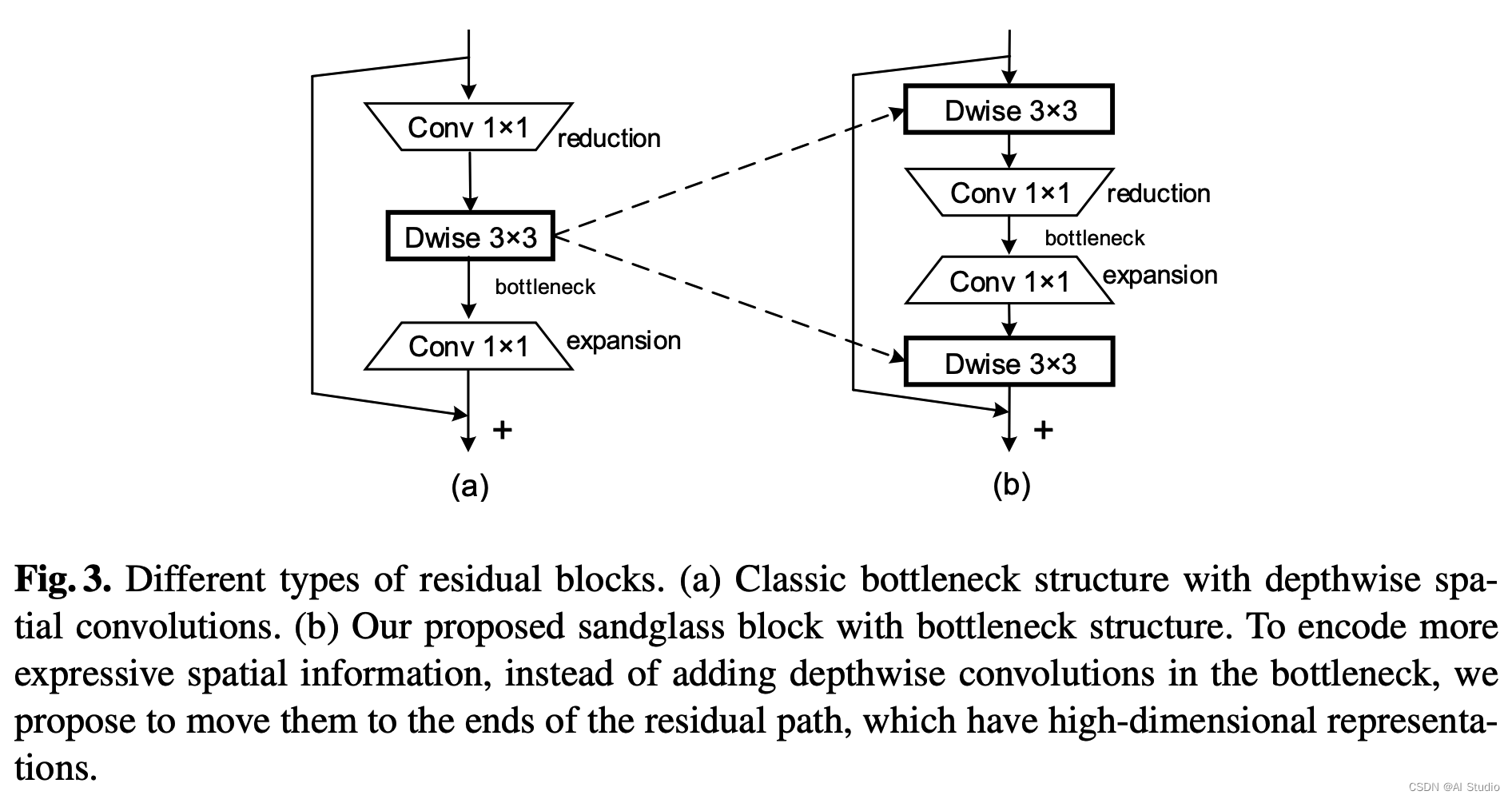
2. 代码复现
2.1 sandglass block的创建
class SGBlock(nn.Layer):
def __init__(self, inp, oup, stride, expand_ratio, keep_3x3=False):
super(SGBlock, self).__init__()
assert stride in [1, 2]
hidden_dim = inp // expand_ratio
if hidden_dim < oup / 6.:
hidden_dim = math.ceil(oup / 6.)
hidden_dim = _make_divisible(hidden_dim, 16) # + 16
self.identity = False
self.identity_div = 1
self.expand_ratio = expand_ratio
if expand_ratio == 2:
self.conv = nn.Sequential(
# dw
Conv2D(
inp, inp, 3, 1, 1, groups=inp, bias_attr=False),
BatchNorm2D(inp),
nn.ReLU6(),
# pw-linear
Conv2D(
inp, hidden_dim, 1, 1, 0, bias_attr=False),
BatchNorm2D(hidden_dim),
# pw-linear
Conv2D(
hidden_dim, oup, 1, 1, 0, bias_attr=False),
BatchNorm2D(oup),
nn.ReLU6(),
# dw
Conv2D(
oup, oup, 3, stride, 1, groups=oup, bias_attr=False),
BatchNorm2D(oup))
elif inp != oup and stride == 1 and keep_3x3 == False:
self.conv = nn.Sequential(
# pw-linear
Conv2D(
inp, hidden_dim, 1, 1, 0, bias_attr=False),
BatchNorm2D(hidden_dim),
# pw-linear
Conv2D(
hidden_dim, oup, 1, 1, 0, bias_attr=False),
BatchNorm2D(oup),
nn.ReLU6())
elif inp != oup and stride == 2 and keep_3x3 == False:
self.conv = nn.Sequential(
# pw-linear
Conv2D(
inp, hidden_dim, 1, 1, 0, bias_attr=False),
BatchNorm2D(hidden_dim),
# pw-linear
Conv2D(
hidden_dim, oup, 1, 1, 0, bias_attr=False),
BatchNorm2D(oup),
nn.ReLU6(),
# dw
Conv2D(
oup, oup, 3, stride, 1, groups=oup, bias_attr=False),
BatchNorm2D(oup))
else:
if keep_3x3 == False:
self.identity = True
self.conv = nn.Sequential(
# dw
Conv2D(
inp, inp, 3, 1, 1, groups=inp, bias_attr=False),
BatchNorm2D(inp),
nn.ReLU6(),
# pw
Conv2D(
inp, hidden_dim, 1, 1, 0, bias_attr=False),
BatchNorm2D(hidden_dim),
#nn.ReLU6(),
# pw
Conv2D(
hidden_dim, oup, 1, 1, 0, bias_attr=False),
BatchNorm2D(oup),
nn.ReLU6(),
# dw
Conv2D(
oup, oup, 3, 1, 1, groups=oup, bias_attr=False),
BatchNorm2D(oup))
def forward(self, x):
out = self.conv(x)
if self.identity:
if self.identity_div == 1:
out = out + x
else:
shape = x.shape
id_tensor = x[:, :shape[1] // self.identity_div, :, :]
out[:, :shape[1] // self.identity_div, :, :] = \
out[:, :shape[1] // self.identity_div, :, :] + id_tensor
return out
2.2 MobileNeXt的构建
class MobileNeXt(nn.Layer):
def __init__(self, class_num=1000, width_mult=1.00):
super().__init__()
# setting of inverted residual blocks
self.cfgs = [
# t, c, n, s
[2, 96, 1, 2],
[6, 144, 1, 1],
[6, 192, 3, 2],
[6, 288, 3, 2],
[6, 384, 4, 1],
[6, 576, 4, 2],
[6, 960, 3, 1],
[6, 1280, 1, 1],
]
# building first layer
input_channel = _make_divisible(32 * width_mult, 4
if width_mult == 0.1 else 8)
layers = [conv_3x3_bn(3, input_channel, 2)]
# building inverted residual blocks
block = SGBlock
for t, c, n, s in self.cfgs:
output_channel = _make_divisible(c * width_mult, 4
if width_mult == 0.1 else 8)
if c == 1280 and width_mult < 1:
output_channel = 1280
layers.append(
block(input_channel, output_channel, s, t, n == 1 and s == 1))
input_channel = output_channel
for _ in range(n - 1):
layers.append(block(input_channel, output_channel, 1, t))
input_channel = output_channel
self.features = nn.Sequential(*layers)
# building last several layers
input_channel = output_channel
output_channel = _make_divisible(input_channel, 4)
self.avgpool = nn.AdaptiveAvgPool2D((1, 1))
self.classifier = nn.Sequential(
nn.Dropout(0.2),
Linear(
output_channel, class_num, bias_attr=no_weight_decay_attr))
self.apply(self._initialize_weights)
def _initialize_weights(self, m):
if isinstance(m, nn.Conv2D):
n = m._kernel_size[0] * m._kernel_size[1] * m._out_channels
nn.initializer.Normal(std=math.sqrt(2. / n))(m.weight)
if m.bias is not None:
nn.initializer.Constant(0)(m.bias)
elif isinstance(m, nn.BatchNorm2D):
nn.initializer.Constant(1)(m.weight)
nn.initializer.Constant(0)(m.bias)
elif isinstance(m, nn.Linear):
nn.initializer.Normal(std=0.01)(m.weight)
nn.initializer.Constant(0)(m.bias)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = x.flatten(1)
x = self.classifier(x)
return x
3.数据集和复现精度
3.1 数据集
ImageNet项目是一个大型视觉数据库,用于视觉目标识别研究任务,该项目已手动标注了 1400 多万张图像。ImageNet-1k 是 ImageNet 数据集的子集,其包含 1000 个类别。训练集包含 1281167 个图像数据,验证集包含 50000 个图像数据。2010 年以来,ImageNet 项目每年举办一次图像分类竞赛,即 ImageNet 大规模视觉识别挑战赛(ILSVRC)。挑战赛使用的数据集即为 ImageNet-1k。到目前为止,ImageNet-1k 已经成为计算机视觉领域发展的最重要的数据集之一,其促进了整个计算机视觉的发展,很多计算机视觉下游任务的初始化模型都是基于该数据集训练得到的。
| 数据集 | 训练集大小 | 测试集大小 | 类别数 | 备注 |
|---|---|---|---|---|
| ImageNet1k | 1.2M | 50k | 1000 |
3.2 复现精度
| 模型 | epochs | top1 acc (参考精度) | (复现精度) | 权重 | 训练日志 |
|---|---|---|---|---|
| MobileNeXt-1.0 | 200 | 74.022 | 74.024 | best_model.pdparams | train.log |
权重及训练日志下载地址:百度网盘 or work/best_model.pdparams
4.准备环境
4.1 安装paddlepaddle
# 安装GPU版本的Paddle
pip install paddlepaddle-gpu==2.3.2
更多安装方法可以参考:Paddle安装指南。
4.2 下载代码
%cd /home/aistudio/
# !git clone https://github.com/flytocc/PaddleClas.git
# !cd PaddleClas
# !git checkout -b mobilenext
!unzip PaddleClas-mobilenext.zip
%cd /home/aistudio/PaddleClas-mobilenext
!pip install -r requirements.txt
5.开始使用
5.1 模型预测

%cd /home/aistudio/PaddleClas-mobilenext
%run tools/infer.py \
-c ./ppcls/configs/ImageNet/MobileNeXt/MobileNeXt_100.yaml \
-o Infer.infer_imgs=./deploy/images/ImageNet/ILSVRC2012_val_00020010.jpeg \
-o Global.pretrained_model=/home/aistudio/work/best_model
最终输出结果为
[{'class_ids': [178, 211, 246, 236, 209], 'scores': [0.85077, 0.0157, 0.01342, 0.00362, 0.00354], 'file_name': './deploy/images/ImageNet/ILSVRC2012_val_00020010.jpeg', 'label_names': ['Weimaraner', 'vizsla, Hungarian pointer', 'Great Dane', 'Doberman, Doberman pinscher', 'Chesapeake Bay retriever']}]
表示预测的类别为Weimaraner(魏玛猎狗),ID是178,置信度为0.85077。
5.2 模型训练
- 单机多卡训练
export CUDA_VISIBLE_DEVICES=0,1,2,3
python -m paddle.distributed.launch --gpus="0,1,2,3" \
tools/train.py \
-c ./ppcls/configs/ImageNet/MobileNeXt/MobileNeXt_100.yaml
cooldown
export CUDA_VISIBLE_DEVICES=0,1,2,3
python -m paddle.distributed.launch --gpus="0,1,2,3" \
tools/train.py \
-c ./ppcls/configs/ImageNet/MobileNeXt/MobileNeXt_100_cooldown.yaml
部分训练日志如下所示。
[2022/09/01 13:08:54] ppcls INFO: [Train][Epoch 187/200][Iter: 1350/2502]lr(LinearWarmup): 0.00125084, CELoss: 2.16119, loss: 2.16119, batch_cost: 0.53062s, reader_cost: 0.11223, ips: 241.22737 samples/s, eta: 4:57:50
[2022/09/01 13:09:19] ppcls INFO: [Train][Epoch 187/200][Iter: 1400/2502]lr(LinearWarmup): 0.00125084, CELoss: 2.16252, loss: 2.16252, batch_cost: 0.53053s, reader_cost: 0.62890, ips: 241.26978 samples/s, eta: 4:57:20
5.3 模型评估
export CUDA_VISIBLE_DEVICES=0,1,2,3
python -m paddle.distributed.launch --gpus="0,1,2,3" \
tools/eval.py \
-c ./ppcls/configs/ImageNet/MobileNeXt/MobileNeXt_100.yaml \
-o Global.pretrained_model=$TRAINED_MODEL
ps: 如果未指定cls_label_path_val,会读取data_path/val里的图片作为val-set。
6. License
This project is released under BSD License.
7. 参考链接与文献
- Rethinking Bottleneck Structure for Efficient Mobile Network Design: https://arxiv.org/pdf/2007.02269.pdf
- MobileNeXt: https://github.com/yitu-opensource/MobileNeXt
- rethinking_bottleneck_design: https://github.com/zhoudaquan/rethinking_bottleneck_design
@article{zhou2020rethinking,
title={Rethinking Bottleneck Structure for Efficient Mobile Network Design},
author={Zhou, Daquan and Hou, Qibin and Chen, Yunpeng and Feng, Jiashi and Yan, Shuicheng},
journal={ECCV, August},
year={2020}
}
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 3
3 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)