
通用多语言OCR自动检测识别
根据语种分类模型与PaddleOCR中的多语言模型,构建一套多语言识别系统
通用多语言OCR系统
1 背景及技术介绍
OCR在各行各位中已经应用很广泛了,比如卡证类、文档、表格等方面。默认的情况下,大多数是使用中文或者中英文识别模型,如果对于多语言的复杂场景,如果能够提前获知目标语言,然后用想用的语言模型进行文字识别。这样可以更加自动化。
1.1 分类方案
PaddleClas 的超轻量图像分类方案(PULC,Practical Ultra Lightweight image Classification)快速构建轻量级、高精度、可落地的语种分类模型。使用该方法训练得到的模型可以快速判断图片中的文字语种,该模型可以广泛应用于金融、政务等各种涉及多语种OCR处理的场景中。
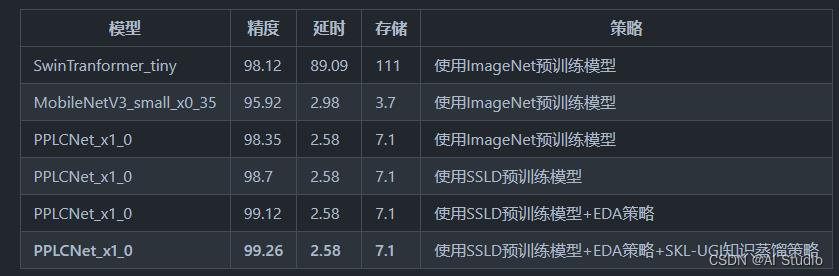
在本项目中我们采用PPLCNet模型,模型经过量化蒸馏无论是精度还是延时方面都有较好的表现,具体比较如下图所示:
备注:
- 关于PP-LCNet的介绍可以参考PP-LCNet介绍,相关论文可以查阅PP-LCNet paper。
目前提供的模型共支持10个类别,分别为:
0 表示阿拉伯语(arabic);1 表示中文繁体(chinese_cht);2 表示斯拉夫语(cyrillic);3 表示梵文(devanagari);4 表示日语(japan);5 表示卡纳达文(ka);6 表示韩语(korean);7 表示泰米尔文(ta);8 表示泰卢固文(te);9 表示拉丁语(latin)。
1.2 OCR语言识别
相较于语言分类,语言的识别支持的种类更多,目前PPOCR的语言模型支持80种语言的检测和识别,并且PPOCR-V3 在检测识别精度上与之前的版本相比都有了很大的提升。
2 语言分类
语言检测主要采用paddleClas中的模型进行分类。这里需要注意的是当前提供的语言分类模型是针对单字、简单词组,目前实际测试长短句效果不好。
存在的问题:
- 当前的语言模型对于日语经常分类错误,大概率是由于日文中有汉字的缘故,模型大概率把文字语言识别为中文繁体。
- 实际应用中,语言分类模型还需要自己进行训练。
# 安装paddleclas库
!pip install paddleclas
# 克隆paddleclas项目到指定目录
!git clone -b release/2.5 https://github.com/PaddlePaddle/PaddleClas.git /home/aistudio/work/paddleClas2-5/
正克隆到 '/home/aistudio/work/paddleClas2-5'...
remote: Enumerating objects: 37844, done.[K
remote: Counting objects: 100% (1099/1099), done.[K
remote: Compressing objects: 100% (534/534), done.[K
remote: Total 37844 (delta 571), reused 996 (delta 518), pack-reused 36745[K
接收对象中: 100% (37844/37844), 208.49 MiB | 15.27 MiB/s, 完成.
处理 delta 中: 100% (26750/26750), 完成.
检查连接... 完成。
# 安装paddleClas依赖
!pip install -r work/paddleClas2-5/requirements.txt
# 获取测试数据
!wget -P work/data https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip
--2022-07-25 14:04:21-- https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip
正在解析主机 paddleclas.bj.bcebos.com (paddleclas.bj.bcebos.com)... 182.61.200.195, 182.61.200.229, 2409:8c04:1001:1002:0:ff:b001:368a
正在连接 paddleclas.bj.bcebos.com (paddleclas.bj.bcebos.com)|182.61.200.195|:443... 已连接。
已发出 HTTP 请求,正在等待回应... 200 OK
长度: 1571878 (1.5M) [application/zip]
正在保存至: “work/data/pulc_demo_imgs.zip”
pulc_demo_imgs.zip 100%[===================>] 1.50M 1.45MB/s in 1.0s
2022-07-25 14:04:23 (1.45 MB/s) - 已保存 “work/data/pulc_demo_imgs.zip” [1571878/1571878])
# 解压数据
!unzip work/data/pulc_demo_imgs.zip -d work/data
分类语言推理模型输出的是top2的结果,如下面示例中输出的结果为日语和韩语,实际使用中我们可以输出top1的结果
# 采用模型进行测试语言分类
import paddleclas
model = paddleclas.PaddleClas(model_name="language_classification")
result = model.predict(input_data="/home/aistudio/work/data/pulc_demo_imgs/language_classification/word_35404.png")
result = list(result)
print(result)
print(result[0][0]['label_names'][0])
[[{'class_ids': [4, 6], 'scores': [0.88672, 0.01434], 'label_names': ['japan', 'korean'], 'filename': '/home/aistudio/work/data/pulc_demo_imgs/language_classification/word_35404.png'}]]
japan
3 语言识别
语言识别模型我们采用paddleocr。在实际的应用中,OCR包括检测和识别两部分,对于分类模型的什么时候用主要有两个路线:
- 如果给定的待识别文字为单行文本片段的,可以直接采用分类+识别技术。
- 如果给定任意的文本,这时候需要提前引入文本检测模型,然后再采用1中的技术路线。
# 安装paddleOCR
!pip install paddleocr
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="japan") # need to run only once to download and load model into memory
img_path = '/home/aistudio/work/data/pulc_demo_imgs/language_classification/word_35404.png'
result = ocr.ocr(img_path, cls=True)
for line in result:
print(line)
# 显示结果
from PIL import Image
image = Image.open(img_path).convert('RGB')
boxes = [line[0][0]for line in result]
txts = [line[0][1][0] for line in result]
scores = [line[0][1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='/home/aistudio/work/simfang.ttf') # 可以根据实际选择自定义字体
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
[2022/10/14 11:00:20] ppocr DEBUG: Namespace(alpha=1.0, benchmark=False, beta=1.0, cls_batch_num=6, cls_image_shape='3, 48, 192', cls_model_dir='/home/aistudio/.paddleocr/whl/cls/ch_ppocr_mobile_v2.0_cls_infer', cls_thresh=0.9, cpu_threads=10, crop_res_save_dir='./output', det=True, det_algorithm='DB', det_db_box_thresh=0.6, det_db_score_mode='fast', det_db_thresh=0.3, det_db_unclip_ratio=1.5, det_east_cover_thresh=0.1, det_east_nms_thresh=0.2, det_east_score_thresh=0.8, det_fce_box_type='poly', det_limit_side_len=960, det_limit_type='max', det_model_dir='/home/aistudio/.paddleocr/whl/det/ml/Multilingual_PP-OCRv3_det_infer', det_pse_box_thresh=0.85, det_pse_box_type='quad', det_pse_min_area=16, det_pse_scale=1, det_pse_thresh=0, det_sast_nms_thresh=0.2, det_sast_polygon=False, det_sast_score_thresh=0.5, draw_img_save_dir='./inference_results', drop_score=0.5, e2e_algorithm='PGNet', e2e_char_dict_path='./ppocr/utils/ic15_dict.txt', e2e_limit_side_len=768, e2e_limit_type='max', e2e_model_dir=None, e2e_pgnet_mode='fast', e2e_pgnet_score_thresh=0.5, e2e_pgnet_valid_set='totaltext', enable_mkldnn=False, fourier_degree=5, gpu_mem=500, help='==SUPPRESS==', image_dir=None, image_orientation=False, ir_optim=True, kie_algorithm='LayoutXLM', label_list=['0', '180'], lang='japan', layout=True, layout_dict_path=None, layout_model_dir=None, layout_nms_threshold=0.5, layout_score_threshold=0.5, max_batch_size=10, max_text_length=25, merge_no_span_structure=True, min_subgraph_size=15, mode='structure', ocr=True, ocr_order_method=None, ocr_version='PP-OCRv3', output='./output', page_num=0, precision='fp32', process_id=0, re_model_dir=None, rec=True, rec_algorithm='SVTR_LCNet', rec_batch_num=6, rec_char_dict_path='/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddleocr/ppocr/utils/dict/japan_dict.txt', rec_image_shape='3, 48, 320', rec_model_dir='/home/aistudio/.paddleocr/whl/rec/japan/japan_PP-OCRv3_rec_infer', recovery=False, save_crop_res=False, save_log_path='./log_output/', scales=[8, 16, 32], ser_dict_path='../train_data/XFUND/class_list_xfun.txt', ser_model_dir=None, show_log=True, sr_batch_num=1, sr_image_shape='3, 32, 128', sr_model_dir=None, structure_version='PP-Structurev2', table=True, table_algorithm='TableAttn', table_char_dict_path=None, table_max_len=488, table_model_dir=None, total_process_num=1, type='ocr', use_angle_cls=True, use_dilation=False, use_gpu=True, use_mp=False, use_npu=False, use_onnx=False, use_pdserving=False, use_space_char=True, use_tensorrt=False, use_visual_backbone=True, use_xpu=False, vis_font_path='./doc/fonts/simfang.ttf', warmup=False)
[2022/10/14 11:00:22] ppocr DEBUG: dt_boxes num : 1, elapse : 0.020247459411621094
[2022/10/14 11:00:22] ppocr DEBUG: cls num : 1, elapse : 0.015371084213256836
[2022/10/14 11:00:22] ppocr DEBUG: rec_res num : 1, elapse : 0.017617225646972656
[[[[26.0, 13.0], [587.0, 15.0], [587.0, 81.0], [26.0, 78.0]], ('バスターミナル', 0.9783002138137817)]]
结果如下
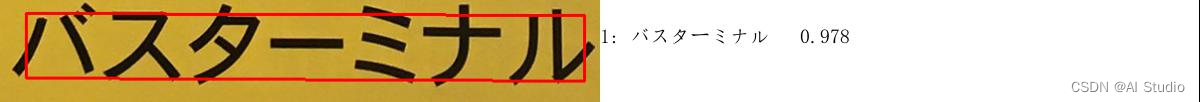
4 模型整合
将语言分类模型和文本识别模型进行组合。
import paddleclas
from paddleocr import PaddleOCR, draw_ocr
from PIL import Image
# 语言检测
lang_model = paddleclas.PaddleClas(model_name="language_classification")
img_path = "/home/aistudio/work/data/pulc_demo_imgs/language_classification/20221014114951.jpg" # 此处可以填写实际图片路径
result = lang_model.predict(input_data=img_path)
result = list(result)
lang_type = result[0][0]['label_names'][0]
print('语言类型为:',lang_type)
# 检测识别
ocr = PaddleOCR(use_angle_cls=True, lang=lang_type)
result = ocr.ocr(img_path, cls=True)
for line in result:
print(line)
# 打印结果
image = Image.open(img_path).convert('RGB')
boxes = [line[0][0] for line in result]
txts = [line[0][1][0] for line in result]
scores = [line[0][1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='/home/aistudio/work/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result1.jpg')
语言类型为: cyrillic
[2022/10/14 11:50:33] ppocr DEBUG: Namespace(alpha=1.0, benchmark=False, beta=1.0, cls_batch_num=6, cls_image_shape='3, 48, 192', cls_model_dir='/home/aistudio/.paddleocr/whl/cls/ch_ppocr_mobile_v2.0_cls_infer', cls_thresh=0.9, cpu_threads=10, crop_res_save_dir='./output', det=True, det_algorithm='DB', det_db_box_thresh=0.6, det_db_score_mode='fast', det_db_thresh=0.3, det_db_unclip_ratio=1.5, det_east_cover_thresh=0.1, det_east_nms_thresh=0.2, det_east_score_thresh=0.8, det_fce_box_type='poly', det_limit_side_len=960, det_limit_type='max', det_model_dir='/home/aistudio/.paddleocr/whl/det/ml/Multilingual_PP-OCRv3_det_infer', det_pse_box_thresh=0.85, det_pse_box_type='quad', det_pse_min_area=16, det_pse_scale=1, det_pse_thresh=0, det_sast_nms_thresh=0.2, det_sast_polygon=False, det_sast_score_thresh=0.5, draw_img_save_dir='./inference_results', drop_score=0.5, e2e_algorithm='PGNet', e2e_char_dict_path='./ppocr/utils/ic15_dict.txt', e2e_limit_side_len=768, e2e_limit_type='max', e2e_model_dir=None, e2e_pgnet_mode='fast', e2e_pgnet_score_thresh=0.5, e2e_pgnet_valid_set='totaltext', enable_mkldnn=False, fourier_degree=5, gpu_mem=500, help='==SUPPRESS==', image_dir=None, image_orientation=False, ir_optim=True, kie_algorithm='LayoutXLM', label_list=['0', '180'], lang='cyrillic', layout=True, layout_dict_path=None, layout_model_dir=None, layout_nms_threshold=0.5, layout_score_threshold=0.5, max_batch_size=10, max_text_length=25, merge_no_span_structure=True, min_subgraph_size=15, mode='structure', ocr=True, ocr_order_method=None, ocr_version='PP-OCRv3', output='./output', page_num=0, precision='fp32', process_id=0, re_model_dir=None, rec=True, rec_algorithm='SVTR_LCNet', rec_batch_num=6, rec_char_dict_path='/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddleocr/ppocr/utils/dict/cyrillic_dict.txt', rec_image_shape='3, 48, 320', rec_model_dir='/home/aistudio/.paddleocr/whl/rec/cyrillic/cyrillic_PP-OCRv3_rec_infer', recovery=False, save_crop_res=False, save_log_path='./log_output/', scales=[8, 16, 32], ser_dict_path='../train_data/XFUND/class_list_xfun.txt', ser_model_dir=None, show_log=True, sr_batch_num=1, sr_image_shape='3, 32, 128', sr_model_dir=None, structure_version='PP-Structurev2', table=True, table_algorithm='TableAttn', table_char_dict_path=None, table_max_len=488, table_model_dir=None, total_process_num=1, type='ocr', use_angle_cls=True, use_dilation=False, use_gpu=True, use_mp=False, use_npu=False, use_onnx=False, use_pdserving=False, use_space_char=True, use_tensorrt=False, use_visual_backbone=True, use_xpu=False, vis_font_path='./doc/fonts/simfang.ttf', warmup=False)
[2022/10/14 11:50:35] ppocr DEBUG: dt_boxes num : 1, elapse : 0.019649267196655273
[2022/10/14 11:50:35] ppocr DEBUG: cls num : 1, elapse : 0.013901233673095703
[2022/10/14 11:50:35] ppocr DEBUG: rec_res num : 1, elapse : 0.015190362930297852
[[[[16.0, 14.0], [102.0, 14.0], [102.0, 46.0], [16.0, 46.0]], ('Тайп', 0.9769517183303833)]]
测试原图为
测试结果为:
测试原图为 
测试结果为:
这里有个地方需要注意的是,示例使用的字体为simfang.ttf,这种字体支持的语言有限,上述的显示并不是识别错误,是由于字体库的不支持,所以显示乱码,大家在这方面需要注意
原图为
测试结果为:
原图为:
测试后为:
5 后记&思考
关于文本的语言分类可以扩展到多行多列的文本或者整个文本。另外对于日语的分类可能需要大量的数据,由于日文中包含大量的繁体汉字,所以当前的分类模型经常将两者弄混。
所以语言分类模型在实际中的位置可能就有这样几种组合:
- 若语言分类为只能区分单行的文本或者词组等,这时候的语言分类模型在检测和识别之间。
- 若语言分类模型可以对整体文本进行区分,则分类模型可以放在任意检测之前。
此外如果一个文本中含有多种语言,这种一般不建议进行语言检测,而是做成类似于中英文检测模型的那种,其中一个难点就是语言之间很难单独区分开,然后再分别调用不同语言模型,这样做其实效率更低。
另外对于当前的语言分类模型大家可以继续提高其准确率,特别是相相似的语言书写,比如拉丁文和英文,日语和汉语等。
以上就是个人的一点看法,如有不对的欢迎大家留言指正交流。
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)