
工程师提效神器,有了这个插件,可以自动写代码了
领先的代码生成模型、基于PaddleNLP的模型加速能力、以及一整套插件开发流程,来了!
代码生成:写代码的AI助理
1 概述
从计算机时代开始,创建程序通常需要人工输入代码。代码生成的目标是使编码过程自动化,并生成满足用户指定意图的计算机程序。有些人称之为计算机科学的圣杯。成功的代码生成不仅可以提高经验丰富的程序员的生产力,而且可以让更多的受众了解程序。在努力实现代码生成时,出现了两个关键挑战:(1)搜索空间的巨大,以及(2)难以去正确识别用户的意图。为了解决这些问题挑战,Salesforce提出CodeGen,一种交互式的代码生成模型。
2. CodeGen模型解读
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis 是Salesforce在2022年提出的工作。它通过大型语言模型进行对话式程序生成的方法,将编写规范和程序的过程转换为用户和系统之间的多回合对话。它把程序生成看作一个序列预测问题,用自然语言表达规范,并对程序进行抽样生成。同时,CodeGen(16B)在HumanEval benchmark上已经超过OpenAI’s Codex。
2.1 开箱即用
下面通过Taskflow来调用CodeGen模型进行做题。(需要参考3.3.2节安装下PaddleNLP)
from paddlenlp import Taskflow
#Taskflow调用
codegen = Taskflow("code_generation", model="Salesforce/codegen-2B-mono",decode_strategy="greedy_search", repetition_penalty=1.0)
[2022-10-24 21:54:04,507] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/Salesforce/codegen-2B-mono/vocab.json
[2022-10-24 21:54:04,511] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/Salesforce/codegen-2B-mono/merges.txt
[2022-10-24 21:54:04,513] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/Salesforce/codegen-2B-mono/added_tokens.json
[2022-10-24 21:54:04,514] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/Salesforce/codegen-2B-mono/special_tokens_map.json
[2022-10-24 21:54:04,516] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/Salesforce/codegen-2B-mono/tokenizer_config.json
[2022-10-24 21:54:04,597] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,599] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,601] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,603] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,605] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,607] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,609] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,611] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,613] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,614] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,616] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,618] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,620] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,622] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,624] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,626] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,628] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,630] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,631] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,633] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,635] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,637] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,639] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,641] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,643] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,645] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,647] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,648] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,650] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,653] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,656] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,660] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,662] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,664] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,666] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,668] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,670] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,672] [ INFO] - Adding to the vocabulary
[2022-10-24 21:54:04,674] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/Salesforce/codegen-2B-mono/model_state.pdparams
[2022-10-24 21:54:04,676] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/Salesforce/codegen-2B-mono/model_config.json
W1024 21:54:04.679530 7395 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W1024 21:54:04.683189 7395 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
代码补全:LeetCode解题
prompt = "def lengthOfLongestSubstring(self, s: str) -> int:"
code = codegen(prompt)
print(prompt)
print(code[0])
def lengthOfLongestSubstring(self, s: str) -> int:
if not s:
return 0
start = 0
end = 0
max_len = 0
while end < len(s):
if s[end] not in s[start:end]:
max_len = max(max_len, end - start + 1)
end += 1
else:
start += 1
return max_len
3. 实践:Copilot插件配置和微调
3.1 效果展示
以下是通过Github Copilot调用CodeGen在VS Code上写代码的效果

图1:CodeGen效果
速度为何这么快?我们底层使用了FasterGeneration来加速,350M的模型加速比已超10,下面是具体的加速比。
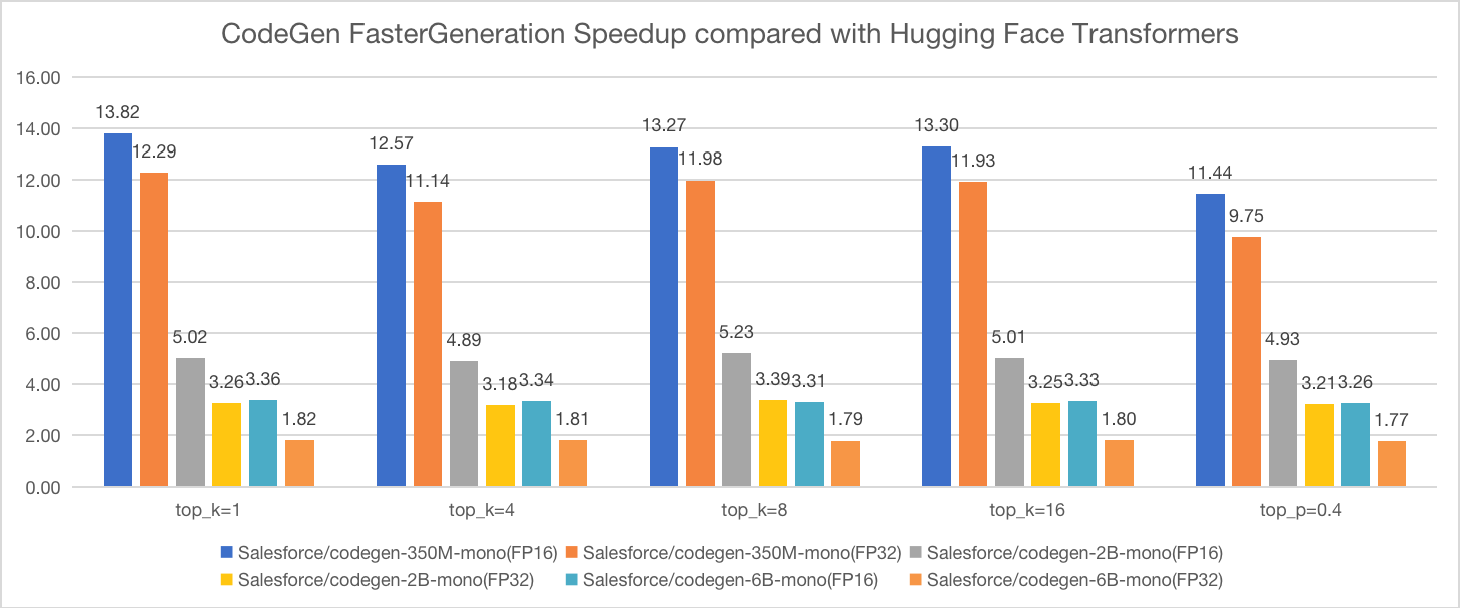
图2:CodeGen FasterGeneration加速对比
3.2 配置GitHub Copilot
配置教程非常简单,完整教程可以参考该链接Copilot with CodeGen
代码插件我们支持GitHub Copilot,也支持Fauxpilot。
3.3 微调
3.3.1 数据集介绍
代码数据即可,任选一条数据,示意如下:
{“code”: “# Copyright © 2020 PaddlePaddle Authors. All Rights Reserve.\n#\n# Licensed under the Apache License, Version 2.0 (the “License”);\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an “AS IS” BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport copy\nimport paddle\n\nfrom …utils.registry import Registry\n\nMODELS = Registry(“MODEL”)\n\n\ndef build_model(cfg):\n cfg_ = cfg.copy()\n name = cfg_.pop(‘name’, None)\n model = MODELS.get(name)(**cfg_)\n return model\n”}
上面是1条样本,每条样本都是一行jsonline,code字段为代码内容。
3.3.2 数据读取
安装并导入依赖库
!pip install regex==2022.6.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install paddlenlp==2.4.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting regex==2022.6.2
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/0f/92/116de5ebb427f567c483768ad15944afb219d36545e09d667338ac3df58e/regex-2022.6.2-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (749 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m749.7/749.7 kB[0m [31m4.9 MB/s[0m eta [36m0:00:00[0m00:01[0m00:01[0m
[?25hInstalling collected packages: regex
Successfully installed regex-2022.6.2
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m A new release of pip available: [0m[31;49m22.1.2[0m[39;49m -> [0m[32;49m22.3[0m
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m To update, run: [0m[32;49mpip install --upgrade pip[0m
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting paddlenlp==2.4.1
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/1f/54/6d5ae82c9a4556daf18334a07d8dd4612b586b4bd4629bcd82099cccf20d/paddlenlp-2.4.1-py3-none-any.whl (1.9 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m1.9/1.9 MB[0m [31m2.2 MB/s[0m eta [36m0:00:00[0m00:01[0m00:01[0m
[?25hRequirement already satisfied: colorlog in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.4.1) (4.1.0)
Requirement already satisfied: seqeval in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.4.1) (1.2.2)
Requirement already satisfied: colorama in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.4.1) (0.4.4)
Requirement already satisfied: tqdm in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.4.1) (4.27.0)
Collecting datasets>=2.0.0
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/7c/75/d282907e7ebd87e4b3475bc5156140465372fa451bc6cbddbefa54915d00/datasets-2.6.1-py3-none-any.whl (441 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m441.9/441.9 kB[0m [31m1.1 MB/s[0m eta [36m0:00:00[0ma [36m0:00:01[0m
[?25hRequirement already satisfied: paddle2onnx in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.4.1) (1.0.0)
Requirement already satisfied: multiprocess<=0.70.12.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.4.1) (0.70.11.1)
Requirement already satisfied: visualdl in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.4.1) (2.4.0)
Requirement already satisfied: sentencepiece in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.4.1) (0.1.96)
Requirement already satisfied: dill<0.3.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.4.1) (0.3.3)
Requirement already satisfied: protobuf<=3.20.0,>=3.1.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.4.1) (3.20.0)
Requirement already satisfied: paddlefsl in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.4.1) (1.0.0)
Requirement already satisfied: jieba in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.4.1) (0.42.1)
Requirement already satisfied: importlib-metadata in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from datasets>=2.0.0->paddlenlp==2.4.1) (4.2.0)
Collecting fsspec[http]>=2021.11.1
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/4c/3d/86112db0fc482c4b11031516340e2d9978aa837ee104b4bebaaad0fae465/fsspec-2022.10.0-py3-none-any.whl (138 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m138.8/138.8 kB[0m [31m1.8 MB/s[0m eta [36m0:00:00[0ma [36m0:00:01[0m
[?25hRequirement already satisfied: pyyaml>=5.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from datasets>=2.0.0->paddlenlp==2.4.1) (5.1.2)
Collecting tqdm
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/47/bb/849011636c4da2e44f1253cd927cfb20ada4374d8b3a4e425416e84900cc/tqdm-4.64.1-py2.py3-none-any.whl (78 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m78.5/78.5 kB[0m [31m1.5 MB/s[0m eta [36m0:00:00[0ma [36m0:00:01[0m
[?25hCollecting responses<0.19
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/79/f3/2b3a6dc5986303b3dd1bbbcf482022acb2583c428cd23f0b6d37b1a1a519/responses-0.18.0-py3-none-any.whl (38 kB)
Collecting pyarrow>=6.0.0
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/7f/08/9b5fe7c9e2774bca77dae29d22a446ead804fb8e050f2899ae1f60d73ad1/pyarrow-9.0.0-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (35.3 MB)
[2K [91m━━━━━━━━━━━━━━━━[0m[90m╺[0m[90m━━━━━━━━━━━━━━━━━━━━━━━[0m [32m14.2/35.3 MB[0m [31m1.2 MB/s[0m eta [36m0:00:18[0m
import os
import argparse
import random
import time
import distutils.util
from pprint import pprint
from functools import partial
import numpy as np
from itertools import chain
from datasets import load_dataset
import math
from visualdl import LogWriter
import paddle
import paddle.nn as nn
from paddle.io import BatchSampler, DistributedBatchSampler, DataLoader
from paddlenlp.transformers import CodeGenForCausalLM, CodeGenTokenizer
from paddlenlp.transformers import LinearDecayWithWarmup
from paddlenlp.utils.log import logger
from paddlenlp.data import DataCollatorWithPadding
from paddle.metric import Accuracy
[2022-10-24 21:02:42,587] [ WARNING] - Detected that datasets module was imported before paddlenlp. This may cause PaddleNLP datasets to be unavalible in intranet. Please import paddlenlp before datasets module to avoid download issues
# 通过load_dataset读取本地数据集:train.json和valid.json
train_dataset = load_dataset("json", data_files='train.json', split="train")
dev_dataset = load_dataset("json", data_files='valid.json', split="train")
Using custom data configuration default-ccc886cb577d29f7
Downloading and preparing dataset json/default to /home/aistudio/.cache/huggingface/datasets/json/default-ccc886cb577d29f7/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab...
Downloading data files: 0%| | 0/1 [00:00<?, ?it/s]
Extracting data files: 0%| | 0/1 [00:00<?, ?it/s]
0 tables [00:00, ? tables/s]
Dataset json downloaded and prepared to /home/aistudio/.cache/huggingface/datasets/json/default-ccc886cb577d29f7/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab. Subsequent calls will reuse this data.
Using custom data configuration default-29f06e7f384f8afe
Downloading and preparing dataset json/default to /home/aistudio/.cache/huggingface/datasets/json/default-29f06e7f384f8afe/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab...
Downloading data files: 0%| | 0/1 [00:00<?, ?it/s]
Extracting data files: 0%| | 0/1 [00:00<?, ?it/s]
0 tables [00:00, ? tables/s]
Dataset json downloaded and prepared to /home/aistudio/.cache/huggingface/datasets/json/default-29f06e7f384f8afe/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab. Subsequent calls will reuse this data.
3.3.3 数据格式转换
创建Tokenizer,用于分词,将token映射成id。
# 初始化分词器
tokenizer = CodeGenTokenizer.from_pretrained('Salesforce/codegen-350M-mono')
[2022-10-21 12:56:44,060] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/community/Salesforce/codegen-350M-mono/vocab.json and saved to /home/aistudio/.paddlenlp/models/Salesforce/codegen-350M-mono
[2022-10-21 12:56:44,063] [ INFO] - Downloading vocab.json from https://bj.bcebos.com/paddlenlp/models/community/Salesforce/codegen-350M-mono/vocab.json
100%|██████████| 779k/779k [00:00<00:00, 31.4MB/s]
[2022-10-21 12:56:44,295] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/community/Salesforce/codegen-350M-mono/merges.txt and saved to /home/aistudio/.paddlenlp/models/Salesforce/codegen-350M-mono
[2022-10-21 12:56:44,298] [ INFO] - Downloading merges.txt from https://bj.bcebos.com/paddlenlp/models/community/Salesforce/codegen-350M-mono/merges.txt
100%|██████████| 446k/446k [00:00<00:00, 27.7MB/s]
[2022-10-21 12:56:44,456] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/community/Salesforce/codegen-350M-mono/added_tokens.json and saved to /home/aistudio/.paddlenlp/models/Salesforce/codegen-350M-mono
[2022-10-21 12:56:44,458] [ INFO] - Downloading added_tokens.json from https://bj.bcebos.com/paddlenlp/models/community/Salesforce/codegen-350M-mono/added_tokens.json
100%|██████████| 0.98k/0.98k [00:00<00:00, 602kB/s]
[2022-10-21 12:56:44,636] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/community/Salesforce/codegen-350M-mono/special_tokens_map.json and saved to /home/aistudio/.paddlenlp/models/Salesforce/codegen-350M-mono
[2022-10-21 12:56:44,639] [ INFO] - Downloading special_tokens_map.json from https://bj.bcebos.com/paddlenlp/models/community/Salesforce/codegen-350M-mono/special_tokens_map.json
100%|██████████| 90.0/90.0 [00:00<00:00, 57.4kB/s]
[2022-10-21 12:56:44,812] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/community/Salesforce/codegen-350M-mono/tokenizer_config.json and saved to /home/aistudio/.paddlenlp/models/Salesforce/codegen-350M-mono
[2022-10-21 12:56:44,814] [ INFO] - Downloading tokenizer_config.json from https://bj.bcebos.com/paddlenlp/models/community/Salesforce/codegen-350M-mono/tokenizer_config.json
100%|██████████| 177/177 [00:00<00:00, 117kB/s]
[2022-10-21 12:56:44,998] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,001] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,004] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,006] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,009] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,011] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,013] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,016] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,018] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,020] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,022] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,025] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,027] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,029] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,032] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,034] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,036] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,041] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,043] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,045] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,047] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,049] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,052] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,054] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,056] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,058] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,060] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,063] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,065] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,067] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,070] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,072] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,074] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,076] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,079] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,081] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,083] [ INFO] - Adding to the vocabulary
[2022-10-21 12:56:45,085] [ INFO] - Adding to the vocabulary
定义convert_example,将code文本映射成int类型的id。
def convert_example(examples, tokenizer):
"""构造模型的输入."""
# 分词
tokenized_examples = tokenizer(examples["code"],
return_attention_mask=True,
return_position_ids=False,
return_token_type_ids=False)
return tokenized_examples
# 将拼接后的文本按照block大小来进行切分
def group_texts(examples, block_size):
concatenated_examples = {
k: list(chain(*examples[k]))
for k in examples.keys()
}
total_length = len(concatenated_examples[list(examples.keys())[0]])
if total_length >= block_size:
total_length = (total_length // block_size) * block_size
result = {
k: [t[i:i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
result["labels"] = result["input_ids"].copy()
return result
使用partial函数指定默认参数,使用map函数转换数据。map函数把原来的文本根据词汇表的编号转换成了相应的id,为了便于理解,这里把训练集合的1条样本展示出来。
block_size = 1024
# 定义转换器
trans_func = partial(convert_example, tokenizer=tokenizer)
group_trans_func = partial(group_texts, block_size=block_size)
# train_dataset和dev_dataset分别转换
train_dataset = train_dataset.map(trans_func,
batched=True,
load_from_cache_file=True,
remove_columns=train_dataset.column_names)
train_dataset = train_dataset.map(group_trans_func,
batched=True,
load_from_cache_file=True)
dev_dataset = dev_dataset.map(trans_func,
batched=True,
load_from_cache_file=True,
remove_columns=dev_dataset.column_names)
dev_dataset = dev_dataset.map(group_trans_func,
batched=True,
load_from_cache_file=True)
# 输出训练集的前 1 条样本
for idx, example in enumerate(dev_dataset):
if idx < 1:
print(example)
{'input_ids': [11748, 1822, 29572, 198, 11748, 279, 4798, 198, 11748, 285, 87, 3262, 355, 285, 87, 198, 198, 6738, 11485, 6404, 1362, 1330, 49706, 198, 6738, 11485, 11250, 1330, 4566, 11, 4277, 11, 7716, 62, 11250, 198, 6738, 11485, 1837, 23650, 1330, 1635, 198, 6738, 11485, 7295, 1330, 23838, 11, 18663, 198, 6738, 11485, 7295, 13, 29356, 1330, 15107, 3978, 353, 198, 6738, 11485, 7295, 13, 21412, 1330, 13859, 540, 26796, 198, 6738, 11485, 36948, 13, 65, 3524, 62, 2301, 2234, 1330, 751, 62, 65, 3524, 62, 2301, 2234, 62, 83, 853, 1039, 198, 6738, 11485, 26791, 13, 2220, 62, 7890, 1330, 3440, 62, 1676, 40007, 62, 3882, 65, 11, 20121, 62, 3882, 65, 11, 8106, 62, 3882, 65, 198, 6738, 11485, 26791, 13, 2220, 62, 19849, 1330, 3440, 62, 17143, 628, 198, 4299, 4512, 62, 6015, 20471, 7, 27349, 11, 27039, 11, 2939, 62, 2617, 11, 6808, 62, 6978, 11, 27039, 62, 6978, 11, 10792, 11, 50273, 74, 85, 8095, 11, 670, 62, 2220, 62, 4868, 11, 645, 62, 2704, 541, 11, 645, 62, 1477, 18137, 11, 15294, 11, 269, 17602, 11, 50273, 5310, 13363, 11, 36835, 11, 21231, 11, 2221, 62, 538, 5374, 11, 886, 62, 538, 5374, 11, 4512, 62, 28710, 11, 50273, 14050, 11, 300, 81, 62, 9662, 11, 6961, 2599, 50284, 2, 900, 510, 4566, 50284, 11250, 13, 51, 3861, 1268, 13, 33, 11417, 62, 3955, 25552, 796, 362, 50284, 11250, 13, 51, 3861, 1268, 13, 33, 11417, 62, 13252, 1797, 796, 13108, 50284, 361, 6961, 6624, 705, 824, 10354, 50280, 11250, 13, 51, 3861, 1268, 13, 40469, 62, 4221, 19535, 39, 62, 21982, 796, 657, 13, 16, 50286, 2, 22919, 12549, 371, 12, 18474, 50284, 2, 3440, 6194, 50284, 37047, 796, 5418, 10786, 1136, 62, 6, 1343, 3127, 1343, 705, 62, 6015, 20471, 6, 5769, 22510, 62, 37724, 28, 11250, 13, 41359, 62, 31631, 1546, 8, 50284, 2, 9058, 5021, 12, 46999, 50284, 43501, 62, 7857, 796, 18896, 7, 49464, 8, 50284, 15414, 62, 43501, 62, 7857, 796, 4566, 13, 51, 3861, 1268, 13, 33, 11417, 62, 3955, 25552, 1635, 15458, 62, 7857, 50284, 2, 3601, 4566, 50284, 6404, 1362, 13, 10951, 7, 381, 22272, 13, 79, 18982, 7, 11250, 4008, 50284, 2, 3440, 27039, 290, 8335, 545, 9945, 329, 3047, 50284, 9060, 62, 28709, 796, 685, 271, 316, 329, 318, 316, 287, 2939, 62, 2617, 13, 35312, 10786, 10, 11537, 60, 50284, 3882, 1443, 796, 685, 50280, 2220, 62, 1676, 40007, 62, 3882, 65, 7, 19608, 292, 316, 11, 50260, 9060, 62, 2617, 11, 50260, 15763, 62, 6978, 11, 50260, 19608, 292, 316, 62, 6978, 11, 50260, 1676, 40007, 28, 1676, 40007, 11, 50260, 33295, 62, 13655, 28, 17821, 11, 50260, 2704, 541, 28, 1662, 645, 62, 2704, 541, 8, 329, 2939, 62, 2617, 287, 2939, 62, 28709, 50284, 60, 50284, 3882, 65, 796, 20121, 62, 3882, 65, 7, 3882, 1443, 8, 50284, 3882, 65, 796, 8106, 62, 3882, 65, 7, 3882, 65, 8, 50284, 1326, 504, 11, 336, 9310, 796, 751, 62, 65, 3524, 62, 2301, 2234, 62, 83, 853, 1039, 7, 3882, 65, 8, 50284, 2, 3440, 3047, 1366, 50284, 27432, 62, 7890, 796, 15107, 3978, 353, 7, 3882, 65, 11, 50263, 43501, 62, 7857, 28, 15414, 62, 43501, 62, 7857, 11, 50263, 1477, 18137, 28, 1662, 645, 62, 1477, 18137, 11, 50263, 49464, 28, 49464, 11, 50263, 1818, 62, 2220, 62, 4868, 28, 1818, 62, 2220, 62, 4868, 11, 50263, 292, 806, 62, 8094, 278, 28, 11250, 13, 51, 3861, 1268, 13, 1921, 47, 9782, 62, 46846, 2751, 8, 50284, 2, 13249, 3509, 5485, 50284, 9806, 62, 7890, 62, 43358, 796, 685, 10786, 7890, 3256, 357, 15414, 62, 43501, 62, 7857, 11, 513, 11, 50257, 9806, 26933, 85, 58, 15, 60, 329, 410, 287, 4566, 13, 6173, 1847, 1546, 46570, 50257, 9806, 26933, 85, 58, 16, 60, 329, 410, 287, 4566, 13, 6173, 1847, 1546, 60, 4008, 15437, 50284, 6404, 1362, 13, 10951, 10786, 15234, 2530, 5415, 5485, 4064, 82, 6, 4064, 3509, 62, 7890, 62, 43358, 8, 50284, 2, 13249, 5485, 50284, 7890, 62, 43358, 62, 11600, 796, 8633, 7, 27432, 62, 7890, 13, 15234, 485, 62, 7890, 1343, 4512, 62, 7890, 13, 15234, 485, 62, 18242, 8, 50284, 853, 62, 43358, 11, 503, 62, 43358, 11, 27506, 62, 43358, 796, 5659, 13, 259, 2232, 62, 43358, 7, 1174, 7890, 62, 43358, 62, 11600, 8, 50284, 853, 62, 43358, 62, 11600, 796, 8633, 7, 13344, 7, 37047, 13, 4868, 62, 853, 2886, 22784, 1822, 62, 43358, 4008, 50284, 448, 62, 43358, 62, 11600, 796, 8633, 7, 13344, 7, 37047, 13, 4868, 62, 22915, 82, 22784, 503, 62, 43358, 4008, 50284, 14644, 62, 43358, 62, 11600, 796, 8633, 7, 13344, 7, 37047, 13, 4868, 62, 14644, 28129, 62, 27219, 22784, 27506, 62, 43358, 4008, 50284, 6404, 1362, 13, 10951, 10786, 22915, 5485, 4064, 82, 6, 4064, 279, 4798, 13, 79, 18982, 7, 448, 62, 43358, 62, 11600, 4008, 50284, 2, 3440, 290, 41216, 42287, 50284, 361, 15294, 25, 50280, 853, 62, 37266, 11, 27506, 62, 37266, 796, 3440, 62, 17143, 7, 40290, 11, 2221, 62, 538, 5374, 11, 10385, 28, 17821, 8, 50284, 17772, 25, 50280, 853, 62, 37266, 11, 27506, 62, 37266, 796, 3440, 62, 17143, 7, 5310, 13363, 11, 36835, 11, 10385, 28, 17821, 8, 50280, 853, 62, 37266, 17816, 565, 82, 62, 26675, 62, 6551, 20520, 796, 285, 87, 13, 25120, 13, 11265, 7, 50276, 15, 11, 657, 13, 486, 11, 5485, 28, 853, 62, 43358, 62, 11600, 17816, 565, 82, 62, 26675, 62, 6551, 6, 12962, 50280, 853, 62, 37266, 17816, 565, 82, 62, 26675, 62, 65, 4448, 20520, 796, 285, 87, 13, 358, 13, 9107, 418, 7, 50276, 43358, 28, 853, 62, 43358, 62, 11600, 17816, 565, 82, 62, 26675, 62, 65, 4448, 6, 12962, 50280, 853, 62, 37266, 17816, 65, 3524, 62, 28764, 62, 6551, 20520, 796, 285, 87, 13, 25120, 13, 11265, 7, 50276, 15, 11, 657, 13, 8298, 11, 5485, 28, 853, 62, 43358, 62, 11600, 17816, 65, 3524, 62, 28764, 62, 6551, 6, 12962, 50280, 853, 62, 37266, 17816, 65, 3524, 62, 28764, 62, 65, 4448, 20520, 796, 285, 87, 13, 358, 13, 9107, 418, 7], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'labels': [11748, 1822, 29572, 198, 11748, 279, 4798, 198, 11748, 285, 87, 3262, 355, 285, 87, 198, 198, 6738, 11485, 6404, 1362, 1330, 49706, 198, 6738, 11485, 11250, 1330, 4566, 11, 4277, 11, 7716, 62, 11250, 198, 6738, 11485, 1837, 23650, 1330, 1635, 198, 6738, 11485, 7295, 1330, 23838, 11, 18663, 198, 6738, 11485, 7295, 13, 29356, 1330, 15107, 3978, 353, 198, 6738, 11485, 7295, 13, 21412, 1330, 13859, 540, 26796, 198, 6738, 11485, 36948, 13, 65, 3524, 62, 2301, 2234, 1330, 751, 62, 65, 3524, 62, 2301, 2234, 62, 83, 853, 1039, 198, 6738, 11485, 26791, 13, 2220, 62, 7890, 1330, 3440, 62, 1676, 40007, 62, 3882, 65, 11, 20121, 62, 3882, 65, 11, 8106, 62, 3882, 65, 198, 6738, 11485, 26791, 13, 2220, 62, 19849, 1330, 3440, 62, 17143, 628, 198, 4299, 4512, 62, 6015, 20471, 7, 27349, 11, 27039, 11, 2939, 62, 2617, 11, 6808, 62, 6978, 11, 27039, 62, 6978, 11, 10792, 11, 50273, 74, 85, 8095, 11, 670, 62, 2220, 62, 4868, 11, 645, 62, 2704, 541, 11, 645, 62, 1477, 18137, 11, 15294, 11, 269, 17602, 11, 50273, 5310, 13363, 11, 36835, 11, 21231, 11, 2221, 62, 538, 5374, 11, 886, 62, 538, 5374, 11, 4512, 62, 28710, 11, 50273, 14050, 11, 300, 81, 62, 9662, 11, 6961, 2599, 50284, 2, 900, 510, 4566, 50284, 11250, 13, 51, 3861, 1268, 13, 33, 11417, 62, 3955, 25552, 796, 362, 50284, 11250, 13, 51, 3861, 1268, 13, 33, 11417, 62, 13252, 1797, 796, 13108, 50284, 361, 6961, 6624, 705, 824, 10354, 50280, 11250, 13, 51, 3861, 1268, 13, 40469, 62, 4221, 19535, 39, 62, 21982, 796, 657, 13, 16, 50286, 2, 22919, 12549, 371, 12, 18474, 50284, 2, 3440, 6194, 50284, 37047, 796, 5418, 10786, 1136, 62, 6, 1343, 3127, 1343, 705, 62, 6015, 20471, 6, 5769, 22510, 62, 37724, 28, 11250, 13, 41359, 62, 31631, 1546, 8, 50284, 2, 9058, 5021, 12, 46999, 50284, 43501, 62, 7857, 796, 18896, 7, 49464, 8, 50284, 15414, 62, 43501, 62, 7857, 796, 4566, 13, 51, 3861, 1268, 13, 33, 11417, 62, 3955, 25552, 1635, 15458, 62, 7857, 50284, 2, 3601, 4566, 50284, 6404, 1362, 13, 10951, 7, 381, 22272, 13, 79, 18982, 7, 11250, 4008, 50284, 2, 3440, 27039, 290, 8335, 545, 9945, 329, 3047, 50284, 9060, 62, 28709, 796, 685, 271, 316, 329, 318, 316, 287, 2939, 62, 2617, 13, 35312, 10786, 10, 11537, 60, 50284, 3882, 1443, 796, 685, 50280, 2220, 62, 1676, 40007, 62, 3882, 65, 7, 19608, 292, 316, 11, 50260, 9060, 62, 2617, 11, 50260, 15763, 62, 6978, 11, 50260, 19608, 292, 316, 62, 6978, 11, 50260, 1676, 40007, 28, 1676, 40007, 11, 50260, 33295, 62, 13655, 28, 17821, 11, 50260, 2704, 541, 28, 1662, 645, 62, 2704, 541, 8, 329, 2939, 62, 2617, 287, 2939, 62, 28709, 50284, 60, 50284, 3882, 65, 796, 20121, 62, 3882, 65, 7, 3882, 1443, 8, 50284, 3882, 65, 796, 8106, 62, 3882, 65, 7, 3882, 65, 8, 50284, 1326, 504, 11, 336, 9310, 796, 751, 62, 65, 3524, 62, 2301, 2234, 62, 83, 853, 1039, 7, 3882, 65, 8, 50284, 2, 3440, 3047, 1366, 50284, 27432, 62, 7890, 796, 15107, 3978, 353, 7, 3882, 65, 11, 50263, 43501, 62, 7857, 28, 15414, 62, 43501, 62, 7857, 11, 50263, 1477, 18137, 28, 1662, 645, 62, 1477, 18137, 11, 50263, 49464, 28, 49464, 11, 50263, 1818, 62, 2220, 62, 4868, 28, 1818, 62, 2220, 62, 4868, 11, 50263, 292, 806, 62, 8094, 278, 28, 11250, 13, 51, 3861, 1268, 13, 1921, 47, 9782, 62, 46846, 2751, 8, 50284, 2, 13249, 3509, 5485, 50284, 9806, 62, 7890, 62, 43358, 796, 685, 10786, 7890, 3256, 357, 15414, 62, 43501, 62, 7857, 11, 513, 11, 50257, 9806, 26933, 85, 58, 15, 60, 329, 410, 287, 4566, 13, 6173, 1847, 1546, 46570, 50257, 9806, 26933, 85, 58, 16, 60, 329, 410, 287, 4566, 13, 6173, 1847, 1546, 60, 4008, 15437, 50284, 6404, 1362, 13, 10951, 10786, 15234, 2530, 5415, 5485, 4064, 82, 6, 4064, 3509, 62, 7890, 62, 43358, 8, 50284, 2, 13249, 5485, 50284, 7890, 62, 43358, 62, 11600, 796, 8633, 7, 27432, 62, 7890, 13, 15234, 485, 62, 7890, 1343, 4512, 62, 7890, 13, 15234, 485, 62, 18242, 8, 50284, 853, 62, 43358, 11, 503, 62, 43358, 11, 27506, 62, 43358, 796, 5659, 13, 259, 2232, 62, 43358, 7, 1174, 7890, 62, 43358, 62, 11600, 8, 50284, 853, 62, 43358, 62, 11600, 796, 8633, 7, 13344, 7, 37047, 13, 4868, 62, 853, 2886, 22784, 1822, 62, 43358, 4008, 50284, 448, 62, 43358, 62, 11600, 796, 8633, 7, 13344, 7, 37047, 13, 4868, 62, 22915, 82, 22784, 503, 62, 43358, 4008, 50284, 14644, 62, 43358, 62, 11600, 796, 8633, 7, 13344, 7, 37047, 13, 4868, 62, 14644, 28129, 62, 27219, 22784, 27506, 62, 43358, 4008, 50284, 6404, 1362, 13, 10951, 10786, 22915, 5485, 4064, 82, 6, 4064, 279, 4798, 13, 79, 18982, 7, 448, 62, 43358, 62, 11600, 4008, 50284, 2, 3440, 290, 41216, 42287, 50284, 361, 15294, 25, 50280, 853, 62, 37266, 11, 27506, 62, 37266, 796, 3440, 62, 17143, 7, 40290, 11, 2221, 62, 538, 5374, 11, 10385, 28, 17821, 8, 50284, 17772, 25, 50280, 853, 62, 37266, 11, 27506, 62, 37266, 796, 3440, 62, 17143, 7, 5310, 13363, 11, 36835, 11, 10385, 28, 17821, 8, 50280, 853, 62, 37266, 17816, 565, 82, 62, 26675, 62, 6551, 20520, 796, 285, 87, 13, 25120, 13, 11265, 7, 50276, 15, 11, 657, 13, 486, 11, 5485, 28, 853, 62, 43358, 62, 11600, 17816, 565, 82, 62, 26675, 62, 6551, 6, 12962, 50280, 853, 62, 37266, 17816, 565, 82, 62, 26675, 62, 65, 4448, 20520, 796, 285, 87, 13, 358, 13, 9107, 418, 7, 50276, 43358, 28, 853, 62, 43358, 62, 11600, 17816, 565, 82, 62, 26675, 62, 65, 4448, 6, 12962, 50280, 853, 62, 37266, 17816, 65, 3524, 62, 28764, 62, 6551, 20520, 796, 285, 87, 13, 25120, 13, 11265, 7, 50276, 15, 11, 657, 13, 8298, 11, 5485, 28, 853, 62, 43358, 62, 11600, 17816, 65, 3524, 62, 28764, 62, 6551, 6, 12962, 50280, 853, 62, 37266, 17816, 65, 3524, 62, 28764, 62, 65, 4448, 20520, 796, 285, 87, 13, 358, 13, 9107, 418, 7]}
3.3.4 组装Batch
# 组装 Batch 数据 & Padding
batchify_fn = DataCollatorWithPadding(tokenizer, return_attention_mask=True)
3.3.5 构造Dataloader
# 分布式批采样器,用于多卡分布式训练
train_batch_sampler = DistributedBatchSampler(
train_dataset, batch_size=2, shuffle=True)
# 构造训练Dataloader
train_data_loader = DataLoader(dataset=train_dataset,
batch_sampler=train_batch_sampler,
num_workers=0,
collate_fn=batchify_fn,
return_list=True)
dev_batch_sampler = BatchSampler(dev_dataset,
batch_size=12,
shuffle=False)
# 构造验证Dataloader
dev_data_loader = DataLoader(dataset=dev_dataset,
batch_sampler=dev_batch_sampler,
num_workers=0,
collate_fn=batchify_fn,
return_list=True)
3.3.6 模型构建
以下面一条数据为例来讲解模型的输入和输出
{“code”: “def build_model(cfg):\n cfg_ = cfg.copy()\n name”}

图3 模型输入和输出
# 初始化模型
model = CodeGenForCausalLM.from_pretrained('Salesforce/codegen-350M-mono')
[2022-10-21 10:17:58,193] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/community/Salesforce/codegen-350M-mono/model_state.pdparams and saved to /home/aistudio/.paddlenlp/models/Salesforce/codegen-350M-mono
[2022-10-21 10:17:58,196] [ INFO] - Downloading model_state.pdparams from https://bj.bcebos.com/paddlenlp/models/community/Salesforce/codegen-350M-mono/model_state.pdparams
100%|██████████| 760M/760M [00:11<00:00, 67.9MB/s]
[2022-10-21 10:18:10,085] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/community/Salesforce/codegen-350M-mono/model_config.json and saved to /home/aistudio/.paddlenlp/models/Salesforce/codegen-350M-mono
[2022-10-21 10:18:10,088] [ INFO] - Downloading model_config.json from https://bj.bcebos.com/paddlenlp/models/community/Salesforce/codegen-350M-mono/model_config.json
100%|██████████| 535/535 [00:00<00:00, 456kB/s]
W1021 10:18:10.161597 165 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W1021 10:18:10.165860 165 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
3.3.7 训练配置
# 学习率预热比例
warmup = 0.02
# 学习率
learning_rate = 5e-5
# 训练轮次
num_epochs = 3
# 训练总步数
num_training_steps = len(train_data_loader) * num_epochs
# AdamW优化器参数epsilon
adam_epsilon = 1e-6
# AdamW优化器参数weight_decay
weight_decay=0.01
# # 训练中,每个log_steps打印一次日志
log_steps = 1
# 训练中,每隔eval_steps进行一次模型评估
eval_steps = 1000
# 训练模型保存路径
output_dir = 'checkpoints'
log_writer = LogWriter('visualdl_log_dir')
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps, warmup)
# LayerNorm参数不参与weight_decay
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
# 优化器AdamW
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
beta1=0.9,
beta2=0.999,
epsilon=adam_epsilon,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
# 交叉熵损失函数
loss_fct = nn.CrossEntropyLoss()
# 评估参数,计算验证集上loss和困惑度
@paddle.no_grad()
def evaluate(model, data_loader, loss_fct):
model.eval()
losses = []
model = model._layers if isinstance(model, paddle.DataParallel) else model
for batch in data_loader:
labels = batch.pop("labels")
logits, _ = model(**batch)
loss = loss_fct(logits[:, :-1, :], labels[:, 1:])
losses.append(loss)
losses = paddle.concat(losses)
eval_loss = paddle.mean(losses)
perplexity = math.exp(eval_loss)
logger.info("[validation] loss: %f, ppl: %f" %
(eval_loss, perplexity))
model.train()
return perplexity
3.3.8 模型训练和评估
def train(model, train_data_loader):
global_step = 0
best_eval_ppl = float("inf")
tic_train = time.time()
for epoch in range(num_epochs):
for step, batch in enumerate(train_data_loader):
global_step += 1
labels = batch.pop("labels")
# 模型前向训练,计算loss
logits, _ = model(**batch)
# 计算loss
loss = loss_fct(logits[:, :-1, :], labels[:, 1:])
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
if global_step % log_steps == 0:
logger.info(
"global step %d/%d, epoch: %d, batch: %d, rank_id: %s, loss: %f, ppl: %f, lr: %.10f, speed: %.4f step/s"
% (global_step, num_training_steps, epoch, step,
paddle.distributed.get_rank(), loss, math.exp(loss),
optimizer.get_lr(), log_steps /
(time.time() - tic_train)))
tic_train = time.time()
log_writer.add_scalar("train_loss", loss.numpy(), global_step)
if global_step % eval_steps == 0 or global_step == num_training_steps:
tic_eval = time.time()
ppl = evaluate(model, dev_data_loader, loss_fct)
logger.info("eval done total : %s s" % (time.time() - tic_eval))
log_writer.add_scalar("eval_ppl", ppl, global_step)
if best_eval_ppl > ppl and paddle.distributed.get_rank() == 0:
best_eval_ppl = ppl
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# Need better way to get inner model of DataParallel
model_to_save = model._layers if isinstance(
model, paddle.DataParallel) else model
model_to_save.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
# 调用模型训练
train(model, train_data_loader)
[2022-10-20 22:09:15,211] [ INFO] - global step 1/2841, epoch: 0, batch: 0, rank_id: 0, loss: 1.082609, ppl: 2.952371, lr: 0.0000008929, speed: 3.8606 step/s
[2022-10-20 22:09:15,443] [ INFO] - global step 2/2841, epoch: 0, batch: 1, rank_id: 0, loss: 1.323762, ppl: 3.757532, lr: 0.0000017857, speed: 4.3524 step/s
[2022-10-20 22:09:15,672] [ INFO] - global step 3/2841, epoch: 0, batch: 2, rank_id: 0, loss: 0.876736, ppl: 2.403043, lr: 0.0000026786, speed: 4.3971 step/s
[2022-10-20 22:09:15,904] [ INFO] - global step 4/2841, epoch: 0, batch: 3, rank_id: 0, loss: 0.685214, ppl: 1.984197, lr: 0.0000035714, speed: 4.3499 step/s
[2022-10-20 22:09:16,136] [ INFO] - global step 5/2841, epoch: 0, batch: 4, rank_id: 0, loss: 0.809222, ppl: 2.246159, lr: 0.0000044643, speed: 4.3485 step/s
[2022-10-20 22:09:16,369] [ INFO] - global step 6/2841, epoch: 0, batch: 5, rank_id: 0, loss: 1.275675, ppl: 3.581118, lr: 0.0000053571, speed: 4.3371 step/s
[2022-10-20 22:09:16,601] [ INFO] - global step 7/2841, epoch: 0, batch: 6, rank_id: 0, loss: 1.088982, ppl: 2.971248, lr: 0.0000062500, speed: 4.3457 step/s
[2022-10-20 22:09:16,833] [ INFO] - global step 8/2841, epoch: 0, batch: 7, rank_id: 0, loss: 0.976502, ppl: 2.655153, lr: 0.0000071429, speed: 4.3439 step/s
[2022-10-20 22:09:17,066] [ INFO] - global step 9/2841, epoch: 0, batch: 8, rank_id: 0, loss: 0.935320, ppl: 2.548029, lr: 0.0000080357, speed: 4.3421 step/s
[2022-10-20 22:09:17,299] [ INFO] - global step 10/2841, epoch: 0, batch: 9, rank_id: 0, loss: 0.649544, ppl: 1.914668, lr: 0.0000089286, speed: 4.3195 step/s
[2022-10-20 22:09:17,532] [ INFO] - global step 11/2841, epoch: 0, batch: 10, rank_id: 0, loss: 1.040924, ppl: 2.831832, lr: 0.0000098214, speed: 4.3346 step/s
[2022-10-20 22:09:17,766] [ INFO] - global step 12/2841, epoch: 0, batch: 11, rank_id: 0, loss: 0.992122, ppl: 2.696952, lr: 0.0000107143, speed: 4.3225 step/s
[2022-10-20 22:09:18,000] [ INFO] - global step 13/2841, epoch: 0, batch: 12, rank_id: 0, loss: 0.753892, ppl: 2.125256, lr: 0.0000116071, speed: 4.3146 step/s
[2022-10-20 22:09:18,233] [ INFO] - global step 14/2841, epoch: 0, batch: 13, rank_id: 0, loss: 0.840042, ppl: 2.316464, lr: 0.0000125000, speed: 4.3250 step/s
[2022-10-20 22:09:18,466] [ INFO] - global step 15/2841, epoch: 0, batch: 14, rank_id: 0, loss: 0.669627, ppl: 1.953508, lr: 0.0000133929, speed: 4.3220 step/s
[2022-10-20 22:09:18,700] [ INFO] - global step 16/2841, epoch: 0, batch: 15, rank_id: 0, loss: 0.944958, ppl: 2.572705, lr: 0.0000142857, speed: 4.3231 step/s
[2022-10-20 22:09:18,937] [ INFO] - global step 17/2841, epoch: 0, batch: 16, rank_id: 0, loss: 0.978635, ppl: 2.660823, lr: 0.0000151786, speed: 4.2543 step/s
[2022-10-20 22:09:19,169] [ INFO] - global step 18/2841, epoch: 0, batch: 17, rank_id: 0, loss: 0.487206, ppl: 1.627762, lr: 0.0000160714, speed: 4.3372 step/s
[2022-10-20 22:09:19,402] [ INFO] - global step 19/2841, epoch: 0, batch: 18, rank_id: 0, loss: 0.714138, ppl: 2.042425, lr: 0.0000169643, speed: 4.3345 step/s
[2022-10-20 22:09:19,634] [ INFO] - global step 20/2841, epoch: 0, batch: 19, rank_id: 0, loss: 0.574549, ppl: 1.776329, lr: 0.0000178571, speed: 4.3467 step/s
[2022-10-20 22:09:19,866] [ INFO] - global step 21/2841, epoch: 0, batch: 20, rank_id: 0, loss: 0.876465, ppl: 2.402392, lr: 0.0000187500, speed: 4.3502 step/s
[2022-10-20 22:09:20,101] [ INFO] - global step 22/2841, epoch: 0, batch: 21, rank_id: 0, loss: 0.913497, ppl: 2.493025, lr: 0.0000196429, speed: 4.2947 step/s
[2022-10-20 22:09:20,333] [ INFO] - global step 23/2841, epoch: 0, batch: 22, rank_id: 0, loss: 0.694862, ppl: 2.003433, lr: 0.0000205357, speed: 4.3436 step/s
[2022-10-20 22:09:20,568] [ INFO] - global step 24/2841, epoch: 0, batch: 23, rank_id: 0, loss: 0.885861, ppl: 2.425071, lr: 0.0000214286, speed: 4.3025 step/s
[2022-10-20 22:09:20,800] [ INFO] - global step 25/2841, epoch: 0, batch: 24, rank_id: 0, loss: 1.042256, ppl: 2.835608, lr: 0.0000223214, speed: 4.3576 step/s
[2022-10-20 22:09:21,031] [ INFO] - global step 26/2841, epoch: 0, batch: 25, rank_id: 0, loss: 0.512760, ppl: 1.669894, lr: 0.0000232143, speed: 4.3592 step/s
[2022-10-20 22:09:21,265] [ INFO] - global step 27/2841, epoch: 0, batch: 26, rank_id: 0, loss: 0.668105, ppl: 1.950538, lr: 0.0000241071, speed: 4.3141 step/s
[2022-10-20 22:09:21,498] [ INFO] - global step 28/2841, epoch: 0, batch: 27, rank_id: 0, loss: 0.826647, ppl: 2.285642, lr: 0.0000250000, speed: 4.3274 step/s
[2022-10-20 22:09:21,730] [ INFO] - global step 29/2841, epoch: 0, batch: 28, rank_id: 0, loss: 0.759358, ppl: 2.136904, lr: 0.0000258929, speed: 4.3514 step/s
[2022-10-20 22:09:21,965] [ INFO] - global step 30/2841, epoch: 0, batch: 29, rank_id: 0, loss: 0.666526, ppl: 1.947460, lr: 0.0000267857, speed: 4.2892 step/s
[2022-10-20 22:09:22,211] [ INFO] - global step 31/2841, epoch: 0, batch: 30, rank_id: 0, loss: 0.793827, ppl: 2.211844, lr: 0.0000276786, speed: 4.1057 step/s
[2022-10-20 22:09:22,446] [ INFO] - global step 32/2841, epoch: 0, batch: 31, rank_id: 0, loss: 0.647644, ppl: 1.911034, lr: 0.0000285714, speed: 4.2872 step/s
[2022-10-20 22:09:22,685] [ INFO] - global step 33/2841, epoch: 0, batch: 32, rank_id: 0, loss: 0.675663, ppl: 1.965336, lr: 0.0000294643, speed: 4.2257 step/s
[2022-10-20 22:09:22,938] [ INFO] - global step 34/2841, epoch: 0, batch: 33, rank_id: 0, loss: 1.066386, ppl: 2.904862, lr: 0.0000303571, speed: 3.9969 step/s
3.3.9 模型推理
# 模型推理,针对单条代码,进行续写补全
def infer(text, model, tokenizer):
tokenized = tokenizer(text,
truncation=True,
max_length=block_size,
return_tensors='pd')
preds, _ = model.generate(input_ids=tokenized['input_ids'],
max_length=128)
print(tokenizer.decode(preds[0], skip_special_tokens=True, clean_up_tokenization_spaces=False))
# 加载训练好的模型
model = CodeGenForCausalLM.from_pretrained('checkpoints')
tokenizer = CodeGenTokenizer.from_pretrained('checkpoints')
text = 'def hello_world():'
infer(text, model, tokenizer)
print("Hello World")
hello_world()
#
完整项目见:https://github.com/PaddlePaddle/PaddleNLP/blob/develop/examples/code_generation/codegen
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)